mirror of
https://github.com/junegunn/fzf
synced 2026-06-09 10:03:17 +00:00
Compare commits
1 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a0ef8987fb |
@@ -1,20 +0,0 @@
|
||||
root = true
|
||||
|
||||
[*.{sh,bash,fish}]
|
||||
indent_style = space
|
||||
indent_size = 2
|
||||
simplify = true
|
||||
binary_next_line = false
|
||||
switch_case_indent = true
|
||||
space_redirects = true
|
||||
function_next_line = false
|
||||
|
||||
# also bash scripts.
|
||||
[{install,uninstall,bin/fzf-preview.sh,bin/fzf-tmux}]
|
||||
indent_style = space
|
||||
indent_size = 2
|
||||
simplify = true
|
||||
binary_next_line = false
|
||||
switch_case_indent = true
|
||||
space_redirects = true
|
||||
function_next_line = false
|
||||
@@ -1 +0,0 @@
|
||||
* @junegunn
|
||||
+1
-1
@@ -1 +1 @@
|
||||
github: junegunn
|
||||
custom: ["https://paypal.me/junegunn", "https://www.buymeacoffee.com/junegunn"]
|
||||
|
||||
@@ -0,0 +1,22 @@
|
||||
<!-- ISSUES NOT FOLLOWING THIS TEMPLATE WILL BE CLOSED AND DELETED -->
|
||||
|
||||
<!-- Check all that apply [x] -->
|
||||
|
||||
- [ ] I have read through the manual page (`man fzf`)
|
||||
- [ ] I have the latest version of fzf
|
||||
- [ ] I have searched through the existing issues
|
||||
|
||||
## Info
|
||||
|
||||
- OS
|
||||
- [ ] Linux
|
||||
- [ ] Mac OS X
|
||||
- [ ] Windows
|
||||
- [ ] Etc.
|
||||
- Shell
|
||||
- [ ] bash
|
||||
- [ ] zsh
|
||||
- [ ] fish
|
||||
|
||||
## Problem / Steps to reproduce
|
||||
|
||||
@@ -1,49 +0,0 @@
|
||||
---
|
||||
name: Issue Template
|
||||
description: Report a problem or bug related to fzf to help us improve
|
||||
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: ISSUES NOT FOLLOWING THIS TEMPLATE WILL BE CLOSED AND DELETED
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Checklist
|
||||
options:
|
||||
- label: I have read through the manual page (`man fzf`)
|
||||
required: true
|
||||
- label: I have searched through the existing issues
|
||||
required: true
|
||||
- label: For bug reports, I have checked if the bug is reproducible in the latest version of fzf
|
||||
required: false
|
||||
|
||||
- type: input
|
||||
attributes:
|
||||
label: Output of `fzf --version`
|
||||
placeholder: e.g. 0.48.1 (d579e33)
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: OS
|
||||
options:
|
||||
- label: Linux
|
||||
- label: macOS
|
||||
- label: Windows
|
||||
- label: Etc.
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Shell
|
||||
options:
|
||||
- label: bash
|
||||
- label: zsh
|
||||
- label: fish
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Problem / Steps to reproduce
|
||||
validations:
|
||||
required: true
|
||||
@@ -1,17 +0,0 @@
|
||||
## Contribution Policy
|
||||
|
||||
We do not accept pull requests generated primarily by AI without genuine understanding or real-world usage context.
|
||||
|
||||
All contributions are expected to demonstrate:
|
||||
- A clear understanding of the codebase
|
||||
- Alignment with product direction
|
||||
- Thoughtful reasoning behind changes
|
||||
- Evidence of real-world usage or hands-on experience with the problem
|
||||
|
||||
If these expectations are not met, we would prefer to implement the changes ourselves rather than spend time reviewing low-effort submissions.
|
||||
|
||||
---
|
||||
|
||||
## Acknowledgement
|
||||
|
||||
- [ ] I confirm that this PR meets the above expectations and reflects my own understanding and real-world context.
|
||||
@@ -1,64 +0,0 @@
|
||||
go:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- src/**
|
||||
- main.go
|
||||
- go.mod
|
||||
- go.sum
|
||||
|
||||
shell:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- shell/**
|
||||
|
||||
bash:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- shell/**/*.bash
|
||||
|
||||
zsh:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- shell/**/*.zsh
|
||||
|
||||
fish:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- shell/**/*.fish
|
||||
|
||||
vim:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- plugin/**
|
||||
|
||||
docs:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- '*.md'
|
||||
- doc/**
|
||||
- man/**
|
||||
|
||||
ci:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- .github/**
|
||||
|
||||
build:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- Makefile
|
||||
- .goreleaser.yml
|
||||
- Dockerfile
|
||||
|
||||
test:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- test/**
|
||||
- src/**/*_test.go
|
||||
|
||||
install:
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- install
|
||||
- install.ps1
|
||||
- uninstall
|
||||
@@ -27,18 +27,18 @@ jobs:
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v5
|
||||
uses: actions/checkout@629c2de402a417ea7690ca6ce3f33229e27606a5 # v2
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
# Initializes the CodeQL tools for scanning.
|
||||
- name: Initialize CodeQL
|
||||
uses: github/codeql-action/init@v4
|
||||
uses: github/codeql-action/init@1ed1437484560351c5be56cf73a48a279d116b78
|
||||
with:
|
||||
languages: ${{ matrix.language }}
|
||||
|
||||
- name: Autobuild
|
||||
uses: github/codeql-action/autobuild@v4
|
||||
uses: github/codeql-action/autobuild@1ed1437484560351c5be56cf73a48a279d116b78
|
||||
|
||||
- name: Perform CodeQL Analysis
|
||||
uses: github/codeql-action/analyze@v4
|
||||
uses: github/codeql-action/analyze@1ed1437484560351c5be56cf73a48a279d116b78
|
||||
|
||||
@@ -1,14 +0,0 @@
|
||||
name: 'Dependency Review'
|
||||
on: [pull_request]
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
dependency-review:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: 'Checkout Repository'
|
||||
uses: actions/checkout@v5
|
||||
- name: 'Dependency Review'
|
||||
uses: actions/dependency-review-action@v5
|
||||
@@ -1,17 +0,0 @@
|
||||
name: Label PRs
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
types: [opened, synchronize, reopened]
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
label:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/labeler@v6
|
||||
with:
|
||||
configuration-path: .github/labeler.yml
|
||||
+12
-25
@@ -1,58 +1,45 @@
|
||||
---
|
||||
name: build
|
||||
name: Test fzf on Linux
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ master, devel ]
|
||||
pull_request:
|
||||
branches: [ master, devel ]
|
||||
branches: [ master ]
|
||||
workflow_dispatch:
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
env:
|
||||
LANG: C.UTF-8
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-24.04
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v5
|
||||
- uses: actions/checkout@629c2de402a417ea7690ca6ce3f33229e27606a5 # v2
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Set up Go
|
||||
uses: actions/setup-go@v6
|
||||
uses: actions/setup-go@f6164bd8c8acb4a71fb2791a8b6c4024ff038dab # v2
|
||||
with:
|
||||
go-version: "1.23"
|
||||
go-version: 1.18
|
||||
|
||||
- name: Setup Ruby
|
||||
uses: ruby/setup-ruby@afeafc3d1ab54a631816aba4c914a0081c12ff2f # v1
|
||||
uses: ruby/setup-ruby@ebaea52cb20fea395b0904125276395e37183dac
|
||||
with:
|
||||
ruby-version: 3.4.6
|
||||
ruby-version: 3.0.0
|
||||
|
||||
- name: Install packages
|
||||
run: |
|
||||
sudo install -d -m 0755 /etc/apt/keyrings
|
||||
wget -qO- https://apt.fury.io/nushell/gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/fury-nushell.gpg
|
||||
echo "deb [signed-by=/etc/apt/keyrings/fury-nushell.gpg] https://apt.fury.io/nushell/ /" | sudo tee /etc/apt/sources.list.d/fury-nushell.list
|
||||
sudo apt-get update
|
||||
sudo apt-get install --yes zsh fish tmux shfmt nushell
|
||||
run: sudo apt-get install --yes zsh fish tmux
|
||||
|
||||
- name: Install Ruby gems
|
||||
run: bundle install
|
||||
run: sudo gem install --no-document minitest:5.14.2 rubocop:1.0.0 rubocop-minitest:0.10.1 rubocop-performance:1.8.1
|
||||
|
||||
- name: Rubocop
|
||||
run: make lint
|
||||
run: rubocop --require rubocop-minitest --require rubocop-performance
|
||||
|
||||
- name: Unit test
|
||||
run: make test
|
||||
|
||||
- name: Fuzz test
|
||||
run: |
|
||||
go test ./src/algo/ -fuzz=FuzzIndexByteTwo -fuzztime=5s
|
||||
go test ./src/algo/ -fuzz=FuzzLastIndexByteTwo -fuzztime=5s
|
||||
|
||||
- name: Integration test
|
||||
run: make install && ./install --all && tmux new-session -d && ruby test/runner.rb --verbose
|
||||
run: make install && ./install --all && LC_ALL=C tmux new-session -d && ruby test/test_go.rb --verbose
|
||||
|
||||
@@ -15,22 +15,22 @@ jobs:
|
||||
build:
|
||||
runs-on: macos-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v5
|
||||
- uses: actions/checkout@629c2de402a417ea7690ca6ce3f33229e27606a5 # v2
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Set up Go
|
||||
uses: actions/setup-go@v6
|
||||
uses: actions/setup-go@f6164bd8c8acb4a71fb2791a8b6c4024ff038dab # v2
|
||||
with:
|
||||
go-version: "1.23"
|
||||
go-version: 1.18
|
||||
|
||||
- name: Setup Ruby
|
||||
uses: ruby/setup-ruby@afeafc3d1ab54a631816aba4c914a0081c12ff2f # v1
|
||||
uses: ruby/setup-ruby@ebaea52cb20fea395b0904125276395e37183dac
|
||||
with:
|
||||
ruby-version: 3.0.0
|
||||
|
||||
- name: Install packages
|
||||
run: HOMEBREW_NO_INSTALL_CLEANUP=1 brew install fish zsh tmux shfmt
|
||||
run: HOMEBREW_NO_INSTALL_CLEANUP=1 brew install fish zsh tmux
|
||||
|
||||
- name: Install Ruby gems
|
||||
run: gem install --no-document minitest:5.14.2 rubocop:1.0.0 rubocop-minitest:0.10.1 rubocop-performance:1.8.1
|
||||
|
||||
@@ -1,76 +0,0 @@
|
||||
name: Release
|
||||
|
||||
on:
|
||||
push:
|
||||
tags:
|
||||
- 'v*'
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version:
|
||||
description: 'Version to validate (e.g. 0.73.0).'
|
||||
type: string
|
||||
required: true
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
|
||||
jobs:
|
||||
release:
|
||||
runs-on: macos-latest
|
||||
environment: release
|
||||
steps:
|
||||
- uses: actions/checkout@v6
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- uses: actions/setup-go@v6
|
||||
with:
|
||||
go-version: stable
|
||||
|
||||
- name: Determine version
|
||||
id: ver
|
||||
run: |
|
||||
if [ "${{ github.event_name }}" = "push" ]; then
|
||||
v=${GITHUB_REF_NAME#v}
|
||||
else
|
||||
v='${{ inputs.version }}'
|
||||
fi
|
||||
echo "version=$v" >> "$GITHUB_OUTPUT"
|
||||
echo "Resolved version: '$v'"
|
||||
|
||||
- name: Verify version consistency
|
||||
run: |
|
||||
set -e
|
||||
V='${{ steps.ver.outputs.version }}'
|
||||
R=$(echo "$V" | sed 's/\./\\./g')
|
||||
grep -q "^${R}$" CHANGELOG.md
|
||||
grep -qF "\"fzf ${V}\"" man/man1/fzf.1
|
||||
grep -qF "\"fzf ${V}\"" man/man1/fzf-tmux.1
|
||||
grep -qF "${V}" install
|
||||
grep -qF "${V}" install.ps1
|
||||
|
||||
- name: Extract release notes
|
||||
run: |
|
||||
set -e
|
||||
mkdir -p tmp
|
||||
V='${{ steps.ver.outputs.version }}'
|
||||
R=$(echo "$V" | sed 's/\./\\./g')
|
||||
sed -n "/^${R}$/,/^[0-9]/p" CHANGELOG.md \
|
||||
| tail -r | sed '1,/^ *$/d' | tail -r | sed '1,2d' \
|
||||
| tee tmp/release-note
|
||||
|
||||
- name: Run goreleaser
|
||||
uses: goreleaser/goreleaser-action@v7
|
||||
with:
|
||||
version: latest
|
||||
args: >-
|
||||
${{ github.event_name == 'push'
|
||||
&& 'release --clean --release-notes tmp/release-note'
|
||||
|| 'release --snapshot --clean --skip=publish' }}
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.RELEASE_PAT }}
|
||||
MACOS_SIGN_P12: ${{ secrets.MACOS_SIGN_P12 }}
|
||||
MACOS_SIGN_PASSWORD: ${{ secrets.MACOS_SIGN_PASSWORD }}
|
||||
MACOS_NOTARY_ISSUER_ID: ${{ secrets.MACOS_NOTARY_ISSUER_ID }}
|
||||
MACOS_NOTARY_KEY_ID: ${{ secrets.MACOS_NOTARY_KEY_ID }}
|
||||
MACOS_NOTARY_KEY: ${{ secrets.MACOS_NOTARY_KEY }}
|
||||
@@ -1,10 +0,0 @@
|
||||
name: "Spell Check"
|
||||
on: [pull_request]
|
||||
|
||||
jobs:
|
||||
typos:
|
||||
name: Spell Check with Typos
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v5
|
||||
- uses: crate-ci/typos@685eb3d55be2f85191e8c84acb9f44d7756f84ab # v1.29.4
|
||||
@@ -1,21 +0,0 @@
|
||||
name: Publish to Winget
|
||||
on:
|
||||
release:
|
||||
types: [released]
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
release-tag:
|
||||
description: 'Release tag to submit (e.g. v0.73.1)'
|
||||
required: true
|
||||
type: string
|
||||
|
||||
jobs:
|
||||
publish:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: vedantmgoyal2009/winget-releaser@4ffc7888bffd451b357355dc214d43bb9f23917e # v2
|
||||
with:
|
||||
identifier: junegunn.fzf
|
||||
release-tag: ${{ inputs.release-tag || github.event.release.tag_name }}
|
||||
installers-regex: '-windows_(armv7|arm64|amd64)\.zip$'
|
||||
token: ${{ secrets.WINGET_TOKEN }}
|
||||
+1
-1
@@ -3,6 +3,7 @@ bin/fzf.exe
|
||||
dist
|
||||
target
|
||||
pkg
|
||||
Gemfile.lock
|
||||
.DS_Store
|
||||
doc/tags
|
||||
vendor
|
||||
@@ -11,4 +12,3 @@ gopath
|
||||
fzf
|
||||
tmp
|
||||
*.patch
|
||||
.idea
|
||||
|
||||
+66
-61
@@ -1,5 +1,4 @@
|
||||
---
|
||||
version: 2
|
||||
project_name: fzf
|
||||
|
||||
before:
|
||||
@@ -7,28 +6,76 @@ before:
|
||||
- go mod download
|
||||
|
||||
builds:
|
||||
- id: fzf
|
||||
- id: fzf-macos
|
||||
binary: fzf
|
||||
goos:
|
||||
- darwin
|
||||
goarch:
|
||||
- amd64
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
hooks:
|
||||
post: |
|
||||
sh -c '
|
||||
cat > /tmp/fzf-gon-amd64.hcl << EOF
|
||||
source = ["./dist/fzf-macos_darwin_amd64/fzf"]
|
||||
bundle_id = "kr.junegunn.fzf"
|
||||
apple_id {
|
||||
username = "junegunn.c@gmail.com"
|
||||
password = "@env:AC_PASSWORD"
|
||||
}
|
||||
sign {
|
||||
application_identity = "Developer ID Application: Junegunn Choi (Y254DRW44Z)"
|
||||
}
|
||||
zip {
|
||||
output_path = "./dist/fzf-{{ .Version }}-darwin_amd64.zip"
|
||||
}
|
||||
EOF
|
||||
gon /tmp/fzf-gon-amd64.hcl
|
||||
'
|
||||
|
||||
- id: fzf-macos-arm
|
||||
binary: fzf
|
||||
goos:
|
||||
- darwin
|
||||
goarch:
|
||||
- arm64
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
hooks:
|
||||
post: |
|
||||
sh -c '
|
||||
cat > /tmp/fzf-gon-arm64.hcl << EOF
|
||||
source = ["./dist/fzf-macos-arm_darwin_arm64/fzf"]
|
||||
bundle_id = "kr.junegunn.fzf"
|
||||
apple_id {
|
||||
username = "junegunn.c@gmail.com"
|
||||
password = "@env:AC_PASSWORD"
|
||||
}
|
||||
sign {
|
||||
application_identity = "Developer ID Application: Junegunn Choi (Y254DRW44Z)"
|
||||
}
|
||||
zip {
|
||||
output_path = "./dist/fzf-{{ .Version }}-darwin_arm64.zip"
|
||||
}
|
||||
EOF
|
||||
gon /tmp/fzf-gon-arm64.hcl
|
||||
'
|
||||
|
||||
- id: fzf
|
||||
goos:
|
||||
- linux
|
||||
- windows
|
||||
- freebsd
|
||||
- openbsd
|
||||
- android
|
||||
goarch:
|
||||
- amd64
|
||||
- arm
|
||||
- arm64
|
||||
- loong64
|
||||
- ppc64le
|
||||
- s390x
|
||||
- riscv64
|
||||
goarm:
|
||||
- "5"
|
||||
- "6"
|
||||
- "7"
|
||||
flags:
|
||||
- -trimpath
|
||||
- 5
|
||||
- 6
|
||||
- 7
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
ignore:
|
||||
@@ -40,59 +87,15 @@ builds:
|
||||
goarch: arm64
|
||||
- goos: openbsd
|
||||
goarch: arm64
|
||||
- goos: openbsd
|
||||
goarch: riscv64
|
||||
- goos: android
|
||||
goarch: amd64
|
||||
- goos: android
|
||||
goarch: arm
|
||||
|
||||
# .goreleaser.yaml
|
||||
notarize:
|
||||
macos:
|
||||
- # Whether this configuration is enabled or not.
|
||||
#
|
||||
# Default: false.
|
||||
# Templates: allowed.
|
||||
enabled: "{{ not .IsSnapshot }}"
|
||||
|
||||
# Before notarizing, we need to sign the binary.
|
||||
# This blocks defines the configuration for doing so.
|
||||
sign:
|
||||
# The .p12 certificate file path or its base64'd contents.
|
||||
certificate: "{{.Env.MACOS_SIGN_P12}}"
|
||||
|
||||
# The password to be used to open the certificate.
|
||||
password: "{{.Env.MACOS_SIGN_PASSWORD}}"
|
||||
|
||||
# Then, we notarize the binaries.
|
||||
notarize:
|
||||
# The issuer ID.
|
||||
# Its the UUID you see when creating the App Store Connect key.
|
||||
issuer_id: "{{.Env.MACOS_NOTARY_ISSUER_ID}}"
|
||||
|
||||
# Key ID.
|
||||
# You can see it in the list of App Store Connect Keys.
|
||||
# It will also be in the ApiKey filename.
|
||||
key_id: "{{.Env.MACOS_NOTARY_KEY_ID}}"
|
||||
|
||||
# The .p8 key file path or its base64'd contents.
|
||||
key: "{{.Env.MACOS_NOTARY_KEY}}"
|
||||
|
||||
# Whether to wait for the notarization to finish.
|
||||
# Not recommended, as it could take a really long time.
|
||||
wait: true
|
||||
|
||||
archives:
|
||||
- name_template: "{{ .ProjectName }}-{{ .Version }}-{{ .Os }}_{{ .Arch }}{{ if .Arm }}v{{ .Arm }}{{ end }}"
|
||||
ids:
|
||||
builds:
|
||||
- fzf
|
||||
formats:
|
||||
- tar.gz
|
||||
format: tar.gz
|
||||
format_overrides:
|
||||
- goos: windows
|
||||
formats:
|
||||
- zip
|
||||
format: zip
|
||||
files:
|
||||
- non-existent*
|
||||
|
||||
@@ -101,10 +104,12 @@ release:
|
||||
owner: junegunn
|
||||
name: fzf
|
||||
prerelease: auto
|
||||
name_template: '{{ .Version }}'
|
||||
name_template: '{{ .Tag }}'
|
||||
extra_files:
|
||||
- glob: ./dist/fzf-*darwin*.zip
|
||||
|
||||
snapshot:
|
||||
version_template: "{{ .Version }}-devel"
|
||||
name_template: "{{ .Tag }}-devel"
|
||||
|
||||
changelog:
|
||||
sort: asc
|
||||
|
||||
+2
-16
@@ -1,16 +1,12 @@
|
||||
AllCops:
|
||||
NewCops: enable
|
||||
Layout/LineLength:
|
||||
Enabled: false
|
||||
Metrics:
|
||||
Enabled: false
|
||||
Lint/ShadowingOuterLocalVariable:
|
||||
Enabled: false
|
||||
Lint/NestedMethodDefinition:
|
||||
Enabled: false
|
||||
Style/MethodCallWithArgsParentheses:
|
||||
Enabled: true
|
||||
AllowedMethods:
|
||||
IgnoredMethods:
|
||||
- assert
|
||||
- exit
|
||||
- paste
|
||||
@@ -19,7 +15,7 @@ Style/MethodCallWithArgsParentheses:
|
||||
- refute
|
||||
- require
|
||||
- send_keys
|
||||
AllowedPatterns:
|
||||
IgnoredPatterns:
|
||||
- ^assert_
|
||||
- ^refute_
|
||||
Style/NumericPredicate:
|
||||
@@ -30,13 +26,3 @@ Style/OptionalBooleanParameter:
|
||||
Enabled: false
|
||||
Style/WordArray:
|
||||
MinSize: 1
|
||||
Minitest/AssertEqual:
|
||||
Enabled: false
|
||||
Minitest/EmptyLineBeforeAssertionMethods:
|
||||
Enabled: false
|
||||
Naming/VariableNumber:
|
||||
Enabled: false
|
||||
Lint/EmptyBlock:
|
||||
Enabled: false
|
||||
Style/SafeNavigationChainLength:
|
||||
Enabled: false
|
||||
|
||||
+1
-3
@@ -1,3 +1 @@
|
||||
golang 1.23
|
||||
ruby 3.4
|
||||
shfmt 3.12
|
||||
golang 1.18
|
||||
|
||||
+136
-246
@@ -1,36 +1,30 @@
|
||||
Advanced fzf examples
|
||||
======================
|
||||
|
||||
* *Last update: 2025/02/02*
|
||||
* *Requires fzf 0.59.0 or later*
|
||||
|
||||
---
|
||||
*(Last update: 2021/05/22)*
|
||||
|
||||
<!-- vim-markdown-toc GFM -->
|
||||
|
||||
* [Introduction](#introduction)
|
||||
* [Display modes](#display-modes)
|
||||
* [`--height`](#--height)
|
||||
* [`--tmux`](#--tmux)
|
||||
* [Screen Layout](#screen-layout)
|
||||
* [`--height`](#--height)
|
||||
* [`fzf-tmux`](#fzf-tmux)
|
||||
* [Popup window support](#popup-window-support)
|
||||
* [Dynamic reloading of the list](#dynamic-reloading-of-the-list)
|
||||
* [Updating the list of processes by pressing CTRL-R](#updating-the-list-of-processes-by-pressing-ctrl-r)
|
||||
* [Toggling between data sources](#toggling-between-data-sources)
|
||||
* [Toggling with a single key binding](#toggling-with-a-single-key-binding)
|
||||
* [Updating the list of processes by pressing CTRL-R](#updating-the-list-of-processes-by-pressing-ctrl-r)
|
||||
* [Toggling between data sources](#toggling-between-data-sources)
|
||||
* [Ripgrep integration](#ripgrep-integration)
|
||||
* [Using fzf as the secondary filter](#using-fzf-as-the-secondary-filter)
|
||||
* [Using fzf as interactive Ripgrep launcher](#using-fzf-as-interactive-ripgrep-launcher)
|
||||
* [Switching to fzf-only search mode](#switching-to-fzf-only-search-mode)
|
||||
* [Switching between Ripgrep mode and fzf mode](#switching-between-ripgrep-mode-and-fzf-mode)
|
||||
* [Switching between Ripgrep mode and fzf mode using a single key binding](#switching-between-ripgrep-mode-and-fzf-mode-using-a-single-key-binding)
|
||||
* [Controlling Ripgrep search and fzf search simultaneously](#controlling-ripgrep-search-and-fzf-search-simultaneously)
|
||||
* [Using fzf as the secondary filter](#using-fzf-as-the-secondary-filter)
|
||||
* [Using fzf as interative Ripgrep launcher](#using-fzf-as-interative-ripgrep-launcher)
|
||||
* [Switching to fzf-only search mode](#switching-to-fzf-only-search-mode)
|
||||
* [Switching between Ripgrep mode and fzf mode](#switching-between-ripgrep-mode-and-fzf-mode)
|
||||
* [Log tailing](#log-tailing)
|
||||
* [Key bindings for git objects](#key-bindings-for-git-objects)
|
||||
* [Files listed in `git status`](#files-listed-in-git-status)
|
||||
* [Branches](#branches)
|
||||
* [Commit hashes](#commit-hashes)
|
||||
* [Files listed in `git status`](#files-listed-in-git-status)
|
||||
* [Branches](#branches)
|
||||
* [Commit hashes](#commit-hashes)
|
||||
* [Color themes](#color-themes)
|
||||
* [fzf Theme Playground](#fzf-theme-playground)
|
||||
* [Generating fzf color theme from Vim color schemes](#generating-fzf-color-theme-from-vim-color-schemes)
|
||||
* [Generating fzf color theme from Vim color schemes](#generating-fzf-color-theme-from-vim-color-schemes)
|
||||
|
||||
<!-- vim-markdown-toc -->
|
||||
|
||||
@@ -63,7 +57,7 @@ learn its wide variety of features.
|
||||
This document will guide you through some examples that will familiarize you
|
||||
with the advanced features of fzf.
|
||||
|
||||
Display modes
|
||||
Screen Layout
|
||||
-------------
|
||||
|
||||
### `--height`
|
||||
@@ -93,7 +87,7 @@ fzf --height=40% --layout=reverse --info=inline --border --margin=1 --padding=1
|
||||
|
||||
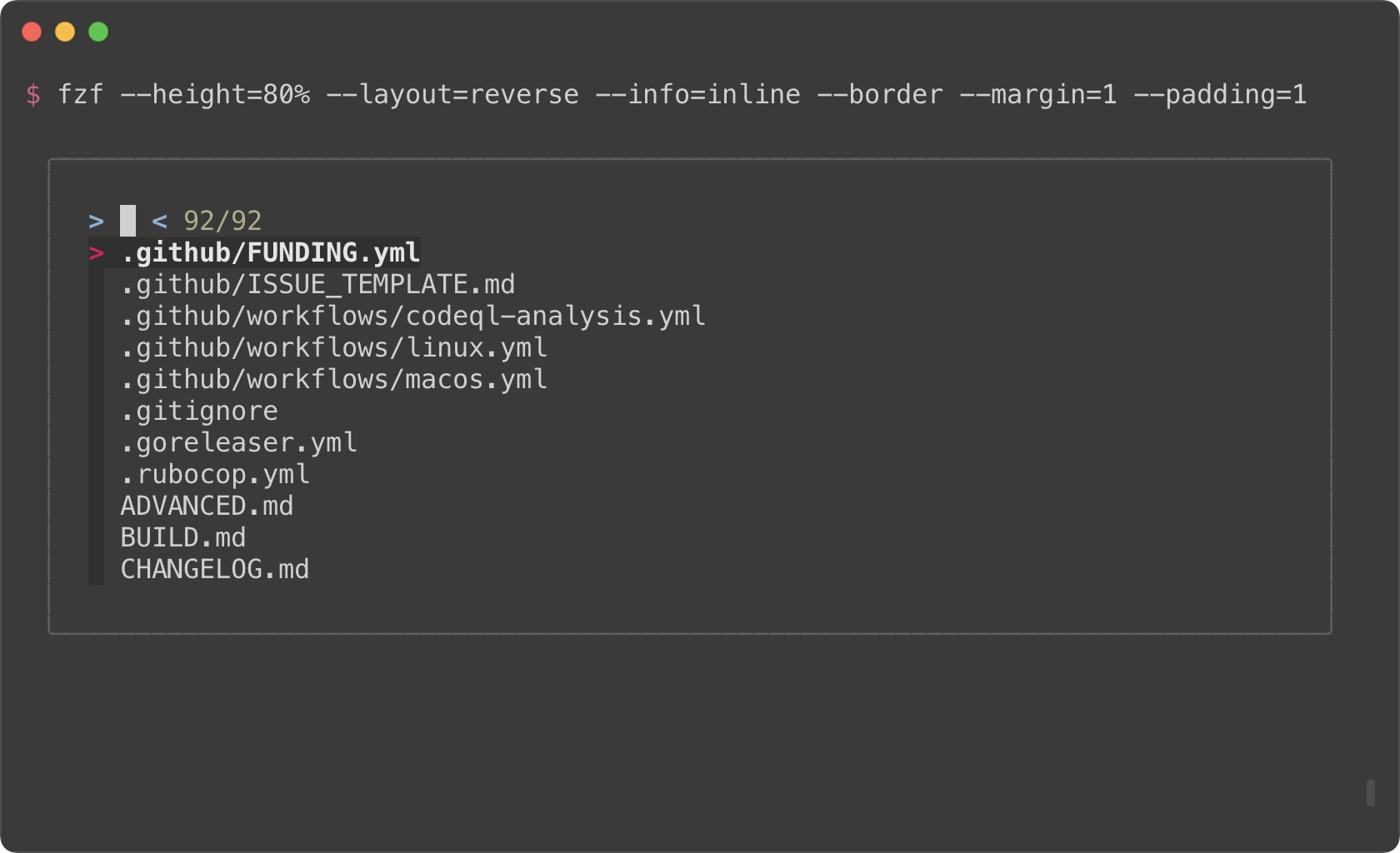
|
||||
|
||||
*(See man page to see the full list of options)*
|
||||
*(See `Layout` section of the man page to see the full list of options)*
|
||||
|
||||
But you definitely don't want to repeat `--height=40% --layout=reverse
|
||||
--info=inline --border --margin=1 --padding=1` every time you use fzf. You
|
||||
@@ -104,55 +98,56 @@ Define `$FZF_DEFAULT_OPTS` like so:
|
||||
export FZF_DEFAULT_OPTS="--height=40% --layout=reverse --info=inline --border --margin=1 --padding=1"
|
||||
```
|
||||
|
||||
### `--tmux`
|
||||
### `fzf-tmux`
|
||||
|
||||
(Requires tmux 3.3 or later)
|
||||
|
||||
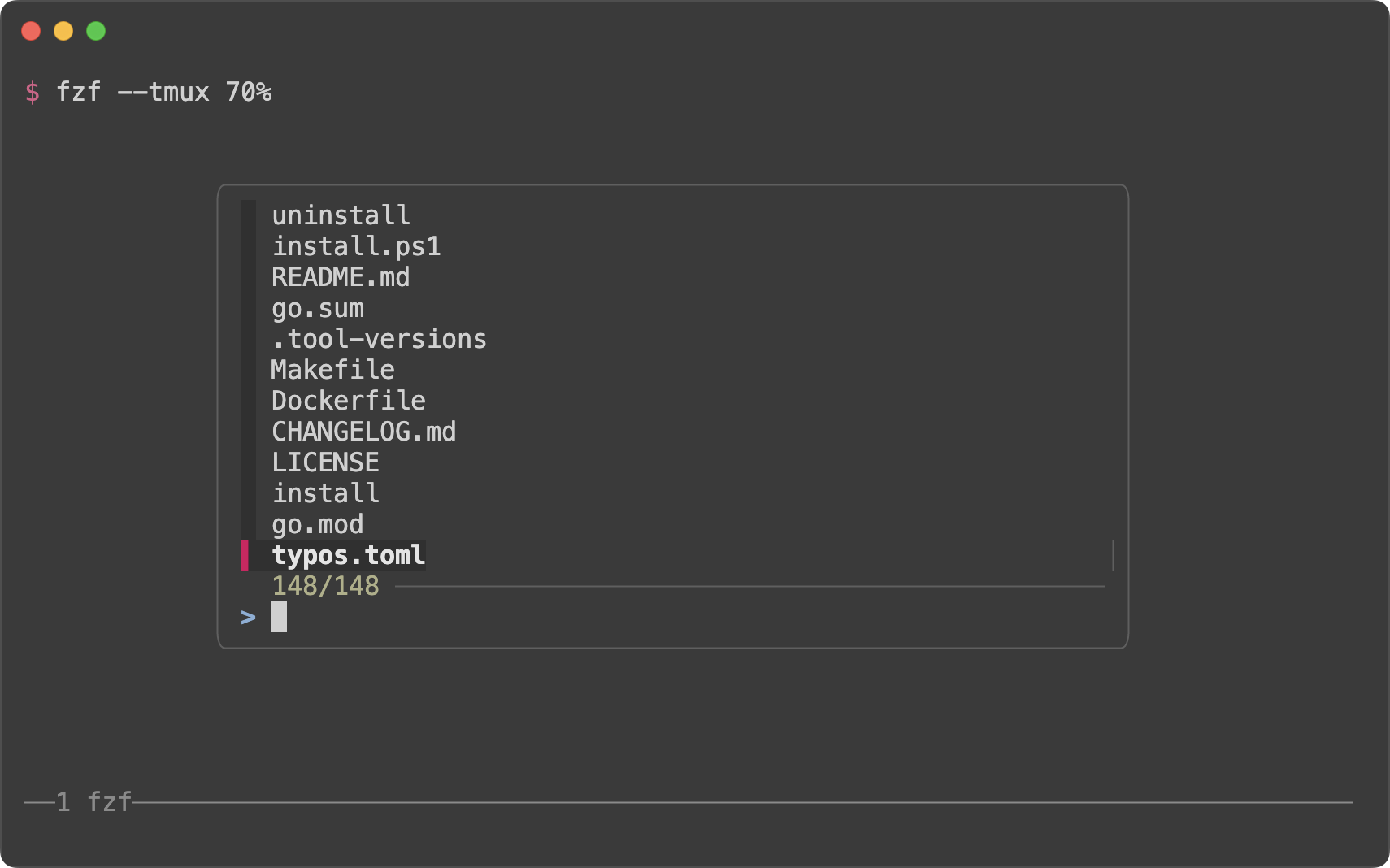
If you're using tmux, you can open fzf in a tmux popup using `--tmux` option.
|
||||
Before fzf had `--height` option, we would open fzf in a tmux split pane not
|
||||
to take up the whole screen. This is done using `fzf-tmux` script.
|
||||
|
||||
```sh
|
||||
# Open fzf in a tmux popup at the center of the screen with 70% width and height
|
||||
fzf --tmux 70%
|
||||
# Open fzf on a tmux split pane below the current pane.
|
||||
# Takes the same set of options.
|
||||
fzf-tmux --layout=reverse
|
||||
```
|
||||
|
||||
|
||||
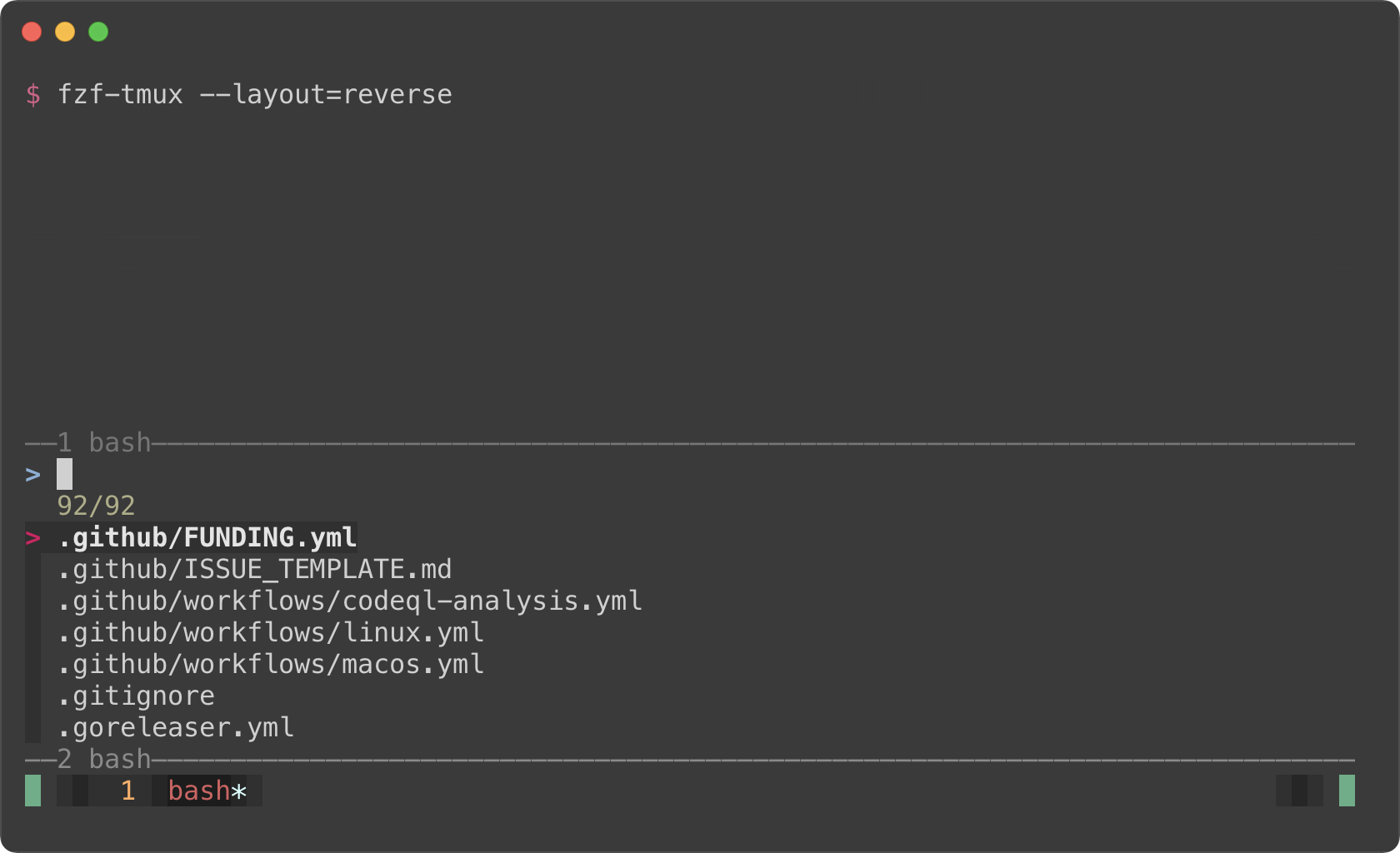
|
||||
|
||||
`--tmux` option is silently ignored if you're not on tmux. So if you're trying
|
||||
to avoid opening fzf in fullscreen, try specifying both `--height` and `--tmux`.
|
||||
The limitation of `fzf-tmux` is that it only works when you're on tmux unlike
|
||||
`--height` option. But the advantage of it is that it's more flexible.
|
||||
(See `man fzf-tmux` for available options.)
|
||||
|
||||
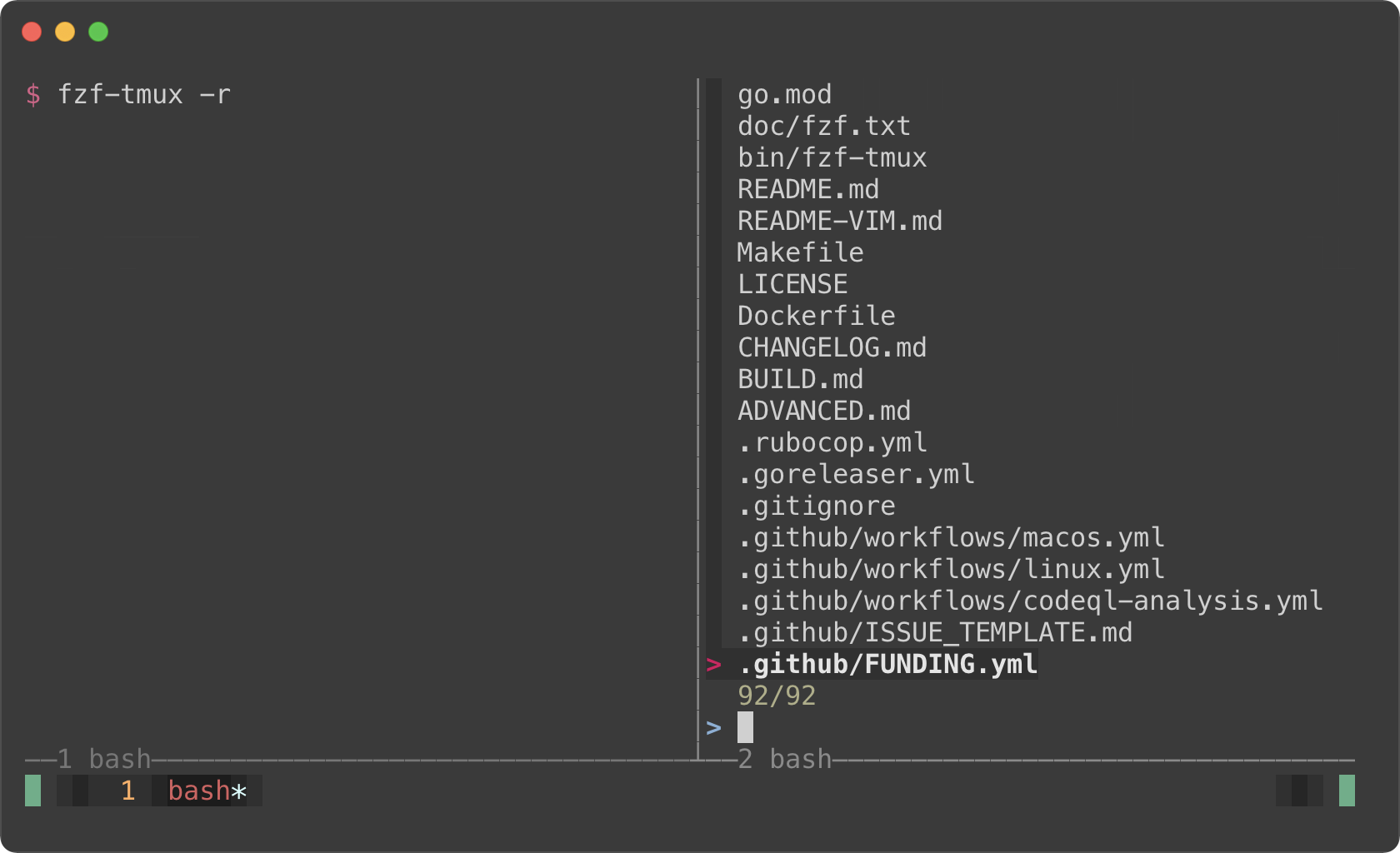
```sh
|
||||
# --tmux is specified later so it takes precedence over --height when on tmux.
|
||||
# If you're not on tmux, --tmux is ignored and --height is used instead.
|
||||
fzf --height 70% --tmux 70%
|
||||
# On the right (50%)
|
||||
fzf-tmux -r
|
||||
|
||||
# On the left (30%)
|
||||
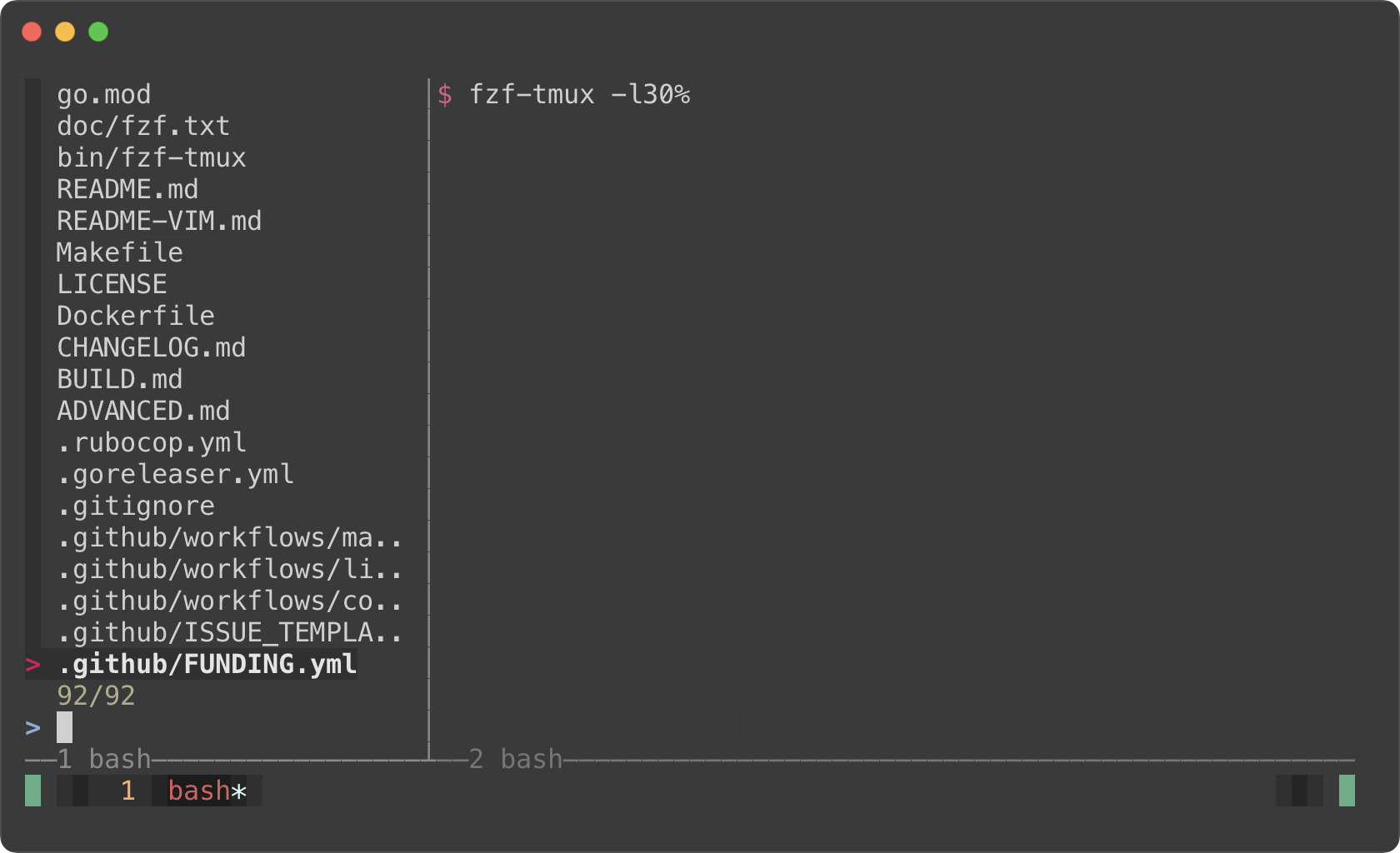
fzf-tmux -l30%
|
||||
|
||||
# Above the cursor
|
||||
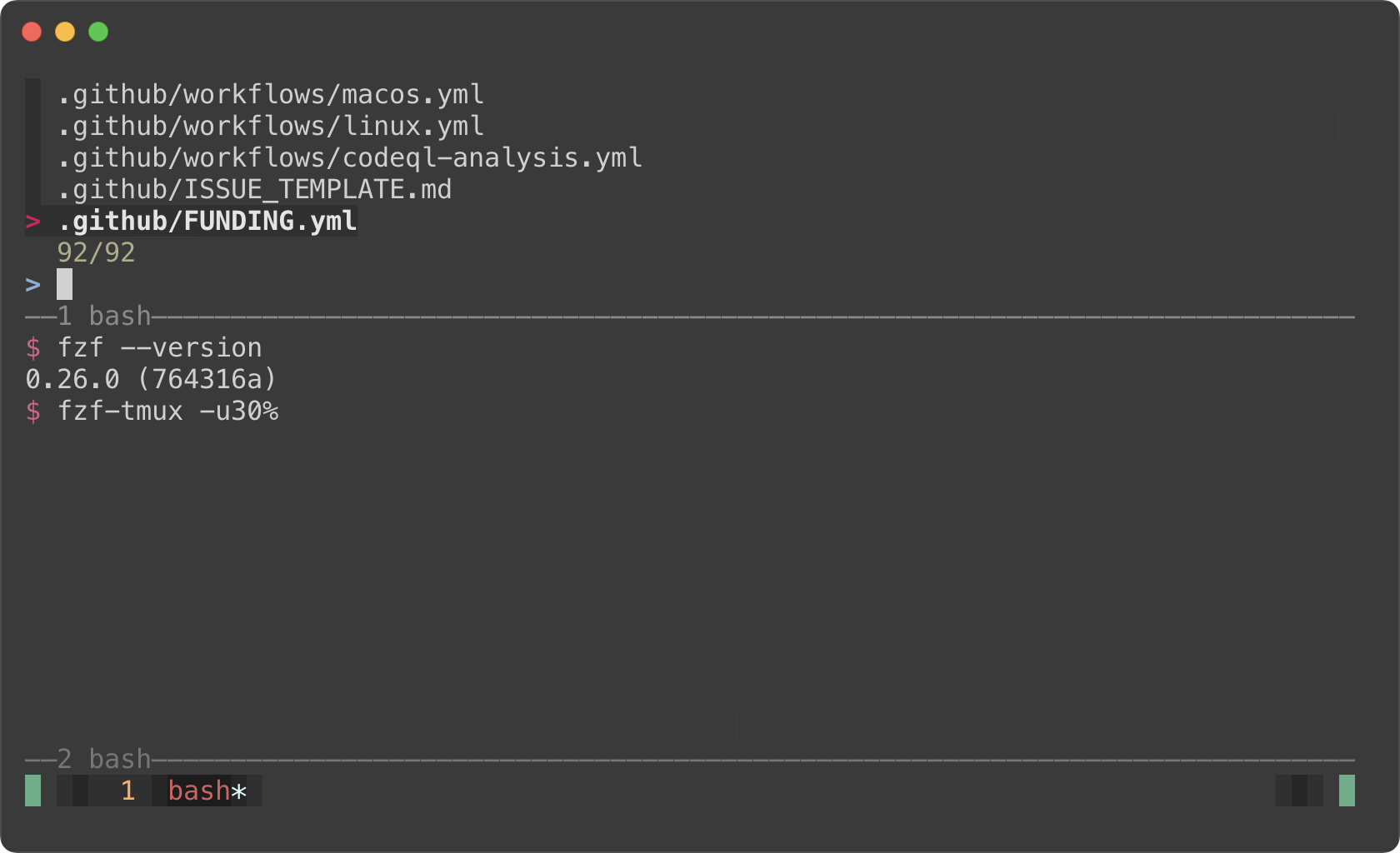
fzf-tmux -u30%
|
||||
```
|
||||
|
||||
You can also specify the position, width, and height of the popup window in
|
||||
the following format:
|
||||
|
||||
|
||||
* `[center|top|bottom|left|right][,SIZE[%]][,SIZE[%][,border-native]]`
|
||||
|
||||
|
||||
|
||||
|
||||
#### Popup window support
|
||||
|
||||
But here's the really cool part; tmux 3.2 added support for popup windows. So
|
||||
you can open fzf in a popup window, which is quite useful if you frequently
|
||||
use split panes.
|
||||
|
||||
```sh
|
||||
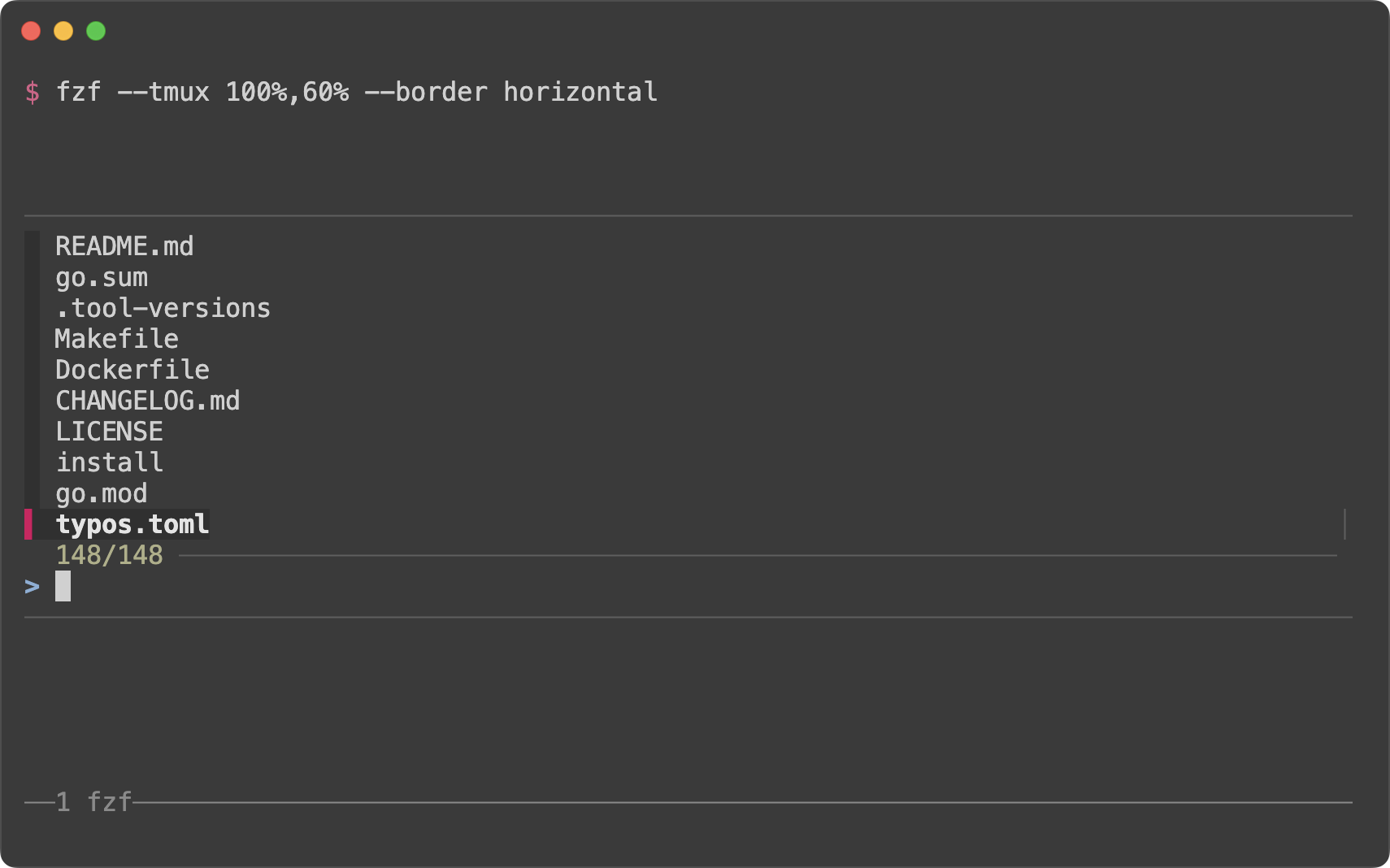
# 100% width and 60% height
|
||||
fzf --tmux 100%,60% --border horizontal
|
||||
# Open tmux in a tmux popup window (default size: 50% of the screen)
|
||||
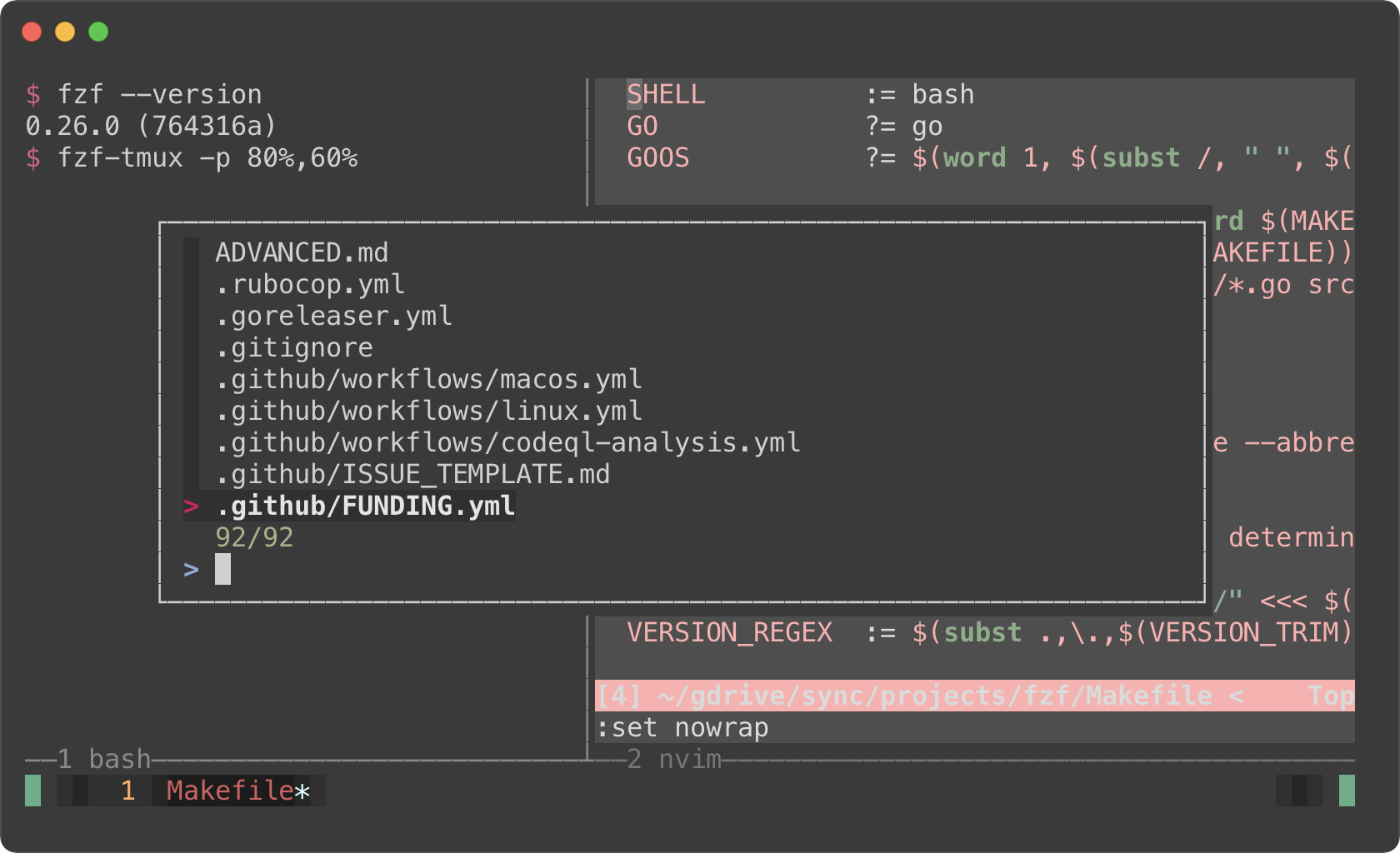
fzf-tmux -p
|
||||
|
||||
# 80% width, 60% height
|
||||
fzf-tmux -p 80%,60%
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
```sh
|
||||
# On the right (50% width)
|
||||
fzf --tmux right
|
||||
```
|
||||
|
||||
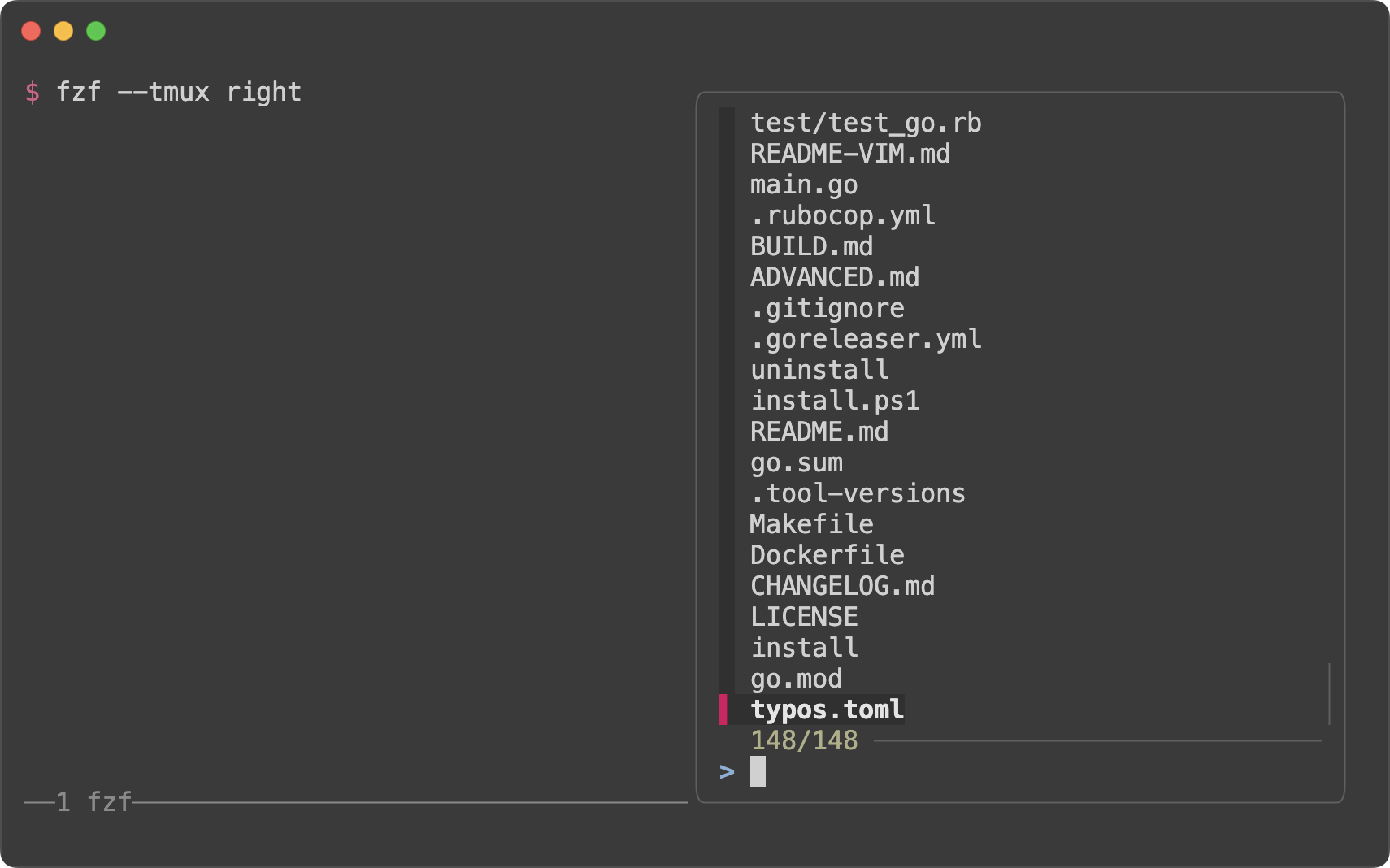
|
||||
|
||||
```sh
|
||||
# On the left (40% width and 70% height)
|
||||
fzf --tmux left,40%,70%
|
||||
```
|
||||
|
||||
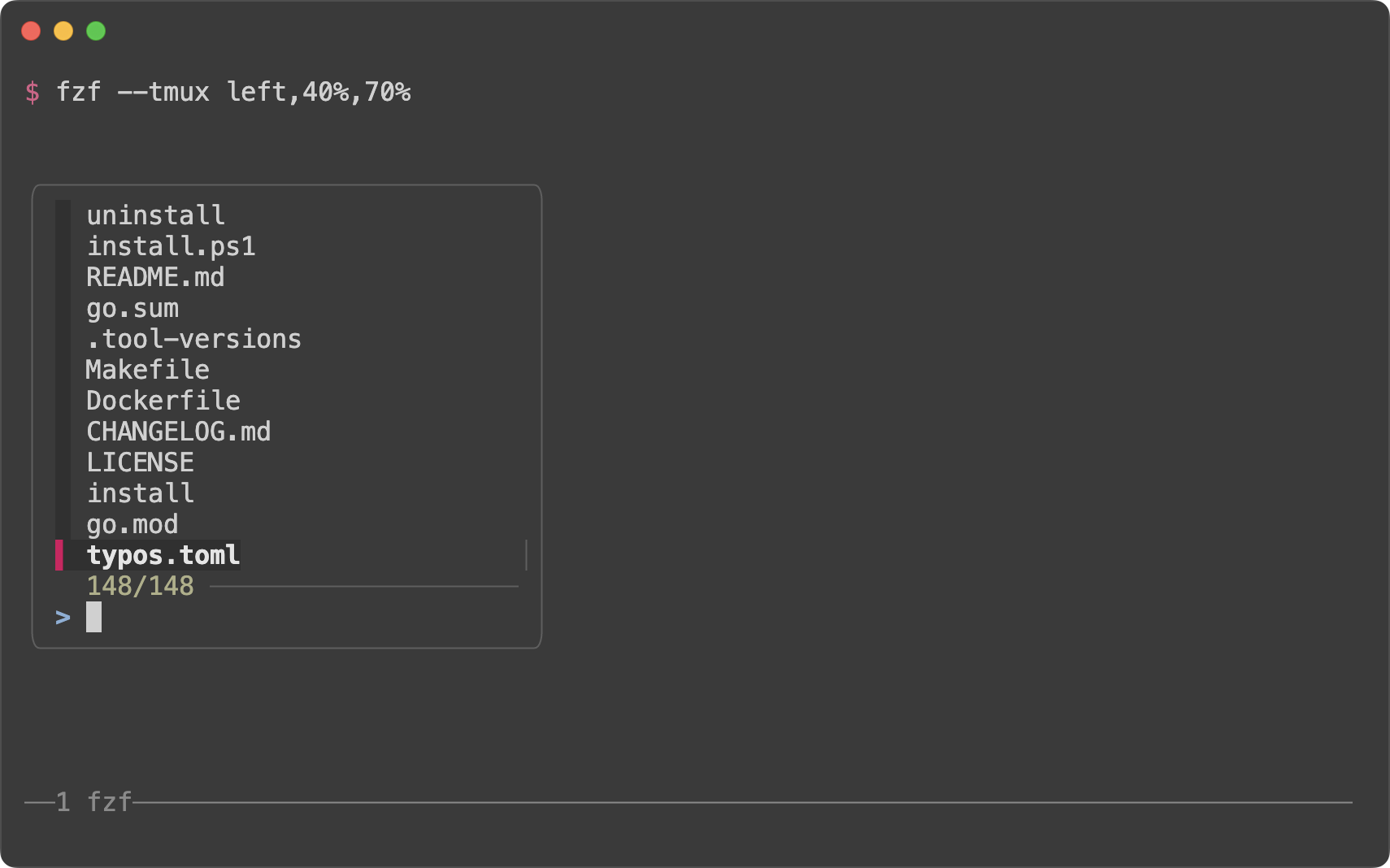
|
||||
|
||||
> [!TIP]
|
||||
> You might also want to check out my tmux plugins which support this popup
|
||||
> window layout.
|
||||
>
|
||||
@@ -210,30 +205,6 @@ find * | fzf --prompt 'All> ' \
|
||||
|
||||
|
||||
|
||||
### Toggling with a single key binding
|
||||
|
||||
The above example uses two different key bindings to toggle between two modes,
|
||||
but can we just use a single key binding?
|
||||
|
||||
To make a key binding behave differently each time it is pressed, we need:
|
||||
|
||||
1. a way to store the current state. i.e. "which mode are we in?"
|
||||
2. and a way to dynamically perform different actions depending on the state.
|
||||
|
||||
The following example shows how to 1. store the current mode in the prompt
|
||||
string, 2. and use this information (`$FZF_PROMPT`) to determine which
|
||||
actions to perform using the `transform` action.
|
||||
|
||||
```sh
|
||||
fd --type file |
|
||||
fzf --prompt 'Files> ' \
|
||||
--header 'CTRL-T: Switch between Files/Directories' \
|
||||
--bind 'ctrl-t:transform:[[ ! $FZF_PROMPT =~ Files ]] &&
|
||||
echo "change-prompt(Files> )+reload(fd --type file)" ||
|
||||
echo "change-prompt(Directories> )+reload(fd --type directory)"' \
|
||||
--preview '[[ $FZF_PROMPT =~ Files ]] && bat --color=always {} || tree -C {}'
|
||||
```
|
||||
|
||||
Ripgrep integration
|
||||
-------------------
|
||||
|
||||
@@ -265,13 +236,15 @@ file called `rfv`.
|
||||
# 1. Search for text in files using Ripgrep
|
||||
# 2. Interactively narrow down the list using fzf
|
||||
# 3. Open the file in Vim
|
||||
rg --color=always --line-number --no-heading --smart-case "${*:-}" |
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
IFS=: read -ra selected < <(
|
||||
rg --color=always --line-number --no-heading --smart-case "${*:-}" |
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
And run it with an initial query string.
|
||||
@@ -309,16 +282,16 @@ I know it's a lot to digest, let's try to break down the code.
|
||||
available color options.
|
||||
- The value of `--preview-window` option consists of 5 components delimited
|
||||
by `,`
|
||||
1. `up` -- Position of the preview window
|
||||
1. `60%` -- Size of the preview window
|
||||
1. `border-bottom` -- Preview window border only on the bottom side
|
||||
1. `+{2}+3/3` -- Scroll offset of the preview contents
|
||||
1. `~3` -- Fixed header
|
||||
1. `up` — Position of the preview window
|
||||
1. `60%` — Size of the preview window
|
||||
1. `border-bottom` — Preview window border only on the bottom side
|
||||
1. `+{2}+3/3` — Scroll offset of the preview contents
|
||||
1. `~3` — Fixed header
|
||||
- Let's break down the latter two. We want to display the bat output in the
|
||||
preview window with a certain scroll offset so that the matching line is
|
||||
positioned near the center of the preview window.
|
||||
- `+{2}` -- The base offset is extracted from the second token
|
||||
- `+3` -- We add 3 lines to the base offset to compensate for the header
|
||||
- `+{2}` — The base offset is extracted from the second token
|
||||
- `+3` — We add 3 lines to the base offset to compensate for the header
|
||||
part of `bat` output
|
||||
- ```
|
||||
───────┬──────────────────────────────────────────────────────────
|
||||
@@ -334,14 +307,10 @@ I know it's a lot to digest, let's try to break down the code.
|
||||
position in the window
|
||||
- `~3` makes the top three lines fixed header so that they are always
|
||||
visible regardless of the scroll offset
|
||||
- Instead of using shell script to process the final output of fzf, we use
|
||||
`become(...)` action which was added in [fzf 0.38.0][0.38.0] to turn fzf
|
||||
into a new process that opens the file with `vim` (`vim {1}`) and move the
|
||||
cursor to the line (`+{2}`).
|
||||
- Once we selected a line, we open the file with `vim` (`vim
|
||||
"${selected[0]}"`) and move the cursor to the line (`+${selected[1]}`).
|
||||
|
||||
[0.38.0]: https://github.com/junegunn/fzf/blob/master/CHANGELOG.md#0380
|
||||
|
||||
### Using fzf as interactive Ripgrep launcher
|
||||
### Using fzf as interative Ripgrep launcher
|
||||
|
||||
We have learned that we can bind `reload` action to a key (e.g.
|
||||
`--bind=ctrl-r:execute(ps -ef)`). In the next example, we are going to **bind
|
||||
@@ -362,20 +331,25 @@ projects, and it will free up memory as you narrow down the results.
|
||||
# 3. Open the file in Vim
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--bind "start:reload:$RG_PREFIX {q} || true" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
IFS=: read -ra selected < <(
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX $(printf %q "$INITIAL_QUERY")" \
|
||||
fzf --ansi \
|
||||
--disabled --query "$INITIAL_QUERY" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
|
||||
|
||||
- Instead of starting fzf in the usual `rg ... | fzf` form, we make it start
|
||||
the initial Ripgrep process immediately via `start:reload` binding for the
|
||||
consistency of the code.
|
||||
- Instead of starting fzf in `rg ... | fzf` form, we start fzf without an
|
||||
explicit input, but with a custom `FZF_DEFAULT_COMMAND` variable. This way
|
||||
fzf can kill the initial Ripgrep process it starts with the initial query.
|
||||
Otherwise, the initial Ripgrep process will keep consuming system resources
|
||||
even after `reload` is triggered.
|
||||
- Filtering is no longer a responsibility of fzf; hence `--disabled`
|
||||
- `{q}` in the reload command evaluates to the query string on fzf prompt.
|
||||
- `sleep 0.1` in the reload command is for "debouncing". This small delay will
|
||||
@@ -384,6 +358,8 @@ fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
|
||||
### Switching to fzf-only search mode
|
||||
|
||||
*(Requires fzf 0.27.1 or above)*
|
||||
|
||||
In the previous example, we lost fuzzy matching capability as we completely
|
||||
delegated search functionality to Ripgrep. But we can dynamically switch to
|
||||
fzf-only search mode by *"unbinding"* `reload` action from `change` event.
|
||||
@@ -399,16 +375,19 @@ fzf-only search mode by *"unbinding"* `reload` action from `change` event.
|
||||
# 3. Open the file in Vim
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--bind "start:reload:$RG_PREFIX {q}" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind "alt-enter:unbind(change,alt-enter)+change-prompt(2. fzf> )+enable-search+clear-query" \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--prompt '1. ripgrep> ' \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
IFS=: read -ra selected < <(
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX $(printf %q "$INITIAL_QUERY")" \
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--disabled --query "$INITIAL_QUERY" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind "alt-enter:unbind(change,alt-enter)+change-prompt(2. fzf> )+enable-search+clear-query" \
|
||||
--prompt '1. ripgrep> ' \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
* Phase 1. Filtering with Ripgrep
|
||||
@@ -429,8 +408,10 @@ fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
|
||||
### Switching between Ripgrep mode and fzf mode
|
||||
|
||||
[fzf 0.30.0][0.30.0] added `rebind` action so we can "rebind" the bindings
|
||||
that were previously "unbound" via `unbind`.
|
||||
*(Requires fzf 0.30.0 or above)*
|
||||
|
||||
fzf 0.30.0 added `rebind` action so we can "rebind" the bindings that were
|
||||
previously "unbound" via `unbind`.
|
||||
|
||||
This is an improved version of the previous example that allows us to switch
|
||||
between Ripgrep launcher mode and fzf-only filtering mode via CTRL-R and
|
||||
@@ -440,103 +421,23 @@ CTRL-F.
