mirror of
https://github.com/junegunn/fzf
synced 2026-06-16 11:03:18 +00:00
Compare commits
1 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
38040d43e4 |
@@ -1,20 +0,0 @@
|
|||||||
root = true
|
|
||||||
|
|
||||||
[*.{sh,bash,fish}]
|
|
||||||
indent_style = space
|
|
||||||
indent_size = 2
|
|
||||||
simplify = true
|
|
||||||
binary_next_line = false
|
|
||||||
switch_case_indent = true
|
|
||||||
space_redirects = true
|
|
||||||
function_next_line = false
|
|
||||||
|
|
||||||
# also bash scripts.
|
|
||||||
[{install,uninstall,bin/fzf-preview.sh,bin/fzf-tmux}]
|
|
||||||
indent_style = space
|
|
||||||
indent_size = 2
|
|
||||||
simplify = true
|
|
||||||
binary_next_line = false
|
|
||||||
switch_case_indent = true
|
|
||||||
space_redirects = true
|
|
||||||
function_next_line = false
|
|
||||||
@@ -1 +0,0 @@
|
|||||||
* @junegunn
|
|
||||||
@@ -1,17 +0,0 @@
|
|||||||
## Contribution Policy
|
|
||||||
|
|
||||||
We do not accept pull requests generated primarily by AI without genuine understanding or real-world usage context.
|
|
||||||
|
|
||||||
All contributions are expected to demonstrate:
|
|
||||||
- A clear understanding of the codebase
|
|
||||||
- Alignment with product direction
|
|
||||||
- Thoughtful reasoning behind changes
|
|
||||||
- Evidence of real-world usage or hands-on experience with the problem
|
|
||||||
|
|
||||||
If these expectations are not met, we would prefer to implement the changes ourselves rather than spend time reviewing low-effort submissions.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
## Acknowledgement
|
|
||||||
|
|
||||||
- [ ] I confirm that this PR meets the above expectations and reflects my own understanding and real-world context.
|
|
||||||
@@ -1,64 +0,0 @@
|
|||||||
go:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- src/**
|
|
||||||
- main.go
|
|
||||||
- go.mod
|
|
||||||
- go.sum
|
|
||||||
|
|
||||||
shell:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- shell/**
|
|
||||||
|
|
||||||
bash:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- shell/**/*.bash
|
|
||||||
|
|
||||||
zsh:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- shell/**/*.zsh
|
|
||||||
|
|
||||||
fish:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- shell/**/*.fish
|
|
||||||
|
|
||||||
vim:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- plugin/**
|
|
||||||
|
|
||||||
docs:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- '*.md'
|
|
||||||
- doc/**
|
|
||||||
- man/**
|
|
||||||
|
|
||||||
ci:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- .github/**
|
|
||||||
|
|
||||||
build:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- Makefile
|
|
||||||
- .goreleaser.yml
|
|
||||||
- Dockerfile
|
|
||||||
|
|
||||||
test:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- test/**
|
|
||||||
- src/**/*_test.go
|
|
||||||
|
|
||||||
install:
|
|
||||||
- changed-files:
|
|
||||||
- any-glob-to-any-file:
|
|
||||||
- install
|
|
||||||
- install.ps1
|
|
||||||
- uninstall
|
|
||||||
@@ -27,18 +27,18 @@ jobs:
|
|||||||
|
|
||||||
steps:
|
steps:
|
||||||
- name: Checkout repository
|
- name: Checkout repository
|
||||||
uses: actions/checkout@v5
|
uses: actions/checkout@v4
|
||||||
with:
|
with:
|
||||||
fetch-depth: 0
|
fetch-depth: 0
|
||||||
|
|
||||||
# Initializes the CodeQL tools for scanning.
|
# Initializes the CodeQL tools for scanning.
|
||||||
- name: Initialize CodeQL
|
- name: Initialize CodeQL
|
||||||
uses: github/codeql-action/init@v4
|
uses: github/codeql-action/init@v3
|
||||||
with:
|
with:
|
||||||
languages: ${{ matrix.language }}
|
languages: ${{ matrix.language }}
|
||||||
|
|
||||||
- name: Autobuild
|
- name: Autobuild
|
||||||
uses: github/codeql-action/autobuild@v4
|
uses: github/codeql-action/autobuild@v3
|
||||||
|
|
||||||
- name: Perform CodeQL Analysis
|
- name: Perform CodeQL Analysis
|
||||||
uses: github/codeql-action/analyze@v4
|
uses: github/codeql-action/analyze@v3
|
||||||
|
|||||||
@@ -9,6 +9,6 @@ jobs:
|
|||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
- name: 'Checkout Repository'
|
- name: 'Checkout Repository'
|
||||||
uses: actions/checkout@v5
|
uses: actions/checkout@v4
|
||||||
- name: 'Dependency Review'
|
- name: 'Dependency Review'
|
||||||
uses: actions/dependency-review-action@v5
|
uses: actions/dependency-review-action@v4
|
||||||
|
|||||||
@@ -1,17 +0,0 @@
|
|||||||
name: Label PRs
|
|
||||||
|
|
||||||
on:
|
|
||||||
pull_request_target:
|
|
||||||
types: [opened, synchronize, reopened]
|
|
||||||
|
|
||||||
permissions:
|
|
||||||
contents: read
|
|
||||||
pull-requests: write
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
label:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/labeler@v6
|
|
||||||
with:
|
|
||||||
configuration-path: .github/labeler.yml
|
|
||||||
+12
-22
@@ -1,11 +1,11 @@
|
|||||||
---
|
---
|
||||||
name: build
|
name: Test fzf on Linux
|
||||||
|
|
||||||
on:
|
on:
|
||||||
push:
|
push:
|
||||||
branches: [ master, devel ]
|
branches: [ master, devel ]
|
||||||
pull_request:
|
pull_request:
|
||||||
branches: [ master, devel ]
|
branches: [ master ]
|
||||||
workflow_dispatch:
|
workflow_dispatch:
|
||||||
|
|
||||||
permissions:
|
permissions:
|
||||||
@@ -16,43 +16,33 @@ env:
|
|||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
build:
|
build:
|
||||||
runs-on: ubuntu-24.04
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v5
|
- uses: actions/checkout@v4
|
||||||
with:
|
with:
|
||||||
fetch-depth: 0
|
fetch-depth: 0
|
||||||
|
|
||||||
- name: Set up Go
|
- name: Set up Go
|
||||||
uses: actions/setup-go@v6
|
uses: actions/setup-go@v5
|
||||||
with:
|
with:
|
||||||
go-version: "1.23"
|
go-version: "1.20"
|
||||||
|
|
||||||
- name: Setup Ruby
|
- name: Setup Ruby
|
||||||
uses: ruby/setup-ruby@89f90524b88a01fe6e0b732220432cc6142926af # v1
|
uses: ruby/setup-ruby@v1
|
||||||
with:
|
with:
|
||||||
ruby-version: 3.4.6
|
ruby-version: 3.1.0
|
||||||