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# Switch between Ripgrep launcher mode (CTRL-R) and fzf filtering mode (CTRL-F)
|
||||
rm -f /tmp/rg-fzf-{r,f}
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--bind "start:reload($RG_PREFIX {q})+unbind(ctrl-r)" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind "ctrl-f:unbind(change,ctrl-f)+change-prompt(2. fzf> )+enable-search+rebind(ctrl-r)+transform-query(echo {q} > /tmp/rg-fzf-r; cat /tmp/rg-fzf-f)" \
|
||||
--bind "ctrl-r:unbind(ctrl-r)+change-prompt(1. ripgrep> )+disable-search+reload($RG_PREFIX {q} || true)+rebind(change,ctrl-f)+transform-query(echo {q} > /tmp/rg-fzf-f; cat /tmp/rg-fzf-r)" \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--prompt '1. ripgrep> ' \
|
||||
--delimiter : \
|
||||
--header '╱ CTRL-R (ripgrep mode) ╱ CTRL-F (fzf mode) ╱' \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
```
|
||||
|
||||
- To restore the query string when switching between modes, we store the
|
||||
current query in `/tmp/rg-fzf-{r,f}` files and restore the query using
|
||||
`transform-query` action which was added in [fzf 0.36.0][0.36.0].
|
||||
- Also note that we unbind `ctrl-r` binding on `start` event which is
|
||||
triggered once when fzf starts.
|
||||
|
||||
[0.30.0]: https://github.com/junegunn/fzf/blob/master/CHANGELOG.md#0300
|
||||
[0.36.0]: https://github.com/junegunn/fzf/blob/master/CHANGELOG.md#0360
|
||||
|
||||
### Switching between Ripgrep mode and fzf mode using a single key binding
|
||||
|
||||
In contrast to the previous version, we use just one hotkey to toggle between
|
||||
ripgrep and fzf mode. This is achieved by using the `$FZF_PROMPT` as a state
|
||||
within the `transform` action, a feature introduced in [fzf 0.45.0][0.45.0]. A
|
||||
more detailed explanation of this feature can be found in a previous section -
|
||||
[Toggling with a single keybinding](#toggling-with-a-single-key-binding).
|
||||
|
||||
[0.45.0]: https://github.com/junegunn/fzf/blob/master/CHANGELOG.md#0450
|
||||
|
||||
When using the `transform` action, the placeholder (`\{q}`) should be escaped to
|
||||
prevent immediate evaluation.
|
||||
|
||||
```sh
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# Switch between Ripgrep mode and fzf filtering mode (CTRL-T)
|
||||
rm -f /tmp/rg-fzf-{r,f}
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--bind "start:reload:$RG_PREFIX {q}" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind 'ctrl-t:transform:[[ ! $FZF_PROMPT =~ ripgrep ]] &&
|
||||
echo "rebind(change)+change-prompt(1. ripgrep> )+disable-search+transform-query:echo \{q} > /tmp/rg-fzf-f; cat /tmp/rg-fzf-r" ||
|
||||
echo "unbind(change)+change-prompt(2. fzf> )+enable-search+transform-query:echo \{q} > /tmp/rg-fzf-r; cat /tmp/rg-fzf-f"' \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--prompt '1. ripgrep> ' \
|
||||
--delimiter : \
|
||||
--header 'CTRL-T: Switch between ripgrep/fzf' \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
```
|
||||
|
||||
### Controlling Ripgrep search and fzf search simultaneously
|
||||
|
||||
`search` and `transform-search` action allow you to trigger an fzf search with
|
||||
an arbitrary query string. This frees fzf from strictly following the prompt
|
||||
input, enabling custom search syntax.
|
||||
|
||||
In the example below, `transform` action is used to conditionally trigger
|
||||
`reload` for ripgrep, followed by `search` for fzf. The first word of the
|
||||
query initiates the Ripgrep process to generate the initial results, while the
|
||||
remainder of the query is passed to fzf for secondary filtering.
|
||||
|
||||
```sh
|
||||
#!/usr/bin/env bash
|
||||
|
||||
export TEMP=$(mktemp -u)
|
||||
trap 'rm -f "$TEMP"' EXIT
|
||||
|
||||
INITIAL_QUERY="${*:-}"
|
||||
TRANSFORMER='
|
||||
rg_pat={q:1} # The first word is passed to ripgrep
|
||||
fzf_pat={q:2..} # The rest are passed to fzf
|
||||
|
||||
if ! [[ -r "$TEMP" ]] || [[ $rg_pat != $(cat "$TEMP") ]]; then
|
||||
echo "$rg_pat" > "$TEMP"
|
||||
printf "reload:sleep 0.1; rg --column --line-number --no-heading --color=always --smart-case %q || true" "$rg_pat"
|
||||
fi
|
||||
echo "+search:$fzf_pat"
|
||||
'
|
||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--with-shell 'bash -c' \
|
||||
--bind "start,change:transform:$TRANSFORMER" \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-line,+{2}+3/3,~3' \
|
||||
--bind 'enter:become(vim {1} +{2})'
|
||||
IFS=: read -ra selected < <(
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX $(printf %q "$INITIAL_QUERY")" \
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--disabled --query "$INITIAL_QUERY" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind "ctrl-f:unbind(change,ctrl-f)+change-prompt(2. fzf> )+enable-search+clear-query+rebind(ctrl-r)" \
|
||||
--bind "ctrl-r:unbind(ctrl-r)+change-prompt(1. ripgrep> )+disable-search+reload($RG_PREFIX {q} || true)+rebind(change,ctrl-f)" \
|
||||
--prompt '1. Ripgrep> ' \
|
||||
--delimiter : \
|
||||
--header '╱ CTRL-R (Ripgrep mode) ╱ CTRL-F (fzf mode) ╱' \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
Log tailing
|
||||
@@ -564,16 +465,16 @@ Kubernetes pods.
|
||||
|
||||
```bash
|
||||
pods() {
|
||||
command='kubectl get pods --all-namespaces' fzf \
|
||||
--info=inline --layout=reverse --header-lines=1 \
|
||||
--prompt "$(kubectl config current-context | sed 's/-context$//')> " \
|
||||
--header $'╱ Enter (kubectl exec) ╱ CTRL-O (open log in editor) ╱ CTRL-R (reload) ╱\n\n' \
|
||||
--bind 'start,ctrl-r:reload:$command' \
|
||||
--bind 'ctrl-/:change-preview-window(80%,border-bottom|hidden|)' \
|
||||
--bind 'enter:execute:kubectl exec -it --namespace {1} {2} -- bash' \
|
||||
--bind 'ctrl-o:execute:${EDITOR:-vim} <(kubectl logs --all-containers --namespace {1} {2})' \
|
||||
--preview-window up:follow \
|
||||
--preview 'kubectl logs --follow --all-containers --tail=10000 --namespace {1} {2}' "$@"
|
||||
FZF_DEFAULT_COMMAND="kubectl get pods --all-namespaces" \
|
||||
fzf --info=inline --layout=reverse --header-lines=1 \
|
||||
--prompt "$(kubectl config current-context | sed 's/-context$//')> " \
|
||||
--header $'╱ Enter (kubectl exec) ╱ CTRL-O (open log in editor) ╱ CTRL-R (reload) ╱\n\n' \
|
||||
--bind 'ctrl-/:change-preview-window(80%,border-bottom|hidden|)' \
|
||||
--bind 'enter:execute:kubectl exec -it --namespace {1} {2} -- bash > /dev/tty' \
|
||||
--bind 'ctrl-o:execute:${EDITOR:-vim} <(kubectl logs --all-containers --namespace {1} {2}) > /dev/tty' \
|
||||
--bind 'ctrl-r:reload:$FZF_DEFAULT_COMMAND' \
|
||||
--preview-window up:follow \
|
||||
--preview 'kubectl logs --follow --all-containers --tail=10000 --namespace {1} {2}' "$@"
|
||||
}
|
||||
```
|
||||
|
||||
@@ -586,7 +487,7 @@ pods() {
|
||||
- Press enter key on a pod to `kubectl exec` into it
|
||||
- Press CTRL-O to open the log in your editor
|
||||
- Press CTRL-R to reload the pod list
|
||||
- Press CTRL-/ repeatedly to rotate through a different sets of preview
|
||||
- Press CTRL-/ repeatedly to to rotate through a different sets of preview
|
||||
window options
|
||||
1. `80%,border-bottom`
|
||||
1. `hidden`
|
||||
@@ -595,17 +496,9 @@ pods() {
|
||||
Key bindings for git objects
|
||||
----------------------------
|
||||
|
||||
Oftentimes, you want to put the identifiers of various Git object to the
|
||||
command-line. For example, it is common to write commands like these:
|
||||
|
||||
```sh
|
||||
git checkout [SOME_COMMIT_HASH or BRANCH or TAG]
|
||||
git diff [SOME_COMMIT_HASH or BRANCH or TAG] [SOME_COMMIT_HASH or BRANCH or TAG]
|
||||
```
|
||||
|
||||
[fzf-git.sh](https://github.com/junegunn/fzf-git.sh) project defines a set of
|
||||
fzf-based key bindings for Git objects. I strongly recommend that you check
|
||||
them out because they are seriously useful.
|
||||
I have [blogged](https://junegunn.kr/2016/07/fzf-git) about my fzf+git key
|
||||
bindings a few years ago. I'm going to show them here again, because they are
|
||||
seriously useful.
|
||||
|
||||
### Files listed in `git status`
|
||||
|
||||
@@ -625,6 +518,9 @@ them out because they are seriously useful.
|
||||
|
||||
|
||||
|
||||
|
||||
The full source code can be found [here](https://gist.github.com/junegunn/8b572b8d4b5eddd8b85e5f4d40f17236).
|
||||
|
||||
Color themes
|
||||
------------
|
||||
|
||||
@@ -667,12 +563,6 @@ export FZF_DEFAULT_OPTS='--color=bg+:#293739,bg:#1B1D1E,border:#808080,spinner:#
|
||||
|
||||
|
||||
|
||||
### fzf Theme Playground
|
||||
|
||||
[fzf Theme Playground](https://vitormv.github.io/fzf-themes/) created by
|
||||
[Vitor Mello](https://github.com/vitormv) is a webpage where you can
|
||||
interactively create fzf themes.
|
||||
|
||||
### Generating fzf color theme from Vim color schemes
|
||||
|
||||
The Vim plugin of fzf can generate `--color` option from the current color
|
||||
|
||||
@@ -6,7 +6,7 @@ Build instructions
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Go 1.23 or above
|
||||
- Go 1.17 or above
|
||||
|
||||
### Using Makefile
|
||||
|
||||
@@ -24,50 +24,24 @@ make build
|
||||
make release
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> Makefile uses git commands to determine the version and the revision
|
||||
> information for `fzf --version`. So if you're building fzf from an
|
||||
> :warning: Makefile uses git commands to determine the version and the
|
||||
> revision information for `fzf --version`. So if you're building fzf from an
|
||||
> environment where its git information is not available, you have to manually
|
||||
> set `$FZF_VERSION` and `$FZF_REVISION`.
|
||||
>
|
||||
> e.g. `FZF_VERSION=0.24.0 FZF_REVISION=tarball make`
|
||||
|
||||
> [!TIP]
|
||||
> To build fzf with profiling options enabled, set `TAGS=pprof`
|
||||
>
|
||||
> ```sh
|
||||
> TAGS=pprof make clean install
|
||||
> fzf --profile-cpu /tmp/cpu.pprof --profile-mem /tmp/mem.pprof \
|
||||
> --profile-block /tmp/block.pprof --profile-mutex /tmp/mutex.pprof
|
||||
> ```
|
||||
|
||||
Running tests
|
||||
-------------
|
||||
|
||||
```sh
|
||||
# Run go unit tests
|
||||
make test
|
||||
|
||||
# Run integration tests (requires to be on tmux)
|
||||
make itest
|
||||
|
||||
# Run a single test case
|
||||
ruby test/runner.rb --name test_something
|
||||
```
|
||||
|
||||
Third-party libraries used
|
||||
--------------------------
|
||||
|
||||
- [rivo/uniseg](https://github.com/rivo/uniseg)
|
||||
- Licensed under [MIT](https://raw.githubusercontent.com/rivo/uniseg/master/LICENSE.txt)
|
||||
- [mattn/go-runewidth](https://github.com/mattn/go-runewidth)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [mattn/go-shellwords](https://github.com/mattn/go-shellwords)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [mattn/go-isatty](https://github.com/mattn/go-isatty)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [tcell](https://github.com/gdamore/tcell)
|
||||
- Licensed under [Apache License 2.0](https://github.com/gdamore/tcell/blob/master/LICENSE)
|
||||
- [fastwalk](https://github.com/charlievieth/fastwalk)
|
||||
- Licensed under [MIT](https://raw.githubusercontent.com/charlievieth/fastwalk/master/LICENSE)
|
||||
|
||||
License
|
||||
-------
|
||||
|
||||
-2080
File diff suppressed because it is too large
Load Diff
+4
-5
@@ -1,6 +1,6 @@
|
||||
FROM rubylang/ruby:3.4.1-noble
|
||||
RUN apt-get update -y && apt install -y git make golang zsh fish tmux
|
||||
RUN gem install --no-document -v 5.22.3 minitest
|
||||
FROM archlinux
|
||||
RUN pacman -Sy && pacman --noconfirm -S awk git tmux zsh fish ruby procps go make gcc
|
||||
RUN gem install --no-document -v 5.14.2 minitest
|
||||
RUN echo '. /usr/share/bash-completion/completions/git' >> ~/.bashrc
|
||||
RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
||||
|
||||
@@ -8,5 +8,4 @@ RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
||||
RUN rm -f /etc/bash.bashrc
|
||||
COPY . /fzf
|
||||
RUN cd /fzf && make install && ./install --all
|
||||
ENV LANG=C.UTF-8
|
||||
CMD ["bash", "-ic", "tmux new 'set -o pipefail; ruby /fzf/test/runner.rb | tee out && touch ok' && cat out && [ -e ok ]"]
|
||||
CMD tmux new 'set -o pipefail; ruby /fzf/test/test_go.rb | tee out && touch ok' && cat out && [ -e ok ]
|
||||
|
||||
@@ -1,8 +0,0 @@
|
||||
# frozen_string_literal: true
|
||||
|
||||
source 'https://rubygems.org'
|
||||
|
||||
gem 'minitest', '5.25.4'
|
||||
gem 'rubocop', '1.71.0'
|
||||
gem 'rubocop-minitest', '0.36.0'
|
||||
gem 'rubocop-performance', '1.23.1'
|
||||
@@ -1,47 +0,0 @@
|
||||
GEM
|
||||
remote: https://rubygems.org/
|
||||
specs:
|
||||
ast (2.4.2)
|
||||
json (2.9.1)
|
||||
language_server-protocol (3.17.0.3)
|
||||
minitest (5.25.4)
|
||||
parallel (1.26.3)
|
||||
parser (3.3.7.0)
|
||||
ast (~> 2.4.1)
|
||||
racc
|
||||
racc (1.8.1)
|
||||
rainbow (3.1.1)
|
||||
regexp_parser (2.10.0)
|
||||
rubocop (1.71.0)
|
||||
json (~> 2.3)
|
||||
language_server-protocol (>= 3.17.0)
|
||||
parallel (~> 1.10)
|
||||
parser (>= 3.3.0.2)
|
||||
rainbow (>= 2.2.2, < 4.0)
|
||||
regexp_parser (>= 2.9.3, < 3.0)
|
||||
rubocop-ast (>= 1.36.2, < 2.0)
|
||||
ruby-progressbar (~> 1.7)
|
||||
unicode-display_width (>= 2.4.0, < 4.0)
|
||||
rubocop-ast (1.37.0)
|
||||
parser (>= 3.3.1.0)
|
||||
rubocop-minitest (0.36.0)
|
||||
rubocop (>= 1.61, < 2.0)
|
||||
rubocop-ast (>= 1.31.1, < 2.0)
|
||||
rubocop-performance (1.23.1)
|
||||
rubocop (>= 1.48.1, < 2.0)
|
||||
rubocop-ast (>= 1.31.1, < 2.0)
|
||||
ruby-progressbar (1.13.0)
|
||||
unicode-display_width (2.6.0)
|
||||
|
||||
PLATFORMS
|
||||
arm64-darwin-23
|
||||
ruby
|
||||
|
||||
DEPENDENCIES
|
||||
minitest (= 5.25.4)
|
||||
rubocop (= 1.71.0)
|
||||
rubocop-minitest (= 0.36.0)
|
||||
rubocop-performance (= 1.23.1)
|
||||
|
||||
BUNDLED WITH
|
||||
2.6.2
|
||||
@@ -1,6 +1,6 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2026 Junegunn Choi
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
@@ -1,44 +1,34 @@
|
||||
SHELL := bash
|
||||
GO ?= go
|
||||
DOCKER ?= docker
|
||||
GOOS ?= $(shell $(GO) env GOOS)
|
||||
GOOS ?= $(word 1, $(subst /, " ", $(word 4, $(shell go version))))
|
||||
|
||||
MAKEFILE := $(realpath $(lastword $(MAKEFILE_LIST)))
|
||||
ROOT_DIR := $(shell dirname $(MAKEFILE))
|
||||
SOURCES := $(wildcard *.go src/*.go src/*/*.go shell/*sh man/man1/*.1) $(MAKEFILE)
|
||||
|
||||
BASH_SCRIPTS := $(ROOT_DIR)/bin/fzf-preview.sh \
|
||||
$(ROOT_DIR)/bin/fzf-tmux \
|
||||
$(ROOT_DIR)/install \
|
||||
$(ROOT_DIR)/uninstall \
|
||||
$(ROOT_DIR)/shell/common.sh \
|
||||
$(ROOT_DIR)/shell/update.sh \
|
||||
$(ROOT_DIR)/shell/completion.bash \
|
||||
$(ROOT_DIR)/shell/key-bindings.bash
|
||||
SOURCES := $(wildcard *.go src/*.go src/*/*.go) $(MAKEFILE)
|
||||
|
||||
ifdef FZF_VERSION
|
||||
VERSION := $(FZF_VERSION)
|
||||
else
|
||||
VERSION := $(shell git describe --abbrev=0 2> /dev/null | sed "s/^v//")
|
||||
VERSION := $(shell git describe --abbrev=0 2> /dev/null)
|
||||
endif
|
||||
ifeq ($(VERSION),)
|
||||
$(error Not on git repository; cannot determine $$FZF_VERSION)
|
||||
endif
|
||||
VERSION_TRIM := $(shell echo $(VERSION) | sed "s/^v//; s/-.*//")
|
||||
VERSION_TRIM := $(shell sed "s/-.*//" <<< $(VERSION))
|
||||
VERSION_REGEX := $(subst .,\.,$(VERSION_TRIM))
|
||||
|
||||
ifdef FZF_REVISION
|
||||
REVISION := $(FZF_REVISION)
|
||||
else
|
||||
REVISION := $(shell git log -n 1 --pretty=format:%h --abbrev=8 -- $(SOURCES) 2> /dev/null)
|
||||
REVISION := $(shell git log -n 1 --pretty=format:%h -- $(SOURCES) 2> /dev/null)
|
||||
endif
|
||||
ifeq ($(REVISION),)
|
||||
$(error Not on git repository; cannot determine $$FZF_REVISION)
|
||||
endif
|
||||
BUILD_FLAGS := -a -ldflags "-s -w -X main.version=$(VERSION) -X main.revision=$(REVISION)" -tags "$(TAGS)" -trimpath
|
||||
BUILD_FLAGS := -a -ldflags "-s -w -X main.version=$(VERSION) -X main.revision=$(REVISION)" -tags "$(TAGS)"
|
||||
|
||||
BINARY32 := fzf-$(GOOS)_386
|
||||
BINARY64 := fzf-$(GOOS)_amd64
|
||||
BINARYS390 := fzf-$(GOOS)_s390x
|
||||
BINARYARM5 := fzf-$(GOOS)_arm5
|
||||
BINARYARM6 := fzf-$(GOOS)_arm6
|
||||
BINARYARM7 := fzf-$(GOOS)_arm7
|
||||
@@ -53,10 +43,6 @@ ifeq ($(UNAME_M),x86_64)
|
||||
BINARY := $(BINARY64)
|
||||
else ifeq ($(UNAME_M),amd64)
|
||||
BINARY := $(BINARY64)
|
||||
else ifeq ($(UNAME_M),i86pc)
|
||||
BINARY := $(BINARY64)
|
||||
else ifeq ($(UNAME_M),s390x)
|
||||
BINARY := $(BINARYS390)
|
||||
else ifeq ($(UNAME_M),i686)
|
||||
BINARY := $(BINARY32)
|
||||
else ifeq ($(UNAME_M),i386)
|
||||
@@ -68,9 +54,7 @@ else ifeq ($(UNAME_M),armv6l)
|
||||
else ifeq ($(UNAME_M),armv7l)
|
||||
BINARY := $(BINARYARM7)
|
||||
else ifeq ($(UNAME_M),armv8l)
|
||||
# armv8l is always 32-bit and should implement the armv7 ISA, so
|
||||
# just use the same filename as for armv7.
|
||||
BINARY := $(BINARYARM7)
|
||||
BINARY := $(BINARYARM8)
|
||||
else ifeq ($(UNAME_M),arm64)
|
||||
BINARY := $(BINARYARM8)
|
||||
else ifeq ($(UNAME_M),aarch64)
|
||||
@@ -88,53 +72,22 @@ endif
|
||||
all: target/$(BINARY)
|
||||
|
||||
test: $(SOURCES)
|
||||
[ -z "$$(gofmt -s -d src)" ] || (gofmt -s -d src; exit 1)
|
||||
SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" \
|
||||
github.com/junegunn/fzf/src \
|
||||
github.com/junegunn/fzf/src/algo \
|
||||
github.com/junegunn/fzf/src/tui \
|
||||
github.com/junegunn/fzf/src/util
|
||||
|
||||
itest:
|
||||
ruby test/runner.rb
|
||||
|
||||
bench:
|
||||
cd src && SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" -run=Bench -bench=. -benchmem
|
||||
|
||||
lint: $(SOURCES) test/*.rb test/lib/*.rb ${BASH_SCRIPTS}
|
||||
[ -z "$$(gofmt -s -d src)" ] || (gofmt -s -d src; exit 1)
|
||||
bundle exec rubocop -a --require rubocop-minitest --require rubocop-performance
|
||||
shell/update.sh --check ${BASH_SCRIPTS}
|
||||
|
||||
fmt: $(SOURCES) $(BASH_SCRIPTS)
|
||||
gofmt -s -w src
|
||||
shell/update.sh ${BASH_SCRIPTS}
|
||||
|
||||
install: bin/fzf
|
||||
|
||||
generate:
|
||||
PATH=$(PATH):$(GOPATH)/bin $(GO) generate ./...
|
||||
|
||||
build:
|
||||
goreleaser build --clean --snapshot --skip=post-hooks
|
||||
|
||||
prerelease:
|
||||
# Check if version numbers are properly updated
|
||||
grep -q ^$(VERSION_REGEX)$$ CHANGELOG.md
|
||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf.1
|
||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf-tmux.1
|
||||
grep -qF $(VERSION) install
|
||||
grep -qF $(VERSION) install.ps1
|
||||
@echo "OK: all files consistent at $(VERSION)"
|
||||
|
||||
tag: prerelease
|
||||
git tag -s v$(VERSION) -m v$(VERSION)
|
||||
git push origin v$(VERSION)
|
||||
goreleaser --rm-dist --snapshot
|
||||
|
||||
release:
|
||||
# Make sure that the tests pass and the build works
|
||||
TAGS=tcell make test
|
||||
make test build clean
|
||||
|
||||
ifndef GITHUB_TOKEN
|
||||
$(error GITHUB_TOKEN is not defined)
|
||||
endif
|
||||
@@ -161,7 +114,7 @@ endif
|
||||
git push origin temp --follow-tags --force
|
||||
|
||||
# Make a GitHub release
|
||||
goreleaser --clean --release-notes tmp/release-note
|
||||
goreleaser --rm-dist --release-notes tmp/release-note
|
||||
|
||||
# Push to master
|
||||
git checkout master
|
||||
@@ -179,8 +132,6 @@ target/$(BINARY32): $(SOURCES)
|
||||
target/$(BINARY64): $(SOURCES)
|
||||
GOARCH=amd64 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYS390): $(SOURCES)
|
||||
GOARCH=s390x $(GO) build $(BUILD_FLAGS) -o $@
|
||||
# https://github.com/golang/go/wiki/GoArm
|
||||
target/$(BINARYARM5): $(SOURCES)
|
||||
GOARCH=arm GOARM=5 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
@@ -204,19 +155,18 @@ target/$(BINARYLOONG64): $(SOURCES)
|
||||
GOARCH=loong64 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
bin/fzf: target/$(BINARY) | bin
|
||||
-rm -f bin/fzf
|
||||
cp -f target/$(BINARY) bin/fzf
|
||||
|
||||
docker:
|
||||
$(DOCKER) build -t fzf-ubuntu .
|
||||
$(DOCKER) run -it fzf-ubuntu tmux
|
||||
docker build -t fzf-arch .
|
||||
docker run -it fzf-arch tmux
|
||||
|
||||
docker-test:
|
||||
$(DOCKER) build -t fzf-ubuntu .
|
||||
$(DOCKER) run -it fzf-ubuntu
|
||||
docker build -t fzf-arch .
|
||||
docker run -it fzf-arch
|
||||
|
||||
update:
|
||||
$(GO) get -u
|
||||
$(GO) mod tidy
|
||||
|
||||
.PHONY: all generate build prerelease tag release test itest bench lint install clean docker docker-test update fmt
|
||||
.PHONY: all build release test bench install clean docker docker-test update
|
||||
|
||||
+18
-28
@@ -12,10 +12,7 @@ differ depending on the package manager.
|
||||
" If installed using Homebrew
|
||||
set rtp+=/usr/local/opt/fzf
|
||||
|
||||
" If installed using Homebrew on Apple Silicon
|
||||
set rtp+=/opt/homebrew/opt/fzf
|
||||
|
||||
" If you have cloned fzf on ~/.fzf directory
|
||||
" If installed using git
|
||||
set rtp+=~/.fzf
|
||||
```
|
||||
|
||||
@@ -26,10 +23,7 @@ written as:
|
||||
" If installed using Homebrew
|
||||
Plug '/usr/local/opt/fzf'
|
||||
|
||||
" If installed using Homebrew on Apple Silicon
|
||||
Plug '/opt/homebrew/opt/fzf'
|
||||
|
||||
" If you have cloned fzf on ~/.fzf directory
|
||||
" If installed using git
|
||||
Plug '~/.fzf'
|
||||
```
|
||||
|
||||
@@ -121,7 +115,7 @@ let g:fzf_action = {
|
||||
|
||||
" An action can be a reference to a function that processes selected lines
|
||||
function! s:build_quickfix_list(lines)
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val, "lnum": 1 }'))
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val }'))
|
||||
copen
|
||||
cc
|
||||
endfunction
|
||||
@@ -155,7 +149,6 @@ let g:fzf_layout = { 'window': '10new' }
|
||||
let g:fzf_colors =
|
||||
\ { 'fg': ['fg', 'Normal'],
|
||||
\ 'bg': ['bg', 'Normal'],
|
||||
\ 'query': ['fg', 'Normal'],
|
||||
\ 'hl': ['fg', 'Comment'],
|
||||
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
||||
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
||||
@@ -239,20 +232,19 @@ call fzf#run({'sink': 'e'})
|
||||
```
|
||||
|
||||
We haven't specified the `source`, so this is equivalent to starting fzf on
|
||||
command line without standard input pipe; fzf will traverse the file system
|
||||
under the current directory to get the list of files. (If
|
||||
`$FZF_DEFAULT_COMMAND` is set, fzf will use the output of the command
|
||||
instead.) When you select one, it will open it with the sink, `:e` command. If
|
||||
you want to open it in a new tab, you can pass `:tabedit` command instead as
|
||||
the sink.
|
||||
command line without standard input pipe; fzf will use find command (or
|
||||
`$FZF_DEFAULT_COMMAND` if defined) to list the files under the current
|
||||
directory. When you select one, it will open it with the sink, `:e` command.
|
||||
If you want to open it in a new tab, you can pass `:tabedit` command instead
|
||||
as the sink.
|
||||
|
||||
```vim
|
||||
call fzf#run({'sink': 'tabedit'})
|
||||
```
|
||||
|
||||
You can use any shell command as the source to generate the list. The
|
||||
following example will list the files managed by git. It's equivalent to
|
||||
running `git ls-files | fzf` on shell.
|
||||
Instead of using the default find command, you can use any shell command as
|
||||
the source. The following example will list the files managed by git. It's
|
||||
equivalent to running `git ls-files | fzf` on shell.
|
||||
|
||||
```vim
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e'})
|
||||
@@ -290,13 +282,12 @@ The following table summarizes the available options.
|
||||
| `source` | string | External command to generate input to fzf (e.g. `find .`) |
|
||||
| `source` | list | Vim list as input to fzf |
|
||||
| `sink` | string | Vim command to handle the selected item (e.g. `e`, `tabe`) |
|
||||
| `sink` | funcref | Function to be called with each selected item |
|
||||
| `sink` | funcref | Reference to function to process each selected item |
|
||||
| `sinklist` (or `sink*`) | funcref | Similar to `sink`, but takes the list of output lines at once |
|
||||
| `exit` | funcref | Function to be called with the exit status of fzf (e.g. 0, 1, 2, 130) |
|
||||
| `options` | string/list | Options to fzf |
|
||||
| `dir` | string | Working directory |
|
||||
| `up`/`down`/`left`/`right` | number/string | (Layout) Window position and size (e.g. `20`, `50%`) |
|
||||
| `tmux` | string | (Layout) `--tmux` options (e.g. `90%,70%`) |
|
||||
| `tmux` | string | (Layout) fzf-tmux options (e.g. `-p90%,60%`) |
|
||||
| `window` (Vim 8 / Neovim) | string | (Layout) Command to open fzf window (e.g. `vertical aboveleft 30new`) |
|
||||
| `window` (Vim 8 / Neovim) | dict | (Layout) Popup window settings (e.g. `{'width': 0.9, 'height': 0.6}`) |
|
||||
|
||||
@@ -318,7 +309,7 @@ following options are allowed:
|
||||
- `yoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `xoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `relative` [boolean default v:false]
|
||||
- `border` [string default `rounded` (`sharp` on Windows)]: Border style
|
||||
- `border` [string default `rounded`]: Border style
|
||||
- `rounded` / `sharp` / `horizontal` / `vertical` / `top` / `bottom` / `left` / `right` / `no[ne]`
|
||||
|
||||
`fzf#wrap`
|
||||
@@ -459,13 +450,12 @@ let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
```
|
||||
|
||||
Alternatively, you can make fzf open in a tmux popup window (requires tmux 3.2
|
||||
or above) by putting `--tmux` option value in `tmux` key.
|
||||
or above) by putting fzf-tmux options in `tmux` key.
|
||||
|
||||
```vim
|
||||
" See `--tmux` option in `man fzf` for available options
|
||||
" [center|top|bottom|left|right][,SIZE[%]][,SIZE[%]]
|
||||
" See `man fzf-tmux` for available options
|
||||
if exists('$TMUX')
|
||||
let g:fzf_layout = { 'tmux': '90%,70%' }
|
||||
let g:fzf_layout = { 'tmux': '-p90%,60%' }
|
||||
else
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
endif
|
||||
@@ -493,4 +483,4 @@ autocmd FileType fzf set laststatus=0 noshowmode noruler
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2026 Junegunn Choi
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
-54
@@ -1,54 +0,0 @@
|
||||
Release process
|
||||
===============
|
||||
|
||||
Building, signing, notarizing, and publishing is handled by
|
||||
[`.github/workflows/release.yml`](.github/workflows/release.yml),
|
||||
triggered by a tag push.
|
||||
|
||||
## Steps
|
||||
|
||||
1. Update version in the following files and commit on `master`:
|
||||
- `CHANGELOG.md`
|
||||
- `main.go`
|
||||
- `install`
|
||||
- `install.ps1`
|
||||
- `man/man1/fzf.1`
|
||||
- `man/man1/fzf-tmux.1`
|
||||
|
||||
2. Verify file consistency, sign the tag, and push the tag.
|
||||
|
||||
```sh
|
||||
make tag VERSION=0.73.1
|
||||
```
|
||||
|
||||
`make tag` runs `prerelease` first (checks that the version
|
||||
appears in CHANGELOG.md, both man pages, install, and install.ps1)
|
||||
and only signs + pushes the tag if the checks pass.
|
||||
|
||||
Only the tag is pushed; `master` on origin still points to the
|
||||
old version, so `/master/install` keeps resolving against existing
|
||||
binaries during the publish window.
|
||||
|
||||
3. The workflow fires on the tag push and pauses on the `release`
|
||||
environment gate. Approve it in the Actions tab to release.
|
||||
|
||||
4. After the GitHub release is published, fast-forward `master`:
|
||||
|
||||
```sh
|
||||
git push origin master
|
||||
```
|
||||
|
||||
## Testing the workflow
|
||||
|
||||
To exercise the workflow without firing a real release:
|
||||
|
||||
1. Actions tab -> **Release** -> **Run workflow**.
|
||||
2. Pick a branch and enter the version currently on that branch
|
||||
(the version-consistency check requires the input to match the
|
||||
files in the checked-out tree).
|
||||
3. Approve the `release` environment gate when prompted.
|
||||
4. Goreleaser runs with `--snapshot --skip=publish`. Signing and
|
||||
notarization run; only the GitHub release upload is skipped.
|
||||
|
||||
Use this to validate the workflow YAML, version-extraction logic,
|
||||
the macOS runner setup, and the signing/notarization credentials.
|
||||
-33
@@ -1,33 +0,0 @@
|
||||
# Security Reporting
|
||||
|
||||
If you wish to report a security vulnerability privately, we appreciate your diligence. Please follow the guidelines below to submit your report.
|
||||
|
||||
## Reporting
|
||||
|
||||
To report a security vulnerability, please provide the following information:
|
||||
|
||||
1. **PROJECT**
|
||||
- https://github.com/junegunn/fzf
|
||||
|
||||
2. **PUBLIC**
|
||||
- Indicate whether this vulnerability has already been publicly discussed or disclosed.
|
||||
- If so, provide relevant links.
|
||||
|
||||
3. **DESCRIPTION**
|
||||
- Provide a detailed description of the security vulnerability.
|
||||
- Include as much information as possible to help us understand and address the issue.
|
||||
|
||||
Send this information, along with any additional relevant details, to <junegunn.c AT gmail DOT com>.
|
||||
|
||||
## Confidentiality
|
||||
|
||||
We kindly ask you to keep the report confidential until a public announcement is made.
|
||||
|
||||
## Notes
|
||||
|
||||
- Vulnerabilities will be handled on a best-effort basis.
|
||||
- You may request an advance copy of the patched release, but we cannot guarantee early access before the public release.
|
||||
- You will be notified via email simultaneously with the public announcement.
|
||||
- We will respond within a few weeks to confirm whether your report has been accepted or rejected.
|
||||
|
||||
Thank you for helping to improve the security of our project!
|
||||
@@ -1,86 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# The purpose of this script is to demonstrate how to preview a file or an
|
||||
# image in the preview window of fzf.
|
||||
#
|
||||
# Dependencies:
|
||||
# - https://github.com/sharkdp/bat
|
||||
# - https://github.com/hpjansson/chafa
|
||||
# - https://iterm2.com/utilities/imgcat
|
||||
|
||||
if [[ $# -ne 1 ]]; then
|
||||
>&2 echo "usage: $0 FILENAME[:LINENO][:IGNORED]"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
file=${1/#\~\//$HOME/}
|
||||
|
||||
center=0
|
||||
if [[ ! -r $file ]]; then
|
||||
if [[ $file =~ ^(.+):([0-9]+)\ *$ ]] && [[ -r ${BASH_REMATCH[1]} ]]; then
|
||||
file=${BASH_REMATCH[1]}
|
||||
center=${BASH_REMATCH[2]}
|
||||
elif [[ $file =~ ^(.+):([0-9]+):[0-9]+\ *$ ]] && [[ -r ${BASH_REMATCH[1]} ]]; then
|
||||
file=${BASH_REMATCH[1]}
|
||||
center=${BASH_REMATCH[2]}
|
||||
fi
|
||||
fi
|
||||
|
||||
type=$(file --brief --dereference --mime -- "$file")
|
||||
|
||||
if [[ ! $type =~ image/ ]]; then
|
||||
if [[ $type =~ =binary ]]; then
|
||||
file "$1"
|
||||
exit
|
||||
fi
|
||||
|
||||
# Sometimes bat is installed as batcat.
|
||||
if command -v batcat > /dev/null; then
|
||||
batname="batcat"
|
||||
elif command -v bat > /dev/null; then
|
||||
batname="bat"
|
||||
else
|
||||
cat "$1"
|
||||
exit
|
||||
fi
|
||||
|
||||
${batname} --style="${BAT_STYLE:-numbers}" --color=always --pager=never --highlight-line="${center:-0}" -- "$file"
|
||||
exit
|
||||
fi
|
||||
|
||||
dim=${FZF_PREVIEW_COLUMNS}x${FZF_PREVIEW_LINES}
|
||||
if [[ $dim == x ]]; then
|
||||
dim=$(stty size < /dev/tty | awk '{print $2 "x" $1}')
|
||||
elif ! [[ $KITTY_WINDOW_ID ]] && ((FZF_PREVIEW_TOP + FZF_PREVIEW_LINES == $(stty size < /dev/tty | awk '{print $1}'))); then
|
||||
# Avoid scrolling issue when the Sixel image touches the bottom of the screen
|
||||
# * https://github.com/junegunn/fzf/issues/2544
|
||||
dim=${FZF_PREVIEW_COLUMNS}x$((FZF_PREVIEW_LINES - 1))
|
||||
fi
|
||||
|
||||
# 1. Use icat (from Kitty) if kitten is installed
|
||||
if [[ $KITTY_WINDOW_ID ]] || [[ $GHOSTTY_RESOURCES_DIR ]] && command -v kitten > /dev/null; then
|
||||
# 1. 'memory' is the fastest option but if you want the image to be scrollable,
|
||||
# you have to use 'stream'.
|
||||
#
|
||||
# 2. The last line of the output is the ANSI reset code without newline.
|
||||
# This confuses fzf and makes it render scroll offset indicator.
|
||||
# So we remove the last line and append the reset code to its previous line.
|
||||
kitten icat --clear --transfer-mode=memory --unicode-placeholder --stdin=no --place="$dim@0x0" "$file" | sed '$d' | sed $'$s/$/\e[m/'
|
||||
|
||||
# 2. Use chafa with Sixel output
|
||||
elif command -v chafa > /dev/null; then
|
||||
chafa -s "$dim" "$file"
|
||||
# Add a new line character so that fzf can display multiple images in the preview window
|
||||
echo
|
||||
|
||||
# 3. If chafa is not found but imgcat is available, use it on iTerm2
|
||||
elif command -v imgcat > /dev/null; then
|
||||
# NOTE: We should use https://iterm2.com/utilities/it2check to check if the
|
||||
# user is running iTerm2. But for the sake of simplicity, we just assume
|
||||
# that's the case here.
|
||||
imgcat -W "${dim%%x*}" -H "${dim##*x}" "$file"
|
||||
|
||||
# 4. Cannot find any suitable method to preview the image
|
||||
else
|
||||
file "$file"
|
||||
fi
|
||||
+61
-84
@@ -7,20 +7,18 @@ fail() {
|
||||
exit 2
|
||||
}
|
||||
|
||||
fzf="$(command which fzf)" || fzf="$(dirname "$0")/fzf"
|
||||
[[ -x $fzf ]] || fail 'fzf executable not found'
|
||||
fzf="$(command -v fzf 2> /dev/null)" || fzf="$(dirname "$0")/fzf"
|
||||
[[ -x "$fzf" ]] || fail 'fzf executable not found'
|
||||
|
||||
tmux_args=()
|
||||
args=()
|
||||
opt=""
|
||||
skip=""
|
||||
swap=""
|
||||
close=""
|
||||
term=""
|
||||
[[ -n $LINES ]] && lines=$LINES || lines=$(tput lines) || lines=$(tmux display-message -p "#{pane_height}")
|
||||
[[ -n $COLUMNS ]] && columns=$COLUMNS || columns=$(tput cols) || columns=$(tmux display-message -p "#{pane_width}")
|
||||
|
||||
tmux_version=$(tmux -V | sed 's/[^0-9.]//g')
|
||||
tmux_32=$(awk '{print ($1 >= 3.2)}' <<< "$tmux_version" 2> /dev/null || bc -l <<< "$tmux_version >= 3.2")
|
||||
[[ -n "$LINES" ]] && lines=$LINES || lines=$(tput lines) || lines=$(tmux display-message -p "#{pane_height}")
|
||||
[[ -n "$COLUMNS" ]] && columns=$COLUMNS || columns=$(tput cols) || columns=$(tmux display-message -p "#{pane_width}")
|
||||
|
||||
help() {
|
||||
>&2 echo 'usage: fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
@@ -47,7 +45,7 @@ help() {
|
||||
while [[ $# -gt 0 ]]; do
|
||||
arg="$1"
|
||||
shift
|
||||
[[ -z $skip ]] && case "$arg" in
|
||||
[[ -z "$skip" ]] && case "$arg" in
|
||||
-)
|
||||
term=1
|
||||
;;
|
||||
@@ -58,19 +56,19 @@ while [[ $# -gt 0 ]]; do
|
||||
echo "fzf-tmux (with fzf $("$fzf" --version))"
|
||||
exit
|
||||
;;
|
||||
-p* | -w* | -h* | -x* | -y* | -d* | -u* | -r* | -l*)
|
||||
if [[ $arg =~ ^-[pwhxy] ]]; then
|
||||
[[ $opt =~ "-E" ]] || opt="-E"
|
||||
elif [[ $arg =~ ^.[lr] ]]; then
|
||||
-p*|-w*|-h*|-x*|-y*|-d*|-u*|-r*|-l*)
|
||||
if [[ "$arg" =~ ^-[pwhxy] ]]; then
|
||||
[[ "$opt" =~ "-K -E" ]] || opt="-K -E"
|
||||
elif [[ "$arg" =~ ^.[lr] ]]; then
|
||||
opt="-h"
|
||||
if [[ $arg =~ ^.l ]]; then
|
||||
if [[ "$arg" =~ ^.l ]]; then
|
||||
opt="$opt -d"
|
||||
swap="; swap-pane -D ; select-pane -L"
|
||||
close="; tmux swap-pane -D"
|
||||
fi
|
||||
else
|
||||
opt=""
|
||||
if [[ $arg =~ ^.u ]]; then
|
||||
if [[ "$arg" =~ ^.u ]]; then
|
||||
opt="$opt -d"
|
||||
swap="; swap-pane -D ; select-pane -U"
|
||||
close="; tmux swap-pane -D"
|
||||
@@ -79,7 +77,7 @@ while [[ $# -gt 0 ]]; do
|
||||
if [[ ${#arg} -gt 2 ]]; then
|
||||
size="${arg:2}"
|
||||
else
|
||||
if [[ $1 =~ ^[0-9%,]+$ ]] || [[ $1 =~ ^[A-Z]$ ]]; then
|
||||
if [[ "$1" =~ ^[0-9%,]+$ ]] || [[ "$1" =~ ^[A-Z]$ ]]; then
|
||||
size="$1"
|
||||
shift
|
||||
else
|
||||
@@ -87,37 +85,29 @@ while [[ $# -gt 0 ]]; do
|
||||
fi
|
||||
fi
|
||||
|
||||
if [[ $arg =~ ^-p ]]; then
|
||||
if [[ -n $size ]]; then
|
||||
if [[ "$arg" =~ ^-p ]]; then
|
||||
if [[ -n "$size" ]]; then
|
||||
w=${size%%,*}
|
||||
h=${size##*,}
|
||||
opt="$opt -w$w -h$h"
|
||||
fi
|
||||
elif [[ $arg =~ ^-[whxy] ]]; then
|
||||
elif [[ "$arg" =~ ^-[whxy] ]]; then
|
||||
opt="$opt ${arg:0:2}$size"
|
||||
elif [[ $size =~ %$ ]]; then
|
||||
size=${size:0:${#size}-1}
|
||||
if [[ $tmux_32 == 1 ]]; then
|
||||
if [[ -n $swap ]]; then
|
||||
opt="$opt -l $((100 - size))%"
|
||||
else
|
||||
opt="$opt -l $size%"
|
||||
fi
|
||||
elif [[ "$size" =~ %$ ]]; then
|
||||
size=${size:0:((${#size}-1))}
|
||||
if [[ -n "$swap" ]]; then
|
||||
opt="$opt -p $(( 100 - size ))"
|
||||
else
|
||||
if [[ -n $swap ]]; then
|
||||
opt="$opt -p $((100 - size))"
|
||||
else
|
||||
opt="$opt -p $size"
|
||||
fi
|
||||
opt="$opt -p $size"
|
||||
fi
|
||||
else
|
||||
if [[ -n $swap ]]; then
|
||||
if [[ $arg =~ ^.l ]]; then
|
||||
if [[ -n "$swap" ]]; then
|
||||
if [[ "$arg" =~ ^.l ]]; then
|
||||
max=$columns
|
||||
else
|
||||
max=$lines
|
||||
fi
|
||||
size=$((max - size))
|
||||
size=$(( max - size ))
|
||||
[[ $size -lt 0 ]] && size=0
|
||||
opt="$opt -l $size"
|
||||
else
|
||||
@@ -129,27 +119,27 @@ while [[ $# -gt 0 ]]; do
|
||||
# "--" can be used to separate fzf-tmux options from fzf options to
|
||||
# avoid conflicts
|
||||
skip=1
|
||||
tmux_args=("${args[@]}")
|
||||
args=()
|
||||
continue
|
||||
;;
|
||||
*)
|
||||
args+=("$arg")
|
||||
;;
|
||||
esac
|
||||
[[ -n $skip ]] && args+=("$arg")
|
||||
[[ -n "$skip" ]] && args+=("$arg")
|
||||
done
|
||||
|
||||
if [[ -z $TMUX ]]; then
|
||||
if [[ -z "$TMUX" ]]; then
|
||||
"$fzf" "${args[@]}"
|
||||
exit $?
|
||||
fi
|
||||
|
||||
# * --height option is not allowed
|
||||
# * CTRL-Z is also disabled
|
||||
# * fzf-tmux script is not compatible with --tmux option in fzf 0.53.0 or later
|
||||
args=("${args[@]}" "--no-height" "--bind=ctrl-z:ignore" "--no-tmux")
|
||||
# --height option is not allowed. CTRL-Z is also disabled.
|
||||
args=("${args[@]}" "--no-height" "--bind=ctrl-z:ignore")
|
||||
|
||||
# Handle zoomed tmux pane without popup options by moving it to a temp window
|
||||
if [[ ! $opt =~ "-E" ]] && tmux list-panes -F '#F' | grep -q Z; then
|
||||
if [[ ! "$opt" =~ "-K -E" ]] && tmux list-panes -F '#F' | grep -q Z; then
|
||||
zoomed_without_popup=1
|
||||
original_window=$(tmux display-message -p "#{window_id}")
|
||||
tmp_window=$(tmux new-window -d -P -F "#{window_id}" "bash -c 'while :; do for c in \\| / - '\\;' do sleep 0.2; printf \"\\r\$c fzf-tmux is running\\r\"; done; done'")
|
||||
@@ -159,27 +149,22 @@ fi
|
||||
set -e
|
||||
|
||||
# Clean up named pipes on exit
|
||||
tmpdir=$(mktemp -d "${TMPDIR:-/tmp}/fzf-tmux-XXXXXX")
|
||||
argsf="$tmpdir/args"
|
||||
fifo1="$tmpdir/fifo1"
|
||||
fifo2="$tmpdir/fifo2"
|
||||
fifo3="$tmpdir/fifo3"
|
||||
if tmux_win_opts=$(tmux show-options -p remain-on-exit \; show-options -p synchronize-panes 2> /dev/null); then
|
||||
tmux_win_opts=($(sed '/ off/d; s/synchronize-panes/set-option -p synchronize-panes/; s/remain-on-exit/set-option -p remain-on-exit/; s/$/ \\;/' <<< "$tmux_win_opts"))
|
||||
tmux_off_opts='; set-option -p synchronize-panes off ; set-option -p remain-on-exit off'
|
||||
else
|
||||
tmux_win_opts=($(tmux show-window-options remain-on-exit \; show-window-options synchronize-panes | sed '/ off/d; s/^/set-window-option /; s/$/ \\;/'))
|
||||
tmux_off_opts='; set-window-option synchronize-panes off ; set-window-option remain-on-exit off'
|
||||
fi
|
||||
id=$RANDOM
|
||||
argsf="${TMPDIR:-/tmp}/fzf-args-$id"
|
||||
fifo1="${TMPDIR:-/tmp}/fzf-fifo1-$id"
|
||||
fifo2="${TMPDIR:-/tmp}/fzf-fifo2-$id"
|
||||
fifo3="${TMPDIR:-/tmp}/fzf-fifo3-$id"
|
||||
tmux_win_opts=( $(tmux show-window-options remain-on-exit \; show-window-options synchronize-panes | sed '/ off/d; s/^/set-window-option /; s/$/ \\;/') )
|
||||
cleanup() {
|
||||
\rm -rf "$tmpdir"
|
||||
\rm -f $argsf $fifo1 $fifo2 $fifo3
|
||||
|
||||
# Restore tmux window options
|
||||
if [[ ${#tmux_win_opts[@]} -gt 1 ]]; then
|
||||
if [[ "${#tmux_win_opts[@]}" -gt 0 ]]; then
|
||||
eval "tmux ${tmux_win_opts[*]}"
|
||||
fi
|
||||
|
||||
# Remove temp window if we were zoomed without popup options
|
||||
if [[ -n $zoomed_without_popup ]]; then
|
||||
if [[ -n "$zoomed_without_popup" ]]; then
|
||||
tmux display-message -p "#{window_id}" > /dev/null
|
||||
tmux swap-pane -t $original_window \; \
|
||||
select-window -t $original_window \; \
|
||||
@@ -195,23 +180,10 @@ cleanup() {
|
||||
trap 'cleanup 1' SIGUSR1
|
||||
trap 'cleanup' EXIT
|
||||
|
||||
envs="export TERM=$(printf %q "$TERM") "
|
||||
if [[ $opt =~ "-E" ]]; then
|
||||
if [[ $tmux_version == 3.2 ]]; then
|
||||
FZF_DEFAULT_OPTS="--margin 0,1 $FZF_DEFAULT_OPTS"
|
||||
elif [[ $tmux_32 == 1 ]]; then
|
||||
FZF_DEFAULT_OPTS="--border $FZF_DEFAULT_OPTS"
|
||||
opt="-B $opt"
|
||||
else
|
||||
echo "fzf-tmux: tmux 3.2 or above is required for popup mode" >&2
|
||||
exit 2
|
||||
fi
|
||||
fi
|
||||
envs="$envs FZF_DEFAULT_COMMAND=$(printf %q "$FZF_DEFAULT_COMMAND")"
|
||||
envs="$envs FZF_DEFAULT_OPTS=$(printf %q "$FZF_DEFAULT_OPTS")"
|
||||
envs="$envs FZF_DEFAULT_OPTS_FILE=$(printf %q "$FZF_DEFAULT_OPTS_FILE")"
|
||||
[[ -n $RUNEWIDTH_EASTASIAN ]] && envs="$envs RUNEWIDTH_EASTASIAN=$(printf %q "$RUNEWIDTH_EASTASIAN")"
|
||||
[[ -n $BAT_THEME ]] && envs="$envs BAT_THEME=$(printf %q "$BAT_THEME")"
|
||||
envs="export TERM=$TERM "
|
||||
[[ "$opt" =~ "-K -E" ]] && FZF_DEFAULT_OPTS="--margin 0,1 $FZF_DEFAULT_OPTS"
|
||||
[[ -n "$FZF_DEFAULT_OPTS" ]] && envs="$envs FZF_DEFAULT_OPTS=$(printf %q "$FZF_DEFAULT_OPTS")"
|
||||
[[ -n "$FZF_DEFAULT_COMMAND" ]] && envs="$envs FZF_DEFAULT_COMMAND=$(printf %q "$FZF_DEFAULT_COMMAND")"
|
||||
echo "$envs;" > "$argsf"
|
||||
|
||||
# Build arguments to fzf
|
||||
@@ -223,9 +195,9 @@ close="; trap - EXIT SIGINT SIGTERM $close"
|
||||
|
||||
export TMUX=$(cut -d , -f 1,2 <<< "$TMUX")
|
||||
mkfifo -m o+w $fifo2
|
||||
if [[ $opt =~ "-E" ]]; then
|
||||
if [[ "$opt" =~ "-K -E" ]]; then
|
||||
cat $fifo2 &
|
||||
if [[ -n $term ]] || [[ -t 0 ]]; then
|
||||
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||
cat <<< "\"$fzf\" $opts > $fifo2; out=\$? $close; exit \$out" >> $argsf
|
||||
else
|
||||
mkfifo $fifo1
|
||||
@@ -233,24 +205,29 @@ if [[ $opt =~ "-E" ]]; then
|
||||
cat <&0 > $fifo1 &
|
||||
fi
|
||||
|
||||
tmux popup -d "$PWD" $opt "bash $argsf" > /dev/null 2>&1
|
||||
# tmux dropped the support for `-K`, `-R` to popup command
|
||||
# TODO: We can remove this once tmux 3.2 is released
|
||||
if [[ ! "$(tmux popup --help 2>&1)" =~ '-R shell-command' ]]; then
|
||||
opt="${opt/-K/}"
|
||||
else
|
||||
opt="${opt} -R"
|
||||
fi
|
||||
|
||||
tmux popup -d "$PWD" "${tmux_args[@]}" $opt "bash $argsf" > /dev/null 2>&1
|
||||
exit $?
|
||||
fi
|
||||
|
||||
mkfifo -m o+w $fifo3
|
||||
if [[ -n $term ]] || [[ -t 0 ]]; then
|
||||
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||
cat <<< "\"$fzf\" $opts > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
||||
else
|
||||
mkfifo $fifo1
|
||||
cat <<< "\"$fzf\" $opts < $fifo1 > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
||||
cat <&0 > $fifo1 &
|
||||
fi
|
||||
tmux \
|
||||
split-window -c "$PWD" $opt "bash -c 'exec -a fzf bash $argsf'" $swap \
|
||||
$tmux_off_opts \
|
||||
> /dev/null 2>&1 || {
|
||||
"$fzf" "${args[@]}"
|
||||
exit $?
|
||||
}
|
||||
tmux set-window-option synchronize-panes off \;\
|
||||
set-window-option remain-on-exit off \;\
|
||||
split-window -c "$PWD" $opt "${tmux_args[@]}" "bash -c 'exec -a fzf bash $argsf'" $swap \
|
||||
> /dev/null 2>&1 || { "$fzf" "${args[@]}"; exit $?; }
|
||||
cat $fifo2
|
||||
exit "$(cat $fifo3)"
|
||||
|
||||
+51
-46
@@ -1,4 +1,4 @@
|
||||
fzf.txt fzf Last change: February 15 2024
|
||||
fzf.txt fzf Last change: May 19 2021
|
||||
FZF - TABLE OF CONTENTS *fzf* *fzf-toc*
|
||||
==============================================================================
|
||||
|
||||
@@ -32,10 +32,7 @@ depending on the package manager.
|
||||
" If installed using Homebrew
|
||||
set rtp+=/usr/local/opt/fzf
|
||||
|
||||
" If installed using Homebrew on Apple Silicon
|
||||
set rtp+=/opt/homebrew/opt/fzf
|
||||
|
||||
" If you have cloned fzf on ~/.fzf directory
|
||||
" If installed using git
|
||||
set rtp+=~/.fzf
|
||||
<
|
||||
If you use {vim-plug}{1}, the same can be written as:
|
||||
@@ -43,10 +40,7 @@ If you use {vim-plug}{1}, the same can be written as:
|
||||
" If installed using Homebrew
|
||||
Plug '/usr/local/opt/fzf'
|
||||
|
||||
" If installed using Homebrew on Apple Silicon
|
||||
Plug '/opt/homebrew/opt/fzf'
|
||||
|
||||
" If you have cloned fzf on ~/.fzf directory
|
||||
" If installed using git
|
||||
Plug '~/.fzf'
|
||||
<
|
||||
But if you want the latest Vim plugin file from GitHub rather than the one
|
||||
@@ -74,16 +68,16 @@ SUMMARY *fzf-summary*
|
||||
The Vim plugin of fzf provides two core functions, and `:FZF` command which is
|
||||
the basic file selector command built on top of them.
|
||||
|
||||
1. `fzf#run([spec dict])`
|
||||
1. `fzf#run([spec dict])`
|
||||
- Starts fzf inside Vim with the given spec
|
||||
- `:call fzf#run({'source': 'ls'})`
|
||||
2. `fzf#wrap([spec dict]) -> (dict)`
|
||||
- `:call fzf#run({'source': 'ls'})`
|
||||
2. `fzf#wrap([spec dict]) -> (dict)`
|
||||
- Takes a spec for `fzf#run` and returns an extended version of it with
|
||||
additional options for addressing global preferences (`g:fzf_xxx`)
|
||||
- `:echo fzf#wrap({'source': 'ls'})`
|
||||
- `:echo fzf#wrap({'source': 'ls'})`
|
||||
- We usually wrap a spec with `fzf#wrap` before passing it to `fzf#run`
|
||||
- `:call fzf#run(fzf#wrap({'source': 'ls'}))`
|
||||
3. `:FZF [fzf_options string] [path string]`
|
||||
- `:call fzf#run(fzf#wrap({'source': 'ls'}))`
|
||||
3. `:FZF [fzf_options string] [path string]`
|
||||
- Basic fuzzy file selector
|
||||
- A reference implementation for those who don't want to write VimScript to
|
||||
implement custom commands
|
||||
@@ -112,7 +106,7 @@ the whole if we start off with `:FZF` command.
|
||||
" Bang version starts fzf in fullscreen mode
|
||||
:FZF!
|
||||
<
|
||||
Similarly to {ctrlp.vim}{3}, use Enter key, CTRL-T, CTRL-X or CTRL-V to open
|
||||
Similarly to {ctrlp.vim}{3}, use enter key, CTRL-T, CTRL-X or CTRL-V to open
|
||||
selected files in the current window, in new tabs, in horizontal splits, or in
|
||||
vertical splits respectively.
|
||||
|
||||
@@ -149,7 +143,7 @@ Examples~
|
||||
|
||||
" An action can be a reference to a function that processes selected lines
|
||||
function! s:build_quickfix_list(lines)
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val, "lnum": 1 }'))
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val }'))
|
||||
copen
|
||||
cc
|
||||
endfunction
|
||||
@@ -218,6 +212,7 @@ list:
|
||||
`fg` / `bg` / `hl` | Item (foreground / background / highlight)
|
||||
`fg+` / `bg+` / `hl+` | Current item (foreground / background / highlight)
|
||||
`preview-fg` / `preview-bg` | Preview window text and background
|
||||
`hl` / `hl+` | Highlighted substrings (normal / current)
|
||||
`gutter` | Background of the gutter on the left
|
||||
`pointer` | Pointer to the current line ( `>` )
|
||||
`marker` | Multi-select marker ( `>` )
|
||||
@@ -227,11 +222,12 @@ list:
|
||||
`spinner` | Streaming input indicator
|
||||
`query` | Query string
|
||||
`disabled` | Query string when search is disabled
|
||||
`prompt` | Prompt before query ( `> ` )
|
||||
`prompt` | Prompt before query ( `> ` )
|
||||
`pointer` | Pointer to the current line ( `>` )
|
||||
----------------------------+------------------------------------------------------
|
||||
- `component` specifies the component (`fg` / `bg`) from which to extract the
|
||||
color when considering each of the following highlight groups
|
||||
- `group1 [, group2, ...]` is a list of highlight groups that are searched (in
|
||||
- `group1 [, group2, ...]` is a list of highlight groups that are searched (in
|
||||
order) for a matching color definition
|
||||
|
||||
For example, consider the following specification:
|
||||
@@ -243,7 +239,7 @@ if it exists, - otherwise use the `fg` attribute of the `Comment` highlight
|
||||
group if it exists, - otherwise fall back to the default color settings for
|
||||
the prompt.
|
||||
|
||||
You can examine the color option generated according to the setting by printing
|
||||
You can examine the color option generated according the setting by printing
|
||||
the result of `fzf#wrap()` function like so:
|
||||
>
|
||||
:echo fzf#wrap()
|
||||
@@ -262,18 +258,17 @@ entry.
|
||||
call fzf#run({'sink': 'e'})
|
||||
<
|
||||
We haven't specified the `source`, so this is equivalent to starting fzf on
|
||||
command line without standard input pipe; fzf will traverse the file system
|
||||
under the current directory to get the list of files. (If
|
||||
`$FZF_DEFAULT_COMMAND` is set, fzf will use the output of the command
|
||||
instead.) When you select one, it will open it with the sink, `:e` command. If
|
||||
you want to open it in a new tab, you can pass `:tabedit` command instead as
|
||||
the sink.
|
||||
command line without standard input pipe; fzf will use find command (or
|
||||
`$FZF_DEFAULT_COMMAND` if defined) to list the files under the current
|
||||
directory. When you select one, it will open it with the sink, `:e` command.
|
||||
If you want to open it in a new tab, you can pass `:tabedit` command instead
|
||||
as the sink.
|
||||
>
|
||||
call fzf#run({'sink': 'tabedit'})
|
||||
<
|
||||
You can use any shell command as the source to generate the list. The
|
||||
following example will list the files managed by git. It's equivalent to
|
||||
running `git ls-files | fzf` on shell.
|
||||
Instead of using the default find command, you can use any shell command as
|
||||
the source. The following example will list the files managed by git. It's
|
||||
equivalent to running `git ls-files | fzf` on shell.
|
||||
>
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e'})
|
||||
<
|
||||
@@ -301,18 +296,17 @@ The following table summarizes the available options.
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
Option name | Type | Description ~
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
`source` | string | External command to generate input to fzf (e.g. `find .` )
|
||||
`source` | string | External command to generate input to fzf (e.g. `find .` )
|
||||
`source` | list | Vim list as input to fzf
|
||||
`sink` | string | Vim command to handle the selected item (e.g. `e` , `tabe` )
|
||||
`sink` | funcref | Function to be called with each selected item
|
||||
`sink` | funcref | Reference to function to process each selected item
|
||||
`sinklist` (or `sink*` ) | funcref | Similar to `sink` , but takes the list of output lines at once
|
||||
`exit` | funcref | Function to be called with the exit status of fzf (e.g. 0, 1, 2, 130)
|
||||
`options` | string/list | Options to fzf
|
||||
`dir` | string | Working directory
|
||||
`up` / `down` / `left` / `right` | number/string | (Layout) Window position and size (e.g. `20` , `50%` )
|
||||
`tmux` | string | (Layout) `--tmux` options (e.g. `90%,70%` )
|
||||
`window` (Vim 8 / Neovim) | string | (Layout) Command to open fzf window (e.g. `vertical aboveleft 30new` )
|
||||
`window` (Vim 8 / Neovim) | dict | (Layout) Popup window settings (e.g. `{'width': 0.9, 'height': 0.6}` )
|
||||
`tmux` | string | (Layout) fzf-tmux options (e.g. `-p90%,60%` )
|
||||
`window` (Vim 8 / Neovim) | string | (Layout) Command to open fzf window (e.g. `vertical aboveleft 30new` )
|
||||
`window` (Vim 8 / Neovim) | dict | (Layout) Popup window settings (e.g. `{'width': 0.9, 'height': 0.6}` )
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
|
||||
`options` entry can be either a string or a list. For simple cases, string
|
||||
@@ -331,7 +325,7 @@ following options are allowed:
|
||||
- `yoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `xoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `relative` [boolean default v:false]
|
||||
- `border` [string default `rounded` (`sharp` on Windows)]: Border style
|
||||
- `border` [string default `rounded`]: Border style
|
||||
- `rounded` / `sharp` / `horizontal` / `vertical` / `top` / `bottom` / `left` / `right` / `no[ne]`
|
||||
|
||||
|
||||
@@ -349,7 +343,7 @@ So how can we make our custom `fzf#run` calls also respect those variables?
|
||||
Simply by "wrapping" the spec dictionary with `fzf#wrap` before passing it to
|
||||
`fzf#run`.
|
||||
|
||||
- `fzf#wrap([name string], [spec dict], [fullscreen bool]) -> (dict)`
|
||||
- `fzf#wrap([name string], [spec dict], [fullscreen bool]) -> (dict)`
|
||||
- All arguments are optional. Usually we only need to pass a spec
|
||||
dictionary.
|
||||
- `name` is for managing history files. It is ignored if `g:fzf_history_dir`
|
||||
@@ -383,7 +377,7 @@ last `fullscreen` argument of `fzf#wrap` (see :help <bang>).
|
||||
command! -bang LS call fzf#run(fzf#wrap({'source': 'ls'}, <bang>0))
|
||||
<
|
||||
Our `:LS` command will be much more useful if we can pass a directory argument
|
||||
to it, so that something like `:LS /tmp` is possible.
|
||||
to it, so that something like `:LS /tmp` is possible.
|
||||
>
|
||||
command! -bang -complete=dir -nargs=? LS
|
||||
\ call fzf#run(fzf#wrap({'source': 'ls', 'dir': <q-args>}, <bang>0))
|
||||
@@ -402,10 +396,10 @@ unique name to our command and pass it as the first argument to `fzf#wrap`.
|
||||
|
||||
- `g:fzf_layout`
|
||||
- `g:fzf_action`
|
||||
- Works only when no custom `sink` (or `sinklist`) is provided
|
||||
- Works only when no custom `sink` (or `sink*`) is provided
|
||||
- Having custom sink usually means that each entry is not an ordinary
|
||||
file path (e.g. name of color scheme), so we can't blindly apply the
|
||||
same strategy (i.e. `tabedit some-color-scheme` doesn't make sense)
|
||||
same strategy (i.e. `tabedit some-color-scheme` doesn't make sense)
|
||||
- `g:fzf_colors`
|
||||
- `g:fzf_history_dir`
|
||||
|
||||
@@ -417,12 +411,24 @@ TIPS *fzf-tips*
|
||||
< fzf inside terminal buffer >________________________________________________~
|
||||
*fzf-inside-terminal-buffer*
|
||||
|
||||
The latest versions of Vim and Neovim include builtin terminal emulator
|
||||
(`:terminal`) and fzf will start in a terminal buffer in the following cases:
|
||||
|
||||
- On Neovim
|
||||
- On GVim
|
||||
- On Terminal Vim with a non-default layout
|
||||
- `call fzf#run({'left': '30%'})` or `let g:fzf_layout = {'left': '30%'}`
|
||||
|
||||
On the latest versions of Vim and Neovim, fzf will start in a terminal buffer.
|
||||
If you find the default ANSI colors to be different, consider configuring the
|
||||
colors using `g:terminal_ansi_colors` in regular Vim or `g:terminal_color_x`
|
||||
in Neovim.
|
||||
|
||||
*g:terminal_color_15* *g:terminal_color_14* *g:terminal_color_13*
|
||||
*g:terminal_color_12* *g:terminal_color_11* *g:terminal_color_10* *g:terminal_color_9*
|
||||
*g:terminal_color_8* *g:terminal_color_7* *g:terminal_color_6* *g:terminal_color_5*
|
||||
*g:terminal_color_4* *g:terminal_color_3* *g:terminal_color_2* *g:terminal_color_1*
|
||||
*g:terminal_color_0*
|
||||
>
|
||||
" Terminal colors for seoul256 color scheme
|
||||
if has('nvim')
|
||||
@@ -468,12 +474,11 @@ in Neovim.
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
<
|
||||
Alternatively, you can make fzf open in a tmux popup window (requires tmux 3.2
|
||||
or above) by putting `--tmux` options in `tmux` key.
|
||||
or above) by putting fzf-tmux options in `tmux` key.
|
||||
>
|
||||
" See `--tmux` option in `man fzf` for available options
|
||||
" [center|top|bottom|left|right][,SIZE[%]][,SIZE[%]]
|
||||
" See `man fzf-tmux` for available options
|
||||
if exists('$TMUX')
|
||||
let g:fzf_layout = { 'tmux': '90%,70%' }
|
||||
let g:fzf_layout = { 'tmux': '-p90%,60%' }
|
||||
else
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
endif
|
||||
@@ -483,7 +488,7 @@ or above) by putting `--tmux` options in `tmux` key.
|
||||
*fzf-hide-statusline*
|
||||
|
||||
When fzf starts in a terminal buffer, the file type of the buffer is set to
|
||||
`fzf`. So you can set up `FileType fzf` autocmd to customize the settings of
|
||||
`fzf`. So you can set up `FileType fzf` autocmd to customize the settings of
|
||||
the window.
|
||||
|
||||
For example, if you open fzf on the bottom on the screen (e.g. `{'down':
|
||||
@@ -501,7 +506,7 @@ LICENSE *fzf-license*
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2026 Junegunn Choi
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
==============================================================================
|
||||
vim:tw=78:sw=2:ts=2:ft=help:norl:nowrap:
|
||||
|
||||
@@ -1,20 +1,21 @@
|
||||
module github.com/junegunn/fzf
|
||||
|
||||
require (
|
||||
github.com/charlievieth/fastwalk v1.0.14
|
||||
github.com/gdamore/tcell/v2 v2.9.0
|
||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741
|
||||
github.com/mattn/go-isatty v0.0.22
|
||||
github.com/rivo/uniseg v0.4.7
|
||||
golang.org/x/sys v0.35.0
|
||||
golang.org/x/term v0.34.0
|
||||
github.com/gdamore/tcell v1.4.0
|
||||
github.com/mattn/go-isatty v0.0.14
|
||||
github.com/mattn/go-runewidth v0.0.13
|
||||
github.com/mattn/go-shellwords v1.0.12
|
||||
github.com/rivo/uniseg v0.2.0
|
||||
github.com/saracen/walker v0.1.2
|
||||
golang.org/x/sys v0.0.0-20220406163625-3f8b81556e12
|
||||
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211
|
||||
)
|
||||
|
||||
require (
|
||||
github.com/gdamore/encoding v1.0.1 // indirect
|
||||
github.com/gdamore/encoding v1.0.0 // indirect
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0 // indirect
|
||||
github.com/mattn/go-runewidth v0.0.16 // indirect
|
||||
golang.org/x/text v0.28.0 // indirect
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c // indirect
|
||||
golang.org/x/text v0.3.7 // indirect
|
||||
)
|
||||
|
||||
go 1.23.0
|
||||
go 1.17
|
||||
|
||||
@@ -1,54 +1,32 @@
|
||||
github.com/charlievieth/fastwalk v1.0.14 h1:3Eh5uaFGwHZd8EGwTjJnSpBkfwfsak9h6ICgnWlhAyg=
|
||||
github.com/charlievieth/fastwalk v1.0.14/go.mod h1:diVcUreiU1aQ4/Wu3NbxxH4/KYdKpLDojrQ1Bb2KgNY=
|
||||
github.com/gdamore/encoding v1.0.1 h1:YzKZckdBL6jVt2Gc+5p82qhrGiqMdG/eNs6Wy0u3Uhw=
|
||||
github.com/gdamore/encoding v1.0.1/go.mod h1:0Z0cMFinngz9kS1QfMjCP8TY7em3bZYeeklsSDPivEo=
|
||||
github.com/gdamore/tcell/v2 v2.9.0 h1:N6t+eqK7/xwtRPwxzs1PXeRWnm0H9l02CrgJ7DLn1ys=
|
||||
github.com/gdamore/tcell/v2 v2.9.0/go.mod h1:8/ZoqM9rxzYphT9tH/9LnunhV9oPBqwS8WHGYm5nrmo=
|
||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741 h1:7dYDtfMDfKzjT+DVfIS4iqknSEKtZpEcXtu6vuaasHs=
|
||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741/go.mod h1:6EILKtGpo5t+KLb85LNZLAF6P9LKp78hJI80PXMcn3c=
|
||||
github.com/gdamore/encoding v1.0.0 h1:+7OoQ1Bc6eTm5niUzBa0Ctsh6JbMW6Ra+YNuAtDBdko=
|
||||
github.com/gdamore/encoding v1.0.0/go.mod h1:alR0ol34c49FCSBLjhosxzcPHQbf2trDkoo5dl+VrEg=
|
||||
github.com/gdamore/tcell v1.4.0 h1:vUnHwJRvcPQa3tzi+0QI4U9JINXYJlOz9yiaiPQ2wMU=
|
||||
github.com/gdamore/tcell v1.4.0/go.mod h1:vxEiSDZdW3L+Uhjii9c3375IlDmR05bzxY404ZVSMo0=
|
||||
github.com/lucasb-eyer/go-colorful v1.0.3/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0 h1:1nnpGOrhyZZuNyfu1QjKiUICQ74+3FNCN69Aj6K7nkY=
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
||||
github.com/mattn/go-isatty v0.0.22 h1:j8l17JJ9i6VGPUFUYoTUKPSgKe/83EYU2zBC7YNKMw4=
|
||||
github.com/mattn/go-isatty v0.0.22/go.mod h1:ZXfXG4SQHsB/w3ZeOYbR0PrPwLy+n6xiMrJlRFqopa4=
|
||||
github.com/mattn/go-runewidth v0.0.16 h1:E5ScNMtiwvlvB5paMFdw9p4kSQzbXFikJ5SQO6TULQc=
|
||||
github.com/mattn/go-runewidth v0.0.16/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
||||
github.com/mattn/go-isatty v0.0.14 h1:yVuAays6BHfxijgZPzw+3Zlu5yQgKGP2/hcQbHb7S9Y=
|
||||
github.com/mattn/go-isatty v0.0.14/go.mod h1:7GGIvUiUoEMVVmxf/4nioHXj79iQHKdU27kJ6hsGG94=
|
||||
github.com/mattn/go-runewidth v0.0.7/go.mod h1:H031xJmbD/WCDINGzjvQ9THkh0rPKHF+m2gUSrubnMI=
|
||||
github.com/mattn/go-runewidth v0.0.13 h1:lTGmDsbAYt5DmK6OnoV7EuIF1wEIFAcxld6ypU4OSgU=
|
||||
github.com/mattn/go-runewidth v0.0.13/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
||||
github.com/mattn/go-shellwords v1.0.12 h1:M2zGm7EW6UQJvDeQxo4T51eKPurbeFbe8WtebGE2xrk=
|
||||
github.com/mattn/go-shellwords v1.0.12/go.mod h1:EZzvwXDESEeg03EKmM+RmDnNOPKG4lLtQsUlTZDWQ8Y=
|
||||
github.com/rivo/uniseg v0.2.0 h1:S1pD9weZBuJdFmowNwbpi7BJ8TNftyUImj/0WQi72jY=
|
||||
github.com/rivo/uniseg v0.2.0/go.mod h1:J6wj4VEh+S6ZtnVlnTBMWIodfgj8LQOQFoIToxlJtxc=
|
||||
github.com/rivo/uniseg v0.4.7 h1:WUdvkW8uEhrYfLC4ZzdpI2ztxP1I582+49Oc5Mq64VQ=
|
||||
github.com/rivo/uniseg v0.4.7/go.mod h1:FN3SvrM+Zdj16jyLfmOkMNblXMcoc8DfTHruCPUcx88=
|
||||
github.com/yuin/goldmark v1.4.13/go.mod h1:6yULJ656Px+3vBD8DxQVa3kxgyrAnzto9xy5taEt/CY=
|
||||
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
|
||||
golang.org/x/crypto v0.0.0-20210921155107-089bfa567519/go.mod h1:GvvjBRRGRdwPK5ydBHafDWAxML/pGHZbMvKqRZ5+Abc=
|
||||
golang.org/x/mod v0.6.0-dev.0.20220419223038-86c51ed26bb4/go.mod h1:jJ57K6gSWd91VN4djpZkiMVwK6gcyfeH4XE8wZrZaV4=
|
||||
golang.org/x/mod v0.8.0/go.mod h1:iBbtSCu2XBx23ZKBPSOrRkjjQPZFPuis4dIYUhu/chs=
|
||||
golang.org/x/net v0.0.0-20190620200207-3b0461eec859/go.mod h1:z5CRVTTTmAJ677TzLLGU+0bjPO0LkuOLi4/5GtJWs/s=
|
||||
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||
golang.org/x/net v0.0.0-20220722155237-a158d28d115b/go.mod h1:XRhObCWvk6IyKnWLug+ECip1KBveYUHfp+8e9klMJ9c=
|
||||
golang.org/x/net v0.6.0/go.mod h1:2Tu9+aMcznHK/AK1HMvgo6xiTLG5rD5rZLDS+rp2Bjs=
|
||||
golang.org/x/sync v0.0.0-20190423024810-112230192c58/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sync v0.0.0-20220722155255-886fb9371eb4/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sync v0.1.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
|
||||
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
github.com/saracen/walker v0.1.2 h1:/o1TxP82n8thLvmL4GpJXduYaRmJ7qXp8u9dSlV0zmo=
|
||||
github.com/saracen/walker v0.1.2/go.mod h1:0oKYMsKVhSJ+ful4p/XbjvXbMgLEkLITZaxozsl4CGE=
|
||||
golang.org/x/sync v0.0.0-20200317015054-43a5402ce75a/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c h1:5KslGYwFpkhGh+Q16bwMP3cOontH8FOep7tGV86Y7SQ=
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sys v0.0.0-20190626150813-e07cf5db2756/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.0.0-20220520151302-bc2c85ada10a/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.35.0 h1:vz1N37gP5bs89s7He8XuIYXpyY0+QlsKmzipCbUtyxI=
|
||||
golang.org/x/sys v0.35.0/go.mod h1:BJP2sWEmIv4KK5OTEluFJCKSidICx8ciO85XgH3Ak8k=
|
||||
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||
golang.org/x/sys v0.0.0-20210630005230-0f9fa26af87c/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/sys v0.0.0-20220406163625-3f8b81556e12 h1:QyVthZKMsyaQwBTJE04jdNN0Pp5Fn9Qga0mrgxyERQM=
|
||||
golang.org/x/sys v0.0.0-20220406163625-3f8b81556e12/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211 h1:JGgROgKl9N8DuW20oFS5gxc+lE67/N3FcwmBPMe7ArY=
|
||||
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
|
||||
golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
|
||||
golang.org/x/term v0.34.0 h1:O/2T7POpk0ZZ7MAzMeWFSg6S5IpWd/RXDlM9hgM3DR4=
|
||||
golang.org/x/term v0.34.0/go.mod h1:5jC53AEywhIVebHgPVeg0mj8OD3VO9OzclacVrqpaAw=
|
||||
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/text v0.3.7 h1:olpwvP2KacW1ZWvsR7uQhoyTYvKAupfQrRGBFM352Gk=
|
||||
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
||||
golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
||||
golang.org/x/text v0.14.0/go.mod h1:18ZOQIKpY8NJVqYksKHtTdi31H5itFRjB5/qKTNYzSU=
|
||||
golang.org/x/text v0.28.0 h1:rhazDwis8INMIwQ4tpjLDzUhx6RlXqZNPEM0huQojng=
|
||||
golang.org/x/text v0.28.0/go.mod h1:U8nCwOR8jO/marOQ0QbDiOngZVEBB7MAiitBuMjXiNU=
|
||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
|
||||
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
||||
golang.org/x/tools v0.6.0/go.mod h1:Xwgl3UAJ/d3gWutnCtw505GrjyAbvKui8lOU390QaIU=
|
||||
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||
|
||||
@@ -2,11 +2,11 @@
|
||||
|
||||
set -u
|
||||
|
||||
version=0.73.1
|
||||
version=0.31.0
|
||||
auto_completion=
|
||||
key_bindings=
|
||||
update_config=2
|
||||
shells="bash zsh fish nushell"
|
||||
shells="bash zsh fish"
|
||||
prefix='~/.fzf'
|
||||
prefix_expand=~/.fzf
|
||||
fish_dir=${XDG_CONFIG_HOME:-$HOME/.config}/fish
|
||||
@@ -27,7 +27,6 @@ usage: $0 [OPTIONS]
|
||||
--no-bash Do not set up bash configuration
|
||||
--no-zsh Do not set up zsh configuration
|
||||
--no-fish Do not set up fish configuration
|
||||
--no-nushell Do not set up nushell configuration
|
||||
EOF
|
||||
}
|
||||
|
||||
@@ -47,17 +46,16 @@ for opt in "$@"; do
|
||||
prefix_expand=${XDG_CONFIG_HOME:-$HOME/.config}/fzf/fzf
|
||||
mkdir -p "${XDG_CONFIG_HOME:-$HOME/.config}/fzf"
|
||||
;;
|
||||
--key-bindings) key_bindings=1 ;;
|
||||
--no-key-bindings) key_bindings=0 ;;
|
||||
--completion) auto_completion=1 ;;
|
||||
--no-completion) auto_completion=0 ;;
|
||||
--update-rc) update_config=1 ;;
|
||||
--no-update-rc) update_config=0 ;;
|
||||
--bin) ;;
|
||||
--no-bash) shells=${shells/bash/} ;;
|
||||
--no-zsh) shells=${shells/zsh/} ;;
|
||||
--no-fish) shells=${shells/fish/} ;;
|
||||
--no-nushell) shells=${shells/nushell/} ;;
|
||||
--key-bindings) key_bindings=1 ;;
|
||||
--no-key-bindings) key_bindings=0 ;;
|
||||
--completion) auto_completion=1 ;;
|
||||
--no-completion) auto_completion=0 ;;
|
||||
--update-rc) update_config=1 ;;
|
||||
--no-update-rc) update_config=0 ;;
|
||||
--bin) ;;
|
||||
--no-bash) shells=${shells/bash/} ;;
|
||||
--no-zsh) shells=${shells/zsh/} ;;
|
||||
--no-fish) shells=${shells/fish/} ;;
|
||||
*)
|
||||
echo "unknown option: $opt"
|
||||
help
|
||||
@@ -85,7 +83,7 @@ ask() {
|
||||
check_binary() {
|
||||
echo -n " - Checking fzf executable ... "
|
||||
local output
|
||||
output=$(FZF_DEFAULT_OPTS= "$fzf_base"/bin/fzf --version 2>&1)
|
||||
output=$("$fzf_base"/bin/fzf --version 2>&1)
|
||||
if [ $? -ne 0 ]; then
|
||||
echo "Error: $output"
|
||||
binary_error="Invalid binary"
|
||||
@@ -106,7 +104,7 @@ check_binary() {
|
||||
|
||||
link_fzf_in_path() {
|
||||
if which_fzf="$(command -v fzf)"; then
|
||||
echo ' - Found in $PATH'
|
||||
echo " - Found in \$PATH"
|
||||
echo " - Creating symlink: bin/fzf -> $which_fzf"
|
||||
(cd "$fzf_base"/bin && rm -f fzf && ln -sf "$which_fzf" fzf)
|
||||
check_binary && return
|
||||
@@ -114,29 +112,24 @@ link_fzf_in_path() {
|
||||
return 1
|
||||
}
|
||||
|
||||
tar_opts="-xzf -"
|
||||
if tar --no-same-owner -tf /dev/null 2> /dev/null; then
|
||||
tar_opts="--no-same-owner $tar_opts"
|
||||
fi
|
||||
|
||||
try_curl() {
|
||||
command -v curl > /dev/null &&
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
curl -fL $1 | tar $tar_opts
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
curl -fLo "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
curl -fL $1 | tar -xzf -
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
curl -fLo "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
}
|
||||
|
||||
try_wget() {
|
||||
command -v wget > /dev/null &&
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
wget -O - $1 | tar $tar_opts
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
wget -O "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
wget -O - $1 | tar -xzf -
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
wget -O "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
}
|
||||
|
||||
download() {
|
||||
@@ -153,7 +146,7 @@ download() {
|
||||
fi
|
||||
|
||||
local url
|
||||
url=https://github.com/junegunn/fzf/releases/download/v$version/${1}
|
||||
url=https://github.com/junegunn/fzf/releases/download/$version/${1}
|
||||
set -o pipefail
|
||||
if ! (try_curl $url || try_wget $url); then
|
||||
set +o pipefail
|
||||
@@ -171,30 +164,25 @@ download() {
|
||||
}
|
||||
|
||||
# Try to download binary executable
|
||||
archi=$(uname -smo 2> /dev/null || uname -sm)
|
||||
archi=$(uname -sm)
|
||||
binary_available=1
|
||||
binary_error=""
|
||||
case "$archi" in
|
||||
Darwin\ arm64*) download fzf-$version-darwin_arm64.tar.gz ;;
|
||||
Darwin\ x86_64*) download fzf-$version-darwin_amd64.tar.gz ;;
|
||||
Linux\ armv5*) download fzf-$version-linux_armv5.tar.gz ;;
|
||||
Linux\ armv6*) download fzf-$version-linux_armv6.tar.gz ;;
|
||||
Linux\ armv7*) download fzf-$version-linux_armv7.tar.gz ;;
|
||||
Linux\ armv8*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ aarch64\ Android) download fzf-$version-android_arm64.tar.gz ;;
|
||||
Linux\ aarch64*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ loongarch64*) download fzf-$version-linux_loong64.tar.gz ;;
|
||||
Linux\ riscv64*) download fzf-$version-linux_riscv64.tar.gz ;;
|
||||
Linux\ ppc64le*) download fzf-$version-linux_ppc64le.tar.gz ;;
|
||||
Linux\ *64*) download fzf-$version-linux_amd64.tar.gz ;;
|
||||
Linux\ s390x*) download fzf-$version-linux_s390x.tar.gz ;;
|
||||
FreeBSD\ *64*) download fzf-$version-freebsd_amd64.tar.gz ;;
|
||||
OpenBSD\ *64*) download fzf-$version-openbsd_amd64.tar.gz ;;
|
||||
CYGWIN*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
||||
MINGW*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
||||
MSYS*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
||||
Windows*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
||||
*) binary_available=0 binary_error=1 ;;
|
||||
Darwin\ arm64) download fzf-$version-darwin_arm64.zip ;;
|
||||
Darwin\ x86_64) download fzf-$version-darwin_amd64.zip ;;
|
||||
Linux\ armv5*) download fzf-$version-linux_armv5.tar.gz ;;
|
||||
Linux\ armv6*) download fzf-$version-linux_armv6.tar.gz ;;
|
||||
Linux\ armv7*) download fzf-$version-linux_armv7.tar.gz ;;
|
||||
Linux\ armv8*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ aarch64*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ *64) download fzf-$version-linux_amd64.tar.gz ;;
|
||||
FreeBSD\ *64) download fzf-$version-freebsd_amd64.tar.gz ;;
|
||||
OpenBSD\ *64) download fzf-$version-openbsd_amd64.tar.gz ;;
|
||||
CYGWIN*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
MINGW*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
MSYS*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
Windows*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
*) binary_available=0 binary_error=1 ;;
|
||||
esac
|
||||
|
||||
cd "$fzf_base"
|
||||
@@ -205,12 +193,12 @@ if [ -n "$binary_error" ]; then
|
||||
echo " - $binary_error !!!"
|
||||
fi
|
||||
if command -v go > /dev/null; then
|
||||
echo -n "Building binary (go install github.com/junegunn/fzf) ... "
|
||||
echo -n "Building binary (go get -u github.com/junegunn/fzf) ... "
|
||||
if [ -z "${GOPATH-}" ]; then
|
||||
export GOPATH="${TMPDIR:-/tmp}/fzf-gopath"
|
||||
mkdir -p "$GOPATH"
|
||||
fi
|
||||
if go install -ldflags "-s -w -X main.version=$version -X main.revision=go-install" github.com/junegunn/fzf; then
|
||||
if go get -ldflags "-s -w -X main.version=$version -X main.revision=go-get" github.com/junegunn/fzf; then
|
||||
echo "OK"
|
||||
cp "$GOPATH/bin/fzf" "$fzf_base/bin/"
|
||||
else
|
||||
@@ -223,12 +211,10 @@ if [ -n "$binary_error" ]; then
|
||||
fi
|
||||
fi
|
||||
|
||||
[[ $* =~ "--bin" ]] && exit 0
|
||||
[[ "$*" =~ "--bin" ]] && exit 0
|
||||
|
||||
for s in $shells; do
|
||||
bin=$s
|
||||
[[ "$s" = nushell ]] && bin=nu
|
||||
if ! command -v "$bin" > /dev/null; then
|
||||
if ! command -v "$s" > /dev/null; then
|
||||
shells=${shells/$s/}
|
||||
fi
|
||||
done
|
||||
@@ -252,17 +238,16 @@ fi
|
||||
|
||||
echo
|
||||
for shell in $shells; do
|
||||
fzf_completion="source \"$fzf_base/shell/completion.${shell}\""
|
||||
fzf_key_bindings="source \"$fzf_base/shell/key-bindings.${shell}\""
|
||||
[[ $shell == fish ]] && continue
|
||||
[[ $shell == nushell ]] && continue
|
||||
[[ "$shell" = fish ]] && continue
|
||||
src=${prefix_expand}.${shell}
|
||||
echo -n "Generate $src ... "
|
||||
|
||||
fzf_completion="[[ \$- == *i* ]] && source \"$fzf_base/shell/completion.${shell}\" 2> /dev/null"
|
||||
if [ $auto_completion -eq 0 ]; then
|
||||
fzf_completion="# $fzf_completion"
|
||||
fi
|
||||
|
||||
fzf_key_bindings="source \"$fzf_base/shell/key-bindings.${shell}\""
|
||||
if [ $key_bindings -eq 0 ]; then
|
||||
fzf_key_bindings="# $fzf_key_bindings"
|
||||
fi
|
||||
@@ -274,16 +259,6 @@ if [[ ! "\$PATH" == *$fzf_base_esc/bin* ]]; then
|
||||
PATH="\${PATH:+\${PATH}:}$fzf_base/bin"
|
||||
fi
|
||||
|
||||
EOF
|
||||
|
||||
if [[ $auto_completion -eq 1 ]] && [[ $key_bindings -eq 1 ]]; then
|
||||
if [[ $shell == zsh ]]; then
|
||||
echo "source <(fzf --$shell)" >> "$src"
|
||||
else
|
||||
echo "eval \"\$(fzf --$shell)\"" >> "$src"
|
||||
fi
|
||||
else
|
||||
cat >> "$src" << EOF
|
||||
# Auto-completion
|
||||
# ---------------
|
||||
$fzf_completion
|
||||
@@ -292,64 +267,61 @@ $fzf_completion
|
||||
# ------------
|
||||
$fzf_key_bindings
|
||||
EOF
|
||||
fi
|
||||
echo "OK"
|
||||
done
|
||||
|
||||
# fish
|
||||
if [[ $shells =~ fish ]]; then
|
||||
if [[ "$shells" =~ fish ]]; then
|
||||
echo -n "Update fish_user_paths ... "
|
||||
fish << EOF
|
||||
echo \$fish_user_paths | \grep "$fzf_base"/bin > /dev/null
|
||||
or set --universal fish_user_paths \$fish_user_paths "$fzf_base"/bin
|
||||
EOF
|
||||
[ $? -eq 0 ] && echo "OK" || echo "Failed"
|
||||
|
||||
mkdir -p "${fish_dir}/functions"
|
||||
fish_binding="${fish_dir}/functions/fzf_key_bindings.fish"
|
||||
if [ $key_bindings -ne 0 ]; then
|
||||
echo -n "Symlink $fish_binding ... "
|
||||
ln -sf "$fzf_base/shell/key-bindings.fish" \
|
||||
"$fish_binding" && echo "OK" || echo "Failed"
|
||||
else
|
||||
echo -n "Removing $fish_binding ... "
|
||||
rm -f "$fish_binding"
|
||||
echo "OK"
|
||||
fi
|
||||
fi
|
||||
|
||||
append_line() {
|
||||
local update line file pat lines
|
||||
set -e
|
||||
|
||||
local update line file pat lno
|
||||
update="$1"
|
||||
line="$2"
|
||||
file="$3"
|
||||
pat="${4:-}"
|
||||
at_lno="${5:-}"
|
||||
lines=""
|
||||
lno=""
|
||||
|
||||
echo "Update $file:"
|
||||
echo " - $line"
|
||||
if [ -f "$file" ]; then
|
||||
if [[ -n $pat ]]; then
|
||||
lines=$(\grep -nF "$pat" "$file")
|
||||
if [ $# -lt 4 ]; then
|
||||
lno=$(\grep -nF "$line" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
else
|
||||
lines=$(\grep -nF "${line#"${line%%[![:space:]]*}"}" "$file")
|
||||
lno=$(\grep -nF "$pat" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
fi
|
||||
fi
|
||||
|
||||
if [ -n "$lines" ]; then
|
||||
echo " - Already exists:"
|
||||
sed 's/^/ Line /' <<< "$lines"
|
||||
|
||||
update=0
|
||||
if ! \grep -qv "^[0-9]*:[[:space:]]*#" <<< "$lines"; then
|
||||
echo " - But they all seem to be commented"
|
||||
ask " - Continue modifying $file?"
|
||||
update=$?
|
||||
fi
|
||||
fi
|
||||
|
||||
set -e
|
||||
if [ "$update" -eq 1 ]; then
|
||||
if [[ -z $at_lno ]]; then
|
||||
if [ -n "$lno" ]; then
|
||||
echo " - Already exists: line #$lno"
|
||||
else
|
||||
if [ $update -eq 1 ]; then
|
||||
[ -f "$file" ] && echo >> "$file"
|
||||
echo "$line" >> "$file"
|
||||
echo " + Added"
|
||||
else
|
||||
sed -i.~fzf_bak "${at_lno}a\\"$'\n'"$line" "$file" && rm "$file.~fzf_bak"
|
||||
echo " ~ Skipped"
|
||||
fi
|
||||
echo " + Added"
|
||||
else
|
||||
echo " ~ Skipped"
|
||||
fi
|
||||
|
||||
echo
|
||||
set +e
|
||||
}
|
||||
@@ -372,105 +344,32 @@ if [ $update_config -eq 2 ]; then
|
||||
fi
|
||||
echo
|
||||
for shell in $shells; do
|
||||
[[ $shell == fish ]] && continue
|
||||
[[ $shell == nushell ]] && continue
|
||||
[[ "$shell" = fish ]] && continue
|
||||
[ $shell = zsh ] && dest=${ZDOTDIR:-~}/.zshrc || dest=~/.bashrc
|
||||
append_line $update_config "[ -f ${prefix}.${shell} ] && source ${prefix}.${shell}" "$dest" "${prefix}.${shell}"
|
||||
done
|
||||
|
||||
if [[ $shells =~ fish ]]; then
|
||||
if [ $key_bindings -eq 1 ] && [[ "$shells" =~ fish ]]; then
|
||||
bind_file="${fish_dir}/functions/fish_user_key_bindings.fish"
|
||||
if [ ! -e "$bind_file" ]; then
|
||||
if [[ $key_bindings -eq 1 || $auto_completion -eq 1 ]]; then
|
||||
mkdir -p "${fish_dir}/functions"
|
||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
||||
create_file "$bind_file" \
|
||||
'function fish_user_key_bindings' \
|
||||
' fzf --fish | source' \
|
||||
'end'
|
||||
elif [[ $key_bindings -eq 1 ]]; then
|
||||
create_file "$bind_file" \
|
||||
'function fish_user_key_bindings' \
|
||||
" $fzf_key_bindings" \
|
||||
'end'
|
||||
elif [[ $auto_completion -eq 1 ]]; then
|
||||
create_file "$bind_file" \
|
||||
'function fish_user_key_bindings' \
|
||||
" $fzf_completion" \
|
||||
'end'
|
||||
fi
|
||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
else
|
||||
lno_func=0
|
||||
fi
|
||||
create_file "$bind_file" \
|
||||
'function fish_user_key_bindings' \
|
||||
' fzf_key_bindings' \
|
||||
'end'
|
||||
else
|
||||
echo "Check $bind_file:"
|
||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
if [[ -z $lno_func ]]; then
|
||||
echo -e "function fish_user_key_bindings\nend" >> "$bind_file"
|
||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
fi
|
||||
lno_keys=$(\grep -nF "fzf_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
if [[ -n $lno_keys ]]; then
|
||||
echo " ** Found 'fzf_key_bindings' in line #$lno_keys"
|
||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
||||
echo " ** You have to replace the line to 'fzf --fish | source'"
|
||||
elif [[ $key_bindings -eq 1 ]]; then
|
||||
echo " ** You have to replace the line to '$fzf_key_bindings'"
|
||||
else
|
||||
echo " ** You have to remove the line"
|
||||
fi
|
||||
echo
|
||||
else
|
||||
echo " - Clear"
|
||||
echo
|
||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
||||
sed -i.~fzf_bak "\#$fzf_completion#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
||||
sed -i.~fzf_bak "\#$fzf_key_bindings#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
||||
append_line $update_config " fzf --fish | source" "$bind_file" "" "$lno_func"
|
||||
else
|
||||
sed -i.~fzf_bak '/fzf --fish \| source/d' "$bind_file" && rm "$bind_file.~fzf_bak"
|
||||
if [[ $key_bindings -eq 1 ]]; then
|
||||
sed -i.~fzf_bak "\#$fzf_completion#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
||||
append_line $update_config " $fzf_key_bindings" "$bind_file" "" "$lno_func"
|
||||
elif [[ $auto_completion -eq 1 ]]; then
|
||||
sed -i.~fzf_bak "\#$fzf_key_bindings#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
||||
append_line $update_config " $fzf_completion" "$bind_file" "" "$lno_func"
|
||||
fi
|
||||
fi
|
||||
fi
|
||||
fi
|
||||
fi
|
||||
|
||||
if [[ "$shells" =~ nushell ]]; then
|
||||
if [[ $key_bindings -eq 1 || $auto_completion -eq 1 ]]; then
|
||||
echo "Setting up Nushell integration ..."
|
||||
nushell_autoload_dir=$(nu -c '$nu.user-autoload-dirs | first')
|
||||
mkdir -p "$nushell_autoload_dir"
|
||||
dest="$nushell_autoload_dir/_fzf_integration.nu"
|
||||
echo -n " Generate $dest ... "
|
||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
||||
"$fzf_base"/bin/fzf --nushell > "$dest"
|
||||
elif [[ $key_bindings -eq 1 ]]; then
|
||||
cp "$fzf_base/shell/key-bindings.nu" "$dest"
|
||||
else
|
||||
cp "$fzf_base/shell/completion.nu" "$dest"
|
||||
fi
|
||||
echo "OK"
|
||||
echo
|
||||
append_line $update_config "fzf_key_bindings" "$bind_file"
|
||||
fi
|
||||
fi
|
||||
|
||||
if [ $update_config -eq 1 ]; then
|
||||
echo 'Finished. Restart your shell or reload config file.'
|
||||
if [[ $shells =~ bash ]]; then
|
||||
if [[ "$shells" =~ bash ]]; then
|
||||
echo -n ' source ~/.bashrc # bash'
|
||||
[[ $archi =~ Darwin ]] && echo -n ' (.bashrc should be loaded from .bash_profile)'
|
||||
[[ "$archi" =~ Darwin ]] && echo -n ' (.bashrc should be loaded from .bash_profile)'
|
||||
echo
|
||||
fi
|
||||
[[ $shells =~ zsh ]] && echo " source ${ZDOTDIR:-~}/.zshrc # zsh"
|
||||
[[ $shells =~ fish && $lno_func -ne 0 ]] && echo ' fish_user_key_bindings # fish'
|
||||
[[ $shells =~ nushell ]] && echo ' # nushell: files are loaded automatically from autoload directory'
|
||||
[[ "$shells" =~ zsh ]] && echo " source ${ZDOTDIR:-~}/.zshrc # zsh"
|
||||
[[ "$shells" =~ fish ]] && [ $key_bindings -eq 1 ] && echo ' fzf_key_bindings # fish'
|
||||
echo
|
||||
echo 'Use uninstall script to remove fzf.'
|
||||
echo
|
||||
|
||||
+2
-2
@@ -1,4 +1,4 @@
|
||||
$version="0.73.1"
|
||||
$version="0.31.0"
|
||||
|
||||
$fzf_base=Split-Path -Parent $MyInvocation.MyCommand.Definition
|
||||
|
||||
@@ -40,7 +40,7 @@ function download {
|
||||
return
|
||||
}
|
||||
cd "$fzf_base\bin"
|
||||
$url="https://github.com/junegunn/fzf/releases/download/v$version/$file"
|
||||
$url="https://github.com/junegunn/fzf/releases/download/$version/$file"
|
||||
$temp=$env:TMP + "\fzf.zip"
|
||||
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
|
||||
if ($PSVersionTable.PSVersion.Major -ge 3) {
|
||||
|
||||
@@ -1,115 +1,14 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
_ "embed"
|
||||
"fmt"
|
||||
"os"
|
||||
"os/exec"
|
||||
"strings"
|
||||
|
||||
fzf "github.com/junegunn/fzf/src"
|
||||
"github.com/junegunn/fzf/src/protector"
|
||||
)
|
||||
|
||||
var version = "0.73"
|
||||
var revision = "devel"
|
||||
|
||||
//go:embed shell/key-bindings.bash
|
||||
var bashKeyBindings []byte
|
||||
|
||||
//go:embed shell/completion.bash
|
||||
var bashCompletion []byte
|
||||
|
||||
//go:embed shell/key-bindings.zsh
|
||||
var zshKeyBindings []byte
|
||||
|
||||
//go:embed shell/completion.zsh
|
||||
var zshCompletion []byte
|
||||
|
||||
//go:embed shell/key-bindings.fish
|
||||
var fishKeyBindings []byte
|
||||
|
||||
//go:embed shell/key-bindings.nu
|
||||
var nushellKeyBindings []byte
|
||||
|
||||
//go:embed shell/completion.nu
|
||||
var nushellCompletion []byte
|
||||
|
||||
//go:embed shell/completion.fish
|
||||
var fishCompletion []byte
|
||||
|
||||
//go:embed man/man1/fzf.1
|
||||
var manPage []byte
|
||||
|
||||
func printScript(label string, content []byte) {
|
||||
fmt.Println("### " + label + " ###")
|
||||
fmt.Println(strings.TrimSpace(string(content)))
|
||||
fmt.Println("### end: " + label + " ###")
|
||||
}
|
||||
|
||||
func exit(code int, err error) {
|
||||
if code == fzf.ExitError && err != nil {
|
||||
fmt.Fprintln(os.Stderr, err.Error())
|
||||
}
|
||||
os.Exit(code)
|
||||
}
|
||||
var version string = "0.31"
|
||||
var revision string = "devel"
|
||||
|
||||
func main() {
|
||||
protector.Protect()
|
||||
|
||||
options, err := fzf.ParseOptions(true, os.Args[1:])
|
||||
if err != nil {
|
||||
exit(fzf.ExitError, err)
|
||||
return
|
||||
}
|
||||
if options.Bash {
|
||||
printScript("key-bindings.bash", bashKeyBindings)
|
||||
printScript("completion.bash", bashCompletion)
|
||||
return
|
||||
}
|
||||
if options.Zsh {
|
||||
printScript("key-bindings.zsh", zshKeyBindings)
|
||||
printScript("completion.zsh", zshCompletion)
|
||||
return
|
||||
}
|
||||
if options.Fish {
|
||||
printScript("key-bindings.fish", fishKeyBindings)
|
||||
printScript("completion.fish", fishCompletion)
|
||||
return
|
||||
}
|
||||
if options.Nushell {
|
||||
printScript("key-bindings.nu", nushellKeyBindings)
|
||||
printScript("completion.nu", nushellCompletion)
|
||||
return
|
||||
}
|
||||
if options.Help {
|
||||
fmt.Print(fzf.Usage)
|
||||
return
|
||||
}
|
||||
if options.Version {
|
||||
if len(revision) > 0 {
|
||||
fmt.Printf("%s (%s)\n", version, revision)
|
||||
} else {
|
||||
fmt.Println(version)
|
||||
}
|
||||
return
|
||||
}
|
||||
if options.Man {
|
||||
file := fzf.WriteTemporaryFile([]string{string(manPage)}, "\n")
|
||||
if len(file) == 0 {
|
||||
fmt.Print(string(manPage))
|
||||
return
|
||||
}
|
||||
defer os.Remove(file)
|
||||
cmd := exec.Command("man", file)
|
||||
cmd.Stdin = os.Stdin
|
||||
cmd.Stdout = os.Stdout
|
||||
if err := cmd.Run(); err != nil {
|
||||
fmt.Print(string(manPage))
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
code, err := fzf.Run(options)
|
||||
exit(code, err)
|
||||
fzf.Run(fzf.ParseOptions(), version, revision)
|
||||
}
|
||||
|
||||
+16
-16
@@ -1,7 +1,7 @@
|
||||
.ig
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2026 Junegunn Choi
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
@@ -21,48 +21,48 @@ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
..
|
||||
.TH fzf\-tmux 1 "May 2026" "fzf 0.73.1" "fzf\-tmux - open fzf in tmux split pane"
|
||||
.TH fzf-tmux 1 "Jul 2022" "fzf 0.31.0" "fzf-tmux - open fzf in tmux split pane"
|
||||
|
||||
.SH NAME
|
||||
fzf\-tmux - open fzf in tmux split pane
|
||||
fzf-tmux - open fzf in tmux split pane
|
||||
|
||||
.SH SYNOPSIS
|
||||
.B fzf\-tmux [\fILAYOUT OPTIONS\fR] [\-\-] [\fIFZF OPTIONS\fR]
|
||||
.B fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
|
||||
.SH DESCRIPTION
|
||||
fzf\-tmux is a wrapper script for fzf that opens fzf in a tmux split pane or in
|
||||
fzf-tmux is a wrapper script for fzf that opens fzf in a tmux split pane or in
|
||||
a tmux popup window. It is designed to work just like fzf except that it does
|
||||
not take up the whole screen. You can safely use fzf\-tmux instead of fzf in
|
||||
not take up the whole screen. You can safely use fzf-tmux instead of fzf in
|
||||
your scripts as the extra options will be silently ignored if you're not on
|
||||
tmux.
|
||||
|
||||
.SH LAYOUT OPTIONS
|
||||
|
||||
(default layout: \fB\-d 50%\fR)
|
||||
(default layout: \fB-d 50%\fR)
|
||||
|
||||
.SS Popup window
|
||||
(requires tmux 3.2 or above)
|
||||
.TP
|
||||
.B "\-p [WIDTH[%][,HEIGHT[%]]]"
|
||||
.B "-p [WIDTH[%][,HEIGHT[%]]]"
|
||||
.TP
|
||||
.B "\-w WIDTH[%]"
|
||||
.B "-w WIDTH[%]"
|
||||
.TP
|
||||
.B "\-h WIDTH[%]"
|
||||
.B "-h WIDTH[%]"
|
||||
.TP
|
||||
.B "\-x COL"
|
||||
.B "-x COL"
|
||||
.TP
|
||||
.B "\-y ROW"
|
||||
.B "-y ROW"
|
||||
|
||||
.SS Split pane
|
||||
.TP
|
||||
.B "\-u [height[%]]"
|
||||
.B "-u [height[%]]"
|
||||
Split above (up)
|
||||
.TP
|
||||
.B "\-d [height[%]]"
|
||||
.B "-d [height[%]]"
|
||||
Split below (down)
|
||||
.TP
|
||||
.B "\-l [width[%]]"
|
||||
.B "-l [width[%]]"
|
||||
Split left
|
||||
.TP
|
||||
.B "\-r [width[%]]"
|
||||
.B "-r [width[%]]"
|
||||
Split right
|
||||
|
||||
+483
-1789
File diff suppressed because it is too large
Load Diff
+99
-197
@@ -1,4 +1,4 @@
|
||||
" Copyright (c) 2013-2026 Junegunn Choi
|
||||
" Copyright (c) 2017 Junegunn Choi
|
||||
"
|
||||
" MIT License
|
||||
"
|
||||
@@ -59,9 +59,12 @@ if s:is_win
|
||||
return iconv(a:str, &encoding, 'cp'.s:codepage)
|
||||
endfunction
|
||||
function! s:wrap_cmds(cmds)
|
||||
return map(['@echo off']
|
||||
return map([
|
||||
\ '@echo off',
|
||||
\ 'setlocal enabledelayedexpansion']
|
||||
\ + (has('gui_running') ? ['set TERM= > nul'] : [])
|
||||
\ + (type(a:cmds) == type([]) ? a:cmds : [a:cmds]),
|
||||
\ + (type(a:cmds) == type([]) ? a:cmds : [a:cmds])
|
||||
\ + ['endlocal'],
|
||||
\ '<SID>enc_to_cp(v:val."\r")')
|
||||
endfunction
|
||||
else
|
||||
@@ -81,21 +84,11 @@ else
|
||||
endif
|
||||
|
||||
function! s:shellesc_cmd(arg)
|
||||
let e = '"'
|
||||
let slashes = 0
|
||||
for c in split(a:arg, '\zs')
|
||||
if c ==# '\'
|
||||
let slashes += 1
|
||||
elseif c ==# '"'
|
||||
let e .= repeat('\', slashes + 1)
|
||||
let slashes = 0
|
||||
else
|
||||
let slashes = 0
|
||||
endif
|
||||
let e .= c
|
||||
endfor
|
||||
let e .= repeat('\', slashes) .'"'
|
||||
return substitute(substitute(e, '[&|<>()^!"]', '^&', 'g'), '%', '%%', 'g')
|
||||
let escaped = substitute(a:arg, '[&|<>()@^]', '^&', 'g')
|
||||
let escaped = substitute(escaped, '%', '%%', 'g')
|
||||
let escaped = substitute(escaped, '"', '\\^&', 'g')
|
||||
let escaped = substitute(escaped, '\(\\\+\)\(\\^\)', '\1\1\2', 'g')
|
||||
return '^"'.substitute(escaped, '\(\\\+\)$', '\1\1', '').'^"'
|
||||
endfunction
|
||||
|
||||
function! fzf#shellescape(arg, ...)
|
||||
@@ -150,7 +143,7 @@ function! fzf#install()
|
||||
if !filereadable(script)
|
||||
throw script.' not found'
|
||||
endif
|
||||
let script = 'powershell -ExecutionPolicy Bypass -file ' . shellescape(script)
|
||||
let script = 'powershell -ExecutionPolicy Bypass -file ' . script
|
||||
else
|
||||
let script = s:base_dir.'/install'
|
||||
if !executable(script)
|
||||
@@ -171,7 +164,7 @@ function s:get_version(bin)
|
||||
if has_key(s:versions, a:bin)
|
||||
return s:versions[a:bin]
|
||||
end
|
||||
let command = (&shell =~ 'powershell\|pwsh' ? '&' : '') . s:fzf_call('shellescape', a:bin) . ' --version --no-height'
|
||||
let command = fzf#shellescape(a:bin) . ' --version --no-height'
|
||||
let output = systemlist(command)
|
||||
if v:shell_error || empty(output)
|
||||
return ''
|
||||
@@ -198,7 +191,6 @@ function! s:compare_binary_versions(a, b)
|
||||
return s:compare_versions(s:get_version(a:a), s:get_version(a:b))
|
||||
endfunction
|
||||
|
||||
let s:min_version = '0.53.0'
|
||||
let s:checked = {}
|
||||
function! fzf#exec(...)
|
||||
if !exists('s:exec')
|
||||
@@ -226,11 +218,7 @@ function! fzf#exec(...)
|
||||
let s:exec = binaries[-1]
|
||||
endif
|
||||
|
||||
let min_version = s:min_version
|
||||
if a:0 && s:compare_versions(a:1, min_version) > 0
|
||||
let min_version = a:1
|
||||
endif
|
||||
if !has_key(s:checked, min_version)
|
||||
if a:0 && !has_key(s:checked, a:1)
|
||||
let fzf_version = s:get_version(s:exec)
|
||||
if empty(fzf_version)
|
||||
let message = printf('Failed to run "%s --version"', s:exec)
|
||||
@@ -238,17 +226,17 @@ function! fzf#exec(...)
|
||||
throw message
|
||||
end
|
||||
|
||||
if s:compare_versions(fzf_version, min_version) >= 0
|
||||
let s:checked[min_version] = 1
|
||||
if s:compare_versions(fzf_version, a:1) >= 0
|
||||
let s:checked[a:1] = 1
|
||||
return s:exec
|
||||
elseif a:0 < 2 && input(printf('You need fzf %s or above. Found: %s. Download binary? (y/n) ', min_version, fzf_version)) =~? '^y'
|
||||
elseif a:0 < 2 && input(printf('You need fzf %s or above. Found: %s. Download binary? (y/n) ', a:1, fzf_version)) =~? '^y'
|
||||
let s:versions = {}
|
||||
unlet s:exec
|
||||
redraw
|
||||
call fzf#install()
|
||||
return fzf#exec(min_version, 1)
|
||||
return fzf#exec(a:1, 1)
|
||||
else
|
||||
throw printf('You need to upgrade fzf (required: %s or above)', min_version)
|
||||
throw printf('You need to upgrade fzf (required: %s or above)', a:1)
|
||||
endif
|
||||
endif
|
||||
|
||||
@@ -332,10 +320,7 @@ function! s:common_sink(action, lines) abort
|
||||
" the execution (e.g. `set autochdir` or `autocmd BufEnter * lcd ...`)
|
||||
let cwd = exists('w:fzf_pushd') ? w:fzf_pushd.dir : expand('%:p:h')
|
||||
for item in a:lines
|
||||
if has('win32unix') && item !~ '/'
|
||||
let item = substitute(item, '\', '/', 'g')
|
||||
end
|
||||
if item[0] != '~' && item !~ (s:is_win ? '^\([A-Z]:\)\?\' : '^/')
|
||||
if item[0] != '~' && item !~ (s:is_win ? '^[A-Z]:\' : '^/')
|
||||
let sep = s:is_win ? '\' : '/'
|
||||
let item = join([cwd, item], cwd[len(cwd)-1] == sep ? '' : sep)
|
||||
endif
|
||||
@@ -357,8 +342,7 @@ function! s:common_sink(action, lines) abort
|
||||
endfunction
|
||||
|
||||
function! s:get_color(attr, ...)
|
||||
" Force 24 bit colors: g:fzf_force_termguicolors (temporary workaround for https://github.com/junegunn/fzf.vim/issues/1152)
|
||||
let gui = get(g:, 'fzf_force_termguicolors', 0) || (!s:is_win && !has('win32unix') && (has('gui_running') || has('termguicolors') && &termguicolors))
|
||||
let gui = !s:is_win && !has('win32unix') && has('termguicolors') && &termguicolors
|
||||
let fam = gui ? 'gui' : 'cterm'
|
||||
let pat = gui ? '^#[a-f0-9]\+' : '^[0-9]\+$'
|
||||
for group in a:000
|
||||
@@ -471,32 +455,6 @@ function! s:writefile(...)
|
||||
endif
|
||||
endfunction
|
||||
|
||||
function! s:extract_option(opts, name)
|
||||
let opt = ''
|
||||
let expect = 0
|
||||
" There are a few cases where this function doesn't work as expected.
|
||||
" Let's just assume such cases are extremely unlikely in real world.
|
||||
" e.g. --query --border
|
||||
for word in split(a:opts)
|
||||
if expect && word !~ '^"\=-'
|
||||
let opt = opt . ' ' . word
|
||||
let expect = 0
|
||||
elseif word == '--no-'.a:name
|
||||
let opt = ''
|
||||
elseif word =~ '^--'.a:name.'='
|
||||
let opt = word
|
||||
elseif word =~ '^--'.a:name.'$'
|
||||
let opt = word
|
||||
let expect = 1
|
||||
elseif expect
|
||||
let expect = 0
|
||||
endif
|
||||
endfor
|
||||
return opt
|
||||
endfunction
|
||||
|
||||
let s:need_cmd_window = has('win32unix') && $TERM_PROGRAM ==# 'mintty' && s:compare_versions($TERM_PROGRAM_VERSION, '3.4.5') < 0 && !executable('winpty')
|
||||
|
||||
function! fzf#run(...) abort
|
||||
try
|
||||
let [shell, shellslash, shellcmdflag, shellxquote] = s:use_sh()
|
||||
@@ -505,7 +463,7 @@ try
|
||||
let temps = { 'result': s:fzf_tempname() }
|
||||
let optstr = s:evaluate_opts(get(dict, 'options', ''))
|
||||
try
|
||||
let fzf_exec = shellescape(fzf#exec())
|
||||
let fzf_exec = fzf#shellescape(fzf#exec())
|
||||
catch
|
||||
throw v:exception
|
||||
endtry
|
||||
@@ -518,19 +476,19 @@ try
|
||||
endif
|
||||
|
||||
if has_key(dict, 'source')
|
||||
let source = dict.source
|
||||
let source = remove(dict, 'source')
|
||||
let type = type(source)
|
||||
if type == 1
|
||||
let prefix = '('.source.')|'
|
||||
let source_command = source
|
||||
elseif type == 3
|
||||
let temps.input = s:fzf_tempname()
|
||||
call s:writefile(source, temps.input)
|
||||
let prefix = (s:is_win ? 'type ' : 'command cat ').fzf#shellescape(temps.input).'|'
|
||||
let source_command = (s:is_win ? 'type ' : 'cat ').fzf#shellescape(temps.input)
|
||||
else
|
||||
throw 'Invalid source type'
|
||||
endif
|
||||
else
|
||||
let prefix = ''
|
||||
let source_command = ''
|
||||
endif
|
||||
|
||||
let prefer_tmux = get(g:, 'fzf_prefer_tmux', 0) || has_key(dict, 'tmux')
|
||||
@@ -539,30 +497,25 @@ try
|
||||
\ executable('tput') && filereadable('/dev/tty')
|
||||
let has_vim8_term = has('terminal') && has('patch-8.0.995')
|
||||
let has_nvim_term = has('nvim-0.2.1') || has('nvim') && !s:is_win
|
||||
let use_term = has_nvim_term || has_vim8_term
|
||||
\ && !s:need_cmd_window
|
||||
\ && (has('gui_running') || s:is_win || s:present(dict, 'down', 'up', 'left', 'right', 'window'))
|
||||
let use_term = has_nvim_term ||
|
||||
\ has_vim8_term && !has('win32unix') && (has('gui_running') || s:is_win || s:present(dict, 'down', 'up', 'left', 'right', 'window'))
|
||||
let use_tmux = (has_key(dict, 'tmux') || (!use_height && !use_term || prefer_tmux) && !has('win32unix') && s:splittable(dict)) && s:tmux_enabled()
|
||||
if prefer_tmux && use_tmux
|
||||
let use_height = 0
|
||||
let use_term = 0
|
||||
endif
|
||||
if use_term
|
||||
let optstr .= ' --no-height --no-tmux'
|
||||
let optstr .= ' --no-height'
|
||||
elseif use_height
|
||||
let height = s:calc_size(&lines, dict.down, dict)
|
||||
let optstr .= ' --no-tmux --height='.height
|
||||
let optstr .= ' --height='.height
|
||||
endif
|
||||
|
||||
if exists('&winborder') && &winborder !=# '' && &winborder !=# 'none'
|
||||
" Add 1-column horizontal margin
|
||||
let optstr = join(['--margin 0,1', optstr])
|
||||
else
|
||||
" Respect --border option given in $FZF_DEFAULT_OPTS and 'options'
|
||||
let optstr = join([s:border_opt(get(dict, 'window', 0)), s:extract_option($FZF_DEFAULT_OPTS, 'border'), optstr])
|
||||
let optstr .= s:border_opt(get(dict, 'window', 0))
|
||||
let prev_default_command = $FZF_DEFAULT_COMMAND
|
||||
if len(source_command)
|
||||
let $FZF_DEFAULT_COMMAND = source_command
|
||||
endif
|
||||
|
||||
let command = prefix.(use_tmux ? s:fzf_tmux(dict) : fzf_exec).' '.optstr.' > '.temps.result
|
||||
let command = (use_tmux ? s:fzf_tmux(dict) : fzf_exec).' '.optstr.' > '.temps.result
|
||||
|
||||
if use_term
|
||||
return s:execute_term(dict, command, temps)
|
||||
@@ -573,6 +526,14 @@ try
|
||||
call s:callback(dict, lines)
|
||||
return lines
|
||||
finally
|
||||
if exists('source_command') && len(source_command)
|
||||
if len(prev_default_command)
|
||||
let $FZF_DEFAULT_COMMAND = prev_default_command
|
||||
else
|
||||
let $FZF_DEFAULT_COMMAND = ''
|
||||
silent! execute 'unlet $FZF_DEFAULT_COMMAND'
|
||||
endif
|
||||
endif
|
||||
let [&shell, &shellslash, &shellcmdflag, &shellxquote] = [shell, shellslash, shellcmdflag, shellxquote]
|
||||
endtry
|
||||
endfunction
|
||||
@@ -591,21 +552,19 @@ function! s:fzf_tmux(dict)
|
||||
if empty(size)
|
||||
for o in ['up', 'down', 'left', 'right']
|
||||
if s:present(a:dict, o)
|
||||
let size = o . ',' . a:dict[o]
|
||||
let spec = a:dict[o]
|
||||
if (o == 'up' || o == 'down') && spec[0] == '~'
|
||||
let size = '-'.o[0].s:calc_size(&lines, spec, a:dict)
|
||||
else
|
||||
" Legacy boolean option
|
||||
let size = '-'.o[0].(spec == 1 ? '' : substitute(spec, '^\~', '', ''))
|
||||
endif
|
||||
break
|
||||
endif
|
||||
endfor
|
||||
endif
|
||||
|
||||
" Legacy fzf-tmux options
|
||||
if size =~ '-'
|
||||
return printf('LINES=%d COLUMNS=%d %s %s %s --',
|
||||
\ &lines, &columns, fzf#shellescape(s:fzf_tmux), size, (has_key(a:dict, 'source') ? '' : '-'))
|
||||
end
|
||||
|
||||
" Using native --tmux option
|
||||
let in = (has_key(a:dict, 'source') ? '' : ' --force-tty-in')
|
||||
return printf('%s --tmux %s%s', fzf#shellescape(fzf#exec()), size, in)
|
||||
return printf('LINES=%d COLUMNS=%d %s %s - --',
|
||||
\ &lines, &columns, fzf#shellescape(s:fzf_tmux), size)
|
||||
endfunction
|
||||
|
||||
function! s:splittable(dict)
|
||||
@@ -677,17 +636,21 @@ else
|
||||
let s:launcher = function('s:xterm_launcher')
|
||||
endif
|
||||
|
||||
function! s:exit_handler(dict, code, command, ...)
|
||||
if has_key(a:dict, 'exit')
|
||||
call a:dict.exit(a:code)
|
||||
endif
|
||||
if a:code == 2
|
||||
function! s:exit_handler(code, command, ...)
|
||||
if a:code == 130
|
||||
return 0
|
||||
elseif has('nvim') && a:code == 129
|
||||
" When deleting the terminal buffer while fzf is still running,
|
||||
" Nvim sends SIGHUP.
|
||||
return 0
|
||||
elseif a:code > 1
|
||||
call s:error('Error running ' . a:command)
|
||||
if !empty(a:000)
|
||||
sleep
|
||||
endif
|
||||
return 0
|
||||
endif
|
||||
return a:code
|
||||
return 1
|
||||
endfunction
|
||||
|
||||
function! s:execute(dict, command, use_height, temps) abort
|
||||
@@ -724,22 +687,21 @@ function! s:execute(dict, command, use_height, temps) abort
|
||||
call jobstart(cmd, fzf)
|
||||
return []
|
||||
endif
|
||||
elseif s:need_cmd_window
|
||||
elseif has('win32unix') && $TERM !=# 'cygwin'
|
||||
let shellscript = s:fzf_tempname()
|
||||
call s:writefile([command], shellscript)
|
||||
let command = 'start //WAIT sh -c '.shellscript
|
||||
let command = 'cmd.exe /C '.fzf#shellescape('set "TERM=" & start /WAIT sh -c '.shellscript)
|
||||
let a:temps.shellscript = shellscript
|
||||
endif
|
||||
if a:use_height
|
||||
let stdin = has_key(a:dict, 'source') ? '' : '< /dev/tty'
|
||||
call system(printf('tput cup %d > /dev/tty; tput cnorm > /dev/tty; %s %s 2> /dev/tty', &lines, command, stdin))
|
||||
call system(printf('tput cup %d > /dev/tty; tput cnorm > /dev/tty; %s < /dev/tty 2> /dev/tty', &lines, command))
|
||||
else
|
||||
execute 'silent !'.command
|
||||
endif
|
||||
let exit_status = v:shell_error
|
||||
redraw!
|
||||
let lines = s:collect(a:temps)
|
||||
return s:exit_handler(a:dict, exit_status, command) < 2 ? lines : []
|
||||
return s:exit_handler(exit_status, command) ? lines : []
|
||||
endfunction
|
||||
|
||||
function! s:execute_tmux(dict, command, temps) abort
|
||||
@@ -754,7 +716,7 @@ function! s:execute_tmux(dict, command, temps) abort
|
||||
let exit_status = v:shell_error
|
||||
redraw!
|
||||
let lines = s:collect(a:temps)
|
||||
return s:exit_handler(a:dict, exit_status, command) < 2 ? lines : []
|
||||
return s:exit_handler(exit_status, command) ? lines : []
|
||||
endfunction
|
||||
|
||||
function! s:calc_size(max, val, dict)
|
||||
@@ -775,7 +737,7 @@ function! s:calc_size(max, val, dict)
|
||||
return size
|
||||
endif
|
||||
let margin = match(opts, '--inline-info\|--info[^-]\{-}inline') > match(opts, '--no-inline-info\|--info[^-]\{-}\(default\|hidden\)') ? 1 : 2
|
||||
let margin += match(opts, '--border\([^-]\|$\)') > match(opts, '--no-border\([^-]\|$\)') ? 2 : 0
|
||||
let margin += stridx(opts, '--border') > stridx(opts, '--no-border') ? 2 : 0
|
||||
if stridx(opts, '--header') > stridx(opts, '--no-header')
|
||||
let margin += len(split(opts, "\n"))
|
||||
endif
|
||||
@@ -792,9 +754,9 @@ function! s:border_opt(window)
|
||||
endif
|
||||
|
||||
" Border style
|
||||
let style = tolower(get(a:window, 'border', ''))
|
||||
if !has_key(a:window, 'border') && has_key(a:window, 'rounded')
|
||||
let style = a:window.rounded ? 'rounded' : 'sharp'
|
||||
let style = tolower(get(a:window, 'border', 'rounded'))
|
||||
if !has_key(a:window, 'border') && !get(a:window, 'rounded', 1)
|
||||
let style = 'sharp'
|
||||
endif
|
||||
if style == 'none' || style == 'no'
|
||||
return ''
|
||||
@@ -802,7 +764,7 @@ function! s:border_opt(window)
|
||||
|
||||
" For --border styles, we need fzf 0.24.0 or above
|
||||
call fzf#exec('0.24.0')
|
||||
let opt = ' --border ' . style
|
||||
let opt = ' --border=' . style
|
||||
if has_key(a:window, 'highlight')
|
||||
let color = s:get_color('fg', a:window.highlight)
|
||||
if len(color)
|
||||
@@ -864,17 +826,6 @@ if exists(':tnoremap')
|
||||
tnoremap <silent> <Plug>(fzf-normal) <C-\><C-n>
|
||||
endif
|
||||
|
||||
let s:warned = 0
|
||||
function! s:handle_ambidouble(dict)
|
||||
if &ambiwidth == 'double'
|
||||
let a:dict.env = { 'RUNEWIDTH_EASTASIAN': '1' }
|
||||
elseif !s:warned && $RUNEWIDTH_EASTASIAN == '1' && &ambiwidth !=# 'double'
|
||||
call s:warn("$RUNEWIDTH_EASTASIAN is '1' but &ambiwidth is not 'double'")
|
||||
2sleep
|
||||
let s:warned = 1
|
||||
endif
|
||||
endfunction
|
||||
|
||||
function! s:execute_term(dict, command, temps) abort
|
||||
let winrest = winrestcmd()
|
||||
let pbuf = bufnr('')
|
||||
@@ -896,7 +847,6 @@ function! s:execute_term(dict, command, temps) abort
|
||||
endif
|
||||
endfunction
|
||||
function! fzf.on_exit(id, code, ...)
|
||||
silent! autocmd! fzf_popup_resize
|
||||
if s:getpos() == self.ppos " {'window': 'enew'}
|
||||
for [opt, val] in items(self.winopts)
|
||||
execute 'let' opt '=' val
|
||||
@@ -921,7 +871,7 @@ function! s:execute_term(dict, command, temps) abort
|
||||
endif
|
||||
|
||||
let lines = s:collect(self.temps)
|
||||
if s:exit_handler(self.dict, a:code, self.command, 1) >= 2
|
||||
if !s:exit_handler(a:code, self.command, 1)
|
||||
return
|
||||
endif
|
||||
|
||||
@@ -945,7 +895,6 @@ function! s:execute_term(dict, command, temps) abort
|
||||
endif
|
||||
let command .= s:term_marker
|
||||
if has('nvim')
|
||||
call s:handle_ambidouble(fzf)
|
||||
call termopen(command, fzf)
|
||||
else
|
||||
let term_opts = {'exit_cb': function(fzf.on_exit)}
|
||||
@@ -957,8 +906,7 @@ function! s:execute_term(dict, command, temps) abort
|
||||
else
|
||||
let term_opts.curwin = 1
|
||||
endif
|
||||
call s:handle_ambidouble(term_opts)
|
||||
keepjumps let fzf.buf = term_start([&shell, &shellcmdflag, command], term_opts)
|
||||
let fzf.buf = term_start([&shell, &shellcmdflag, command], term_opts)
|
||||
if is_popup && exists('#TerminalWinOpen')
|
||||
doautocmd <nomodeline> TerminalWinOpen
|
||||
endif
|
||||
@@ -1024,79 +972,41 @@ function! s:callback(dict, lines) abort
|
||||
endfunction
|
||||
|
||||
if has('nvim')
|
||||
function! s:create_popup() abort
|
||||
let opts = s:popup_bounds()
|
||||
let opts = extend({'relative': 'editor', 'style': 'minimal'}, opts)
|
||||
|
||||
function s:create_popup(hl, opts) abort
|
||||
let buf = nvim_create_buf(v:false, v:true)
|
||||
let s:popup_id = nvim_open_win(buf, v:true, opts)
|
||||
call setwinvar(s:popup_id, '&colorcolumn', '')
|
||||
|
||||
" Colors
|
||||
try
|
||||
call setwinvar(s:popup_id, '&winhighlight', 'Pmenu:,Normal:Normal')
|
||||
let rules = get(g:, 'fzf_colors', {})
|
||||
if has_key(rules, 'bg')
|
||||
let color = call('s:get_color', rules.bg)
|
||||
if len(color)
|
||||
let ns = nvim_create_namespace('fzf_popup')
|
||||
let hl = nvim_set_hl(ns, 'Normal',
|
||||
\ &termguicolors ? { 'bg': color } : { 'ctermbg': str2nr(color) })
|
||||
call nvim_win_set_hl_ns(s:popup_id, ns)
|
||||
endif
|
||||
endif
|
||||
catch
|
||||
endtry
|
||||
let opts = extend({'relative': 'editor', 'style': 'minimal'}, a:opts)
|
||||
let win = nvim_open_win(buf, v:true, opts)
|
||||
call setwinvar(win, '&winhighlight', 'NormalFloat:'..a:hl)
|
||||
call setwinvar(win, '&colorcolumn', '')
|
||||
return buf
|
||||
endfunction
|
||||
|
||||
function! s:resize_popup() abort
|
||||
if !exists('s:popup_id') || !nvim_win_is_valid(s:popup_id)
|
||||
return
|
||||
endif
|
||||
let opts = s:popup_bounds()
|
||||
let opts = extend({'relative': 'editor'}, opts)
|
||||
call nvim_win_set_config(s:popup_id, opts)
|
||||
endfunction
|
||||
else
|
||||
function! s:create_popup() abort
|
||||
function! s:popup_create(buf)
|
||||
let s:popup_id = popup_create(a:buf, #{zindex: 1000})
|
||||
call s:resize_popup()
|
||||
endfunction
|
||||
function! s:create_popup(hl, opts) abort
|
||||
let s:popup_create = {buf -> popup_create(buf, #{
|
||||
\ line: a:opts.row,
|
||||
\ col: a:opts.col,
|
||||
\ minwidth: a:opts.width,
|
||||
\ maxwidth: a:opts.width,
|
||||
\ minheight: a:opts.height,
|
||||
\ maxheight: a:opts.height,
|
||||
\ zindex: 1000,
|
||||
\ })}
|
||||
autocmd TerminalOpen * ++once call s:popup_create(str2nr(expand('<abuf>')))
|
||||
endfunction
|
||||
|
||||
function! s:resize_popup() abort
|
||||
if !exists('s:popup_id') || empty(popup_getpos(s:popup_id))
|
||||
return
|
||||
endif
|
||||
let opts = s:popup_bounds()
|
||||
call popup_move(s:popup_id, {
|
||||
\ 'line': opts.row,
|
||||
\ 'col': opts.col,
|
||||
\ 'minwidth': opts.width,
|
||||
\ 'maxwidth': opts.width,
|
||||
\ 'minheight': opts.height,
|
||||
\ 'maxheight': opts.height,
|
||||
\ })
|
||||
endfunction
|
||||
endif
|
||||
|
||||
function! s:popup_bounds() abort
|
||||
let opts = s:popup_opts
|
||||
|
||||
let xoffset = get(opts, 'xoffset', 0.5)
|
||||
let yoffset = get(opts, 'yoffset', 0.5)
|
||||
let relative = get(opts, 'relative', 0)
|
||||
function! s:popup(opts) abort
|
||||
let xoffset = get(a:opts, 'xoffset', 0.5)
|
||||
let yoffset = get(a:opts, 'yoffset', 0.5)
|
||||
let relative = get(a:opts, 'relative', 0)
|
||||
|
||||
" Use current window size for positioning relatively positioned popups
|
||||
let columns = relative ? winwidth(0) : &columns
|
||||
let lines = relative ? winheight(0) : (&lines - has('nvim'))
|
||||
|
||||
" Size and position
|
||||
let width = min([max([8, opts.width > 1 ? opts.width : float2nr(columns * opts.width)]), columns])
|
||||
let height = min([max([4, opts.height > 1 ? opts.height : float2nr(lines * opts.height)]), lines])
|
||||
let width = min([max([8, a:opts.width > 1 ? a:opts.width : float2nr(columns * a:opts.width)]), columns])
|
||||
let height = min([max([4, a:opts.height > 1 ? a:opts.height : float2nr(lines * a:opts.height)]), lines])
|
||||
let row = float2nr(yoffset * (lines - height)) + (relative ? win_screenpos(0)[0] - 1 : 0)
|
||||
let col = float2nr(xoffset * (columns - width)) + (relative ? win_screenpos(0)[1] - 1 : 0)
|
||||
|
||||
@@ -1106,17 +1016,9 @@ function! s:popup_bounds() abort
|
||||
let row += !has('nvim')
|
||||
let col += !has('nvim')
|
||||
|
||||
return { 'row': row, 'col': col, 'width': width, 'height': height }
|
||||
endfunction
|
||||
|
||||
function! s:popup(opts) abort
|
||||
let s:popup_opts = a:opts
|
||||
call s:create_popup()
|
||||
|
||||
augroup fzf_popup_resize
|
||||
autocmd!
|
||||
autocmd VimResized * call s:resize_popup()
|
||||
augroup END
|
||||
call s:create_popup('Normal', {
|
||||
\ 'row': row, 'col': col, 'width': width, 'height': height
|
||||
\ })
|
||||
endfunction
|
||||
|
||||
let s:default_action = {
|
||||
@@ -1135,7 +1037,7 @@ endfunction
|
||||
|
||||
function! s:cmd(bang, ...) abort
|
||||
let args = copy(a:000)
|
||||
let opts = { 'options': ['--multi', '--scheme', 'path'] }
|
||||
let opts = { 'options': ['--multi'] }
|
||||
if len(args) && isdirectory(expand(args[-1]))
|
||||
let opts.dir = substitute(substitute(remove(args, -1), '\\\(["'']\)', '\1', 'g'), '[/\\]*$', '/', '')
|
||||
if s:is_win && !&shellslash
|
||||
|
||||
@@ -1,40 +0,0 @@
|
||||
__fzf_defaults() {
|
||||
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
||||
}
|
||||
|
||||
__fzf_exec_awk() {
|
||||
# This function performs `exec awk "$@"` safely by working around awk
|
||||
# compatibility issues.
|
||||
#
|
||||
# To reduce an extra fork, this function performs "exec" so is expected to be
|
||||
# run as the last command in a subshell.
|
||||
if [[ -z ${__fzf_awk-} ]]; then
|
||||
__fzf_awk=awk
|
||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
||||
# Note: Solaris awk at /usr/bin/awk is meant for backward compatibility
|
||||
# with an ancient implementation of 1977 awk in the original UNIX. It
|
||||
# lacks many features of POSIX awk, so it is essentially useless in the
|
||||
# modern point of view. To use a standard-conforming version in Solaris,
|
||||
# one needs to explicitly use /usr/xpg4/bin/awk.
|
||||
__fzf_awk=/usr/xpg4/bin/awk
|
||||
elif command -v mawk > /dev/null 2>&1; then
|
||||
# choose the faster mawk if: it's installed && build date >= 20230322 &&
|
||||
# version >= 1.3.4
|
||||
local n x y z d
|
||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||
[[ $n == mawk ]] &&
|
||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
||||
((d >= 20230302)) 2> /dev/null &&
|
||||
__fzf_awk=mawk
|
||||
fi
|
||||
fi
|
||||
# Note: macOS awk has a quirk that it stops processing at all when it sees
|
||||
# any data not following UTF-8 in the input stream when the current LC_CTYPE
|
||||
# specifies the UTF-8 encoding. To work around this quirk, one needs to
|
||||
# specify LC_ALL=C to change the current encoding to the plain one.
|
||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
||||
}
|
||||
@@ -1,91 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion-examples.nu
|
||||
#
|
||||
# Example custom completers for fzf's Nushell integration.
|
||||
#
|
||||
# To use these, add the desired entries to $env.FZF_COMPLETERS in your
|
||||
# config.nu. Each closure receives two arguments:
|
||||
# - prefix: the text before the trigger (e.g. "vim" in "vim **<TAB>")
|
||||
# - spans: the full command as a list of words (e.g. ["pacman", "-S", "vim**"])
|
||||
#
|
||||
# A closure can return either:
|
||||
# - a list of candidate strings (fzf will use default options), or
|
||||
# - a record with the following optional fields:
|
||||
# candidates: list<string> # candidates to feed to fzf
|
||||
# opts: list<string> # custom fzf options (default: ["-m"])
|
||||
# post: closure (|sel| ...) # post-processing of the selected item
|
||||
#
|
||||
# Simple example:
|
||||
# $env.FZF_COMPLETERS = {
|
||||
# git: {|prefix, spans| ["branch-main", "branch-dev", "branch-feature"]}
|
||||
# }
|
||||
|
||||
# --- pacman / paru ---
|
||||
# Completes package names for pacman and paru.
|
||||
# Uses the spans to distinguish between subcommands:
|
||||
# -S (sync), -F (files): list available packages from repos
|
||||
# -Q (query), -R (remove): list installed packages
|
||||
# Returns a record with custom fzf options for package preview.
|
||||
|
||||
$env.FZF_COMPLETERS = {}
|
||||
|
||||
$env.FZF_COMPLETERS.pacman = {|prefix, spans|
|
||||
let sub = $spans | skip 1 | first
|
||||
let candidates = (if ($sub =~ "-[SF]") {
|
||||
^pacman -Slq | lines
|
||||
} else if ($sub =~ "-[QR]") {
|
||||
^pacman -Qq | lines
|
||||
} else {
|
||||
[]
|
||||
})
|
||||
{
|
||||
candidates: $candidates
|
||||
opts: ["-m", "--preview", "pacman -Si {}", "--prompt", "Package > "]
|
||||
}
|
||||
}
|
||||
|
||||
$env.FZF_COMPLETERS.paru = {|prefix, spans|
|
||||
let sub = $spans | skip 1 | first
|
||||
let candidates = (if ($sub =~ "-[SF]") {
|
||||
^pacman -Slq | lines
|
||||
} else if ($sub =~ "-[QR]") {
|
||||
^pacman -Qq | lines
|
||||
} else {
|
||||
[]
|
||||
})
|
||||
{
|
||||
candidates: $candidates
|
||||
opts: ["-m", "--preview", "pacman -Si {}", "--prompt", "Package > "]
|
||||
}
|
||||
}
|
||||
|
||||
# --- pass (password-store) ---
|
||||
# Completes entry names from ~/.password-store.
|
||||
# Returns a simple list (no custom fzf options needed).
|
||||
|
||||
$env.FZF_COMPLETERS.pass = {|prefix, spans|
|
||||
try {
|
||||
ls ~/.password-store/**/*.gpg
|
||||
| get name
|
||||
| each {$in | str replace -r '^.*?\.password-store/(.*).gpg' '${1}'}
|
||||
} catch {
|
||||
[]
|
||||
}
|
||||
}
|
||||
|
||||
# --- Example with post-processing hook ---
|
||||
# The "post" closure transforms the selected line after fzf returns.
|
||||
# This is useful when the displayed line contains more information than
|
||||
# what you want inserted on the command line (e.g. extracting a PID from
|
||||
# a full "ps" output line).
|
||||
#
|
||||
# $env.FZF_COMPLETERS.mycommand = {|prefix, spans|
|
||||
# {
|
||||
# candidates: (^some-command | lines)
|
||||
# opts: ["+m", "--header-lines=1"]
|
||||
# post: {|selection| $selection | split row ' ' | get 0}
|
||||
# }
|
||||
# }
|
||||
+152
-517
@@ -4,65 +4,40 @@
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.bash
|
||||
#
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_DIR_OPTS (default: empty)
|
||||
# - $FZF_TMUX (default: 0)
|
||||
# - $FZF_TMUX_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
|
||||
if [[ $- =~ i ]]; then
|
||||
|
||||
|
||||
# To use custom commands instead of find, override _fzf_compgen_{path,dir}
|
||||
#
|
||||
# _fzf_compgen_path() {
|
||||
# echo "$1"
|
||||
# command find -L "$1" \
|
||||
# -name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
# -a -not -path "$1" -print 2> /dev/null | command sed 's@^\./@@'
|
||||
# }
|
||||
#
|
||||
# _fzf_compgen_dir() {
|
||||
# command find -L "$1" \
|
||||
# -name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
# -a -not -path "$1" -print 2> /dev/null | command sed 's@^\./@@'
|
||||
# }
|
||||
if ! declare -f _fzf_compgen_path > /dev/null; then
|
||||
_fzf_compgen_path() {
|
||||
echo "$1"
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
if ! declare -f _fzf_compgen_dir > /dev/null; then
|
||||
_fzf_compgen_dir() {
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
###########################################################
|
||||
|
||||
#----BEGIN shfmt
|
||||
#----BEGIN INCLUDE common.sh
|
||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
||||
# the changes. See code comments in "common.sh" for the implementation details.
|
||||
|
||||
__fzf_defaults() {
|
||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
||||
}
|
||||
|
||||
__fzf_exec_awk() {
|
||||
if [[ -z ${__fzf_awk-} ]]; then
|
||||
__fzf_awk=awk
|
||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
||||
__fzf_awk=/usr/xpg4/bin/awk
|
||||
elif command -v mawk > /dev/null 2>&1; then
|
||||
local n x y z d
|
||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||
[[ $n == mawk ]] &&
|
||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
||||
((d >= 20230302)) 2> /dev/null &&
|
||||
__fzf_awk=mawk
|
||||
fi
|
||||
fi
|
||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
||||
}
|
||||
#----END INCLUDE
|
||||
# To redraw line after fzf closes (printf '\e[5n')
|
||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
||||
|
||||
__fzf_comprun() {
|
||||
if [[ "$(type -t _fzf_comprun 2>&1)" == function ]]; then
|
||||
if [[ "$(type -t _fzf_comprun 2>&1)" = function ]]; then
|
||||
_fzf_comprun "$@"
|
||||
elif [[ -n ${TMUX_PANE-} ]] && { [[ ${FZF_TMUX:-0} != 0 ]] || [[ -n ${FZF_TMUX_OPTS-} ]]; }; then
|
||||
elif [[ -n "$TMUX_PANE" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "$FZF_TMUX_OPTS" ]]; }; then
|
||||
shift
|
||||
fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- "$@"
|
||||
else
|
||||
@@ -74,239 +49,84 @@ __fzf_comprun() {
|
||||
__fzf_orig_completion() {
|
||||
local l comp f cmd
|
||||
while read -r l; do
|
||||
if [[ $l =~ ^(.*\ -F)\ *([^ ]*).*\ ([^ ]*)$ ]]; then
|
||||
if [[ "$l" =~ ^(.*\ -F)\ *([^ ]*).*\ ([^ ]*)$ ]]; then
|
||||
comp="${BASH_REMATCH[1]}"
|
||||
f="${BASH_REMATCH[2]}"
|
||||
cmd="${BASH_REMATCH[3]}"
|
||||
[[ $f == _fzf_* ]] && continue
|
||||
builtin printf -v "_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}" "%s" "${comp} %s ${cmd} #${f}"
|
||||
if [[ $l == *" -o nospace "* ]] && [[ ${__fzf_nospace_commands-} != *" $cmd "* ]]; then
|
||||
__fzf_nospace_commands="${__fzf_nospace_commands-} $cmd "
|
||||
[[ "$f" = _fzf_* ]] && continue
|
||||
printf -v "_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}" "%s" "${comp} %s ${cmd} #${f}"
|
||||
if [[ "$l" = *" -o nospace "* ]] && [[ ! "$__fzf_nospace_commands" = *" $cmd "* ]]; then
|
||||
__fzf_nospace_commands="$__fzf_nospace_commands $cmd "
|
||||
fi
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
# @param $1 cmd - Command name for which the original completion is searched
|
||||
# @var[out] REPLY - Original function name is returned
|
||||
__fzf_orig_completion_get_orig_func() {
|
||||
local cmd orig_var orig
|
||||
cmd=$1
|
||||
orig_var="_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}"
|
||||
orig="${!orig_var-}"
|
||||
REPLY="${orig##*#}"
|
||||
[[ $REPLY ]] && type "$REPLY" &> /dev/null
|
||||
}
|
||||
|
||||
# @param $1 cmd - Command name for which the original completion is searched
|
||||
# @param $2 func - Fzf's completion function to replace the original function
|
||||
# @var[out] REPLY - Completion setting is returned as a string to "eval"
|
||||
__fzf_orig_completion_instantiate() {
|
||||
local cmd func orig_var orig
|
||||
cmd=$1
|
||||
func=$2
|
||||
orig_var="_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}"
|
||||
orig="${!orig_var-}"
|
||||
orig="${orig%#*}"
|
||||
[[ $orig == *' %s '* ]] || return 1
|
||||
builtin printf -v REPLY "$orig" "$func"
|
||||
}
|
||||
|
||||
_fzf_opts_completion() {
|
||||
local cur prev opts
|
||||
COMPREPLY=()
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
prev="${COMP_WORDS[COMP_CWORD - 1]}"
|
||||
prev="${COMP_WORDS[COMP_CWORD-1]}"
|
||||
opts="
|
||||
+c --no-color
|
||||
+i --no-ignore-case
|
||||
-x --extended
|
||||
-e --exact
|
||||
--algo
|
||||
-i +i
|
||||
-n --nth
|
||||
--with-nth
|
||||
-d --delimiter
|
||||
+s --no-sort
|
||||
+x --no-extended
|
||||
--accept-nth
|
||||
--ansi
|
||||
--bash
|
||||
--tac
|
||||
--tiebreak
|
||||
-m --multi
|
||||
--no-mouse
|
||||
--bind
|
||||
--border
|
||||
--border-label
|
||||
--border-label-pos
|
||||
--color
|
||||
--cycle
|
||||
--disabled
|
||||
--ellipsis
|
||||
--expect
|
||||
--filepath-word
|
||||
--fish
|
||||
--footer
|
||||
--footer-border
|
||||
--footer-label
|
||||
--footer-label-pos
|
||||
--freeze-left
|
||||
--freeze-right
|
||||
--gap
|
||||
--gap-line
|
||||
--ghost
|
||||
--gutter
|
||||
--gutter-raw
|
||||
--header
|
||||
--header-border
|
||||
--header-first
|
||||
--header-label
|
||||
--header-label-pos
|
||||
--header-lines
|
||||
--header-lines-border
|
||||
--no-hscroll
|
||||
--jump-labels
|
||||
--height
|
||||
--highlight-line
|
||||
--literal
|
||||
--reverse
|
||||
--margin
|
||||
--inline-info
|
||||
--prompt
|
||||
--pointer
|
||||
--marker
|
||||
--header
|
||||
--header-lines
|
||||
--ansi
|
||||
--tabstop
|
||||
--color
|
||||
--no-bold
|
||||
--history
|
||||
--history-size
|
||||
--hscroll-off
|
||||
--id-nth
|
||||
--info
|
||||
--info-command
|
||||
--input-border
|
||||
--input-label
|
||||
--input-label-pos
|
||||
--jump-labels
|
||||
--keep-right
|
||||
--layout
|
||||
--listen
|
||||
--listen-unsafe
|
||||
--list-border
|
||||
--list-label
|
||||
--list-label-pos
|
||||
--literal
|
||||
--man
|
||||
--margin
|
||||
--marker
|
||||
--marker-multi-line
|
||||
--min-height
|
||||
--no-bold
|
||||
--no-hscroll
|
||||
--no-input
|
||||
--no-multi-line
|
||||
--no-scrollbar
|
||||
--no-separator
|
||||
--padding
|
||||
--pointer
|
||||
--preview
|
||||
--preview-border
|
||||
--preview-label
|
||||
--preview-label-pos
|
||||
--preview-window
|
||||
--print-query
|
||||
--print0
|
||||
--prompt
|
||||
--raw
|
||||
--read0
|
||||
--scheme
|
||||
--scroll-off
|
||||
--scrollbar
|
||||
--separator
|
||||
--smart-case
|
||||
--style
|
||||
--sync
|
||||
--tabstop
|
||||
--tac
|
||||
--tail
|
||||
--tiebreak
|
||||
--tmux
|
||||
--track
|
||||
--version
|
||||
--walker
|
||||
--walker-root
|
||||
--walker-skip
|
||||
--with-nth
|
||||
--with-shell
|
||||
--wrap
|
||||
--wrap-sign
|
||||
--preview-wrap-sign
|
||||
--zsh
|
||||
-0 --exit-0
|
||||
-1 --select-1
|
||||
-d --delimiter
|
||||
-e --exact
|
||||
-f --filter
|
||||
-h --help
|
||||
-i --ignore-case
|
||||
-m --multi
|
||||
-n --nth
|
||||
-q --query
|
||||
--"
|
||||
-1 --select-1
|
||||
-0 --exit-0
|
||||
-f --filter
|
||||
--print-query
|
||||
--expect
|
||||
--sync"
|
||||
|
||||
case "${prev}" in
|
||||
--scheme)
|
||||
COMPREPLY=($(compgen -W "default path history" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--tiebreak)
|
||||
COMPREPLY=($(compgen -W "length chunk pathname begin end index" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--color)
|
||||
COMPREPLY=($(compgen -W "dark light base16 16 bw no" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--layout)
|
||||
COMPREPLY=($(compgen -W "default reverse reverse-list" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--info)
|
||||
COMPREPLY=($(compgen -W "default right hidden inline inline-right" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--wrap)
|
||||
COMPREPLY=($(compgen -W "char word" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--style)
|
||||
COMPREPLY=($(compgen -W "default minimal full" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--preview-window)
|
||||
COMPREPLY=($(compgen -W "
|
||||
default
|
||||
hidden
|
||||
nohidden
|
||||
wrap
|
||||
wrap-word
|
||||
nowrap
|
||||
cycle
|
||||
nocycle
|
||||
up top
|
||||
down bottom
|
||||
left
|
||||
right
|
||||
rounded border border-rounded
|
||||
border-line
|
||||
sharp border-sharp
|
||||
border-bold
|
||||
border-block
|
||||
border-thinblock
|
||||
border-double
|
||||
noborder border-none
|
||||
border-horizontal
|
||||
border-vertical
|
||||
border-up border-top
|
||||
border-down border-bottom
|
||||
border-left
|
||||
border-right
|
||||
follow
|
||||
nofollow
|
||||
info
|
||||
noinfo" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--border | --list-border | --header-border | --header-lines-border | --footer-border | --input-border | --preview-border)
|
||||
COMPREPLY=($(compgen -W "line rounded sharp bold block thinblock double horizontal vertical top bottom left right none" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--border-label-pos | --preview-label-pos | --list-label-pos | --header-label-pos | --footer-label-pos | --input-label-pos)
|
||||
COMPREPLY=($(compgen -W "center bottom top" -- "$cur"))
|
||||
return 0
|
||||
;;
|
||||
--tiebreak)
|
||||
COMPREPLY=( $(compgen -W "length begin end index" -- "$cur") )
|
||||
return 0
|
||||
;;
|
||||
--color)
|
||||
COMPREPLY=( $(compgen -W "dark light 16 bw" -- "$cur") )
|
||||
return 0
|
||||
;;
|
||||
--history)
|
||||
COMPREPLY=()
|
||||
return 0
|
||||
;;
|
||||
esac
|
||||
|
||||
if [[ $cur =~ ^-|\+ ]]; then
|
||||
COMPREPLY=($(compgen -W "${opts}" -- "$cur"))
|
||||
if [[ "$cur" =~ ^-|\+ ]]; then
|
||||
COMPREPLY=( $(compgen -W "${opts}" -- "$cur") )
|
||||
return 0
|
||||
fi
|
||||
|
||||
@@ -314,93 +134,63 @@ _fzf_opts_completion() {
|
||||
}
|
||||
|
||||
_fzf_handle_dynamic_completion() {
|
||||
local cmd ret REPLY orig_cmd orig_complete
|
||||
local cmd orig_var orig ret orig_cmd orig_complete
|
||||
cmd="$1"
|
||||
shift
|
||||
orig_cmd="$1"
|
||||
if __fzf_orig_completion_get_orig_func "$cmd"; then
|
||||
"$REPLY" "$@"
|
||||
elif [[ -n ${_fzf_completion_loader-} ]]; then
|
||||
orig_var="_fzf_orig_completion_$cmd"
|
||||
orig="${!orig_var##*#}"
|
||||
if [[ -n "$orig" ]] && type "$orig" > /dev/null 2>&1; then
|
||||
$orig "$@"
|
||||
elif [[ -n "$_fzf_completion_loader" ]]; then
|
||||
orig_complete=$(complete -p "$orig_cmd" 2> /dev/null)
|
||||
$_fzf_completion_loader "$@"
|
||||
_completion_loader "$@"
|
||||
ret=$?
|
||||
# _completion_loader may not have updated completion for the command
|
||||
if [[ "$(complete -p "$orig_cmd" 2> /dev/null)" != "$orig_complete" ]]; then
|
||||
__fzf_orig_completion < <(complete -p "$orig_cmd" 2> /dev/null)
|
||||
__fzf_orig_completion_get_orig_func "$cmd" || ret=1
|
||||
|
||||
# Update orig_complete by _fzf_orig_completion entry
|
||||
[[ $orig_complete =~ ' -F '(_fzf_[^ ]+)' ' ]] &&
|
||||
__fzf_orig_completion_instantiate "$cmd" "${BASH_REMATCH[1]}" &&
|
||||
orig_complete=$REPLY
|
||||
|
||||
if [[ ${__fzf_nospace_commands-} == *" $orig_cmd "* ]]; then
|
||||
if [[ "$__fzf_nospace_commands" = *" $orig_cmd "* ]]; then
|
||||
eval "${orig_complete/ -F / -o nospace -F }"
|
||||
else
|
||||
eval "$orig_complete"
|
||||
fi
|
||||
fi
|
||||
[[ $ret -eq 0 ]] && return 124
|
||||
return $ret
|
||||
fi
|
||||
}
|
||||
|
||||
__fzf_generic_path_completion() {
|
||||
local cur base dir leftover matches trigger cmd
|
||||
cmd="${COMP_WORDS[0]}"
|
||||
if [[ $cmd == \\* ]]; then
|
||||
cmd="${cmd:1}"
|
||||
fi
|
||||
cmd="${COMP_WORDS[0]//[^A-Za-z0-9_=]/_}"
|
||||
COMPREPLY=()
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
[[ $COMP_CWORD -ge 0 ]] && cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ $cur == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ "$cur" == *"$trigger" ]]; then
|
||||
base=${cur:0:${#cur}-${#trigger}}
|
||||
eval "base=$base" 2> /dev/null || return
|
||||
eval "base=$base"
|
||||
|
||||
dir=
|
||||
[[ $base == *"/"* ]] && dir="$base"
|
||||
[[ $base = *"/"* ]] && dir="$base"
|
||||
while true; do
|
||||
if [[ -z $dir ]] || [[ -d $dir ]]; then
|
||||
leftover=${base/#"$dir"/}
|
||||
leftover=${leftover/#\//}
|
||||
[[ -z $dir ]] && dir='.'
|
||||
[[ $dir != "/" ]] && dir="${dir/%\//}"
|
||||
matches=$(
|
||||
export FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-} $2")
|
||||
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
||||
if [[ $1 =~ dir ]]; then
|
||||
eval "rest=(${FZF_COMPLETION_DIR_OPTS-})"
|
||||
else
|
||||
eval "rest=(${FZF_COMPLETION_PATH_OPTS-})"
|
||||
fi
|
||||
if declare -F "$1" > /dev/null; then
|
||||
eval "$1 $(builtin printf %q "$dir")" | __fzf_comprun "$4" -q "$leftover" "${rest[@]}"
|
||||
else
|
||||
if [[ $1 =~ dir ]]; then
|
||||
walker=dir,follow
|
||||
else
|
||||
walker=file,dir,follow,hidden
|
||||
fi
|
||||
__fzf_comprun "$4" -q "$leftover" --walker "$walker" --walker-root="$dir" "${rest[@]}"
|
||||
fi | while read -r item; do
|
||||
builtin printf "%q " "${item%$3}$3"
|
||||
done
|
||||
)
|
||||
if [[ -z "$dir" ]] || [[ -d "$dir" ]]; then
|
||||
leftover=${base/#"$dir"}
|
||||
leftover=${leftover/#\/}
|
||||
[[ -z "$dir" ]] && dir='.'
|
||||
[[ "$dir" != "/" ]] && dir="${dir/%\//}"
|
||||
matches=$(eval "$1 $(printf %q "$dir")" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $2" __fzf_comprun "$4" -q "$leftover" | while read -r item; do
|
||||
printf "%q$3 " "$item"
|
||||
done)
|
||||
matches=${matches% }
|
||||
[[ -z $3 ]] && [[ ${__fzf_nospace_commands-} == *" ${COMP_WORDS[0]} "* ]] && matches="$matches "
|
||||
if [[ -n $matches ]]; then
|
||||
COMPREPLY=("$matches")
|
||||
[[ -z "$3" ]] && [[ "$__fzf_nospace_commands" = *" ${COMP_WORDS[0]} "* ]] && matches="$matches "
|
||||
if [[ -n "$matches" ]]; then
|
||||
COMPREPLY=( "$matches" )
|
||||
else
|
||||
COMPREPLY=("$cur")
|
||||
COMPREPLY=( "$cur" )
|
||||
fi
|
||||
# To redraw line after fzf closes (builtin printf '\e[5n')
|
||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
||||
builtin printf '\e[5n'
|
||||
printf '\e[5n'
|
||||
return 0
|
||||
fi
|
||||
dir=$(command dirname "$dir")
|
||||
[[ $dir =~ /$ ]] || dir="$dir"/
|
||||
dir=$(dirname "$dir")
|
||||
[[ "$dir" =~ /$ ]] || dir="$dir"/
|
||||
done
|
||||
else
|
||||
shift
|
||||
@@ -416,15 +206,15 @@ _fzf_complete() {
|
||||
args=("$@")
|
||||
sep=
|
||||
for i in "${!args[@]}"; do
|
||||
if [[ ${args[$i]} == -- ]]; then
|
||||
if [[ "${args[$i]}" = -- ]]; then
|
||||
sep=$i
|
||||
break
|
||||
fi
|
||||
done
|
||||
if [[ -n $sep ]]; then
|
||||
if [[ -n "$sep" ]]; then
|
||||
str_arg=
|
||||
rest=("${args[@]:$((sep + 1)):${#args[@]}}")
|
||||
args=("${args[@]:0:sep}")
|
||||
args=("${args[@]:0:$sep}")
|
||||
else
|
||||
str_arg=$1
|
||||
args=()
|
||||
@@ -433,28 +223,23 @@ _fzf_complete() {
|
||||
fi
|
||||
|
||||
local cur selected trigger cmd post
|
||||
post="$(caller 0 | __fzf_exec_awk '{print $2}')_post"
|
||||
type -t "$post" > /dev/null 2>&1 || post='command cat'
|
||||
post="$(caller 0 | awk '{print $2}')_post"
|
||||
type -t "$post" > /dev/null 2>&1 || post=cat
|
||||
|
||||
cmd="${COMP_WORDS[0]//[^A-Za-z0-9_=]/_}"
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
cmd="${COMP_WORDS[0]}"
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ $cur == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
||||
if [[ "$cur" == *"$trigger" ]]; then
|
||||
cur=${cur:0:${#cur}-${#trigger}}
|
||||
|
||||
selected=$(
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
||||
FZF_DEFAULT_OPTS_FILE='' \
|
||||
__fzf_comprun "${rest[0]}" "${args[@]}" -q "$cur" | eval "$post" | command tr '\n' ' '
|
||||
)
|
||||
selected=$(FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $str_arg" __fzf_comprun "${rest[0]}" "${args[@]}" -q "$cur" | $post | tr '\n' ' ')
|
||||
selected=${selected% } # Strip trailing space not to repeat "-o nospace"
|
||||
if [[ -n $selected ]]; then
|
||||
if [[ -n "$selected" ]]; then
|
||||
COMPREPLY=("$selected")
|
||||
else
|
||||
COMPREPLY=("$cur")
|
||||
fi
|
||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
||||
builtin printf '\e[5n'
|
||||
printf '\e[5n'
|
||||
return 0
|
||||
else
|
||||
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||
@@ -479,139 +264,33 @@ _fzf_complete_kill() {
|
||||
}
|
||||
|
||||
_fzf_proc_completion() {
|
||||
local transformer
|
||||
transformer='
|
||||
if [[ $FZF_KEY =~ ctrl|alt|shift ]] && [[ -n $FZF_NTH ]]; then
|
||||
nths=( ${FZF_NTH//,/ } )
|
||||
new_nths=()
|
||||
found=0
|
||||
for nth in ${nths[@]}; do
|
||||
if [[ $nth = $FZF_CLICK_HEADER_NTH ]]; then
|
||||
found=1
|
||||
else
|
||||
new_nths+=($nth)
|
||||
fi
|
||||
done
|
||||
[[ $found = 0 ]] && new_nths+=($FZF_CLICK_HEADER_NTH)
|
||||
new_nths=${new_nths[*]}
|
||||
new_nths=${new_nths// /,}
|
||||
echo "change-nth($new_nths)+change-prompt($new_nths> )"
|
||||
else
|
||||
if [[ $FZF_NTH = $FZF_CLICK_HEADER_NTH ]]; then
|
||||
echo "change-nth()+change-prompt(> )"
|
||||
else
|
||||
echo "change-nth($FZF_CLICK_HEADER_NTH)+change-prompt($FZF_CLICK_HEADER_WORD> )"
|
||||
fi
|
||||
fi
|
||||
'
|
||||
_fzf_complete -m --header-lines=1 --no-preview --wrap --color fg:dim,nth:regular \
|
||||
--bind "click-header:transform:$transformer" -- "$@" < <(
|
||||
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
||||
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
||||
command ps --everyone --full --windows # For cygwin
|
||||
)
|
||||
_fzf_complete -m --preview 'echo {}' --preview-window down:3:wrap --min-height 15 -- "$@" < <(
|
||||
command ps -ef | sed 1d
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_proc_completion_post() {
|
||||
__fzf_exec_awk '{print $2}'
|
||||
awk '{print $2}'
|
||||
}
|
||||
|
||||
# To use custom hostname lists, override __fzf_list_hosts.
|
||||
# The function is expected to print hostnames, one per line as well as in the
|
||||
# desired sorting and with any duplicates removed, to standard output.
|
||||
#
|
||||
# e.g.
|
||||
# # Use bash-completions’s _known_hosts_real() for getting the list of hosts
|
||||
# __fzf_list_hosts() {
|
||||
# # Set the local attribute for any non-local variable that is set by _known_hosts_real()
|
||||
# local COMPREPLY=()
|
||||
# _known_hosts_real ''
|
||||
# builtin printf '%s\n' "${COMPREPLY[@]}" | command sort -u --version-sort
|
||||
# }
|
||||
if ! declare -F __fzf_list_hosts > /dev/null; then
|
||||
__fzf_list_hosts() {
|
||||
command sort -u \
|
||||
<(
|
||||
# Note: To make the pathname expansion of "~/.ssh/config.d/*" work
|
||||
# properly, we need to adjust the related shell options. We need to
|
||||
# unset "set -f" and "GLOBIGNORE", which disable the pathname expansion
|
||||
# totally or partially. We need to unset "dotglob" and "nocaseglob" to
|
||||
# avoid matching unwanted files. We need to unset "failglob" to avoid
|
||||
# outputting the error messages to the terminal when no matching is
|
||||
# found. We need to set "nullglob" to avoid attempting to read the
|
||||
# literal filename '~/.ssh/config.d/*' when no matching is found.
|
||||
set +f
|
||||
GLOBIGNORE=
|
||||
shopt -u dotglob nocaseglob failglob
|
||||
shopt -s nullglob
|
||||
|
||||
__fzf_exec_awk '
|
||||
# Note: mawk <= 1.3.3-20090705 does not support the POSIX brackets of
|
||||
# the form [[:blank:]], and Ubuntu 18.04 LTS still uses this
|
||||
# 16-year-old mawk unfortunately. We need to use [ \t] instead.
|
||||
match(tolower($0), /^[ \t]*host(name)?[ \t]*[ \t=]/) {
|
||||
$0 = substr($0, RLENGTH + 1) # Remove "Host(name)?=?"
|
||||
sub(/#.*/, "")
|
||||
for (i = 1; i <= NF; i++)
|
||||
if ($i !~ /[*?%]/)
|
||||
print $i
|
||||
}
|
||||
' ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null
|
||||
) \
|
||||
<(
|
||||
__fzf_exec_awk -F ',' '
|
||||
match($0, /^[][a-zA-Z0-9.,:-]+/) {
|
||||
$0 = substr($0, 1, RLENGTH)
|
||||
gsub(/[][]|:[^,]*/, "")
|
||||
for (i = 1; i <= NF; i++)
|
||||
print $i
|
||||
}
|
||||
' ~/.ssh/known_hosts 2> /dev/null
|
||||
) \
|
||||
<(
|
||||
__fzf_exec_awk '
|
||||
{
|
||||
sub(/#.*/, "")
|
||||
for (i = 2; i <= NF; i++)
|
||||
if ($i != "0.0.0.0")
|
||||
print $i
|
||||
}
|
||||
' /etc/hosts 2> /dev/null
|
||||
)
|
||||
}
|
||||
fi
|
||||
|
||||
_fzf_host_completion() {
|
||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts)
|
||||
}
|
||||
|
||||
# Values for $1 $2 $3 are described here
|
||||
# https://www.gnu.org/software/bash/manual/html_node/Programmable-Completion.html
|
||||
# > the first argument ($1) is the name of the command whose arguments are being completed,
|
||||
# > the second argument ($2) is the word being completed,
|
||||
# > and the third argument ($3) is the word preceding the word being completed on the current command line.
|
||||
_fzf_complete_ssh() {
|
||||
case $3 in
|
||||
-i | -F | -E)
|
||||
_fzf_path_completion "$@"
|
||||
;;
|
||||
*)
|
||||
local user=
|
||||
[[ $2 =~ '@' ]] && user="${2%%@*}@"
|
||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | __fzf_exec_awk -v user="$user" '{print user $0}')
|
||||
;;
|
||||
esac
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?]') \
|
||||
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts | tr ',' '\n' | tr -d '[' | awk '{ print $1 " " $1 }') \
|
||||
<(command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0') |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_var_completion() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
declare -xp | command sed -En 's|^declare [^ ]+ ([^=]+).*|\1|p'
|
||||
declare -xp | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_alias_completion() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
alias | command sed -En 's|^alias ([^=]+).*|\1|p'
|
||||
alias | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
@@ -622,71 +301,36 @@ complete -o default -F _fzf_opts_completion fzf
|
||||
# fzf-tmux specific options (like `-w WIDTH`) are left as a future patch.
|
||||
complete -o default -F _fzf_opts_completion fzf-tmux
|
||||
|
||||
# Default path completion
|
||||
__fzf_default_completion() {
|
||||
__fzf_generic_path_completion _fzf_compgen_path "-m" "" "$@"
|
||||
|
||||
# Dynamic completion loader has updated the completion for the command
|
||||
if [[ $? -eq 124 ]]; then
|
||||
# We trigger _fzf_setup_completion so that fuzzy completion for the command
|
||||
# still works. However, loader can update the completion for multiple
|
||||
# commands at once, and fuzzy completion will no longer work for those
|
||||
# other commands. e.g. pytest -> py.test, pytest-2, pytest-3, etc
|
||||
_fzf_setup_completion path "$1"
|
||||
return 124
|
||||
fi
|
||||
}
|
||||
|
||||
# Set fuzzy path completion as the default completion for all commands.
|
||||
# We can't set up default completion,
|
||||
# 1. if it's already set up by another script
|
||||
# 2. or if the current version of bash doesn't support -D option
|
||||
complete | command grep -q __fzf_default_completion ||
|
||||
complete | command grep -- '-D$' | command grep -qv _comp_complete_load ||
|
||||
complete -D -F __fzf_default_completion -o default -o bashdefault 2> /dev/null
|
||||
|
||||
d_cmds="${FZF_COMPLETION_DIR_COMMANDS-cd pushd rmdir}"
|
||||
|
||||
# NOTE: $FZF_COMPLETION_PATH_COMMANDS and $FZF_COMPLETION_VAR_COMMANDS are
|
||||
# undocumented and subject to change in the future.
|
||||
#
|
||||
# NOTE: Although we have default completion, we still need to set up completion
|
||||
# for each command in case they already have completion set up by another script.
|
||||
a_cmds="${FZF_COMPLETION_PATH_COMMANDS-"
|
||||
awk bat cat code diff diff3
|
||||
emacs emacsclient ex file ftp g++ gcc gvim head hg hx java
|
||||
d_cmds="${FZF_COMPLETION_DIR_COMMANDS:-cd pushd rmdir}"
|
||||
a_cmds="
|
||||
awk cat diff diff3
|
||||
emacs emacsclient ex file ftp g++ gcc gvim head hg java
|
||||
javac ld less more mvim nvim patch perl python ruby
|
||||
sed sftp sort source tail tee uniq vi view vim wc xdg-open
|
||||
basename bunzip2 bzip2 chmod chown curl cp dirname du
|
||||
find git grep gunzip gzip hg jar
|
||||
ln ls mv open rm rsync scp
|
||||
svn tar unzip zip"}"
|
||||
v_cmds="${FZF_COMPLETION_VAR_COMMANDS-export unset printenv}"
|
||||
svn tar unzip zip"
|
||||
|
||||
# Preserve existing completion
|
||||
__fzf_orig_completion < <(complete -p $d_cmds $a_cmds $v_cmds unalias kill ssh 2> /dev/null)
|
||||
__fzf_orig_completion < <(complete -p $d_cmds $a_cmds 2> /dev/null)
|
||||
|
||||
if type _comp_load > /dev/null 2>&1; then
|
||||
# _comp_load was added in bash-completion 2.12 to replace _completion_loader.
|
||||
# We use it without -D option so that it does not use _comp_complete_minimal as the fallback.
|
||||
_fzf_completion_loader=_comp_load
|
||||
elif type __load_completion > /dev/null 2>&1; then
|
||||
# In bash-completion 2.11, _completion_loader internally calls __load_completion
|
||||
# and if it returns a non-zero status, it sets the default 'minimal' completion.
|
||||
_fzf_completion_loader=__load_completion
|
||||
elif type _completion_loader > /dev/null 2>&1; then
|
||||
_fzf_completion_loader=_completion_loader
|
||||
if type _completion_loader > /dev/null 2>&1; then
|
||||
_fzf_completion_loader=1
|
||||
fi
|
||||
|
||||
__fzf_defc() {
|
||||
local cmd func opts REPLY
|
||||
local cmd func opts orig_var orig def
|
||||
cmd="$1"
|
||||
func="$2"
|
||||
opts="$3"
|
||||
if __fzf_orig_completion_instantiate "$cmd" "$func"; then
|
||||
eval "$REPLY"
|
||||
orig_var="_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}"
|
||||
orig="${!orig_var}"
|
||||
if [[ -n "$orig" ]]; then
|
||||
printf -v def "$orig" "$func"
|
||||
eval "$def"
|
||||
else
|
||||
eval "complete -F \"$func\" $opts \"$cmd\""
|
||||
complete -F "$func" $opts "$cmd"
|
||||
fi
|
||||
}
|
||||
|
||||
@@ -697,24 +341,10 @@ done
|
||||
|
||||
# Directory
|
||||
for cmd in $d_cmds; do
|
||||
__fzf_defc "$cmd" _fzf_dir_completion "-o bashdefault -o nospace -o dirnames"
|
||||
__fzf_defc "$cmd" _fzf_dir_completion "-o nospace -o dirnames"
|
||||
done
|
||||
|
||||
# Variables
|
||||
for cmd in $v_cmds; do
|
||||
__fzf_defc "$cmd" _fzf_var_completion "-o default -o nospace -v"
|
||||
done
|
||||
|
||||
# Aliases
|
||||
__fzf_defc unalias _fzf_alias_completion "-a"
|
||||
|
||||
# Processes
|
||||
__fzf_defc kill _fzf_proc_completion "-o default -o bashdefault"
|
||||
|
||||
# ssh
|
||||
__fzf_defc ssh _fzf_complete_ssh "-o default -o bashdefault"
|
||||
|
||||
unset cmd d_cmds a_cmds v_cmds
|
||||
unset cmd d_cmds a_cmds
|
||||
|
||||
_fzf_setup_completion() {
|
||||
local kind fn cmd
|
||||
@@ -728,13 +358,18 @@ _fzf_setup_completion() {
|
||||
__fzf_orig_completion < <(complete -p "$@" 2> /dev/null)
|
||||
for cmd in "$@"; do
|
||||
case "$kind" in
|
||||
dir) __fzf_defc "$cmd" "$fn" "-o nospace -o dirnames" ;;
|
||||
var) __fzf_defc "$cmd" "$fn" "-o default -o nospace -v" ;;
|
||||
dir) __fzf_defc "$cmd" "$fn" "-o nospace -o dirnames" ;;
|
||||
var) __fzf_defc "$cmd" "$fn" "-o default -o nospace -v" ;;
|
||||
alias) __fzf_defc "$cmd" "$fn" "-a" ;;
|
||||
*) __fzf_defc "$cmd" "$fn" "-o default -o bashdefault" ;;
|
||||
*) __fzf_defc "$cmd" "$fn" "-o default -o bashdefault" ;;
|
||||
esac
|
||||
done
|
||||
}
|
||||
#----END shfmt
|
||||
|
||||
# Environment variables / Aliases / Hosts / Process
|
||||
_fzf_setup_completion 'var' export unset
|
||||
_fzf_setup_completion 'alias' unalias
|
||||
_fzf_setup_completion 'host' ssh telnet
|
||||
_fzf_setup_completion 'proc' kill
|
||||
|
||||
fi
|
||||
|
||||
@@ -1,169 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.fish
|
||||
#
|
||||
# - $FZF_COMPLETION_OPTS
|
||||
# - $FZF_EXPANSION_OPTS
|
||||
|
||||
# The oldest supported fish version is 3.4.0. For this message being able to be
|
||||
# displayed on older versions, the command substitution syntax $() should not
|
||||
# be used anywhere in the script, otherwise the source command will fail.
|
||||
if string match -qr -- '^[12]\\.|^3\\.[0-3]' $version
|
||||
echo "fzf completion script requires fish version 3.4.0 or newer." >&2
|
||||
return 1
|
||||
else if not command -q fzf
|
||||
echo "fzf was not found in path." >&2
|
||||
return 1
|
||||
end
|
||||
|
||||
function fzf_complete -w fzf -d 'fzf command completion and wildcard expansion search'
|
||||
# Restore the default shift-tab behavior on tab completions
|
||||
if commandline --paging-mode
|
||||
commandline -f complete-and-search
|
||||
return
|
||||
end
|
||||
|
||||
# Remove any trailing unescaped backslash from token and update command line
|
||||
set -l -- token (string replace -r -- '(?<!\\\\)(?:\\\\\\\\)*\\K\\\\$' '' (commandline -t | string collect) | string collect)
|
||||
commandline -rt -- $token
|
||||
|
||||
# Remove any line breaks from token
|
||||
set -- token (string replace -ra -- '\\\\\\n' '' $token | string collect)
|
||||
|
||||
# regex: Match token with unescaped/unquoted glob character
|
||||
set -l -- r_glob '^(?:[^\'"\\\\*]|\\\\[\\S\\s]|\'(?:\\\\[\\S\\s]|[^\'\\\\])*\'|"(?:\\\\[\\S\\s]|[^"\\\\])*")*\\*[\\S\\s]*$'
|
||||
|
||||
# regex: Match any unbalanced quote character
|
||||
set -l -- r_quote '^(?>(?:\\\\[\\s\\S]|"(?:[^"\\\\]|\\\\[\\s\\S])*"|\'(?:[^\'\\\\]|\\\\[\\s\\S])*\'|[^\'"\\\\]+)*)\\K[\'"]'
|
||||
|
||||
# The expansion pattern is the token with any open quote closed, or is empty.
|
||||
set -l -- glob_pattern (string match -r -- $r_glob $token | string collect)(string match -r -- $r_quote $token | string collect -a)
|
||||
|
||||
set -l -- cl_tokenize_opt '--tokens-expanded'
|
||||
string match -q -- '3.*' $version
|
||||
and set -- cl_tokenize_opt '--tokenize'
|
||||
|
||||
# Set command line tokens without any leading variable definitions or launcher
|
||||
# commands (including their options, but not any option arguments).
|
||||
set -l -- r_cmd '^(?:(?:builtin|command|doas|env|sudo|\\w+=\\S*|-\\S+)\\s+)*\\K[\\s\\S]+'
|
||||
set -l -- cmd (commandline $cl_tokenize_opt --input=(commandline -pc | string match -r $r_cmd))
|
||||
test -z "$token"
|
||||
and set -a -- cmd ''
|
||||
|
||||
# Set fzf options
|
||||
test -z "$FZF_TMUX_HEIGHT"
|
||||
and set -l -- FZF_TMUX_HEIGHT 40%
|
||||
|
||||
set -lax -- FZF_DEFAULT_OPTS \
|
||||
"--height=$FZF_TMUX_HEIGHT --min-height=20+ --bind=ctrl-z:ignore" \
|
||||
(test -r "$FZF_DEFAULT_OPTS_FILE"; and string join -- ' ' <$FZF_DEFAULT_OPTS_FILE) \
|
||||
$FZF_DEFAULT_OPTS '--bind=alt-r:toggle-raw --multi --wrap=word --reverse' \
|
||||
(if test -n "$glob_pattern"; string collect -- $FZF_EXPANSION_OPTS; else;
|
||||
string collect -- $FZF_COMPLETION_OPTS; end; string escape -n -- $argv) \
|
||||
--with-shell=(status fish-path)\\ -c
|
||||
|
||||
set -lx FZF_DEFAULT_OPTS_FILE
|
||||
|
||||
set -l -- fzf_cmd fzf
|
||||
test "$FZF_TMUX" = 1
|
||||
and set -- fzf_cmd fzf-tmux $FZF_TMUX_OPTS -d$FZF_TMUX_HEIGHT --
|
||||
|
||||
set -l result
|
||||
|
||||
# Get the completion list from stdin when it's not a tty
|
||||
if not isatty stdin
|
||||
set -l -- custom_post_func _fzf_post_complete_$cmd[1]
|
||||
functions -q $custom_post_func
|
||||
or set -- custom_post_func _fzf_complete_$cmd[1]_post
|
||||
|
||||
if functions -q $custom_post_func
|
||||
$fzf_cmd | $custom_post_func $cmd | while read -l r; set -a -- result $r; end
|
||||
else if string match -q -- '*--print0*' "$FZF_DEFAULT_OPTS"
|
||||
$fzf_cmd | while read -lz r; set -a -- result $r; end
|
||||
else
|
||||
$fzf_cmd | while read -l r; set -a -- result $r; end
|
||||
end
|
||||
|
||||
# Wildcard expansion
|
||||
else if test -n "$glob_pattern"