|
|
||||||
- name: Install packages
|
- name: Install packages
|
||||||
run: |
|
run: sudo apt-get install --yes zsh fish tmux
|
||||||
sudo install -d -m 0755 /etc/apt/keyrings
|
|
||||||
wget -qO- https://apt.fury.io/nushell/gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/fury-nushell.gpg
|
|
||||||
echo "deb [signed-by=/etc/apt/keyrings/fury-nushell.gpg] https://apt.fury.io/nushell/ /" | sudo tee /etc/apt/sources.list.d/fury-nushell.list
|
|
||||||
sudo apt-get update
|
|
||||||
sudo apt-get install --yes zsh fish tmux shfmt nushell
|
|
||||||
|
|
||||||
- name: Install Ruby gems
|
- name: Install Ruby gems
|
||||||
run: bundle install
|
run: sudo gem install --no-document minitest:5.25.1 rubocop:1.65.0 rubocop-minitest:0.35.1 rubocop-performance:1.21.1
|
||||||
|
|
||||||
- name: Rubocop
|
- name: Rubocop
|
||||||
run: make lint
|
run: rubocop --require rubocop-minitest --require rubocop-performance
|
||||||
|
|
||||||
- name: Unit test
|
- name: Unit test
|
||||||
run: make test
|
run: make test
|
||||||
|
|
||||||
- name: Fuzz test
|
|
||||||
run: |
|
|
||||||
go test ./src/algo/ -fuzz=FuzzIndexByteTwo -fuzztime=5s
|
|
||||||
go test ./src/algo/ -fuzz=FuzzLastIndexByteTwo -fuzztime=5s
|
|
||||||
|
|
||||||
- name: Integration test
|
- name: Integration test
|
||||||
run: make install && ./install --all && tmux new-session -d && ruby test/runner.rb --verbose
|
run: make install && ./install --all && tmux new-session -d && ruby test/test_go.rb --verbose
|
||||||
|
|||||||
@@ -15,22 +15,22 @@ jobs:
|
|||||||
build:
|
build:
|
||||||
runs-on: macos-latest
|
runs-on: macos-latest
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v5
|
- uses: actions/checkout@v4
|
||||||
with:
|
with:
|
||||||
fetch-depth: 0
|
fetch-depth: 0
|
||||||
|
|
||||||
- name: Set up Go
|
- name: Set up Go
|
||||||
uses: actions/setup-go@v6
|
uses: actions/setup-go@v5
|
||||||
with:
|
with:
|
||||||
go-version: "1.23"
|
go-version: "1.20"
|
||||||
|
|
||||||
- name: Setup Ruby
|
- name: Setup Ruby
|
||||||
uses: ruby/setup-ruby@89f90524b88a01fe6e0b732220432cc6142926af # v1
|
uses: ruby/setup-ruby@v1
|
||||||
with:
|
with:
|
||||||
ruby-version: 3.0.0
|
ruby-version: 3.0.0
|
||||||
|
|
||||||
- name: Install packages
|
- name: Install packages
|
||||||
run: HOMEBREW_NO_INSTALL_CLEANUP=1 brew install fish zsh tmux shfmt
|
run: HOMEBREW_NO_INSTALL_CLEANUP=1 brew install fish zsh tmux
|
||||||
|
|
||||||
- name: Install Ruby gems
|
- name: Install Ruby gems
|
||||||
run: gem install --no-document minitest:5.14.2 rubocop:1.0.0 rubocop-minitest:0.10.1 rubocop-performance:1.8.1
|
run: gem install --no-document minitest:5.14.2 rubocop:1.0.0 rubocop-minitest:0.10.1 rubocop-performance:1.8.1
|
||||||
|
|||||||
@@ -1,76 +0,0 @@
|
|||||||
name: Release
|
|
||||||
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
tags:
|
|
||||||
- 'v*'
|
|
||||||
workflow_dispatch:
|
|
||||||
inputs:
|
|
||||||
version:
|
|
||||||
description: 'Version to validate (e.g. 0.73.0).'
|
|
||||||
type: string
|
|
||||||
required: true
|
|
||||||
|
|
||||||
permissions:
|
|
||||||
contents: write
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
release:
|
|
||||||
runs-on: macos-latest
|
|
||||||
environment: release
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v6
|
|
||||||
with:
|
|
||||||
fetch-depth: 0
|
|
||||||
|
|
||||||
- uses: actions/setup-go@v6
|
|
||||||
with:
|
|
||||||
go-version: stable
|
|
||||||
|
|
||||||
- name: Determine version
|
|
||||||
id: ver
|
|
||||||
run: |
|
|
||||||
if [ "${{ github.event_name }}" = "push" ]; then
|
|
||||||
v=${GITHUB_REF_NAME#v}
|
|
||||||
else
|
|
||||||
v='${{ inputs.version }}'
|
|
||||||
fi
|
|
||||||
echo "version=$v" >> "$GITHUB_OUTPUT"
|
|
||||||
echo "Resolved version: '$v'"
|
|
||||||
|
|
||||||
- name: Verify version consistency
|
|
||||||
run: |
|
|
||||||
set -e
|
|
||||||
V='${{ steps.ver.outputs.version }}'
|
|
||||||
R=$(echo "$V" | sed 's/\./\\./g')
|
|
||||||
grep -q "^${R}$" CHANGELOG.md
|
|
||||||
grep -qF "\"fzf ${V}\"" man/man1/fzf.1
|
|
||||||
grep -qF "\"fzf ${V}\"" man/man1/fzf-tmux.1
|
|
||||||
grep -qF "${V}" install
|
|
||||||
grep -qF "${V}" install.ps1
|
|
||||||
|
|
||||||
- name: Extract release notes
|
|
||||||
run: |
|
|
||||||
set -e
|
|
||||||
mkdir -p tmp
|
|
||||||
V='${{ steps.ver.outputs.version }}'
|
|
||||||
R=$(echo "$V" | sed 's/\./\\./g')
|
|
||||||
sed -n "/^${R}$/,/^[0-9]/p" CHANGELOG.md \
|
|
||||||
| tail -r | sed '1,/^ *$/d' | tail -r | sed '1,2d' \
|
|
||||||
| tee tmp/release-note
|
|
||||||
|
|
||||||
- name: Run goreleaser
|
|
||||||
uses: goreleaser/goreleaser-action@v7
|
|
||||||
with:
|
|
||||||
version: latest
|
|
||||||
args: >-
|
|
||||||
${{ github.event_name == 'push'
|
|
||||||
&& 'release --clean --release-notes tmp/release-note'
|
|
||||||
|| 'release --snapshot --clean --skip=publish' }}
|
|
||||||
env:
|
|
||||||
GITHUB_TOKEN: ${{ secrets.RELEASE_PAT }}
|
|
||||||
MACOS_SIGN_P12: ${{ secrets.MACOS_SIGN_P12 }}
|
|
||||||
MACOS_SIGN_PASSWORD: ${{ secrets.MACOS_SIGN_PASSWORD }}
|
|
||||||
MACOS_NOTARY_ISSUER_ID: ${{ secrets.MACOS_NOTARY_ISSUER_ID }}
|
|
||||||
MACOS_NOTARY_KEY_ID: ${{ secrets.MACOS_NOTARY_KEY_ID }}
|
|
||||||
MACOS_NOTARY_KEY: ${{ secrets.MACOS_NOTARY_KEY }}
|
|
||||||
@@ -0,0 +1,24 @@
|
|||||||
|
---
|
||||||
|
name: Generate Sponsors README
|
||||||
|
on:
|
||||||
|
workflow_dispatch:
|
||||||
|
schedule:
|
||||||
|
- cron: 0 0 * * 0
|
||||||
|
jobs:
|
||||||
|
deploy:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- name: Checkout 🛎️
|
||||||
|
uses: actions/checkout@v4
|
||||||
|
|
||||||
|
- name: Generate Sponsors 💖
|
||||||
|
uses: JamesIves/github-sponsors-readme-action@v1
|
||||||
|
with:
|
||||||
|
token: ${{ secrets.SPONSORS_TOKEN }}
|
||||||
|
file: 'README.md'
|
||||||
|
|
||||||
|
- name: Deploy to GitHub Pages 🚀
|
||||||
|
uses: JamesIves/github-pages-deploy-action@v4
|
||||||
|
with:
|
||||||
|
branch: master
|
||||||
|
folder: '.'