|
||||
# Set the command to be run by fzf, so there is a visual indicator and an
|
||||
# easy way to abort on long recursive searches.
|
||||
set -lx -- FZF_DEFAULT_COMMAND "for i in $glob_pattern;" \
|
||||
'test -d "$i"; and string match -qv -- "*/" $i; and set -- i $i/;' \
|
||||
'string join0 -- $i; end'
|
||||
|
||||
set -- result (string escape -n -- ($fzf_cmd --read0 --print0 --scheme=path --no-multi-line | string split0))
|
||||
|
||||
# Command completion
|
||||
else
|
||||
# Call custom function if defined
|
||||
set -l -- custom_func _fzf_complete_$cmd[1]
|
||||
if functions -q $custom_func; and not set -q __fzf_no_custom_complete
|
||||
set -lx __fzf_no_custom_complete
|
||||
$custom_func $cmd
|
||||
return
|
||||
end
|
||||
|
||||
# Workaround for complete not having newlines in results
|
||||
if string match -qr -- '\\n' $token
|
||||
set -- token (string replace -ra -- '(?<!\\\\)(?:\\\\\\\\)*\\K\\\\\$' '\\\\\\\\\$' $token | string collect)
|
||||
set -- token (string unescape -- $token | string collect)
|
||||
set -- token (string replace -ra -- '\\n' '\\\\n' $token | string collect)
|
||||
end
|
||||
|
||||
set -- list (complete -C --escape -- (string join -- ' ' (commandline -pc $cl_tokenize_opt) $token | string collect))
|
||||
if test -n "$list"
|
||||
# Get the initial tabstop value
|
||||
if set -l -- tabstop (string match -rga -- '--tabstop[= ](?:0*)([1-9]\\d+|[4-9])' "$FZF_DEFAULT_OPTS")[-1]
|
||||
set -- tabstop (math $tabstop - 4)
|
||||
else
|
||||
set -- tabstop 4
|
||||
end
|
||||
|
||||
# Determine the tabstop length for description alignment
|
||||
set -l -- max_columns (math $COLUMNS - 40)
|
||||
for i in $list[1..500]
|
||||
set -l -- item (string split -f 1 -- \t $i)
|
||||
and set -l -- len (string length -V -- $item)
|
||||
and test "$len" -gt "$tabstop" -a "$len" -lt "$max_columns"
|
||||
and set -- tabstop $len
|
||||
end
|
||||
set -- tabstop (math $tabstop + 4)
|
||||
|
||||
set -- result (string collect -- $list | $fzf_cmd --delimiter="\t" --tabstop=$tabstop --wrap-sign=\t"↳ " --accept-nth=1)
|
||||
end
|
||||
end
|
||||
|
||||
# Update command line
|
||||
if test -n "$result"
|
||||
# No extra space after single selection that ends with path separator
|
||||
set -l -- tail ' '
|
||||
test (count $result) -eq 1
|
||||
and string match -q -- '*/' "$result"
|
||||
and set -- tail ''
|
||||
|
||||
commandline -rt -- (string join -- ' ' $result)$tail
|
||||
end
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function _fzf_complete
|
||||
set -l fzf_args
|
||||
for i in $argv
|
||||
string match -q -- '--' $i; and break
|
||||
set -a -- fzf_args $i
|
||||
end
|
||||
fzf_complete $fzf_args
|
||||
end
|
||||
|
||||
# Bind to shift-tab
|
||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
||||
bind shift-tab fzf_complete
|
||||
bind -M insert shift-tab fzf_complete
|
||||
else
|
||||
bind -k btab fzf_complete
|
||||
bind -M insert -k btab fzf_complete
|
||||
end
|
||||
@@ -1,489 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.nu
|
||||
|
||||
|
||||
# An implementation of completion.nu
|
||||
# This loads FZF as a Nushell External Completer
|
||||
# https://www.nushell.sh/cookbook/external_completers.html
|
||||
|
||||
|
||||
# --- Default Environment Variables ---
|
||||
# These can be overridden in your config.nu or environment.
|
||||
# Example: $env.FZF_COMPLETION_TRIGGER = "!<TAB>"
|
||||
|
||||
# - $env.FZF_TMUX (default: 0)
|
||||
# - $env.FZF_TMUX_OPTS (default: empty)
|
||||
# - $env.FZF_TMUX_HEIGHT (default: 40%)
|
||||
# - $env.FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $env.FZF_COMPLETION_OPTS (default: empty)
|
||||
# - $env.FZF_COMPLETION_PATH_OPTS (default: empty)
|
||||
# - $env.FZF_COMPLETION_DIR_OPTS (default: empty)
|
||||
|
||||
|
||||
|
||||
$env.FZF_COMPLETION_TRIGGER = $env.FZF_COMPLETION_TRIGGER? | default '**'
|
||||
|
||||
# Options for fzf completion in general. e.g. '--border'
|
||||
$env.FZF_COMPLETION_OPTS = $env.FZF_COMPLETION_OPTS? | default ''
|
||||
|
||||
# Options specific to path completion. e.g. '--extended'
|
||||
$env.FZF_COMPLETION_PATH_OPTS = $env.FZF_COMPLETION_PATH_OPTS? | default ''
|
||||
# Options specific to directory completion. e.g. '--extended'
|
||||
$env.FZF_COMPLETION_DIR_OPTS = $env.FZF_COMPLETION_DIR_OPTS? | default ''
|
||||
|
||||
$env.FZF_COMPLETION_DIR_COMMANDS = $env.FZF_COMPLETION_DIR_COMMANDS? | default ['cd', 'pushd', 'rmdir']
|
||||
|
||||
# --- Helper Functions ---
|
||||
|
||||
# Helper to build default fzf options list
|
||||
def __fzf_defaults_completion [prepend: string, append: string]: nothing -> string {
|
||||
let base = $"--height ($env.FZF_TMUX_HEIGHT? | default '40%') --min-height 20+ --bind=ctrl-z:ignore ($prepend)"
|
||||
let opts_file = if ($env.FZF_DEFAULT_OPTS_FILE? | default '' | is-not-empty) {
|
||||
try { open --raw ($env.FZF_DEFAULT_OPTS_FILE) | str trim } catch { '' }
|
||||
} else {
|
||||
''
|
||||
}
|
||||
let default_opts = $env.FZF_DEFAULT_OPTS? | default ''
|
||||
$"($base) ($opts_file) ($default_opts) ($append)" | str trim
|
||||
}
|
||||
|
||||
# Wrapper for running fzf or fzf-tmux
|
||||
def __fzf_comprun [ context_name: string # e.g., "fzf-completion" , "fzf-helper" - mainly for potential debugging
|
||||
, query: string # The initial query string for fzf
|
||||
, fzf_opts_arg: list<string> # Remaining options for fzf/fzf-tmux
|
||||
] {
|
||||
let stdin_content = try {
|
||||
# Collect stdin into a single string. Adjust if structured data is expected.
|
||||
$in | into string
|
||||
} catch {
|
||||
null # Set to null if there's no stdin or an error occurs reading it
|
||||
}
|
||||
|
||||
let fzf_default_opts = (__fzf_defaults_completion "" ($env.FZF_COMPLETION_OPTS | default ''))
|
||||
let fzf_prefinal_opt = ['--query', $query, '--reverse'] | append $fzf_opts_arg
|
||||
|
||||
# Get the configured height, defaulting to '40%'
|
||||
let height_opt = $env.FZF_TMUX_HEIGHT? | default '40%'
|
||||
|
||||
# Determine if fzf should generate its own candidates via walker
|
||||
let has_walker = ($fzf_prefinal_opt | find '--walker' | is-not-empty)
|
||||
|
||||
# Check for custom comprun function (Nu equivalent)
|
||||
if (which _fzf_comprun | is-not-empty) {
|
||||
# Note: Nushell doesn't have a direct equivalent to Zsh/Bash `type -t _fzf_comprun`.
|
||||
# This check assumes a user might define a custom command named `_fzf_comprun`.
|
||||
_fzf_comprun $context_name $query ...$fzf_prefinal_opt # Pass args correctly to custom function
|
||||
} else if ($env.TMUX_PANE? | default '' | into string | is-not-empty) and (($env.FZF_TMUX? | default 0) != 0 or ($env.FZF_TMUX_OPTS? | is-not-empty)) {
|
||||
# Running inside tmux, use fzf-tmux
|
||||
let final_fzf_opts = if ($env.FZF_TMUX_OPTS? | is-not-empty) {
|
||||
$env.FZF_TMUX_OPTS | split row ' ' | append ['--'] | append $fzf_prefinal_opt
|
||||
} else {
|
||||
# Use the default -d option with the configured height for fzf-tmux
|
||||
['-d', $height_opt, '--'] | append $fzf_prefinal_opt
|
||||
}
|
||||
|
||||
if $has_walker or ($stdin_content == null) {
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf-tmux ...$final_fzf_opts }
|
||||
} else {
|
||||
$stdin_content | with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf-tmux ...$final_fzf_opts }
|
||||
}
|
||||
|
||||
} else {
|
||||
# Not in tmux or not configured for fzf-tmux, use fzf directly
|
||||
let final_fzf_opts = $fzf_prefinal_opt
|
||||
|
||||
if $has_walker or ($stdin_content == null) {
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf ...$final_fzf_opts }
|
||||
} else {
|
||||
$stdin_content | with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf ...$final_fzf_opts }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# Generate host list for ssh/telnet
|
||||
def __fzf_list_hosts [] {
|
||||
# Translate the Zsh pipeline using Nu commands and external tools
|
||||
let ssh_configs = try { open ~/.ssh/config | lines } catch { [] }
|
||||
let ssh_configs_d = try { open ~/.ssh/config.d/* | lines } catch { [] }
|
||||
let ssh_config_global = try { open /etc/ssh/ssh_config | lines } catch { [] }
|
||||
let known_hosts = try { open ~/.ssh/known_hosts | lines } catch { [] }
|
||||
let hosts_file = try { open /etc/hosts | lines } catch { [] }
|
||||
|
||||
[
|
||||
(
|
||||
# Process ssh config files
|
||||
$ssh_configs | append $ssh_configs_d | append $ssh_config_global
|
||||
| where {|it| ($it | str downcase | str starts-with 'host') or ($it | str downcase | str starts-with 'hostname') }
|
||||
| parse --regex '^\s*host(?:name)?\s+(?<hosts>.+)' # Extract hosts after keyword
|
||||
| default { hosts: null } # Handle lines that don't match regex
|
||||
| get hosts
|
||||
| where {|it| $it != null }
|
||||
| split row ' '
|
||||
| where {|it| not ($it =~ '[*?%]') } # Exclude patterns containing *, ?, or %
|
||||
)
|
||||
(
|
||||
# Process known_hosts file
|
||||
$known_hosts | parse --regex '^(?:\[)?(?<hosts>[a-z0-9.,:_-]+)' # Extract hostnames (possibly in [], possibly comma-separated) - added underscore
|
||||
| default { hosts: null }
|
||||
| get hosts
|
||||
| where {|it| $it != null }
|
||||
| each { |it| $it | split row ',' } # Split comma-separated hosts if any
|
||||
| flatten
|
||||
)
|
||||
(
|
||||
# Process /etc/hosts file
|
||||
$hosts_file | where { |it| not ($it | str starts-with '#') } # Ignore comments
|
||||
| where { |it| not ($it | str trim | is-empty) } # Ignore empty lines
|
||||
| where { |it| not ($it | str contains '0.0.0.0') } # Ignore 0.0.0.0
|
||||
| str replace --regex '#.*$' '' # Remove trailing comments
|
||||
| parse --regex '^\s*\S+\s+(?<hosts>.+)' # Extract hosts part (after IP)
|
||||
| default { hosts: null }
|
||||
| get hosts
|
||||
| where {|it| $it != null }
|
||||
| split row ' ' # Split multiple hosts on the same line
|
||||
)
|
||||
]
|
||||
| flatten # Combine all lists into a single stream
|
||||
| where {|it| not ($it | is-empty) } # Remove empty entries
|
||||
| sort | uniq # Sort and remove duplicates
|
||||
}
|
||||
|
||||
|
||||
# Base function for path/directory completion
|
||||
def __fzf_generic_path_completion [ prefix: string # The text before the trigger
|
||||
, fzf_opts_arg: list<string> # Extra options for fzf
|
||||
, suffix: string # Suffix to add to selection (e.g. , "/")
|
||||
] {
|
||||
# --- Determine walker root and initial query from the prefix ---
|
||||
|
||||
mut walker_root = "."
|
||||
mut initial_query = ""
|
||||
|
||||
if ($prefix | is-empty) {
|
||||
# Case: "**"
|
||||
$walker_root = "."
|
||||
$initial_query = ""
|
||||
} else if ($prefix | str contains (char separator)) {
|
||||
# Case: "dir/subdir/partial**" or "dir/**"
|
||||
$walker_root = $prefix | path dirname
|
||||
$initial_query = $prefix | path basename
|
||||
# Handle edge case where prefix ends with separator, e.g., "dir/"
|
||||
if ($prefix | str ends-with (char separator)) {
|
||||
# Remove trailing separator to get the intended directory
|
||||
$walker_root = $prefix | str substring 0..-2
|
||||
$initial_query = ""
|
||||
}
|
||||
# Ensure walker_root isn't empty if prefix was like "/file**"
|
||||
# or if path dirname returned empty string for some reason (e.g. prefix="file/")
|
||||
if ($walker_root | is-empty) {
|
||||
if ($prefix | str starts-with (char separator)) {
|
||||
$walker_root = (char separator)
|
||||
} else if ($prefix | str ends-with (char separator)) {
|
||||
$walker_root = $prefix | str substring 0..-2
|
||||
} else { $walker_root = "." } # Fallback if dirname weirdly fails
|
||||
}
|
||||
} else {
|
||||
# Case: "partial**" (no slashes)
|
||||
$walker_root = "."
|
||||
$initial_query = $prefix
|
||||
}
|
||||
|
||||
# --- Prepare FZF options ---
|
||||
let completion_type_opts = if $suffix == '/' {
|
||||
$env.FZF_COMPLETION_DIR_OPTS? | default '' | split row ' ' | where {not ($in | is-empty)}
|
||||
} else {
|
||||
$env.FZF_COMPLETION_PATH_OPTS? | default '' | split row ' ' | where {not ($in | is-empty)}
|
||||
}
|
||||
|
||||
let walker_type = if ($suffix == '/') {
|
||||
"dir,follow"
|
||||
} else {
|
||||
"file,dir,follow,hidden"
|
||||
}
|
||||
# Expand tilde so fzf receives a valid absolute path as walker-root
|
||||
let needs_tilde_rewrite = ($walker_root | str starts-with '~')
|
||||
let walker_root_expanded = ($walker_root | path expand)
|
||||
|
||||
# Use the 'walker_root' calculated at the beginning
|
||||
let fzf_all_opts = ["--scheme=path", "--walker", $walker_type, "--walker-root", $walker_root_expanded] | append $fzf_opts_arg
|
||||
| append $completion_type_opts
|
||||
|
||||
# Call FZF run
|
||||
let fzf_selection = ( __fzf_comprun "fzf-path-completion-walker" $initial_query $fzf_all_opts ) | str trim
|
||||
|
||||
|
||||
# --- Return Result ---
|
||||
if ($fzf_selection | is-not-empty) {
|
||||
# Restore tilde prefix if the user originally typed ~/
|
||||
let home = $nu.home-dir | path expand
|
||||
let result = if $needs_tilde_rewrite {
|
||||
$fzf_selection | lines | each {|line| $line | str replace $home '~' } | str join ' '
|
||||
} else {
|
||||
$fzf_selection | lines | str join ' '
|
||||
}
|
||||
[$result]
|
||||
} else {
|
||||
[]
|
||||
}
|
||||
}
|
||||
|
||||
# Specific path completion wrapper
|
||||
def _fzf_path_completion [prefix: string] {
|
||||
# Zsh args: base, lbuf, _fzf_compgen_path, "-m", "", " "
|
||||
# Nu: prefix, empty command name (use find), ["-m"], "", " "
|
||||
__fzf_generic_path_completion $prefix ["-m"] ""
|
||||
}
|
||||
|
||||
# General completion helper for commands that feed a list to fzf
|
||||
# This is called by ssh, kill, and user-defined completers.
|
||||
def _fzf_complete [ query: string # The initial query string for fzf
|
||||
, data_gen_closure: closure # Closure that generates candidates
|
||||
, fzf_opts_arg: list<string> # Extra options for fzf (like -m, +m)
|
||||
, --post_process_closure: closure # Closure to process the selected item (optional)
|
||||
] {
|
||||
# Generate candidates using the provided command
|
||||
let candidates = try {
|
||||
do $data_gen_closure
|
||||
} catch {
|
||||
# Capture the actual error object provided by the catch block
|
||||
let actual_error = $in
|
||||
# Print a more informative error message including the actual error details
|
||||
print -e $"Error executing data_gen closure. Closure code: ($data_gen_closure). Actual error: ($actual_error)"
|
||||
[]
|
||||
}
|
||||
|
||||
# Run fzf and get selection
|
||||
let fzf_selection = $candidates | to text
|
||||
| __fzf_comprun "fzf-helper" $query $fzf_opts_arg
|
||||
| str trim # Trim potential trailing newline from fzf
|
||||
|
||||
# Apply post-processing if closure provided and selection is not empty
|
||||
let processed_selection = if ($fzf_selection | is-not-empty) and ($post_process_closure | is-not-empty) {
|
||||
# Call the post-processing closure with the selection
|
||||
try {
|
||||
do $post_process_closure $fzf_selection
|
||||
} catch {
|
||||
print -e $"Error executing post_process closure: ($post_process_closure)"
|
||||
$fzf_selection # Return original selection on error
|
||||
}
|
||||
} else {
|
||||
$fzf_selection
|
||||
}
|
||||
|
||||
if not ($processed_selection | is-empty) {
|
||||
[($processed_selection | lines | str join ' ')]
|
||||
} else {
|
||||
[]
|
||||
}
|
||||
}
|
||||
|
||||
# SSH/Telnet completion
|
||||
def _fzf_complete_ssh [ prefix: string
|
||||
, input_line_before_trigger: string
|
||||
] {
|
||||
let words = ($input_line_before_trigger | split row ' ')
|
||||
let word_count = $words | length
|
||||
|
||||
# Find the index of the word being completed (which is the prefix)
|
||||
# If prefix is empty, completion happens after a space, index is word_count
|
||||
# If prefix is not empty, it's the last word, index is word_count - 1
|
||||
let completion_index = if ($prefix | is-empty) { $word_count } else { $word_count - 1 }
|
||||
|
||||
mut handled = false
|
||||
mut completion_result = [] # List of completion strings to return
|
||||
|
||||
# Check for -i, -F, -E flags immediately preceding the cursor position
|
||||
if $completion_index > 0 {
|
||||
let prev_arg = ($words | get ($completion_index - 1))
|
||||
if ($prev_arg in ['-i', '-F', '-E']) {
|
||||
$handled = true
|
||||
# Call path completion with the current prefix
|
||||
$completion_result = (_fzf_path_completion $prefix)
|
||||
}
|
||||
}
|
||||
|
||||
# If not handled by path completion, do host completion
|
||||
if not $handled {
|
||||
let user_part = if ($prefix | str contains "@") { ($prefix | split row "@" | first) + "@" } else { "" }
|
||||
# The part after '@' (or the whole prefix if no '@') is the initial query for fzf
|
||||
let query = if ($prefix | str contains "@") { $prefix | split row "@" | last } else { $prefix }
|
||||
|
||||
let host_candidates_gen = {||
|
||||
__fzf_list_hosts
|
||||
| each {|host_item| $user_part + $host_item } # Prepend user@ if present in prefix
|
||||
}
|
||||
|
||||
# Zsh options: +m -- ; Nu: pass ["+m"]
|
||||
# Pass the host part of the prefix to _fzf_complete for the initial query
|
||||
let selected_host = (_fzf_complete $query $host_candidates_gen ["+m"]) # Pass host_prefix here
|
||||
if not ($selected_host | is-empty) {
|
||||
$completion_result = $selected_host # _fzf_complete returns a list
|
||||
}
|
||||
}
|
||||
|
||||
$completion_result
|
||||
}
|
||||
|
||||
# Kill completion post-processor (extracts PID)
|
||||
def _fzf_complete_kill_post_get_pid [selected_line: string] {
|
||||
# Assuming standard ps output where PID is the second column
|
||||
$selected_line | lines | each { $in | from ssv --noheaders | get 0.column1 } | to text
|
||||
}
|
||||
|
||||
# Kill completion to get process PID
|
||||
def _fzf_complete_kill [query: string] {
|
||||
let ps_gen_closure = {|| # Define ps generator as a closure
|
||||
# Try standard ps, then busybox, then cygwin format approximation
|
||||
# Use `^ps` to ensure external command execution
|
||||
try {
|
||||
^ps -eo user,pid,ppid,start,time,command | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
||||
} catch {
|
||||
try {
|
||||
^ps -eo user,pid,ppid,time,args | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
||||
} catch {
|
||||
try {
|
||||
^ps --everyone --full --windows | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
||||
} catch {
|
||||
print -e "Error: ps command failed."
|
||||
[] # Return empty list on failure
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# Note: Complex Zsh FZF bindings for kill (click-header transformer) are omitted for simplicity.
|
||||
# Users can set custom bindings via FZF_DEFAULT_OPTS if needed.
|
||||
let kill_post_closure = {|selected_line| _fzf_complete_kill_post_get_pid $selected_line }
|
||||
|
||||
let fzf_opts = ["-m", "--header-lines=1", "--no-preview", "--wrap", "--color", "fg:dim,nth:regular"]
|
||||
|
||||
_fzf_complete $query $ps_gen_closure $fzf_opts --post_process_closure $kill_post_closure
|
||||
}
|
||||
|
||||
|
||||
# --- Main FZF External Completer ---
|
||||
|
||||
# This function is registered with Nushell's external completion system.
|
||||
# It gets called when Tab is pressed.
|
||||
let fzf_external_completer = {|spans|
|
||||
let trigger: string = $env.FZF_COMPLETION_TRIGGER? | default '**'
|
||||
|
||||
if ($trigger | is-empty) { return null } # Cannot work with empty trigger
|
||||
if (($spans | length ) == 0) { return null } # Nothing to complete
|
||||
|
||||
let last_span = $spans | last
|
||||
|
||||
if ($last_span | str ends-with $trigger) {
|
||||
# --- Trigger Found ---
|
||||
|
||||
# Skip sudo to determine the actual command
|
||||
let cmd_spans = if ($spans | first) == "sudo" { $spans | skip 1 } else { $spans }
|
||||
let cmd_word = ($cmd_spans | first | default "")
|
||||
|
||||
# Calculate the prefix (part before the trigger in the last span)
|
||||
let prefix = $last_span | str substring 0..(-1 * ($trigger | str length) - 1)
|
||||
|
||||
# Reconstruct the line content *before* the trigger for context
|
||||
# This is an approximation based on spans
|
||||
let line_without_trigger = $cmd_spans | take (($cmd_spans | length) - 1) | append $prefix | str join ' '
|
||||
|
||||
# --- Dispatch to Completer ---
|
||||
mut completion_results = [] # Will hold the list of strings from the completer
|
||||
|
||||
# Check for user-defined completer in $env.FZF_COMPLETERS first.
|
||||
# Users can define custom completers in their config.nu as a record of closures:
|
||||
# $env.FZF_COMPLETERS = { git: {|prefix, spans| ... }, docker: {|prefix, spans| ... } }
|
||||
# Each closure receives the prefix (text before the trigger) and the full
|
||||
# command spans (e.g. ["pacman", "-S", "vim**"]), and should return either:
|
||||
# - a list of candidate strings, or
|
||||
# - a record { candidates: [...], opts: [...], post: {|sel| ...} } to pass
|
||||
# custom fzf options and/or a post-processing closure.
|
||||
# See shell/completion-examples.nu for examples.
|
||||
let user_completers = ($env.FZF_COMPLETERS? | default {})
|
||||
if ($cmd_word in $user_completers) {
|
||||
let user_gen = ($user_completers | get $cmd_word)
|
||||
let user_result = (do $user_gen $prefix $cmd_spans)
|
||||
if ($user_result | describe | str starts-with 'record') {
|
||||
let candidates = ($user_result | get candidates)
|
||||
let fzf_opts = ($user_result | get opts? | default ["-m"])
|
||||
let post = ($user_result | get post? | default null)
|
||||
if ($post != null) {
|
||||
$completion_results = (_fzf_complete $prefix {|| $candidates} $fzf_opts --post_process_closure $post)
|
||||
} else {
|
||||
$completion_results = (_fzf_complete $prefix {|| $candidates} $fzf_opts)
|
||||
}
|
||||
} else {
|
||||
$completion_results = (_fzf_complete $prefix {|| $user_result} ["-m"])
|
||||
}
|
||||
} else {
|
||||
match $cmd_word {
|
||||
"ssh" | "scp" | "sftp" | "telnet" => { $completion_results = (_fzf_complete_ssh $prefix $line_without_trigger) }
|
||||
"kill" => { $completion_results = (_fzf_complete_kill $prefix) }
|
||||
_ if ($cmd_word in $env.FZF_COMPLETION_DIR_COMMANDS) => {
|
||||
$completion_results = (__fzf_generic_path_completion $prefix [] "/")
|
||||
}
|
||||
_ => {
|
||||
# Default to path completion if no specific command matches
|
||||
$completion_results = (_fzf_path_completion $prefix)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# --- Return Results ---
|
||||
# The _fzf_... functions return a list of completion strings.
|
||||
# Nushell's completer expects the suggestions for the token being completed (prefix + trigger).
|
||||
# The results from the helper functions should be the final desired strings.
|
||||
# We don't need to manually add spaces; Nushell handles that.
|
||||
$completion_results # Return the list directly
|
||||
} else {
|
||||
# --- Trigger Not Found ---
|
||||
# Return null to let Nushell fall back to other completers (e.g., default file completion).
|
||||
null
|
||||
}
|
||||
}
|
||||
|
||||
# --- WRAPPER AND REGISTRATION ---
|
||||
|
||||
# Guard against re-sourcing: wrapping the completer multiple times would
|
||||
# nest wrappers and grow the call chain on every reload.
|
||||
if ($env.__fzf_completer_registered? | default false) != true {
|
||||
|
||||
# Get the currently configured external completer, if any exists
|
||||
let previous_external_completer = $env.config? | get completions? | get external? | get completer?
|
||||
|
||||
# Define the new wrapper completer
|
||||
let fzf_wrapper_completer = {|spans|
|
||||
# 1. Try the FZF completer logic first
|
||||
let fzf_result = do $fzf_external_completer $spans
|
||||
|
||||
# 2. If FZF returned a result (a list, even an empty one), return it.
|
||||
# `null` means FZF didn't handle it because the trigger wasn't present.
|
||||
if $fzf_result != null {
|
||||
$fzf_result
|
||||
} else {
|
||||
# 3. FZF didn't handle it, so call the previous completer (if it exists).
|
||||
if $previous_external_completer != null {
|
||||
do $previous_external_completer $spans
|
||||
} else {
|
||||
# 4. No previous completer, and FZF didn't handle it. Return null.
|
||||
null
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# Register the new wrapper completer
|
||||
# This ensures external completions are enabled and sets our wrapper.
|
||||
$env.config = $env.config | upsert completions {
|
||||
external: {
|
||||
enable: true
|
||||
completer: $fzf_wrapper_completer
|
||||
}
|
||||
}
|
||||
|
||||
$env.__fzf_completer_registered = true
|
||||
}
|
||||
|
||||
# vim: set sts=2 ts=2 sw=2 tw=120 et :
|
||||
+74
-227
@@ -4,11 +4,10 @@
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.zsh
|
||||
#
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_DIR_OPTS (default: empty)
|
||||
|
||||
# - $FZF_TMUX (default: 0)
|
||||
# - $FZF_TMUX_OPTS (default: '-d 40%')
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
|
||||
# Both branches of the following `if` do the same thing -- define
|
||||
# __fzf_completion_options such that `eval $__fzf_completion_options` sets
|
||||
@@ -68,67 +67,41 @@ fi
|
||||
# control. There are several others that could wreck havoc if they are set
|
||||
# to values we don't expect. With the following `emulate` command we
|
||||
# sidestep this issue entirely.
|
||||
'builtin' 'emulate' 'zsh' && 'builtin' 'setopt' 'no_aliases'
|
||||
'emulate' 'zsh' '-o' 'no_aliases'
|
||||
|
||||
# This brace is the start of try-always block. The `always` part is like
|
||||
# `finally` in lesser languages. We use it to *always* restore user options.
|
||||
{
|
||||
# The 'emulate' command should not be placed inside the interactive if check;
|
||||
# placing it there fails to disable alias expansion. See #3731.
|
||||
if [[ -o interactive ]]; then
|
||||
|
||||
# Bail out if not interactive shell.
|
||||
[[ -o interactive ]] || return 0
|
||||
|
||||
# To use custom commands instead of find, override _fzf_compgen_{path,dir}
|
||||
#
|
||||
# _fzf_compgen_path() {
|
||||
# echo "$1"
|
||||
# command find -L "$1" \
|
||||
# -name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
# -a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
# }
|
||||
#
|
||||
# _fzf_compgen_dir() {
|
||||
# command find -L "$1" \
|
||||
# -name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
# -a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
# }
|
||||
if ! declare -f _fzf_compgen_path > /dev/null; then
|
||||
_fzf_compgen_path() {
|
||||
echo "$1"
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
if ! declare -f _fzf_compgen_dir > /dev/null; then
|
||||
_fzf_compgen_dir() {
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
###########################################################
|
||||
|
||||
#----BEGIN INCLUDE common.sh
|
||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
||||
# the changes. See code comments in "common.sh" for the implementation details.
|
||||
|
||||
__fzf_defaults() {
|
||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
||||
}
|
||||
|
||||
__fzf_exec_awk() {
|
||||
if [[ -z ${__fzf_awk-} ]]; then
|
||||
__fzf_awk=awk
|
||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
||||
__fzf_awk=/usr/xpg4/bin/awk
|
||||
elif command -v mawk > /dev/null 2>&1; then
|
||||
local n x y z d
|
||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||
[[ $n == mawk ]] &&
|
||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
||||
((d >= 20230302)) 2> /dev/null &&
|
||||
__fzf_awk=mawk
|
||||
fi
|
||||
fi
|
||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
||||
}
|
||||
#----END INCLUDE
|
||||
|
||||
__fzf_comprun() {
|
||||
if [[ "$(type _fzf_comprun 2>&1)" =~ function ]]; then
|
||||
_fzf_comprun "$@"
|
||||
elif [ -n "${TMUX_PANE-}" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "${FZF_TMUX_OPTS-}" ]; }; then
|
||||
elif [ -n "$TMUX_PANE" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "$FZF_TMUX_OPTS" ]; }; then
|
||||
shift
|
||||
if [ -n "${FZF_TMUX_OPTS-}" ]; then
|
||||
if [ -n "$FZF_TMUX_OPTS" ]; then
|
||||
fzf-tmux ${(Q)${(Z+n+)FZF_TMUX_OPTS}} -- "$@"
|
||||
else
|
||||
fzf-tmux -d ${FZF_TMUX_HEIGHT:-40%} -- "$@"
|
||||
@@ -139,28 +112,32 @@ __fzf_comprun() {
|
||||
fi
|
||||
}
|
||||
|
||||
# Extract the name of the command. e.g. ls; foo=1 ssh **<tab>
|
||||
# Extract the name of the command. e.g. foo=1 bar baz**<tab>
|
||||
__fzf_extract_command() {
|
||||
# Control completion with the "compstate" parameter, insert and list nothing
|
||||
compstate[insert]=
|
||||
compstate[list]=
|
||||
cmd_word="${(Q)words[1]}"
|
||||
local token tokens
|
||||
tokens=(${(z)1})
|
||||
for token in $tokens; do
|
||||
token=${(Q)token}
|
||||
if [[ "$token" =~ [[:alnum:]] && ! "$token" =~ "=" ]]; then
|
||||
echo "$token"
|
||||
return
|
||||
fi
|
||||
done
|
||||
echo "${tokens[1]}"
|
||||
}
|
||||
|
||||
__fzf_generic_path_completion() {
|
||||
local base lbuf compgen fzf_opts suffix tail dir leftover matches
|
||||
local base lbuf cmd compgen fzf_opts suffix tail dir leftover matches
|
||||
base=$1
|
||||
lbuf=$2
|
||||
cmd=$(__fzf_extract_command "$lbuf")
|
||||
compgen=$3
|
||||
fzf_opts=$4
|
||||
suffix=$5
|
||||
tail=$6
|
||||
|
||||
setopt localoptions nonomatch
|
||||
if [[ $base = *'$('* ]] || [[ $base = *'<('* ]] || [[ $base = *'>('* ]] || [[ $base = *':='* ]] || [[ $base = *'`'* ]]; then
|
||||
return
|
||||
fi
|
||||
eval "base=$base" 2> /dev/null || return
|
||||
eval "base=$base"
|
||||
[[ $base = *"/"* ]] && dir="$base"
|
||||
while [ 1 ]; do
|
||||
if [[ -z "$dir" || -d ${dir} ]]; then
|
||||
@@ -168,29 +145,9 @@ __fzf_generic_path_completion() {
|
||||
leftover=${leftover/#\/}
|
||||
[ -z "$dir" ] && dir='.'
|
||||
[ "$dir" != "/" ] && dir="${dir/%\//}"
|
||||
matches=$(
|
||||
export FZF_DEFAULT_OPTS
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-}")
|
||||
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
||||
if [[ $compgen =~ dir ]]; then
|
||||
rest=${FZF_COMPLETION_DIR_OPTS-}
|
||||
else
|
||||
rest=${FZF_COMPLETION_PATH_OPTS-}
|
||||
fi
|
||||
if declare -f "$compgen" > /dev/null; then
|
||||
eval "$compgen $(printf %q "$dir")" | __fzf_comprun "$cmd_word" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" ${(Q)${(Z+n+)rest}}
|
||||
else
|
||||
if [[ $compgen =~ dir ]]; then
|
||||
walker=dir,follow
|
||||
else
|
||||
walker=file,dir,follow,hidden
|
||||
fi
|
||||
__fzf_comprun "$cmd_word" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" --walker "$walker" --walker-root="$dir" ${(Q)${(Z+n+)rest}} < /dev/tty
|
||||
fi | while read -r item; do
|
||||
item="${item%$suffix}$suffix"
|
||||
echo -n -E "${(q)item} "
|
||||
done
|
||||
)
|
||||
matches=$(eval "$compgen $(printf %q "$dir")" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS" __fzf_comprun "$cmd" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" | while read item; do
|
||||
echo -n "${(q)item}$suffix "
|
||||
done)
|
||||
matches=${matches% }
|
||||
if [ -n "$matches" ]; then
|
||||
LBUFFER="$lbuf$matches$tail"
|
||||
@@ -213,11 +170,11 @@ _fzf_dir_completion() {
|
||||
"" "/" ""
|
||||
}
|
||||
|
||||
_fzf_feed_fifo() {
|
||||
_fzf_feed_fifo() (
|
||||
command rm -f "$1"
|
||||
mkfifo "$1"
|
||||
cat <&0 > "$1" &|
|
||||
}
|
||||
cat <&0 > "$1" &
|
||||
)
|
||||
|
||||
_fzf_complete() {
|
||||
setopt localoptions ksh_arrays
|
||||
@@ -226,7 +183,7 @@ _fzf_complete() {
|
||||
args=("$@")
|
||||
sep=
|
||||
for i in {0..${#args[@]}}; do
|
||||
if [[ "${args[$i]-}" = -- ]]; then
|
||||
if [[ "${args[$i]}" = -- ]]; then
|
||||
sep=$i
|
||||
break
|
||||
fi
|
||||
@@ -242,94 +199,36 @@ _fzf_complete() {
|
||||
rest=("$@")
|
||||
fi
|
||||
|
||||
local fifo lbuf matches post
|
||||
local fifo lbuf cmd matches post
|
||||
fifo="${TMPDIR:-/tmp}/fzf-complete-fifo-$$"
|
||||
lbuf=${rest[0]}
|
||||
cmd=$(__fzf_extract_command "$lbuf")
|
||||
post="${funcstack[1]}_post"
|
||||
type $post > /dev/null 2>&1 || post=cat
|
||||
|
||||
_fzf_feed_fifo "$fifo"
|
||||
matches=$(
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
||||
FZF_DEFAULT_OPTS_FILE='' \
|
||||
__fzf_comprun "$cmd_word" "${args[@]}" -q "${(Q)prefix}" < "$fifo" | $post | tr '\n' ' ')
|
||||
matches=$(FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $str_arg" __fzf_comprun "$cmd" "${args[@]}" -q "${(Q)prefix}" < "$fifo" | $post | tr '\n' ' ')
|
||||
if [ -n "$matches" ]; then
|
||||
LBUFFER="$lbuf$matches"
|
||||
fi
|
||||
command rm -f "$fifo"
|
||||
}
|
||||
|
||||
# To use custom hostname lists, override __fzf_list_hosts.
|
||||
# The function is expected to print hostnames, one per line as well as in the
|
||||
# desired sorting and with any duplicates removed, to standard output.
|
||||
if ! declare -f __fzf_list_hosts > /dev/null; then
|
||||
__fzf_list_hosts() {
|
||||
command sort -u \
|
||||
<(
|
||||
# Note: To make the pathname expansion of "~/.ssh/config.d/*" work
|
||||
# properly, we need to adjust the related shell options. We need to
|
||||
# unset "NO_GLOB" (or reset "GLOB"), which disable the pathname
|
||||
# expansion totally. We need to unset "DOT_GLOB" and set "CASE_GLOB"
|
||||
# to avoid matching unwanted files. We need to set "NULL_GLOB" to
|
||||
# avoid attempting to read the literal filename '~/.ssh/config.d/*'
|
||||
# when no matching is found.
|
||||
setopt GLOB NO_DOT_GLOB CASE_GLOB NO_NOMATCH NULL_GLOB
|
||||
|
||||
__fzf_exec_awk '
|
||||
# Note: mawk <= 1.3.3-20090705 does not support the POSIX brackets of
|
||||
# the form [[:blank:]], and Ubuntu 18.04 LTS still uses this
|
||||
# 16-year-old mawk unfortunately. We need to use [ \t] instead.
|
||||
match(tolower($0), /^[ \t]*host(name)?[ \t]*[ \t=]/) {
|
||||
$0 = substr($0, RLENGTH + 1) # Remove "Host(name)?=?"
|
||||
sub(/#.*/, "")
|
||||
for (i = 1; i <= NF; i++)
|
||||
if ($i !~ /[*?%]/)
|
||||
print $i
|
||||
}
|
||||
' ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null
|
||||
) \
|
||||
<(
|
||||
__fzf_exec_awk -F ',' '
|
||||
match($0, /^[][a-zA-Z0-9.,:-]+/) {
|
||||
$0 = substr($0, 1, RLENGTH)
|
||||
gsub(/[][]|:[^,]*/, "")
|
||||
for (i = 1; i <= NF; i++)
|
||||
print $i
|
||||
}
|
||||
' ~/.ssh/known_hosts 2> /dev/null
|
||||
) \
|
||||
<(
|
||||
__fzf_exec_awk '
|
||||
{
|
||||
sub(/#.*/, "")
|
||||
for (i = 2; i <= NF; i++)
|
||||
if ($i != "0.0.0.0")
|
||||
print $i
|
||||
}
|
||||
' /etc/hosts 2> /dev/null
|
||||
)
|
||||
}
|
||||
fi
|
||||
|
||||
_fzf_complete_telnet() {
|
||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts)
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0' |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
# The first and the only argument is the LBUFFER without the current word that contains the trigger.
|
||||
# The current word without the trigger is in the $prefix variable passed from the caller.
|
||||
_fzf_complete_ssh() {
|
||||
local -a tokens
|
||||
tokens=(${(z)1})
|
||||
case ${tokens[-1]} in
|
||||
-i|-F|-E)
|
||||
_fzf_path_completion "$prefix" "$1"
|
||||
;;
|
||||
*)
|
||||
local user
|
||||
[[ $prefix =~ @ ]] && user="${prefix%%@*}@"
|
||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | __fzf_exec_awk -v user="$user" '{print user $0}')
|
||||
;;
|
||||
esac
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
setopt localoptions nonomatch
|
||||
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?]') \
|
||||
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts | tr ',' '\n' | tr -d '[' | awk '{ print $1 " " $1 }') \
|
||||
<(command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0') |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_export() {
|
||||
@@ -351,45 +250,17 @@ _fzf_complete_unalias() {
|
||||
}
|
||||
|
||||
_fzf_complete_kill() {
|
||||
local transformer
|
||||
transformer='
|
||||
if [[ $FZF_KEY =~ ctrl|alt|shift ]] && [[ -n $FZF_NTH ]]; then
|
||||
nths=( ${FZF_NTH//,/ } )
|
||||
new_nths=()
|
||||
found=0
|
||||
for nth in ${nths[@]}; do
|
||||
if [[ $nth = $FZF_CLICK_HEADER_NTH ]]; then
|
||||
found=1
|
||||
else
|
||||
new_nths+=($nth)
|
||||
fi
|
||||
done
|
||||
[[ $found = 0 ]] && new_nths+=($FZF_CLICK_HEADER_NTH)
|
||||
new_nths=${new_nths[*]}
|
||||
new_nths=${new_nths// /,}
|
||||
echo "change-nth($new_nths)+change-prompt($new_nths> )"
|
||||
else
|
||||
if [[ $FZF_NTH = $FZF_CLICK_HEADER_NTH ]]; then
|
||||
echo "change-nth()+change-prompt(> )"
|
||||
else
|
||||
echo "change-nth($FZF_CLICK_HEADER_NTH)+change-prompt($FZF_CLICK_HEADER_WORD> )"
|
||||
fi
|
||||
fi
|
||||
'
|
||||
_fzf_complete -m --header-lines=1 --no-preview --wrap --color fg:dim,nth:regular \
|
||||
--bind "click-header:transform:$transformer" -- "$@" < <(
|
||||
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
||||
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
||||
command ps --everyone --full --windows # For cygwin
|
||||
_fzf_complete -m --preview 'echo {}' --preview-window down:3:wrap --min-height 15 -- "$@" < <(
|
||||
command ps -ef | sed 1d
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_kill_post() {
|
||||
__fzf_exec_awk '{print $2}'
|
||||
awk '{print $2}'
|
||||
}
|
||||
|
||||
fzf-completion() {
|
||||
local tokens prefix trigger tail matches lbuf d_cmds cursor_pos cmd_word
|
||||
local tokens cmd prefix trigger tail matches lbuf d_cmds
|
||||
setopt localoptions noshwordsplit noksh_arrays noposixbuiltins
|
||||
|
||||
# http://zsh.sourceforge.net/FAQ/zshfaq03.html
|
||||
@@ -400,13 +271,15 @@ fzf-completion() {
|
||||
return
|
||||
fi
|
||||
|
||||
cmd=$(__fzf_extract_command "$LBUFFER")
|
||||
|
||||
# Explicitly allow for empty trigger.
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
[[ -z $trigger && ${LBUFFER[-1]} == ' ' ]] && tokens+=("")
|
||||
[ -z "$trigger" -a ${LBUFFER[-1]} = ' ' ] && tokens+=("")
|
||||
|
||||
# When the trigger starts with ';', it becomes a separate token
|
||||
if [[ ${LBUFFER} = *"${tokens[-2]-}${tokens[-1]}" ]]; then
|
||||
tokens[-2]="${tokens[-2]-}${tokens[-1]}"
|
||||
if [[ ${LBUFFER} = *"${tokens[-2]}${tokens[-1]}" ]]; then
|
||||
tokens[-2]="${tokens[-2]}${tokens[-1]}"
|
||||
tokens=(${tokens[0,-2]})
|
||||
fi
|
||||
|
||||
@@ -415,39 +288,15 @@ fzf-completion() {
|
||||
|
||||
# Trigger sequence given
|
||||
if [ ${#tokens} -gt 1 -a "$tail" = "$trigger" ]; then
|
||||
d_cmds=(${=FZF_COMPLETION_DIR_COMMANDS-cd pushd rmdir})
|
||||
|
||||
{
|
||||
cursor_pos=$CURSOR
|
||||
# Move the cursor before the trigger to preserve word array elements when
|
||||
# trigger chars like ';' or '`' would otherwise reset the 'words' array.
|
||||
CURSOR=$((cursor_pos - ${#trigger} - 1))
|
||||
# Check if at least one completion system (old or new) is active.
|
||||
# If at least one user-defined completion widget is detected, nothing will
|
||||
# be completed if neither the old nor the new completion system is enabled.
|
||||
# In such cases, the 'zsh/compctl' module is loaded as a fallback.
|
||||
if ! zmodload -F zsh/parameter p:functions 2>/dev/null || ! (( ${+functions[compdef]} )); then
|
||||
zmodload -F zsh/compctl 2>/dev/null
|
||||
fi
|
||||
# Create a completion widget to access the 'words' array (man zshcompwid)
|
||||
zle -C __fzf_extract_command .complete-word __fzf_extract_command
|
||||
zle __fzf_extract_command
|
||||
} always {
|
||||
CURSOR=$cursor_pos
|
||||
# Delete the completion widget
|
||||
zle -D __fzf_extract_command 2>/dev/null
|
||||
}
|
||||
d_cmds=(${=FZF_COMPLETION_DIR_COMMANDS:-cd pushd rmdir})
|
||||
|
||||
[ -z "$trigger" ] && prefix=${tokens[-1]} || prefix=${tokens[-1]:0:-${#trigger}}
|
||||
if [[ $prefix = *'$('* ]] || [[ $prefix = *'<('* ]] || [[ $prefix = *'>('* ]] || [[ $prefix = *':='* ]] || [[ $prefix = *'`'* ]]; then
|
||||
return
|
||||
fi
|
||||
[ -n "${tokens[-1]}" ] && lbuf=${lbuf:0:-${#tokens[-1]}}
|
||||
|
||||
if eval "noglob type _fzf_complete_${cmd_word} >/dev/null"; then
|
||||
prefix="$prefix" eval _fzf_complete_${cmd_word} ${(q)lbuf}
|
||||
if eval "type _fzf_complete_${cmd} > /dev/null"; then
|
||||
prefix="$prefix" eval _fzf_complete_${cmd} ${(q)lbuf}
|
||||
zle reset-prompt
|
||||
elif [ ${d_cmds[(i)$cmd_word]} -le ${#d_cmds} ]; then
|
||||
elif [ ${d_cmds[(i)$cmd]} -le ${#d_cmds} ]; then
|
||||
_fzf_dir_completion "$prefix" "$lbuf"
|
||||
else
|
||||
_fzf_path_completion "$prefix" "$lbuf"
|
||||
@@ -464,10 +313,8 @@ fzf-completion() {
|
||||
unset binding
|
||||
}
|
||||
|
||||
# Normal widget
|
||||
zle -N fzf-completion
|
||||
bindkey '^I' fzf-completion
|
||||
fi
|
||||
|
||||
} always {
|
||||
# Restore the original options.
|
||||
|
||||
+51
-144
@@ -4,192 +4,99 @@
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.bash
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_COMMAND
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
if [[ $- =~ i ]]; then
|
||||
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
|
||||
#----BEGIN shfmt
|
||||
#----BEGIN INCLUDE common.sh
|
||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
||||
# the changes. See code comments in "common.sh" for the implementation details.
|
||||
|
||||
__fzf_defaults() {
|
||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
||||
}
|
||||
|
||||
__fzf_exec_awk() {
|
||||
if [[ -z ${__fzf_awk-} ]]; then
|
||||
__fzf_awk=awk
|
||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
||||
__fzf_awk=/usr/xpg4/bin/awk
|
||||
elif command -v mawk > /dev/null 2>&1; then
|
||||
local n x y z d
|
||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||
[[ $n == mawk ]] &&
|
||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
||||
((d >= 20230302)) 2> /dev/null &&
|
||||
__fzf_awk=mawk
|
||||
fi
|
||||
fi
|
||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
||||
}
|
||||
#----END INCLUDE
|
||||
|
||||
__fzf_select__() {
|
||||
FZF_DEFAULT_COMMAND=${FZF_CTRL_T_COMMAND:-} \
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=file,dir,follow,hidden --scheme=path" "${FZF_CTRL_T_OPTS-} -m") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) "$@" |
|
||||
local cmd opts
|
||||
cmd="${FZF_CTRL_T_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | cut -b3-"}"
|
||||
opts="--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore --reverse $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS -m"
|
||||
eval "$cmd" |
|
||||
FZF_DEFAULT_OPTS="$opts" $(__fzfcmd) "$@" |
|
||||
while read -r item; do
|
||||
printf '%q ' "$item" # escape special chars
|
||||
printf '%q ' "$item" # escape special chars
|
||||
done
|
||||
}
|
||||
|
||||
if [[ $- =~ i ]]; then
|
||||
|
||||
__fzfcmd() {
|
||||
[[ -n ${TMUX_PANE-} ]] && { [[ ${FZF_TMUX:-0} != 0 ]] || [[ -n ${FZF_TMUX_OPTS-} ]]; } &&
|
||||
[[ -n "$TMUX_PANE" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "$FZF_TMUX_OPTS" ]]; } &&
|
||||
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
||||
}
|
||||
|
||||
fzf-file-widget() {
|
||||
local selected="$(__fzf_select__ "$@")"
|
||||
READLINE_LINE="${READLINE_LINE:0:READLINE_POINT}$selected${READLINE_LINE:READLINE_POINT}"
|
||||
READLINE_POINT=$((READLINE_POINT + ${#selected}))
|
||||
READLINE_LINE="${READLINE_LINE:0:$READLINE_POINT}$selected${READLINE_LINE:$READLINE_POINT}"
|
||||
READLINE_POINT=$(( READLINE_POINT + ${#selected} ))
|
||||
}
|
||||
|
||||
__fzf_cd__() {
|
||||
local dir
|
||||
dir=$(
|
||||
FZF_DEFAULT_COMMAND=${FZF_ALT_C_COMMAND:-} \
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=dir,follow,hidden --scheme=path" "${FZF_ALT_C_OPTS-} +m") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd)
|
||||
) && printf 'builtin cd -- %q' "$(builtin unset CDPATH && builtin cd -- "$dir" && builtin pwd)"
|
||||
local cmd opts dir
|
||||
cmd="${FZF_ALT_C_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | cut -b3-"}"
|
||||
opts="--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore --reverse $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS +m"
|
||||
dir=$(eval "$cmd" | FZF_DEFAULT_OPTS="$opts" $(__fzfcmd)) && printf 'builtin cd -- %q' "$dir"
|
||||
}
|
||||
|
||||
__fzf_history_delete() {
|
||||
[[ -s $1 ]] || return
|
||||
|
||||
local offsets
|
||||
offsets=($(sort -rnu "$1"))
|
||||
for offset in "${offsets[@]}"; do
|
||||
builtin history -d "$offset"
|
||||
done
|
||||
|
||||
if [[ ${#offsets[@]} -gt 0 ]] && shopt -q histappend; then
|
||||
builtin history -w
|
||||
__fzf_history__() {
|
||||
local output opts script
|
||||
opts="--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS -n2..,.. --tiebreak=index --bind=ctrl-r:toggle-sort $FZF_CTRL_R_OPTS +m --read0"
|
||||
script='BEGIN { getc; $/ = "\n\t"; $HISTCOUNT = $ENV{last_hist} + 1 } s/^[ *]//; print $HISTCOUNT - $. . "\t$_" if !$seen{$_}++'
|
||||
output=$(
|
||||
builtin fc -lnr -2147483648 |
|
||||
last_hist=$(HISTTIMEFORMAT='' builtin history 1) perl -n -l0 -e "$script" |
|
||||
FZF_DEFAULT_OPTS="$opts" $(__fzfcmd) --query "$READLINE_LINE"
|
||||
) || return
|
||||
READLINE_LINE=${output#*$'\t'}
|
||||
if [[ -z "$READLINE_POINT" ]]; then
|
||||
echo "$READLINE_LINE"
|
||||
else
|
||||
READLINE_POINT=0x7fffffff
|
||||
fi
|
||||
}
|
||||
|
||||
if command -v perl > /dev/null; then
|
||||
__fzf_history__() {
|
||||
local output script deletefile
|
||||
deletefile=$(mktemp)
|
||||
script='BEGIN { getc; $/ = "\n\t"; $HISTCOUNT = $ENV{last_hist} + 1 } s/^[ *]//; s/\n/\n\t/gm; print $HISTCOUNT - $. . "\t$_" if !$seen{$_}++'
|
||||
output=$(
|
||||
set +o pipefail
|
||||
builtin fc -lnr -2147483648 |
|
||||
last_hist=$(HISTTIMEFORMAT='' builtin history 1) command perl -n -l0 -e "$script" |
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '"$'\t'"↳ ' --highlight-line --bind 'shift-delete:execute-silent(cat {+f1} >> \"$deletefile\")+exclude-multi' --multi ${FZF_CTRL_R_OPTS-} --read0") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
||||
)
|
||||
__fzf_history_delete "$deletefile"
|
||||
command rm -f "$deletefile"
|
||||
[[ -n $output ]] || return
|
||||
READLINE_LINE=$(command perl -pe 's/^\d*\t//' <<< "$output")
|
||||
if [[ -z $READLINE_POINT ]]; then
|
||||
echo "$READLINE_LINE"
|
||||
else
|
||||
READLINE_POINT=0x7fffffff
|
||||
fi
|
||||
}
|
||||
else # awk - fallback for POSIX systems
|
||||
__fzf_history__() {
|
||||
local output script deletefile
|
||||
deletefile=$(mktemp)
|
||||
[[ $(HISTTIMEFORMAT='' builtin history 1) =~ [[:digit:]]+ ]] # how many history entries
|
||||
script='function P(b) { ++n; sub(/^[ *]/, "", b); if (!seen[b]++) { printf "%d\t%s%c", '$((BASH_REMATCH + 1))' - n, b, 0 } }
|
||||
NR==1 { b = substr($0, 2); next }
|
||||
/^\t/ { P(b); b = substr($0, 2); next }
|
||||
{ b = b RS $0 }
|
||||
END { if (NR) P(b) }'
|
||||
output=$(
|
||||
set +o pipefail
|
||||
builtin fc -lnr -2147483648 2> /dev/null | # ( $'\t '<lines>$'\n' )* ; <lines> ::= [^\n]* ( $'\n'<lines> )*
|
||||
__fzf_exec_awk "$script" | # ( <counter>$'\t'<lines>$'\000' )*
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '"$'\t'"↳ ' --highlight-line --bind 'shift-delete:execute-silent(cat {+f1} >> \"$deletefile\")+exclude-multi' --multi ${FZF_CTRL_R_OPTS-} --read0") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
||||
)
|
||||
__fzf_history_delete "$deletefile"
|
||||
command rm -f "$deletefile"
|
||||
[[ -n $output ]] || return
|
||||
READLINE_LINE=${output#*$'\t'}
|
||||
if [[ -z $READLINE_POINT ]]; then
|
||||
echo "$READLINE_LINE"
|
||||
else
|
||||
READLINE_POINT=0x7fffffff
|
||||
fi
|
||||
}
|
||||
fi
|
||||
|
||||
# Required to refresh the prompt after fzf
|
||||
bind -m emacs-standard '"\C-\e(": redraw-current-line'
|
||||
bind -m emacs-standard '"\er": redraw-current-line'
|
||||
|
||||
bind -m vi-command '"\C-z": emacs-editing-mode'
|
||||
bind -m vi-insert '"\C-z": emacs-editing-mode'
|
||||
bind -m emacs-standard '"\C-z": vi-editing-mode'
|
||||
|
||||
if ((BASH_VERSINFO[0] < 4)); then
|
||||
if (( BASH_VERSINFO[0] < 4 )); then
|
||||
# CTRL-T - Paste the selected file path into the command line
|
||||
if [[ ${FZF_CTRL_T_COMMAND-x} != "" ]]; then
|
||||
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`__fzf_select__`\e\C-e\C-\e(\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f\C-y\ey\C-_"'
|
||||
bind -m vi-command '"\C-t": "\C-z\C-t\C-z"'
|
||||
bind -m vi-insert '"\C-t": "\C-z\C-t\C-z"'
|
||||
fi
|
||||
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`__fzf_select__`\e\C-e\er\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f"'
|
||||
bind -m vi-command '"\C-t": "\C-z\C-t\C-z"'
|
||||
bind -m vi-insert '"\C-t": "\C-z\C-t\C-z"'
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
||||
fi
|
||||
bind -m emacs-standard '"\C-r": "\C-e \C-u\C-y\ey\C-u`__fzf_history__`\e\C-e\C-\e("'
|
||||
bind -m vi-command '"\C-r": "\C-z\C-r\C-z"'
|
||||
bind -m vi-insert '"\C-r": "\C-z\C-r\C-z"'
|
||||
fi
|
||||
bind -m emacs-standard '"\C-r": "\C-e \C-u\C-y\ey\C-u"$(__fzf_history__)"\e\C-e\er"'
|
||||
bind -m vi-command '"\C-r": "\C-z\C-r\C-z"'
|
||||
bind -m vi-insert '"\C-r": "\C-z\C-r\C-z"'
|
||||
else
|
||||
# CTRL-T - Paste the selected file path into the command line
|
||||
if [[ ${FZF_CTRL_T_COMMAND-x} != "" ]]; then
|
||||
bind -m emacs-standard -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-command -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-insert -x '"\C-t": fzf-file-widget'
|
||||
fi
|
||||
bind -m emacs-standard -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-command -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-insert -x '"\C-t": fzf-file-widget'
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
||||
fi
|
||||
bind -m emacs-standard -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-command -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-insert -x '"\C-r": __fzf_history__'
|
||||
fi
|
||||
bind -m emacs-standard -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-command -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-insert -x '"\C-r": __fzf_history__'
|
||||
fi
|
||||
|
||||
# ALT-C - cd into the selected directory
|
||||
if [[ ${FZF_ALT_C_COMMAND-x} != "" ]]; then
|
||||
bind -m emacs-standard '"\ec": " \C-b\C-k \C-u`__fzf_cd__`\e\C-e\C-\e(\C-m\C-y\C-h\e \C-y\ey\C-x\C-x\C-d\C-y\ey\C-_"'
|
||||
bind -m vi-command '"\ec": "\C-z\ec\C-z"'
|
||||
bind -m vi-insert '"\ec": "\C-z\ec\C-z"'
|
||||
fi
|
||||
#----END shfmt
|
||||
bind -m emacs-standard '"\ec": " \C-b\C-k \C-u`__fzf_cd__`\e\C-e\er\C-m\C-y\C-h\e \C-y\ey\C-x\C-x\C-d"'
|
||||
bind -m vi-command '"\ec": "\C-z\ec\C-z"'
|
||||
bind -m vi-insert '"\ec": "\C-z\ec\C-z"'
|
||||
|
||||
fi
|
||||
|
||||
+138
-185
@@ -4,9 +4,9 @@
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.fish
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_COMMAND
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
@@ -15,205 +15,158 @@
|
||||
# ------------
|
||||
function fzf_key_bindings
|
||||
|
||||
# The oldest supported fish version is 3.4.0. For this message being able to be
|
||||
# displayed on older versions, the command substitution syntax $() should not
|
||||
# be used anywhere in the script, otherwise the source command will fail.
|
||||
if string match -qr -- '^[12]\\.|^3\\.[0-3]' $version
|
||||
echo "fzf key bindings script requires fish version 3.4.0 or newer." >&2
|
||||
return 1
|
||||
else if not command -q fzf
|
||||
echo "fzf was not found in path." >&2
|
||||
return 1
|
||||
# Store current token in $dir as root for the 'find' command
|
||||
function fzf-file-widget -d "List files and folders"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -l dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
# "-path \$dir'*/\\.*'" matches hidden files/folders inside $dir but not
|
||||
# $dir itself, even if hidden.
|
||||
test -n "$FZF_CTRL_T_COMMAND"; or set -l FZF_CTRL_T_COMMAND "
|
||||
command find -L \$dir -mindepth 1 \\( -path \$dir'*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | sed 's@^\./@@'"
|
||||
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS"
|
||||
eval "$FZF_CTRL_T_COMMAND | "(__fzfcmd)' -m --query "'$fzf_query'"' | while read -l r; set result $result $r; end
|
||||
end
|
||||
if [ -z "$result" ]
|
||||
commandline -f repaint
|
||||
return
|
||||
else
|
||||
# Remove last token from commandline.
|
||||
commandline -t ""
|
||||
end
|
||||
for i in $result
|
||||
commandline -it -- $prefix
|
||||
commandline -it -- (string escape $i)
|
||||
commandline -it -- ' '
|
||||
end
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function __fzf_defaults
|
||||
# $argv[1]: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||
# $argv[2..]: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set -l FZF_TMUX_HEIGHT 40%
|
||||
string join ' ' -- \
|
||||
"--height $FZF_TMUX_HEIGHT --min-height=20+ --bind=ctrl-z:ignore" $argv[1] \
|
||||
(test -r "$FZF_DEFAULT_OPTS_FILE"; and string join -- ' ' <$FZF_DEFAULT_OPTS_FILE) \
|
||||
$FZF_DEFAULT_OPTS $argv[2..]
|
||||
function fzf-history-widget -d "Show command history"
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT $FZF_DEFAULT_OPTS --tiebreak=index --bind=ctrl-r:toggle-sort,ctrl-z:ignore $FZF_CTRL_R_OPTS +m"
|
||||
|
||||
set -l FISH_MAJOR (echo $version | cut -f1 -d.)
|
||||
set -l FISH_MINOR (echo $version | cut -f2 -d.)
|
||||
|
||||
# history's -z flag is needed for multi-line support.
|
||||
# history's -z flag was added in fish 2.4.0, so don't use it for versions
|
||||
# before 2.4.0.
|
||||
if [ "$FISH_MAJOR" -gt 2 -o \( "$FISH_MAJOR" -eq 2 -a "$FISH_MINOR" -ge 4 \) ];
|
||||
history -z | eval (__fzfcmd) --read0 --print0 -q '(commandline)' | read -lz result
|
||||
and commandline -- $result
|
||||
else
|
||||
history | eval (__fzfcmd) -q '(commandline)' | read -l result
|
||||
and commandline -- $result
|
||||
end
|
||||
end
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function fzf-cd-widget -d "Change directory"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -l dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
test -n "$FZF_ALT_C_COMMAND"; or set -l FZF_ALT_C_COMMAND "
|
||||
command find -L \$dir -mindepth 1 \\( -path \$dir'*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | sed 's@^\./@@'"
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS"
|
||||
eval "$FZF_ALT_C_COMMAND | "(__fzfcmd)' +m --query "'$fzf_query'"' | read -l result
|
||||
|
||||
if [ -n "$result" ]
|
||||
builtin cd -- $result
|
||||
|
||||
# Remove last token from commandline.
|
||||
commandline -t ""
|
||||
commandline -it -- $prefix
|
||||
end
|
||||
end
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function __fzfcmd
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set -l FZF_TMUX_HEIGHT 40%
|
||||
if test -n "$FZF_TMUX_OPTS"
|
||||
test -n "$FZF_TMUX"; or set FZF_TMUX 0
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
if [ -n "$FZF_TMUX_OPTS" ]
|
||||
echo "fzf-tmux $FZF_TMUX_OPTS -- "
|
||||
else if test "$FZF_TMUX" = "1"
|
||||
else if [ $FZF_TMUX -eq 1 ]
|
||||
echo "fzf-tmux -d$FZF_TMUX_HEIGHT -- "
|
||||
else
|
||||
echo "fzf"
|
||||
end
|
||||
end
|
||||
|
||||
function __fzf_parse_commandline -d 'Parse the current command line token and return split of existing filepath, fzf query, and optional -option= prefix'
|
||||
set -l fzf_query ''
|
||||
set -l prefix ''
|
||||
set -l dir '.'
|
||||
bind \ct fzf-file-widget
|
||||
bind \cr fzf-history-widget
|
||||
bind \ec fzf-cd-widget
|
||||
|
||||
set -l -- match_regex '(?<fzf_query>[\\s\\S]*?(?=\\n?$)$)'
|
||||
set -l -- prefix_regex '^-[^\\s=]+=|^-(?!-)\\S'
|
||||
|
||||
# Don't use option prefix if " -- " is preceded.
|
||||
string match -qv -- '* -- *' (string sub -l (commandline -Cp) -- (commandline -p))
|
||||
and set -- match_regex "(?<prefix>$prefix_regex)?$match_regex"
|
||||
|
||||
# Set $prefix and expanded $fzf_query with preserved trailing newlines.
|
||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
||||
# fish v4.0.0 and newer
|
||||
string match -q -r -- $match_regex (commandline --current-token --tokens-expanded | string collect -N)
|
||||
else
|
||||
string match -q -r -- $match_regex (commandline --current-token --tokenize | string collect -N)
|
||||
eval set -- fzf_query (string escape -n -- $fzf_query | string replace -r -a '^\\\\(?=~)|\\\\(?=\\$\\w)' '')
|
||||
end
|
||||
|
||||
if test -n "$fzf_query"
|
||||
# Normalize path in $fzf_query, set $dir to the longest existing directory.
|
||||
if string match -qr -- '^\\d\\d+|^4|^3\\.[5-9]' $version
|
||||
# fish v3.5.0 and newer
|
||||
set -- fzf_query (path normalize -- $fzf_query)
|
||||
set -- dir $fzf_query
|
||||
while not path is -d $dir
|
||||
set -- dir (path dirname $dir)
|
||||
end
|
||||
else
|
||||
string match -q -r -- '(?<fzf_query>^[\\s\\S]*?(?=\\n?$)$)' \
|
||||
(string replace -r -a -- '(?<=/)/|(?<!^)/+(?!\\n)$' '' $fzf_query | string collect -N)
|
||||
set -- dir $fzf_query
|
||||
while not test -d "$dir"
|
||||
set -- dir (dirname -z -- "$dir" | string split0)
|
||||
end
|
||||
end
|
||||
|
||||
if not string match -q -- '.' $dir; or string match -qr -- '^\\.(/|$)' $fzf_query
|
||||
# Strip $dir from $fzf_query - preserve trailing newlines.
|
||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
||||
# fish v4.0.0 and newer
|
||||
string match -q -r -- '^'(string escape --style=regex -- $dir)'/?(?<fzf_query>[\\s\\S]*)' $fzf_query
|
||||
else
|
||||
string match -q -r -- '^/?(?<fzf_query>[\\s\\S]*?(?=\\n?$)$)' \
|
||||
(string replace -- "$dir" '' $fzf_query | string collect -N)
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
string escape -n -- "$dir" "$fzf_query" "$prefix"
|
||||
end
|
||||
|
||||
# Store current token in $dir as root for the 'find' command
|
||||
function fzf-file-widget -d "List files and folders"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -lx dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
set -lx FZF_DEFAULT_OPTS (__fzf_defaults \
|
||||
"--reverse --walker=file,dir,follow,hidden --scheme=path" \
|
||||
"--multi $FZF_CTRL_T_OPTS --print0")
|
||||
|
||||
set -lx FZF_DEFAULT_COMMAND "$FZF_CTRL_T_COMMAND"
|
||||
set -lx FZF_DEFAULT_OPTS_FILE
|
||||
|
||||
set -l result (eval (__fzfcmd) --walker-root=$dir --query=$fzf_query | string split0)
|
||||
and commandline -rt -- (string join -- ' ' $prefix(string escape -n -- $result))' '
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function fzf-history-widget -d "Show command history"
|
||||
set -l -- command_line (commandline)
|
||||
set -l -- current_line (commandline -L)
|
||||
set -l -- total_lines (count $command_line)
|
||||
set -l -- fzf_query (string escape -- $command_line[$current_line])
|
||||
|
||||
set -lx -- FZF_DEFAULT_OPTS (__fzf_defaults '' \
|
||||
'--with-nth=2.. --nth=2..,.. --scheme=history --multi --no-multi-line' \
|
||||
'--no-wrap --wrap-sign="\t\t\t↳ " --preview-wrap-sign="↳ " --freeze-left=1' \
|
||||
'--bind="alt-enter:become(set -g fzf_temp {+sf3..}; string join0 -- (string split0 -- <$fzf_temp | fish_indent -i); unlink $fzf_temp &>/dev/null)"' \
|
||||
'--bind="alt-t:change-with-nth(1,3..|3..|2..)"' \
|
||||
'--bind="shift-delete:execute-silent(eval builtin history delete -Ce -- (string escape -n -- (string split0 -- <{+sf3..})))+reload(eval $FZF_DEFAULT_COMMAND)"' \
|
||||
"--bind=ctrl-r:toggle-sort,alt-r:toggle-raw --highlight-line $FZF_CTRL_R_OPTS" \
|
||||
'--accept-nth=3.. --delimiter="\t" --tabstop=4 --read0 --print0 --with-shell='(status fish-path)\\ -c)
|
||||
|
||||
# Add dynamic preview options if preview command isn't already set by user
|
||||
if string match -qvr -- '--preview[= ]' "$FZF_DEFAULT_OPTS"
|
||||
# Prepend the options to allow user overrides
|
||||
set -p -- FZF_DEFAULT_OPTS \
|
||||
'--bind="focus,multi,resize:bg-transform:if test \\"$FZF_COLUMNS\\" -gt 100 -a \\\\( \\"$FZF_SELECT_COUNT\\" -gt 0 -o \\\\( -z \\"$FZF_WRAP\\" -a (string join0 -- <{f3..} | string length) -gt (math $FZF_COLUMNS - (switch $FZF_WITH_NTH; case 2..; echo 13; case 1,3..; echo 25; case 3..; echo 1; end)) \\\\) -o (string split0 -- <{sf3..} | fish_indent | count) -gt 1 \\\\); echo show-preview; else; echo hide-preview; end"' \
|
||||
'--preview="test \\"$FZF_SELECT_COUNT\\" -gt 0; and string split0 -- <{+sf3..} | fish_indent (string match -q -- 3.\\\\* $version; or echo -- --only-indent) --ansi; and echo -n \\\\n; string collect -- \\\\#\\\\ {1} (string split0 -- <{sf3..}) | fish_indent --ansi"' \
|
||||
'--preview-window="right,50%,wrap-word,follow,info,hidden"'
|
||||
end
|
||||
|
||||
set -lx FZF_DEFAULT_OPTS_FILE
|
||||
|
||||
set -lx -- FZF_DEFAULT_COMMAND 'builtin history -z'
|
||||
|
||||
# Enable syntax highlighting colors on fish v4.3.3 and newer
|
||||
if string match -qr -- '^\\d\\d+|^4\\.[4-9]|^4\\.3\\.[3-9]' $version
|
||||
set -a -- FZF_DEFAULT_OPTS '--ansi'
|
||||
set -a -- FZF_DEFAULT_COMMAND '--color=always --show-time=(set_color $fish_color_comment)"%F %a %T%t%s%t"(set_color $fish_color_normal)'
|
||||
else
|
||||
set -a -- FZF_DEFAULT_COMMAND '--show-time="%F %a %T%t%s%t"'
|
||||
end
|
||||
|
||||
# Merge history from other sessions before searching
|
||||
test -z "$fish_private_mode"; and builtin history merge
|
||||
|
||||
if set -l result (eval $FZF_DEFAULT_COMMAND \| (__fzfcmd) --query=$fzf_query | string split0)
|
||||
if test "$total_lines" -eq 1
|
||||
commandline -- $result
|
||||
else
|
||||
set -l a (math $current_line - 1)
|
||||
set -l b (math $current_line + 1)
|
||||
commandline -- $command_line[1..$a] $result
|
||||
commandline -a -- '' $command_line[$b..-1]
|
||||
end
|
||||
end
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function fzf-cd-widget -d "Change directory"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -lx dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
set -lx FZF_DEFAULT_OPTS (__fzf_defaults \
|
||||
"--reverse --walker=dir,follow,hidden --scheme=path" \
|
||||
"$FZF_ALT_C_OPTS --no-multi --print0")
|
||||
|
||||
set -lx FZF_DEFAULT_OPTS_FILE
|
||||
set -lx FZF_DEFAULT_COMMAND "$FZF_ALT_C_COMMAND"
|
||||
|
||||
if set -l result (eval (__fzfcmd) --query=$fzf_query --walker-root=$dir | string split0)
|
||||
cd -- $result
|
||||
commandline -rt -- $prefix
|
||||
end
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
if not set -q FZF_CTRL_R_COMMAND; or test -n "$FZF_CTRL_R_COMMAND"
|
||||
if test -n "$FZF_CTRL_R_COMMAND"
|
||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
||||
end
|
||||
bind \cr fzf-history-widget
|
||||
bind -M insert \cr fzf-history-widget
|
||||
end
|
||||
|
||||
if not set -q FZF_CTRL_T_COMMAND; or test -n "$FZF_CTRL_T_COMMAND"
|
||||
bind \ct fzf-file-widget
|
||||
if bind -M insert > /dev/null 2>&1
|
||||
bind -M insert \ct fzf-file-widget
|
||||
end
|
||||
|
||||
if not set -q FZF_ALT_C_COMMAND; or test -n "$FZF_ALT_C_COMMAND"
|
||||
bind \ec fzf-cd-widget
|
||||
bind -M insert \cr fzf-history-widget
|
||||
bind -M insert \ec fzf-cd-widget
|
||||
end
|
||||
|
||||
end
|
||||
function __fzf_parse_commandline -d 'Parse the current command line token and return split of existing filepath, fzf query, and optional -option= prefix'
|
||||
set -l commandline (commandline -t)
|
||||
|
||||
# Run setup
|
||||
fzf_key_bindings
|
||||
# strip -option= from token if present
|
||||
set -l prefix (string match -r -- '^-[^\s=]+=' $commandline)
|
||||
set commandline (string replace -- "$prefix" '' $commandline)
|
||||
|
||||
# eval is used to do shell expansion on paths
|
||||
eval set commandline $commandline
|
||||
|
||||
if [ -z $commandline ]
|
||||
# Default to current directory with no --query
|
||||
set dir '.'
|
||||
set fzf_query ''
|
||||
else
|
||||
set dir (__fzf_get_dir $commandline)
|
||||
|
||||
if [ "$dir" = "." -a (string sub -l 1 -- $commandline) != '.' ]
|
||||
# if $dir is "." but commandline is not a relative path, this means no file path found
|
||||
set fzf_query $commandline
|
||||
else
|
||||
# Also remove trailing slash after dir, to "split" input properly
|
||||
set fzf_query (string replace -r "^$dir/?" -- '' "$commandline")
|
||||
end
|
||||
end
|
||||
|
||||
echo $dir
|
||||
echo $fzf_query
|
||||
echo $prefix
|
||||
end
|
||||
|
||||
function __fzf_get_dir -d 'Find the longest existing filepath from input string'
|
||||
set dir $argv
|
||||
|
||||
# Strip all trailing slashes. Ignore if $dir is root dir (/)
|
||||
if [ (string length -- $dir) -gt 1 ]
|
||||
set dir (string replace -r '/*$' -- '' $dir)
|
||||
end
|
||||
|
||||
# Iteratively check if dir exists and strip tail end of path
|
||||
while [ ! -d "$dir" ]
|
||||
# If path is absolute, this can keep going until ends up at /
|
||||
# If path is relative, this can keep going until entire input is consumed, dirname returns "."
|
||||
set dir (dirname -- "$dir")
|
||||
end
|
||||
|
||||
echo $dir
|
||||
end
|
||||
|
||||
end
|
||||
|
||||
@@ -1,166 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.nu
|
||||
#
|
||||
# - $FZF_TMUX (default: 0)
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_TMUX_HEIGHT (default: 40%)
|
||||
# - $FZF_CTRL_T_COMMAND (set to "" to disable)
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_COMMAND (set to "" to disable)
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND (set to "" to disable)
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
# Code provided by @igor-ramazanov
|
||||
# Source: https://github.com/junegunn/fzf/issues/4122#issuecomment-2607368316
|
||||
|
||||
# Merge default options in the same order as bash/zsh:
|
||||
# 1. --height, --min-height, --bind=ctrl-z:ignore, $prepend
|
||||
# 2. $FZF_DEFAULT_OPTS_FILE contents
|
||||
# 3. $FZF_DEFAULT_OPTS, $append
|
||||
def __fzf_defaults [prepend: string, append: string]: nothing -> string {
|
||||
let base = $"--height ($env.FZF_TMUX_HEIGHT? | default '40%') --min-height 20+ --bind=ctrl-z:ignore ($prepend)"
|
||||
let opts_file = if ($env.FZF_DEFAULT_OPTS_FILE? | default '' | is-not-empty) {
|
||||
try { open --raw ($env.FZF_DEFAULT_OPTS_FILE) | str trim } catch { '' }
|
||||
} else {
|
||||
''
|
||||
}
|
||||
let default_opts = $env.FZF_DEFAULT_OPTS? | default ''
|
||||
$"($base) ($opts_file) ($default_opts) ($append)" | str trim
|
||||
}
|
||||
|
||||
# Return the fzf command to use: fzf-tmux when inside tmux and
|
||||
# FZF_TMUX is enabled or FZF_TMUX_OPTS is set, plain fzf otherwise.
|
||||
def __fzfcmd []: nothing -> list<string> {
|
||||
let in_tmux = ($env.TMUX_PANE? | default '' | into string | is-not-empty)
|
||||
if $in_tmux {
|
||||
let fzf_tmux = ($env.FZF_TMUX? | default 0 | into string)
|
||||
let fzf_tmux_opts = ($env.FZF_TMUX_OPTS? | default '' | into string)
|
||||
if ($fzf_tmux != '0') or ($fzf_tmux_opts | is-not-empty) {
|
||||
let opts = if ($fzf_tmux_opts | is-not-empty) { $fzf_tmux_opts } else { $"-d($env.FZF_TMUX_HEIGHT? | default '40%')" }
|
||||
return ['fzf-tmux' ...(($opts | split row ' ' | where { $in != '' })) '--']
|
||||
}
|
||||
}
|
||||
['fzf']
|
||||
}
|
||||
|
||||
|
||||
export-env {
|
||||
$env.FZF_CTRL_T_OPTS = $env.FZF_CTRL_T_OPTS? | default ""
|
||||
$env.FZF_CTRL_R_OPTS = $env.FZF_CTRL_R_OPTS? | default ""
|
||||
$env.FZF_ALT_C_OPTS = $env.FZF_ALT_C_OPTS? | default ""
|
||||
}
|
||||
|
||||
# Directories
|
||||
const alt_c = {
|
||||
name: fzf_dirs
|
||||
modifier: alt
|
||||
keycode: char_c
|
||||
mode: [emacs, vi_normal, vi_insert]
|
||||
event: [
|
||||
{
|
||||
send: executehostcommand
|
||||
cmd: "
|
||||
let fzf_opts = (__fzf_defaults '--reverse --walker=dir,follow,hidden --scheme=path' $'($env.FZF_ALT_C_OPTS) +m');
|
||||
let fzfcmd = (__fzfcmd);
|
||||
let fzf_args = ($fzfcmd | skip 1);
|
||||
let alt_c_cmd = ($env.FZF_ALT_C_COMMAND? | default null);
|
||||
let result = if ($alt_c_cmd == null) or ($alt_c_cmd | is-empty) {
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args }
|
||||
} else {
|
||||
let fzf_cmd_str = ($fzfcmd | str join ' ');
|
||||
let sh_cmd = [$alt_c_cmd '|' $fzf_cmd_str] | str join ' ';
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^sh -c $sh_cmd }
|
||||
};
|
||||
if ($result | is-not-empty) { cd $result };
|
||||
"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
# History
|
||||
const ctrl_r = {
|
||||
name: fzf_history
|
||||
modifier: control
|
||||
keycode: char_r
|
||||
mode: [emacs, vi_insert, vi_normal]
|
||||
event: [
|
||||
{
|
||||
send: executehostcommand
|
||||
cmd: "commandline edit --replace (
|
||||
let fzf_opts = (__fzf_defaults '' $'--scheme=history --bind=ctrl-r:toggle-sort --wrap-sign \"\t↳ \" --highlight-line ($env.FZF_CTRL_R_OPTS) +m --read0');
|
||||
let fzfcmd = (__fzfcmd);
|
||||
let fzf_args = ($fzfcmd | skip 1);
|
||||
# reverse | uniq: show most recent first, deduplicate keeping the latest.
|
||||
# Nushell's `history` loads the full history as an in-memory table
|
||||
# (bounded by $env.config.history.max_size, default 100,000), so
|
||||
# reverse and uniq run on an already-materialized list. This is O(n)
|
||||
# but acceptable for typical history sizes; unlike bash/zsh `fc -r`,
|
||||
# there is no streaming primitive that would let fzf show the latest
|
||||
# entries before the full list is consumed.
|
||||
history
|
||||
| get command
|
||||
| reverse
|
||||
| uniq
|
||||
| str join (char -i 0)
|
||||
| with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args --query (commandline) }
|
||||
| decode utf-8
|
||||
| str trim
|
||||
)"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
# Files
|
||||
const ctrl_t = {
|
||||
name: fzf_files
|
||||
modifier: control
|
||||
keycode: char_t
|
||||
mode: [emacs, vi_normal, vi_insert]
|
||||
event: [
|
||||
{
|
||||
send: executehostcommand
|
||||
cmd: "
|
||||
let fzf_opts = (__fzf_defaults '--reverse --walker=file,dir,follow,hidden --scheme=path' $'($env.FZF_CTRL_T_OPTS) -m');
|
||||
let fzfcmd = (__fzfcmd);
|
||||
let fzf_args = ($fzfcmd | skip 1);
|
||||
let ctrl_t_cmd = ($env.FZF_CTRL_T_COMMAND? | default null);
|
||||
let result = if ($ctrl_t_cmd == null) or ($ctrl_t_cmd | is-empty) {
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args }
|
||||
} else {
|
||||
let fzf_cmd_str = ($fzfcmd | str join ' ');
|
||||
let sh_cmd = [$ctrl_t_cmd '|' $fzf_cmd_str] | str join ' ';
|
||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^sh -c $sh_cmd }
|
||||
};
|
||||
let result = ($result | str replace --all (char newline) ' ' | str trim);
|
||||
commandline edit --append $result;
|
||||
commandline set-cursor --end
|
||||
"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
# Helper to check if a binding is enabled. A binding is disabled when
|
||||
# the corresponding *_COMMAND variable is explicitly set to "".
|
||||
# When not defined (null), the binding is enabled (using fzf's built-in walker).
|
||||
def __fzf_binding_enabled [var_name: string]: nothing -> bool {
|
||||
let val = ($env | get -o $var_name)
|
||||
# null = not defined = enabled; "" = explicitly disabled
|
||||
$val == null or ($val | into string | is-not-empty)
|
||||
}
|
||||
|
||||
# Update the $env.config
|
||||
export-env {
|
||||
let fzf_names = ['fzf_files', 'fzf_dirs', 'fzf_history']
|
||||
# Filter out any existing fzf bindings, then re-add the enabled ones.
|
||||
# This allows re-sourcing to update bindings (e.g. after changing
|
||||
# FZF_CTRL_T_COMMAND) without creating duplicates.
|
||||
mut bindings = ($env.config.keybindings | where { |kb| $kb.name not-in $fzf_names })
|
||||
if (__fzf_binding_enabled 'FZF_ALT_C_COMMAND') { $bindings = ($bindings | append $alt_c) }
|
||||
if (__fzf_binding_enabled 'FZF_CTRL_R_COMMAND') { $bindings = ($bindings | append $ctrl_r) }
|
||||
if (__fzf_binding_enabled 'FZF_CTRL_T_COMMAND') { $bindings = ($bindings | append $ctrl_t) }
|
||||
$env.config.keybindings = $bindings
|
||||
}
|
||||
+35
-112
@@ -4,14 +4,13 @@
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.zsh
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_COMMAND
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
|
||||
@@ -33,48 +32,22 @@ else
|
||||
}
|
||||
fi
|
||||
|
||||
'builtin' 'emulate' 'zsh' && 'builtin' 'setopt' 'no_aliases'
|
||||
'emulate' 'zsh' '-o' 'no_aliases'
|
||||
|
||||
{
|
||||
if [[ -o interactive ]]; then
|
||||
|
||||
#----BEGIN INCLUDE common.sh
|
||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
||||
# the changes. See code comments in "common.sh" for the implementation details.
|
||||
|
||||
__fzf_defaults() {
|
||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
||||
}
|
||||
|
||||
__fzf_exec_awk() {
|
||||
if [[ -z ${__fzf_awk-} ]]; then
|
||||
__fzf_awk=awk
|
||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
||||
__fzf_awk=/usr/xpg4/bin/awk
|
||||
elif command -v mawk > /dev/null 2>&1; then
|
||||
local n x y z d
|
||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||
[[ $n == mawk ]] &&
|
||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
||||
((d >= 20230302)) 2> /dev/null &&
|
||||
__fzf_awk=mawk
|
||||
fi
|
||||
fi
|
||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
||||
}
|
||||
#----END INCLUDE
|
||||
[[ -o interactive ]] || return 0
|
||||
|
||||
# CTRL-T - Paste the selected file path(s) into the command line
|
||||
__fzf_select() {
|
||||
__fsel() {
|
||||
local cmd="${FZF_CTRL_T_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | cut -b3-"}"
|
||||
setopt localoptions pipefail no_aliases 2> /dev/null
|
||||
local item
|
||||
FZF_DEFAULT_COMMAND=${FZF_CTRL_T_COMMAND:-} \
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=file,dir,follow,hidden --scheme=path" "${FZF_CTRL_T_OPTS-} -m") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) "$@" < /dev/tty | while read -r item; do
|
||||
echo -n -E "${(q)item} "
|
||||
eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS" $(__fzfcmd) -m "$@" | while read item; do
|
||||
echo -n "${(q)item} "
|
||||
done
|
||||
local ret=$?
|
||||
echo
|
||||
@@ -82,114 +55,64 @@ __fzf_select() {
|
||||
}
|
||||
|
||||
__fzfcmd() {
|
||||
[ -n "${TMUX_PANE-}" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "${FZF_TMUX_OPTS-}" ]; } &&
|
||||
[ -n "$TMUX_PANE" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "$FZF_TMUX_OPTS" ]; } &&
|
||||
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
||||
}
|
||||
|
||||
fzf-file-widget() {
|
||||
LBUFFER="${LBUFFER}$(__fzf_select)"
|
||||
LBUFFER="${LBUFFER}$(__fsel)"
|
||||
local ret=$?