|
||||||
@@ -6,5 +6,5 @@ jobs:
|
|||||||
name: Spell Check with Typos
|
name: Spell Check with Typos
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
- uses: actions/checkout@v5
|
- uses: actions/checkout@v4
|
||||||
- uses: crate-ci/typos@685eb3d55be2f85191e8c84acb9f44d7756f84ab # v1.29.4
|
- uses: crate-ci/typos@v1.24.1
|
||||||
|
|||||||
@@ -2,20 +2,13 @@ name: Publish to Winget
|
|||||||
on:
|
on:
|
||||||
release:
|
release:
|
||||||
types: [released]
|
types: [released]
|
||||||
workflow_dispatch:
|
|
||||||
inputs:
|
|
||||||
release-tag:
|
|
||||||
description: 'Release tag to submit (e.g. v0.73.1)'
|
|
||||||
required: true
|
|
||||||
type: string
|
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
publish:
|
publish:
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
- uses: vedantmgoyal2009/winget-releaser@4ffc7888bffd451b357355dc214d43bb9f23917e # v2
|
- uses: vedantmgoyal2009/winget-releaser@v2
|
||||||
with:
|
with:
|
||||||
identifier: junegunn.fzf
|
identifier: junegunn.fzf
|
||||||
release-tag: ${{ inputs.release-tag || github.event.release.tag_name }}
|
|
||||||
installers-regex: '-windows_(armv7|arm64|amd64)\.zip$'
|
installers-regex: '-windows_(armv7|arm64|amd64)\.zip$'
|
||||||
token: ${{ secrets.WINGET_TOKEN }}
|
token: ${{ secrets.WINGET_TOKEN }}
|
||||||
|
|||||||
+1
-1
@@ -3,6 +3,7 @@ bin/fzf.exe
|
|||||||
dist
|
dist
|
||||||
target
|
target
|
||||||
pkg
|
pkg
|
||||||
|
Gemfile.lock
|
||||||
.DS_Store
|
.DS_Store
|
||||||
doc/tags
|
doc/tags
|
||||||
vendor
|
vendor
|
||||||
@@ -11,4 +12,3 @@ gopath
|
|||||||
fzf
|
fzf
|
||||||
tmp
|
tmp
|
||||||
*.patch
|
*.patch
|
||||||
.idea
|
|
||||||
|
|||||||
+7
-17
@@ -14,7 +14,6 @@ builds:
|
|||||||
- windows
|
- windows
|
||||||
- freebsd
|
- freebsd
|
||||||
- openbsd
|
- openbsd
|
||||||
- android
|
|
||||||
goarch:
|
goarch:
|
||||||
- amd64
|
- amd64
|
||||||
- arm
|
- arm
|
||||||
@@ -22,11 +21,10 @@ builds:
|
|||||||
- loong64
|
- loong64
|
||||||
- ppc64le
|
- ppc64le
|
||||||
- s390x
|
- s390x
|
||||||
- riscv64
|
|
||||||
goarm:
|
goarm:
|
||||||
- "5"
|
- 5
|
||||||
- "6"
|
- 6
|
||||||
- "7"
|
- 7
|
||||||
flags:
|
flags:
|
||||||
- -trimpath
|
- -trimpath
|
||||||
ldflags:
|
ldflags:
|
||||||
@@ -40,12 +38,6 @@ builds:
|
|||||||
goarch: arm64
|
goarch: arm64
|
||||||
- goos: openbsd
|
- goos: openbsd
|
||||||
goarch: arm64
|
goarch: arm64
|
||||||
- goos: openbsd
|
|
||||||
goarch: riscv64
|
|
||||||
- goos: android
|
|
||||||
goarch: amd64
|
|
||||||
- goos: android
|
|
||||||
goarch: arm
|
|
||||||
|
|
||||||
# .goreleaser.yaml
|
# .goreleaser.yaml
|
||||||
notarize:
|
notarize:
|
||||||
@@ -85,14 +77,12 @@ notarize:
|
|||||||
|
|
||||||
archives:
|
archives:
|
||||||
- name_template: "{{ .ProjectName }}-{{ .Version }}-{{ .Os }}_{{ .Arch }}{{ if .Arm }}v{{ .Arm }}{{ end }}"
|
- name_template: "{{ .ProjectName }}-{{ .Version }}-{{ .Os }}_{{ .Arch }}{{ if .Arm }}v{{ .Arm }}{{ end }}"
|
||||||
ids:
|
builds:
|
||||||
- fzf
|
- fzf
|
||||||
formats:
|
format: tar.gz
|
||||||
- tar.gz
|
|
||||||
format_overrides:
|
format_overrides:
|
||||||
- goos: windows
|
- goos: windows
|
||||||
formats:
|
format: zip
|
||||||
- zip
|
|
||||||
files:
|
files:
|
||||||
- non-existent*
|
- non-existent*
|
||||||
|
|
||||||
@@ -104,7 +94,7 @@ release:
|
|||||||
name_template: '{{ .Version }}'
|
name_template: '{{ .Version }}'
|
||||||
|
|
||||||
snapshot:
|
snapshot:
|
||||||
version_template: "{{ .Version }}-devel"
|
name_template: "{{ .Version }}-devel"
|
||||||
|
|
||||||
changelog:
|
changelog:
|
||||||
sort: asc
|
sort: asc
|
||||||
|
|||||||
@@ -1,13 +1,9 @@
|
|||||||
AllCops:
|
|
||||||
NewCops: enable
|
|
||||||
Layout/LineLength:
|
Layout/LineLength:
|
||||||
Enabled: false
|
Enabled: false
|
||||||
Metrics:
|
Metrics:
|
||||||
Enabled: false
|
Enabled: false
|
||||||
Lint/ShadowingOuterLocalVariable:
|
Lint/ShadowingOuterLocalVariable:
|
||||||
Enabled: false
|
Enabled: false
|
||||||
Lint/NestedMethodDefinition:
|
|
||||||
Enabled: false
|
|
||||||
Style/MethodCallWithArgsParentheses:
|
Style/MethodCallWithArgsParentheses:
|
||||||
Enabled: true
|
Enabled: true
|
||||||
AllowedMethods:
|
AllowedMethods:
|
||||||
@@ -32,11 +28,5 @@ Style/WordArray:
|
|||||||
MinSize: 1
|
MinSize: 1
|
||||||
Minitest/AssertEqual:
|
Minitest/AssertEqual:
|
||||||
Enabled: false
|
Enabled: false
|
||||||
Minitest/EmptyLineBeforeAssertionMethods:
|
|
||||||
Enabled: false
|
|
||||||
Naming/VariableNumber:
|
Naming/VariableNumber:
|
||||||
Enabled: false
|
Enabled: false
|
||||||
Lint/EmptyBlock:
|
|
||||||
Enabled: false
|
|
||||||
Style/SafeNavigationChainLength:
|
|
||||||
Enabled: false
|
|
||||||
|
|||||||
+1
-3
@@ -1,3 +1 @@
|
|||||||
golang 1.23
|
golang 1.20.13
|
||||||
ruby 3.4
|
|
||||||
shfmt 3.12
|
|
||||||
|
|||||||
+14
-52
@@ -1,8 +1,8 @@
|
|||||||
Advanced fzf examples
|
Advanced fzf examples
|
||||||
======================
|
======================
|
||||||
|
|
||||||
* *Last update: 2025/02/02*
|
* *Last update: 2024/06/24*
|
||||||
* *Requires fzf 0.59.0 or later*
|
* *Requires fzf 0.54.0 or later*
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -22,7 +22,6 @@ Advanced fzf examples
|
|||||||
* [Switching to fzf-only search mode](#switching-to-fzf-only-search-mode)
|
* [Switching to fzf-only search mode](#switching-to-fzf-only-search-mode)
|
||||||
* [Switching between Ripgrep mode and fzf mode](#switching-between-ripgrep-mode-and-fzf-mode)
|
* [Switching between Ripgrep mode and fzf mode](#switching-between-ripgrep-mode-and-fzf-mode)
|
||||||
* [Switching between Ripgrep mode and fzf mode using a single key binding](#switching-between-ripgrep-mode-and-fzf-mode-using-a-single-key-binding)
|
* [Switching between Ripgrep mode and fzf mode using a single key binding](#switching-between-ripgrep-mode-and-fzf-mode-using-a-single-key-binding)
|
||||||
* [Controlling Ripgrep search and fzf search simultaneously](#controlling-ripgrep-search-and-fzf-search-simultaneously)
|
|
||||||
* [Log tailing](#log-tailing)
|
* [Log tailing](#log-tailing)
|
||||||
* [Key bindings for git objects](#key-bindings-for-git-objects)
|
* [Key bindings for git objects](#key-bindings-for-git-objects)
|
||||||
* [Files listed in `git status`](#files-listed-in-git-status)
|
* [Files listed in `git status`](#files-listed-in-git-status)
|
||||||
@@ -93,7 +92,7 @@ fzf --height=40% --layout=reverse --info=inline --border --margin=1 --padding=1
|
|||||||
|
|
||||||
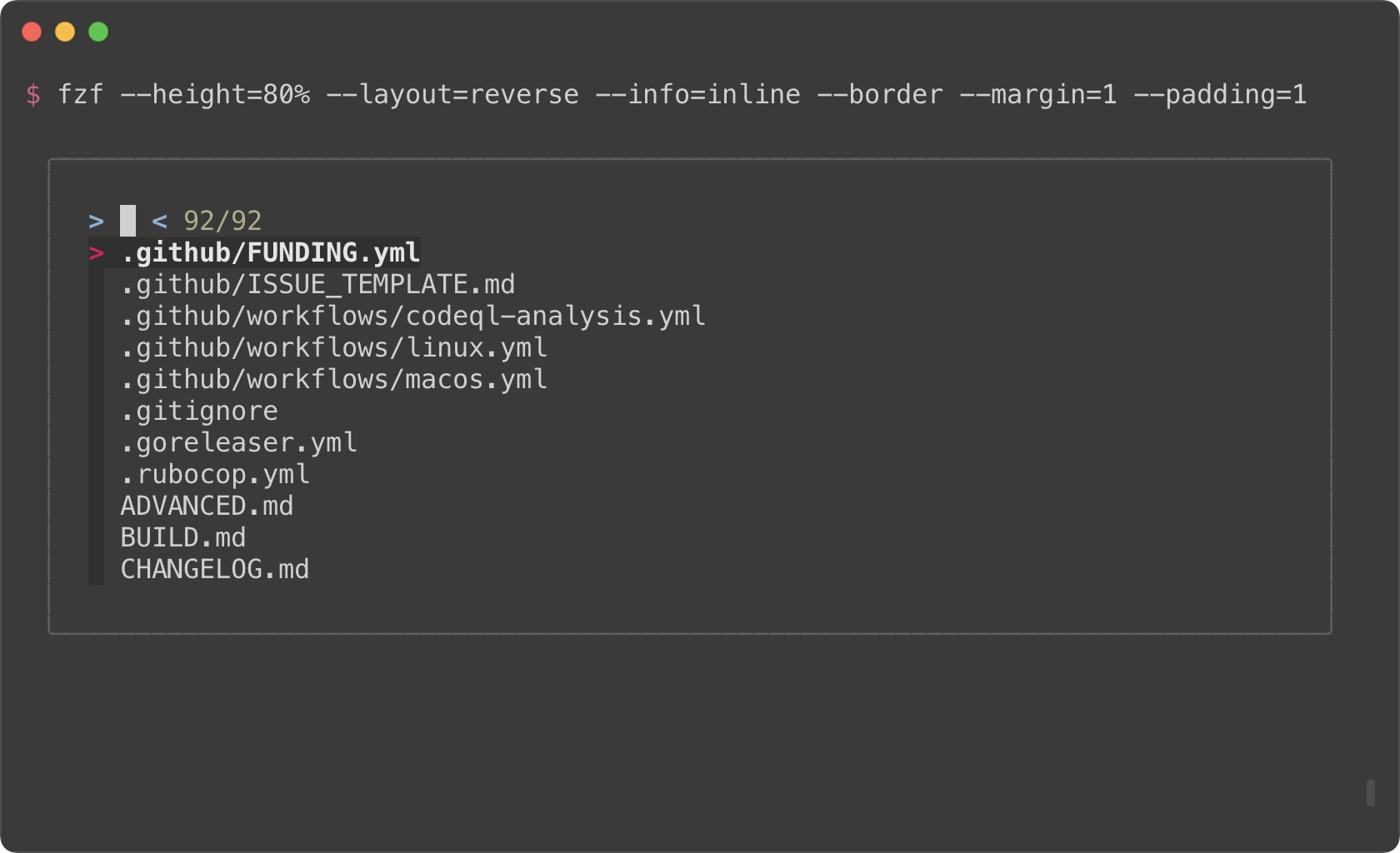
|

|
||||||
|
|
||||||
*(See man page to see the full list of options)*
|
*(See `Layout` section of the man page to see the full list of options)*
|
||||||
|
|
||||||
But you definitely don't want to repeat `--height=40% --layout=reverse
|
But you definitely don't want to repeat `--height=40% --layout=reverse
|
||||||
--info=inline --border --margin=1 --padding=1` every time you use fzf. You
|
--info=inline --border --margin=1 --padding=1` every time you use fzf. You
|
||||||
@@ -129,7 +128,7 @@ fzf --height 70% --tmux 70%
|
|||||||
You can also specify the position, width, and height of the popup window in
|
You can also specify the position, width, and height of the popup window in
|
||||||
the following format:
|
the following format:
|
||||||
|
|
||||||
* `[center|top|bottom|left|right][,SIZE[%]][,SIZE[%][,border-native]]`
|
* `[center|top|bottom|left|right][,SIZE[%]][,SIZE[%]]`
|
||||||
|
|
||||||
```sh
|
```sh
|
||||||
# 100% width and 60% height
|
# 100% width and 60% height
|
||||||
@@ -309,16 +308,16 @@ I know it's a lot to digest, let's try to break down the code.