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
if [[ "${FZF_CTRL_T_COMMAND-x}" != "" ]]; then
|
||||
zle -N fzf-file-widget
|
||||
bindkey -M emacs '^T' fzf-file-widget
|
||||
bindkey -M vicmd '^T' fzf-file-widget
|
||||
bindkey -M viins '^T' fzf-file-widget
|
||||
fi
|
||||
zle -N fzf-file-widget
|
||||
bindkey -M emacs '^T' fzf-file-widget
|
||||
bindkey -M vicmd '^T' fzf-file-widget
|
||||
bindkey -M viins '^T' fzf-file-widget
|
||||
|
||||
# ALT-C - cd into the selected directory
|
||||
fzf-cd-widget() {
|
||||
local cmd="${FZF_ALT_C_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | cut -b3-"}"
|
||||
setopt localoptions pipefail no_aliases 2> /dev/null
|
||||
local dir="$(
|
||||
FZF_DEFAULT_COMMAND=${FZF_ALT_C_COMMAND:-} \
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=dir,follow,hidden --scheme=path" "${FZF_ALT_C_OPTS-} +m") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) < /dev/tty)"
|
||||
local dir="$(eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS" $(__fzfcmd) +m)"
|
||||
if [[ -z "$dir" ]]; then
|
||||
zle redisplay
|
||||
return 0
|
||||
fi
|
||||
zle push-line # Clear buffer. Auto-restored on next prompt.
|
||||
BUFFER="builtin cd -- ${(q)dir:a}"
|
||||
BUFFER="builtin cd -- ${(q)dir}"
|
||||
zle accept-line
|
||||
local ret=$?
|
||||
unset dir # ensure this doesn't end up appearing in prompt expansion
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
if [[ "${FZF_ALT_C_COMMAND-x}" != "" ]]; then
|
||||
zle -N fzf-cd-widget
|
||||
bindkey -M emacs '\ec' fzf-cd-widget
|
||||
bindkey -M vicmd '\ec' fzf-cd-widget
|
||||
bindkey -M viins '\ec' fzf-cd-widget
|
||||
fi
|
||||
zle -N fzf-cd-widget
|
||||
bindkey -M emacs '\ec' fzf-cd-widget
|
||||
bindkey -M vicmd '\ec' fzf-cd-widget
|
||||
bindkey -M viins '\ec' fzf-cd-widget
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
fzf-history-widget() {
|
||||
local selected extracted_with_perl=0
|
||||
setopt localoptions noglobsubst noposixbuiltins pipefail no_aliases no_glob no_sh_glob no_ksharrays extendedglob 2> /dev/null
|
||||
# Ensure the module is loaded if not already, and the required features, such
|
||||
# as the associative 'history' array, which maps event numbers to full history
|
||||
# lines, are set. Also, make sure Perl is installed for multi-line output.
|
||||
if zmodload -F zsh/parameter p:{commands,history} 2>/dev/null && (( ${+commands[perl]} )); then
|
||||
selected="$(printf '%s\t%s\000' "${(kv)history[@]}" |
|
||||
perl -0 -ne 'if (!$seen{(/^\s*[0-9]+\**\t(.*)/s, $1)}++) { s/\n/\n\t/g; print; }' |
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '\t↳ ' --highlight-line --multi ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER} --read0") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
||||
extracted_with_perl=1
|
||||
else
|
||||
selected="$(fc -rl 1 | __fzf_exec_awk '{ cmd=$0; sub(/^[ \t]*[0-9]+\**[ \t]+/, "", cmd); if (!seen[cmd]++) print $0 }' |
|
||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '\t↳ ' --highlight-line --multi ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER}") \
|
||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
||||
fi
|
||||
local selected num
|
||||
setopt localoptions noglobsubst noposixbuiltins pipefail no_aliases 2> /dev/null
|
||||
selected=( $(fc -rl 1 | awk '{ cmd=$0; sub(/^\s*[0-9]+\**\s+/, "", cmd); if (!seen[cmd]++) print $0 }' |
|
||||
FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} $FZF_DEFAULT_OPTS -n2..,.. --tiebreak=index --bind=ctrl-r:toggle-sort,ctrl-z:ignore $FZF_CTRL_R_OPTS --query=${(qqq)LBUFFER} +m" $(__fzfcmd)) )
|
||||
local ret=$?
|
||||
local -a cmds
|
||||
# Avoid leaking auto assigned values when using backreferences '(#b)'
|
||||
local -a mbegin mend match
|
||||
if [ -n "$selected" ]; then
|
||||
# Heuristic to check if the selected value is from history or a custom query
|
||||
if ((( extracted_with_perl )) && [[ $selected == <->$'\t'* ]]) ||
|
||||
((( ! extracted_with_perl )) && [[ $selected == [[:blank:]]#<->( |\* )* ]]); then
|
||||
# Split at newlines
|
||||
for line in ${(ps:\n:)selected}; do
|
||||
if (( extracted_with_perl )); then
|
||||
if [[ $line == (#b)(<->)(#B)$'\t'* ]]; then
|
||||
(( ${+history[${match[1]}]} )) && cmds+=("${history[${match[1]}]}")
|
||||
fi
|
||||
elif [[ $line == [[:blank:]]#(#b)(<->)(#B)( |\* )* ]]; then
|
||||
# Avoid $history array: lags behind 'fc' on foreign commands (*)
|
||||
# https://zsh.org/mla/users/2024/msg00692.html
|
||||
# Push BUFFER onto stack; fetch and save history entry from BUFFER; restore
|
||||
zle .push-line
|
||||
zle vi-fetch-history -n ${match[1]}
|
||||
(( ${#BUFFER} )) && cmds+=("${BUFFER}")
|
||||
BUFFER=""
|
||||
zle .get-line
|
||||
fi
|
||||
done
|
||||
if (( ${#cmds[@]} )); then
|
||||
# Join by newline after stripping trailing newlines from each command
|
||||
BUFFER="${(pj:\n:)${(@)cmds%%$'\n'#}}"
|
||||
CURSOR=${#BUFFER}
|
||||
fi
|
||||
else # selected is a custom query, not from history
|
||||
LBUFFER="$selected"
|
||||
num=$selected[1]
|
||||
if [ -n "$num" ]; then
|
||||
zle vi-fetch-history -n $num
|
||||
fi
|
||||
fi
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
||||
fi
|
||||
zle -N fzf-history-widget
|
||||
bindkey -M emacs '^R' fzf-history-widget
|
||||
bindkey -M vicmd '^R' fzf-history-widget
|
||||
bindkey -M viins '^R' fzf-history-widget
|
||||
fi
|
||||
fi
|
||||
zle -N fzf-history-widget
|
||||
bindkey -M emacs '^R' fzf-history-widget
|
||||
bindkey -M vicmd '^R' fzf-history-widget
|
||||
bindkey -M viins '^R' fzf-history-widget
|
||||
|
||||
} always {
|
||||
eval $__fzf_key_bindings_options
|
||||
|
||||
@@ -1,68 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# This script applies the contents of "common.sh" to the other files.
|
||||
|
||||
set -e
|
||||
|
||||
dir=${0%"${0##*/}"}
|
||||
|
||||
update() {
|
||||
{
|
||||
sed -n '1,/^#----BEGIN INCLUDE common\.sh/p' "$1"
|
||||
cat << EOF
|
||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
||||
# the changes. See code comments in "common.sh" for the implementation details.
|
||||
EOF
|
||||
echo
|
||||
grep -v '^[[:blank:]]*#' "$dir/common.sh" # remove code comments in common.sh
|
||||
sed -n '/^#----END INCLUDE/,$p' "$1"
|
||||
} > "$1.part"
|
||||
|
||||
mv -f "$1.part" "$1"
|
||||
}
|
||||
|
||||
update "$dir/completion.bash"
|
||||
update "$dir/completion.zsh"
|
||||
update "$dir/key-bindings.bash"
|
||||
update "$dir/key-bindings.zsh"
|
||||
|
||||
# Check if --check is in ARGV
|
||||
check=0
|
||||
rest=()
|
||||
for arg in "$@"; do
|
||||
case $arg in
|
||||
--check) check=1 ;;
|
||||
*) rest+=("$arg") ;;
|
||||
esac
|
||||
done
|
||||
|
||||
fmt() {
|
||||
if ! grep -q "^#----BEGIN shfmt" "$1"; then
|
||||
if [[ $check == 1 ]]; then
|
||||
shfmt -d "$1"
|
||||
return $?
|
||||
else
|
||||
shfmt -w "$1"
|
||||
fi
|
||||
else
|
||||
{
|
||||
sed -n '1,/^#----BEGIN shfmt/p' "$1" | sed '$d'
|
||||
sed -n '/^#----BEGIN shfmt/,/^#----END shfmt/p' "$1" | shfmt --filename "$1"
|
||||
sed -n '/^#----END shfmt/,$p' "$1" | sed '1d'
|
||||
} > "$1.part"
|
||||
|
||||
if [[ $check == 1 ]]; then
|
||||
diff -q "$1" "$1.part"
|
||||
ret=$?
|
||||
rm -f "$1.part"
|
||||
return $ret
|
||||
fi
|
||||
|
||||
mv -f "$1.part" "$1"
|
||||
fi
|
||||
}
|
||||
|
||||
for file in "${rest[@]}"; do
|
||||
fmt "$file" || exit $?
|
||||
done
|
||||
+1
-1
@@ -1,6 +1,6 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2026 Junegunn Choi
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
|
||||
@@ -1,200 +0,0 @@
|
||||
// Code generated by "stringer -type=actionType"; DO NOT EDIT.
|
||||
|
||||
package fzf
|
||||
|
||||
import "strconv"
|
||||
|
||||
func _() {
|
||||
// An "invalid array index" compiler error signifies that the constant values have changed.
|
||||
// Re-run the stringer command to generate them again.
|
||||
var x [1]struct{}
|
||||
_ = x[actIgnore-0]
|
||||
_ = x[actStart-1]
|
||||
_ = x[actClick-2]
|
||||
_ = x[actInvalid-3]
|
||||
_ = x[actBracketedPasteBegin-4]
|
||||
_ = x[actBracketedPasteEnd-5]
|
||||
_ = x[actChar-6]
|
||||
_ = x[actMouse-7]
|
||||
_ = x[actBeginningOfLine-8]
|
||||
_ = x[actAbort-9]
|
||||
_ = x[actAccept-10]
|
||||
_ = x[actAcceptNonEmpty-11]
|
||||
_ = x[actAcceptOrPrintQuery-12]
|
||||
_ = x[actBackwardChar-13]
|
||||
_ = x[actBackwardDeleteChar-14]
|
||||
_ = x[actBackwardDeleteCharEof-15]
|
||||
_ = x[actBackwardWord-16]
|
||||
_ = x[actBackwardSubWord-17]
|
||||
_ = x[actCancel-18]
|
||||
_ = x[actChangeBorderLabel-19]
|
||||
_ = x[actChangeGhost-20]
|
||||
_ = x[actChangeHeader-21]
|
||||
_ = x[actChangeHeaderLines-22]
|
||||
_ = x[actChangeFooter-23]
|
||||
_ = x[actChangeHeaderLabel-24]
|
||||
_ = x[actChangeFooterLabel-25]
|
||||
_ = x[actChangeInputLabel-26]
|
||||
_ = x[actChangeListLabel-27]
|
||||
_ = x[actChangeMulti-28]
|
||||
_ = x[actChangeNth-29]
|
||||
_ = x[actChangeWithNth-30]
|
||||
_ = x[actChangePointer-31]
|
||||
_ = x[actChangePreview-32]
|
||||
_ = x[actChangePreviewLabel-33]
|
||||
_ = x[actChangePreviewWindow-34]
|
||||
_ = x[actChangePrompt-35]
|
||||
_ = x[actChangeQuery-36]
|
||||
_ = x[actClearScreen-37]
|
||||
_ = x[actClearQuery-38]
|
||||
_ = x[actClearSelection-39]
|
||||
_ = x[actClose-40]
|
||||
_ = x[actDeleteChar-41]
|
||||
_ = x[actDeleteCharEof-42]
|
||||
_ = x[actEndOfLine-43]
|
||||
_ = x[actFatal-44]
|
||||
_ = x[actForwardChar-45]
|
||||
_ = x[actForwardWord-46]
|
||||
_ = x[actForwardSubWord-47]
|
||||
_ = x[actKillLine-48]
|
||||
_ = x[actKillWord-49]
|
||||
_ = x[actKillSubWord-50]
|
||||
_ = x[actUnixLineDiscard-51]
|
||||
_ = x[actUnixWordRubout-52]
|
||||
_ = x[actYank-53]
|
||||
_ = x[actBackwardKillWord-54]
|
||||
_ = x[actBackwardKillSubWord-55]
|
||||
_ = x[actSelectAll-56]
|
||||
_ = x[actDeselectAll-57]
|
||||
_ = x[actToggle-58]
|
||||
_ = x[actToggleSearch-59]
|
||||
_ = x[actToggleAll-60]
|
||||
_ = x[actToggleDown-61]
|
||||
_ = x[actToggleUp-62]
|
||||
_ = x[actToggleIn-63]
|
||||
_ = x[actToggleOut-64]
|
||||
_ = x[actToggleTrack-65]
|
||||
_ = x[actToggleTrackCurrent-66]
|
||||
_ = x[actToggleHeader-67]
|
||||
_ = x[actToggleWrap-68]
|
||||
_ = x[actToggleWrapWord-69]
|
||||
_ = x[actToggleMultiLine-70]
|
||||
_ = x[actToggleHscroll-71]
|
||||
_ = x[actToggleRaw-72]
|
||||
_ = x[actEnableRaw-73]
|
||||
_ = x[actDisableRaw-74]
|
||||
_ = x[actTrackCurrent-75]
|
||||
_ = x[actToggleInput-76]
|
||||
_ = x[actHideInput-77]
|
||||
_ = x[actShowInput-78]
|
||||
_ = x[actUntrackCurrent-79]
|
||||
_ = x[actDown-80]
|
||||
_ = x[actDownMatch-81]
|
||||
_ = x[actUp-82]
|
||||
_ = x[actUpMatch-83]
|
||||
_ = x[actPageUp-84]
|
||||
_ = x[actPageDown-85]
|
||||
_ = x[actPosition-86]
|
||||
_ = x[actHalfPageUp-87]
|
||||
_ = x[actHalfPageDown-88]
|
||||
_ = x[actOffsetUp-89]
|
||||
_ = x[actOffsetDown-90]
|
||||
_ = x[actOffsetMiddle-91]
|
||||
_ = x[actJump-92]
|
||||
_ = x[actJumpAccept-93]
|
||||
_ = x[actPrintQuery-94]
|
||||
_ = x[actRefreshPreview-95]
|
||||
_ = x[actReplaceQuery-96]
|
||||
_ = x[actToggleSort-97]
|
||||
_ = x[actShowPreview-98]
|
||||
_ = x[actHidePreview-99]
|
||||
_ = x[actTogglePreview-100]
|
||||
_ = x[actTogglePreviewWrap-101]
|
||||
_ = x[actTogglePreviewWrapWord-102]
|
||||
_ = x[actTransform-103]
|
||||
_ = x[actTransformBorderLabel-104]
|
||||
_ = x[actTransformGhost-105]
|
||||
_ = x[actTransformHeader-106]
|
||||
_ = x[actTransformHeaderLines-107]
|
||||
_ = x[actTransformFooter-108]
|
||||
_ = x[actTransformHeaderLabel-109]
|
||||
_ = x[actTransformFooterLabel-110]
|
||||
_ = x[actTransformInputLabel-111]
|
||||
_ = x[actTransformListLabel-112]
|
||||
_ = x[actTransformNth-113]
|
||||
_ = x[actTransformWithNth-114]
|
||||
_ = x[actTransformPointer-115]
|
||||
_ = x[actTransformPreviewLabel-116]
|
||||
_ = x[actTransformPrompt-117]
|
||||
_ = x[actTransformQuery-118]
|
||||
_ = x[actTransformSearch-119]
|
||||
_ = x[actTrigger-120]
|
||||
_ = x[actBgTransform-121]
|
||||
_ = x[actBgTransformBorderLabel-122]
|
||||
_ = x[actBgTransformGhost-123]
|
||||
_ = x[actBgTransformHeader-124]
|
||||
_ = x[actBgTransformHeaderLines-125]
|
||||
_ = x[actBgTransformFooter-126]
|
||||
_ = x[actBgTransformHeaderLabel-127]
|
||||
_ = x[actBgTransformFooterLabel-128]
|
||||
_ = x[actBgTransformInputLabel-129]
|
||||
_ = x[actBgTransformListLabel-130]
|
||||
_ = x[actBgTransformNth-131]
|
||||
_ = x[actBgTransformWithNth-132]
|
||||
_ = x[actBgTransformPointer-133]
|
||||
_ = x[actBgTransformPreviewLabel-134]
|
||||
_ = x[actBgTransformPrompt-135]
|
||||
_ = x[actBgTransformQuery-136]
|
||||
_ = x[actBgTransformSearch-137]
|
||||
_ = x[actBgCancel-138]
|
||||
_ = x[actSearch-139]
|
||||
_ = x[actPreview-140]
|
||||
_ = x[actPreviewTop-141]
|
||||
_ = x[actPreviewBottom-142]
|
||||
_ = x[actPreviewUp-143]
|
||||
_ = x[actPreviewDown-144]
|
||||
_ = x[actPreviewPageUp-145]
|
||||
_ = x[actPreviewPageDown-146]
|
||||
_ = x[actPreviewHalfPageUp-147]
|
||||
_ = x[actPreviewHalfPageDown-148]
|
||||
_ = x[actPrevHistory-149]
|
||||
_ = x[actPrevSelected-150]
|
||||
_ = x[actPrint-151]
|
||||
_ = x[actPut-152]
|
||||
_ = x[actNextHistory-153]
|
||||
_ = x[actNextSelected-154]
|
||||
_ = x[actExecute-155]
|
||||
_ = x[actExecuteSilent-156]
|
||||
_ = x[actExecuteMulti-157]
|
||||
_ = x[actSigStop-158]
|
||||
_ = x[actBest-159]
|
||||
_ = x[actFirst-160]
|
||||
_ = x[actLast-161]
|
||||
_ = x[actReload-162]
|
||||
_ = x[actReloadSync-163]
|
||||
_ = x[actDisableSearch-164]
|
||||
_ = x[actEnableSearch-165]
|
||||
_ = x[actSelect-166]
|
||||
_ = x[actDeselect-167]
|
||||
_ = x[actUnbind-168]
|
||||
_ = x[actRebind-169]
|
||||
_ = x[actToggleBind-170]
|
||||
_ = x[actBecome-171]
|
||||
_ = x[actShowHeader-172]
|
||||
_ = x[actHideHeader-173]
|
||||
_ = x[actBell-174]
|
||||
_ = x[actExclude-175]
|
||||
_ = x[actExcludeMulti-176]
|
||||
_ = x[actAsync-177]
|
||||
}
|
||||
|
||||
const _actionType_name = "actIgnoreactStartactClickactInvalidactBracketedPasteBeginactBracketedPasteEndactCharactMouseactBeginningOfLineactAbortactAcceptactAcceptNonEmptyactAcceptOrPrintQueryactBackwardCharactBackwardDeleteCharactBackwardDeleteCharEofactBackwardWordactBackwardSubWordactCancelactChangeBorderLabelactChangeGhostactChangeHeaderactChangeHeaderLinesactChangeFooteractChangeHeaderLabelactChangeFooterLabelactChangeInputLabelactChangeListLabelactChangeMultiactChangeNthactChangeWithNthactChangePointeractChangePreviewactChangePreviewLabelactChangePreviewWindowactChangePromptactChangeQueryactClearScreenactClearQueryactClearSelectionactCloseactDeleteCharactDeleteCharEofactEndOfLineactFatalactForwardCharactForwardWordactForwardSubWordactKillLineactKillWordactKillSubWordactUnixLineDiscardactUnixWordRuboutactYankactBackwardKillWordactBackwardKillSubWordactSelectAllactDeselectAllactToggleactToggleSearchactToggleAllactToggleDownactToggleUpactToggleInactToggleOutactToggleTrackactToggleTrackCurrentactToggleHeaderactToggleWrapactToggleWrapWordactToggleMultiLineactToggleHscrollactToggleRawactEnableRawactDisableRawactTrackCurrentactToggleInputactHideInputactShowInputactUntrackCurrentactDownactDownMatchactUpactUpMatchactPageUpactPageDownactPositionactHalfPageUpactHalfPageDownactOffsetUpactOffsetDownactOffsetMiddleactJumpactJumpAcceptactPrintQueryactRefreshPreviewactReplaceQueryactToggleSortactShowPreviewactHidePreviewactTogglePreviewactTogglePreviewWrapactTogglePreviewWrapWordactTransformactTransformBorderLabelactTransformGhostactTransformHeaderactTransformHeaderLinesactTransformFooteractTransformHeaderLabelactTransformFooterLabelactTransformInputLabelactTransformListLabelactTransformNthactTransformWithNthactTransformPointeractTransformPreviewLabelactTransformPromptactTransformQueryactTransformSearchactTriggeractBgTransformactBgTransformBorderLabelactBgTransformGhostactBgTransformHeaderactBgTransformHeaderLinesactBgTransformFooteractBgTransformHeaderLabelactBgTransformFooterLabelactBgTransformInputLabelactBgTransformListLabelactBgTransformNthactBgTransformWithNthactBgTransformPointeractBgTransformPreviewLabelactBgTransformPromptactBgTransformQueryactBgTransformSearchactBgCancelactSearchactPreviewactPreviewTopactPreviewBottomactPreviewUpactPreviewDownactPreviewPageUpactPreviewPageDownactPreviewHalfPageUpactPreviewHalfPageDownactPrevHistoryactPrevSelectedactPrintactPutactNextHistoryactNextSelectedactExecuteactExecuteSilentactExecuteMultiactSigStopactBestactFirstactLastactReloadactReloadSyncactDisableSearchactEnableSearchactSelectactDeselectactUnbindactRebindactToggleBindactBecomeactShowHeaderactHideHeaderactBellactExcludeactExcludeMultiactAsync"
|
||||
|
||||
var _actionType_index = [...]uint16{0, 9, 17, 25, 35, 57, 77, 84, 92, 110, 118, 127, 144, 165, 180, 201, 225, 240, 258, 267, 287, 301, 316, 336, 351, 371, 391, 410, 428, 442, 454, 470, 486, 502, 523, 545, 560, 574, 588, 601, 618, 626, 639, 655, 667, 675, 689, 703, 720, 731, 742, 756, 774, 791, 798, 817, 839, 851, 865, 874, 889, 901, 914, 925, 936, 948, 962, 983, 998, 1011, 1028, 1046, 1062, 1074, 1086, 1099, 1114, 1128, 1140, 1152, 1169, 1176, 1188, 1193, 1203, 1212, 1223, 1234, 1247, 1262, 1273, 1286, 1301, 1308, 1321, 1334, 1351, 1366, 1379, 1393, 1407, 1423, 1443, 1467, 1479, 1502, 1519, 1537, 1560, 1578, 1601, 1624, 1646, 1667, 1682, 1701, 1720, 1744, 1762, 1779, 1797, 1807, 1821, 1846, 1865, 1885, 1910, 1930, 1955, 1980, 2004, 2027, 2044, 2065, 2086, 2112, 2132, 2151, 2171, 2182, 2191, 2201, 2214, 2230, 2242, 2256, 2272, 2290, 2310, 2332, 2346, 2361, 2369, 2375, 2389, 2404, 2414, 2430, 2445, 2455, 2462, 2470, 2477, 2486, 2499, 2515, 2530, 2539, 2550, 2559, 2568, 2581, 2590, 2603, 2616, 2623, 2633, 2648, 2656}
|
||||
|
||||
func (i actionType) String() string {
|
||||
if i < 0 || i >= actionType(len(_actionType_index)-1) {
|
||||
return "actionType(" + strconv.FormatInt(int64(i), 10) + ")"
|
||||
}
|
||||
return _actionType_name[_actionType_index[i]:_actionType_index[i+1]]
|
||||
}
|
||||
@@ -1,99 +0,0 @@
|
||||
# SIMD byte search: `indexByteTwo` / `lastIndexByteTwo`
|
||||
|
||||
## What these functions do
|
||||
|
||||
`indexByteTwo(s []byte, b1, b2 byte) int` -- returns the index of the
|
||||
**first** occurrence of `b1` or `b2` in `s`, or `-1`.
|
||||
|
||||
`lastIndexByteTwo(s []byte, b1, b2 byte) int` -- returns the index of the
|
||||
**last** occurrence of `b1` or `b2` in `s`, or `-1`.
|
||||
|
||||
They are used by the fuzzy matching algorithm (`algo.go`) to skip ahead
|
||||
during case-insensitive search. Instead of calling `bytes.IndexByte` twice
|
||||
(once for lowercase, once for uppercase), a single SIMD pass finds both at
|
||||
once.
|
||||
|
||||
## File layout
|
||||
|
||||
| File | Purpose |
|
||||
| ------ | --------- |
|
||||
| `indexbyte2_arm64.go` | Go declarations (`//go:noescape`) for ARM64 |
|
||||
| `indexbyte2_arm64.s` | ARM64 NEON assembly (32-byte aligned blocks, syndrome extraction) |
|
||||
| `indexbyte2_amd64.go` | Go declarations + AVX2 runtime detection for AMD64 |
|
||||
| `indexbyte2_amd64.s` | AMD64 AVX2/SSE2 assembly with CPUID dispatch |
|
||||
| `indexbyte2_other.go` | Pure Go fallback for all other architectures |
|
||||
| `indexbyte2_test.go` | Unit tests, exhaustive tests, fuzz tests, and benchmarks |
|
||||
|
||||
## How the SIMD implementations work
|
||||
|
||||
**ARM64 (NEON):**
|
||||
- Broadcasts both needle bytes into NEON registers (`VMOV`).
|
||||
- Processes 32-byte aligned chunks. For each chunk, compares all bytes
|
||||
against both needles (`VCMEQ`), ORs the results (`VORR`), and builds a
|
||||
64-bit syndrome with 2 bits per byte.
|
||||
- `indexByteTwo` uses `RBIT` + `CLZ` to find the lowest set bit (first match).
|
||||
- `lastIndexByteTwo` scans backward and uses `CLZ` on the raw syndrome to
|
||||
find the highest set bit (last match).
|
||||
- Handles alignment and partial first/last blocks with bit masking.
|
||||
- Adapted from Go's `internal/bytealg/indexbyte_arm64.s`.
|
||||
|
||||
**AMD64 (AVX2 with SSE2 fallback):**
|
||||
- At init time, `cpuHasAVX2()` checks CPUID + XGETBV for AVX2 and OS YMM
|
||||
support. The result is cached in `_useAVX2`.
|
||||
- **AVX2 path** (inputs >= 32 bytes, when available):
|
||||
- Broadcasts both needles via `VPBROADCASTB`.
|
||||
- Processes 32-byte blocks: `VPCMPEQB` against both needles, `VPOR`, then
|
||||
`VPMOVMSKB` to get a 32-bit mask.
|
||||
- 5 instructions per loop iteration (vs 7 for SSE2) at 2x the throughput.
|
||||
- `VZEROUPPER` before every return to avoid SSE/AVX transition penalties.
|
||||
- **SSE2 fallback** (inputs < 32 bytes, or CPUs without AVX2):
|
||||
- Broadcasts via `PUNPCKLBW` + `PSHUFL`.
|
||||
- Processes 16-byte blocks: `PCMPEQB`, `POR`, `PMOVMSKB`.
|
||||
- Small inputs (<16 bytes) are handled with page-boundary-safe loads.
|
||||
- Both paths use `BSFL` (forward) / `BSRL` (reverse) for bit scanning.
|
||||
- Adapted from Go's `internal/bytealg/indexbyte_amd64.s`.
|
||||
|
||||
**Fallback (other platforms):**
|
||||
- `indexByteTwo` uses two `bytes.IndexByte` calls with scope-limiting
|
||||
(search `b1` first, then limit the `b2` search to `s[:i1]`).
|
||||
- `lastIndexByteTwo` uses a simple backward for loop.
|
||||
|
||||
## Running tests
|
||||
|
||||
```bash
|
||||
# Unit + exhaustive tests
|
||||
go test ./src/algo/ -run 'TestIndexByteTwo|TestLastIndexByteTwo' -v
|
||||
|
||||
# Fuzz tests (run for 10 seconds each)
|
||||
go test ./src/algo/ -run '^$' -fuzz FuzzIndexByteTwo -fuzztime 10s
|
||||
go test ./src/algo/ -run '^$' -fuzz FuzzLastIndexByteTwo -fuzztime 10s
|
||||
|
||||
# Cross-architecture: test amd64 on an arm64 Mac (via Rosetta)
|
||||
GOARCH=amd64 go test ./src/algo/ -run 'TestIndexByteTwo|TestLastIndexByteTwo' -v
|
||||
GOARCH=amd64 go test ./src/algo/ -run '^$' -fuzz FuzzIndexByteTwo -fuzztime 10s
|
||||
GOARCH=amd64 go test ./src/algo/ -run '^$' -fuzz FuzzLastIndexByteTwo -fuzztime 10s
|
||||
```
|
||||
|
||||
## Running micro-benchmarks
|
||||
|
||||
```bash
|
||||
# All indexByteTwo / lastIndexByteTwo benchmarks
|
||||
go test ./src/algo/ -bench 'IndexByteTwo' -benchmem
|
||||
|
||||
# Specific size
|
||||
go test ./src/algo/ -bench 'IndexByteTwo_1000'
|
||||
```
|
||||
|
||||
Each benchmark compares the SIMD `asm` implementation against reference
|
||||
implementations (`2xIndexByte` using `bytes.IndexByte`, and a simple `loop`).
|
||||
|
||||
## Correctness verification
|
||||
|
||||
The assembly is verified by three layers of testing:
|
||||
|
||||
1. **Table-driven tests** -- known inputs with expected outputs.
|
||||
2. **Exhaustive tests** -- all lengths 0–256, every match position, no-match
|
||||
cases, and both-bytes-present cases, compared against a simple loop
|
||||
reference.
|
||||
3. **Fuzz tests** -- randomized inputs via `testing.F`, compared against the
|
||||
same loop reference.
|
||||
+91
-237
@@ -80,7 +80,6 @@ Scoring criteria
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"os"
|
||||
"strings"
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
@@ -90,10 +89,6 @@ import (
|
||||
|
||||
var DEBUG bool
|
||||
|
||||
var delimiterChars = "/,:;|"
|
||||
|
||||
const whiteChars = " \t\n\v\f\r\x85\xA0"
|
||||
|
||||
func indexAt(index int, max int, forward bool) int {
|
||||
if forward {
|
||||
return index
|
||||
@@ -145,78 +140,16 @@ const (
|
||||
bonusFirstCharMultiplier = 2
|
||||
)
|
||||
|
||||
var (
|
||||
// Extra bonus for word boundary after whitespace character or beginning of the string
|
||||
bonusBoundaryWhite int16 = bonusBoundary + 2
|
||||
|
||||
// Extra bonus for word boundary after slash, colon, semi-colon, and comma
|
||||
bonusBoundaryDelimiter int16 = bonusBoundary + 1
|
||||
|
||||
initialCharClass = charWhite
|
||||
|
||||
// A minor optimization that can give 15%+ performance boost
|
||||
asciiCharClasses [unicode.MaxASCII + 1]charClass
|
||||
|
||||
// A minor optimization that can give yet another 5% performance boost
|
||||
bonusMatrix [charNumber + 1][charNumber + 1]int16
|
||||
)
|
||||
|
||||
type charClass int
|
||||
|
||||
const (
|
||||
charWhite charClass = iota
|
||||
charNonWord
|
||||
charDelimiter
|
||||
charNonWord charClass = iota
|
||||
charLower
|
||||
charUpper
|
||||
charLetter
|
||||
charNumber
|
||||
)
|
||||
|
||||
func Init(scheme string) bool {
|
||||
switch scheme {
|
||||
case "default":
|
||||
bonusBoundaryWhite = bonusBoundary + 2
|
||||
bonusBoundaryDelimiter = bonusBoundary + 1
|
||||
case "path":
|
||||
bonusBoundaryWhite = bonusBoundary
|
||||
bonusBoundaryDelimiter = bonusBoundary + 1
|
||||
if os.PathSeparator == '/' {
|
||||
delimiterChars = "/"
|
||||
} else {
|
||||
delimiterChars = string([]rune{os.PathSeparator, '/'})
|
||||
}
|
||||
initialCharClass = charDelimiter
|
||||
case "history":
|
||||
bonusBoundaryWhite = bonusBoundary
|
||||
bonusBoundaryDelimiter = bonusBoundary
|
||||
default:
|
||||
return false
|
||||
}
|
||||
for i := 0; i <= unicode.MaxASCII; i++ {
|
||||
char := rune(i)
|
||||
c := charNonWord
|
||||
if char >= 'a' && char <= 'z' {
|
||||
c = charLower
|
||||
} else if char >= 'A' && char <= 'Z' {
|
||||
c = charUpper
|
||||
} else if char >= '0' && char <= '9' {
|
||||
c = charNumber
|
||||
} else if strings.ContainsRune(whiteChars, char) {
|
||||
c = charWhite
|
||||
} else if strings.ContainsRune(delimiterChars, char) {
|
||||
c = charDelimiter
|
||||
}
|
||||
asciiCharClasses[i] = c
|
||||
}
|
||||
for i := 0; i <= int(charNumber); i++ {
|
||||
for j := 0; j <= int(charNumber); j++ {
|
||||
bonusMatrix[i][j] = bonusFor(charClass(i), charClass(j))
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func posArray(withPos bool, len int) *[]int {
|
||||
if withPos {
|
||||
pos := make([]int, 0, len)
|
||||
@@ -241,6 +174,17 @@ func alloc32(offset int, slab *util.Slab, size int) (int, []int32) {
|
||||
return offset, make([]int32, size)
|
||||
}
|
||||
|
||||
func charClassOfAscii(char rune) charClass {
|
||||
if char >= 'a' && char <= 'z' {
|
||||
return charLower
|
||||
} else if char >= 'A' && char <= 'Z' {
|
||||
return charUpper
|
||||
} else if char >= '0' && char <= '9' {
|
||||
return charNumber
|
||||
}
|
||||
return charNonWord
|
||||
}
|
||||
|
||||
func charClassOfNonAscii(char rune) charClass {
|
||||
if unicode.IsLower(char) {
|
||||
return charLower
|
||||
@@ -250,60 +194,40 @@ func charClassOfNonAscii(char rune) charClass {
|
||||
return charNumber
|
||||
} else if unicode.IsLetter(char) {
|
||||
return charLetter
|
||||
} else if unicode.IsSpace(char) {
|
||||
return charWhite
|
||||
} else if strings.ContainsRune(delimiterChars, char) {
|
||||
return charDelimiter
|
||||
}
|
||||
return charNonWord
|
||||
}
|
||||
|
||||
func charClassOf(char rune) charClass {
|
||||
if char <= unicode.MaxASCII {
|
||||
return asciiCharClasses[char]
|
||||
return charClassOfAscii(char)
|
||||
}
|
||||
return charClassOfNonAscii(char)
|
||||
}
|
||||
|
||||
func bonusFor(prevClass charClass, class charClass) int16 {
|
||||
if class >= charNonWord {
|
||||
switch prevClass {
|
||||
case charWhite:
|
||||
// Word boundary after whitespace
|
||||
return bonusBoundaryWhite
|
||||
case charDelimiter:
|
||||
// Word boundary after a delimiter character
|
||||
return bonusBoundaryDelimiter
|
||||
case charNonWord:
|
||||
// Word boundary
|
||||
return bonusBoundary
|
||||
}
|
||||
}
|
||||
|
||||
if prevClass == charLower && class == charUpper ||
|
||||
if prevClass == charNonWord && class != charNonWord {
|
||||
// Word boundary
|
||||
return bonusBoundary
|
||||
} else if prevClass == charLower && class == charUpper ||
|
||||
prevClass != charNumber && class == charNumber {
|
||||
// camelCase letter123
|
||||
return bonusCamel123
|
||||
}
|
||||
|
||||
switch class {
|
||||
case charNonWord, charDelimiter:
|
||||
} else if class == charNonWord {
|
||||
return bonusNonWord
|
||||
case charWhite:
|
||||
return bonusBoundaryWhite
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func bonusAt(input *util.Chars, idx int) int16 {
|
||||
if idx == 0 {
|
||||
return bonusBoundaryWhite
|
||||
return bonusBoundary
|
||||
}
|
||||
return bonusMatrix[charClassOf(input.Get(idx-1))][charClassOf(input.Get(idx))]
|
||||
return bonusFor(charClassOf(input.Get(idx-1)), charClassOf(input.Get(idx)))
|
||||
}
|
||||
|
||||
func normalizeRune(r rune) rune {
|
||||
if r < 0x00C0 || r > 0xFF61 {
|
||||
if r < 0x00C0 || r > 0x2184 {
|
||||
return r
|
||||
}
|
||||
|
||||
@@ -321,15 +245,22 @@ type Algo func(caseSensitive bool, normalize bool, forward bool, input *util.Cha
|
||||
|
||||
func trySkip(input *util.Chars, caseSensitive bool, b byte, from int) int {
|
||||
byteArray := input.Bytes()[from:]
|
||||
// For case-insensitive search of a letter, search for both cases in one pass
|
||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||
idx := IndexByteTwo(byteArray, b, b-32)
|
||||
if idx < 0 {
|
||||
return -1
|
||||
}
|
||||
return from + idx
|
||||
}
|
||||
idx := bytes.IndexByte(byteArray, b)
|
||||
if idx == 0 {
|
||||
// Can't skip any further
|
||||
return from
|
||||
}
|
||||
// We may need to search for the uppercase letter again. We don't have to
|
||||
// consider normalization as we can be sure that this is an ASCII string.
|
||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||
if idx > 0 {
|
||||
byteArray = byteArray[:idx]
|
||||
}
|
||||
uidx := bytes.IndexByte(byteArray, b-32)
|
||||
if uidx >= 0 {
|
||||
idx = uidx
|
||||
}
|
||||
}
|
||||
if idx < 0 {
|
||||
return -1
|
||||
}
|
||||
@@ -345,48 +276,30 @@ func isAscii(runes []rune) bool {
|
||||
return true
|
||||
}
|
||||
|
||||
func asciiFuzzyIndex(input *util.Chars, pattern []rune, caseSensitive bool) (int, int) {
|
||||
func asciiFuzzyIndex(input *util.Chars, pattern []rune, caseSensitive bool) int {
|
||||
// Can't determine
|
||||
if !input.IsBytes() {
|
||||
return 0, input.Length()
|
||||
return 0
|
||||
}
|
||||
|
||||
// Not possible
|
||||
if !isAscii(pattern) {
|
||||
return -1, -1
|
||||
return -1
|
||||
}
|
||||
|
||||
firstIdx, idx, lastIdx := 0, 0, 0
|
||||
var b byte
|
||||
for pidx := range pattern {
|
||||
b = byte(pattern[pidx])
|
||||
idx = trySkip(input, caseSensitive, b, idx)
|
||||
firstIdx, idx := 0, 0
|
||||
for pidx := 0; pidx < len(pattern); pidx++ {
|
||||
idx = trySkip(input, caseSensitive, byte(pattern[pidx]), idx)
|
||||
if idx < 0 {
|
||||
return -1, -1
|
||||
return -1
|
||||
}
|
||||
if pidx == 0 && idx > 0 {
|
||||
// Step back to find the right bonus point
|
||||
firstIdx = idx - 1
|
||||
}
|
||||
lastIdx = idx
|
||||
idx++
|
||||
}
|
||||
|
||||
// Find the last appearance of the last character of the pattern to limit the search scope
|
||||
scope := input.Bytes()[lastIdx:]
|
||||
if len(scope) > 1 {
|
||||
tail := scope[1:]
|
||||
var end int
|
||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||
end = lastIndexByteTwo(tail, b, b-32)
|
||||
} else {
|
||||
end = bytes.LastIndexByte(tail, b)
|
||||
}
|
||||
if end >= 0 {
|
||||
return firstIdx, lastIdx + 1 + end + 1
|
||||
}
|
||||
}
|
||||
return firstIdx, lastIdx + 1
|
||||
return firstIdx
|
||||
}
|
||||
|
||||
func debugV2(T []rune, pattern []rune, F []int32, lastIdx int, H []int16, C []int16) {
|
||||
@@ -397,7 +310,7 @@ func debugV2(T []rune, pattern []rune, F []int32, lastIdx int, H []int16, C []in
|
||||
if i == 0 {
|
||||
fmt.Print(" ")
|
||||
for j := int(f); j <= lastIdx; j++ {
|
||||
fmt.Print(" " + string(T[j]) + " ")
|
||||
fmt.Printf(" " + string(T[j]) + " ")
|
||||
}
|
||||
fmt.Println()
|
||||
}
|
||||
@@ -435,25 +348,18 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
return Result{0, 0, 0}, posArray(withPos, M)
|
||||
}
|
||||
N := input.Length()
|
||||
if M > N {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// Since O(nm) algorithm can be prohibitively expensive for large input,
|
||||
// we fall back to the greedy algorithm.
|
||||
// Also, we should not allow a very long pattern to avoid 16-bit integer
|
||||
// overflow in the score matrix. 1000 is a safe limit.
|
||||
if slab != nil && int64(N)*int64(M) > int64(cap(slab.I16)) || M > 1000 {
|
||||
if slab != nil && N*M > cap(slab.I16) {
|
||||
return FuzzyMatchV1(caseSensitive, normalize, forward, input, pattern, withPos, slab)
|
||||
}
|
||||
|
||||
// Phase 1. Optimized search for ASCII string
|
||||
minIdx, maxIdx := asciiFuzzyIndex(input, pattern, caseSensitive)
|
||||
if minIdx < 0 {
|
||||
idx := asciiFuzzyIndex(input, pattern, caseSensitive)
|
||||
if idx < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
// fmt.Println(N, maxIdx, idx, maxIdx-idx, input.ToString())
|
||||
N = maxIdx - minIdx
|
||||
|
||||
// Reuse pre-allocated integer slice to avoid unnecessary sweeping of garbages
|
||||
offset16 := 0
|
||||
@@ -466,19 +372,20 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
offset32, F := alloc32(offset32, slab, M)
|
||||
// Rune array
|
||||
_, T := alloc32(offset32, slab, N)
|
||||
input.CopyRunes(T, minIdx)
|
||||
input.CopyRunes(T)
|
||||
|
||||
// Phase 2. Calculate bonus for each point
|
||||
maxScore, maxScorePos := int16(0), 0
|
||||
pidx, lastIdx := 0, 0
|
||||
pchar0, pchar, prevH0, prevClass, inGap := pattern[0], pattern[0], int16(0), initialCharClass, false
|
||||
for off, char := range T {
|
||||
pchar0, pchar, prevH0, prevClass, inGap := pattern[0], pattern[0], int16(0), charNonWord, false
|
||||
Tsub := T[idx:]
|
||||
H0sub, C0sub, Bsub := H0[idx:][:len(Tsub)], C0[idx:][:len(Tsub)], B[idx:][:len(Tsub)]
|
||||
for off, char := range Tsub {
|
||||
var class charClass
|
||||
if char <= unicode.MaxASCII {
|
||||
class = asciiCharClasses[char]
|
||||
class = charClassOfAscii(char)
|
||||
if !caseSensitive && class == charUpper {
|
||||
char += 32
|
||||
T[off] = char
|
||||
}
|
||||
} else {
|
||||
class = charClassOfNonAscii(char)
|
||||
@@ -488,53 +395,53 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
T[off] = char
|
||||
}
|
||||
|
||||
bonus := bonusMatrix[prevClass][class]
|
||||
B[off] = bonus
|
||||
Tsub[off] = char
|
||||
bonus := bonusFor(prevClass, class)
|
||||
Bsub[off] = bonus
|
||||
prevClass = class
|
||||
|
||||
if char == pchar {
|
||||
if pidx < M {
|
||||
F[pidx] = int32(off)
|
||||
F[pidx] = int32(idx + off)
|
||||
pidx++
|
||||
pchar = pattern[min(pidx, M-1)]
|
||||
pchar = pattern[util.Min(pidx, M-1)]
|
||||
}
|
||||
lastIdx = off
|
||||
lastIdx = idx + off
|
||||
}
|
||||
|
||||
if char == pchar0 {
|
||||
score := scoreMatch + bonus*bonusFirstCharMultiplier
|
||||
H0[off] = score
|
||||
C0[off] = 1
|
||||
H0sub[off] = score
|
||||
C0sub[off] = 1
|
||||
if M == 1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
||||
maxScore, maxScorePos = score, off
|
||||
if forward && bonus >= bonusBoundary {
|
||||
maxScore, maxScorePos = score, idx+off
|
||||
if forward && bonus == bonusBoundary {
|
||||
break
|
||||
}
|
||||
}
|
||||
inGap = false
|
||||
} else {
|
||||
if inGap {
|
||||
H0[off] = max(prevH0+scoreGapExtension, 0)
|
||||
H0sub[off] = util.Max16(prevH0+scoreGapExtension, 0)
|
||||
} else {
|
||||
H0[off] = max(prevH0+scoreGapStart, 0)
|
||||
H0sub[off] = util.Max16(prevH0+scoreGapStart, 0)
|
||||
}
|
||||
C0[off] = 0
|
||||
C0sub[off] = 0
|
||||
inGap = true
|
||||
}
|
||||
prevH0 = H0[off]
|
||||
prevH0 = H0sub[off]
|
||||
}
|
||||
if pidx != M {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
if M == 1 {
|
||||
result := Result{minIdx + maxScorePos, minIdx + maxScorePos + 1, int(maxScore)}
|
||||
result := Result{maxScorePos, maxScorePos + 1, int(maxScore)}
|
||||
if !withPos {
|
||||
return result, nil
|
||||
}
|
||||
pos := []int{minIdx + maxScorePos}
|
||||
pos := []int{maxScorePos}
|
||||
return result, &pos
|
||||
}
|
||||
|
||||
@@ -579,14 +486,11 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
s1 = Hdiag[off] + scoreMatch
|
||||
b := Bsub[off]
|
||||
consecutive = Cdiag[off] + 1
|
||||
if consecutive > 1 {
|
||||
fb := B[col-int(consecutive)+1]
|
||||
// Break consecutive chunk
|
||||
if b >= bonusBoundary && b > fb {
|
||||
consecutive = 1
|
||||
} else {
|
||||
b = max(b, bonusConsecutive, fb)
|
||||
}
|
||||
// Break consecutive chunk
|
||||
if b == bonusBoundary {
|
||||
consecutive = 1
|
||||
} else if consecutive > 1 {
|
||||
b = util.Max16(b, util.Max16(bonusConsecutive, B[col-int(consecutive)+1]))
|
||||
}
|
||||
if s1+b < s2 {
|
||||
s1 += Bsub[off]
|
||||
@@ -598,7 +502,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
Csub[off] = consecutive
|
||||
|
||||
inGap = s1 < s2
|
||||
score := max(s1, s2, 0)
|
||||
score := util.Max16(util.Max16(s1, s2), 0)
|
||||
if pidx == M-1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
||||
maxScore, maxScorePos = score, col
|
||||
}
|
||||
@@ -631,7 +535,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
}
|
||||
|
||||
if s > s1 && (s > s2 || s == s2 && preferMatch) {
|
||||
*pos = append(*pos, j+minIdx)
|
||||
*pos = append(*pos, j)
|
||||
if i == 0 {
|
||||
break
|
||||
}
|
||||
@@ -644,14 +548,14 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
||||
// Start offset we return here is only relevant when begin tiebreak is used.
|
||||
// However finding the accurate offset requires backtracking, and we don't
|
||||
// want to pay extra cost for the option that has lost its importance.
|
||||
return Result{minIdx + j, minIdx + maxScorePos + 1, int(maxScore)}, pos
|
||||
return Result{j, maxScorePos + 1, int(maxScore)}, pos
|
||||
}
|
||||
|
||||
// Implement the same sorting criteria as V2
|
||||
func calculateScore(caseSensitive bool, normalize bool, text *util.Chars, pattern []rune, sidx int, eidx int, withPos bool) (int, *[]int) {
|
||||
pidx, score, inGap, consecutive, firstBonus := 0, 0, false, 0, int16(0)
|
||||
pos := posArray(withPos, len(pattern))
|
||||
prevClass := initialCharClass
|
||||
prevClass := charNonWord
|
||||
if sidx > 0 {
|
||||
prevClass = charClassOf(text.Get(sidx - 1))
|
||||
}
|
||||
@@ -674,15 +578,15 @@ func calculateScore(caseSensitive bool, normalize bool, text *util.Chars, patter
|
||||
*pos = append(*pos, idx)
|
||||
}
|
||||
score += scoreMatch
|
||||
bonus := bonusMatrix[prevClass][class]
|
||||
bonus := bonusFor(prevClass, class)
|
||||
if consecutive == 0 {
|
||||
firstBonus = bonus
|
||||
} else {
|
||||
// Break consecutive chunk
|
||||
if bonus >= bonusBoundary && bonus > firstBonus {
|
||||
if bonus == bonusBoundary {
|
||||
firstBonus = bonus
|
||||
}
|
||||
bonus = max(bonus, firstBonus, bonusConsecutive)
|
||||
bonus = util.Max16(util.Max16(bonus, firstBonus), bonusConsecutive)
|
||||
}
|
||||
if pidx == 0 {
|
||||
score += int(bonus * bonusFirstCharMultiplier)
|
||||
@@ -712,8 +616,7 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
||||
if len(pattern) == 0 {
|
||||
return Result{0, 0, 0}, nil
|
||||
}
|
||||
idx, _ := asciiFuzzyIndex(text, pattern, caseSensitive)
|
||||
if idx < 0 {
|
||||
if asciiFuzzyIndex(text, pattern, caseSensitive) < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
@@ -724,7 +627,7 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
||||
lenRunes := text.Length()
|
||||
lenPattern := len(pattern)
|
||||
|
||||
for index := range lenRunes {
|
||||
for index := 0; index < lenRunes; index++ {
|
||||
char := text.Get(indexAt(index, lenRunes, forward))
|
||||
// This is considerably faster than blindly applying strings.ToLower to the
|
||||
// whole string
|
||||
@@ -765,9 +668,6 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
|
||||
pidx_ := indexAt(pidx, lenPattern, forward)
|
||||
pchar := pattern[pidx_]
|
||||
@@ -799,14 +699,6 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
||||
// The solution is much cheaper since there is only one possible alignment of
|
||||
// the pattern.
|
||||
func ExactMatchNaive(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
return exactMatchNaive(caseSensitive, normalize, forward, false, text, pattern, withPos, slab)
|
||||
}
|
||||
|
||||
func ExactMatchBoundary(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
return exactMatchNaive(caseSensitive, normalize, forward, true, text, pattern, withPos, slab)
|
||||
}
|
||||
|
||||
func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryCheck bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
if len(pattern) == 0 {
|
||||
return Result{0, 0, 0}, nil
|
||||
}
|
||||
@@ -818,14 +710,13 @@ func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryC
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
idx, _ := asciiFuzzyIndex(text, pattern, caseSensitive)
|
||||
if idx < 0 {
|
||||
if asciiFuzzyIndex(text, pattern, caseSensitive) < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// For simplicity, only look at the bonus at the first character position
|
||||
pidx := 0
|
||||
bestPos, bonus, bbonus, bestBonus := -1, int16(0), int16(0), int16(-1)
|
||||
bestPos, bonus, bestBonus := -1, int16(0), int16(-1)
|
||||
for index := 0; index < lenRunes; index++ {
|
||||
index_ := indexAt(index, lenRunes, forward)
|
||||
char := text.Get(index_)
|
||||
@@ -841,37 +732,16 @@ func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryC
|
||||
}
|
||||
pidx_ := indexAt(pidx, lenPattern, forward)
|
||||
pchar := pattern[pidx_]
|
||||
ok := pchar == char
|
||||
if ok {
|
||||
if pchar == char {
|
||||
if pidx_ == 0 {
|
||||
bonus = bonusAt(text, index_)
|
||||
}
|
||||
if boundaryCheck {
|
||||
if forward && pidx_ == 0 {
|
||||
bbonus = bonus
|
||||
} else if !forward && pidx_ == lenPattern-1 {
|
||||
if index_ < lenRunes-1 {
|
||||
bbonus = bonusAt(text, index_+1)
|
||||
} else {
|
||||
bbonus = bonusBoundaryWhite
|
||||
}
|
||||
}
|
||||
ok = bbonus >= bonusBoundary
|
||||
if ok && pidx_ == 0 {
|
||||
ok = index_ == 0 || charClassOf(text.Get(index_-1)) <= charDelimiter
|
||||
}
|
||||
if ok && pidx_ == len(pattern)-1 {
|
||||
ok = index_ == lenRunes-1 || charClassOf(text.Get(index_+1)) <= charDelimiter
|
||||
}
|
||||
}
|
||||
}
|
||||
if ok {
|
||||
pidx++
|
||||
if pidx == lenPattern {
|
||||
if bonus > bestBonus {
|
||||
bestPos, bestBonus = index, bonus
|
||||
}
|
||||
if bonus >= bonusBoundary {
|
||||
if bonus == bonusBoundary {
|
||||
break
|
||||
}
|
||||
index -= pidx - 1
|
||||
@@ -891,23 +761,7 @@ func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryC
|
||||
sidx = lenRunes - (bestPos + 1)
|
||||
eidx = lenRunes - (bestPos - lenPattern + 1)
|
||||
}
|
||||
var score int
|
||||
if boundaryCheck {
|
||||
// Underscore boundaries should be ranked lower than the other types of boundaries
|
||||
score = int(bonus)
|
||||
deduct := int(bonus-bonusBoundary) + 1
|
||||
if sidx > 0 && text.Get(sidx-1) == '_' {
|
||||
score -= deduct + 1
|
||||
deduct = 1
|
||||
}
|
||||
if eidx < lenRunes && text.Get(eidx) == '_' {
|
||||
score -= deduct
|
||||
}
|
||||
// Add base score so that this can compete with other match types e.g. 'foo' | bar
|
||||
score += scoreMatch*lenPattern + int(bonusBoundaryWhite)*(lenPattern+1)
|
||||
} else {
|
||||
score, _ = calculateScore(caseSensitive, normalize, text, pattern, sidx, eidx, false)
|
||||
}
|
||||
score, _ := calculateScore(caseSensitive, normalize, text, pattern, sidx, eidx, false)
|
||||
return Result{sidx, eidx, score}, nil
|
||||
}
|
||||
return Result{-1, -1, 0}, nil
|
||||
@@ -1023,8 +877,8 @@ func EqualMatch(caseSensitive bool, normalize bool, forward bool, text *util.Cha
|
||||
match = runesStr == string(pattern)
|
||||
}
|
||||
if match {
|
||||
return Result{trimmedLen, trimmedLen + lenPattern, (scoreMatch+int(bonusBoundaryWhite))*lenPattern +
|
||||
(bonusFirstCharMultiplier-1)*int(bonusBoundaryWhite)}, nil
|
||||
return Result{trimmedLen, trimmedLen + lenPattern, (scoreMatch+bonusBoundary)*lenPattern +
|
||||
(bonusFirstCharMultiplier-1)*bonusBoundary}, nil
|
||||
}
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
+22
-45
@@ -9,10 +9,6 @@ import (
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func init() {
|
||||
Init("default")
|
||||
}
|
||||
|
||||
func assertMatch(t *testing.T, fun Algo, caseSensitive, forward bool, input, pattern string, sidx int, eidx int, score int) {
|
||||
assertMatch2(t, fun, caseSensitive, false, forward, input, pattern, sidx, eidx, score)
|
||||
}
|
||||
@@ -49,38 +45,29 @@ func TestFuzzyMatch(t *testing.T) {
|
||||
assertMatch(t, fn, false, forward, "fooBarbaz1", "oBZ", 2, 9,
|
||||
scoreMatch*3+bonusCamel123+scoreGapStart+scoreGapExtension*3)
|
||||
assertMatch(t, fn, false, forward, "foo bar baz", "fbb", 0, 9,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+
|
||||
int(bonusBoundaryWhite)*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusBoundary*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "/AutomatorDocument.icns", "rdoc", 9, 13,
|
||||
scoreMatch*4+bonusCamel123+bonusConsecutive*2)
|
||||
assertMatch(t, fn, false, forward, "/man1/zshcompctl.1", "zshc", 6, 10,
|
||||
scoreMatch*4+int(bonusBoundaryDelimiter)*bonusFirstCharMultiplier+int(bonusBoundaryDelimiter)*3)
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3)
|
||||
assertMatch(t, fn, false, forward, "/.oh-my-zsh/cache", "zshc", 8, 13,
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*2+scoreGapStart+int(bonusBoundaryDelimiter))
|
||||
// Non-word character at start of input is treated as a strong boundary
|
||||
assertMatch(t, fn, false, forward, ".vimrc", ".vimrc", 0, 6,
|
||||
scoreMatch*6+int(bonusBoundaryWhite)*(bonusFirstCharMultiplier+5))
|
||||
// Non-word character right after a delimiter inherits the delimiter boundary
|
||||
assertMatch(t, fn, false, forward, "/.vimrc", ".vimrc", 1, 7,
|
||||
scoreMatch*6+int(bonusBoundaryDelimiter)*(bonusFirstCharMultiplier+5))
|
||||
// Non-word character in the middle of a word stays at bonusNonWord
|
||||
assertMatch(t, fn, false, forward, "a.vimrc", ".vimrc", 1, 7,
|
||||
scoreMatch*6+bonusBoundary*(bonusFirstCharMultiplier+5))
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3+scoreGapStart)
|
||||
assertMatch(t, fn, false, forward, "ab0123 456", "12356", 3, 10,
|
||||
scoreMatch*5+bonusConsecutive*3+scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "abc123 456", "12356", 3, 10,
|
||||
scoreMatch*5+bonusCamel123*bonusFirstCharMultiplier+bonusCamel123*2+bonusConsecutive+scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "foo/bar/baz", "fbb", 0, 9,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+
|
||||
int(bonusBoundaryDelimiter)*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusBoundary*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "fooBarBaz", "fbb", 0, 7,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusCamel123*2+2*scoreGapStart+2*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "foo barbaz", "fbb", 0, 8,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite)+
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary+
|
||||
scoreGapStart*2+scoreGapExtension*3)
|
||||
assertMatch(t, fn, false, forward, "fooBar Baz", "foob", 0, 4,
|
||||
scoreMatch*4+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite)*3)
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3)
|
||||
assertMatch(t, fn, false, forward, "xFoo-Bar Baz", "foo-b", 1, 6,
|
||||
scoreMatch*5+bonusCamel123*bonusFirstCharMultiplier+bonusCamel123*2+
|
||||
bonusNonWord+bonusBoundary)
|
||||
@@ -88,14 +75,14 @@ func TestFuzzyMatch(t *testing.T) {
|
||||
assertMatch(t, fn, true, forward, "fooBarbaz", "oBz", 2, 9,
|
||||
scoreMatch*3+bonusCamel123+scoreGapStart+scoreGapExtension*3)
|
||||
assertMatch(t, fn, true, forward, "Foo/Bar/Baz", "FBB", 0, 9,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryDelimiter)*2+
|
||||
scoreMatch*3+bonusBoundary*(bonusFirstCharMultiplier+2)+
|
||||
scoreGapStart*2+scoreGapExtension*4)
|
||||
assertMatch(t, fn, true, forward, "FooBarBaz", "FBB", 0, 7,
|
||||
scoreMatch*3+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+bonusCamel123*2+
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+bonusCamel123*2+
|
||||
scoreGapStart*2+scoreGapExtension*2)
|
||||
assertMatch(t, fn, true, forward, "FooBar Baz", "FooB", 0, 4,
|
||||
scoreMatch*4+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite)*2+
|
||||
max(bonusCamel123, int(bonusBoundaryWhite)))
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*2+
|
||||
util.Max(bonusCamel123, bonusBoundary))
|
||||
|
||||
// Consecutive bonus updated
|
||||
assertMatch(t, fn, true, forward, "foo-bar", "o-ba", 2, 6,
|
||||
@@ -111,10 +98,10 @@ func TestFuzzyMatch(t *testing.T) {
|
||||
|
||||
func TestFuzzyMatchBackward(t *testing.T) {
|
||||
assertMatch(t, FuzzyMatchV1, false, true, "foobar fb", "fb", 0, 4,
|
||||
scoreMatch*2+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+
|
||||
scoreMatch*2+bonusBoundary*bonusFirstCharMultiplier+
|
||||
scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, FuzzyMatchV1, false, false, "foobar fb", "fb", 7, 9,
|
||||
scoreMatch*2+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite))
|
||||
scoreMatch*2+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary)
|
||||
}
|
||||
|
||||
func TestExactMatchNaive(t *testing.T) {
|
||||
@@ -127,9 +114,9 @@ func TestExactMatchNaive(t *testing.T) {
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/AutomatorDocument.icns", "rdoc", 9, 13,
|
||||
scoreMatch*4+bonusCamel123+bonusConsecutive*2)
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/man1/zshcompctl.1", "zshc", 6, 10,
|
||||
scoreMatch*4+int(bonusBoundaryDelimiter)*(bonusFirstCharMultiplier+3))
|
||||
scoreMatch*4+bonusBoundary*(bonusFirstCharMultiplier+3))
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/.oh-my-zsh/cache", "zsh/c", 8, 13,
|
||||
scoreMatch*5+bonusBoundary*(bonusFirstCharMultiplier+3)+int(bonusBoundaryDelimiter))
|
||||
scoreMatch*5+bonusBoundary*(bonusFirstCharMultiplier+4))
|
||||
}
|
||||
}
|
||||
|
||||
@@ -141,7 +128,7 @@ func TestExactMatchNaiveBackward(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestPrefixMatch(t *testing.T) {
|
||||
score := scoreMatch*3 + int(bonusBoundaryWhite)*bonusFirstCharMultiplier + int(bonusBoundaryWhite)*2
|
||||
score := (scoreMatch+bonusBoundary)*3 + bonusBoundary*(bonusFirstCharMultiplier-1)
|
||||
|
||||
for _, dir := range []bool{true, false} {
|
||||
assertMatch(t, PrefixMatch, true, dir, "fooBarbaz", "Foo", -1, -1, 0)
|
||||
@@ -169,10 +156,9 @@ func TestSuffixMatch(t *testing.T) {
|
||||
// Strip trailing white space from the string
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz ", "baz", 6, 9,
|
||||
scoreMatch*3+bonusConsecutive*2)
|
||||
|
||||
// Only when the pattern doesn't end with a space
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz ", "baz ", 6, 10,
|
||||
scoreMatch*4+bonusConsecutive*2+int(bonusBoundaryWhite))
|
||||
scoreMatch*4+bonusConsecutive*2+bonusNonWord)
|
||||
}
|
||||
}
|
||||
|
||||
@@ -196,9 +182,9 @@ func TestNormalize(t *testing.T) {
|
||||
input, pattern, sidx, eidx, score)
|
||||
}
|
||||
}
|
||||
test("Só Danço Samba", "So", 0, 2, 62, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, ExactMatchNaive)
|
||||
test("Só Danço Samba", "sodc", 0, 7, 97, FuzzyMatchV1, FuzzyMatchV2)
|
||||
test("Danço", "danco", 0, 5, 140, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, SuffixMatch, ExactMatchNaive, EqualMatch)
|
||||
test("Só Danço Samba", "So", 0, 2, 56, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, ExactMatchNaive)
|
||||
test("Só Danço Samba", "sodc", 0, 7, 89, FuzzyMatchV1, FuzzyMatchV2)
|
||||
test("Danço", "danco", 0, 5, 128, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, SuffixMatch, ExactMatchNaive, EqualMatch)
|
||||
}
|
||||
|
||||
func TestLongString(t *testing.T) {
|
||||
@@ -209,12 +195,3 @@ func TestLongString(t *testing.T) {
|
||||
bytes[math.MaxUint16] = 'z'
|
||||
assertMatch(t, FuzzyMatchV2, true, true, string(bytes), "zx", math.MaxUint16, math.MaxUint16+2, scoreMatch*2+bonusConsecutive)
|
||||
}
|
||||
|
||||
func TestLongStringWithNormalize(t *testing.T) {
|
||||
bytes := make([]byte, 30000)
|
||||
for i := range bytes {
|
||||
bytes[i] = 'x'
|
||||
}
|
||||
unicodeString := string(bytes) + " Minímal example"
|
||||
assertMatch2(t, FuzzyMatchV1, false, true, false, unicodeString, "minim", 30001, 30006, 140)
|
||||
}
|
||||
|
||||
@@ -1,24 +0,0 @@
|
||||
//go:build amd64
|
||||
|
||||
package algo
|
||||
|
||||
var _useAVX2 bool
|
||||
|
||||
func init() {
|
||||
_useAVX2 = cpuHasAVX2()
|
||||
}
|
||||
|
||||
//go:noescape
|
||||
func cpuHasAVX2() bool
|
||||
|
||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present. Uses AVX2 when available, SSE2 otherwise.
|
||||
//
|
||||
//go:noescape
|
||||
func IndexByteTwo(s []byte, b1, b2 byte) int
|
||||
|
||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present. Uses AVX2 when available, SSE2 otherwise.
|
||||
//
|
||||
//go:noescape
|
||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
||||
@@ -1,377 +0,0 @@
|
||||
#include "textflag.h"
|
||||
|
||||
// func cpuHasAVX2() bool
|
||||
//
|
||||
// Checks CPUID and XGETBV for AVX2 + OS YMM support.
|
||||
TEXT ·cpuHasAVX2(SB),NOSPLIT,$0-1
|
||||
MOVQ BX, R8 // save BX (callee-saved, clobbered by CPUID)
|
||||
|
||||
// Check max CPUID leaf >= 7
|
||||
MOVL $0, AX
|
||||
CPUID
|
||||
CMPL AX, $7
|
||||
JL cpuid_no
|
||||
|
||||
// Check OSXSAVE (CPUID.1:ECX bit 27)
|
||||
MOVL $1, AX
|
||||
CPUID
|
||||
TESTL $(1<<27), CX
|
||||
JZ cpuid_no
|
||||
|
||||
// Check AVX2 (CPUID.7.0:EBX bit 5)
|
||||
MOVL $7, AX
|
||||
MOVL $0, CX
|
||||
CPUID
|
||||
TESTL $(1<<5), BX
|
||||
JZ cpuid_no
|
||||
|
||||
// Check OS YMM state support via XGETBV
|
||||
MOVL $0, CX
|
||||
BYTE $0x0F; BYTE $0x01; BYTE $0xD0 // XGETBV → EDX:EAX
|
||||
ANDL $6, AX // bits 1 (XMM) and 2 (YMM)
|
||||
CMPL AX, $6
|
||||
JNE cpuid_no
|
||||
|
||||
MOVQ R8, BX // restore BX
|
||||
MOVB $1, ret+0(FP)
|
||||
RET
|
||||
|
||||
cpuid_no:
|
||||
MOVQ R8, BX
|
||||
MOVB $0, ret+0(FP)
|
||||
RET
|
||||
|
||||
// func IndexByteTwo(s []byte, b1, b2 byte) int
|
||||
//
|
||||
// Returns the index of the first occurrence of b1 or b2 in s, or -1.
|
||||
// Uses AVX2 (32 bytes/iter) when available, SSE2 (16 bytes/iter) otherwise.
|
||||
TEXT ·IndexByteTwo(SB),NOSPLIT,$0-40
|
||||
MOVQ s_base+0(FP), SI
|
||||
MOVQ s_len+8(FP), BX
|
||||
MOVBLZX b1+24(FP), AX
|
||||
MOVBLZX b2+25(FP), CX
|
||||
LEAQ ret+32(FP), R8
|
||||
|
||||
TESTQ BX, BX
|
||||
JEQ fwd_failure
|
||||
|
||||
// Try AVX2 for inputs >= 32 bytes
|
||||
CMPQ BX, $32
|
||||
JLT fwd_sse2
|
||||
CMPB ·_useAVX2(SB), $1
|
||||
JNE fwd_sse2
|
||||
|
||||
// ====== AVX2 forward search ======
|
||||
MOVD AX, X0
|
||||
VPBROADCASTB X0, Y0 // Y0 = splat(b1)
|
||||
MOVD CX, X1
|
||||
VPBROADCASTB X1, Y1 // Y1 = splat(b2)
|
||||
|
||||
MOVQ SI, DI
|
||||
LEAQ -32(SI)(BX*1), AX // AX = last valid 32-byte chunk
|
||||
JMP fwd_avx2_entry
|
||||
|
||||
fwd_avx2_loop:
|
||||
VMOVDQU (DI), Y2
|
||||
VPCMPEQB Y0, Y2, Y3
|
||||
VPCMPEQB Y1, Y2, Y4
|
||||
VPOR Y3, Y4, Y3
|
||||
VPMOVMSKB Y3, DX
|
||||
BSFL DX, DX
|
||||
JNZ fwd_avx2_success
|
||||
ADDQ $32, DI
|
||||
|
||||
fwd_avx2_entry:
|
||||
CMPQ DI, AX
|
||||
JB fwd_avx2_loop
|
||||
|
||||
// Last 32-byte chunk (may overlap with previous)
|
||||
MOVQ AX, DI
|
||||
VMOVDQU (AX), Y2
|
||||
VPCMPEQB Y0, Y2, Y3
|
||||
VPCMPEQB Y1, Y2, Y4
|
||||
VPOR Y3, Y4, Y3
|
||||
VPMOVMSKB Y3, DX
|
||||
BSFL DX, DX
|
||||
JNZ fwd_avx2_success
|
||||
|
||||
MOVQ $-1, (R8)
|
||||
VZEROUPPER
|
||||
RET
|
||||
|
||||
fwd_avx2_success:
|
||||
SUBQ SI, DI
|
||||
ADDQ DX, DI
|
||||
MOVQ DI, (R8)
|
||||
VZEROUPPER
|
||||
RET
|
||||
|
||||
// ====== SSE2 forward search (< 32 bytes or no AVX2) ======
|
||||
|
||||
fwd_sse2:
|
||||
// Broadcast b1 into X0
|
||||
MOVD AX, X0
|
||||
PUNPCKLBW X0, X0
|
||||
PUNPCKLBW X0, X0
|
||||
PSHUFL $0, X0, X0
|
||||
|
||||
// Broadcast b2 into X4
|
||||
MOVD CX, X4
|
||||
PUNPCKLBW X4, X4
|
||||
PUNPCKLBW X4, X4
|
||||
PSHUFL $0, X4, X4
|
||||
|
||||
CMPQ BX, $16
|
||||
JLT fwd_small
|
||||
|
||||
MOVQ SI, DI
|
||||
LEAQ -16(SI)(BX*1), AX
|
||||
JMP fwd_sseloopentry
|
||||
|
||||
fwd_sseloop:
|
||||
MOVOU (DI), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
BSFL DX, DX
|
||||
JNZ fwd_ssesuccess
|
||||
ADDQ $16, DI
|
||||
|
||||
fwd_sseloopentry:
|
||||
CMPQ DI, AX
|
||||
JB fwd_sseloop
|
||||
|
||||
// Search the last 16-byte chunk (may overlap)
|
||||
MOVQ AX, DI
|
||||
MOVOU (AX), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
BSFL DX, DX
|
||||
JNZ fwd_ssesuccess
|
||||
|
||||
fwd_failure:
|
||||
MOVQ $-1, (R8)
|
||||
RET
|
||||
|
||||
fwd_ssesuccess:
|
||||
SUBQ SI, DI
|
||||
ADDQ DX, DI
|
||||
MOVQ DI, (R8)
|
||||
RET
|
||||
|
||||
fwd_small:
|
||||
// Check if loading 16 bytes from SI would cross a page boundary
|
||||
LEAQ 16(SI), AX
|
||||
TESTW $0xff0, AX
|
||||
JEQ fwd_endofpage
|
||||
|
||||
MOVOU (SI), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
BSFL DX, DX
|
||||
JZ fwd_failure
|
||||
CMPL DX, BX
|
||||
JAE fwd_failure
|
||||
MOVQ DX, (R8)
|
||||
RET
|
||||
|
||||
fwd_endofpage:
|
||||
MOVOU -16(SI)(BX*1), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
MOVL BX, CX
|
||||
SHLL CX, DX
|
||||
SHRL $16, DX
|
||||
BSFL DX, DX
|
||||
JZ fwd_failure
|
||||
MOVQ DX, (R8)
|
||||
RET
|
||||
|
||||
// func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
||||
//
|
||||
// Returns the index of the last occurrence of b1 or b2 in s, or -1.
|
||||
// Uses AVX2 (32 bytes/iter) when available, SSE2 (16 bytes/iter) otherwise.
|
||||
TEXT ·lastIndexByteTwo(SB),NOSPLIT,$0-40
|
||||
MOVQ s_base+0(FP), SI
|
||||
MOVQ s_len+8(FP), BX
|
||||
MOVBLZX b1+24(FP), AX
|
||||
MOVBLZX b2+25(FP), CX
|
||||
LEAQ ret+32(FP), R8
|
||||
|
||||
TESTQ BX, BX
|
||||
JEQ back_failure
|
||||
|
||||
// Try AVX2 for inputs >= 32 bytes
|
||||
CMPQ BX, $32
|
||||
JLT back_sse2
|
||||
CMPB ·_useAVX2(SB), $1
|
||||
JNE back_sse2
|
||||
|
||||
// ====== AVX2 backward search ======
|
||||
MOVD AX, X0
|
||||
VPBROADCASTB X0, Y0
|
||||
MOVD CX, X1
|
||||
VPBROADCASTB X1, Y1
|
||||
|
||||
// DI = start of last 32-byte chunk
|
||||
LEAQ -32(SI)(BX*1), DI
|
||||
|
||||
back_avx2_loop:
|
||||
CMPQ DI, SI
|
||||
JBE back_avx2_first
|
||||
|
||||
VMOVDQU (DI), Y2
|
||||
VPCMPEQB Y0, Y2, Y3
|
||||
VPCMPEQB Y1, Y2, Y4
|
||||
VPOR Y3, Y4, Y3
|
||||
VPMOVMSKB Y3, DX
|
||||
BSRL DX, DX
|
||||
JNZ back_avx2_success
|
||||
SUBQ $32, DI
|
||||
JMP back_avx2_loop
|
||||
|
||||
back_avx2_first:
|
||||
// First 32 bytes (DI <= SI, load from SI)
|
||||
VMOVDQU (SI), Y2
|
||||
VPCMPEQB Y0, Y2, Y3
|
||||
VPCMPEQB Y1, Y2, Y4
|
||||
VPOR Y3, Y4, Y3
|
||||
VPMOVMSKB Y3, DX
|
||||
BSRL DX, DX
|
||||
JNZ back_avx2_firstsuccess
|
||||
|
||||
MOVQ $-1, (R8)
|
||||
VZEROUPPER
|
||||
RET
|
||||
|
||||
back_avx2_success:
|
||||
SUBQ SI, DI
|
||||
ADDQ DX, DI
|
||||
MOVQ DI, (R8)
|
||||
VZEROUPPER
|
||||
RET
|
||||
|
||||
back_avx2_firstsuccess:
|
||||
MOVQ DX, (R8)
|
||||
VZEROUPPER
|
||||
RET
|
||||
|
||||
// ====== SSE2 backward search (< 32 bytes or no AVX2) ======
|
||||
|
||||
back_sse2:
|
||||
// Broadcast b1 into X0
|
||||
MOVD AX, X0
|
||||
PUNPCKLBW X0, X0
|
||||
PUNPCKLBW X0, X0
|
||||
PSHUFL $0, X0, X0
|
||||
|
||||
// Broadcast b2 into X4
|
||||
MOVD CX, X4
|
||||
PUNPCKLBW X4, X4
|
||||
PUNPCKLBW X4, X4
|
||||
PSHUFL $0, X4, X4
|
||||
|
||||
CMPQ BX, $16
|
||||
JLT back_small
|
||||
|
||||
// DI = start of last 16-byte chunk
|
||||
LEAQ -16(SI)(BX*1), DI
|
||||
|
||||
back_sseloop:
|
||||
CMPQ DI, SI
|
||||
JBE back_ssefirst
|
||||
|
||||
MOVOU (DI), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
BSRL DX, DX
|
||||
JNZ back_ssesuccess
|
||||
SUBQ $16, DI
|
||||
JMP back_sseloop
|
||||
|
||||
back_ssefirst:
|
||||
// First 16 bytes (DI <= SI, load from SI)
|
||||
MOVOU (SI), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
BSRL DX, DX
|
||||
JNZ back_ssefirstsuccess
|
||||
|
||||
back_failure:
|
||||
MOVQ $-1, (R8)
|
||||
RET
|
||||
|
||||
back_ssesuccess:
|
||||
SUBQ SI, DI
|
||||
ADDQ DX, DI
|
||||
MOVQ DI, (R8)
|
||||
RET
|
||||
|
||||
back_ssefirstsuccess:
|
||||
// DX = byte offset from base
|
||||
MOVQ DX, (R8)
|
||||
RET
|
||||
|
||||
back_small:
|
||||
// Check page boundary
|
||||
LEAQ 16(SI), AX
|
||||
TESTW $0xff0, AX
|
||||
JEQ back_endofpage
|
||||
|
||||
MOVOU (SI), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
// Mask to first BX bytes: keep bits 0..BX-1
|
||||
MOVL $1, AX
|
||||
MOVL BX, CX
|
||||
SHLL CX, AX
|
||||
DECL AX
|
||||
ANDL AX, DX
|
||||
BSRL DX, DX
|
||||
JZ back_failure
|
||||
MOVQ DX, (R8)
|
||||
RET
|
||||
|
||||
back_endofpage:
|
||||
// Load 16 bytes ending at base+n
|
||||
MOVOU -16(SI)(BX*1), X1
|
||||
MOVOU X1, X2
|
||||
PCMPEQB X0, X1
|
||||
PCMPEQB X4, X2
|
||||
POR X2, X1
|
||||
PMOVMSKB X1, DX
|
||||
// Bits correspond to bytes [base+n-16, base+n).
|
||||
// We want original bytes [0, n), which are bits [16-n, 16).
|
||||
// Mask: keep bits (16-n) through 15.
|
||||
MOVL $16, CX
|
||||
SUBL BX, CX
|
||||
SHRL CX, DX
|
||||
SHLL CX, DX
|
||||
BSRL DX, DX
|
||||
JZ back_failure
|
||||
// DX is the bit position in the loaded chunk.
|
||||
// Original byte index = DX - (16 - n) = DX + n - 16
|
||||
ADDL BX, DX
|
||||
SUBL $16, DX
|
||||
MOVQ DX, (R8)
|
||||
RET
|
||||
@@ -1,17 +0,0 @@
|
||||
//go:build arm64
|
||||
|
||||
package algo
|
||||
|
||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present. Implemented in assembly using ARM64 NEON
|
||||
// to search for both bytes in a single pass.
|
||||
//
|
||||
//go:noescape
|
||||
func IndexByteTwo(s []byte, b1, b2 byte) int
|
||||
|
||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present. Implemented in assembly using ARM64 NEON,
|
||||
// scanning backward.
|
||||
//
|
||||
//go:noescape
|
||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
||||
@@ -1,249 +0,0 @@
|
||||
#include "textflag.h"
|
||||
|
||||
// func IndexByteTwo(s []byte, b1, b2 byte) int
|
||||
//
|
||||
// Returns the index of the first occurrence of b1 or b2 in s, or -1.
|
||||
// Uses ARM64 NEON to search for both bytes in a single pass over the data.
|
||||
// Adapted from Go's internal/bytealg/indexbyte_arm64.s (single-byte version).
|
||||
TEXT ·IndexByteTwo(SB),NOSPLIT,$0-40
|
||||
MOVD s_base+0(FP), R0
|
||||
MOVD s_len+8(FP), R2
|
||||
MOVBU b1+24(FP), R1
|
||||
MOVBU b2+25(FP), R7
|
||||
MOVD $ret+32(FP), R8
|
||||
|
||||
// Core algorithm:
|
||||
// For each 32-byte chunk we calculate a 64-bit syndrome value,
|
||||
// with two bits per byte. We compare against both b1 and b2,
|
||||
// OR the results, then use the same syndrome extraction as
|
||||
// Go's IndexByte.
|
||||
|
||||
CBZ R2, fail
|
||||
MOVD R0, R11
|
||||
// Magic constant 0x40100401 allows us to identify which lane matches.
|
||||
// Each byte in the group of 4 gets a distinct bit: 1, 4, 16, 64.
|
||||
MOVD $0x40100401, R5
|
||||
VMOV R1, V0.B16 // V0 = splat(b1)
|
||||
VMOV R7, V7.B16 // V7 = splat(b2)
|
||||
// Work with aligned 32-byte chunks
|
||||
BIC $0x1f, R0, R3
|
||||
VMOV R5, V5.S4
|
||||
ANDS $0x1f, R0, R9
|
||||
AND $0x1f, R2, R10
|
||||
BEQ loop
|
||||
|
||||
// Input string is not 32-byte aligned. Process the first
|
||||
// aligned 32-byte block and mask off bytes before our start.
|
||||
VLD1.P (R3), [V1.B16, V2.B16]
|
||||
SUB $0x20, R9, R4
|
||||
ADDS R4, R2, R2
|
||||
// Compare against both needles
|
||||
VCMEQ V0.B16, V1.B16, V3.B16 // b1 vs first 16 bytes
|
||||
VCMEQ V7.B16, V1.B16, V8.B16 // b2 vs first 16 bytes
|
||||
VORR V8.B16, V3.B16, V3.B16 // combine
|
||||
VCMEQ V0.B16, V2.B16, V4.B16 // b1 vs second 16 bytes
|
||||
VCMEQ V7.B16, V2.B16, V9.B16 // b2 vs second 16 bytes
|
||||
VORR V9.B16, V4.B16, V4.B16 // combine
|
||||
// Build syndrome
|
||||
VAND V5.B16, V3.B16, V3.B16
|
||||
VAND V5.B16, V4.B16, V4.B16
|
||||
VADDP V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.B16, V6.B16, V6.B16
|
||||
VMOV V6.D[0], R6
|
||||
// Clear the irrelevant lower bits
|
||||
LSL $1, R9, R4
|
||||
LSR R4, R6, R6
|
||||
LSL R4, R6, R6
|
||||
// The first block can also be the last
|
||||
BLS masklast
|
||||
// Have we found something already?