|
|||||||
available color options.
|
available color options.
|
||||||
- The value of `--preview-window` option consists of 5 components delimited
|
- The value of `--preview-window` option consists of 5 components delimited
|
||||||
by `,`
|
by `,`
|
||||||
1. `up` -- Position of the preview window
|
1. `up` — Position of the preview window
|
||||||
1. `60%` -- Size of the preview window
|
1. `60%` — Size of the preview window
|
||||||
1. `border-bottom` -- Preview window border only on the bottom side
|
1. `border-bottom` — Preview window border only on the bottom side
|
||||||
1. `+{2}+3/3` -- Scroll offset of the preview contents
|
1. `+{2}+3/3` — Scroll offset of the preview contents
|
||||||
1. `~3` -- Fixed header
|
1. `~3` — Fixed header
|
||||||
- Let's break down the latter two. We want to display the bat output in the
|
- Let's break down the latter two. We want to display the bat output in the
|
||||||
preview window with a certain scroll offset so that the matching line is
|
preview window with a certain scroll offset so that the matching line is
|
||||||
positioned near the center of the preview window.
|
positioned near the center of the preview window.
|
||||||
- `+{2}` -- The base offset is extracted from the second token
|
- `+{2}` — The base offset is extracted from the second token
|
||||||
- `+3` -- We add 3 lines to the base offset to compensate for the header
|
- `+3` — We add 3 lines to the base offset to compensate for the header
|
||||||
part of `bat` output
|
part of `bat` output
|
||||||
- ```
|
- ```
|
||||||
───────┬──────────────────────────────────────────────────────────
|
───────┬──────────────────────────────────────────────────────────
|
||||||
@@ -363,7 +362,7 @@ projects, and it will free up memory as you narrow down the results.
|
|||||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||||
INITIAL_QUERY="${*:-}"
|
INITIAL_QUERY="${*:-}"
|
||||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
||||||
--bind "start:reload:$RG_PREFIX {q} || true" \
|
--bind "start:reload:$RG_PREFIX {q}" \
|
||||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||||
--delimiter : \
|
--delimiter : \
|
||||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||||
@@ -501,44 +500,6 @@ fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
|||||||
--bind 'enter:become(vim {1} +{2})'
|
--bind 'enter:become(vim {1} +{2})'
|
||||||
```
|
```
|
||||||
|
|
||||||
### Controlling Ripgrep search and fzf search simultaneously
|
|
||||||
|
|
||||||
`search` and `transform-search` action allow you to trigger an fzf search with
|
|
||||||
an arbitrary query string. This frees fzf from strictly following the prompt
|
|
||||||
input, enabling custom search syntax.
|
|
||||||
|
|
||||||
In the example below, `transform` action is used to conditionally trigger
|
|
||||||
`reload` for ripgrep, followed by `search` for fzf. The first word of the
|
|
||||||
query initiates the Ripgrep process to generate the initial results, while the
|
|
||||||
remainder of the query is passed to fzf for secondary filtering.
|
|
||||||
|
|
||||||
```sh
|
|
||||||
#!/usr/bin/env bash
|
|
||||||
|
|
||||||
export TEMP=$(mktemp -u)
|
|
||||||
trap 'rm -f "$TEMP"' EXIT
|
|
||||||
|
|
||||||
INITIAL_QUERY="${*:-}"
|
|
||||||
TRANSFORMER='
|
|
||||||
rg_pat={q:1} # The first word is passed to ripgrep
|
|
||||||
fzf_pat={q:2..} # The rest are passed to fzf
|
|
||||||
|
|
||||||
if ! [[ -r "$TEMP" ]] || [[ $rg_pat != $(cat "$TEMP") ]]; then
|
|
||||||
echo "$rg_pat" > "$TEMP"
|
|
||||||
printf "reload:sleep 0.1; rg --column --line-number --no-heading --color=always --smart-case %q || true" "$rg_pat"
|
|
||||||
fi
|
|
||||||
echo "+search:$fzf_pat"
|
|
||||||
'
|
|
||||||
fzf --ansi --disabled --query "$INITIAL_QUERY" \
|
|
||||||
--with-shell 'bash -c' \
|
|
||||||
--bind "start,change:transform:$TRANSFORMER" \
|
|
||||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
|
||||||
--delimiter : \
|
|
||||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
|
||||||
--preview-window 'up,60%,border-line,+{2}+3/3,~3' \
|
|
||||||
--bind 'enter:become(vim {1} +{2})'
|
|
||||||
```
|
|
||||||
|
|
||||||
Log tailing
|
Log tailing
|
||||||
-----------
|
-----------
|
||||||
|
|
||||||
@@ -568,7 +529,8 @@ pods() {
|
|||||||
--info=inline --layout=reverse --header-lines=1 \
|
--info=inline --layout=reverse --header-lines=1 \
|
||||||
--prompt "$(kubectl config current-context | sed 's/-context$//')> " \
|
--prompt "$(kubectl config current-context | sed 's/-context$//')> " \
|
||||||
--header $'╱ Enter (kubectl exec) ╱ CTRL-O (open log in editor) ╱ CTRL-R (reload) ╱\n\n' \
|
--header $'╱ Enter (kubectl exec) ╱ CTRL-O (open log in editor) ╱ CTRL-R (reload) ╱\n\n' \
|
||||||
--bind 'start,ctrl-r:reload:$command' \
|
--bind 'start:reload:$command' \
|
||||||
|
--bind 'ctrl-r:reload:$command' \
|
||||||
--bind 'ctrl-/:change-preview-window(80%,border-bottom|hidden|)' \
|
--bind 'ctrl-/:change-preview-window(80%,border-bottom|hidden|)' \
|
||||||
--bind 'enter:execute:kubectl exec -it --namespace {1} {2} -- bash' \
|
--bind 'enter:execute:kubectl exec -it --namespace {1} {2} -- bash' \
|
||||||
--bind 'ctrl-o:execute:${EDITOR:-vim} <(kubectl logs --all-containers --namespace {1} {2})' \
|
--bind 'ctrl-o:execute:${EDITOR:-vim} <(kubectl logs --all-containers --namespace {1} {2})' \
|
||||||
|
|||||||
@@ -6,7 +6,7 @@ Build instructions
|
|||||||
|
|