|
||||
CBNZ R6, tail
|
||||
|
||||
loop:
|
||||
VLD1.P (R3), [V1.B16, V2.B16]
|
||||
SUBS $0x20, R2, R2
|
||||
// Compare against both needles, OR results
|
||||
VCMEQ V0.B16, V1.B16, V3.B16
|
||||
VCMEQ V7.B16, V1.B16, V8.B16
|
||||
VORR V8.B16, V3.B16, V3.B16
|
||||
VCMEQ V0.B16, V2.B16, V4.B16
|
||||
VCMEQ V7.B16, V2.B16, V9.B16
|
||||
VORR V9.B16, V4.B16, V4.B16
|
||||
// If we're out of data we finish regardless of the result
|
||||
BLS end
|
||||
// Fast check: OR both halves and check for any match
|
||||
VORR V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.D2, V6.D2, V6.D2
|
||||
VMOV V6.D[0], R6
|
||||
CBZ R6, loop
|
||||
|
||||
end:
|
||||
// Found something or out of data, build full syndrome
|
||||
VAND V5.B16, V3.B16, V3.B16
|
||||
VAND V5.B16, V4.B16, V4.B16
|
||||
VADDP V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.B16, V6.B16, V6.B16
|
||||
VMOV V6.D[0], R6
|
||||
// Only mask for the last block
|
||||
BHS tail
|
||||
|
||||
masklast:
|
||||
// Clear irrelevant upper bits
|
||||
ADD R9, R10, R4
|
||||
AND $0x1f, R4, R4
|
||||
SUB $0x20, R4, R4
|
||||
NEG R4<<1, R4
|
||||
LSL R4, R6, R6
|
||||
LSR R4, R6, R6
|
||||
|
||||
tail:
|
||||
CBZ R6, fail
|
||||
RBIT R6, R6
|
||||
SUB $0x20, R3, R3
|
||||
CLZ R6, R6
|
||||
ADD R6>>1, R3, R0
|
||||
SUB R11, R0, R0
|
||||
MOVD R0, (R8)
|
||||
RET
|
||||
|
||||
fail:
|
||||
MOVD $-1, R0
|
||||
MOVD R0, (R8)
|
||||
RET
|
||||
|
||||
// func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
||||
//
|
||||
// Returns the index of the last occurrence of b1 or b2 in s, or -1.
|
||||
// Scans backward using ARM64 NEON.
|
||||
TEXT ·lastIndexByteTwo(SB),NOSPLIT,$0-40
|
||||
MOVD s_base+0(FP), R0
|
||||
MOVD s_len+8(FP), R2
|
||||
MOVBU b1+24(FP), R1
|
||||
MOVBU b2+25(FP), R7
|
||||
MOVD $ret+32(FP), R8
|
||||
|
||||
CBZ R2, lfail
|
||||
MOVD R0, R11 // save base
|
||||
ADD R0, R2, R12 // R12 = end = base + len
|
||||
MOVD $0x40100401, R5
|
||||
VMOV R1, V0.B16 // V0 = splat(b1)
|
||||
VMOV R7, V7.B16 // V7 = splat(b2)
|
||||
VMOV R5, V5.S4
|
||||
|
||||
// Align: find the aligned block containing the last byte
|
||||
SUB $1, R12, R3
|
||||
BIC $0x1f, R3, R3 // R3 = start of aligned block containing last byte
|
||||
|
||||
// --- Process tail block ---
|
||||
VLD1 (R3), [V1.B16, V2.B16]
|
||||
VCMEQ V0.B16, V1.B16, V3.B16
|
||||
VCMEQ V7.B16, V1.B16, V8.B16
|
||||
VORR V8.B16, V3.B16, V3.B16
|
||||
VCMEQ V0.B16, V2.B16, V4.B16
|
||||
VCMEQ V7.B16, V2.B16, V9.B16
|
||||
VORR V9.B16, V4.B16, V4.B16
|
||||
VAND V5.B16, V3.B16, V3.B16
|
||||
VAND V5.B16, V4.B16, V4.B16
|
||||
VADDP V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.B16, V6.B16, V6.B16
|
||||
VMOV V6.D[0], R6
|
||||
|
||||
// Mask upper bits (bytes past end of slice)
|
||||
// tail_bytes = end - R3 (1..32)
|
||||
SUB R3, R12, R10 // R10 = tail_bytes
|
||||
MOVD $64, R4
|
||||
SUB R10<<1, R4, R4 // R4 = 64 - 2*tail_bytes
|
||||
LSL R4, R6, R6
|
||||
LSR R4, R6, R6
|
||||
|
||||
// Is this also the head block?
|
||||
CMP R11, R3 // R3 - R11
|
||||
BLO lmaskfirst // R3 < base: head+tail in same block
|
||||
BEQ ltailonly // R3 == base: single aligned block
|
||||
|
||||
// R3 > base: more blocks before this one
|
||||
CBNZ R6, llast
|
||||
B lbacksetup
|
||||
|
||||
ltailonly:
|
||||
// Single block, already masked upper bits
|
||||
CBNZ R6, llast
|
||||
B lfail
|
||||
|
||||
lmaskfirst:
|
||||
// Mask lower bits (bytes before start of slice)
|
||||
SUB R3, R11, R4 // R4 = base - R3
|
||||
LSL $1, R4, R4
|
||||
LSR R4, R6, R6
|
||||
LSL R4, R6, R6
|
||||
CBNZ R6, llast
|
||||
B lfail
|
||||
|
||||
lbacksetup:
|
||||
SUB $0x20, R3
|
||||
|
||||
lbackloop:
|
||||
VLD1 (R3), [V1.B16, V2.B16]
|
||||
VCMEQ V0.B16, V1.B16, V3.B16
|
||||
VCMEQ V7.B16, V1.B16, V8.B16
|
||||
VORR V8.B16, V3.B16, V3.B16
|
||||
VCMEQ V0.B16, V2.B16, V4.B16
|
||||
VCMEQ V7.B16, V2.B16, V9.B16
|
||||
VORR V9.B16, V4.B16, V4.B16
|
||||
// Quick check: any match in this block?
|
||||
VORR V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.D2, V6.D2, V6.D2
|
||||
VMOV V6.D[0], R6
|
||||
|
||||
// Is this a head block? (R3 < base)
|
||||
CMP R11, R3
|
||||
BLO lheadblock
|
||||
|
||||
// Full block (R3 >= base)
|
||||
CBNZ R6, lbackfound
|
||||
// More blocks?
|
||||
BEQ lfail // R3 == base, no more
|
||||
SUB $0x20, R3
|
||||
B lbackloop
|
||||
|
||||
lbackfound:
|
||||
// Build full syndrome
|
||||
VAND V5.B16, V3.B16, V3.B16
|
||||
VAND V5.B16, V4.B16, V4.B16
|
||||
VADDP V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.B16, V6.B16, V6.B16
|
||||
VMOV V6.D[0], R6
|
||||
B llast
|
||||
|
||||
lheadblock:
|
||||
// R3 < base. Build full syndrome if quick check had a match.
|
||||
CBZ R6, lfail
|
||||
VAND V5.B16, V3.B16, V3.B16
|
||||
VAND V5.B16, V4.B16, V4.B16
|
||||
VADDP V4.B16, V3.B16, V6.B16
|
||||
VADDP V6.B16, V6.B16, V6.B16
|
||||
VMOV V6.D[0], R6
|
||||
// Mask lower bits
|
||||
SUB R3, R11, R4 // R4 = base - R3
|
||||
LSL $1, R4, R4
|
||||
LSR R4, R6, R6
|
||||
LSL R4, R6, R6
|
||||
CBZ R6, lfail
|
||||
|
||||
llast:
|
||||
// Find last match: highest set bit in syndrome
|
||||
// Syndrome has bit 2i set for matching byte i.
|
||||
// CLZ gives leading zeros; byte_offset = (63 - CLZ) / 2.
|
||||
CLZ R6, R6
|
||||
MOVD $63, R4
|
||||
SUB R6, R4, R6 // R6 = 63 - CLZ = bit position
|
||||
LSR $1, R6 // R6 = byte offset within block
|
||||
ADD R3, R6, R0 // R0 = absolute address
|
||||
SUB R11, R0, R0 // R0 = slice index
|
||||
MOVD R0, (R8)
|
||||
RET
|
||||
|
||||
lfail:
|
||||
MOVD $-1, R0
|
||||
MOVD R0, (R8)
|
||||
RET
|
||||
@@ -1,33 +0,0 @@
|
||||
//go:build !arm64 && !amd64
|
||||
|
||||
package algo
|
||||
|
||||
import "bytes"
|
||||
|
||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present.
|
||||
func IndexByteTwo(s []byte, b1, b2 byte) int {
|
||||
i1 := bytes.IndexByte(s, b1)
|
||||
if i1 == 0 {
|
||||
return 0
|
||||
}
|
||||
scope := s
|
||||
if i1 > 0 {
|
||||
scope = s[:i1]
|
||||
}
|
||||
if i2 := bytes.IndexByte(scope, b2); i2 >= 0 {
|
||||
return i2
|
||||
}
|
||||
return i1
|
||||
}
|
||||
|
||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
||||
// or -1 if neither is present.
|
||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int {
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
if s[i] == b1 || s[i] == b2 {
|
||||
return i
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
@@ -1,259 +0,0 @@
|
||||
package algo
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"testing"
|
||||
)
|
||||
|
||||
func TestIndexByteTwo(t *testing.T) {
|
||||
tests := []struct {
|
||||
name string
|
||||
s string
|
||||
b1 byte
|
||||
b2 byte
|
||||
want int
|
||||
}{
|
||||
{"empty", "", 'a', 'b', -1},
|
||||
{"single_b1", "a", 'a', 'b', 0},
|
||||
{"single_b2", "b", 'a', 'b', 0},
|
||||
{"single_none", "c", 'a', 'b', -1},
|
||||
{"b1_first", "xaxb", 'a', 'b', 1},
|
||||
{"b2_first", "xbxa", 'a', 'b', 1},
|
||||
{"same_byte", "xxa", 'a', 'a', 2},
|
||||
{"at_end", "xxxxa", 'a', 'b', 4},
|
||||
{"not_found", "xxxxxxxx", 'a', 'b', -1},
|
||||
{"long_b1_at_3000", string(make([]byte, 3000)) + "a" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
||||
{"long_b2_at_3000", string(make([]byte, 3000)) + "b" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
||||
}
|
||||
|
||||
for _, tt := range tests {
|
||||
t.Run(tt.name, func(t *testing.T) {
|
||||
got := IndexByteTwo([]byte(tt.s), tt.b1, tt.b2)
|
||||
if got != tt.want {
|
||||
t.Errorf("IndexByteTwo(%q, %c, %c) = %d, want %d", tt.s[:min(len(tt.s), 40)], tt.b1, tt.b2, got, tt.want)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
// Exhaustive test: compare against loop reference for various lengths,
|
||||
// including sizes around SIMD block boundaries (16, 32, 64).
|
||||
for n := 0; n <= 256; n++ {
|
||||
data := make([]byte, n)
|
||||
for i := range data {
|
||||
data[i] = byte('c' + (i % 20))
|
||||
}
|
||||
// Test with match at every position
|
||||
for pos := 0; pos < n; pos++ {
|
||||
for _, b := range []byte{'A', 'B'} {
|
||||
data[pos] = b
|
||||
got := IndexByteTwo(data, 'A', 'B')
|
||||
want := loopIndexByteTwo(data, 'A', 'B')
|
||||
if got != want {
|
||||
t.Fatalf("IndexByteTwo(len=%d, match=%c@%d) = %d, want %d", n, b, pos, got, want)
|
||||
}
|
||||
data[pos] = byte('c' + (pos % 20))
|
||||
}
|
||||
}
|
||||
// Test with no match
|
||||
got := IndexByteTwo(data, 'A', 'B')
|
||||
if got != -1 {
|
||||
t.Fatalf("IndexByteTwo(len=%d, no match) = %d, want -1", n, got)
|
||||
}
|
||||
// Test with both bytes present
|
||||
if n >= 2 {
|
||||
data[n/3] = 'A'
|
||||
data[n*2/3] = 'B'
|
||||
got := IndexByteTwo(data, 'A', 'B')
|
||||
want := loopIndexByteTwo(data, 'A', 'B')
|
||||
if got != want {
|
||||
t.Fatalf("IndexByteTwo(len=%d, both@%d,%d) = %d, want %d", n, n/3, n*2/3, got, want)
|
||||
}
|
||||
data[n/3] = byte('c' + ((n / 3) % 20))
|
||||
data[n*2/3] = byte('c' + ((n * 2 / 3) % 20))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestLastIndexByteTwo(t *testing.T) {
|
||||
tests := []struct {
|
||||
name string
|
||||
s string
|
||||
b1 byte
|
||||
b2 byte
|
||||
want int
|
||||
}{
|
||||
{"empty", "", 'a', 'b', -1},
|
||||
{"single_b1", "a", 'a', 'b', 0},
|
||||
{"single_b2", "b", 'a', 'b', 0},
|
||||
{"single_none", "c", 'a', 'b', -1},
|
||||
{"b1_last", "xbxa", 'a', 'b', 3},
|
||||
{"b2_last", "xaxb", 'a', 'b', 3},
|
||||
{"same_byte", "axx", 'a', 'a', 0},
|
||||
{"at_start", "axxxx", 'a', 'b', 0},
|
||||
{"both_present", "axbx", 'a', 'b', 2},
|
||||
{"not_found", "xxxxxxxx", 'a', 'b', -1},
|
||||
{"long_b1_at_3000", string(make([]byte, 3000)) + "a" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
||||
{"long_b2_at_end", string(make([]byte, 4000)) + "b", 'a', 'b', 4000},
|
||||
}
|
||||
|
||||
for _, tt := range tests {
|
||||
t.Run(tt.name, func(t *testing.T) {
|
||||
got := lastIndexByteTwo([]byte(tt.s), tt.b1, tt.b2)
|
||||
if got != tt.want {
|
||||
t.Errorf("lastIndexByteTwo(%q, %c, %c) = %d, want %d", tt.s[:min(len(tt.s), 40)], tt.b1, tt.b2, got, tt.want)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
// Exhaustive test against loop reference
|
||||
for n := 0; n <= 256; n++ {
|
||||
data := make([]byte, n)
|
||||
for i := range data {
|
||||
data[i] = byte('c' + (i % 20))
|
||||
}
|
||||
for pos := 0; pos < n; pos++ {
|
||||
for _, b := range []byte{'A', 'B'} {
|
||||
data[pos] = b
|
||||
got := lastIndexByteTwo(data, 'A', 'B')
|
||||
want := refLastIndexByteTwo(data, 'A', 'B')
|
||||
if got != want {
|
||||
t.Fatalf("lastIndexByteTwo(len=%d, match=%c@%d) = %d, want %d", n, b, pos, got, want)
|
||||
}
|
||||
data[pos] = byte('c' + (pos % 20))
|
||||
}
|
||||
}
|
||||
// No match
|
||||
got := lastIndexByteTwo(data, 'A', 'B')
|
||||
if got != -1 {
|
||||
t.Fatalf("lastIndexByteTwo(len=%d, no match) = %d, want -1", n, got)
|
||||
}
|
||||
// Both bytes present
|
||||
if n >= 2 {
|
||||
data[n/3] = 'A'
|
||||
data[n*2/3] = 'B'
|
||||
got := lastIndexByteTwo(data, 'A', 'B')
|
||||
want := refLastIndexByteTwo(data, 'A', 'B')
|
||||
if got != want {
|
||||
t.Fatalf("lastIndexByteTwo(len=%d, both@%d,%d) = %d, want %d", n, n/3, n*2/3, got, want)
|
||||
}
|
||||
data[n/3] = byte('c' + ((n / 3) % 20))
|
||||
data[n*2/3] = byte('c' + ((n * 2 / 3) % 20))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func FuzzIndexByteTwo(f *testing.F) {
|
||||
f.Add([]byte("hello world"), byte('o'), byte('l'))
|
||||
f.Add([]byte(""), byte('a'), byte('b'))
|
||||
f.Add([]byte("aaa"), byte('a'), byte('a'))
|
||||
f.Fuzz(func(t *testing.T, data []byte, b1, b2 byte) {
|
||||
got := IndexByteTwo(data, b1, b2)
|
||||
want := loopIndexByteTwo(data, b1, b2)
|
||||
if got != want {
|
||||
t.Errorf("IndexByteTwo(len=%d, b1=%d, b2=%d) = %d, want %d", len(data), b1, b2, got, want)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
func FuzzLastIndexByteTwo(f *testing.F) {
|
||||
f.Add([]byte("hello world"), byte('o'), byte('l'))
|
||||
f.Add([]byte(""), byte('a'), byte('b'))
|
||||
f.Add([]byte("aaa"), byte('a'), byte('a'))
|
||||
f.Fuzz(func(t *testing.T, data []byte, b1, b2 byte) {
|
||||
got := lastIndexByteTwo(data, b1, b2)
|
||||
want := refLastIndexByteTwo(data, b1, b2)
|
||||
if got != want {
|
||||
t.Errorf("lastIndexByteTwo(len=%d, b1=%d, b2=%d) = %d, want %d", len(data), b1, b2, got, want)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
// Reference implementations for correctness checking
|
||||
func refIndexByteTwo(s []byte, b1, b2 byte) int {
|
||||
i1 := bytes.IndexByte(s, b1)
|
||||
if i1 == 0 {
|
||||
return 0
|
||||
}
|
||||
scope := s
|
||||
if i1 > 0 {
|
||||
scope = s[:i1]
|
||||
}
|
||||
if i2 := bytes.IndexByte(scope, b2); i2 >= 0 {
|
||||
return i2
|
||||
}
|
||||
return i1
|
||||
}
|
||||
|
||||
func loopIndexByteTwo(s []byte, b1, b2 byte) int {
|
||||
for i, b := range s {
|
||||
if b == b1 || b == b2 {
|
||||
return i
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
func refLastIndexByteTwo(s []byte, b1, b2 byte) int {
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
if s[i] == b1 || s[i] == b2 {
|
||||
return i
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
func benchIndexByteTwo(b *testing.B, size int, pos int) {
|
||||
data := make([]byte, size)
|
||||
for i := range data {
|
||||
data[i] = byte('a' + (i % 20))
|
||||
}
|
||||
data[pos] = 'Z'
|
||||
|
||||
type impl struct {
|
||||
name string
|
||||
fn func([]byte, byte, byte) int
|
||||
}
|
||||
impls := []impl{
|
||||
{"asm", IndexByteTwo},
|
||||
{"2xIndexByte", refIndexByteTwo},
|
||||
{"loop", loopIndexByteTwo},
|
||||
}
|
||||
for _, im := range impls {
|
||||
b.Run(im.name, func(b *testing.B) {
|
||||
for i := 0; i < b.N; i++ {
|
||||
im.fn(data, 'Z', 'z')
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
func benchLastIndexByteTwo(b *testing.B, size int, pos int) {
|
||||
data := make([]byte, size)
|
||||
for i := range data {
|
||||
data[i] = byte('a' + (i % 20))
|
||||
}
|
||||
data[pos] = 'Z'
|
||||
|
||||
type impl struct {
|
||||
name string
|
||||
fn func([]byte, byte, byte) int
|
||||
}
|
||||
impls := []impl{
|
||||
{"asm", lastIndexByteTwo},
|
||||
{"loop", refLastIndexByteTwo},
|
||||
}
|
||||
for _, im := range impls {
|
||||
b.Run(im.name, func(b *testing.B) {
|
||||
for i := 0; i < b.N; i++ {
|
||||
im.fn(data, 'Z', 'z')
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
func BenchmarkIndexByteTwo_10(b *testing.B) { benchIndexByteTwo(b, 10, 8) }
|
||||
func BenchmarkIndexByteTwo_100(b *testing.B) { benchIndexByteTwo(b, 100, 80) }
|
||||
func BenchmarkIndexByteTwo_1000(b *testing.B) { benchIndexByteTwo(b, 1000, 800) }
|
||||
func BenchmarkLastIndexByteTwo_10(b *testing.B) { benchLastIndexByteTwo(b, 10, 2) }
|
||||
func BenchmarkLastIndexByteTwo_100(b *testing.B) { benchLastIndexByteTwo(b, 100, 20) }
|
||||
func BenchmarkLastIndexByteTwo_1000(b *testing.B) { benchLastIndexByteTwo(b, 1000, 200) }
|
||||
+2
-99
@@ -3,7 +3,7 @@
|
||||
|
||||
package algo
|
||||
|
||||
var normalized = map[rune]rune{
|
||||
var normalized map[rune]rune = map[rune]rune{
|
||||
0x00E1: 'a', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0103: 'a', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01CE: 'a', // WITH CARON, LATIN SMALL LETTER
|
||||
@@ -473,103 +473,6 @@ var normalized = map[rune]rune{
|
||||
'ử': 'u',
|
||||
'ữ': 'u',
|
||||
'ự': 'u',
|
||||
|
||||
// https://en.wikipedia.org/wiki/Halfwidth_and_Fullwidth_Forms_(Unicode_block)
|
||||
0xFF01: '!', // Fullwidth exclamation
|
||||
0xFF02: '"', // Fullwidth quotation mark
|
||||
0xFF03: '#', // Fullwidth number sign
|
||||
0xFF04: '$', // Fullwidth dollar sign
|
||||
0xFF05: '%', // Fullwidth percent
|
||||
0xFF06: '&', // Fullwidth ampersand
|
||||
0xFF07: '\'', // Fullwidth apostrophe
|
||||
0xFF08: '(', // Fullwidth left parenthesis
|
||||
0xFF09: ')', // Fullwidth right parenthesis
|
||||
0xFF0A: '*', // Fullwidth asterisk
|
||||
0xFF0B: '+', // Fullwidth plus
|
||||
0xFF0C: ',', // Fullwidth comma
|
||||
0xFF0D: '-', // Fullwidth hyphen-minus
|
||||
0xFF0E: '.', // Fullwidth period
|
||||
0xFF0F: '/', // Fullwidth slash
|
||||
0xFF10: '0',
|
||||
0xFF11: '1',
|
||||
0xFF12: '2',
|
||||
0xFF13: '3',
|
||||
0xFF14: '4',
|
||||
0xFF15: '5',
|
||||
0xFF16: '6',
|
||||
0xFF17: '7',
|
||||
0xFF18: '8',
|
||||
0xFF19: '9',
|
||||
0xFF1A: ':', // Fullwidth colon
|
||||
0xFF1B: ';', // Fullwidth semicolon
|
||||
0xFF1C: '<', // Fullwidth less-than
|
||||
0xFF1D: '=', // Fullwidth equal
|
||||
0xFF1E: '>', // Fullwidth greater-than
|
||||
0xFF1F: '?', // Fullwidth question mark
|
||||
0xFF20: '@', // Fullwidth at sign
|
||||
0xFF21: 'A',
|
||||
0xFF22: 'B',
|
||||
0xFF23: 'C',
|
||||
0xFF24: 'D',
|
||||
0xFF25: 'E',
|
||||
0xFF26: 'F',
|
||||
0xFF27: 'G',
|
||||
0xFF28: 'H',
|
||||
0xFF29: 'I',
|
||||
0xFF2A: 'J',
|
||||
0xFF2B: 'K',
|
||||
0xFF2C: 'L',
|
||||
0xFF2D: 'M',
|
||||
0xFF2E: 'N',
|
||||
0xFF2F: 'O',
|
||||
0xFF30: 'P',
|
||||
0xFF31: 'Q',
|
||||
0xFF32: 'R',
|
||||
0xFF33: 'S',
|
||||
0xFF34: 'T',
|
||||
0xFF35: 'U',
|
||||
0xFF36: 'V',
|
||||
0xFF37: 'W',
|
||||
0xFF38: 'X',
|
||||
0xFF39: 'Y',
|
||||
0xFF3A: 'Z',
|
||||
0xFF3B: '[', // Fullwidth left bracket
|
||||
0xFF3C: '\\', // Fullwidth backslash
|
||||
0xFF3D: ']', // Fullwidth right bracket
|
||||
0xFF3E: '^', // Fullwidth circumflex
|
||||
0xFF3F: '_', // Fullwidth underscore
|
||||
0xFF40: '`', // Fullwidth grave accent
|
||||
0xFF41: 'a',
|
||||
0xFF42: 'b',
|
||||
0xFF43: 'c',
|
||||
0xFF44: 'd',
|
||||
0xFF45: 'e',
|
||||
0xFF46: 'f',
|
||||
0xFF47: 'g',
|
||||
0xFF48: 'h',
|
||||
0xFF49: 'i',
|
||||
0xFF4A: 'j',
|
||||
0xFF4B: 'k',
|
||||
0xFF4C: 'l',
|
||||
0xFF4D: 'm',
|
||||
0xFF4E: 'n',
|
||||
0xFF4F: 'o',
|
||||
0xFF50: 'p',
|
||||
0xFF51: 'q',
|
||||
0xFF52: 'r',
|
||||
0xFF53: 's',
|
||||
0xFF54: 't',
|
||||
0xFF55: 'u',
|
||||
0xFF56: 'v',
|
||||
0xFF57: 'w',
|
||||
0xFF58: 'x',
|
||||
0xFF59: 'y',
|
||||
0xFF5A: 'z',
|
||||
0xFF5B: '{', // Fullwidth left brace
|
||||
0xFF5C: '|', // Fullwidth vertical bar
|
||||
0xFF5D: '}', // Fullwidth right brace
|
||||
0xFF5E: '~', // Fullwidth tilde
|
||||
0xFF61: '.', // Halfwidth ideographic full stop
|
||||
}
|
||||
|
||||
// NormalizeRunes normalizes latin script letters
|
||||
@@ -577,7 +480,7 @@ func NormalizeRunes(runes []rune) []rune {
|
||||
ret := make([]rune, len(runes))
|
||||
copy(ret, runes)
|
||||
for idx, r := range runes {
|
||||
if r < 0x00C0 || r > 0xFF61 {
|
||||
if r < 0x00C0 || r > 0x2184 {
|
||||
continue
|
||||
}
|
||||
n := normalized[r]
|
||||
|
||||
+55
-224
@@ -1,12 +1,10 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"strconv"
|
||||
"strings"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/junegunn/fzf/src/algo"
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
)
|
||||
|
||||
@@ -15,29 +13,22 @@ type ansiOffset struct {
|
||||
color ansiState
|
||||
}
|
||||
|
||||
type url struct {
|
||||
uri string
|
||||
params string
|
||||
}
|
||||
|
||||
type ansiState struct {
|
||||
fg tui.Color
|
||||
bg tui.Color
|
||||
ul tui.Color
|
||||
attr tui.Attr
|
||||
lbg tui.Color
|
||||
url *url
|
||||
}
|
||||
|
||||
func (s *ansiState) colored() bool {
|
||||
return s.fg != -1 || s.bg != -1 || s.ul != -1 || s.attr > 0 || s.lbg >= 0 || s.url != nil
|
||||
return s.fg != -1 || s.bg != -1 || s.attr > 0 || s.lbg >= 0
|
||||
}
|
||||
|
||||
func (s *ansiState) equals(t *ansiState) bool {
|
||||
if t == nil {
|
||||
return !s.colored()
|
||||
}
|
||||
return s.fg == t.fg && s.bg == t.bg && s.ul == t.ul && s.attr == t.attr && s.lbg == t.lbg && s.url == t.url
|
||||
return s.fg == t.fg && s.bg == t.bg && s.attr == t.attr && s.lbg == t.lbg
|
||||
}
|
||||
|
||||
func (s *ansiState) ToString() string {
|
||||
@@ -46,7 +37,7 @@ func (s *ansiState) ToString() string {
|
||||
}
|
||||
|
||||
ret := ""
|
||||
if s.attr&tui.Bold > 0 || s.attr&tui.BoldForce > 0 {
|
||||
if s.attr&tui.Bold > 0 {
|
||||
ret += "1;"
|
||||
}
|
||||
if s.attr&tui.Dim > 0 {
|
||||
@@ -56,18 +47,7 @@ func (s *ansiState) ToString() string {
|
||||
ret += "3;"
|
||||
}
|
||||
if s.attr&tui.Underline > 0 {
|
||||
switch s.attr.UnderlineStyle() {
|
||||
case tui.UlStyleDouble:
|
||||
ret += "4:2;"
|
||||
case tui.UlStyleCurly:
|
||||
ret += "4:3;"
|
||||
case tui.UlStyleDotted:
|
||||
ret += "4:4;"
|
||||
case tui.UlStyleDashed:
|
||||
ret += "4:5;"
|
||||
default:
|
||||
ret += "4;"
|
||||
}
|
||||
ret += "4;"
|
||||
}
|
||||
if s.attr&tui.Blink > 0 {
|
||||
ret += "5;"
|
||||
@@ -75,33 +55,9 @@ func (s *ansiState) ToString() string {
|
||||
if s.attr&tui.Reverse > 0 {
|
||||
ret += "7;"
|
||||
}
|
||||
if s.attr&tui.StrikeThrough > 0 {
|
||||
ret += "9;"
|
||||
}
|
||||
ret += toAnsiString(s.fg, 30) + toAnsiString(s.bg, 40)
|
||||
if s.ul != -1 {
|
||||
ret += toAnsiStringUl(s.ul)
|
||||
}
|
||||
|
||||
ret = "\x1b[" + strings.TrimSuffix(ret, ";") + "m"
|
||||
if s.url != nil {
|
||||
ret = fmt.Sprintf("\x1b]8;%s;%s\x1b\\%s\x1b]8;;\x1b", s.url.params, s.url.uri, ret)
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
func toAnsiStringUl(color tui.Color) string {
|
||||
col := int(color)
|
||||
if col < 0 {
|
||||
return ""
|
||||
}
|
||||
if col >= (1 << 24) {
|
||||
r := strconv.Itoa((col >> 16) & 0xff)
|
||||
g := strconv.Itoa((col >> 8) & 0xff)
|
||||
b := strconv.Itoa(col & 0xff)
|
||||
return "58;2;" + r + ";" + g + ";" + b + ";"
|
||||
}
|
||||
return "58;5;" + strconv.Itoa(col) + ";"
|
||||
return "\x1b[" + strings.TrimSuffix(ret, ";") + "m"
|
||||
}
|
||||
|
||||
func toAnsiString(color tui.Color, offset int) string {
|
||||
@@ -124,75 +80,59 @@ func toAnsiString(color tui.Color, offset int) string {
|
||||
return ret + ";"
|
||||
}
|
||||
|
||||
func matchOperatingSystemCommand(s string, start int) int {
|
||||
// `\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
// ^ match starting here after the first printable character
|
||||
func isPrint(c uint8) bool {
|
||||
return '\x20' <= c && c <= '\x7e'
|
||||
}
|
||||
|
||||
func matchOperatingSystemCommand(s string) int {
|
||||
// `\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
// ^ match starting here
|
||||
//
|
||||
i := start // prefix matched in nextAnsiEscapeSequence()
|
||||
|
||||
// Find the terminator: BEL (\x07) or ESC (\x1b) for ST (\x1b\\)
|
||||
idx := algo.IndexByteTwo(stringBytes(s[i:]), '\x07', '\x1b')
|
||||
if idx < 0 {
|
||||
return -1
|
||||
i := 5 // prefix matched in nextAnsiEscapeSequence()
|
||||
for ; i < len(s) && isPrint(s[i]); i++ {
|
||||
}
|
||||
i += idx
|
||||
|
||||
if s[i] == '\x07' {
|
||||
return i + 1
|
||||
if i < len(s) {
|
||||
if s[i] == '\x07' {
|
||||
return i + 1
|
||||
}
|
||||
if s[i] == '\x1b' && i < len(s)-1 && s[i+1] == '\\' {
|
||||
return i + 2
|
||||
}
|
||||
}
|
||||
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
||||
// ------
|
||||
if i < len(s)-1 && s[i+1] == '\\' {
|
||||
return i + 2
|
||||
}
|
||||
|
||||
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
||||
// ------------
|
||||
if s[:i+1] == "\x1b]8;;\x1b" {
|
||||
return i + 1
|
||||
}
|
||||
|
||||
return -1
|
||||
}
|
||||
|
||||
func matchControlSequence(s string) int {
|
||||
// `\x1b[\\[()][0-9;:?]*[a-zA-Z@]`
|
||||
// ^ match starting here
|
||||
// `\x1b[\\[()][0-9;?]*[a-zA-Z@]`
|
||||
// ^ match starting here
|
||||
//
|
||||
i := 2 // prefix matched in nextAnsiEscapeSequence()
|
||||
for ; i < len(s); i++ {
|
||||
for ; i < len(s) && (isNumeric(s[i]) || s[i] == ';' || s[i] == '?'); i++ {
|
||||
}
|
||||
if i < len(s) {
|
||||
c := s[i]
|
||||
switch c {
|
||||
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ';', ':', '?':
|
||||
// ok
|
||||
default:
|
||||
if 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' || c == '@' {
|
||||
return i + 1
|
||||
}
|
||||
return -1
|
||||
if 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' || c == '@' {
|
||||
return i + 1
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
func isCtrlSeqStart(c uint8) bool {
|
||||
switch c {
|
||||
case '\\', '[', '(', ')':
|
||||
return true
|
||||
}
|
||||
return false
|
||||
return c == '\\' || c == '[' || c == '(' || c == ')'
|
||||
}
|
||||
|
||||
// nextAnsiEscapeSequence returns the ANSI escape sequence and is equivalent to
|
||||
// calling FindStringIndex() on the below regex (which was originally used):
|
||||
//
|
||||
// "(?:\x1b[\\[()][0-9;:?]*[a-zA-Z@]|\x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08|\n)"
|
||||
// "(?:\x1b[\\[()][0-9;?]*[a-zA-Z@]|\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)"
|
||||
//
|
||||
func nextAnsiEscapeSequence(s string) (int, int) {
|
||||
// fast check for ANSI escape sequences
|
||||
i := 0
|
||||
for ; i < len(s); i++ {
|
||||
switch s[i] {
|
||||
case '\x0e', '\x0f', '\x1b', '\x08', '\n':
|
||||
case '\x0e', '\x0f', '\x1b', '\x08':
|
||||
// We ignore the fact that '\x08' cannot be the first char
|
||||
// in the string and be an escape sequence for the sake of
|
||||
// speed and simplicity.
|
||||
@@ -204,9 +144,6 @@ func nextAnsiEscapeSequence(s string) (int, int) {
|
||||
Loop:
|
||||
for ; i < len(s); i++ {
|
||||
switch s[i] {
|
||||
case '\n':
|
||||
// match: `\n`
|
||||
return i, i + 1
|
||||
case '\x08':
|
||||
// backtrack to match: `.\x08`
|
||||
if i > 0 && s[i-1] != '\n' {
|
||||
@@ -217,27 +154,19 @@ Loop:
|
||||
return i - n, i + 1
|
||||
}
|
||||
case '\x1b':
|
||||
// match: `\x1b[\\[()][0-9;:?]*[a-zA-Z@]`
|
||||
// match: `\x1b[\\[()][0-9;?]*[a-zA-Z@]`
|
||||
if i+2 < len(s) && isCtrlSeqStart(s[i+1]) {
|
||||
if j := matchControlSequence(s[i:]); j != -1 {
|
||||
return i, i + j
|
||||
}
|
||||
}
|
||||
|
||||
// match: `\x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
if i+5 < len(s) && s[i+1] == ']' {
|
||||
j := 2
|
||||
// \x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)
|
||||
// ------
|
||||
for ; i+j < len(s) && isNumeric(s[i+j]); j++ {
|
||||
}
|
||||
// match: `\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
if i+5 < len(s) && s[i+1] == ']' && isNumeric(s[i+2]) &&
|
||||
s[i+3] == ';' && isPrint(s[i+4]) {
|
||||
|
||||
// \x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)
|
||||
// ---------------
|
||||
if j > 2 && i+j+1 < len(s) && (s[i+j] == ';' || s[i+j] == ':') && s[i+j+1] >= '\x20' {
|
||||
if k := matchOperatingSystemCommand(s[i:], j+2); k != -1 {
|
||||
return i, i + k
|
||||
}
|
||||
if j := matchOperatingSystemCommand(s[i:]); j != -1 {
|
||||
return i, i + j
|
||||
}
|
||||
}
|
||||
|
||||
@@ -298,30 +227,13 @@ func extractColor(str string, state *ansiState, proc func(string, *ansiState) bo
|
||||
output.WriteString(prev)
|
||||
}
|
||||
|
||||
code := str[start:idx]
|
||||
newState := interpretCode(code, state)
|
||||
if code == "\n" || !newState.equals(state) {
|
||||
newState := interpretCode(str[start:idx], state)
|
||||
if !newState.equals(state) {
|
||||
if state != nil {
|
||||
// Update last offset
|
||||
(&offsets[len(offsets)-1]).offset[1] = int32(runeCount)
|
||||
}
|
||||
|
||||
if code == "\n" {
|
||||
output.WriteRune('\n')
|
||||
runeCount++
|
||||
// Full-background marker
|
||||
if newState.lbg >= 0 {
|
||||
marker := newState
|
||||
marker.attr |= tui.FullBg
|
||||
offsets = append(offsets, ansiOffset{
|
||||
[2]int32{int32(runeCount), int32(runeCount)},
|
||||
marker,
|
||||
})
|
||||
// Reset the full-line background color
|
||||
newState.lbg = -1
|
||||
}
|
||||
}
|
||||
|
||||
if newState.colored() {
|
||||
// Append new offset
|
||||
if pstate == nil {
|
||||
@@ -368,19 +280,9 @@ func extractColor(str string, state *ansiState, proc func(string, *ansiState) bo
|
||||
return trimmed, nil, state
|
||||
}
|
||||
|
||||
func parseAnsiCode(s string) (int, byte, string) {
|
||||
func parseAnsiCode(s string) (int, string) {
|
||||
var remaining string
|
||||
var sep byte
|
||||
// Find the first separator (either ; or :)
|
||||
i := -1
|
||||
for j := 0; j < len(s); j++ {
|
||||
if s[j] == ';' || s[j] == ':' {
|
||||
i = j
|
||||
break
|
||||
}
|
||||
}
|
||||
if i >= 0 {
|
||||
sep = s[i]
|
||||
if i := strings.IndexByte(s, ';'); i >= 0 {
|
||||
remaining = s[i+1:]
|
||||
s = s[:i]
|
||||
}
|
||||
@@ -389,62 +291,37 @@ func parseAnsiCode(s string) (int, byte, string) {
|
||||
// Inlined version of strconv.Atoi() that only handles positive
|
||||
// integers and does not allocate on error.
|
||||
code := 0
|
||||
for _, ch := range stringBytes(s) {
|
||||
for _, ch := range []byte(s) {
|
||||
ch -= '0'
|
||||
if ch > 9 {
|
||||
return -1, sep, remaining
|
||||
return -1, remaining
|
||||
}
|
||||
code = code*10 + int(ch)
|
||||
}
|
||||
return code, sep, remaining
|
||||
return code, remaining
|
||||
}
|
||||
|
||||
return -1, sep, remaining
|
||||
return -1, remaining
|
||||
}
|
||||
|
||||
func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
if ansiCode == "\n" {
|
||||
if prevState != nil {
|
||||
return *prevState
|
||||
}
|
||||
return ansiState{-1, -1, -1, 0, -1, nil}
|
||||
}
|
||||
|
||||
var state ansiState
|
||||
if prevState == nil {
|
||||
state = ansiState{-1, -1, -1, 0, -1, nil}
|
||||
state = ansiState{-1, -1, 0, -1}
|
||||
} else {
|
||||
state = ansiState{prevState.fg, prevState.bg, prevState.ul, prevState.attr, prevState.lbg, prevState.url}
|
||||
state = ansiState{prevState.fg, prevState.bg, prevState.attr, prevState.lbg}
|
||||
}
|
||||
if ansiCode[0] != '\x1b' || ansiCode[1] != '[' || ansiCode[len(ansiCode)-1] != 'm' {
|
||||
if prevState != nil && (strings.HasSuffix(ansiCode, "0K") || strings.HasSuffix(ansiCode, "[K")) {
|
||||
if prevState != nil && strings.HasSuffix(ansiCode, "0K") {
|
||||
state.lbg = prevState.bg
|
||||
} else if strings.HasPrefix(ansiCode, "\x1b]8;") && (strings.HasSuffix(ansiCode, "\x1b\\") || strings.HasSuffix(ansiCode, "\a")) {
|
||||
stLen := 2
|
||||
if strings.HasSuffix(ansiCode, "\a") {
|
||||
stLen = 1
|
||||
}
|
||||
// "\x1b]8;;\x1b\\" or "\x1b]8;;\a"
|
||||
if len(ansiCode) == 5+stLen && ansiCode[4] == ';' {
|
||||
state.url = nil
|
||||
} else if paramsEnd := strings.IndexRune(ansiCode[4:], ';'); paramsEnd >= 0 {
|
||||
params := ansiCode[4 : 4+paramsEnd]
|
||||
uri := ansiCode[5+paramsEnd : len(ansiCode)-stLen]
|
||||
state.url = &url{uri: uri, params: params}
|
||||
}
|
||||
}
|
||||
return state
|
||||
}
|
||||
|
||||
reset := func() {
|
||||
if len(ansiCode) <= 3 {
|
||||
state.fg = -1
|
||||
state.bg = -1
|
||||
state.ul = -1
|
||||
state.attr = 0
|
||||
}
|
||||
|
||||
if len(ansiCode) <= 3 {
|
||||
reset()
|
||||
return state
|
||||
}
|
||||
ansiCode = ansiCode[2 : len(ansiCode)-1]
|
||||
@@ -452,12 +329,9 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
state256 := 0
|
||||
ptr := &state.fg
|
||||
|
||||
count := 0
|
||||
for len(ansiCode) != 0 {
|
||||
var num int
|
||||
var sep byte
|
||||
if num, sep, ansiCode = parseAnsiCode(ansiCode); num != -1 {
|
||||
count++
|
||||
if num, ansiCode = parseAnsiCode(ansiCode); num != -1 {
|
||||
switch state256 {
|
||||
case 0:
|
||||
switch num {
|
||||
@@ -467,15 +341,10 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
case 48:
|
||||
ptr = &state.bg
|
||||
state256++
|
||||
case 58:
|
||||
ptr = &state.ul
|
||||
state256++
|
||||
case 39:
|
||||
state.fg = -1
|
||||
case 49:
|
||||
state.bg = -1
|
||||
case 59:
|
||||
state.ul = -1
|
||||
case 1:
|
||||
state.attr = state.attr | tui.Bold
|
||||
case 2:
|
||||
@@ -483,52 +352,19 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
case 3:
|
||||
state.attr = state.attr | tui.Italic
|
||||
case 4:
|
||||
if sep == ':' {
|
||||
// SGR 4:N - underline style sub-parameter
|
||||
var subNum int
|
||||
subNum, _, ansiCode = parseAnsiCode(ansiCode)
|
||||
state.attr = state.attr &^ tui.UnderlineStyleMask
|
||||
switch subNum {
|
||||
case 0:
|
||||
state.attr = state.attr &^ tui.Underline
|
||||
case 1:
|
||||
state.attr = state.attr | tui.Underline
|
||||
case 2:
|
||||
state.attr = state.attr | tui.Underline | tui.UlStyleDouble
|
||||
case 3:
|
||||
state.attr = state.attr | tui.Underline | tui.UlStyleCurly
|
||||
case 4:
|
||||
state.attr = state.attr | tui.Underline | tui.UlStyleDotted
|
||||
case 5:
|
||||
state.attr = state.attr | tui.Underline | tui.UlStyleDashed
|
||||
default:
|
||||
state.attr = state.attr | tui.Underline
|
||||
}
|
||||
} else {
|
||||
state.attr = state.attr | tui.Underline
|
||||
}
|
||||
state.attr = state.attr | tui.Underline
|
||||
case 5:
|
||||
state.attr = state.attr | tui.Blink
|
||||
case 7:
|
||||
state.attr = state.attr | tui.Reverse
|
||||
case 9:
|
||||
state.attr = state.attr | tui.StrikeThrough
|
||||
case 22:
|
||||
state.attr = state.attr &^ tui.Bold
|
||||
state.attr = state.attr &^ tui.Dim
|
||||
case 23: // tput rmso
|
||||
state.attr = state.attr &^ tui.Italic
|
||||
case 24: // tput rmul
|
||||
state.attr = state.attr &^ tui.Underline
|
||||
state.attr = state.attr &^ tui.UnderlineStyleMask
|
||||
case 25:
|
||||
state.attr = state.attr &^ tui.Blink
|
||||
case 27:
|
||||
state.attr = state.attr &^ tui.Reverse
|
||||
case 29:
|
||||
state.attr = state.attr &^ tui.StrikeThrough
|
||||
case 0:
|
||||
reset()
|
||||
state.fg = -1
|
||||
state.bg = -1
|
||||
state.attr = 0
|
||||
state256 = 0
|
||||
default:
|
||||
if num >= 30 && num <= 37 {
|
||||
@@ -566,11 +402,6 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
}
|
||||
}
|
||||
|
||||
// Empty sequence: reset
|
||||
if count == 0 {
|
||||
reset()
|
||||
}
|
||||
|
||||
if state256 > 0 {
|
||||
*ptr = -1
|
||||
}
|
||||
|
||||
+31
-163
@@ -15,14 +15,14 @@ import (
|
||||
// testing nextAnsiEscapeSequence().
|
||||
//
|
||||
// References:
|
||||
// - https://github.com/gnachman/iTerm2
|
||||
// - https://web.archive.org/web/20090204053813/http://ascii-table.com/ansi-escape-sequences.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences.php)
|
||||
// - https://web.archive.org/web/20090227051140/http://ascii-table.com/ansi-escape-sequences-vt-100.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences-vt-100.php)
|
||||
// - http://tldp.org/HOWTO/Bash-Prompt-HOWTO/x405.html
|
||||
// - https://invisible-island.net/xterm/ctlseqs/ctlseqs.html
|
||||
var ansiRegexReference = regexp.MustCompile("(?:\x1b[\\[()][0-9;:]*[a-zA-Z@]|\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08|\n)")
|
||||
// - https://github.com/gnachman/iTerm2
|
||||
// - https://web.archive.org/web/20090204053813/http://ascii-table.com/ansi-escape-sequences.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences.php)
|
||||
// - https://web.archive.org/web/20090227051140/http://ascii-table.com/ansi-escape-sequences-vt-100.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences-vt-100.php)
|
||||
// - http://tldp.org/HOWTO/Bash-Prompt-HOWTO/x405.html
|
||||
// - https://invisible-island.net/xterm/ctlseqs/ctlseqs.html
|
||||
var ansiRegexReference = regexp.MustCompile("(?:\x1b[\\[()][0-9;]*[a-zA-Z@]|\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)")
|
||||
|
||||
func testParserReference(t testing.TB, str string) {
|
||||
t.Helper()
|
||||
@@ -41,7 +41,7 @@ func testParserReference(t testing.TB, str string) {
|
||||
|
||||
equal := len(got) == len(exp)
|
||||
if equal {
|
||||
for i := range got {
|
||||
for i := 0; i < len(got); i++ {
|
||||
if got[i] != exp[i] {
|
||||
equal = false
|
||||
break
|
||||
@@ -167,9 +167,9 @@ func TestNextAnsiEscapeSequence_Fuzz_Random(t *testing.T) {
|
||||
randomString := func(rr *rand.Rand) string {
|
||||
numChars := rand.Intn(50)
|
||||
codePoints := make([]rune, numChars)
|
||||
for i := range codePoints {
|
||||
for i := 0; i < len(codePoints); i++ {
|
||||
var r rune
|
||||
for range 1000 {
|
||||
for n := 0; n < 1000; n++ {
|
||||
r = rune(rr.Intn(utf8.MaxRune))
|
||||
// Allow 10% of runes to be invalid
|
||||
if utf8.ValidRune(r) || rr.Float64() < 0.10 {
|
||||
@@ -182,7 +182,7 @@ func TestNextAnsiEscapeSequence_Fuzz_Random(t *testing.T) {
|
||||
}
|
||||
|
||||
rr := rand.New(rand.NewSource(1))
|
||||
for range 100_000 {
|
||||
for i := 0; i < 100_000; i++ {
|
||||
testParserReference(t, randomString(rr))
|
||||
}
|
||||
}
|
||||
@@ -335,28 +335,6 @@ func TestExtractColor(t *testing.T) {
|
||||
assert((*offsets)[0], 0, 6, 2, -1, true)
|
||||
assert((*offsets)[1], 6, 11, 200, 100, false)
|
||||
})
|
||||
|
||||
state = nil
|
||||
var color24 tui.Color = (1 << 24) + (180 << 16) + (190 << 8) + 254
|
||||
src = "\x1b[1mhello \x1b[22;1;38:2:180:190:254mworld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 2 {
|
||||
t.Fail()
|
||||
}
|
||||
if state.fg != color24 || state.attr != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 6, -1, -1, true)
|
||||
assert((*offsets)[1], 6, 11, color24, -1, true)
|
||||
})
|
||||
|
||||
src = "\x1b]133;A\x1b\\hello \x1b]133;C\x1b\\world"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 11, color24, -1, true)
|
||||
})
|
||||
}
|
||||
|
||||
func TestAnsiCodeStringConversion(t *testing.T) {
|
||||
@@ -364,15 +342,12 @@ func TestAnsiCodeStringConversion(t *testing.T) {
|
||||
state := interpretCode(code, prevState)
|
||||
if expected != state.ToString() {
|
||||
t.Errorf("expected: %s, actual: %s",
|
||||
strings.ReplaceAll(expected, "\x1b[", "\\x1b["),
|
||||
strings.ReplaceAll(state.ToString(), "\x1b[", "\\x1b["))
|
||||
strings.Replace(expected, "\x1b[", "\\x1b[", -1),
|
||||
strings.Replace(state.ToString(), "\x1b[", "\\x1b[", -1))
|
||||
}
|
||||
}
|
||||
assert("\x1b[m", nil, "")
|
||||
assert("\x1b[m", &ansiState{attr: tui.Blink, ul: -1, lbg: -1}, "")
|
||||
assert("\x1b[0m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
||||
assert("\x1b[;m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
||||
assert("\x1b[;;m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
||||
assert("\x1b[m", &ansiState{attr: tui.Blink, lbg: -1}, "")
|
||||
|
||||
assert("\x1b[31m", nil, "\x1b[31;49m")
|
||||
assert("\x1b[41m", nil, "\x1b[39;41m")
|
||||
@@ -380,146 +355,39 @@ func TestAnsiCodeStringConversion(t *testing.T) {
|
||||
assert("\x1b[92m", nil, "\x1b[92;49m")
|
||||
assert("\x1b[102m", nil, "\x1b[39;102m")
|
||||
|
||||
assert("\x1b[31m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "\x1b[31;44m")
|
||||
assert("\x1b[1;2;31m", &ansiState{fg: 2, bg: -1, ul: -1, attr: tui.Reverse, lbg: -1}, "\x1b[1;2;7;31;49m")
|
||||
assert("\x1b[31m", &ansiState{fg: 4, bg: 4, lbg: -1}, "\x1b[31;44m")
|
||||
assert("\x1b[1;2;31m", &ansiState{fg: 2, bg: -1, attr: tui.Reverse, lbg: -1}, "\x1b[1;2;7;31;49m")
|
||||
assert("\x1b[38;5;100;48;5;200m", nil, "\x1b[38;5;100;48;5;200m")
|
||||
assert("\x1b[38:5:100:48:5:200m", nil, "\x1b[38;5;100;48;5;200m")
|
||||
assert("\x1b[48;5;100;38;5;200m", nil, "\x1b[38;5;200;48;5;100m")
|
||||
assert("\x1b[48;5;100;38;2;10;20;30;1m", nil, "\x1b[1;38;2;10;20;30;48;5;100m")
|
||||
assert("\x1b[48;5;100;38;2;10;20;30;7m",
|
||||
&ansiState{attr: tui.Dim | tui.Italic, fg: 1, bg: 1, ul: -1},
|
||||
&ansiState{attr: tui.Dim | tui.Italic, fg: 1, bg: 1},
|
||||
"\x1b[2;3;7;38;2;10;20;30;48;5;100m")
|
||||
|
||||
// Underline styles
|
||||
assert("\x1b[4:3m", nil, "\x1b[4:3;39;49m")
|
||||
assert("\x1b[4:2m", nil, "\x1b[4:2;39;49m")
|
||||
assert("\x1b[4:4m", nil, "\x1b[4:4;39;49m")
|
||||
assert("\x1b[4:5m", nil, "\x1b[4:5;39;49m")
|
||||
assert("\x1b[4:1m", nil, "\x1b[4;39;49m")
|
||||
|
||||
// Underline color (256-color)
|
||||
assert("\x1b[4;58;5;100m", nil, "\x1b[4;39;49;58;5;100m")
|
||||
// Underline color (24-bit)
|
||||
assert("\x1b[4;58;2;255;0;128m", nil, "\x1b[4;39;49;58;2;255;0;128m")
|
||||
// Curly underline + underline color
|
||||
assert("\x1b[4:3;58;2;255;0;0m", nil, "\x1b[4:3;39;49;58;2;255;0;0m")
|
||||
// SGR 59 resets underline color
|
||||
assert("\x1b[59m", &ansiState{fg: 1, bg: -1, ul: 100, lbg: -1}, "\x1b[31;49m")
|
||||
}
|
||||
|
||||
func TestParseAnsiCode(t *testing.T) {
|
||||
tests := []struct {
|
||||
In string
|
||||
Exp string
|
||||
N int
|
||||
Sep byte
|
||||
In, Exp string
|
||||
N int
|
||||
}{
|
||||
{"123", "", 123, 0},
|
||||
{"1a", "", -1, 0},
|
||||
{"1a;12", "12", -1, ';'},
|
||||
{"12;a", "a", 12, ';'},
|
||||
{"-2", "", -1, 0},
|
||||
// Colon sub-parameters: earliest separator wins (@shtse8)
|
||||
{"4:3", "3", 4, ':'},
|
||||
{"4:3;31", "3;31", 4, ':'},
|
||||
{"38:2:255:0:0", "2:255:0:0", 38, ':'},
|
||||
{"58:5:200", "5:200", 58, ':'},
|
||||
// Semicolon before colon
|
||||
{"4;38:2:0:0:0", "38:2:0:0:0", 4, ';'},
|
||||
{"123", "", 123},
|
||||
{"1a", "", -1},
|
||||
{"1a;12", "12", -1},
|
||||
{"12;a", "a", 12},
|
||||
{"-2", "", -1},
|
||||
}
|
||||
for _, x := range tests {
|
||||
n, sep, s := parseAnsiCode(x.In)
|
||||
if n != x.N || s != x.Exp || sep != x.Sep {
|
||||
t.Fatalf("%q: got: (%d %q %q) want: (%d %q %q)", x.In, n, s, string(sep), x.N, x.Exp, string(x.Sep))
|
||||
n, s := parseAnsiCode(x.In)
|
||||
if n != x.N || s != x.Exp {
|
||||
t.Fatalf("%q: got: (%d %q) want: (%d %q)", x.In, n, s, x.N, x.Exp)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Test cases adapted from @shtse8 (PR #4678)
|
||||
func TestInterpretCodeUnderlineStyles(t *testing.T) {
|
||||
// 4:0 = no underline
|
||||
state := interpretCode("\x1b[4:0m", nil)
|
||||
if state.attr&tui.Underline != 0 {
|
||||
t.Error("4:0 should not set underline")
|
||||
}
|
||||
|
||||
// 4:1 = single underline
|
||||
state = interpretCode("\x1b[4:1m", nil)
|
||||
if state.attr&tui.Underline == 0 {
|
||||
t.Error("4:1 should set underline")
|
||||
}
|
||||
|
||||
// 4:3 = curly underline
|
||||
state = interpretCode("\x1b[4:3m", nil)
|
||||
if state.attr&tui.Underline == 0 {
|
||||
t.Error("4:3 should set underline")
|
||||
}
|
||||
if state.attr.UnderlineStyle() != tui.UlStyleCurly {
|
||||
t.Error("4:3 should set curly underline style")
|
||||
}
|
||||
|
||||
// 4:3 should NOT set italic (3 is a sub-param, not SGR 3)
|
||||
if state.attr&tui.Italic != 0 {
|
||||
t.Error("4:3 should not set italic")
|
||||
}
|
||||
|
||||
// 4:2;31 = double underline + red fg
|
||||
state = interpretCode("\x1b[4:2;31m", nil)
|
||||
if state.attr&tui.Underline == 0 {
|
||||
t.Error("4:2;31 should set underline")
|
||||
}
|
||||
if state.fg != 1 {
|
||||
t.Errorf("4:2;31 should set fg to red (1), got %d", state.fg)
|
||||
}
|
||||
if state.attr&tui.Dim != 0 {
|
||||
t.Error("4:2;31 should not set dim")
|
||||
}
|
||||
|
||||
// Plain 4 still works
|
||||
state = interpretCode("\x1b[4m", nil)
|
||||
if state.attr&tui.Underline == 0 {
|
||||
t.Error("4 should set underline")
|
||||
}
|
||||
|
||||
// 4;2 (semicolon) = underline + dim
|
||||
state = interpretCode("\x1b[4;2m", nil)
|
||||
if state.attr&tui.Underline == 0 {
|
||||
t.Error("4;2 should set underline")
|
||||
}
|
||||
if state.attr&tui.Dim == 0 {
|
||||
t.Error("4;2 should set dim")
|
||||
}
|
||||
}
|
||||
|
||||
// Test cases adapted from @shtse8 (PR #4678)
|
||||
func TestInterpretCodeUnderlineColor(t *testing.T) {
|
||||
// 58:2:R:G:B should not affect fg or bg
|
||||
state := interpretCode("\x1b[58:2:255:0:0m", nil)
|
||||
if state.fg != -1 || state.bg != -1 {
|
||||
t.Errorf("58:2:R:G:B should not affect fg/bg, got fg=%d bg=%d", state.fg, state.bg)
|
||||
}
|
||||
|
||||
// 58:5:200 should not affect fg or bg
|
||||
state = interpretCode("\x1b[58:5:200m", nil)
|
||||
if state.fg != -1 || state.bg != -1 {
|
||||
t.Errorf("58:5:N should not affect fg/bg, got fg=%d bg=%d", state.fg, state.bg)
|
||||
}
|
||||
|
||||
// 58:2:R:G:B combined with 38:2:R:G:B should only set fg
|
||||
state = interpretCode("\x1b[58:2:255:0:0;38:2:0:255:0m", nil)
|
||||
expectedFg := tui.Color(1<<24 | 0<<16 | 255<<8 | 0)
|
||||
if state.fg != expectedFg {
|
||||
t.Errorf("expected fg=%d, got %d", expectedFg, state.fg)
|
||||
}
|
||||
if state.bg != -1 {
|
||||
t.Errorf("bg should be -1, got %d", state.bg)
|
||||
}
|
||||
}
|
||||
|
||||
// kernel/bpf/preload/iterators/README
|
||||
const ansiBenchmarkString = "\x1b[38;5;81m\x1b[01;31m\x1b[Kkernel/\x1b[0m\x1b[38:5:81mbpf/" +
|
||||
"\x1b[0m\x1b[38:5:81mpreload/\x1b[0m\x1b[38;5;81miterators/" +
|
||||
"\x1b[0m\x1b[38:5:149mMakefile\x1b[m\x1b[K\x1b[0m"
|
||||
const ansiBenchmarkString = "\x1b[38;5;81m\x1b[01;31m\x1b[Kkernel/\x1b[0m\x1b[38;5;81mbpf/" +
|
||||
"\x1b[0m\x1b[38;5;81mpreload/\x1b[0m\x1b[38;5;81miterators/" +
|
||||
"\x1b[0m\x1b[38;5;149mMakefile\x1b[m\x1b[K\x1b[0m"
|
||||
|
||||
func BenchmarkNextAnsiEscapeSequence(b *testing.B) {
|
||||
b.SetBytes(int64(len(ansiBenchmarkString)))
|
||||
|
||||
+17
-34
@@ -2,40 +2,23 @@ package fzf
|
||||
|
||||
import "sync"
|
||||
|
||||
// ChunkBitmap is a bitmap with one bit per item in a chunk.
|
||||
type ChunkBitmap [chunkBitWords]uint64
|
||||
// queryCache associates strings to lists of items
|
||||
type queryCache map[string][]Result
|
||||
|
||||
// queryCache associates query strings to bitmaps of matching items
|
||||
type queryCache map[string]ChunkBitmap
|
||||
|
||||
// ChunkCache associates Chunk and query string to bitmaps
|
||||
// ChunkCache associates Chunk and query string to lists of items
|
||||
type ChunkCache struct {
|
||||
mutex sync.Mutex
|
||||
cache map[*Chunk]*queryCache
|
||||
}
|
||||
|
||||
// NewChunkCache returns a new ChunkCache
|
||||
func NewChunkCache() *ChunkCache {
|
||||
return &ChunkCache{sync.Mutex{}, make(map[*Chunk]*queryCache)}
|
||||
func NewChunkCache() ChunkCache {
|
||||
return ChunkCache{sync.Mutex{}, make(map[*Chunk]*queryCache)}
|
||||
}
|
||||
|
||||
func (cc *ChunkCache) Clear() {
|
||||
cc.mutex.Lock()
|
||||
cc.cache = make(map[*Chunk]*queryCache)
|
||||
cc.mutex.Unlock()
|
||||
}
|
||||
|
||||
func (cc *ChunkCache) retire(chunk ...*Chunk) {
|
||||
cc.mutex.Lock()
|
||||
for _, c := range chunk {
|
||||
delete(cc.cache, c)
|
||||
}
|
||||
cc.mutex.Unlock()
|
||||
}
|
||||
|
||||
// Add stores the bitmap for the given chunk and key
|
||||
func (cc *ChunkCache) Add(chunk *Chunk, key string, bitmap ChunkBitmap, matchCount int) {
|
||||
if len(key) == 0 || !chunk.IsFull() || matchCount > queryCacheMax {
|
||||
// Add adds the list to the cache
|
||||
func (cc *ChunkCache) Add(chunk *Chunk, key string, list []Result) {
|
||||
if len(key) == 0 || !chunk.IsFull() || len(list) > queryCacheMax {
|
||||
return
|
||||
}
|
||||
|
||||
@@ -47,11 +30,11 @@ func (cc *ChunkCache) Add(chunk *Chunk, key string, bitmap ChunkBitmap, matchCou
|
||||
cc.cache[chunk] = &queryCache{}
|
||||
qc = cc.cache[chunk]
|
||||
}
|
||||
(*qc)[key] = bitmap
|
||||
(*qc)[key] = list
|
||||
}
|
||||
|
||||
// Lookup returns the bitmap for the exact key
|
||||
func (cc *ChunkCache) Lookup(chunk *Chunk, key string) *ChunkBitmap {
|
||||
// Lookup is called to lookup ChunkCache
|
||||
func (cc *ChunkCache) Lookup(chunk *Chunk, key string) []Result {
|
||||
if len(key) == 0 || !chunk.IsFull() {
|
||||
return nil
|
||||
}
|
||||
@@ -61,15 +44,15 @@ func (cc *ChunkCache) Lookup(chunk *Chunk, key string) *ChunkBitmap {
|
||||
|
||||
qc, ok := cc.cache[chunk]
|
||||
if ok {
|
||||
if bm, ok := (*qc)[key]; ok {
|
||||
return &bm
|
||||
list, ok := (*qc)[key]
|
||||
if ok {
|
||||
return list
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// Search finds the bitmap for the longest prefix or suffix of the key
|
||||
func (cc *ChunkCache) Search(chunk *Chunk, key string) *ChunkBitmap {
|
||||
func (cc *ChunkCache) Search(chunk *Chunk, key string) []Result {
|
||||
if len(key) == 0 || !chunk.IsFull() {
|
||||
return nil
|
||||
}
|
||||
@@ -89,8 +72,8 @@ func (cc *ChunkCache) Search(chunk *Chunk, key string) *ChunkBitmap {
|
||||
prefix := key[:len(key)-idx]
|
||||
suffix := key[idx:]
|
||||
for _, substr := range [2]string{prefix, suffix} {
|
||||
if bm, found := (*qc)[substr]; found {
|
||||
return &bm
|
||||
if cached, found := (*qc)[substr]; found {
|
||||
return cached
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
+11
-11
@@ -6,34 +6,34 @@ func TestChunkCache(t *testing.T) {
|
||||
cache := NewChunkCache()
|
||||
chunk1p := &Chunk{}
|
||||
chunk2p := &Chunk{count: chunkSize}
|
||||
bm1 := ChunkBitmap{1}
|
||||
bm2 := ChunkBitmap{1, 2}
|
||||
cache.Add(chunk1p, "foo", bm1, 1)
|
||||
cache.Add(chunk2p, "foo", bm1, 1)
|
||||
cache.Add(chunk2p, "bar", bm2, 2)
|
||||
items1 := []Result{{}}
|
||||
items2 := []Result{{}, {}}
|
||||
cache.Add(chunk1p, "foo", items1)
|
||||
cache.Add(chunk2p, "foo", items1)
|
||||
cache.Add(chunk2p, "bar", items2)
|
||||
|
||||
{ // chunk1 is not full
|
||||
cached := cache.Lookup(chunk1p, "foo")
|
||||
if cached != nil {
|
||||
t.Error("Cached disabled for non-full chunks", cached)
|
||||
t.Error("Cached disabled for non-empty chunks", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk2p, "foo")
|
||||
if cached == nil || cached[0] != 1 {
|
||||
t.Error("Expected bitmap cached", cached)
|
||||
if cached == nil || len(cached) != 1 {
|
||||
t.Error("Expected 1 item cached", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk2p, "bar")
|
||||
if cached == nil || cached[1] != 2 {
|
||||
t.Error("Expected bitmap cached", cached)
|
||||
if cached == nil || len(cached) != 2 {
|
||||
t.Error("Expected 2 items cached", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk1p, "foobar")
|
||||
if cached != nil {
|
||||
t.Error("Expected nil cached", cached)
|
||||
t.Error("Expected 0 item cached", cached)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
+6
-87
@@ -16,16 +16,14 @@ type ChunkList struct {
|
||||
chunks []*Chunk
|
||||
mutex sync.Mutex
|
||||
trans ItemBuilder
|
||||
cache *ChunkCache
|
||||
}
|
||||
|
||||
// NewChunkList returns a new ChunkList
|
||||
func NewChunkList(cache *ChunkCache, trans ItemBuilder) *ChunkList {
|
||||
func NewChunkList(trans ItemBuilder) *ChunkList {
|
||||
return &ChunkList{
|
||||
chunks: []*Chunk{},
|
||||
mutex: sync.Mutex{},
|
||||
trans: trans,
|
||||
cache: cache}
|
||||
trans: trans}
|
||||
}
|
||||
|
||||
func (c *Chunk) push(trans ItemBuilder, data []byte) bool {
|
||||
@@ -41,42 +39,16 @@ func (c *Chunk) IsFull() bool {
|
||||
return c.count == chunkSize
|
||||
}
|
||||
|
||||
func (c *Chunk) lastIndex(minValue int32) int32 {
|
||||
if c.count == 0 {
|
||||
return minValue
|
||||
}
|
||||
return c.items[c.count-1].Index() + 1 // Exclusive
|
||||
}
|
||||
|
||||
func (cl *ChunkList) lastChunk() *Chunk {
|
||||
return cl.chunks[len(cl.chunks)-1]
|
||||
}
|
||||
|
||||
// GetItems returns the first n items from the given chunks
|
||||
func GetItems(chunks []*Chunk, n int) []Item {
|
||||
items := make([]Item, 0, n)
|
||||
for _, chunk := range chunks {
|
||||
for i := 0; i < chunk.count && len(items) < n; i++ {
|
||||
items = append(items, chunk.items[i])
|
||||
}
|
||||
if len(items) >= n {
|
||||
break
|
||||
}
|
||||
}
|
||||
return items
|
||||
}
|
||||
|
||||
// CountItems returns the total number of Items
|
||||
func CountItems(cs []*Chunk) int {
|
||||
if len(cs) == 0 {
|
||||
return 0
|
||||
}
|
||||
if len(cs) == 1 {
|
||||
return cs[0].count
|
||||
}
|
||||
|
||||
// First chunk might not be full due to --tail=N
|
||||
return cs[0].count + chunkSize*(len(cs)-2) + cs[len(cs)-1].count
|
||||
return chunkSize*(len(cs)-1) + cs[len(cs)-1].count
|
||||
}
|
||||
|
||||
// Push adds the item to the list
|
||||
@@ -99,72 +71,19 @@ func (cl *ChunkList) Clear() {
|
||||
cl.mutex.Unlock()
|
||||
}
|
||||
|
||||
// ForEachItem iterates all items and applies fn to each one.
|
||||
// The done callback runs under the lock to safely update shared state.
|
||||
func (cl *ChunkList) ForEachItem(fn func(*Item), done func()) {
|
||||
cl.mutex.Lock()
|
||||
for _, chunk := range cl.chunks {
|
||||
for i := 0; i < chunk.count; i++ {
|
||||
fn(&chunk.items[i])
|
||||
}
|
||||
}
|
||||
if done != nil {
|
||||
done()
|
||||
}
|
||||
cl.mutex.Unlock()
|
||||
}
|
||||
|
||||
// Snapshot returns immutable snapshot of the ChunkList
|
||||
func (cl *ChunkList) Snapshot(tail int) ([]*Chunk, int, bool) {
|
||||
func (cl *ChunkList) Snapshot() ([]*Chunk, int) {
|
||||
cl.mutex.Lock()
|
||||
|
||||
changed := false
|
||||
if tail > 0 && CountItems(cl.chunks) > tail {
|
||||
changed = true
|
||||
// Find the number of chunks to keep
|
||||
numChunks := 0
|
||||
for left, i := tail, len(cl.chunks)-1; left > 0 && i >= 0; i-- {
|
||||
numChunks++
|
||||
left -= cl.chunks[i].count
|
||||
}
|
||||
|
||||
// Copy the chunks to keep
|
||||
ret := make([]*Chunk, numChunks)
|
||||
minIndex := len(cl.chunks) - numChunks
|
||||
cl.cache.retire(cl.chunks[:minIndex]...)
|
||||
copy(ret, cl.chunks[minIndex:])
|
||||
|
||||
for left, i := tail, len(ret)-1; i >= 0; i-- {
|
||||
chunk := ret[i]
|
||||
if chunk.count > left {
|
||||
newChunk := *chunk
|
||||
newChunk.count = left
|
||||
oldCount := chunk.count
|
||||
for i := 0; i < left; i++ {
|
||||
newChunk.items[i] = chunk.items[oldCount-left+i]
|
||||
}
|
||||
ret[i] = &newChunk
|
||||
cl.cache.retire(chunk)
|
||||
break
|
||||
}
|
||||
left -= chunk.count
|
||||
}
|
||||
cl.chunks = ret
|
||||
}
|
||||
|
||||
ret := make([]*Chunk, len(cl.chunks))
|
||||
copy(ret, cl.chunks)
|
||||
|
||||
// Duplicate the first and the last chunk
|
||||
// Duplicate the last chunk
|
||||
if cnt := len(ret); cnt > 0 {
|
||||
if tail > 0 && cnt > 1 {
|
||||
newChunk := *ret[0]
|
||||
ret[0] = &newChunk
|
||||
}
|
||||
newChunk := *ret[cnt-1]
|
||||
ret[cnt-1] = &newChunk
|
||||
}
|
||||
|
||||
cl.mutex.Unlock()
|
||||
return ret, CountItems(ret), changed
|
||||
return ret, CountItems(ret)
|
||||
}
|
||||
|
||||
+6
-42
@@ -11,13 +11,13 @@ func TestChunkList(t *testing.T) {
|
||||
// FIXME global
|
||||
sortCriteria = []criterion{byScore, byLength}
|
||||
|
||||
cl := NewChunkList(NewChunkCache(), func(item *Item, s []byte) bool {
|
||||
cl := NewChunkList(func(item *Item, s []byte) bool {
|
||||
item.text = util.ToChars(s)
|
||||
return true
|
||||
})
|
||||
|
||||
// Snapshot
|
||||
snapshot, count, _ := cl.Snapshot(0)
|
||||
snapshot, count := cl.Snapshot()
|
||||
if len(snapshot) > 0 || count > 0 {
|
||||
t.Error("Snapshot should be empty now")
|
||||
}
|
||||
@@ -32,7 +32,7 @@ func TestChunkList(t *testing.T) {
|
||||
}
|
||||
|
||||
// But the new snapshot should contain the added items
|
||||
snapshot, count, _ = cl.Snapshot(0)
|
||||
snapshot, count = cl.Snapshot()
|
||||
if len(snapshot) != 1 && count != 2 {
|
||||
t.Error("Snapshot should not be empty now")
|
||||
}
|
||||
@@ -51,8 +51,8 @@ func TestChunkList(t *testing.T) {
|
||||
}
|
||||
|
||||
// Add more data
|
||||
for i := range chunkSize * 2 {
|
||||
cl.Push(fmt.Appendf(nil, "item %d", i))
|
||||
for i := 0; i < chunkSize*2; i++ {
|
||||
cl.Push([]byte(fmt.Sprintf("item %d", i)))
|
||||
}
|
||||
|
||||
// Previous snapshot should remain the same
|
||||
@@ -61,7 +61,7 @@ func TestChunkList(t *testing.T) {
|
||||
}
|
||||
|
||||
// New snapshot
|
||||
snapshot, count, _ = cl.Snapshot(0)
|
||||
snapshot, count = cl.Snapshot()
|
||||
if len(snapshot) != 3 || !snapshot[0].IsFull() ||
|
||||
!snapshot[1].IsFull() || snapshot[2].IsFull() || count != chunkSize*2+2 {
|
||||
t.Error("Expected two full chunks and one more chunk")
|
||||
@@ -78,39 +78,3 @@ func TestChunkList(t *testing.T) {
|
||||
t.Error("Unexpected number of items:", lastChunkCount)
|
||||
}
|
||||
}
|
||||
|
||||
func TestChunkListTail(t *testing.T) {
|
||||
cl := NewChunkList(NewChunkCache(), func(item *Item, s []byte) bool {
|
||||
item.text = util.ToChars(s)
|
||||
return true
|
||||
})
|
||||
total := chunkSize*2 + chunkSize/2
|
||||
for i := range total {
|
||||
cl.Push(fmt.Appendf(nil, "item %d", i))
|
||||
}
|
||||
|
||||
snapshot, count, changed := cl.Snapshot(0)
|
||||
assertCount := func(expected int, shouldChange bool) {
|
||||
if count != expected || CountItems(snapshot) != expected {
|
||||
t.Errorf("Unexpected count: %d (expected: %d)", count, expected)
|
||||
}
|
||||
if changed != shouldChange {
|
||||
t.Error("Unexpected change status")
|
||||
}
|
||||
}
|
||||
assertCount(total, false)
|
||||
|
||||
tail := chunkSize + chunkSize/2
|
||||
snapshot, count, changed = cl.Snapshot(tail)
|
||||
assertCount(tail, true)
|
||||
|
||||
snapshot, count, changed = cl.Snapshot(tail)
|
||||
assertCount(tail, false)
|
||||
|
||||
snapshot, count, changed = cl.Snapshot(0)
|
||||
assertCount(tail, false)
|
||||
|
||||
tail = chunkSize / 2
|
||||
snapshot, count, changed = cl.Snapshot(tail)
|
||||
assertCount(tail, true)
|
||||
}
|
||||
|
||||
+23
-15
@@ -2,6 +2,7 @@ package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"os"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
@@ -14,7 +15,6 @@ const (
|
||||
|
||||
// Reader
|
||||
readerBufferSize = 64 * 1024
|
||||
readerSlabSize = 128 * 1024
|
||||
readerPollIntervalMin = 10 * time.Millisecond
|
||||
readerPollIntervalStep = 5 * time.Millisecond
|
||||
readerPollIntervalMax = 50 * time.Millisecond
|
||||
@@ -26,26 +26,23 @@ const (
|
||||
previewCancelWait = 500 * time.Millisecond
|
||||
previewChunkDelay = 100 * time.Millisecond
|
||||
previewDelayed = 500 * time.Millisecond
|
||||
maxPatternLength = 1000
|
||||
maxPatternLength = 300
|
||||
maxMulti = math.MaxInt32
|
||||
|
||||
// Background processes
|
||||
maxBgProcesses = 30
|
||||
maxBgProcessesPerAction = 3
|
||||
|
||||
// Matcher
|
||||
progressMinDuration = 200 * time.Millisecond
|
||||
numPartitionsMultiplier = 8
|
||||
maxPartitions = 32
|
||||
progressMinDuration = 200 * time.Millisecond
|
||||
|
||||
// Capacity of each chunk
|
||||
chunkSize int = 1024
|
||||
chunkBitWords = (chunkSize + 63) / 64
|
||||
chunkSize int = 100
|
||||
|
||||
// Pre-allocated memory slices to minimize GC
|
||||
slab16Size int = 100 * 1024 // 200KB * 32 = 12.8MB
|
||||
slab32Size int = 2048 // 8KB * 32 = 256KB
|
||||
|
||||
// Do not cache results of low selectivity queries
|
||||
queryCacheMax int = chunkSize / 2
|
||||
queryCacheMax int = chunkSize / 5
|
||||
|
||||
// Not to cache mergers with large lists
|
||||
mergerCacheMax int = 100000
|
||||
@@ -57,6 +54,16 @@ const (
|
||||
defaultJumpLabels string = "asdfghjklqwertyuiopzxcvbnm1234567890ASDFGHJKLQWERTYUIOPZXCVBNM`~;:,<.>/?'\"!@#$%^&*()[{]}-_=+"
|
||||
)
|
||||
|
||||
var defaultCommand string
|
||||
|
||||
func init() {
|
||||
if !util.IsWindows() {
|
||||
defaultCommand = `set -o pipefail; command find -L . -mindepth 1 \( -path '*/\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \) -prune -o -type f -print -o -type l -print 2> /dev/null | cut -b3-`
|
||||
} else if os.Getenv("TERM") == "cygwin" {
|
||||
defaultCommand = `sh -c "command find -L . -mindepth 1 -path '*/\.*' -prune -o -type f -print -o -type l -print 2> /dev/null | cut -b3-"`
|
||||
}
|
||||
}
|
||||
|
||||
// fzf events
|
||||
const (
|
||||
EvtReadNew util.EventType = iota
|
||||
@@ -64,14 +71,15 @@ const (
|
||||
EvtSearchNew
|
||||
EvtSearchProgress
|
||||
EvtSearchFin
|
||||
EvtHeader
|
||||
EvtReady
|
||||
EvtQuit
|
||||
)
|
||||
|
||||
const (
|
||||
ExitOk = 0
|
||||
ExitNoMatch = 1
|
||||
ExitError = 2
|
||||
ExitBecome = 126
|
||||
ExitInterrupt = 130
|
||||
exitCancel = -1
|
||||
exitOk = 0
|
||||
exitNoMatch = 1
|
||||
exitError = 2
|
||||
exitInterrupt = 130
|
||||
)
|
||||
|
||||
+158
-447
@@ -1,15 +1,35 @@
|
||||
// Package fzf implements fzf, a command-line fuzzy finder.
|
||||
/*
|
||||
Package fzf implements fzf, a command-line fuzzy finder.
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
*/
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"maps"
|
||||
"math"
|
||||
"os"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
@@ -19,69 +39,23 @@ Reader -> EvtReadNew -> Matcher (restart)
|
||||
Terminal -> EvtSearchNew:bool -> Matcher (restart)
|
||||
Matcher -> EvtSearchProgress -> Terminal (update info)
|
||||
Matcher -> EvtSearchFin -> Terminal (update list)
|
||||
Matcher -> EvtHeader -> Terminal (update header)
|
||||
*/
|
||||
|
||||
type revision struct {
|
||||
major int
|
||||
minor int
|
||||
}
|
||||
|
||||
func (r *revision) bumpMajor() {
|
||||
r.major++
|
||||
r.minor = 0
|
||||
}
|
||||
|
||||
func (r *revision) bumpMinor() {
|
||||
r.minor++
|
||||
}
|
||||
|
||||
func (r revision) compatible(other revision) bool {
|
||||
return r.major == other.major
|
||||
}
|
||||
|
||||
func buildItemTransformer(opts *Options) func(*Item) string {
|
||||
if opts.AcceptNth != nil {
|
||||
fn := opts.AcceptNth(opts.Delimiter)
|
||||
return func(item *Item) string {
|
||||
return item.acceptNth(opts.Ansi, opts.Delimiter, fn)
|
||||
}
|
||||
}
|
||||
return func(item *Item) string {
|
||||
return item.AsString(opts.Ansi)
|
||||
}
|
||||
}
|
||||
|
||||
// Run starts fzf
|
||||
func Run(opts *Options) (int, error) {
|
||||
if opts.Filter == nil {
|
||||
if opts.useTmux() {
|
||||
return runTmux(os.Args, opts)
|
||||
}
|
||||
if opts.useZellij() {
|
||||
return runZellij(os.Args, opts)
|
||||
}
|
||||
|
||||
if needWinpty(opts) {
|
||||
return runWinpty(os.Args, opts)
|
||||
}
|
||||
}
|
||||
|
||||
if err := postProcessOptions(opts); err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
|
||||
defer util.RunAtExitFuncs()
|
||||
|
||||
// Output channel given
|
||||
if opts.Output != nil {
|
||||
opts.Printer = func(str string) {
|
||||
opts.Output <- str
|
||||
}
|
||||
}
|
||||
|
||||
func Run(opts *Options, version string, revision string) {
|
||||
sort := opts.Sort > 0
|
||||
sortCriteria = opts.Criteria
|
||||
|
||||
if opts.Version {
|
||||
if len(revision) > 0 {
|
||||
fmt.Printf("%s (%s)\n", version, revision)
|
||||
} else {
|
||||
fmt.Println(version)
|
||||
}
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
|
||||
// Event channel
|
||||
eventBox := util.NewEventBox()
|
||||
|
||||
@@ -92,82 +66,67 @@ func Run(opts *Options) (int, error) {
|
||||
|
||||
var lineAnsiState, prevLineAnsiState *ansiState
|
||||
if opts.Ansi {
|
||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
prevLineAnsiState = lineAnsiState
|
||||
trimmed, offsets, newState := extractColor(byteString(data), lineAnsiState, nil)
|
||||
lineAnsiState = newState
|
||||
|
||||
// Full line background is found. Add a special marker.
|
||||
if offsets != nil && newState != nil && len(*offsets) > 0 && newState.lbg >= 0 {
|
||||
marker := (*offsets)[len(*offsets)-1]
|
||||
marker.offset[0] = marker.offset[1]
|
||||
marker.color.bg = newState.lbg
|
||||
marker.color.attr = marker.color.attr | tui.FullBg
|
||||
newOffsets := append(*offsets, marker)
|
||||
offsets = &newOffsets
|
||||
|
||||
// Reset the full-line background color
|
||||
lineAnsiState.lbg = -1
|
||||
if opts.Theme.Colored {
|
||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
prevLineAnsiState = lineAnsiState
|
||||
trimmed, offsets, newState := extractColor(string(data), lineAnsiState, nil)
|
||||
lineAnsiState = newState
|
||||
return util.ToChars([]byte(trimmed)), offsets
|
||||
}
|
||||
} else {
|
||||
// When color is disabled but ansi option is given,
|
||||
// we simply strip out ANSI codes from the input
|
||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
trimmed, _, _ := extractColor(string(data), nil, nil)
|
||||
return util.ToChars([]byte(trimmed)), nil
|
||||
}
|
||||
return util.ToChars(stringBytes(trimmed)), offsets
|
||||
}
|
||||
}
|
||||
|
||||
// Chunk list
|
||||
cache := NewChunkCache()
|
||||
var chunkList *ChunkList
|
||||
var itemIndex int32
|
||||
// transformItem applies with-nth transformation to an item's raw data.
|
||||
// It handles ANSI token propagation using prevLineAnsiState for cross-line continuity.
|
||||
transformItem := func(item *Item, data []byte, transformer func([]Token, int32) string, index int32) {
|
||||
tokens := Tokenize(byteString(data), opts.Delimiter)
|
||||
if opts.Ansi && len(tokens) > 1 {
|
||||
var ansiState *ansiState
|
||||
if prevLineAnsiState != nil {
|
||||
ansiStateDup := *prevLineAnsiState
|
||||
ansiState = &ansiStateDup
|
||||
header := make([]string, 0, opts.HeaderLines)
|
||||
if len(opts.WithNth) == 0 {
|
||||
chunkList = NewChunkList(func(item *Item, data []byte) bool {
|
||||
if len(header) < opts.HeaderLines {
|
||||
header = append(header, string(data))
|
||||
eventBox.Set(EvtHeader, header)
|
||||
return false
|
||||
}
|
||||
for _, token := range tokens {
|
||||
prevAnsiState := ansiState
|
||||
_, _, ansiState = extractColor(token.text.ToString(), ansiState, nil)
|
||||
if prevAnsiState != nil {
|
||||
token.text.Prepend("\x1b[m" + prevAnsiState.ToString())
|
||||
} else {
|
||||
token.text.Prepend("\x1b[m")
|
||||
}
|
||||
}
|
||||
}
|
||||
transformed := transformer(tokens, index)
|
||||
item.text, item.colors = ansiProcessor(stringBytes(transformed))
|
||||
|
||||
// We should not trim trailing whitespaces with background colors
|
||||
var maxColorOffset int32
|
||||
if item.colors != nil {
|
||||
for _, ansi := range *item.colors {
|
||||
if ansi.color.bg >= 0 {
|
||||
maxColorOffset = max(maxColorOffset, ansi.offset[1])
|
||||
}
|
||||
}
|
||||
}
|
||||
item.text.TrimTrailingWhitespaces(int(maxColorOffset))
|
||||
}
|
||||
|
||||
var nthTransformer func([]Token, int32) string
|
||||
if opts.WithNth == nil {
|
||||
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
||||
item.text, item.colors = ansiProcessor(data)
|
||||
item.text.Index = itemIndex
|
||||
itemIndex++
|
||||
return true
|
||||
})
|
||||
} else {
|
||||
nthTransformer = opts.WithNth(opts.Delimiter)
|
||||
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
||||
if nthTransformer == nil {
|
||||
item.text, item.colors = ansiProcessor(data)
|
||||
} else {
|
||||
transformItem(item, data, nthTransformer, itemIndex)
|
||||
chunkList = NewChunkList(func(item *Item, data []byte) bool {
|
||||
tokens := Tokenize(string(data), opts.Delimiter)
|
||||
if opts.Ansi && opts.Theme.Colored && len(tokens) > 1 {
|
||||
var ansiState *ansiState
|
||||
if prevLineAnsiState != nil {
|
||||
ansiStateDup := *prevLineAnsiState
|
||||
ansiState = &ansiStateDup
|
||||
}
|
||||
for _, token := range tokens {
|
||||
prevAnsiState := ansiState
|
||||
_, _, ansiState = extractColor(token.text.ToString(), ansiState, nil)
|
||||
if prevAnsiState != nil {
|
||||
token.text.Prepend("\x1b[m" + prevAnsiState.ToString())
|
||||
} else {
|
||||
token.text.Prepend("\x1b[m")
|
||||
}
|
||||
}
|
||||
}
|
||||
trans := Transform(tokens, opts.WithNth)
|
||||
transformed := joinTokens(trans)
|
||||
if len(header) < opts.HeaderLines {
|
||||
header = append(header, transformed)
|
||||
eventBox.Set(EvtHeader, header)
|
||||
return false
|
||||
}
|
||||
item.text, item.colors = ansiProcessor([]byte(transformed))
|
||||
item.text.TrimTrailingWhitespaces()
|
||||
item.text.Index = itemIndex
|
||||
item.origText = &data
|
||||
itemIndex++
|
||||
@@ -175,87 +134,33 @@ func Run(opts *Options) (int, error) {
|
||||
})
|
||||
}
|
||||
|
||||
// Process executor
|
||||
executor := util.NewExecutor(opts.WithShell)
|
||||
|
||||
// Terminal I/O
|
||||
var terminal *Terminal
|
||||
var err error
|
||||
var initialEnv []string
|
||||
initialReload := opts.extractReloadOnStart()
|
||||
if opts.Filter == nil {
|
||||
terminal, err = NewTerminal(opts, eventBox, executor)
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
if len(initialReload) > 0 {
|
||||
var temps []string
|
||||
initialReload, temps = terminal.replacePlaceholderInInitialCommand(initialReload)
|
||||
initialEnv = terminal.environ()
|
||||
defer removeFiles(temps)
|
||||
}
|
||||
}
|
||||
|
||||
// Reader
|
||||
streamingFilter := opts.Filter != nil && !sort && !opts.Tac && !opts.Sync && opts.Bench == 0
|
||||
streamingFilter := opts.Filter != nil && !sort && !opts.Tac && !opts.Sync
|
||||
var reader *Reader
|
||||
var ingestionStart time.Time
|
||||
if !streamingFilter {
|
||||
reader = NewReader(func(data []byte) bool {
|
||||
return chunkList.Push(data)
|
||||
}, eventBox, executor, opts.ReadZero, opts.Filter == nil)
|
||||
|
||||
ingestionStart = time.Now()
|
||||
readyChan := make(chan bool)
|
||||
go reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv, readyChan)
|
||||
<-readyChan
|
||||
}, eventBox, opts.ReadZero, opts.Filter == nil)
|
||||
go reader.ReadSource()
|
||||
}
|
||||
|
||||
// Matcher
|
||||
forward := true
|
||||
withPos := false
|
||||
for idx := len(opts.Criteria) - 1; idx > 0; idx-- {
|
||||
switch opts.Criteria[idx] {
|
||||
case byChunk:
|
||||
withPos = true
|
||||
case byEnd:
|
||||
forward = false
|
||||
case byBegin:
|
||||
forward = true
|
||||
case byPathname:
|
||||
withPos = true
|
||||
for _, cri := range opts.Criteria[1:] {
|
||||
if cri == byEnd {
|
||||
forward = false
|
||||
break
|
||||
}
|
||||
if cri == byBegin {
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
nth := opts.Nth
|
||||
inputRevision := revision{}
|
||||
snapshotRevision := revision{}
|
||||
patternCache := make(map[string]*Pattern)
|
||||
denyMutex := sync.Mutex{}
|
||||
denylist := make(map[int32]struct{})
|
||||
clearDenylist := func() {
|
||||
denyMutex.Lock()
|
||||
if len(denylist) > 0 {
|
||||
patternCache = make(map[string]*Pattern)
|
||||
}
|
||||
denylist = make(map[int32]struct{})
|
||||
denyMutex.Unlock()
|
||||
}
|
||||
if opts.HeaderLines > math.MaxInt32 {
|
||||
opts.HeaderLines = math.MaxInt32
|
||||
}
|
||||
headerLines := int32(opts.HeaderLines)
|
||||
headerUpdated := false
|
||||
patternBuilder := func(runes []rune) *Pattern {
|
||||
denyMutex.Lock()
|
||||
denylistCopy := maps.Clone(denylist)
|
||||
denyMutex.Unlock()
|
||||
return BuildPattern(cache, patternCache,
|
||||
opts.Fuzzy, opts.FuzzyAlgo, opts.Extended, opts.Case, opts.Normalize, forward, withPos,
|
||||
opts.Filter == nil, nth, opts.Delimiter, inputRevision, runes, denylistCopy, headerLines)
|
||||
return BuildPattern(
|
||||
opts.Fuzzy, opts.FuzzyAlgo, opts.Extended, opts.Case, opts.Normalize, forward,
|
||||
opts.Filter == nil, opts.Nth, opts.Delimiter, runes)
|
||||
}
|
||||
matcher := NewMatcher(cache, patternBuilder, sort, opts.Tac, eventBox, inputRevision, opts.Threads)
|
||||
matcher := NewMatcher(patternBuilder, sort, opts.Tac, eventBox)
|
||||
|
||||
// Filtering mode
|
||||
if opts.Filter != nil {
|
||||
@@ -266,89 +171,38 @@ func Run(opts *Options) (int, error) {
|
||||
pattern := patternBuilder([]rune(*opts.Filter))
|
||||
matcher.sort = pattern.sortable
|
||||
|
||||
transformer := buildItemTransformer(opts)
|
||||
|
||||
found := false
|
||||
if streamingFilter {
|
||||
slab := util.MakeSlab(slab16Size, slab32Size)
|
||||
mutex := sync.Mutex{}
|
||||
reader := NewReader(
|
||||
func(runes []byte) bool {
|
||||
item := Item{}
|
||||
if chunkList.trans(&item, runes) {
|
||||
if item.Index() < headerLines {
|
||||
return false
|
||||
}
|
||||
mutex.Lock()
|
||||
if result, _, _ := pattern.MatchItem(&item, false, slab); result.item != nil {
|
||||
opts.Printer(transformer(&item))
|
||||
if result, _, _ := pattern.MatchItem(&item, false, slab); result != nil {
|
||||
opts.Printer(item.text.ToString())
|
||||
found = true
|
||||
}
|
||||
mutex.Unlock()
|
||||
}
|
||||
return false
|
||||
}, eventBox, executor, opts.ReadZero, false)
|
||||
reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv, nil)
|
||||
}, eventBox, opts.ReadZero, false)
|
||||
reader.ReadSource()
|
||||
} else {
|
||||
eventBox.Unwatch(EvtReadNew)
|
||||
eventBox.WaitFor(EvtReadFin)
|
||||
ingestionTime := time.Since(ingestionStart)
|
||||
|
||||
// NOTE: Streaming filter is inherently not compatible with --tail
|
||||
snapshot, _, _ := chunkList.Snapshot(opts.Tail)
|
||||
|
||||
if opts.Bench > 0 {
|
||||
// Benchmark mode: repeat scan for the given duration
|
||||
totalItems := CountItems(snapshot)
|
||||
var matchCount int
|
||||
var times []time.Duration
|
||||
deadline := time.Now().Add(opts.Bench)
|
||||
for time.Now().Before(deadline) {
|
||||
cache.Clear()
|
||||
start := time.Now()
|
||||
result := matcher.scan(MatchRequest{
|
||||
chunks: snapshot,
|
||||
pattern: pattern})
|
||||
times = append(times, time.Since(start))
|
||||
matchCount = result.merger.Length()
|
||||
}
|
||||
// Print stats
|
||||
var total time.Duration
|
||||
minD, maxD := times[0], times[0]
|
||||
for _, d := range times {
|
||||
total += d
|
||||
if d < minD {
|
||||
minD = d
|
||||
}
|
||||
if d > maxD {
|
||||
maxD = d
|
||||
}
|
||||
}
|
||||
avg := total / time.Duration(len(times))
|
||||
selectivity := float64(matchCount) / float64(totalItems) * 100
|
||||
fmt.Printf(" %d iterations avg: %.2fms min: %.2fms max: %.2fms total: %.2fs items: %d matches: %d (%.2f%%) ingestion: %.2fms\n",
|
||||
len(times),
|
||||
float64(avg.Microseconds())/1000,
|
||||
float64(minD.Microseconds())/1000,
|
||||
float64(maxD.Microseconds())/1000,
|
||||
total.Seconds(),
|
||||
totalItems, matchCount, selectivity,
|
||||
float64(ingestionTime.Microseconds())/1000)
|
||||
return ExitOk, nil
|
||||
}
|
||||
|
||||
result := matcher.scan(MatchRequest{
|
||||
snapshot, _ := chunkList.Snapshot()
|
||||
merger, _ := matcher.scan(MatchRequest{
|
||||
chunks: snapshot,
|
||||
pattern: pattern})
|
||||
for i := 0; i < result.merger.Length(); i++ {
|
||||
opts.Printer(transformer(result.merger.Get(i).item))
|
||||
for i := 0; i < merger.Length(); i++ {
|
||||
opts.Printer(merger.Get(i).item.AsString(opts.Ansi))
|
||||
found = true
|
||||
}
|
||||
}
|
||||
if found {
|
||||
return ExitOk, nil
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
return ExitNoMatch, nil
|
||||
os.Exit(exitNoMatch)
|
||||
}
|
||||
|
||||
// Synchronous search
|
||||
@@ -359,71 +213,40 @@ func Run(opts *Options) (int, error) {
|
||||
|
||||
// Go interactive
|
||||
go matcher.Loop()
|
||||
defer matcher.Stop()
|
||||
|
||||
// Handling adaptive height
|
||||
maxFit := 0 // Maximum number of items that can fit on screen
|
||||
padHeight := 0
|
||||
heightUnknown := opts.Height.auto
|
||||
if heightUnknown {
|
||||
maxFit, padHeight = terminal.MaxFitAndPad()
|
||||
}
|
||||
deferred := opts.Select1 || opts.Exit0 || opts.Sync
|
||||
// Terminal I/O
|
||||
terminal := NewTerminal(opts, eventBox)
|
||||
deferred := opts.Select1 || opts.Exit0
|
||||
go terminal.Loop()
|
||||
if !deferred && !heightUnknown {
|
||||
// Start right away
|
||||
terminal.startChan <- fitpad{-1, -1}
|
||||
if !deferred {
|
||||
terminal.startChan <- true
|
||||
}
|
||||
|
||||
// Event coordination
|
||||
reading := true
|
||||
clearCache := util.Once(false)
|
||||
clearSelection := util.Once(false)
|
||||
ticks := 0
|
||||
startTick := 0
|
||||
var nextCommand *commandSpec
|
||||
var nextEnviron []string
|
||||
eventBox.Watch(EvtReadNew)
|
||||
total := 0
|
||||
query := []rune{}
|
||||
determine := func(final bool) {
|
||||
if heightUnknown {
|
||||
items := max(0, total-int(headerLines))
|
||||
if items >= maxFit || final {
|
||||
deferred = false
|
||||
heightUnknown = false
|
||||
terminal.startChan <- fitpad{min(items, maxFit), padHeight}
|
||||
}
|
||||
} else if deferred {
|
||||
deferred = false
|
||||
terminal.startChan <- fitpad{-1, -1}
|
||||
}
|
||||
}
|
||||
|
||||
useSnapshot := false
|
||||
var snapshot []*Chunk
|
||||
var count int
|
||||
restart := func(command commandSpec, environ []string) {
|
||||
if !useSnapshot {
|
||||
clearDenylist()
|
||||
}
|
||||
var nextCommand *string
|
||||
restart := func(command string) {
|
||||
reading = true
|
||||
headerUpdated = false
|
||||
startTick = ticks
|
||||
clearCache = util.Once(true)
|
||||
clearSelection = util.Once(true)
|
||||
chunkList.Clear()
|
||||
itemIndex = 0
|
||||
inputRevision.bumpMajor()
|
||||
readyChan := make(chan bool)
|
||||
go reader.restart(command, environ, readyChan)
|
||||
<-readyChan
|
||||
header = make([]string, 0, opts.HeaderLines)
|
||||
go reader.restart(command)
|
||||
}
|
||||
|
||||
exitCode := ExitOk
|
||||
stop := false
|
||||
eventBox.Watch(EvtReadNew)
|
||||
query := []rune{}
|
||||
for {
|
||||
delay := true
|
||||
ticks++
|
||||
input := func() []rune {
|
||||
input := func(reloaded bool) []rune {
|
||||
paused, input := terminal.Input()
|
||||
if !paused {
|
||||
if reloaded && paused {
|
||||
query = []rune{}
|
||||
} else if !paused {
|
||||
query = input
|
||||
}
|
||||
return query
|
||||
@@ -438,155 +261,43 @@ func Run(opts *Options) (int, error) {
|
||||
if reading {
|
||||
reader.terminate()
|
||||
}
|
||||
quitSignal := value.(quitSignal)
|
||||
exitCode = quitSignal.code
|
||||
err = quitSignal.err
|
||||
stop = true
|
||||
return
|
||||
os.Exit(value.(int))
|
||||
case EvtReadNew, EvtReadFin:
|
||||
if evt == EvtReadFin && nextCommand != nil {
|
||||
restart(*nextCommand, nextEnviron)
|
||||
restart(*nextCommand)
|
||||
nextCommand = nil
|
||||
nextEnviron = nil
|
||||
break
|
||||
} else {
|
||||
reading = reading && evt == EvtReadNew
|
||||
}
|
||||
if useSnapshot && evt == EvtReadFin { // reload-sync
|
||||
clearDenylist()
|
||||
useSnapshot = false
|
||||
}
|
||||
if !useSnapshot {
|
||||
if !snapshotRevision.compatible(inputRevision) {
|
||||
query = []rune{}
|
||||
}
|
||||
var changed bool
|
||||
snapshot, count, changed = chunkList.Snapshot(opts.Tail)
|
||||
if changed {
|
||||
inputRevision.bumpMinor()
|
||||
}
|
||||
snapshotRevision = inputRevision
|
||||
}
|
||||
total = count
|
||||
terminal.UpdateCount(max(0, total-int(headerLines)), !reading, value.(*string))
|
||||
if headerLines > 0 && !headerUpdated {
|
||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
||||
headerUpdated = total >= int(headerLines)
|
||||
}
|
||||
if heightUnknown && !deferred {
|
||||
determine(!reading)
|
||||
}
|
||||
if !useSnapshot || evt == EvtReadFin {
|
||||
matcher.Reset(snapshot, input(), false, !reading, sort, snapshotRevision)
|
||||
snapshot, count := chunkList.Snapshot()
|
||||
terminal.UpdateCount(count, !reading, value.(*string))
|
||||
if opts.Sync {
|
||||
opts.Sync = false
|
||||
terminal.UpdateList(PassMerger(&snapshot, opts.Tac), false)
|
||||
}
|
||||
reset := clearCache()
|
||||
matcher.Reset(snapshot, input(reset), false, !reading, sort, reset)
|
||||
|
||||
case EvtSearchNew:
|
||||
var command *commandSpec
|
||||
var environ []string
|
||||
var changed bool
|
||||
headerLinesChanged := false
|
||||
withNthChanged := false
|
||||
var command *string
|
||||
switch val := value.(type) {
|
||||
case searchRequest:
|
||||
sort = val.sort
|
||||
command = val.command
|
||||
environ = val.environ
|
||||
changed = val.changed
|
||||
bump := false
|
||||
if len(val.denylist) > 0 && val.revision.compatible(inputRevision) {
|
||||
denyMutex.Lock()
|
||||
for _, itemIndex := range val.denylist {
|
||||
denylist[itemIndex] = struct{}{}
|
||||
}
|
||||
denyMutex.Unlock()
|
||||
bump = true
|
||||
}
|
||||
if val.nth != nil {
|
||||
// Change nth and clear caches
|
||||
nth = *val.nth
|
||||
bump = true
|
||||
}
|
||||
if val.headerLines != nil {
|
||||
headerLines = int32(*val.headerLines)
|
||||
headerUpdated = false
|
||||
headerLinesChanged = true
|
||||
bump = true
|
||||
}
|
||||
if val.withNth != nil {
|
||||
newTransformer := val.withNth.fn
|
||||
// Cancel any in-flight scan and block the terminal from reading
|
||||
// items before mutating them in-place. Snapshot shares middle
|
||||
// chunk pointers, so the matcher and terminal can race with us.
|
||||
matcher.CancelScan()
|
||||
terminal.PauseRendering()
|
||||
// Reset cross-line ANSI state before re-processing all items
|
||||
lineAnsiState = nil
|
||||
prevLineAnsiState = nil
|
||||
chunkList.ForEachItem(func(item *Item) {
|
||||
origBytes := *item.origText
|
||||
savedIndex := item.Index()
|
||||
if newTransformer != nil {
|
||||
transformItem(item, origBytes, newTransformer, savedIndex)
|
||||
} else {
|
||||
item.text, item.colors = ansiProcessor(origBytes)
|
||||
}
|
||||
item.text.Index = savedIndex
|
||||
item.transformed = nil
|
||||
}, func() {
|
||||
nthTransformer = newTransformer
|
||||
})
|
||||
terminal.ResumeRendering()
|
||||
matcher.ResumeScan()
|
||||
withNthChanged = true
|
||||
bump = true
|
||||
}
|
||||
if bump {
|
||||
patternCache = make(map[string]*Pattern)
|
||||
cache.Clear()
|
||||
inputRevision.bumpMinor()
|
||||
}
|
||||
if command != nil {
|
||||
useSnapshot = val.sync
|
||||
}
|
||||
}
|
||||
if command != nil {
|
||||
if reading {
|
||||
reader.terminate()
|
||||
nextCommand = command
|
||||
nextEnviron = environ
|
||||
} else {
|
||||
restart(*command, environ)
|
||||
restart(*command)
|
||||
}
|
||||
}
|
||||
if !changed {
|
||||
break
|
||||
}
|
||||
if !useSnapshot {
|
||||
newSnapshot, newCount, changed := chunkList.Snapshot(opts.Tail)
|
||||
if changed {
|
||||
inputRevision.bumpMinor()
|
||||
}
|
||||
// We want to avoid showing empty list when reload is triggered
|
||||
// and the query string is changed at the same time i.e. command != nil && changed
|
||||
if command == nil || newCount > 0 {
|
||||
if snapshotRevision != inputRevision {
|
||||
query = []rune{}
|
||||
}
|
||||
snapshot = newSnapshot
|
||||
snapshotRevision = inputRevision
|
||||
}
|
||||
}
|
||||
if headerLinesChanged {
|
||||
terminal.UpdateCount(max(0, total-int(headerLines)), !reading, nil)
|
||||
if headerLines > 0 {
|
||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
||||
} else {
|
||||
terminal.UpdateHeader(nil)
|
||||
}
|
||||
} else if withNthChanged && headerLines > 0 {
|
||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
||||
}
|
||||
matcher.Reset(snapshot, input(), true, !reading, sort, snapshotRevision)
|
||||
snapshot, _ := chunkList.Snapshot()
|
||||
reset := clearCache()
|
||||
matcher.Reset(snapshot, input(reset), true, !reading, sort, reset)
|
||||
delay = false
|
||||
|
||||
case EvtSearchProgress:
|
||||
@@ -595,15 +306,20 @@ func Run(opts *Options) (int, error) {
|
||||
terminal.UpdateProgress(val)
|
||||
}
|
||||
|
||||
case EvtHeader:
|
||||
headerPadded := make([]string, opts.HeaderLines)
|
||||
copy(headerPadded, value.([]string))
|
||||
terminal.UpdateHeader(headerPadded)
|
||||
|
||||
case EvtSearchFin:
|
||||
switch val := value.(type) {
|
||||
case MatchResult:
|
||||
merger := val.merger
|
||||
case *Merger:
|
||||
if deferred {
|
||||
count := merger.Length()
|
||||
count := val.Length()
|
||||
if opts.Select1 && count > 1 || opts.Exit0 && !opts.Select1 && count > 0 {
|
||||
determine(merger.final)
|
||||
} else if merger.final {
|
||||
deferred = false
|
||||
terminal.startChan <- true
|
||||
} else if val.final {
|
||||
if opts.Exit0 && count == 0 || opts.Select1 && count == 1 {
|
||||
if opts.PrintQuery {
|
||||
opts.Printer(opts.Query)
|
||||
@@ -611,34 +327,29 @@ func Run(opts *Options) (int, error) {
|
||||
if len(opts.Expect) > 0 {
|
||||
opts.Printer("")
|
||||
}
|
||||
transformer := buildItemTransformer(opts)
|
||||
for i := range count {
|
||||
opts.Printer(transformer(merger.Get(i).item))
|
||||
for i := 0; i < count; i++ {
|
||||
opts.Printer(val.Get(i).item.AsString(opts.Ansi))
|
||||
}
|
||||
if count == 0 {
|
||||
exitCode = ExitNoMatch
|
||||
if count > 0 {
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
stop = true
|
||||
return
|
||||
os.Exit(exitNoMatch)
|
||||
}
|
||||
determine(merger.final)
|
||||
deferred = false
|
||||
terminal.startChan <- true
|
||||
}
|
||||
}
|
||||
terminal.UpdateList(val)
|
||||
terminal.UpdateList(val, clearSelection())
|
||||
}
|
||||
}
|
||||
}
|
||||
events.Clear()
|
||||
})
|
||||
if stop {
|
||||
break
|
||||
}
|
||||
if delay && reading {
|
||||
dur := util.Constrain(
|
||||
time.Duration(ticks-startTick)*coordinatorDelayStep,
|
||||
dur := util.DurWithin(
|
||||
time.Duration(ticks)*coordinatorDelayStep,
|
||||
0, coordinatorDelayMax)
|
||||
time.Sleep(dur)
|
||||
}
|
||||
}
|
||||
return exitCode, err
|
||||
}
|
||||
|
||||
@@ -1,35 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"os"
|
||||
"strings"
|
||||
"unsafe"
|
||||
)
|
||||
|
||||
func WriteTemporaryFile(data []string, printSep string) string {
|
||||
f, err := os.CreateTemp("", "fzf-temp-*")
|
||||
if err != nil {
|
||||
// Unable to create temporary file
|
||||
// FIXME: Should we terminate the program?
|
||||
return ""
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
f.WriteString(strings.Join(data, printSep))
|
||||
f.WriteString(printSep)
|
||||
return f.Name()
|
||||
}
|
||||
|
||||
func removeFiles(files []string) {
|
||||
for _, filename := range files {
|
||||
os.Remove(filename)
|
||||
}
|
||||
}
|
||||
|
||||
func stringBytes(data string) []byte {
|
||||
return unsafe.Slice(unsafe.StringData(data), len(data))
|
||||
}
|
||||
|
||||
func byteString(data []byte) string {
|
||||
return unsafe.String(unsafe.SliceData(data), len(data))
|
||||
}
|
||||
+5
-4
@@ -2,6 +2,7 @@ package fzf
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"strings"
|
||||
)
|
||||
@@ -25,12 +26,12 @@ func NewHistory(path string, maxSize int) (*History, error) {
|
||||
}
|
||||
|
||||
// Read history file
|
||||
data, err := os.ReadFile(path)
|
||||
data, err := ioutil.ReadFile(path)
|
||||
if err != nil {
|
||||
// If it doesn't exist, check if we can create a file with the name
|
||||
if os.IsNotExist(err) {
|
||||
data = []byte{}
|
||||
if err := os.WriteFile(path, data, 0600); err != nil {
|
||||
if err := ioutil.WriteFile(path, data, 0600); err != nil {
|
||||
return nil, fmtError(err)
|
||||
}
|
||||
} else {
|
||||
@@ -61,11 +62,11 @@ func (h *History) append(line string) error {
|
||||
lines = lines[len(lines)-h.maxSize:]
|
||||
}
|
||||
h.lines = append(lines, "")
|
||||
return os.WriteFile(h.path, []byte(strings.Join(h.lines, "\n")), 0600)
|
||||
return ioutil.WriteFile(h.path, []byte(strings.Join(h.lines, "\n")), 0600)
|
||||
}
|
||||
|
||||
func (h *History) override(str string) {
|
||||
// You can update the history, but they're not written to the file
|
||||
// You can update the history but they're not written to the file
|
||||
if h.cursor == len(h.lines)-1 {
|
||||
h.lines[h.cursor] = str
|
||||
} else if h.cursor < len(h.lines)-1 {
|
||||
|
||||
+3
-2
@@ -1,6 +1,7 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"runtime"
|
||||
"testing"
|
||||
@@ -24,7 +25,7 @@ func TestHistory(t *testing.T) {
|
||||
}
|
||||
}
|
||||
|
||||
f, _ := os.CreateTemp("", "fzf-history")
|
||||
f, _ := ioutil.TempFile("", "fzf-history")
|
||||
f.Close()
|
||||
|
||||
{ // Append lines
|
||||
@@ -38,7 +39,7 @@ func TestHistory(t *testing.T) {
|
||||
if len(h.lines) != maxHistory+1 {
|
||||
t.Errorf("Expected: %d, actual: %d\n", maxHistory+1, len(h.lines))
|
||||
}
|
||||
for i := range maxHistory {
|
||||
for i := 0; i < maxHistory; i++ {
|
||||
if h.lines[i] != "foobar" {
|
||||
t.Error("Expected: foobar, actual: " + h.lines[i])
|
||||
}
|
||||
|
||||
+2
-17
@@ -1,22 +1,13 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
type transformed struct {
|
||||
// Because nth can be changed dynamically by change-nth action, we need to
|
||||
// keep the revision number at the time of transformation.
|
||||
revision revision
|
||||
tokens []Token
|
||||
}
|
||||
|
||||
// Item represents each input line. 56 bytes.
|
||||
type Item struct {
|
||||
text util.Chars // 32 = 24 + 1 + 1 + 2 + 4
|
||||
transformed *transformed // 8
|
||||
transformed *[]Token // 8
|
||||
origText *[]byte // 8
|
||||
colors *[]ansiOffset // 8
|
||||
}
|
||||
@@ -26,7 +17,7 @@ func (item *Item) Index() int32 {
|
||||
return item.text.Index
|
||||
}
|
||||
|
||||
var minItem = Item{text: util.Chars{Index: math.MinInt32}}
|
||||
var minItem = Item{text: util.Chars{Index: -1}}
|
||||
|
||||
func (item *Item) TrimLength() uint16 {
|
||||
return item.text.TrimLength()
|
||||
@@ -51,9 +42,3 @@ func (item *Item) AsString(stripAnsi bool) string {
|
||||
}
|
||||
return item.text.ToString()
|
||||
}
|
||||
|
||||
func (item *Item) acceptNth(stripAnsi bool, delimiter Delimiter, transformer func([]Token, int32) string) string {
|
||||
tokens := Tokenize(item.AsString(stripAnsi), delimiter)
|
||||
transformed := transformer(tokens, item.Index())
|
||||
return StripLastDelimiter(transformed, delimiter)
|
||||
}
|
||||
|
||||
+90
-126
@@ -3,8 +3,8 @@ package fzf
|
||||
import (
|
||||
"fmt"
|
||||
"runtime"
|
||||
"sort"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
@@ -12,30 +12,15 @@ import (
|
||||
|
||||
// MatchRequest represents a search request
|
||||
type MatchRequest struct {
|
||||
chunks []*Chunk
|
||||
pattern *Pattern
|
||||
final bool
|
||||
sort bool
|
||||
revision revision
|
||||
}
|
||||
|
||||
type MatchResult struct {
|
||||
merger *Merger
|
||||
passMerger *Merger
|
||||
cancelled bool
|
||||
}
|
||||
|
||||
func (mr MatchResult) cacheable() bool {
|
||||
return mr.merger != nil && mr.merger.cacheable()
|
||||
}
|
||||
|
||||
func (mr MatchResult) final() bool {
|
||||
return mr.merger != nil && mr.merger.final
|
||||
chunks []*Chunk
|
||||
pattern *Pattern
|
||||
final bool
|
||||
sort bool
|
||||
clearCache bool
|
||||
}
|
||||
|
||||
// Matcher is responsible for performing search
|
||||
type Matcher struct {
|
||||
cache *ChunkCache
|
||||
patternBuilder func([]rune) *Pattern
|
||||
sort bool
|
||||
tac bool
|
||||
@@ -43,11 +28,7 @@ type Matcher struct {
|
||||
reqBox *util.EventBox
|
||||
partitions int
|
||||
slab []*util.Slab
|
||||
sortBuf [][]Result
|
||||
mergerCache map[string]MatchResult
|
||||
revision revision
|
||||
scanMutex sync.Mutex
|
||||
cancelScan *util.AtomicBool
|
||||
mergerCache map[string]*Merger
|
||||
}
|
||||
|
||||
const (
|
||||
@@ -56,14 +37,10 @@ const (
|
||||
)
|
||||
|
||||
// NewMatcher returns a new Matcher
|
||||
func NewMatcher(cache *ChunkCache, patternBuilder func([]rune) *Pattern,
|
||||
sort bool, tac bool, eventBox *util.EventBox, revision revision, threads int) *Matcher {
|
||||
partitions := runtime.NumCPU()
|
||||
if threads > 0 {
|
||||
partitions = threads
|
||||
}
|
||||
func NewMatcher(patternBuilder func([]rune) *Pattern,
|
||||
sort bool, tac bool, eventBox *util.EventBox) *Matcher {
|
||||
partitions := util.Min(numPartitionsMultiplier*runtime.NumCPU(), maxPartitions)
|
||||
return &Matcher{
|
||||
cache: cache,
|
||||
patternBuilder: patternBuilder,
|
||||
sort: sort,
|
||||
tac: tac,
|
||||
@@ -71,10 +48,7 @@ func NewMatcher(cache *ChunkCache, patternBuilder func([]rune) *Pattern,
|
||||
reqBox: util.NewEventBox(),
|
||||
partitions: partitions,
|
||||
slab: make([]*util.Slab, partitions),
|
||||
sortBuf: make([][]Result, partitions),
|
||||
mergerCache: make(map[string]MatchResult),
|
||||
revision: revision,
|
||||
cancelScan: util.NewAtomicBool(false)}
|
||||
mergerCache: make(map[string]*Merger)}
|
||||
}
|
||||
|
||||
// Loop puts Matcher in action
|
||||
@@ -84,13 +58,8 @@ func (m *Matcher) Loop() {
|
||||
for {
|
||||
var request MatchRequest
|
||||
|
||||
stop := false
|
||||
m.reqBox.Wait(func(events *util.Events) {
|
||||
for t, val := range *events {
|
||||
if t == reqQuit {
|
||||
stop = true
|
||||
return
|
||||
}
|
||||
for _, val := range *events {
|
||||
switch val := val.(type) {
|
||||
case MatchRequest:
|
||||
request = val
|
||||
@@ -100,109 +69,123 @@ func (m *Matcher) Loop() {
|
||||
}
|
||||
events.Clear()
|
||||
})
|
||||
if stop {
|
||||
break
|
||||
}
|
||||
|
||||
cacheCleared := false
|
||||
if request.sort != m.sort || request.revision != m.revision {
|
||||
if request.sort != m.sort || request.clearCache {
|
||||
m.sort = request.sort
|
||||
m.mergerCache = make(map[string]MatchResult)
|
||||
if !request.revision.compatible(m.revision) {
|
||||
m.cache.Clear()
|
||||
}
|
||||
m.revision = request.revision
|
||||
cacheCleared = true
|
||||
m.mergerCache = make(map[string]*Merger)
|
||||
clearChunkCache()
|
||||
}
|
||||
|
||||
// Restart search
|
||||
patternString := request.pattern.AsString()
|
||||
var result MatchResult
|
||||
var merger *Merger
|
||||
cancelled := false
|
||||
count := CountItems(request.chunks)
|
||||
|
||||
if !cacheCleared {
|
||||
if count == prevCount {
|
||||
// Look up mergerCache
|
||||
if cached, found := m.mergerCache[patternString]; found && cached.final() == request.final {
|
||||
result = cached
|
||||
}
|
||||
} else {
|
||||
// Invalidate mergerCache
|
||||
prevCount = count
|
||||
m.mergerCache = make(map[string]MatchResult)
|
||||
foundCache := false
|
||||
if count == prevCount {
|
||||
// Look up mergerCache
|
||||
if cached, found := m.mergerCache[patternString]; found {
|
||||
foundCache = true
|
||||
merger = cached
|
||||
}
|
||||
} else {
|
||||
// Invalidate mergerCache
|
||||
prevCount = count
|
||||
m.mergerCache = make(map[string]*Merger)
|
||||
}
|
||||
|
||||
if result.merger == nil {
|
||||
m.scanMutex.Lock()
|
||||
result = m.scan(request)
|
||||
m.scanMutex.Unlock()
|
||||
if !foundCache {
|
||||
merger, cancelled = m.scan(request)
|
||||
}
|
||||
|
||||
if !result.cancelled {
|
||||
if result.cacheable() {
|
||||
m.mergerCache[patternString] = result
|
||||
if !cancelled {
|
||||
if merger.cacheable() {
|
||||
m.mergerCache[patternString] = merger
|
||||
}
|
||||
result.merger.final = request.final
|
||||
m.eventBox.Set(EvtSearchFin, result)
|
||||
merger.final = request.final
|
||||
m.eventBox.Set(EvtSearchFin, merger)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (m *Matcher) sliceChunks(chunks []*Chunk) [][]*Chunk {
|
||||
partitions := m.partitions
|
||||
perSlice := len(chunks) / partitions
|
||||
|
||||
if perSlice == 0 {
|
||||
partitions = len(chunks)
|
||||
perSlice = 1
|
||||
}
|
||||
|
||||
slices := make([][]*Chunk, partitions)
|
||||
for i := 0; i < partitions; i++ {
|
||||
start := i * perSlice
|
||||
end := start + perSlice
|
||||
if i == partitions-1 {
|
||||
end = len(chunks)
|
||||
}
|
||||
slices[i] = chunks[start:end]
|
||||
}
|
||||
return slices
|
||||
}
|
||||
|
||||
type partialResult struct {
|
||||
index int
|
||||
matches []Result
|
||||
}
|
||||
|
||||
func (m *Matcher) scan(request MatchRequest) MatchResult {
|
||||
func (m *Matcher) scan(request MatchRequest) (*Merger, bool) {
|
||||
startedAt := time.Now()
|
||||
|
||||
numChunks := len(request.chunks)
|
||||
if numChunks == 0 {
|
||||
m := EmptyMerger(request.revision)
|
||||
return MatchResult{m, m, false}
|
||||
return EmptyMerger, false
|
||||
}
|
||||
pattern := request.pattern
|
||||
passMerger := PassMerger(&request.chunks, m.tac, request.revision, pattern.startIndex)
|
||||
if pattern.IsEmpty() {
|
||||
return MatchResult{passMerger, passMerger, false}
|
||||
return PassMerger(&request.chunks, m.tac), false
|
||||
}
|
||||
|
||||
minIndex := request.chunks[0].items[0].Index()
|
||||
maxIndex := request.chunks[numChunks-1].lastIndex(minIndex)
|
||||
cancelled := util.NewAtomicBool(false)
|
||||
|
||||
numWorkers := min(m.partitions, numChunks)
|
||||
var nextChunk atomic.Int32
|
||||
resultChan := make(chan partialResult, numWorkers)
|
||||
slices := m.sliceChunks(request.chunks)
|
||||
numSlices := len(slices)
|
||||
resultChan := make(chan partialResult, numSlices)
|
||||
countChan := make(chan int, numChunks)
|
||||
waitGroup := sync.WaitGroup{}
|
||||
|
||||
for idx := range numWorkers {
|
||||
for idx, chunks := range slices {
|
||||
waitGroup.Add(1)
|
||||
if m.slab[idx] == nil {
|
||||
m.slab[idx] = util.MakeSlab(slab16Size, slab32Size)
|
||||
}
|
||||
go func(idx int, slab *util.Slab) {
|
||||
defer waitGroup.Done()
|
||||
var matches []Result
|
||||
for {
|
||||
ci := int(nextChunk.Add(1)) - 1
|
||||
if ci >= numChunks {
|
||||
break
|
||||
}
|
||||
chunkMatches := request.pattern.Match(request.chunks[ci], slab)
|
||||
matches = append(matches, chunkMatches...)
|
||||
go func(idx int, slab *util.Slab, chunks []*Chunk) {
|
||||
defer func() { waitGroup.Done() }()
|
||||
count := 0
|
||||
allMatches := make([][]Result, len(chunks))
|
||||
for idx, chunk := range chunks {
|
||||
matches := request.pattern.Match(chunk, slab)
|
||||
allMatches[idx] = matches
|
||||
count += len(matches)
|
||||
if cancelled.Get() {
|
||||
return
|
||||
}
|
||||
countChan <- len(chunkMatches)
|
||||
countChan <- len(matches)
|
||||
}
|
||||
if m.sort && request.pattern.sortable {
|
||||
m.sortBuf[idx] = radixSortResults(matches, m.tac, m.sortBuf[idx])
|
||||
sliceMatches := make([]Result, 0, count)
|
||||
for _, matches := range allMatches {
|
||||
sliceMatches = append(sliceMatches, matches...)
|
||||
}
|
||||
resultChan <- partialResult{idx, matches}
|
||||
}(idx, m.slab[idx])
|
||||
if m.sort {
|
||||
if m.tac {
|
||||
sort.Sort(ByRelevanceTac(sliceMatches))
|
||||
} else {
|
||||
sort.Sort(ByRelevance(sliceMatches))
|
||||
}
|
||||
}
|
||||
resultChan <- partialResult{idx, sliceMatches}
|
||||
}(idx, m.slab[idx], chunks)
|
||||
}
|
||||
|
||||
wait := func() bool {
|
||||
@@ -221,8 +204,8 @@ func (m *Matcher) scan(request MatchRequest) MatchResult {
|
||||
break
|
||||
}
|
||||
|
||||
if m.cancelScan.Get() || m.reqBox.Peek(reqReset) {
|
||||
return MatchResult{nil, nil, wait()}
|
||||
if m.reqBox.Peek(reqReset) {
|
||||
return nil, wait()
|
||||
}
|
||||
|
||||
if time.Since(startedAt) > progressMinDuration {
|
||||
@@ -230,17 +213,16 @@ func (m *Matcher) scan(request MatchRequest) MatchResult {
|
||||
}
|
||||
}
|
||||
|
||||
partialResults := make([][]Result, numWorkers)
|
||||
for range numWorkers {
|
||||
partialResults := make([][]Result, numSlices)
|
||||
for range slices {
|
||||
partialResult := <-resultChan
|
||||
partialResults[partialResult.index] = partialResult.matches
|
||||
}
|
||||
merger := NewMerger(pattern, partialResults, m.sort && request.pattern.sortable, m.tac, request.revision, minIndex, maxIndex)
|
||||
return MatchResult{merger, passMerger, false}
|
||||
return NewMerger(pattern, partialResults, m.sort, m.tac), false
|
||||
}
|
||||
|
||||
// Reset is called to interrupt/signal the ongoing search
|
||||
func (m *Matcher) Reset(chunks []*Chunk, patternRunes []rune, cancel bool, final bool, sort bool, revision revision) {
|
||||
func (m *Matcher) Reset(chunks []*Chunk, patternRunes []rune, cancel bool, final bool, sort bool, clearCache bool) {
|
||||
pattern := m.patternBuilder(patternRunes)
|
||||
|
||||
var event util.EventType
|
||||
@@ -249,23 +231,5 @@ func (m *Matcher) Reset(chunks []*Chunk, patternRunes []rune, cancel bool, final
|
||||
} else {
|
||||
event = reqRetry
|
||||
}
|
||||
m.reqBox.Set(event, MatchRequest{chunks, pattern, final, sort, revision})
|
||||
}
|
||||
|
||||
// CancelScan cancels any in-flight scan, waits for it to finish,
|
||||
// and prevents new scans from starting until ResumeScan is called.
|
||||
// This is used to safely mutate shared items (e.g., during with-nth changes).
|
||||
func (m *Matcher) CancelScan() {
|
||||
m.cancelScan.Set(true)
|
||||
m.scanMutex.Lock()
|
||||
m.cancelScan.Set(false)
|
||||
}
|
||||
|
||||
// ResumeScan allows scans to proceed again after CancelScan.
|
||||
func (m *Matcher) ResumeScan() {
|
||||
m.scanMutex.Unlock()
|
||||
}
|
||||
|
||||
func (m *Matcher) Stop() {
|
||||
m.reqBox.Set(reqQuit, nil)
|
||||
m.reqBox.Set(event, MatchRequest{chunks, pattern, final, sort && pattern.sortable, clearCache})
|
||||
}
|
||||
|
||||
+34
-97
@@ -3,71 +3,49 @@ package fzf
|
||||
import "fmt"
|
||||
|
||||
// EmptyMerger is a Merger with no data
|
||||
func EmptyMerger(revision revision) *Merger {
|
||||
return NewMerger(nil, [][]Result{}, false, false, revision, 0, 0)
|
||||
}
|
||||
var EmptyMerger = NewMerger(nil, [][]Result{}, false, false)
|
||||
|
||||
// Merger holds a set of locally sorted lists of items and provides the view of
|
||||
// a single, globally-sorted list
|
||||
type Merger struct {
|
||||
pattern *Pattern
|
||||
lists [][]Result
|
||||
merged []Result
|
||||
chunks *[]*Chunk
|
||||
cursors []int
|
||||
sorted bool
|
||||
tac bool
|
||||
final bool
|
||||
count int
|
||||
pass bool
|
||||
startIndex int
|
||||
revision revision
|
||||
minIndex int32
|
||||
maxIndex int32
|
||||
pattern *Pattern
|
||||
lists [][]Result
|
||||
merged []Result
|
||||
chunks *[]*Chunk
|
||||
cursors []int
|
||||
sorted bool
|
||||
tac bool
|
||||
final bool
|
||||
count int
|
||||
}
|
||||
|
||||
// PassMerger returns a new Merger that simply returns the items in the
|
||||
// original order. startIndex items are skipped from the beginning.
|
||||
func PassMerger(chunks *[]*Chunk, tac bool, revision revision, startIndex int32) *Merger {
|
||||
var minIndex, maxIndex int32
|
||||
if len(*chunks) > 0 {
|
||||
minIndex = (*chunks)[0].items[0].Index()
|
||||
maxIndex = (*chunks)[len(*chunks)-1].lastIndex(minIndex)
|
||||
}
|
||||
si := int(startIndex)
|
||||
// original order
|
||||
func PassMerger(chunks *[]*Chunk, tac bool) *Merger {
|
||||
mg := Merger{
|
||||
pattern: nil,
|
||||
chunks: chunks,
|
||||
tac: tac,
|
||||
count: 0,
|
||||
pass: true,
|
||||
startIndex: si,
|
||||
revision: revision,
|
||||
minIndex: minIndex + startIndex,
|
||||
maxIndex: maxIndex}
|
||||
pattern: nil,
|
||||
chunks: chunks,
|
||||
tac: tac,
|
||||
count: 0}
|
||||
|
||||
for _, chunk := range *mg.chunks {
|
||||
mg.count += chunk.count
|
||||
}
|
||||
mg.count = max(0, mg.count-si)
|
||||
return &mg
|
||||
}
|
||||
|
||||
// NewMerger returns a new Merger
|
||||
func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool, revision revision, minIndex int32, maxIndex int32) *Merger {
|
||||
func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool) *Merger {
|
||||
mg := Merger{
|
||||
pattern: pattern,
|
||||
lists: lists,
|
||||
merged: []Result{},
|
||||
chunks: nil,
|
||||
cursors: make([]int, len(lists)),
|
||||
sorted: sorted,
|
||||
tac: tac,
|
||||
final: false,
|
||||
count: 0,
|
||||
revision: revision,
|
||||
minIndex: minIndex,
|
||||
maxIndex: maxIndex}
|
||||
pattern: pattern,
|
||||
lists: lists,
|
||||
merged: []Result{},
|
||||
chunks: nil,
|
||||
cursors: make([]int, len(lists)),
|
||||
sorted: sorted,
|
||||
tac: tac,
|
||||
final: false,
|
||||
count: 0}
|
||||
|
||||
for _, list := range mg.lists {
|
||||
mg.count += len(list)
|
||||
@@ -75,56 +53,17 @@ func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool, revisi
|
||||
return &mg
|
||||
}
|
||||
|
||||
// Revision returns revision number
|
||||
func (mg *Merger) Revision() revision {
|
||||
return mg.revision
|
||||
}
|
||||
|
||||
// Length returns the number of items
|
||||
func (mg *Merger) Length() int {
|
||||
return mg.count
|
||||
}
|
||||
|
||||
func (mg *Merger) First() Result {
|
||||
if mg.tac && !mg.sorted {
|
||||
return mg.Get(mg.count - 1)
|
||||
}
|
||||
return mg.Get(0)
|
||||
}
|
||||
|
||||
// FindIndex returns the index of the item with the given item index
|
||||
func (mg *Merger) FindIndex(itemIndex int32) int {
|
||||
index := -1
|
||||
if mg.pass {
|
||||
index = int(itemIndex - mg.minIndex)
|
||||
if mg.tac {
|
||||
index = mg.count - index - 1
|
||||
}
|
||||
} else {
|
||||
for i := 0; i < mg.count; i++ {
|
||||
if mg.Get(i).item.Index() == itemIndex {
|
||||
index = i
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
return index
|
||||
}
|
||||
|
||||
// Get returns the pointer to the Result object indexed by the given integer
|
||||
func (mg *Merger) Get(idx int) Result {
|
||||
if mg.chunks != nil {
|
||||
if mg.tac {
|
||||
idx = mg.count - idx - 1
|
||||
}
|
||||
idx += mg.startIndex
|
||||
firstChunk := (*mg.chunks)[0]
|
||||
if firstChunk.count < chunkSize && idx >= firstChunk.count {
|
||||
idx -= firstChunk.count
|
||||
|
||||
chunk := (*mg.chunks)[idx/chunkSize+1]
|
||||
return Result{item: &chunk.items[idx%chunkSize]}
|
||||
}
|
||||
chunk := (*mg.chunks)[idx/chunkSize]
|
||||
return Result{item: &chunk.items[idx%chunkSize]}
|
||||
}
|
||||
@@ -136,16 +75,14 @@ func (mg *Merger) Get(idx int) Result {
|
||||
if mg.tac {
|
||||
idx = mg.count - idx - 1
|
||||
}
|
||||
return mg.mergedGet(idx)
|
||||
}
|
||||
|
||||
func (mg *Merger) ToMap() map[int32]Result {
|
||||
ret := make(map[int32]Result, mg.count)
|
||||
for i := 0; i < mg.count; i++ {
|
||||
result := mg.Get(i)
|
||||
ret[result.Index()] = result
|
||||
for _, list := range mg.lists {
|
||||
numItems := len(list)
|
||||
if idx < numItems {
|
||||
return list[idx]
|
||||
}
|
||||
idx -= numItems
|
||||
}
|
||||
return ret
|
||||
panic(fmt.Sprintf("Index out of bounds (unsorted, %d/%d)", idx, mg.count))
|
||||
}
|
||||
|
||||
func (mg *Merger) cacheable() bool {
|
||||
@@ -164,7 +101,7 @@ func (mg *Merger) mergedGet(idx int) Result {
|
||||
}
|
||||
if cursor >= 0 {
|
||||
rank := list[cursor]
|
||||
if minIdx < 0 || mg.sorted && compareRanks(rank, minRank, mg.tac) || !mg.sorted && rank.item.Index() < minRank.item.Index() {
|
||||
if minIdx < 0 || compareRanks(rank, minRank, mg.tac) {
|
||||
minRank = rank
|
||||
minIdx = listIdx
|
||||
}
|
||||
|
||||
+13
-29
@@ -23,22 +23,21 @@ func randResult() Result {
|
||||
}
|
||||
|
||||
func TestEmptyMerger(t *testing.T) {
|
||||
r := revision{}
|
||||
assert(t, EmptyMerger(r).Length() == 0, "Not empty")
|
||||
assert(t, EmptyMerger(r).count == 0, "Invalid count")
|
||||
assert(t, len(EmptyMerger(r).lists) == 0, "Invalid lists")
|
||||
assert(t, len(EmptyMerger(r).merged) == 0, "Invalid merged list")
|
||||
assert(t, EmptyMerger.Length() == 0, "Not empty")
|
||||
assert(t, EmptyMerger.count == 0, "Invalid count")
|
||||
assert(t, len(EmptyMerger.lists) == 0, "Invalid lists")
|
||||
assert(t, len(EmptyMerger.merged) == 0, "Invalid merged list")
|
||||
}
|
||||
|
||||
func buildLists(partiallySorted bool) ([][]Result, []Result) {
|
||||
numLists := 4
|
||||
lists := make([][]Result, numLists)
|
||||
cnt := 0
|
||||
for i := range numLists {
|
||||
for i := 0; i < numLists; i++ {
|
||||
numResults := rand.Int() % 20
|
||||
cnt += numResults
|
||||
lists[i] = make([]Result, numResults)
|
||||
for j := range numResults {
|
||||
for j := 0; j < numResults; j++ {
|
||||
item := randResult()
|
||||
lists[i][j] = item
|
||||
}
|
||||
@@ -54,28 +53,13 @@ func buildLists(partiallySorted bool) ([][]Result, []Result) {
|
||||
}
|
||||
|
||||
func TestMergerUnsorted(t *testing.T) {
|
||||
lists, _ := buildLists(false)
|
||||
|
||||
// Sort each list by index to simulate real worker behavior
|
||||
// (workers process chunks in ascending order via nextChunk.Add(1))
|
||||
for _, list := range lists {
|
||||
sort.Slice(list, func(i, j int) bool {
|
||||
return list[i].item.Index() < list[j].item.Index()
|
||||
})
|
||||
}
|
||||
items := []Result{}
|
||||
for _, list := range lists {
|
||||
items = append(items, list...)
|
||||
}
|
||||
sort.Slice(items, func(i, j int) bool {
|
||||
return items[i].item.Index() < items[j].item.Index()
|
||||
})
|
||||
lists, items := buildLists(false)
|
||||
cnt := len(items)
|
||||
|
||||
// Not sorted: items in ascending index order
|
||||
mg := NewMerger(nil, lists, false, false, revision{}, 0, 0)
|
||||
// Not sorted: same order
|
||||
mg := NewMerger(nil, lists, false, false)
|
||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||
for i := range cnt {
|
||||
for i := 0; i < cnt; i++ {
|
||||
assert(t, items[i] == mg.Get(i), "Invalid Get")
|
||||
}
|
||||
}
|
||||
@@ -85,17 +69,17 @@ func TestMergerSorted(t *testing.T) {
|
||||
cnt := len(items)
|
||||
|
||||
// Sorted sorted order
|
||||
mg := NewMerger(nil, lists, true, false, revision{}, 0, 0)
|
||||
mg := NewMerger(nil, lists, true, false)
|
||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||
sort.Sort(ByRelevance(items))
|
||||
for i := range cnt {
|
||||
for i := 0; i < cnt; i++ {
|
||||
if items[i] != mg.Get(i) {
|
||||
t.Error("Not sorted", items[i], mg.Get(i))
|
||||
}
|
||||
}
|
||||
|
||||
// Inverse order
|
||||
mg2 := NewMerger(nil, lists, true, false, revision{}, 0, 0)
|
||||
mg2 := NewMerger(nil, lists, true, false)
|
||||
for i := cnt - 1; i >= 0; i-- {
|
||||
if items[i] != mg2.Get(i) {
|
||||
t.Error("Not sorted", items[i], mg2.Get(i))
|
||||
|
||||
+861
-3086
File diff suppressed because it is too large
Load Diff
@@ -1,13 +0,0 @@
|
||||
//go:build !pprof
|
||||
// +build !pprof
|
||||
|
||||
package fzf
|
||||
|
||||
import "errors"
|
||||
|
||||
func (o *Options) initProfiling() error {
|
||||
if o.CPUProfile != "" || o.MEMProfile != "" || o.BlockProfile != "" || o.MutexProfile != "" {
|
||||
return errors.New("error: profiling not supported: FZF must be built with '-tags=pprof' to enable profiling")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
@@ -1,73 +0,0 @@
|
||||
//go:build pprof
|
||||
// +build pprof
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"runtime"
|
||||
"runtime/pprof"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func (o *Options) initProfiling() error {
|
||||
if o.CPUProfile != "" {
|
||||
f, err := os.Create(o.CPUProfile)
|
||||
if err != nil {
|
||||
return fmt.Errorf("could not create CPU profile: %w", err)
|
||||
}
|
||||
|
||||
if err := pprof.StartCPUProfile(f); err != nil {
|
||||
return fmt.Errorf("could not start CPU profile: %w", err)
|
||||
}
|
||||
|
||||
util.AtExit(func() {
|
||||
pprof.StopCPUProfile()
|
||||
if err := f.Close(); err != nil {
|
||||
fmt.Fprintln(os.Stderr, "Error: closing cpu profile:", err)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
stopProfile := func(name string, f *os.File) {
|
||||
if err := pprof.Lookup(name).WriteTo(f, 0); err != nil {
|
||||
fmt.Fprintf(os.Stderr, "Error: could not write %s profile: %v\n", name, err)
|
||||
}
|
||||
if err := f.Close(); err != nil {
|
||||
fmt.Fprintf(os.Stderr, "Error: closing %s profile: %v\n", name, err)
|
||||
}
|
||||
}
|
||||
|
||||
if o.MEMProfile != "" {
|
||||
f, err := os.Create(o.MEMProfile)
|
||||
if err != nil {
|
||||
return fmt.Errorf("could not create MEM profile: %w", err)
|
||||
}
|
||||
util.AtExit(func() {
|
||||
runtime.GC()
|
||||
stopProfile("allocs", f)
|
||||
})
|
||||
}
|
||||
|
||||
if o.BlockProfile != "" {
|
||||
runtime.SetBlockProfileRate(1)
|
||||
f, err := os.Create(o.BlockProfile)
|
||||
if err != nil {
|
||||
return fmt.Errorf("could not create BLOCK profile: %w", err)
|
||||
}
|
||||
util.AtExit(func() { stopProfile("block", f) })
|
||||
}
|
||||
|
||||
if o.MutexProfile != "" {
|
||||
runtime.SetMutexProfileFraction(1)
|
||||
f, err := os.Create(o.MutexProfile)
|
||||
if err != nil {
|
||||
return fmt.Errorf("could not create MUTEX profile: %w", err)
|
||||
}
|
||||
util.AtExit(func() { stopProfile("mutex", f) })
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -1,89 +0,0 @@
|
||||
//go:build pprof
|
||||
// +build pprof
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"flag"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
// runInitProfileTests is an internal flag used TestInitProfiling
|
||||
var runInitProfileTests = flag.Bool("test-init-profile", false, "run init profile tests")
|
||||
|
||||
func TestInitProfiling(t *testing.T) {
|
||||
if testing.Short() {
|
||||
t.Skip("short test")
|
||||
}
|
||||
|
||||
// Run this test in a separate process since it interferes with
|
||||
// profiling and modifies the global atexit state. Without this
|
||||
// running `go test -bench . -cpuprofile cpu.out` will fail.
|
||||
if !*runInitProfileTests {
|
||||
t.Parallel()
|
||||
|
||||
// Make sure we are not the child process.
|
||||
if os.Getenv("_FZF_CHILD_PROC") != "" {
|
||||
t.Fatal("already running as child process!")
|
||||
}
|
||||
|
||||
cmd := exec.Command(os.Args[0],
|
||||
"-test.timeout", "30s",
|
||||
"-test.run", "^"+t.Name()+"$",
|
||||
"-test-init-profile",
|
||||
)
|
||||
cmd.Env = append(os.Environ(), "_FZF_CHILD_PROC=1")
|
||||
|
||||
out, err := cmd.CombinedOutput()
|
||||
out = bytes.TrimSpace(out)
|
||||
if err != nil {
|
||||
t.Fatalf("Child test process failed: %v:\n%s", err, out)
|
||||
}
|
||||
// Make sure the test actually ran
|
||||
if bytes.Contains(out, []byte("no tests to run")) {
|
||||
t.Fatalf("Failed to run test %q:\n%s", t.Name(), out)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
// Child process
|
||||
|
||||
tempdir := t.TempDir()
|
||||
t.Cleanup(util.RunAtExitFuncs)
|
||||
|
||||
o := Options{
|
||||
CPUProfile: filepath.Join(tempdir, "cpu.prof"),
|
||||
MEMProfile: filepath.Join(tempdir, "mem.prof"),
|
||||
BlockProfile: filepath.Join(tempdir, "block.prof"),
|
||||
MutexProfile: filepath.Join(tempdir, "mutex.prof"),
|
||||
}
|
||||
if err := o.initProfiling(); err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
profiles := []string{
|
||||
o.CPUProfile,
|
||||
o.MEMProfile,
|
||||
o.BlockProfile,
|
||||
o.MutexProfile,
|
||||
}
|
||||
for _, name := range profiles {
|
||||
if _, err := os.Stat(name); err != nil {
|
||||
t.Errorf("Failed to create profile %s: %v", filepath.Base(name), err)
|
||||
}
|
||||
}
|
||||
|
||||
util.RunAtExitFuncs()
|
||||
|
||||
for _, name := range profiles {
|
||||
if _, err := os.Stat(name); err != nil {
|
||||
t.Errorf("Failed to write profile %s: %v", filepath.Base(name), err)
|
||||
}
|
||||
}
|
||||
}
|
||||
+43
-179
@@ -2,20 +2,16 @@ package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"io/ioutil"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
)
|
||||
|
||||
func TestDelimiterRegex(t *testing.T) {
|
||||
// Valid regex, but a single character -> string
|
||||
// Valid regex
|
||||
delim := delimiterRegexp(".")
|
||||
if delim.regex != nil || *delim.str != "." {
|
||||
t.Error(delim)
|
||||
}
|
||||
delim = delimiterRegexp("|")
|
||||
if delim.regex != nil || *delim.str != "|" {
|
||||
if delim.regex == nil || delim.str != nil {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Broken regex -> string
|
||||
@@ -84,7 +80,7 @@ func TestDelimiterRegexRegexCaret(t *testing.T) {
|
||||
|
||||
func TestSplitNth(t *testing.T) {
|
||||
{
|
||||
ranges, _ := splitNth("..")
|
||||
ranges := splitNth("..")
|
||||
if len(ranges) != 1 ||
|
||||
ranges[0].begin != rangeEllipsis ||
|
||||
ranges[0].end != rangeEllipsis {
|
||||
@@ -92,7 +88,7 @@ func TestSplitNth(t *testing.T) {
|
||||
}
|
||||
}
|
||||
{
|
||||
ranges, _ := splitNth("..3,1..,2..3,4..-1,-3..-2,..,2,-2,2..-2,1..-1")
|
||||
ranges := splitNth("..3,1..,2..3,4..-1,-3..-2,..,2,-2,2..-2,1..-1")
|
||||
if len(ranges) != 10 ||
|
||||
ranges[0].begin != rangeEllipsis || ranges[0].end != 3 ||
|
||||
ranges[1].begin != rangeEllipsis || ranges[1].end != rangeEllipsis ||
|
||||
@@ -110,11 +106,10 @@ func TestSplitNth(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestIrrelevantNth(t *testing.T) {
|
||||
index := 0
|
||||
{
|
||||
opts := defaultOptions()
|
||||
words := []string{"--nth", "..", "-x"}
|
||||
parseOptions(&index, opts, words)
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 0 {
|
||||
t.Errorf("nth should be empty: %v", opts.Nth)
|
||||
@@ -123,7 +118,7 @@ func TestIrrelevantNth(t *testing.T) {
|
||||
for _, words := range [][]string{{"--nth", "..,3", "+x"}, {"--nth", "3,1..", "+x"}, {"--nth", "..-1,1", "+x"}} {
|
||||
{
|
||||
opts := defaultOptions()
|
||||
parseOptions(&index, opts, words)
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 0 {
|
||||
t.Errorf("nth should be empty: %v", opts.Nth)
|
||||
@@ -132,7 +127,7 @@ func TestIrrelevantNth(t *testing.T) {
|
||||
{
|
||||
opts := defaultOptions()
|
||||
words = append(words, "-x")
|
||||
parseOptions(&index, opts, words)
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 2 {
|
||||
t.Errorf("nth should not be empty: %v", opts.Nth)
|
||||
@@ -142,7 +137,7 @@ func TestIrrelevantNth(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestParseKeys(t *testing.T) {
|
||||
pairs, _, _ := parseKeyChords("ctrl-z,alt-z,f2,@,Alt-a,!,ctrl-G,J,g,ctrl-alt-a,ALT-enter,alt-SPACE", "")
|
||||
pairs := parseKeyChords("ctrl-z,alt-z,f2,@,Alt-a,!,ctrl-G,J,g,ctrl-alt-a,ALT-enter,alt-SPACE", "")
|
||||
checkEvent := func(e tui.Event, s string) {
|
||||
if pairs[e] != s {
|
||||
t.Errorf("%s != %s", pairs[e], s)
|
||||
@@ -168,35 +163,35 @@ func TestParseKeys(t *testing.T) {
|
||||
checkEvent(tui.AltKey(' '), "alt-SPACE")
|
||||
|
||||
// Synonyms
|
||||
pairs, _, _ = parseKeyChords("enter,Return,space,tab,btab,esc,up,down,left,right", "")
|
||||
pairs = parseKeyChords("enter,Return,space,tab,btab,esc,up,down,left,right", "")
|
||||
if len(pairs) != 9 {
|
||||
t.Error(9)
|
||||
}
|
||||
check(tui.Enter, "Return")
|
||||
check(tui.CtrlM, "Return")
|
||||
checkEvent(tui.Key(' '), "space")
|
||||
check(tui.Tab, "tab")
|
||||
check(tui.ShiftTab, "btab")
|
||||
check(tui.Esc, "esc")
|
||||
check(tui.BTab, "btab")
|
||||
check(tui.ESC, "esc")
|
||||
check(tui.Up, "up")
|
||||
check(tui.Down, "down")
|
||||
check(tui.Left, "left")
|
||||
check(tui.Right, "right")
|
||||
|
||||
pairs, _, _ = parseKeyChords("Tab,Ctrl-I,PgUp,page-up,pgdn,Page-Down,Home,End,Alt-BS,Alt-BSpace,shift-left,shift-right,btab,shift-tab,return,Enter,bspace", "")
|
||||
pairs = parseKeyChords("Tab,Ctrl-I,PgUp,page-up,pgdn,Page-Down,Home,End,Alt-BS,Alt-BSpace,shift-left,shift-right,btab,shift-tab,return,Enter,bspace", "")
|
||||
if len(pairs) != 11 {
|
||||
t.Error(11)
|
||||
}
|
||||
check(tui.Tab, "Ctrl-I")
|
||||
check(tui.PageUp, "page-up")
|
||||
check(tui.PageDown, "Page-Down")
|
||||
check(tui.PgUp, "page-up")
|
||||
check(tui.PgDn, "Page-Down")
|
||||
check(tui.Home, "Home")
|
||||
check(tui.End, "End")
|
||||
check(tui.AltBackspace, "Alt-BSpace")
|
||||
check(tui.ShiftLeft, "shift-left")
|
||||
check(tui.ShiftRight, "shift-right")
|
||||
check(tui.ShiftTab, "shift-tab")
|
||||
check(tui.Enter, "Enter")
|
||||
check(tui.Backspace, "bspace")
|
||||
check(tui.AltBS, "Alt-BSpace")
|
||||
check(tui.SLeft, "shift-left")
|
||||
check(tui.SRight, "shift-right")
|
||||
check(tui.BTab, "shift-tab")
|
||||
check(tui.CtrlM, "Enter")
|
||||
check(tui.BSpace, "bspace")
|
||||
}
|
||||
|
||||
func TestParseKeysWithComma(t *testing.T) {
|
||||
@@ -211,40 +206,40 @@ func TestParseKeysWithComma(t *testing.T) {
|
||||
}
|
||||
}
|
||||
|
||||
pairs, _, _ := parseKeyChords(",", "")
|
||||
pairs := parseKeyChords(",", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords(",,a,b", "")
|
||||
pairs = parseKeyChords(",,a,b", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords("a,b,,", "")
|
||||
pairs = parseKeyChords("a,b,,", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords("a,,,b", "")
|
||||
pairs = parseKeyChords("a,,,b", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords("a,,,b,c", "")
|
||||
pairs = parseKeyChords("a,,,b,c", "")
|
||||
checkN(len(pairs), 4)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key('c'), "c")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords(",,,", "")
|
||||
pairs = parseKeyChords(",,,", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs, _, _ = parseKeyChords(",ALT-,,", "")
|
||||
pairs = parseKeyChords(",ALT-,,", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.AltKey(','), "ALT-,")
|
||||
}
|
||||
@@ -269,7 +264,7 @@ func TestBind(t *testing.T) {
|
||||
check(tui.CtrlA.AsEvent(), "", actBeginningOfLine)
|
||||
parseKeymap(keymap,
|
||||
"ctrl-a:kill-line,ctrl-b:toggle-sort+up+down,c:page-up,alt-z:page-down,"+
|
||||
"f1:execute(ls {+})+abort+execute(echo \n{+})+select-all,f2:execute/echo {}, {}, {}/,f3:execute[echo '({})'],f4:execute;less {};,"+
|
||||
"f1:execute(ls {+})+abort+execute(echo {+})+select-all,f2:execute/echo {}, {}, {}/,f3:execute[echo '({})'],f4:execute;less {};,"+
|
||||
"alt-a:execute-Multi@echo (,),[,],/,:,;,%,{}@,alt-b:execute;echo (,),[,],/,:,@,%,{};,"+
|
||||
"x:Execute(foo+bar),X:execute/bar+baz/"+
|
||||
",f1:+first,f1:+top"+
|
||||
@@ -299,46 +294,9 @@ func TestBind(t *testing.T) {
|
||||
check(tui.F1.AsEvent(), "", actAbort)
|
||||
}
|
||||
|
||||
func TestParseEveryEvent(t *testing.T) {
|
||||
pairs, _, err := parseKeyChords("every(2),every(0.5)", "")
|
||||
if err != nil {
|
||||
t.Fatalf("unexpected error: %v", err)
|
||||
}
|
||||
if len(pairs) != 2 {
|
||||
t.Errorf("expected 2 distinct every events, got %d", len(pairs))
|
||||
}
|
||||
if pairs[(tui.Event{Type: tui.Every, Char: 2000})] != "every(2)" {
|
||||
t.Errorf("every(2) not registered")
|
||||
}
|
||||
if pairs[(tui.Event{Type: tui.Every, Char: 500})] != "every(0.5)" {
|
||||
t.Errorf("every(0.5) not registered")
|
||||
}
|
||||
|
||||
// Floor at 0.01s -> 10ms
|
||||
pairs, _, err = parseKeyChords("every(0.001)", "")
|
||||
if err != nil {
|
||||
t.Fatalf("unexpected error: %v", err)
|
||||
}
|
||||
if pairs[(tui.Event{Type: tui.Every, Char: 10})] != "every(0.001)" {
|
||||
t.Errorf("every(0.001) should floor to 10ms")
|
||||
}
|
||||
|
||||
// Reject zero, negatives, and overflow (>= 2^31 ms = ~24.85 days)
|
||||
for _, bad := range []string{"every(0)", "every(-1)", "every(abc)", "every()", "every(2147484)"} {
|
||||
if _, _, err := parseKeyChords(bad, ""); err == nil {
|
||||
t.Errorf("%s should be rejected", bad)
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func TestColorSpec(t *testing.T) {
|
||||
var base *tui.ColorTheme
|
||||
theme := tui.Dark256
|
||||
base, dark, _ := parseTheme(theme, "dark")
|
||||
if *dark != *base {
|
||||
t.Errorf("incorrect base theme returned")
|
||||
}
|
||||
dark := parseTheme(theme, "dark")
|
||||
if *dark != *theme {
|
||||
t.Errorf("colors should be equivalent")
|
||||
}
|
||||
@@ -346,10 +304,7 @@ func TestColorSpec(t *testing.T) {
|
||||
t.Errorf("point should not be equivalent")
|
||||
}
|
||||
|
||||
base, light, _ := parseTheme(theme, "dark,light")
|
||||
if *light != *base {
|
||||
t.Errorf("incorrect base theme returned")
|
||||
}
|
||||
light := parseTheme(theme, "dark,light")
|
||||
if *light == *theme {
|
||||
t.Errorf("should not be equivalent")
|
||||
}
|
||||
@@ -360,7 +315,7 @@ func TestColorSpec(t *testing.T) {
|
||||
t.Errorf("point should not be equivalent")
|
||||
}
|
||||
|
||||
_, customized, _ := parseTheme(theme, "fg:231,bg:232")
|
||||
customized := parseTheme(theme, "fg:231,bg:232")
|
||||
if customized.Fg.Color != 231 || customized.Bg.Color != 232 {
|
||||
t.Errorf("color not customized")
|
||||
}
|
||||
@@ -373,46 +328,44 @@ func TestColorSpec(t *testing.T) {
|
||||
t.Errorf("colors should now be equivalent: %v, %v", tui.Dark256, customized)
|
||||
}
|
||||
|
||||
_, customized, _ = parseTheme(theme, "fg:231,dark bg:232")
|
||||
customized = parseTheme(theme, "fg:231,dark,bg:232")
|
||||
if customized.Fg != tui.Dark256.Fg || customized.Bg == tui.Dark256.Bg {
|
||||
t.Errorf("color not customized")
|
||||
}
|
||||
}
|
||||
|
||||
func TestDefaultCtrlNP(t *testing.T) {
|
||||
index := 0
|
||||
check := func(words []string, et tui.EventType, expected actionType) {
|
||||
e := et.AsEvent()
|
||||
opts := defaultOptions()
|
||||
parseOptions(&index, opts, words)
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if opts.Keymap[e][0].t != expected {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
check([]string{}, tui.CtrlN, actDownMatch)
|
||||
check([]string{}, tui.CtrlP, actUpMatch)
|
||||
check([]string{}, tui.CtrlN, actDown)
|
||||
check([]string{}, tui.CtrlP, actUp)
|
||||
|
||||
check([]string{"--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
||||
check([]string{"--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
||||
|
||||
f, _ := os.CreateTemp("", "fzf-history")
|
||||
f, _ := ioutil.TempFile("", "fzf-history")
|
||||
f.Close()
|
||||
hist := "--history=" + f.Name()
|
||||
check([]string{hist}, tui.CtrlN, actNextHistory)
|
||||
check([]string{hist}, tui.CtrlP, actPrevHistory)
|
||||
check([]string{hist}, tui.CtrlP, actPreviousHistory)
|
||||
|
||||
check([]string{hist, "--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
||||
check([]string{hist, "--bind=ctrl-n:accept"}, tui.CtrlP, actPrevHistory)
|
||||
check([]string{hist, "--bind=ctrl-n:accept"}, tui.CtrlP, actPreviousHistory)
|
||||
|
||||
check([]string{hist, "--bind=ctrl-p:accept"}, tui.CtrlN, actNextHistory)
|
||||
check([]string{hist, "--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
||||
}
|
||||
|
||||
func optsFor(words ...string) *Options {
|
||||
index := 0
|
||||
opts := defaultOptions()
|
||||
parseOptions(&index, opts, words)
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
return opts
|
||||
}
|
||||
@@ -481,64 +434,6 @@ func TestPreviewOpts(t *testing.T) {
|
||||
opts.Preview.size.size == 70) {
|
||||
t.Error(opts.Preview)
|
||||
}
|
||||
|
||||
// wrap-word tests
|
||||
opts = optsFor("--preview-window=wrap-word")
|
||||
if !(opts.Preview.wrap == true && opts.Preview.wrapWord == true) {
|
||||
t.Errorf("wrap-word: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
||||
}
|
||||
opts = optsFor("--preview-window=wrap-word,nowrap")
|
||||
if !(opts.Preview.wrap == false && opts.Preview.wrapWord == false) {
|
||||
t.Errorf("wrap-word,nowrap: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
||||
}
|
||||
opts = optsFor("--preview-window=wrap-word,wrap")
|
||||
if !(opts.Preview.wrap == true && opts.Preview.wrapWord == false) {
|
||||
t.Errorf("wrap-word,wrap: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
||||
}
|
||||
}
|
||||
|
||||
func TestPreviewWrapSign(t *testing.T) {
|
||||
// Default: no preview wrap sign override
|
||||
opts := optsFor()
|
||||
if opts.PreviewWrapSign != nil {
|
||||
t.Errorf("expected nil PreviewWrapSign, got %v", *opts.PreviewWrapSign)
|
||||
}
|
||||
|
||||
// --preview-wrap-sign sets PreviewWrapSign
|
||||
opts = optsFor("--preview-wrap-sign", ">> ")
|
||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != ">> " {
|
||||
t.Errorf("expected '>> ', got %v", opts.PreviewWrapSign)
|
||||
}
|
||||
|
||||
// --preview-wrap-sign is independent of --wrap-sign
|
||||
opts = optsFor("--wrap-sign", "| ", "--preview-wrap-sign", ">> ")
|
||||
if opts.WrapSign == nil || *opts.WrapSign != "| " {
|
||||
t.Errorf("expected WrapSign '| ', got %v", opts.WrapSign)
|
||||
}
|
||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != ">> " {
|
||||
t.Errorf("expected PreviewWrapSign '>> ', got %v", opts.PreviewWrapSign)
|
||||
}
|
||||
|
||||
// --preview-wrap-sign without --wrap-sign
|
||||
opts = optsFor("--preview-wrap-sign", "→ ")
|
||||
if opts.WrapSign != nil {
|
||||
t.Errorf("expected nil WrapSign, got %v", *opts.WrapSign)
|
||||
}
|
||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "→ " {
|
||||
t.Errorf("expected PreviewWrapSign '→ ', got %v", opts.PreviewWrapSign)
|
||||
}
|
||||
|
||||
// Last --preview-wrap-sign wins
|
||||
opts = optsFor("--preview-wrap-sign", "A ", "--preview-wrap-sign", "B ")
|
||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "B " {
|
||||
t.Errorf("expected PreviewWrapSign 'B ', got %v", opts.PreviewWrapSign)
|
||||
}
|
||||
|
||||
// Empty string is allowed
|
||||
opts = optsFor("--preview-wrap-sign", "")
|
||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "" {
|
||||
t.Errorf("expected empty PreviewWrapSign, got %v", opts.PreviewWrapSign)
|
||||
}
|
||||
}
|
||||
|
||||
func TestAdditiveExpect(t *testing.T) {
|
||||
@@ -556,11 +451,12 @@ func TestValidateSign(t *testing.T) {
|
||||
{"> ", true},
|
||||
{"아", true},
|
||||
{"😀", true},
|
||||
{"", false},
|
||||
{">>>", false},
|
||||
}
|
||||
|
||||
for _, testCase := range testCases {
|
||||
err := validateSign(testCase.inputSign, "", 2)
|
||||
err := validateSign(testCase.inputSign, "")
|
||||
if testCase.isValid && err != nil {
|
||||
t.Errorf("Input sign `%s` caused error", testCase.inputSign)
|
||||
}
|
||||
@@ -570,35 +466,3 @@ func TestValidateSign(t *testing.T) {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestParseSingleActionList(t *testing.T) {
|
||||
actions, _ := parseSingleActionList("Execute@foo+bar,baz@+up+up+reload:down+down")
|
||||
if len(actions) != 4 {
|
||||
t.Errorf("Invalid number of actions parsed:%d", len(actions))
|
||||
}
|
||||
if actions[0].t != actExecute || actions[0].a != "foo+bar,baz" {
|
||||
t.Errorf("Invalid action parsed: %v", actions[0])
|
||||
}
|
||||
if actions[1].t != actUp || actions[2].t != actUp {
|
||||
t.Errorf("Invalid action parsed: %v / %v", actions[1], actions[2])
|
||||
}
|
||||
if actions[3].t != actReload || actions[3].a != "down+down" {
|
||||
t.Errorf("Invalid action parsed: %v", actions[3])
|
||||
}
|
||||
}
|
||||
|
||||
func TestParseSingleActionListError(t *testing.T) {
|
||||
_, err := parseSingleActionList("change-query(foobar)baz")
|
||||
if err == nil {
|
||||
t.Errorf("Failed to detect error")
|
||||
}
|
||||
}
|
||||
|
||||
func TestMaskActionContents(t *testing.T) {
|
||||
original := ":execute((f)(o)(o)(b)(a)(r))+change-query@qu@ry@+up,x:reload:hello:world"
|
||||
expected := ":execute +change-query +up,x:reload "
|
||||
masked := maskActionContents(original)
|
||||
if masked != expected {
|
||||
t.Errorf("Not masked: %s", masked)
|
||||
}
|
||||
}
|
||||
|
||||
+57
-133
@@ -23,7 +23,6 @@ type termType int
|
||||
const (
|
||||
termFuzzy termType = iota
|
||||
termExact
|
||||
termExactBoundary
|
||||
termPrefix
|
||||
termSuffix
|
||||
termEqual
|
||||
@@ -52,7 +51,6 @@ type Pattern struct {
|
||||
caseSensitive bool
|
||||
normalize bool
|
||||
forward bool
|
||||
withPos bool
|
||||
text []rune
|
||||
termSets []termSet
|
||||
sortable bool
|
||||
@@ -60,24 +58,34 @@ type Pattern struct {
|
||||
cacheKey string
|
||||
delimiter Delimiter
|
||||
nth []Range
|
||||
revision revision
|
||||
procFun [6]algo.Algo
|
||||
cache *ChunkCache
|
||||
denylist map[int32]struct{}
|
||||
startIndex int32
|
||||
directAlgo algo.Algo
|
||||
directTerm *term
|
||||
procFun map[termType]algo.Algo
|
||||
}
|
||||
|
||||
var _splitRegex *regexp.Regexp
|
||||
var (
|
||||
_patternCache map[string]*Pattern
|
||||
_splitRegex *regexp.Regexp
|
||||
_cache ChunkCache
|
||||
)
|
||||
|
||||
func init() {
|
||||
_splitRegex = regexp.MustCompile(" +")
|
||||
clearPatternCache()
|
||||
clearChunkCache()
|
||||
}
|
||||
|
||||
func clearPatternCache() {
|
||||
// We can uniquely identify the pattern for a given string since
|
||||
// search mode and caseMode do not change while the program is running
|
||||
_patternCache = make(map[string]*Pattern)
|
||||
}
|
||||
|
||||
func clearChunkCache() {
|
||||
_cache = NewChunkCache()
|
||||
}
|
||||
|
||||
// BuildPattern builds Pattern object from the given arguments
|
||||
func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
||||
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, revision revision, runes []rune, denylist map[int32]struct{}, startIndex int32) *Pattern {
|
||||
func BuildPattern(fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
||||
cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
||||
|
||||
var asString string
|
||||
if extended {
|
||||
@@ -89,9 +97,7 @@ func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy boo
|
||||
asString = string(runes)
|
||||
}
|
||||
|
||||
// We can uniquely identify the pattern for a given string since
|
||||
// search mode and caseMode do not change while the program is running
|
||||
cached, found := patternCache[asString]
|
||||
cached, found := _patternCache[asString]
|
||||
if found {
|
||||
return cached
|
||||
}
|
||||
@@ -139,41 +145,34 @@ func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy boo
|
||||
caseSensitive: caseSensitive,
|
||||
normalize: normalize,
|
||||
forward: forward,
|
||||
withPos: withPos,
|
||||
text: []rune(asString),
|
||||
termSets: termSets,
|
||||
sortable: sortable,
|
||||
cacheable: cacheable,
|
||||
nth: nth,
|
||||
revision: revision,
|
||||
delimiter: delimiter,
|
||||
cache: cache,
|
||||
denylist: denylist,
|
||||
startIndex: startIndex,
|
||||
}
|
||||
procFun: make(map[termType]algo.Algo)}
|
||||
|
||||
ptr.cacheKey = ptr.buildCacheKey()
|
||||
ptr.directAlgo, ptr.directTerm = ptr.buildDirectAlgo(fuzzyAlgo)
|
||||
ptr.procFun[termFuzzy] = fuzzyAlgo
|
||||
ptr.procFun[termEqual] = algo.EqualMatch
|
||||
ptr.procFun[termExact] = algo.ExactMatchNaive
|
||||
ptr.procFun[termExactBoundary] = algo.ExactMatchBoundary
|
||||
ptr.procFun[termPrefix] = algo.PrefixMatch
|
||||
ptr.procFun[termSuffix] = algo.SuffixMatch
|
||||
|
||||
patternCache[asString] = ptr
|
||||
_patternCache[asString] = ptr
|
||||
return ptr
|
||||
}
|
||||
|
||||
func parseTerms(fuzzy bool, caseMode Case, normalize bool, str string) []termSet {
|
||||
str = strings.ReplaceAll(str, "\\ ", "\t")
|
||||
str = strings.Replace(str, "\\ ", "\t", -1)
|
||||
tokens := _splitRegex.Split(str, -1)
|
||||
sets := []termSet{}
|
||||
set := termSet{}
|
||||
switchSet := false
|
||||
afterBar := false
|
||||
for _, token := range tokens {
|
||||
typ, inv, text := termFuzzy, false, strings.ReplaceAll(token, "\t", " ")
|
||||
typ, inv, text := termFuzzy, false, strings.Replace(token, "\t", " ", -1)
|
||||
lowerText := strings.ToLower(text)
|
||||
caseSensitive := caseMode == CaseRespect ||
|
||||
caseMode == CaseSmart && text != lowerText
|
||||
@@ -204,17 +203,15 @@ func parseTerms(fuzzy bool, caseMode Case, normalize bool, str string) []termSet
|
||||
text = text[:len(text)-1]
|
||||
}
|
||||
|
||||
if len(text) > 2 && strings.HasPrefix(text, "'") && strings.HasSuffix(text, "'") {
|
||||
typ = termExactBoundary
|
||||
text = text[1 : len(text)-1]
|
||||
} else if strings.HasPrefix(text, "'") {
|
||||
if strings.HasPrefix(text, "'") {
|
||||
// Flip exactness
|
||||
if fuzzy && !inv {
|
||||
typ = termExact
|
||||
text = text[1:]
|
||||
} else {
|
||||
typ = termFuzzy
|
||||
text = text[1:]
|
||||
}
|
||||
text = text[1:]
|
||||
} else if strings.HasPrefix(text, "^") {
|
||||
if typ == termSuffix {
|
||||
typ = termEqual
|
||||
@@ -250,9 +247,6 @@ func parseTerms(fuzzy bool, caseMode Case, normalize bool, str string) []termSet
|
||||
|
||||
// IsEmpty returns true if the pattern is effectively empty
|
||||
func (p *Pattern) IsEmpty() bool {
|
||||
if len(p.denylist) > 0 {
|
||||
return false
|
||||
}
|
||||
if !p.extended {
|
||||
return len(p.text) == 0
|
||||
}
|
||||
@@ -277,22 +271,6 @@ func (p *Pattern) buildCacheKey() string {
|
||||
return strings.Join(cacheableTerms, "\t")
|
||||
}
|
||||
|
||||
// buildDirectAlgo returns the algo function and term for the direct fast path
|
||||
// in matchChunk. Returns (nil, nil) if the pattern is not suitable.
|
||||
// Requirements: extended mode, single term set with single non-inverse fuzzy term, no nth.