||||||
### Prerequisites
|
### Prerequisites
|
||||||
|
|
||||||
- Go 1.23 or above
|
- Go 1.20 or above
|
||||||
|
|
||||||
### Using Makefile
|
### Using Makefile
|
||||||
|
|
||||||
@@ -41,20 +41,6 @@ make release
|
|||||||
> --profile-block /tmp/block.pprof --profile-mutex /tmp/mutex.pprof
|
> --profile-block /tmp/block.pprof --profile-mutex /tmp/mutex.pprof
|
||||||
> ```
|
> ```
|
||||||
|
|
||||||
Running tests
|
|
||||||
-------------
|
|
||||||
|
|
||||||
```sh
|
|
||||||
# Run go unit tests
|
|
||||||
make test
|
|
||||||
|
|
||||||
# Run integration tests (requires to be on tmux)
|
|
||||||
make itest
|
|
||||||
|
|
||||||
# Run a single test case
|
|
||||||
ruby test/runner.rb --name test_something
|
|
||||||
```
|
|
||||||
|
|
||||||
Third-party libraries used
|
Third-party libraries used
|
||||||
--------------------------
|
--------------------------
|
||||||
|
|
||||||
|
|||||||
+1
-1053
File diff suppressed because it is too large
Load Diff
+4
-14
@@ -1,15 +1,5 @@
|
|||||||
FROM rubylang/ruby:3.4.1-noble
|
FROM ubuntu:24.04
|
||||||
RUN apt-get update && apt-get install -y git make golang zsh fish tmux
|
RUN apt-get update -y && apt install -y git make golang zsh fish ruby tmux
|
||||||
|
|
||||||
# https://www.nushell.sh/book/installation.html
|
|
||||||
RUN <<EOF
|
|
||||||
set -ex
|
|
||||||
apt-get install -y wget gnupg
|
|
||||||
wget -qO- https://apt.fury.io/nushell/gpg.key | gpg --dearmor -o /etc/apt/keyrings/fury-nushell.gpg
|
|
||||||
echo "deb [signed-by=/etc/apt/keyrings/fury-nushell.gpg] https://apt.fury.io/nushell/ /" | tee /etc/apt/sources.list.d/fury-nushell.list
|
|
||||||
apt-get update
|
|
||||||
apt-get install -y nushell
|
|
||||||
EOF
|
|
||||||
RUN gem install --no-document -v 5.22.3 minitest
|
RUN gem install --no-document -v 5.22.3 minitest
|
||||||
RUN echo '. /usr/share/bash-completion/completions/git' >> ~/.bashrc
|
RUN echo '. /usr/share/bash-completion/completions/git' >> ~/.bashrc
|
||||||
RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
||||||
@@ -18,5 +8,5 @@ RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
|||||||
RUN rm -f /etc/bash.bashrc
|
RUN rm -f /etc/bash.bashrc
|
||||||
COPY . /fzf
|
COPY . /fzf
|
||||||
RUN cd /fzf && make install && ./install --all
|
RUN cd /fzf && make install && ./install --all
|
||||||
ENV LANG=C.UTF-8
|
ENV LANG C.UTF-8
|
||||||
CMD ["bash", "-ic", "tmux new 'set -o pipefail; ruby /fzf/test/runner.rb | tee out && touch ok' && cat out && [ -e ok ]"]
|
CMD tmux new 'set -o pipefail; ruby /fzf/test/test_go.rb | tee out && touch ok' && cat out && [ -e ok ]
|
||||||
|
|||||||
@@ -1,8 +0,0 @@
|
|||||||
# frozen_string_literal: true
|
|
||||||
|
|
||||||
source 'https://rubygems.org'
|
|
||||||
|
|
||||||
gem 'minitest', '5.25.4'
|
|
||||||
gem 'rubocop', '1.71.0'
|
|
||||||
gem 'rubocop-minitest', '0.36.0'
|
|
||||||
gem 'rubocop-performance', '1.23.1'
|
|
||||||
@@ -1,47 +0,0 @@
|
|||||||
GEM
|
|
||||||
remote: https://rubygems.org/
|
|
||||||
specs:
|
|
||||||
ast (2.4.2)
|
|
||||||
json (2.9.1)
|
|
||||||
language_server-protocol (3.17.0.3)
|
|
||||||
minitest (5.25.4)
|
|
||||||
parallel (1.26.3)
|
|
||||||
parser (3.3.7.0)
|
|
||||||
ast (~> 2.4.1)
|
|
||||||
racc
|
|
||||||
racc (1.8.1)
|
|
||||||
rainbow (3.1.1)
|
|
||||||
regexp_parser (2.10.0)
|
|
||||||
rubocop (1.71.0)
|
|
||||||
json (~> 2.3)
|
|
||||||
language_server-protocol (>= 3.17.0)
|
|
||||||
parallel (~> 1.10)
|
|
||||||
parser (>= 3.3.0.2)
|
|
||||||
rainbow (>= 2.2.2, < 4.0)
|
|
||||||
regexp_parser (>= 2.9.3, < 3.0)
|
|
||||||
rubocop-ast (>= 1.36.2, < 2.0)
|
|
||||||
ruby-progressbar (~> 1.7)
|
|
||||||
unicode-display_width (>= 2.4.0, < 4.0)
|
|
||||||
rubocop-ast (1.37.0)
|
|
||||||
parser (>= 3.3.1.0)
|
|
||||||
rubocop-minitest (0.36.0)
|
|
||||||
rubocop (>= 1.61, < 2.0)
|
|
||||||
rubocop-ast (>= 1.31.1, < 2.0)
|
|
||||||
rubocop-performance (1.23.1)
|
|
||||||
rubocop (>= 1.48.1, < 2.0)
|
|
||||||
rubocop-ast (>= 1.31.1, < 2.0)
|
|
||||||
ruby-progressbar (1.13.0)
|
|
||||||
unicode-display_width (2.6.0)
|
|
||||||
|
|
||||||
PLATFORMS
|
|
||||||
arm64-darwin-23
|
|
||||||
ruby
|
|
||||||
|
|
||||||
DEPENDENCIES
|
|
||||||
minitest (= 5.25.4)
|
|
||||||
rubocop (= 1.71.0)
|
|
||||||
rubocop-minitest (= 0.36.0)
|
|
||||||
rubocop-performance (= 1.23.1)
|
|
||||||
|
|
||||||
BUNDLED WITH
|
|
||||||
2.6.2
|
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
The MIT License (MIT)
|
The MIT License (MIT)
|
||||||
|
|
||||||
Copyright (c) 2013-2026 Junegunn Choi
|
Copyright (c) 2013-2024 Junegunn Choi
|
||||||
|
|
||||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
of this software and associated documentation files (the "Software"), to deal
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
|||||||
@@ -1,20 +1,11 @@
|
|||||||
|
SHELL := bash
|
||||||
GO ?= go
|
GO ?= go
|
||||||
DOCKER ?= docker
|
|
||||||
GOOS ?= $(shell $(GO) env GOOS)
|
GOOS ?= $(shell $(GO) env GOOS)
|
||||||
|
|
||||||
MAKEFILE := $(realpath $(lastword $(MAKEFILE_LIST)))
|
MAKEFILE := $(realpath $(lastword $(MAKEFILE_LIST)))
|
||||||
ROOT_DIR := $(shell dirname $(MAKEFILE))
|
ROOT_DIR := $(shell dirname $(MAKEFILE))
|
||||||
SOURCES := $(wildcard *.go src/*.go src/*/*.go shell/*sh man/man1/*.1) $(MAKEFILE)
|
SOURCES := $(wildcard *.go src/*.go src/*/*.go shell/*sh man/man1/*.1) $(MAKEFILE)
|
||||||
|
|
||||||
BASH_SCRIPTS := $(ROOT_DIR)/bin/fzf-preview.sh \
|
|
||||||
$(ROOT_DIR)/bin/fzf-tmux \
|
|
||||||
$(ROOT_DIR)/install \
|
|
||||||
$(ROOT_DIR)/uninstall \
|
|
||||||
$(ROOT_DIR)/shell/common.sh \
|
|
||||||
$(ROOT_DIR)/shell/update.sh \
|
|
||||||
$(ROOT_DIR)/shell/completion.bash \
|
|
||||||
$(ROOT_DIR)/shell/key-bindings.bash
|
|
||||||
|
|
||||||
ifdef FZF_VERSION
|
ifdef FZF_VERSION
|
||||||
VERSION := $(FZF_VERSION)
|
VERSION := $(FZF_VERSION)
|
||||||
else
|
else
|
||||||
@@ -23,7 +14,7 @@ endif
|
|||||||
ifeq ($(VERSION),)
|
ifeq ($(VERSION),)
|
||||||
$(error Not on git repository; cannot determine $$FZF_VERSION)
|
$(error Not on git repository; cannot determine $$FZF_VERSION)
|
||||||
endif
|
endif
|
||||||
VERSION_TRIM := $(shell echo $(VERSION) | sed "s/^v//; s/-.*//")
|
VERSION_TRIM := $(shell sed "s/^v//; s/-.*//" <<< $(VERSION))
|
||||||
VERSION_REGEX := $(subst .,\.,$(VERSION_TRIM))
|
VERSION_REGEX := $(subst .,\.,$(VERSION_TRIM))
|
||||||
|
|
||||||
ifdef FZF_REVISION
|
ifdef FZF_REVISION
|
||||||
@@ -53,8 +44,6 @@ ifeq ($(UNAME_M),x86_64)
|
|||||||
BINARY := $(BINARY64)
|
BINARY := $(BINARY64)
|
||||||
else ifeq ($(UNAME_M),amd64)
|
else ifeq ($(UNAME_M),amd64)
|
||||||
BINARY := $(BINARY64)
|
BINARY := $(BINARY64)
|
||||||
else ifeq ($(UNAME_M),i86pc)
|
|
||||||
BINARY := $(BINARY64)
|
|
||||||
else ifeq ($(UNAME_M),s390x)
|
else ifeq ($(UNAME_M),s390x)
|
||||||
BINARY := $(BINARYS390)
|
BINARY := $(BINARYS390)
|
||||||
else ifeq ($(UNAME_M),i686)
|
else ifeq ($(UNAME_M),i686)
|
||||||
@@ -94,20 +83,12 @@ test: $(SOURCES)
|
|||||||
github.com/junegunn/fzf/src/tui \
|
github.com/junegunn/fzf/src/tui \
|
||||||
github.com/junegunn/fzf/src/util
|
github.com/junegunn/fzf/src/util
|
||||||
|
|
||||||
itest:
|
|
||||||
ruby test/runner.rb
|
|
||||||
|
|
||||||
bench:
|
bench:
|
||||||
cd src && SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" -run=Bench -bench=. -benchmem
|
cd src && SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" -run=Bench -bench=. -benchmem
|
||||||
|
|
||||||
lint: $(SOURCES) test/*.rb test/lib/*.rb ${BASH_SCRIPTS}
|
lint: $(SOURCES) test/test_go.rb
|
||||||
[ -z "$$(gofmt -s -d src)" ] || (gofmt -s -d src; exit 1)
|
[ -z "$$(gofmt -s -d src)" ] || (gofmt -s -d src; exit 1)
|
||||||
bundle exec rubocop -a --require rubocop-minitest --require rubocop-performance
|
rubocop --require rubocop-minitest --require rubocop-performance
|
||||||
shell/update.sh --check ${BASH_SCRIPTS}
|
|
||||||
|
|
||||||
fmt: $(SOURCES) $(BASH_SCRIPTS)
|
|
||||||
gofmt -s -w src
|
|
||||||
shell/update.sh ${BASH_SCRIPTS}
|
|
||||||
|
|
||||||
install: bin/fzf
|
install: bin/fzf
|
||||||
|
|
||||||
@@ -117,19 +98,6 @@ generate:
|
|||||||
build:
|
build:
|
||||||
goreleaser build --clean --snapshot --skip=post-hooks
|
goreleaser build --clean --snapshot --skip=post-hooks
|
||||||
|
|
||||||
prerelease:
|
|
||||||
# Check if version numbers are properly updated
|
|
||||||
grep -q ^$(VERSION_REGEX)$$ CHANGELOG.md
|
|
||||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf.1
|
|
||||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf-tmux.1
|
|
||||||
grep -qF $(VERSION) install
|
|
||||||
grep -qF $(VERSION) install.ps1
|
|
||||||
@echo "OK: all files consistent at $(VERSION)"
|
|
||||||
|
|
||||||
tag: prerelease
|
|
||||||
git tag -s v$(VERSION) -m v$(VERSION)
|
|
||||||
git push origin v$(VERSION)
|
|
||||||
|
|
||||||
release:
|
release:
|
||||||
# Make sure that the tests pass and the build works
|
# Make sure that the tests pass and the build works
|
||||||
TAGS=tcell make test
|
TAGS=tcell make test
|
||||||
@@ -208,15 +176,15 @@ bin/fzf: target/$(BINARY) | bin
|
|||||||
cp -f target/$(BINARY) bin/fzf
|
cp -f target/$(BINARY) bin/fzf
|
||||||
|
|
||||||
docker:
|
docker:
|
||||||
$(DOCKER) build -t fzf-ubuntu .
|
docker build -t fzf-ubuntu .
|
||||||
$(DOCKER) run -it fzf-ubuntu tmux
|
docker run -it fzf-ubuntu tmux
|
||||||
|
|
||||||
docker-test:
|
docker-test:
|
||||||
$(DOCKER) build -t fzf-ubuntu .
|
docker build -t fzf-ubuntu .
|
||||||
$(DOCKER) run -it fzf-ubuntu
|
docker run -it fzf-ubuntu
|
||||||
|
|
||||||
update:
|
update:
|
||||||
$(GO) get -u
|
$(GO) get -u
|
||||||
$(GO) mod tidy
|
$(GO) mod tidy
|
||||||
|
|
||||||
.PHONY: all generate build prerelease tag release test itest bench lint install clean docker docker-test update fmt
|
.PHONY: all generate build release test bench lint install clean docker docker-test update
|
||||||
|
|||||||
+1
-2
@@ -155,7 +155,6 @@ let g:fzf_layout = { 'window': '10new' }
|
|||||||
let g:fzf_colors =
|
let g:fzf_colors =
|
||||||
\ { 'fg': ['fg', 'Normal'],
|
\ { 'fg': ['fg', 'Normal'],
|
||||||
\ 'bg': ['bg', 'Normal'],
|
\ 'bg': ['bg', 'Normal'],
|
||||||
\ 'query': ['fg', 'Normal'],
|
|
||||||
\ 'hl': ['fg', 'Comment'],
|
\ 'hl': ['fg', 'Comment'],
|
||||||
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
||||||
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
||||||
@@ -493,4 +492,4 @@ autocmd FileType fzf set laststatus=0 noshowmode noruler
|
|||||||
|
|
||||||
The MIT License (MIT)
|
The MIT License (MIT)
|
||||||
|
|
||||||
Copyright (c) 2013-2026 Junegunn Choi
|
Copyright (c) 2013-2024 Junegunn Choi
|
||||||
|
|||||||
-54
@@ -1,54 +0,0 @@
|
|||||||
Release process
|
|
||||||
===============
|
|
||||||
|
|
||||||
Building, signing, notarizing, and publishing is handled by
|
|
||||||
[`.github/workflows/release.yml`](.github/workflows/release.yml),
|
|
||||||
triggered by a tag push.