|
||||
func (p *Pattern) buildDirectAlgo(fuzzyAlgo algo.Algo) (algo.Algo, *term) {
|
||||
if !p.extended || len(p.nth) > 0 {
|
||||
return nil, nil
|
||||
}
|
||||
if len(p.termSets) == 1 && len(p.termSets[0]) == 1 {
|
||||
t := &p.termSets[0][0]
|
||||
if !t.inv && t.typ == termFuzzy {
|
||||
return fuzzyAlgo, t
|
||||
}
|
||||
}
|
||||
return nil, nil
|
||||
}
|
||||
|
||||
// CacheKey is used to build string to be used as the key of result cache
|
||||
func (p *Pattern) CacheKey() string {
|
||||
return p.cacheKey
|
||||
@@ -300,104 +278,60 @@ func (p *Pattern) CacheKey() string {
|
||||
|
||||
// Match returns the list of matches Items in the given Chunk
|
||||
func (p *Pattern) Match(chunk *Chunk, slab *util.Slab) []Result {
|
||||
// ChunkCache: Exact match
|
||||
cacheKey := p.CacheKey()
|
||||
|
||||
// Bitmap cache: exact match or prefix/suffix
|
||||
var cachedBitmap *ChunkBitmap
|
||||
if p.cacheable {
|
||||
cachedBitmap = p.cache.Lookup(chunk, cacheKey)
|
||||
}
|
||||
if cachedBitmap == nil {
|
||||
cachedBitmap = p.cache.Search(chunk, cacheKey)
|
||||
if cached := _cache.Lookup(chunk, cacheKey); cached != nil {
|
||||
return cached
|
||||
}
|
||||
}
|
||||
|
||||
matches, bitmap := p.matchChunk(chunk, cachedBitmap, slab)
|
||||
// Prefix/suffix cache
|
||||
space := _cache.Search(chunk, cacheKey)
|
||||
|
||||
matches := p.matchChunk(chunk, space, slab)
|
||||
|
||||
if p.cacheable {
|
||||
p.cache.Add(chunk, cacheKey, bitmap, len(matches))
|
||||
_cache.Add(chunk, cacheKey, matches)
|
||||
}
|
||||
return matches
|
||||
}
|
||||
|
||||
func (p *Pattern) matchChunk(chunk *Chunk, cachedBitmap *ChunkBitmap, slab *util.Slab) ([]Result, ChunkBitmap) {
|
||||
func (p *Pattern) matchChunk(chunk *Chunk, space []Result, slab *util.Slab) []Result {
|
||||
matches := []Result{}
|
||||
var bitmap ChunkBitmap
|
||||
|
||||
// Skip header items in chunks that contain them
|
||||
startIdx := 0
|
||||
if p.startIndex > 0 && chunk.count > 0 && chunk.items[0].Index() < p.startIndex {
|
||||
startIdx = int(p.startIndex - chunk.items[0].Index())
|
||||
if startIdx >= chunk.count {
|
||||
return matches, bitmap
|
||||
}
|
||||
}
|
||||
|
||||
hasCachedBitmap := cachedBitmap != nil
|
||||
|
||||
// Fast path: single fuzzy term, no nth, no denylist.
|
||||
// Calls the algo function directly, bypassing MatchItem/extendedMatch/iter
|
||||
// and avoiding per-match []Offset heap allocation.
|
||||
if p.directAlgo != nil && len(p.denylist) == 0 {
|
||||
t := p.directTerm
|
||||
for idx := startIdx; idx < chunk.count; idx++ {
|
||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
||||
continue
|
||||
}
|
||||
res, _ := p.directAlgo(t.caseSensitive, t.normalize, p.forward,
|
||||
&chunk.items[idx].text, t.text, p.withPos, slab)
|
||||
if res.Start >= 0 {
|
||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
||||
matches = append(matches, buildResultFromBounds(
|
||||
&chunk.items[idx], res.Score,
|
||||
int(res.Start), int(res.End), int(res.End), true))
|
||||
if space == nil {
|
||||
for idx := 0; idx < chunk.count; idx++ {
|
||||
if match, _, _ := p.MatchItem(&chunk.items[idx], false, slab); match != nil {
|
||||
matches = append(matches, *match)
|
||||
}
|
||||
}
|
||||
return matches, bitmap
|
||||
}
|
||||
|
||||
if len(p.denylist) == 0 {
|
||||
for idx := startIdx; idx < chunk.count; idx++ {
|
||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
||||
continue
|
||||
}
|
||||
if match, _, _ := p.MatchItem(&chunk.items[idx], p.withPos, slab); match.item != nil {
|
||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
||||
matches = append(matches, match)
|
||||
} else {
|
||||
for _, result := range space {
|
||||
if match, _, _ := p.MatchItem(result.item, false, slab); match != nil {
|
||||
matches = append(matches, *match)
|
||||
}
|
||||
}
|
||||
return matches, bitmap
|
||||
}
|
||||
|
||||
for idx := startIdx; idx < chunk.count; idx++ {
|
||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
||||
continue
|
||||
}
|
||||
if _, prs := p.denylist[chunk.items[idx].Index()]; prs {
|
||||
continue
|
||||
}
|
||||
if match, _, _ := p.MatchItem(&chunk.items[idx], p.withPos, slab); match.item != nil {
|
||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
||||
matches = append(matches, match)
|
||||
}
|
||||
}
|
||||
return matches, bitmap
|
||||
return matches
|
||||
}
|
||||
|
||||
// MatchItem returns the match result if the Item is a match.
|
||||
// A zero-value Result (with item == nil) indicates no match.
|
||||
func (p *Pattern) MatchItem(item *Item, withPos bool, slab *util.Slab) (Result, []Offset, *[]int) {
|
||||
// MatchItem returns true if the Item is a match
|
||||
func (p *Pattern) MatchItem(item *Item, withPos bool, slab *util.Slab) (*Result, []Offset, *[]int) {
|
||||
if p.extended {
|
||||
if offsets, bonus, pos := p.extendedMatch(item, withPos, slab); len(offsets) == len(p.termSets) {
|
||||
return buildResult(item, offsets, bonus), offsets, pos
|
||||
result := buildResult(item, offsets, bonus)
|
||||
return &result, offsets, pos
|
||||
}
|
||||
return Result{}, nil, nil
|
||||
return nil, nil, nil
|
||||
}
|
||||
offset, bonus, pos := p.basicMatch(item, withPos, slab)
|
||||
if sidx := offset[0]; sidx >= 0 {
|
||||
offsets := []Offset{offset}
|
||||
return buildResult(item, offsets, bonus), offsets, pos
|
||||
result := buildResult(item, offsets, bonus)
|
||||
return &result, offsets, pos
|
||||
}
|
||||
return Result{}, nil, nil
|
||||
return nil, nil, nil
|
||||
}
|
||||
|
||||
func (p *Pattern) basicMatch(item *Item, withPos bool, slab *util.Slab) (Offset, int, *[]int) {
|
||||
@@ -465,22 +399,12 @@ func (p *Pattern) extendedMatch(item *Item, withPos bool, slab *util.Slab) ([]Of
|
||||
|
||||
func (p *Pattern) transformInput(item *Item) []Token {
|
||||
if item.transformed != nil {
|
||||
transformed := *item.transformed
|
||||
if transformed.revision == p.revision {
|
||||
return transformed.tokens
|
||||
}
|
||||
return *item.transformed
|
||||
}
|
||||
|
||||
tokens := Tokenize(item.text.ToString(), p.delimiter)
|
||||
ret := Transform(tokens, p.nth)
|
||||
// Strip the last delimiter to allow suffix match
|
||||
if len(ret) > 0 && !p.delimiter.IsAwk() {
|
||||
chars := ret[len(ret)-1].text
|
||||
stripped := StripLastDelimiter(chars.ToString(), p.delimiter)
|
||||
newChars := util.ToChars(stringBytes(stripped))
|
||||
ret[len(ret)-1].text = &newChars
|
||||
}
|
||||
item.transformed = &transformed{p.revision, ret}
|
||||
item.transformed = &ret
|
||||
return ret
|
||||
}
|
||||
|
||||
|
||||
+30
-139
@@ -2,7 +2,6 @@ package fzf
|
||||
|
||||
import (
|
||||
"reflect"
|
||||
"runtime"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/algo"
|
||||
@@ -65,15 +64,10 @@ func TestParseTermsEmpty(t *testing.T) {
|
||||
}
|
||||
}
|
||||
|
||||
func buildPattern(fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
||||
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
||||
return BuildPattern(NewChunkCache(), make(map[string]*Pattern),
|
||||
fuzzy, fuzzyAlgo, extended, caseMode, normalize, forward,
|
||||
withPos, cacheable, nth, delimiter, revision{}, runes, nil, 0)
|
||||
}
|
||||
|
||||
func TestExact(t *testing.T) {
|
||||
pattern := buildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, false, true,
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true,
|
||||
[]Range{}, Delimiter{}, []rune("'abc"))
|
||||
chars := util.ToChars([]byte("aabbcc abc"))
|
||||
res, pos := algo.ExactMatchNaive(
|
||||
@@ -87,7 +81,9 @@ func TestExact(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestEqual(t *testing.T) {
|
||||
pattern := buildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, false, true, []Range{}, Delimiter{}, []rune("^AbC$"))
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("^AbC$"))
|
||||
|
||||
match := func(str string, sidxExpected int, eidxExpected int) {
|
||||
chars := util.ToChars([]byte(str))
|
||||
@@ -108,12 +104,19 @@ func TestEqual(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestCaseSensitivity(t *testing.T) {
|
||||
pat1 := buildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, false, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
pat2 := buildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, false, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
pat3 := buildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, false, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
pat4 := buildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, false, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
pat5 := buildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, false, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
pat6 := buildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, false, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pat1 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat2 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
clearPatternCache()
|
||||
pat3 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat4 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
clearPatternCache()
|
||||
pat5 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat6 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
|
||||
if string(pat1.text) != "abc" || pat1.caseSensitive != false ||
|
||||
string(pat2.text) != "Abc" || pat2.caseSensitive != true ||
|
||||
@@ -126,7 +129,7 @@ func TestCaseSensitivity(t *testing.T) {
|
||||
}
|
||||
|
||||
func TestOrigTextAndTransformed(t *testing.T) {
|
||||
pattern := buildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, false, true, []Range{}, Delimiter{}, []rune("jg"))
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("jg"))
|
||||
tokens := Tokenize("junegunn", Delimiter{})
|
||||
trans := Transform(tokens, []Range{{1, 1}})
|
||||
|
||||
@@ -136,12 +139,12 @@ func TestOrigTextAndTransformed(t *testing.T) {
|
||||
chunk.items[0] = Item{
|
||||
text: util.ToChars([]byte("junegunn")),
|
||||
origText: &origBytes,
|
||||
transformed: &transformed{pattern.revision, trans}}
|
||||
transformed: &trans}
|
||||
pattern.extended = extended
|
||||
matches, _ := pattern.matchChunk(&chunk, nil, slab) // No cache
|
||||
matches := pattern.matchChunk(&chunk, nil, slab) // No cache
|
||||
if !(matches[0].item.text.ToString() == "junegunn" &&
|
||||
string(*matches[0].item.origText) == "junegunn.choi" &&
|
||||
reflect.DeepEqual((*matches[0].item.transformed).tokens, trans)) {
|
||||
reflect.DeepEqual(*matches[0].item.transformed, trans)) {
|
||||
t.Error("Invalid match result", matches)
|
||||
}
|
||||
|
||||
@@ -149,7 +152,7 @@ func TestOrigTextAndTransformed(t *testing.T) {
|
||||
if !(match.item.text.ToString() == "junegunn" &&
|
||||
string(*match.item.origText) == "junegunn.choi" &&
|
||||
offsets[0][0] == 0 && offsets[0][1] == 5 &&
|
||||
reflect.DeepEqual((*match.item.transformed).tokens, trans)) {
|
||||
reflect.DeepEqual(*match.item.transformed, trans)) {
|
||||
t.Error("Invalid match result", match, offsets, extended)
|
||||
}
|
||||
if !((*pos)[0] == 4 && (*pos)[1] == 0) {
|
||||
@@ -160,13 +163,15 @@ func TestOrigTextAndTransformed(t *testing.T) {
|
||||
|
||||
func TestCacheKey(t *testing.T) {
|
||||
test := func(extended bool, patStr string, expected string, cacheable bool) {
|
||||
pat := buildPattern(true, algo.FuzzyMatchV2, extended, CaseSmart, false, true, false, true, []Range{}, Delimiter{}, []rune(patStr))
|
||||
clearPatternCache()
|
||||
pat := BuildPattern(true, algo.FuzzyMatchV2, extended, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune(patStr))
|
||||
if pat.CacheKey() != expected {
|
||||
t.Errorf("Expected: %s, actual: %s", expected, pat.CacheKey())
|
||||
}
|
||||
if pat.cacheable != cacheable {
|
||||
t.Errorf("Expected: %t, actual: %t (%s)", cacheable, pat.cacheable, patStr)
|
||||
}
|
||||
clearPatternCache()
|
||||
}
|
||||
test(false, "foo !bar", "foo !bar", true)
|
||||
test(false, "foo | bar !baz", "foo | bar !baz", true)
|
||||
@@ -182,13 +187,15 @@ func TestCacheKey(t *testing.T) {
|
||||
|
||||
func TestCacheable(t *testing.T) {
|
||||
test := func(fuzzy bool, str string, expected string, cacheable bool) {
|
||||
pat := buildPattern(fuzzy, algo.FuzzyMatchV2, true, CaseSmart, true, true, false, true, []Range{}, Delimiter{}, []rune(str))
|
||||
clearPatternCache()
|
||||
pat := BuildPattern(fuzzy, algo.FuzzyMatchV2, true, CaseSmart, true, true, true, []Range{}, Delimiter{}, []rune(str))
|
||||
if pat.CacheKey() != expected {
|
||||
t.Errorf("Expected: %s, actual: %s", expected, pat.CacheKey())
|
||||
}
|
||||
if cacheable != pat.cacheable {
|
||||
t.Errorf("Invalid Pattern.cacheable for \"%s\": %v (expected: %v)", str, pat.cacheable, cacheable)
|
||||
}
|
||||
clearPatternCache()
|
||||
}
|
||||
test(true, "foo bar", "foo\tbar", true)
|
||||
test(true, "foo 'bar", "foo\tbar", false)
|
||||
@@ -200,119 +207,3 @@ func TestCacheable(t *testing.T) {
|
||||
test(false, "foo 'bar", "foo", false)
|
||||
test(false, "foo !bar", "foo", false)
|
||||
}
|
||||
|
||||
func buildChunks(numChunks int) []*Chunk {
|
||||
chunks := make([]*Chunk, numChunks)
|
||||
words := []string{
|
||||
"src/main/java/com/example/service/UserService.java",
|
||||
"src/test/java/com/example/service/UserServiceTest.java",
|
||||
"docs/api/reference/endpoints.md",
|
||||
"lib/internal/utils/string_helper.go",
|
||||
"pkg/server/http/handler/auth.go",
|
||||
"build/output/release/app.exe",
|
||||
"config/production/database.yml",
|
||||
"scripts/deploy/kubernetes/setup.sh",
|
||||
"vendor/github.com/junegunn/fzf/src/core.go",
|
||||
"node_modules/.cache/babel/transform.js",
|
||||
}
|
||||
for ci := range numChunks {
|
||||
chunks[ci] = &Chunk{count: chunkSize}
|
||||
for i := range chunkSize {
|
||||
text := words[(ci*chunkSize+i)%len(words)]
|
||||
chunks[ci].items[i] = Item{text: util.ToChars([]byte(text))}
|
||||
chunks[ci].items[i].text.Index = int32(ci*chunkSize + i)
|
||||
}
|
||||
}
|
||||
return chunks
|
||||
}
|
||||
|
||||
func buildPatternWith(cache *ChunkCache, runes []rune) *Pattern {
|
||||
return BuildPattern(cache, make(map[string]*Pattern),
|
||||
true, algo.FuzzyMatchV2, true, CaseSmart, false, true,
|
||||
false, true, []Range{}, Delimiter{}, revision{}, runes, nil, 0)
|
||||
}
|
||||
|
||||
func TestBitmapCacheBenefit(t *testing.T) {
|
||||
numChunks := 100
|
||||
chunks := buildChunks(numChunks)
|
||||
queries := []string{"s", "se", "ser", "serv", "servi"}
|
||||
|
||||
// 1. Run all queries with shared cache (simulates incremental typing)
|
||||
cache := NewChunkCache()
|
||||
for _, q := range queries {
|
||||
pat := buildPatternWith(cache, []rune(q))
|
||||
for _, chunk := range chunks {
|
||||
pat.Match(chunk, slab)
|
||||
}
|
||||
}
|
||||
|
||||
// 2. GC and measure memory with cache populated
|
||||
runtime.GC()
|
||||
runtime.GC()
|
||||
var memWith runtime.MemStats
|
||||
runtime.ReadMemStats(&memWith)
|
||||
|
||||
// 3. Clear cache, GC, measure again
|
||||
cache.Clear()
|
||||
runtime.GC()
|
||||
runtime.GC()
|
||||
var memWithout runtime.MemStats
|
||||
runtime.ReadMemStats(&memWithout)
|
||||
|
||||
cacheMem := int64(memWith.Alloc) - int64(memWithout.Alloc)
|
||||
t.Logf("Chunks: %d, Queries: %d", numChunks, len(queries))
|
||||
t.Logf("Cache memory: %d bytes (%.1f KB)", cacheMem, float64(cacheMem)/1024)
|
||||
t.Logf("Per-chunk-per-query: %.0f bytes", float64(cacheMem)/float64(numChunks*len(queries)))
|
||||
|
||||
// 4. Verify correctness: cached vs uncached produce same results
|
||||
cache2 := NewChunkCache()
|
||||
for _, q := range queries {
|
||||
pat := buildPatternWith(cache2, []rune(q))
|
||||
for _, chunk := range chunks {
|
||||
pat.Match(chunk, slab)
|
||||
}
|
||||
}
|
||||
for _, q := range queries {
|
||||
patCached := buildPatternWith(cache2, []rune(q))
|
||||
patFresh := buildPatternWith(NewChunkCache(), []rune(q))
|
||||
var countCached, countFresh int
|
||||
for _, chunk := range chunks {
|
||||
countCached += len(patCached.Match(chunk, slab))
|
||||
countFresh += len(patFresh.Match(chunk, slab))
|
||||
}
|
||||
if countCached != countFresh {
|
||||
t.Errorf("query=%q: cached=%d, fresh=%d", q, countCached, countFresh)
|
||||
}
|
||||
t.Logf("query=%q: matches=%d", q, countCached)
|
||||
}
|
||||
}
|
||||
|
||||
func BenchmarkWithCache(b *testing.B) {
|
||||
numChunks := 100
|
||||
chunks := buildChunks(numChunks)
|
||||
queries := []string{"s", "se", "ser", "serv", "servi"}
|
||||
|
||||
b.Run("cached", func(b *testing.B) {
|
||||
for range b.N {
|
||||
cache := NewChunkCache()
|
||||
for _, q := range queries {
|
||||
pat := buildPatternWith(cache, []rune(q))
|
||||
for _, chunk := range chunks {
|
||||
pat.Match(chunk, slab)
|
||||
}
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
b.Run("uncached", func(b *testing.B) {
|
||||
for range b.N {
|
||||
for _, q := range queries {
|
||||
cache := NewChunkCache()
|
||||
pat := buildPatternWith(cache, []rune(q))
|
||||
for _, chunk := range chunks {
|
||||
pat.Match(chunk, slab)
|
||||
}
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
@@ -3,4 +3,6 @@
|
||||
package protector
|
||||
|
||||
// Protect calls OS specific protections like pledge on OpenBSD
|
||||
func Protect() {}
|
||||
func Protect() {
|
||||
return
|
||||
}
|
||||
|
||||
@@ -6,5 +6,5 @@ import "golang.org/x/sys/unix"
|
||||
|
||||
// Protect calls OS specific protections like pledge on OpenBSD
|
||||
func Protect() {
|
||||
unix.PledgePromises("stdio cpath dpath wpath rpath inet fattr unix tty proc exec")
|
||||
unix.PledgePromises("stdio rpath tty proc exec")
|
||||
}
|
||||
|
||||
-188
@@ -1,188 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"os"
|
||||
"os/exec"
|
||||
"os/signal"
|
||||
"path/filepath"
|
||||
"regexp"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
const becomeSuffix = ".become"
|
||||
|
||||
func escapeSingleQuote(str string) string {
|
||||
return "'" + strings.ReplaceAll(str, "'", "'\\''") + "'"
|
||||
}
|
||||
|
||||
func popupArgStr(args []string, opts *Options) (string, string) {
|
||||
fzf, rest := args[0], args[1:]
|
||||
args = []string{"--bind=ctrl-z:ignore"}
|
||||
if !opts.Tmux.border && (opts.BorderShape == tui.BorderUndefined || opts.BorderShape == tui.BorderLine) {
|
||||
if tui.DefaultBorderShape == tui.BorderRounded {
|
||||
rest = append(rest, "--border=rounded")
|
||||
} else {
|
||||
rest = append(rest, "--border=sharp")
|
||||
}
|
||||
}
|
||||
if opts.Tmux.border && opts.Margin == defaultMargin() {
|
||||
args = append(args, "--margin=0,1")
|
||||
}
|
||||
argStr := escapeSingleQuote(fzf)
|
||||
for _, arg := range append(args, rest...) {
|
||||
argStr += " " + escapeSingleQuote(arg)
|
||||
}
|
||||
argStr += ` --no-popup --no-height`
|
||||
|
||||
dir, err := os.Getwd()
|
||||
if err != nil {
|
||||
dir = "."
|
||||
}
|
||||
return argStr, dir
|
||||
}
|
||||
|
||||
func fifo(name string) (string, error) {
|
||||
ns := time.Now().UnixNano()
|
||||
output := filepath.Join(os.TempDir(), fmt.Sprintf("fzf-%s-%d", name, ns))
|
||||
output, err := mkfifo(output, 0600)
|
||||
if err != nil {
|
||||
return output, err
|
||||
}
|
||||
return output, nil
|
||||
}
|
||||
|
||||
func runProxy(commandPrefix string, cmdBuilder func(temp string, needBash bool) (*exec.Cmd, error), opts *Options, withExports bool) (int, error) {
|
||||
output, err := fifo("proxy-output")
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
defer os.Remove(output)
|
||||
|
||||
// Take the output
|
||||
go func() {
|
||||
withOutputPipe(output, func(outputFile io.ReadCloser) {
|
||||
if opts.Output == nil {
|
||||
io.Copy(os.Stdout, outputFile)
|
||||
} else {
|
||||
reader := bufio.NewReader(outputFile)
|
||||
sep := opts.PrintSep[0]
|
||||
for {
|
||||
item, err := reader.ReadString(sep)
|
||||
if err != nil {
|
||||
break
|
||||
}
|
||||
opts.Output <- item
|
||||
}
|
||||
}
|
||||
})
|
||||
}()
|
||||
|
||||
var command, input string
|
||||
commandPrefix += ` --no-force-tty-in --proxy-script "$0"`
|
||||
if opts.Input == nil && (opts.ForceTtyIn || util.IsTty(os.Stdin)) {
|
||||
command = fmt.Sprintf(`%s > %q`, commandPrefix, output)
|
||||
} else {
|
||||
input, err = fifo("proxy-input")
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
defer os.Remove(input)
|
||||
|
||||
go func() {
|
||||
withInputPipe(input, func(inputFile io.WriteCloser) {
|
||||
if opts.Input == nil {
|
||||
io.Copy(inputFile, os.Stdin)
|
||||
} else {
|
||||
for item := range opts.Input {
|
||||
fmt.Fprint(inputFile, item+opts.PrintSep)
|
||||
}
|
||||
}
|
||||
})
|
||||
}()
|
||||
|
||||
if withExports {
|
||||
command = fmt.Sprintf(`%s < %q > %q`, commandPrefix, input, output)
|
||||
} else {
|
||||
// For mintty: cannot directly read named pipe from Go code
|
||||
command = fmt.Sprintf(`command cat %q | %s > %q`, input, commandPrefix, output)
|
||||
}
|
||||
}
|
||||
|
||||
// Write the command to a temporary file and run it with sh to ensure POSIX compliance.
|
||||
var exports []string
|
||||
needBash := false
|
||||
if withExports {
|
||||
// Nullify FZF_DEFAULT_* variables as tmux popup may inject them even when undefined.
|
||||
exports = []string{"FZF_DEFAULT_COMMAND=", "FZF_DEFAULT_OPTS=", "FZF_DEFAULT_OPTS_FILE="}
|
||||
validIdentifier := regexp.MustCompile(`^[a-zA-Z_][a-zA-Z0-9_]*$`)
|
||||
for _, pairStr := range os.Environ() {
|
||||
pair := strings.SplitN(pairStr, "=", 2)
|
||||
if validIdentifier.MatchString(pair[0]) {
|
||||
exports = append(exports, fmt.Sprintf("export %s=%s", pair[0], escapeSingleQuote(pair[1])))
|
||||
} else if strings.HasPrefix(pair[0], "BASH_FUNC_") && strings.HasSuffix(pair[0], "%%") {
|
||||
name := pair[0][10 : len(pair[0])-2]
|
||||
exports = append(exports, name+pair[1])
|
||||
exports = append(exports, "export -f "+name)
|
||||
needBash = true
|
||||
}
|
||||
}
|
||||
}
|
||||
temp := WriteTemporaryFile(append(exports, command), "\n")
|
||||
defer os.Remove(temp)
|
||||
|
||||
cmd, err := cmdBuilder(temp, needBash)
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
cmd.Stderr = os.Stderr
|
||||
intChan := make(chan os.Signal, 1)
|
||||
defer close(intChan)
|
||||
go func() {
|
||||
if sig, valid := <-intChan; valid {
|
||||
cmd.Process.Signal(sig)
|
||||
}
|
||||
}()
|
||||
signal.Notify(intChan, os.Interrupt)
|
||||
if err := cmd.Run(); err != nil {
|
||||
if exitError, ok := err.(*exec.ExitError); ok {
|
||||
code := exitError.ExitCode()
|
||||
if code == ExitBecome {
|
||||
becomeFile := temp + becomeSuffix
|
||||
data, err := os.ReadFile(becomeFile)
|
||||
os.Remove(becomeFile)
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
elems := strings.Split(string(data), "\x00")
|
||||
if len(elems) < 1 {
|
||||
return ExitError, errors.New("invalid become command")
|
||||
}
|
||||
command := elems[0]
|
||||
env := []string{}
|
||||
if len(elems) > 1 {
|
||||
env = elems[1:]
|
||||
}
|
||||
executor := util.NewExecutor(opts.WithShell)
|
||||
ttyin, err := tui.TtyIn(opts.TtyDefault)
|
||||
if err != nil {
|
||||
return ExitError, err
|
||||
}
|
||||
os.Remove(temp)
|
||||
os.Remove(input)
|
||||
os.Remove(output)
|
||||
executor.Become(ttyin, env, command)
|
||||
}
|
||||
return code, err
|
||||
}
|
||||
}
|
||||
|
||||
return ExitOk, nil
|
||||
}
|
||||
@@ -1,41 +0,0 @@
|
||||
//go:build !windows
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"io"
|
||||
"os"
|
||||
|
||||
"golang.org/x/sys/unix"
|
||||
)
|
||||
|
||||
func sh(bash bool) (string, error) {
|
||||
if bash {
|
||||
return "bash", nil
|
||||
}
|
||||
return "sh", nil
|
||||
}
|
||||
|
||||
func mkfifo(path string, mode uint32) (string, error) {
|
||||
return path, unix.Mkfifo(path, mode)
|
||||
}
|
||||
|
||||
func withOutputPipe(output string, task func(io.ReadCloser)) error {
|
||||
outputFile, err := os.OpenFile(output, os.O_RDONLY, 0)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
task(outputFile)
|
||||
outputFile.Close()
|
||||
return nil
|
||||
}
|
||||
|
||||
func withInputPipe(input string, task func(io.WriteCloser)) error {
|
||||
inputFile, err := os.OpenFile(input, os.O_WRONLY, 0)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
task(inputFile)
|
||||
inputFile.Close()
|
||||
return nil
|
||||
}
|
||||
@@ -1,85 +0,0 @@
|
||||
//go:build windows
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"io"
|
||||
"os/exec"
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
var shPath atomic.Value
|
||||
|
||||
func sh(bash bool) (string, error) {
|
||||
if cached := shPath.Load(); cached != nil {
|
||||
return cached.(string), nil
|
||||
}
|
||||
|
||||
name := "sh"
|
||||
if bash {
|
||||
name = "bash"
|
||||
}
|
||||
cmd := exec.Command("cygpath", "-w", "/usr/bin/"+name)
|
||||
bytes, err := cmd.Output()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
sh := strings.TrimSpace(string(bytes))
|
||||
shPath.Store(sh)
|
||||
return sh, nil
|
||||
}
|
||||
|
||||
func mkfifo(path string, mode uint32) (string, error) {
|
||||
m := strconv.FormatUint(uint64(mode), 8)
|
||||
sh, err := sh(false)
|
||||
if err != nil {
|
||||
return path, err
|
||||
}
|
||||
cmd := exec.Command(sh, "-c", fmt.Sprintf(`command mkfifo -m %s %q`, m, path))
|
||||
if err := cmd.Run(); err != nil {
|
||||
return path, err
|
||||
}
|
||||
return path + ".lnk", nil
|
||||
}
|
||||
|
||||
func withOutputPipe(output string, task func(io.ReadCloser)) error {
|
||||
sh, err := sh(false)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
cmd := exec.Command(sh, "-c", fmt.Sprintf(`command cat %q`, output))
|
||||
outputFile, err := cmd.StdoutPipe()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err := cmd.Start(); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
task(outputFile)
|
||||
cmd.Wait()
|
||||
return nil
|
||||
}
|
||||
|
||||
func withInputPipe(input string, task func(io.WriteCloser)) error {
|
||||
sh, err := sh(false)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
cmd := exec.Command(sh, "-c", fmt.Sprintf(`command cat - > %q`, input))
|
||||
inputFile, err := cmd.StdinPipe()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err := cmd.Start(); err != nil {
|
||||
return err
|
||||
}
|
||||
task(inputFile)
|
||||
inputFile.Close()
|
||||
cmd.Wait()
|
||||
return nil
|
||||
}
|
||||
+64
-276
@@ -1,51 +1,37 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"bufio"
|
||||
"context"
|
||||
"io"
|
||||
"io/fs"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"slices"
|
||||
"strings"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
"time"
|
||||
|
||||
"github.com/charlievieth/fastwalk"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
"github.com/saracen/walker"
|
||||
)
|
||||
|
||||
// Reader reads from command or standard input
|
||||
type Reader struct {
|
||||
pusher func([]byte) bool
|
||||
executor *util.Executor
|
||||
eventBox *util.EventBox
|
||||
delimNil bool
|
||||
event int32
|
||||
finChan chan bool
|
||||
mutex sync.Mutex
|
||||
killed bool
|
||||
termFunc func()
|
||||
exec *exec.Cmd
|
||||
command *string
|
||||
killed bool
|
||||
wait bool
|
||||
}
|
||||
|
||||
// NewReader returns new Reader object
|
||||
func NewReader(pusher func([]byte) bool, eventBox *util.EventBox, executor *util.Executor, delimNil bool, wait bool) *Reader {
|
||||
return &Reader{
|
||||
pusher,
|
||||
executor,
|
||||
eventBox,
|
||||
delimNil,
|
||||
int32(EvtReady),
|
||||
make(chan bool, 1),
|
||||
sync.Mutex{},
|
||||
false,
|
||||
func() { os.Stdin.Close() },
|
||||
nil,
|
||||
wait}
|
||||
func NewReader(pusher func([]byte) bool, eventBox *util.EventBox, delimNil bool, wait bool) *Reader {
|
||||
return &Reader{pusher, eventBox, delimNil, int32(EvtReady), make(chan bool, 1), sync.Mutex{}, nil, nil, false, wait}
|
||||
}
|
||||
|
||||
func (r *Reader) startEventPoller() {
|
||||
@@ -90,151 +76,73 @@ func (r *Reader) fin(success bool) {
|
||||
|
||||
func (r *Reader) terminate() {
|
||||
r.mutex.Lock()
|
||||
defer func() { r.mutex.Unlock() }()
|
||||
|
||||
r.killed = true
|
||||
if r.termFunc != nil {
|
||||
r.termFunc()
|
||||
r.termFunc = nil
|
||||
if r.exec != nil && r.exec.Process != nil {
|
||||
util.KillCommand(r.exec)
|
||||
} else if defaultCommand != "" {
|
||||
os.Stdin.Close()
|
||||
}
|
||||
r.mutex.Unlock()
|
||||
}
|
||||
|
||||
func (r *Reader) restart(command commandSpec, environ []string, readyChan chan bool) {
|
||||
func (r *Reader) restart(command string) {
|
||||
r.event = int32(EvtReady)
|
||||
r.startEventPoller()
|
||||
success := r.readFromCommand(command.command, environ, func() {
|
||||
readyChan <- true
|
||||
})
|
||||
success := r.readFromCommand(nil, command)
|
||||
r.fin(success)
|
||||
removeFiles(command.tempFiles)
|
||||
}
|
||||
|
||||
func (r *Reader) readChannel(inputChan chan string) bool {
|
||||
for {
|
||||
item, more := <-inputChan
|
||||
if !more {
|
||||
break
|
||||
}
|
||||
if r.pusher([]byte(item)) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// ReadSource reads data from the default command or from standard input
|
||||
func (r *Reader) ReadSource(inputChan chan string, roots []string, opts walkerOpts, ignores []string, initCmd string, initEnv []string, readyChan chan bool) {
|
||||
func (r *Reader) ReadSource() {
|
||||
r.startEventPoller()
|
||||
var success bool
|
||||
signalReady := func() {
|
||||
if readyChan != nil {
|
||||
readyChan <- true
|
||||
}
|
||||
}
|
||||
if inputChan != nil {
|
||||
signalReady()
|
||||
success = r.readChannel(inputChan)
|
||||
} else if len(initCmd) > 0 {
|
||||
success = r.readFromCommand(initCmd, initEnv, signalReady)
|
||||
} else if util.IsTty(os.Stdin) {
|
||||
if util.IsTty() {
|
||||
// The default command for *nix requires bash
|
||||
shell := "bash"
|
||||
cmd := os.Getenv("FZF_DEFAULT_COMMAND")
|
||||
if len(cmd) == 0 {
|
||||
signalReady()
|
||||
success = r.readFiles(roots, opts, ignores)
|
||||
if defaultCommand != "" {
|
||||
success = r.readFromCommand(&shell, defaultCommand)
|
||||
} else {
|
||||
success = r.readFiles()
|
||||
}
|
||||
} else {
|
||||
success = r.readFromCommand(cmd, initEnv, signalReady)
|
||||
success = r.readFromCommand(nil, cmd)
|
||||
}
|
||||
} else {
|
||||
signalReady()
|
||||
success = r.readFromStdin()
|
||||
}
|
||||
r.fin(success)
|
||||
}
|
||||
|
||||
func (r *Reader) feed(src io.Reader) {
|
||||
/*
|
||||
readerSlabSize, ae := strconv.Atoi(os.Getenv("SLAB_KB"))
|
||||
if ae != nil {
|
||||
readerSlabSize = 128 * 1024
|
||||
} else {
|
||||
readerSlabSize *= 1024
|
||||
}
|
||||
readerBufferSize, be := strconv.Atoi(os.Getenv("BUF_KB"))
|
||||
if be != nil {
|
||||
readerBufferSize = 64 * 1024
|
||||
} else {
|
||||
readerBufferSize *= 1024
|
||||
}
|
||||
*/
|
||||
|
||||
delim := byte('\n')
|
||||
trimCR := util.IsWindows()
|
||||
if r.delimNil {
|
||||
delim = '\000'
|
||||
trimCR = false
|
||||
}
|
||||
|
||||
slab := make([]byte, readerSlabSize)
|
||||
leftover := []byte{}
|
||||
var err error
|
||||
reader := bufio.NewReaderSize(src, readerBufferSize)
|
||||
for {
|
||||
n := 0
|
||||
scope := slab[:min(len(slab), readerBufferSize)]
|
||||
for range 100 {
|
||||
n, err = src.Read(scope)
|
||||
if n > 0 || err != nil {
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
// We're not making any progress after 100 tries. Stop.
|
||||
if n == 0 {
|
||||
break
|
||||
}
|
||||
|
||||
buf := slab[:n]
|
||||
slab = slab[n:]
|
||||
|
||||
for len(buf) > 0 {
|
||||
if i := bytes.IndexByte(buf, delim); i >= 0 {
|
||||
// Found the delimiter
|
||||
slice := buf[:i+1]
|
||||
buf = buf[i+1:]
|
||||
if trimCR && len(slice) >= 2 && slice[len(slice)-2] == byte('\r') {
|
||||
slice = slice[:len(slice)-2]
|
||||
// ReadBytes returns err != nil if and only if the returned data does not
|
||||
// end in delim.
|
||||
bytea, err := reader.ReadBytes(delim)
|
||||
byteaLen := len(bytea)
|
||||
if byteaLen > 0 {
|
||||
if err == nil {
|
||||
// get rid of carriage return if under Windows:
|
||||
if util.IsWindows() && byteaLen >= 2 && bytea[byteaLen-2] == byte('\r') {
|
||||
bytea = bytea[:byteaLen-2]
|
||||
} else {
|
||||
slice = slice[:len(slice)-1]
|
||||
bytea = bytea[:byteaLen-1]
|
||||
}
|
||||
if len(leftover) > 0 {
|
||||
slice = append(leftover, slice...)
|
||||
leftover = []byte{}
|
||||
}
|
||||
if (err == nil || len(slice) > 0) && r.pusher(slice) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
} else {
|
||||
// Could not find the delimiter in the buffer
|
||||
// NOTE: We can further optimize this by keeping track of the cursor
|
||||
// position in the slab so that a straddling item that doesn't go
|
||||
// beyond the boundary of a slab doesn't need to be copied to
|
||||
// another buffer. However, the performance gain is negligible in
|
||||
// practice (< 0.1%) and is not
|
||||
// worth the added complexity.
|
||||
leftover = append(leftover, buf...)
|
||||
break
|
||||
}
|
||||
if r.pusher(bytea) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
|
||||
if err == io.EOF {
|
||||
leftover = append(leftover, buf...)
|
||||
if err != nil {
|
||||
break
|
||||
}
|
||||
|
||||
if len(slab) == 0 {
|
||||
slab = make([]byte, readerSlabSize)
|
||||
}
|
||||
}
|
||||
if len(leftover) > 0 && r.pusher(leftover) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
|
||||
@@ -243,128 +151,16 @@ func (r *Reader) readFromStdin() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
func isSymlinkToDir(path string, de os.DirEntry) bool {
|
||||
if de.Type()&fs.ModeSymlink == 0 {
|
||||
return false
|
||||
}
|
||||
if s, err := os.Stat(path); err == nil {
|
||||
return s.IsDir()
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func trimPath(path string) string {
|
||||
bytes := stringBytes(path)
|
||||
|
||||
for len(bytes) > 1 && bytes[0] == '.' && (bytes[1] == '/' || bytes[1] == '\\') {
|
||||
bytes = bytes[2:]
|
||||
}
|
||||
|
||||
if len(bytes) == 0 {
|
||||
return "."
|
||||
}
|
||||
|
||||
return byteString(bytes)
|
||||
}
|
||||
|
||||
func (r *Reader) readFiles(roots []string, opts walkerOpts, ignores []string) bool {
|
||||
conf := fastwalk.Config{
|
||||
Follow: opts.follow,
|
||||
// Use forward slashes when running a Windows binary under WSL or MSYS
|
||||
ToSlash: fastwalk.DefaultToSlash(),
|
||||
Sort: fastwalk.SortFilesFirst,
|
||||
}
|
||||
|
||||
// When following symlinks, precompute the absolute real paths of walker
|
||||
// roots so we can skip symlinks that point to an ancestor. fastwalk's
|
||||
// built-in loop detection (shouldTraverse) catches loops on the second
|
||||
// pass, but a single pass through a symlink like z: -> / already
|
||||
// traverses the entire root filesystem, causing severe resource
|
||||
// exhaustion. Skipping ancestor symlinks prevents this entirely.
|
||||
var absRoots []string
|
||||
if opts.follow {
|
||||
for _, root := range roots {
|
||||
if real, err := filepath.EvalSymlinks(root); err == nil {
|
||||
if abs, err := filepath.Abs(real); err == nil {
|
||||
absRoots = append(absRoots, filepath.Clean(abs))
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
ignoresBase := []string{}
|
||||
ignoresFull := []string{}
|
||||
ignoresSuffix := []string{}
|
||||
sep := string(os.PathSeparator)
|
||||
if _, ok := os.LookupEnv("MSYSTEM"); ok {
|
||||
sep = "/"
|
||||
}
|
||||
for _, ignore := range ignores {
|
||||
if strings.ContainsRune(ignore, os.PathSeparator) {
|
||||
if strings.HasPrefix(ignore, sep) {
|
||||
ignoresSuffix = append(ignoresSuffix, ignore)
|
||||
} else {
|
||||
// 'foo/bar' should match
|
||||
// * 'foo/bar'
|
||||
// * 'baz/foo/bar'
|
||||
// * but NOT 'bazfoo/bar'
|
||||
ignoresFull = append(ignoresFull, ignore)
|
||||
ignoresSuffix = append(ignoresSuffix, sep+ignore)
|
||||
}
|
||||
} else {
|
||||
ignoresBase = append(ignoresBase, ignore)
|
||||
}
|
||||
}
|
||||
fn := func(path string, de os.DirEntry, err error) error {
|
||||
if err != nil {
|
||||
return nil
|
||||
}
|
||||
path = trimPath(path)
|
||||
func (r *Reader) readFiles() bool {
|
||||
r.killed = false
|
||||
fn := func(path string, mode os.FileInfo) error {
|
||||
path = filepath.Clean(path)
|
||||
if path != "." {
|
||||
isDirSymlink := isSymlinkToDir(path, de)
|
||||
if isDirSymlink && !opts.follow {
|
||||
isDir := mode.Mode().IsDir()
|
||||
if isDir && filepath.Base(path)[0] == '.' {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
// Skip symlinks whose target is an ancestor of (or equal to)
|
||||
// any walker root. Following such symlinks would traverse a
|
||||
// superset of the tree we're already walking.
|
||||
if isDirSymlink && len(absRoots) > 0 {
|
||||
if target, err := filepath.EvalSymlinks(path); err == nil {
|
||||
if abs, err := filepath.Abs(target); err == nil {
|
||||
abs = filepath.Clean(abs)
|
||||
if abs == string(os.PathSeparator) {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
for _, absRoot := range absRoots {
|
||||
if absRoot == abs || strings.HasPrefix(absRoot, abs+string(os.PathSeparator)) {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
isDir := de.IsDir() || isDirSymlink
|
||||
if isDir {
|
||||
base := filepath.Base(path)
|
||||
if !opts.hidden && base[0] == '.' && base != ".." {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
if slices.Contains(ignoresBase, base) {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
if slices.Contains(ignoresFull, path) {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
for _, ignore := range ignoresSuffix {
|
||||
if strings.HasSuffix(path, ignore) {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
}
|
||||
if path != sep {
|
||||
path += sep
|
||||
}
|
||||
}
|
||||
if ((opts.file && !isDir) || (opts.dir && isDir)) && r.pusher(stringBytes(path)) {
|
||||
if !isDir && r.pusher([]byte(path)) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
@@ -375,39 +171,31 @@ func (r *Reader) readFiles(roots []string, opts walkerOpts, ignores []string) bo
|
||||
}
|
||||
return nil
|
||||
}
|
||||
noerr := true
|
||||
for _, root := range roots {
|
||||
noerr = noerr && (fastwalk.Walk(&conf, root, fn) == nil)
|
||||
}
|
||||
return noerr
|
||||
cb := walker.WithErrorCallback(func(pathname string, err error) error {
|
||||
return nil
|
||||
})
|
||||
return walker.Walk(".", fn, cb) == nil
|
||||
}
|
||||
|
||||
func (r *Reader) readFromCommand(command string, environ []string, signalReady func()) bool {
|
||||
func (r *Reader) readFromCommand(shell *string, command string) bool {
|
||||
r.mutex.Lock()
|
||||
|
||||
r.killed = false
|
||||
r.termFunc = nil
|
||||
r.command = &command
|
||||
exec := r.executor.ExecCommand(command, true)
|
||||
if environ != nil {
|
||||
exec.Env = environ
|
||||
if shell != nil {
|
||||
r.exec = util.ExecCommandWith(*shell, command, true)
|
||||
} else {
|
||||
r.exec = util.ExecCommand(command, true)
|
||||
}
|
||||
execOut, err := exec.StdoutPipe()
|
||||
if err != nil || exec.Start() != nil {
|
||||
signalReady()
|
||||
out, err := r.exec.StdoutPipe()
|
||||
if err != nil {
|
||||
r.mutex.Unlock()
|
||||
return false
|
||||
}
|
||||
|
||||
// Function to call to terminate the running command
|
||||
r.termFunc = func() {
|
||||
execOut.Close()
|
||||
util.KillCommand(exec)
|
||||
}
|
||||
|
||||
signalReady()
|
||||
err = r.exec.Start()
|
||||
r.mutex.Unlock()
|
||||
|
||||
r.feed(execOut)
|
||||
return exec.Wait() == nil
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
r.feed(out)
|
||||
return r.exec.Wait() == nil
|
||||
}
|
||||
|
||||
+5
-10
@@ -10,10 +10,9 @@ import (
|
||||
func TestReadFromCommand(t *testing.T) {
|
||||
strs := []string{}
|
||||
eb := util.NewEventBox()
|
||||
exec := util.NewExecutor("")
|
||||
reader := NewReader(
|
||||
func(s []byte) bool { strs = append(strs, string(s)); return true },
|
||||
eb, exec, false, true)
|
||||
eb, false, true)
|
||||
|
||||
reader.startEventPoller()
|
||||
|
||||
@@ -23,12 +22,8 @@ func TestReadFromCommand(t *testing.T) {
|
||||
}
|
||||
|
||||
// Normal command
|
||||
counter := 0
|
||||
ready := func() {
|
||||
counter++
|
||||
}
|
||||
reader.fin(reader.readFromCommand(`echo abc&&echo def`, nil, ready))
|
||||
if len(strs) != 2 || strs[0] != "abc" || strs[1] != "def" || counter != 1 {
|
||||
reader.fin(reader.readFromCommand(nil, `echo abc&&echo def`))
|
||||
if len(strs) != 2 || strs[0] != "abc" || strs[1] != "def" {
|
||||
t.Errorf("%s", strs)
|
||||
}
|
||||
|
||||
@@ -52,9 +47,9 @@ func TestReadFromCommand(t *testing.T) {
|
||||
reader.startEventPoller()
|
||||
|
||||
// Failing command
|
||||
reader.fin(reader.readFromCommand(`no-such-command`, nil, ready))
|
||||
reader.fin(reader.readFromCommand(nil, `no-such-command`))
|
||||
strs = []string{}
|
||||
if len(strs) > 0 || counter != 2 {
|
||||
if len(strs) > 0 {
|
||||
t.Errorf("%s", strs)
|
||||
}
|
||||
|
||||
|
||||
+56
-234
@@ -2,7 +2,6 @@ package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"slices"
|
||||
"sort"
|
||||
"unicode"
|
||||
|
||||
@@ -16,12 +15,6 @@ type Offset [2]int32
|
||||
type colorOffset struct {
|
||||
offset [2]int32
|
||||
color tui.ColorPair
|
||||
match bool
|
||||
url *url
|
||||
}
|
||||
|
||||
func (co colorOffset) IsFullBgMarker(at int32) bool {
|
||||
return at == co.offset[0] && at == co.offset[1] && co.color.Attr()&tui.FullBg > 0
|
||||
}
|
||||
|
||||
type Result struct {
|
||||
@@ -31,9 +24,11 @@ type Result struct {
|
||||
|
||||
func buildResult(item *Item, offsets []Offset, score int) Result {
|
||||
if len(offsets) > 1 {
|
||||
slices.SortFunc(offsets, compareOffsets)
|
||||
sort.Sort(ByOrder(offsets))
|
||||
}
|
||||
|
||||
result := Result{item: item}
|
||||
numChars := item.text.Length()
|
||||
minBegin := math.MaxUint16
|
||||
minEnd := math.MaxUint16
|
||||
maxEnd := 0
|
||||
@@ -41,63 +36,25 @@ func buildResult(item *Item, offsets []Offset, score int) Result {
|
||||
for _, offset := range offsets {
|
||||
b, e := int(offset[0]), int(offset[1])
|
||||
if b < e {
|
||||
minBegin = min(b, minBegin)
|
||||
minEnd = min(e, minEnd)
|
||||
maxEnd = max(e, maxEnd)
|
||||
minBegin = util.Min(b, minBegin)
|
||||
minEnd = util.Min(e, minEnd)
|
||||
maxEnd = util.Max(e, maxEnd)
|
||||
validOffsetFound = true
|
||||
}
|
||||
}
|
||||
|
||||
return buildResultFromBounds(item, score, minBegin, minEnd, maxEnd, validOffsetFound)
|
||||
}
|
||||
|
||||
// buildResultFromBounds builds a Result from pre-computed offset bounds.
|
||||
func buildResultFromBounds(item *Item, score int, minBegin, minEnd, maxEnd int, validOffsetFound bool) Result {
|
||||
result := Result{item: item}
|
||||
numChars := item.text.Length()
|
||||
|
||||
for idx, criterion := range sortCriteria {
|
||||
val := uint16(math.MaxUint16)
|
||||
switch criterion {
|
||||
case byScore:
|
||||
// Higher is better
|
||||
val = math.MaxUint16 - util.AsUint16(score)
|
||||
case byChunk:
|
||||
if validOffsetFound {
|
||||
b := minBegin
|
||||
e := maxEnd
|
||||
for ; b >= 1; b-- {
|
||||
if unicode.IsSpace(item.text.Get(b - 1)) {
|
||||
break
|
||||
}
|
||||
}
|
||||
for ; e < numChars; e++ {
|
||||
if unicode.IsSpace(item.text.Get(e)) {
|
||||
break
|
||||
}
|
||||
}
|
||||
val = util.AsUint16(e - b)
|
||||
}
|
||||
case byLength:
|
||||
val = item.TrimLength()
|
||||
case byPathname:
|
||||
if validOffsetFound {
|
||||
lastDelim := -1
|
||||
s := item.text.ToString()
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
if s[i] == '/' || s[i] == '\\' {
|
||||
lastDelim = i
|
||||
break
|
||||
}
|
||||
}
|
||||
if lastDelim <= minBegin {
|
||||
val = util.AsUint16(minBegin - lastDelim)
|
||||
}
|
||||
}
|
||||
case byBegin, byEnd:
|
||||
if validOffsetFound {
|
||||
whitePrefixLen := 0
|
||||
for idx := range numChars {
|
||||
for idx := 0; idx < numChars; idx++ {
|
||||
r := item.text.Get(idx)
|
||||
whitePrefixLen = idx
|
||||
if idx == minBegin || !unicode.IsSpace(r) {
|
||||
@@ -107,7 +64,7 @@ func buildResultFromBounds(item *Item, score int, minBegin, minEnd, maxEnd int,
|
||||
if criterion == byBegin {
|
||||
val = util.AsUint16(minEnd - whitePrefixLen)
|
||||
} else {
|
||||
val = util.AsUint16(math.MaxUint16 - math.MaxUint16*(maxEnd-whitePrefixLen)/(int(item.TrimLength())+1))
|
||||
val = util.AsUint16(math.MaxUint16 - math.MaxUint16*(maxEnd-whitePrefixLen)/int(item.TrimLength()))
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -129,21 +86,21 @@ func minRank() Result {
|
||||
return Result{item: &minItem, points: [4]uint16{math.MaxUint16, 0, 0, 0}}
|
||||
}
|
||||
|
||||
func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, theme *tui.ColorTheme, colBase tui.ColorPair, colMatch tui.ColorPair, attrNth tui.Attr, nthOverlay tui.Attr, hidden bool) []colorOffset {
|
||||
func (result *Result) colorOffsets(matchOffsets []Offset, theme *tui.ColorTheme, colBase tui.ColorPair, colMatch tui.ColorPair, current bool) []colorOffset {
|
||||
itemColors := result.item.Colors()
|
||||
|
||||
// No ANSI codes
|
||||
if len(itemColors) == 0 && len(nthOffsets) == 0 {
|
||||
offsets := make([]colorOffset, len(matchOffsets))
|
||||
for i, off := range matchOffsets {
|
||||
offsets[i] = colorOffset{offset: [2]int32{off[0], off[1]}, color: colMatch, match: true}
|
||||
if len(itemColors) == 0 {
|
||||
var offsets []colorOffset
|
||||
for _, off := range matchOffsets {
|
||||
offsets = append(offsets, colorOffset{offset: [2]int32{off[0], off[1]}, color: colMatch})
|
||||
}
|
||||
return offsets
|
||||
}
|
||||
|
||||
// Find max column
|
||||
var maxCol int32
|
||||
for _, off := range append(matchOffsets, nthOffsets...) {
|
||||
for _, off := range matchOffsets {
|
||||
if off[1] > maxCol {
|
||||
maxCol = off[1]
|
||||
}
|
||||
@@ -154,92 +111,55 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
||||
}
|
||||
}
|
||||
|
||||
type cellInfo struct {
|
||||
index int
|
||||
color bool
|
||||
match bool
|
||||
nth bool
|
||||
fbg tui.Color
|
||||
}
|
||||
|
||||
cols := make([]cellInfo, maxCol+1)
|
||||
for idx := range cols {
|
||||
cols[idx].fbg = -1
|
||||
}
|
||||
cols := make([]int, maxCol)
|
||||
for colorIndex, ansi := range itemColors {
|
||||
if ansi.offset[0] == ansi.offset[1] && ansi.color.attr&tui.FullBg > 0 {
|
||||
cols[ansi.offset[0]].fbg = ansi.color.lbg
|
||||
} else {
|
||||
for i := ansi.offset[0]; i < ansi.offset[1]; i++ {
|
||||
cols[i] = cellInfo{colorIndex, true, false, false, cols[i].fbg}
|
||||
}
|
||||
for i := ansi.offset[0]; i < ansi.offset[1]; i++ {
|
||||
cols[i] = colorIndex + 1 // 1-based index of itemColors
|
||||
}
|
||||
}
|
||||
|
||||
for _, off := range matchOffsets {
|
||||
for i := off[0]; i < off[1]; i++ {
|
||||
cols[i].match = true
|
||||
// Negative of 1-based index of itemColors
|
||||
// - The extra -1 means highlighted
|
||||
cols[i] = cols[i]*-1 - 1
|
||||
}
|
||||
}
|
||||
|
||||
for _, off := range nthOffsets {
|
||||
for i := off[0]; i < off[1]; i++ {
|
||||
cols[i].nth = true
|
||||
}
|
||||
}
|
||||
|
||||
// slices.SortFunc(offsets, compareOffsets)
|
||||
// sort.Sort(ByOrder(offsets))
|
||||
|
||||
// Merge offsets
|
||||
// ------------ ---- -- ----
|
||||
// ++++++++ ++++++++++
|
||||
// --++++++++-- --++++++++++---
|
||||
curr := cellInfo{0, false, false, false, -1}
|
||||
curr := 0
|
||||
start := 0
|
||||
ansiToColorPair := func(ansi ansiOffset, base tui.ColorPair) tui.ColorPair {
|
||||
if !theme.Colored {
|
||||
return tui.NewColorPair(-1, -1, ansi.color.attr).MergeAttr(base)
|
||||
}
|
||||
// fd --color always | fzf --ansi --delimiter / --nth -1 --color fg:dim:strip,nth:regular
|
||||
if base.ShouldStripColors() {
|
||||
return base
|
||||
}
|
||||
fg := ansi.color.fg
|
||||
bg := ansi.color.bg
|
||||
if fg == -1 {
|
||||
fg = colBase.Fg()
|
||||
if current {
|
||||
fg = theme.Current.Color
|
||||
} else {
|
||||
fg = theme.Fg.Color
|
||||
}
|
||||
}
|
||||
if bg == -1 {
|
||||
bg = colBase.Bg()
|
||||
if current {
|
||||
bg = theme.DarkBg.Color
|
||||
} else {
|
||||
bg = theme.Bg.Color
|
||||
}
|
||||
}
|
||||
return tui.NewColorPair(fg, bg, ansi.color.attr).WithUl(ansi.color.ul).MergeAttr(base)
|
||||
return tui.NewColorPair(fg, bg, ansi.color.attr).MergeAttr(base)
|
||||
}
|
||||
fgAttr := tui.ColNormal.Attr()
|
||||
nthAttrFinal := fgAttr.Merge(attrNth).Merge(nthOverlay)
|
||||
nthBase := colBase.WithNewAttr(nthAttrFinal)
|
||||
|
||||
var colors []colorOffset
|
||||
add := func(idx int) {
|
||||
if curr.fbg >= 0 {
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(start)},
|
||||
color: tui.NewColorPair(-1, curr.fbg, tui.FullBg),
|
||||
match: false,
|
||||
url: nil})
|
||||
}
|
||||
if (curr.color || curr.nth || curr.match) && idx > start {
|
||||
if curr.match {
|
||||
var color tui.ColorPair
|
||||
if curr.nth {
|
||||
color = nthBase.Merge(colMatch)
|
||||
} else {
|
||||
color = colBase.Merge(colMatch)
|
||||
}
|
||||
var url *url
|
||||
if curr.color {
|
||||
ansi := itemColors[curr.index]
|
||||
url = ansi.color.url
|
||||
origColor := ansiToColorPair(ansi, colMatch)
|
||||
if curr != 0 && idx > start {
|
||||
if curr < 0 {
|
||||
color := colMatch
|
||||
if curr < -1 && theme.Colored {
|
||||
origColor := ansiToColorPair(itemColors[-curr-2], colMatch)
|
||||
// hl or hl+ only sets the foreground color, so colMatch is the
|
||||
// combination of either [hl and bg] or [hl+ and bg+].
|
||||
//
|
||||
@@ -250,40 +170,17 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
||||
// echo -e "\x1b[42mfoo\x1b[mbar" | fzf --ansi --color bg+:1,hl+:-1:underline
|
||||
if color.Fg().IsDefault() && origColor.HasBg() {
|
||||
color = origColor
|
||||
if curr.nth {
|
||||
color = color.WithAttr((attrNth &^ tui.AttrRegular).Merge(nthOverlay))
|
||||
}
|
||||
} else {
|
||||
color = origColor.MergeNonDefault(color)
|
||||
}
|
||||
}
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(idx)}, color: color, match: true, url: url})
|
||||
} else if curr.color {
|
||||
ansi := itemColors[curr.index]
|
||||
base := colBase
|
||||
if curr.nth {
|
||||
base = nthBase
|
||||
}
|
||||
if hidden {
|
||||
base = base.WithFg(theme.Nomatch)
|
||||
}
|
||||
color := ansiToColorPair(ansi, base)
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(idx)},
|
||||
color: color,
|
||||
match: false,
|
||||
url: ansi.color.url})
|
||||
offset: [2]int32{int32(start), int32(idx)}, color: color})
|
||||
} else {
|
||||
color := nthBase
|
||||
if hidden {
|
||||
color = color.WithFg(theme.Nomatch)
|
||||
}
|
||||
ansi := itemColors[curr-1]
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(idx)},
|
||||
color: color,
|
||||
match: false,
|
||||
url: nil})
|
||||
color: ansiToColorPair(ansi, colBase)})
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -298,20 +195,21 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
||||
return colors
|
||||
}
|
||||
|
||||
func compareOffsets(a, b Offset) int {
|
||||
if a[0] < b[0] {
|
||||
return -1
|
||||
}
|
||||
if a[0] > b[0] {
|
||||
return 1
|
||||
}
|
||||
if a[1] < b[1] {
|
||||
return -1
|
||||
}
|
||||
if a[1] > b[1] {
|
||||
return 1
|
||||
}
|
||||
return 0
|
||||
// ByOrder is for sorting substring offsets
|
||||
type ByOrder []Offset
|
||||
|
||||
func (a ByOrder) Len() int {
|
||||
return len(a)
|
||||
}
|
||||
|
||||
func (a ByOrder) Swap(i, j int) {
|
||||
a[i], a[j] = a[j], a[i]
|
||||
}
|
||||
|
||||
func (a ByOrder) Less(i, j int) bool {
|
||||
ioff := a[i]
|
||||
joff := a[j]
|
||||
return (ioff[0] < joff[0]) || (ioff[0] == joff[0]) && (ioff[1] <= joff[1])
|
||||
}
|
||||
|
||||
// ByRelevance is for sorting Items
|
||||
@@ -343,79 +241,3 @@ func (a ByRelevanceTac) Swap(i, j int) {
|
||||
func (a ByRelevanceTac) Less(i, j int) bool {
|
||||
return compareRanks(a[i], a[j], true)
|
||||
}
|
||||
|
||||
// radixSortResults sorts Results by their points key using LSD radix sort.
|
||||
// O(n) time complexity vs O(n log n) for comparison sort.
|
||||
// The sort is stable, so equal-key items maintain original (item-index) order.
|
||||
// For tac mode, runs of equal keys are reversed after sorting.
|
||||
func radixSortResults(a []Result, tac bool, scratch []Result) []Result {
|
||||
n := len(a)
|
||||
if n < 128 {
|
||||
if tac {
|
||||
sort.Sort(ByRelevanceTac(a))
|
||||
} else {
|
||||
sort.Sort(ByRelevance(a))
|
||||
}
|
||||
return scratch[:0]
|
||||
}
|
||||
|
||||
if cap(scratch) < n {
|
||||
scratch = make([]Result, n)
|
||||
}
|
||||
buf := scratch[:n]
|
||||
src, dst := a, buf
|
||||
scattered := 0
|
||||
|
||||
for pass := range 8 {
|
||||
shift := uint(pass) * 8
|
||||
|
||||
var count [256]int
|
||||
for i := range src {
|
||||
count[byte(sortKey(&src[i])>>shift)]++
|
||||
}
|
||||
|
||||
// Skip if all items have the same byte value at this position
|
||||
if count[byte(sortKey(&src[0])>>shift)] == n {
|
||||
continue
|
||||
}
|
||||
|
||||
var offset [256]int
|
||||
for i := 1; i < 256; i++ {
|
||||
offset[i] = offset[i-1] + count[i-1]
|
||||
}
|
||||
|
||||
for i := range src {
|
||||
b := byte(sortKey(&src[i]) >> shift)
|
||||
dst[offset[b]] = src[i]
|
||||
offset[b]++
|
||||
}
|
||||
|
||||
src, dst = dst, src
|
||||
scattered++
|
||||
}
|
||||
|
||||
// If odd number of scatters, data is in buf, copy back to a
|
||||
if scattered%2 == 1 {
|
||||
copy(a, src)
|
||||
}
|
||||
|
||||
// Handle tac: reverse runs of equal keys so equal-key items
|
||||
// are in reverse item-index order
|
||||
if tac {
|
||||
i := 0
|
||||
for i < n {
|
||||
ki := sortKey(&a[i])
|
||||
j := i + 1
|
||||
for j < n && sortKey(&a[j]) == ki {
|
||||
j++
|
||||
}
|
||||
if j-i > 1 {
|
||||
for l, r := i, j-1; l < r; l, r = l+1, r-1 {
|
||||
a[l], a[r] = a[r], a[l]
|
||||
}
|
||||
}
|
||||
i = j
|
||||
}
|
||||
}
|
||||
return scratch
|
||||
}
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
//go:build !386 && !amd64 && !arm64
|
||||
//go:build !386 && !amd64
|
||||
|
||||
package fzf
|
||||
|
||||
@@ -14,7 +14,3 @@ func compareRanks(irank Result, jrank Result, tac bool) bool {
|
||||
}
|
||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||
}
|
||||
|
||||
func sortKey(r *Result) uint64 {
|
||||
return uint64(r.points[0]) | uint64(r.points[1])<<16 | uint64(r.points[2])<<32 | uint64(r.points[3])<<48
|
||||
}
|
||||
|
||||
+16
-133
@@ -2,8 +2,6 @@ package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"math/rand"
|
||||
"slices"
|
||||
"sort"
|
||||
"testing"
|
||||
|
||||
@@ -20,7 +18,7 @@ func TestOffsetSort(t *testing.T) {
|
||||
offsets := []Offset{
|
||||
{3, 5}, {2, 7},
|
||||
{1, 3}, {2, 9}}
|
||||
slices.SortFunc(offsets, compareOffsets)
|
||||
sort.Sort(ByOrder(offsets))
|
||||
|
||||
if offsets[0][0] != 1 || offsets[0][1] != 3 ||
|
||||
offsets[1][0] != 2 || offsets[1][1] != 7 ||
|
||||
@@ -56,9 +54,9 @@ func TestResultRank(t *testing.T) {
|
||||
// FIXME global
|
||||
sortCriteria = []criterion{byScore, byLength}
|
||||
|
||||
str := []rune("foo")
|
||||
strs := [][]rune{[]rune("foo"), []rune("foobar"), []rune("bar"), []rune("baz")}
|
||||
item1 := buildResult(
|
||||
withIndex(&Item{text: util.RunesToChars(str)}, 1), []Offset{}, 2)
|
||||
withIndex(&Item{text: util.RunesToChars(strs[0])}, 1), []Offset{}, 2)
|
||||
if item1.points[3] != math.MaxUint16-2 || // Bonus
|
||||
item1.points[2] != 3 || // Length
|
||||
item1.points[1] != 0 || // Unused
|
||||
@@ -67,7 +65,7 @@ func TestResultRank(t *testing.T) {
|
||||
t.Error(item1)
|
||||
}
|
||||
// Only differ in index
|
||||
item2 := buildResult(&Item{text: util.RunesToChars(str)}, []Offset{}, 2)
|
||||
item2 := buildResult(&Item{text: util.RunesToChars(strs[0])}, []Offset{}, 2)
|
||||
|
||||
items := []Result{item1, item2}
|
||||
sort.Sort(ByRelevance(items))
|
||||
@@ -100,40 +98,23 @@ func TestResultRank(t *testing.T) {
|
||||
}
|
||||
}
|
||||
|
||||
func TestChunkTiebreak(t *testing.T) {
|
||||
// FIXME global
|
||||
sortCriteria = []criterion{byScore, byChunk}
|
||||
|
||||
score := 100
|
||||
test := func(input string, offset Offset, chunk string) {
|
||||
item := buildResult(withIndex(&Item{text: util.RunesToChars([]rune(input))}, 1), []Offset{offset}, score)
|
||||
if !(item.points[3] == math.MaxUint16-uint16(score) && item.points[2] == uint16(len(chunk))) {
|
||||
t.Error(item.points)
|
||||
}
|
||||
}
|
||||
test("hello foobar goodbye", Offset{8, 9}, "foobar")
|
||||
test("hello foobar goodbye", Offset{7, 18}, "foobar goodbye")
|
||||
test("hello foobar goodbye", Offset{0, 1}, "hello")
|
||||
test("hello foobar goodbye", Offset{5, 7}, "hello foobar") // TBD
|
||||
}
|
||||
|
||||
func TestColorOffset(t *testing.T) {
|
||||
// ------------ 20 ---- -- ----
|
||||
// ++++++++ ++++++++++
|
||||
// --++++++++-- --++++++++++---
|
||||
|
||||
offsets := []Offset{{5, 15}, {10, 12}, {25, 35}}
|
||||
offsets := []Offset{{5, 15}, {25, 35}}
|
||||
item := Result{
|
||||
item: &Item{
|
||||
colors: &[]ansiOffset{
|
||||
{[2]int32{0, 20}, ansiState{1, 5, -1, 0, -1, nil}},
|
||||
{[2]int32{22, 27}, ansiState{2, 6, -1, tui.Bold, -1, nil}},
|
||||
{[2]int32{30, 32}, ansiState{3, 7, -1, 0, -1, nil}},
|
||||
{[2]int32{33, 40}, ansiState{4, 8, -1, tui.Bold, -1, nil}}}}}
|
||||
{[2]int32{0, 20}, ansiState{1, 5, 0, -1}},
|
||||
{[2]int32{22, 27}, ansiState{2, 6, tui.Bold, -1}},
|
||||
{[2]int32{30, 32}, ansiState{3, 7, 0, -1}},
|
||||
{[2]int32{33, 40}, ansiState{4, 8, tui.Bold, -1}}}}}
|
||||
|
||||
colBase := tui.NewColorPair(89, 189, tui.AttrUndefined)
|
||||
colMatch := tui.NewColorPair(99, 199, tui.AttrUndefined)
|
||||
colors := item.colorOffsets(offsets, nil, tui.Dark256, colBase, colMatch, tui.AttrUndefined, 0, false)
|
||||
colors := item.colorOffsets(offsets, tui.Dark256, colBase, colMatch, true)
|
||||
assert := func(idx int, b int32, e int32, c tui.ColorPair) {
|
||||
o := colors[idx]
|
||||
if o.offset[0] != b || o.offset[1] != e || o.color != c {
|
||||
@@ -157,40 +138,12 @@ func TestColorOffset(t *testing.T) {
|
||||
|
||||
colRegular := tui.NewColorPair(-1, -1, tui.AttrUndefined)
|
||||
colUnderline := tui.NewColorPair(-1, -1, tui.Underline)
|
||||
colors = item.colorOffsets(offsets, tui.Dark256, colRegular, colUnderline, true)
|
||||
|
||||
nthOffsets := []Offset{{37, 39}, {42, 45}}
|
||||
for _, attr := range []tui.Attr{tui.AttrRegular, tui.StrikeThrough} {
|
||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, attr, 0, false)
|
||||
|
||||
// [{[0 5] {1 5 0}} {[5 15] {1 5 8}} {[15 20] {1 5 0}}
|
||||
// {[22 25] {2 6 1}} {[25 27] {2 6 9}} {[27 30] {-1 -1 8}}
|
||||
// {[30 32] {3 7 8}} {[32 33] {-1 -1 8}} {[33 35] {4 8 9}}
|
||||
// {[35 37] {4 8 1}} {[37 39] {4 8 x|1}} {[39 40] {4 8 x|1}}]
|
||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(3, 22, 25, tui.NewColorPair(2, 6, tui.Bold))
|
||||
assert(4, 25, 27, tui.NewColorPair(2, 6, tui.Bold|tui.Underline))
|
||||
assert(5, 27, 30, colUnderline)
|
||||
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
||||
assert(7, 32, 33, colUnderline)
|
||||
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
||||
assert(9, 35, 37, tui.NewColorPair(4, 8, tui.Bold))
|
||||
expected := tui.Bold | attr
|
||||
if attr == tui.AttrRegular {
|
||||
expected = tui.Bold
|
||||
}
|
||||
assert(10, 37, 39, tui.NewColorPair(4, 8, expected))
|
||||
assert(11, 39, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||
}
|
||||
|
||||
// Test nthOverlay: simulates nth:regular with current-fg:underline
|
||||
// The overlay (underline) should survive even though nth:regular clears attrs.
|
||||
// Precedence: fg < nth < current-fg
|
||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, tui.AttrRegular, tui.Underline, false)
|
||||
|
||||
// nth regions should have Underline (from overlay), not cleared by AttrRegular
|
||||
// Non-nth regions keep colBase attrs (AttrUndefined)
|
||||
// [{[0 5] {1 5 0}} {[5 15] {1 5 8}} {[15 20] {1 5 0}}
|
||||
// {[22 25] {2 6 1}} {[25 27] {2 6 9}} {[27 30] {-1 -1 8}}
|
||||
// {[30 32] {3 7 8}} {[32 33] {-1 -1 8}} {[33 35] {4 8 9}}
|
||||
// {[35 40] {4 8 1}}]
|
||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
@@ -200,75 +153,5 @@ func TestColorOffset(t *testing.T) {
|
||||
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
||||
assert(7, 32, 33, colUnderline)
|
||||
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
||||
assert(9, 35, 37, tui.NewColorPair(4, 8, tui.Bold))
|
||||
// nth region within ANSI bold: AttrRegular clears, overlay adds Underline back
|
||||
assert(10, 37, 39, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
||||
assert(11, 39, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||
|
||||
// Test nthOverlay with additive attrs: nth:strikethrough with selected-fg:bold
|
||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, tui.StrikeThrough, tui.Bold, false)
|
||||
|
||||
// Non-nth entries unchanged from overlay=0 case
|
||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(5, 27, 30, colUnderline) // match only, no nth
|
||||
assert(7, 32, 33, colUnderline) // match only, no nth
|
||||
// nth region within ANSI bold: StrikeThrough|Bold merged with ANSI Bold
|
||||
assert(10, 37, 39, tui.NewColorPair(4, 8, tui.Bold|tui.StrikeThrough))
|
||||
}
|
||||
|
||||
func TestRadixSortResults(t *testing.T) {
|
||||
sortCriteria = []criterion{byScore, byLength}
|
||||
|
||||
rng := rand.New(rand.NewSource(42))
|
||||
|
||||
for _, n := range []int{128, 256, 500, 1000} {
|
||||
for _, tac := range []bool{false, true} {
|
||||
// Build items with random points and indices
|
||||
items := make([]*Item, n)
|
||||
for i := range items {
|
||||
items[i] = &Item{text: util.Chars{Index: int32(i)}}
|
||||
}
|
||||
|
||||
results := make([]Result, n)
|
||||
for i := range results {
|
||||
results[i] = Result{
|
||||
item: items[i],
|
||||
points: [4]uint16{
|
||||
uint16(rng.Intn(256)),
|
||||
uint16(rng.Intn(256)),
|
||||
uint16(rng.Intn(256)),
|
||||
uint16(rng.Intn(256)),
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
// Make some duplicates to test stability
|
||||
for i := 0; i < n/4; i++ {
|
||||
j := rng.Intn(n)
|
||||
k := rng.Intn(n)
|
||||
results[j].points = results[k].points
|
||||
}
|
||||
|
||||
// Copy for reference sort
|
||||
expected := make([]Result, n)
|
||||
copy(expected, results)
|
||||
if tac {
|
||||
sort.Sort(ByRelevanceTac(expected))
|
||||
} else {
|
||||
sort.Sort(ByRelevance(expected))
|
||||
}
|
||||
|
||||
// Radix sort
|
||||
var scratch []Result
|
||||
scratch = radixSortResults(results, tac, scratch)
|
||||
|
||||
for i := range results {
|
||||
if results[i] != expected[i] {
|
||||
t.Errorf("n=%d tac=%v: mismatch at index %d: got item %d, want item %d",
|
||||
n, tac, i, results[i].item.Index(), expected[i].item.Index())
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
assert(9, 35, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||
}
|
||||
|
||||
+1
-5
@@ -1,4 +1,4 @@
|
||||
//go:build 386 || amd64 || arm64
|
||||
//go:build 386 || amd64
|
||||
|
||||
package fzf
|
||||
|
||||
@@ -14,7 +14,3 @@ func compareRanks(irank Result, jrank Result, tac bool) bool {
|
||||
}
|
||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||
}
|
||||
|
||||
func sortKey(r *Result) uint64 {
|
||||
return *(*uint64)(unsafe.Pointer(&r.points[0]))
|
||||
}
|
||||
|
||||
-277
@@ -1,277 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"crypto/subtle"
|
||||
"errors"
|
||||
"fmt"
|
||||
"net"
|
||||
"os"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"strings"
|
||||
"time"
|
||||
)
|
||||
|
||||
var getRegex *regexp.Regexp
|
||||
|
||||
func init() {
|
||||
getRegex = regexp.MustCompile(`^GET /(?:\?([a-z0-9=&]+))? HTTP`)
|
||||
}
|
||||
|
||||
type getParams struct {
|
||||
limit int
|
||||
offset int
|
||||
}
|
||||
|
||||
const (
|
||||
crlf = "\r\n"
|
||||
httpOk = "HTTP/1.1 200 OK" + crlf
|
||||
httpBadRequest = "HTTP/1.1 400 Bad Request" + crlf
|
||||
httpUnauthorized = "HTTP/1.1 401 Unauthorized" + crlf
|
||||
httpUnavailable = "HTTP/1.1 503 Service Unavailable" + crlf
|
||||
httpReadTimeout = 10 * time.Second
|
||||
channelTimeout = 2 * time.Second
|
||||
jsonContentType = "Content-Type: application/json" + crlf
|
||||
maxContentLength = 1024 * 1024
|
||||
)
|
||||
|
||||
type httpServer struct {
|
||||
apiKey []byte
|
||||
actionChannel chan []*action
|
||||
getHandler func(getParams) string
|
||||
}
|
||||
|
||||
type listenAddress struct {
|
||||
host string
|
||||
port int
|
||||
sock string
|
||||
}
|
||||
|
||||
func (addr listenAddress) IsLocal() bool {
|
||||
return addr.host == "localhost" || addr.host == "127.0.0.1" || len(addr.sock) > 0
|
||||
}
|
||||
|
||||
var defaultListenAddr = listenAddress{"localhost", 0, ""}
|
||||
|
||||
func parseListenAddress(address string) (listenAddress, error) {
|
||||
if strings.HasSuffix(address, ".sock") {
|
||||
return listenAddress{"", 0, address}, nil
|
||||
}
|
||||
|
||||
parts := strings.SplitN(address, ":", 3)
|
||||
if len(parts) == 1 {
|
||||
parts = []string{"localhost", parts[0]}
|
||||
}
|
||||
if len(parts) != 2 {
|
||||
return defaultListenAddr, fmt.Errorf("invalid listen address: %s", address)
|
||||
}
|
||||
portStr := parts[len(parts)-1]
|
||||
port, err := strconv.Atoi(portStr)
|
||||
if err != nil || port < 0 || port > 65535 {
|
||||
return defaultListenAddr, fmt.Errorf("invalid listen port: %s", portStr)
|
||||
}
|
||||
if len(parts[0]) == 0 {
|
||||
parts[0] = "localhost"
|
||||
}
|
||||
return listenAddress{parts[0], port, ""}, nil
|
||||
}
|
||||
|
||||
func startHttpServer(address listenAddress, actionChannel chan []*action, getHandler func(getParams) string) (net.Listener, int, error) {
|
||||
host := address.host
|
||||
port := address.port
|
||||
apiKey := os.Getenv("FZF_API_KEY")
|
||||
if !address.IsLocal() && len(apiKey) == 0 {
|
||||
return nil, port, errors.New("FZF_API_KEY is required to allow remote access")
|
||||
}
|
||||
|
||||
var listener net.Listener
|
||||
var err error
|
||||
if len(address.sock) > 0 {
|
||||
if _, err := os.Stat(address.sock); err == nil {
|
||||
// Check if the socket is already in use
|
||||
if conn, err := net.Dial("unix", address.sock); err == nil {
|
||||
conn.Close()
|
||||
return nil, 0, fmt.Errorf("socket already in use: %s", address.sock)
|
||||
}
|
||||
os.Remove(address.sock)
|
||||
}
|
||||
listener, err = net.Listen("unix", address.sock)
|
||||
if err != nil {
|
||||
return nil, 0, fmt.Errorf("failed to listen on %s", address.sock)
|
||||
}
|
||||
os.Chmod(address.sock, 0600)
|
||||
} else {
|
||||
addrStr := fmt.Sprintf("%s:%d", host, port)
|
||||
listener, err = net.Listen("tcp", addrStr)
|
||||
if err != nil {
|
||||
return nil, port, fmt.Errorf("failed to listen on %s", addrStr)
|
||||
}
|
||||
if port == 0 {
|
||||
addr := listener.Addr().String()
|
||||
parts := strings.Split(addr, ":")
|
||||
if len(parts) < 2 {
|
||||
return nil, port, fmt.Errorf("cannot extract port: %s", addr)
|
||||
}
|
||||
var err error
|
||||
port, err = strconv.Atoi(parts[len(parts)-1])
|
||||
if err != nil {
|
||||
return nil, port, err
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
go func() {
|
||||
server := httpServer{
|
||||
apiKey: []byte(apiKey),
|
||||
actionChannel: actionChannel,
|
||||
getHandler: getHandler,
|
||||
}
|
||||
for {
|
||||
conn, err := listener.Accept()
|
||||
if err != nil {
|
||||
if errors.Is(err, net.ErrClosed) {
|
||||
return
|
||||
}
|
||||
continue
|
||||
}
|
||||
conn.Write([]byte(server.handleHttpRequest(conn)))
|
||||
conn.Close()
|
||||
}
|
||||
}()
|
||||
|
||||
return listener, port, nil
|
||||
}
|
||||
|
||||
// Here we are writing a simplistic HTTP server without using net/http
|
||||
// package to reduce the size of the binary.
|
||||
//
|
||||
// * No --listen: 2.8MB
|
||||
// * --listen with net/http: 5.7MB
|
||||
// * --listen w/o net/http: 3.3MB
|
||||
func (server *httpServer) handleHttpRequest(conn net.Conn) string {
|
||||
contentLength := 0
|
||||
apiKey := ""
|
||||
var bodyBuilder strings.Builder
|
||||
answer := func(code string, message string) string {
|
||||
message += "\n"
|
||||
return code + fmt.Sprintf("Content-Length: %d%s", len(message), crlf+crlf+message)
|
||||
}
|
||||
unauthorized := func(message string) string {
|
||||
return answer(httpUnauthorized, message)
|
||||
}
|
||||
bad := func(message string) string {
|
||||
return answer(httpBadRequest, message)
|
||||
}
|
||||
good := func(message string) string {
|
||||
return answer(httpOk+jsonContentType, message)
|
||||
}
|
||||
conn.SetReadDeadline(time.Now().Add(httpReadTimeout))
|
||||
scanner := bufio.NewScanner(conn)
|
||||
scanner.Split(func(data []byte, atEOF bool) (int, []byte, error) {
|
||||
found := bytes.Index(data, []byte(crlf))
|
||||
if found >= 0 {
|
||||
token := data[:found+len(crlf)]
|
||||
return len(token), token, nil
|
||||
}
|
||||
if atEOF || bodyBuilder.Len()+len(data) >= contentLength {
|
||||
return 0, data, bufio.ErrFinalToken
|
||||
}
|
||||
return 0, nil, nil
|
||||
})
|
||||
|
||||
section := 0
|
||||
var getMatch []string
|
||||
Loop:
|
||||
for scanner.Scan() {
|
||||
text := scanner.Text()
|
||||
switch section {
|
||||
case 0: // Request line
|
||||
getMatch = getRegex.FindStringSubmatch(text)
|
||||
if len(getMatch) == 0 && !strings.HasPrefix(text, "POST / HTTP") {
|
||||
return bad("invalid request method")
|
||||
}
|
||||
section++
|
||||
case 1: // Request headers
|
||||
if text == crlf { // End of headers
|
||||
if len(getMatch) > 0 {
|
||||
break Loop
|
||||
}
|
||||
if contentLength == 0 {
|
||||
return bad("content-length header missing")
|
||||
}
|
||||
section++
|
||||
continue
|
||||
}
|
||||
pair := strings.SplitN(text, ":", 2)
|
||||
if len(pair) == 2 {
|
||||
switch strings.ToLower(pair[0]) {
|
||||
case "content-length":
|
||||
length, err := strconv.Atoi(strings.TrimSpace(pair[1]))
|
||||
if err != nil || length <= 0 || length > maxContentLength {
|
||||
return bad("invalid content length")
|
||||
}
|
||||
contentLength = length
|
||||
case "x-api-key":
|
||||
apiKey = strings.TrimSpace(pair[1])
|
||||
}
|
||||
}
|
||||
case 2: // Request body
|
||||
bodyBuilder.WriteString(text)
|
||||
}
|
||||
}
|
||||
|
||||
if len(server.apiKey) != 0 && subtle.ConstantTimeCompare([]byte(apiKey), server.apiKey) != 1 {
|
||||
return unauthorized("invalid api key")
|
||||
}
|
||||
|
||||
if len(getMatch) > 0 {
|
||||
response := server.getHandler(parseGetParams(getMatch[1]))
|
||||
if len(response) > 0 {
|
||||
return good(response)
|
||||
}
|
||||
return answer(httpUnavailable+jsonContentType, `{"error":"timeout"}`)
|
||||
}
|
||||
|
||||
body := bodyBuilder.String()
|
||||
if len(body) < contentLength {
|
||||
return bad("incomplete request")
|
||||
}
|
||||
body = body[:contentLength]
|
||||
|
||||
actions, err := parseSingleActionList(strings.Trim(string(body), "\r\n"))
|
||||
if err != nil {
|
||||
return bad(err.Error())
|
||||
}
|
||||
if len(actions) == 0 {
|
||||
return bad("no action specified")
|
||||
}
|
||||
|
||||
select {
|
||||
case server.actionChannel <- actions:
|
||||
case <-time.After(channelTimeout):
|
||||
return httpUnavailable + crlf
|
||||
}
|
||||
return httpOk + crlf
|
||||
}
|
||||
|
||||
func parseGetParams(query string) getParams {
|
||||
params := getParams{limit: 100, offset: 0}
|
||||
for _, pair := range strings.Split(query, "&") {
|
||||
parts := strings.SplitN(pair, "=", 2)
|
||||
if len(parts) == 2 {
|
||||
switch parts[0] {
|
||||
case "limit", "offset":
|
||||
if val, err := strconv.Atoi(parts[1]); err == nil {
|
||||
if parts[0] == "limit" {
|
||||
params.limit = val
|
||||
} else {
|
||||
params.offset = val
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return params
|
||||
}
|
||||
+989
-6417
File diff suppressed because it is too large
Load Diff
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user