|
|
||||||
|
|
||||||
## Steps
|
|
||||||
|
|
||||||
1. Update version in the following files and commit on `master`:
|
|
||||||
- `CHANGELOG.md`
|
|
||||||
- `main.go`
|
|
||||||
- `install`
|
|
||||||
- `install.ps1`
|
|
||||||
- `man/man1/fzf.1`
|
|
||||||
- `man/man1/fzf-tmux.1`
|
|
||||||
|
|
||||||
2. Verify file consistency, sign the tag, and push the tag.
|
|
||||||
|
|
||||||
```sh
|
|
||||||
make tag VERSION=0.73.1
|
|
||||||
```
|
|
||||||
|
|
||||||
`make tag` runs `prerelease` first (checks that the version
|
|
||||||
appears in CHANGELOG.md, both man pages, install, and install.ps1)
|
|
||||||
and only signs + pushes the tag if the checks pass.
|
|
||||||
|
|
||||||
Only the tag is pushed; `master` on origin still points to the
|
|
||||||
old version, so `/master/install` keeps resolving against existing
|
|
||||||
binaries during the publish window.
|
|
||||||
|
|
||||||
3. The workflow fires on the tag push and pauses on the `release`
|
|
||||||
environment gate. Approve it in the Actions tab to release.
|
|
||||||
|
|
||||||
4. After the GitHub release is published, fast-forward `master`:
|
|
||||||
|
|
||||||
```sh
|
|
||||||
git push origin master
|
|
||||||
```
|
|
||||||
|
|
||||||
## Testing the workflow
|
|
||||||
|
|
||||||
To exercise the workflow without firing a real release:
|
|
||||||
|
|
||||||
1. Actions tab -> **Release** -> **Run workflow**.
|
|
||||||
2. Pick a branch and enter the version currently on that branch
|
|
||||||
(the version-consistency check requires the input to match the
|
|
||||||
files in the checked-out tree).
|
|
||||||
3. Approve the `release` environment gate when prompted.
|
|
||||||
4. Goreleaser runs with `--snapshot --skip=publish`. Signing and
|
|
||||||
notarization run; only the GitHub release upload is skipped.
|
|
||||||
|
|
||||||
Use this to validate the workflow YAML, version-extraction logic,
|
|
||||||
the macOS runner setup, and the signing/notarization credentials.
|
|
||||||
-33
@@ -1,33 +0,0 @@
|
|||||||
# Security Reporting
|
|
||||||
|
|
||||||
If you wish to report a security vulnerability privately, we appreciate your diligence. Please follow the guidelines below to submit your report.
|
|
||||||
|
|
||||||
## Reporting
|
|
||||||
|
|
||||||
To report a security vulnerability, please provide the following information:
|
|
||||||
|
|
||||||
1. **PROJECT**
|
|
||||||
- https://github.com/junegunn/fzf
|
|
||||||
|
|
||||||
2. **PUBLIC**
|
|
||||||
- Indicate whether this vulnerability has already been publicly discussed or disclosed.
|
|
||||||
- If so, provide relevant links.
|
|
||||||
|
|
||||||
3. **DESCRIPTION**
|
|
||||||
- Provide a detailed description of the security vulnerability.
|
|
||||||
- Include as much information as possible to help us understand and address the issue.
|
|
||||||
|
|
||||||
Send this information, along with any additional relevant details, to <junegunn.c AT gmail DOT com>.
|
|
||||||
|
|
||||||
## Confidentiality
|
|
||||||
|
|
||||||
We kindly ask you to keep the report confidential until a public announcement is made.
|
|
||||||
|
|
||||||
## Notes
|
|
||||||
|
|
||||||
- Vulnerabilities will be handled on a best-effort basis.
|
|
||||||
- You may request an advance copy of the patched release, but we cannot guarantee early access before the public release.
|
|
||||||
- You will be notified via email simultaneously with the public announcement.
|
|
||||||
- We will respond within a few weeks to confirm whether your report has been accepted or rejected.
|
|
||||||
|
|
||||||
Thank you for helping to improve the security of our project!
|
|
||||||
+8
-20
@@ -9,24 +9,12 @@
|
|||||||
# - https://iterm2.com/utilities/imgcat
|
# - https://iterm2.com/utilities/imgcat
|
||||||
|
|
||||||
if [[ $# -ne 1 ]]; then
|
if [[ $# -ne 1 ]]; then
|
||||||
>&2 echo "usage: $0 FILENAME[:LINENO][:IGNORED]"
|
>&2 echo "usage: $0 FILENAME"
|
||||||
exit 1
|
exit 1
|
||||||
fi
|
fi
|
||||||
|
|
||||||
file=${1/#\~\//$HOME/}
|
file=${1/#\~\//$HOME/}
|
||||||
|
type=$(file --dereference --mime -- "$file")
|
||||||
center=0
|
|
||||||
if [[ ! -r $file ]]; then
|
|
||||||
if [[ $file =~ ^(.+):([0-9]+)\ *$ ]] && [[ -r ${BASH_REMATCH[1]} ]]; then
|
|
||||||
file=${BASH_REMATCH[1]}
|
|
||||||
center=${BASH_REMATCH[2]}
|
|
||||||
elif [[ $file =~ ^(.+):([0-9]+):[0-9]+\ *$ ]] && [[ -r ${BASH_REMATCH[1]} ]]; then
|
|
||||||
file=${BASH_REMATCH[1]}
|
|
||||||
center=${BASH_REMATCH[2]}
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
type=$(file --brief --dereference --mime -- "$file")
|
|
||||||
|
|
||||||
if [[ ! $type =~ image/ ]]; then
|
if [[ ! $type =~ image/ ]]; then
|
||||||
if [[ $type =~ =binary ]]; then
|
if [[ $type =~ =binary ]]; then
|
||||||
@@ -44,28 +32,28 @@ if [[ ! $type =~ image/ ]]; then
|
|||||||
exit
|
exit
|
||||||
fi
|
fi
|
||||||
|
|
||||||
${batname} --style="${BAT_STYLE:-numbers}" --color=always --pager=never --highlight-line="${center:-0}" -- "$file"
|
${batname} --style="${BAT_STYLE:-numbers}" --color=always --pager=never -- "$file"
|
||||||
exit
|
exit
|
||||||
fi
|
fi
|
||||||
|
|
||||||
dim=${FZF_PREVIEW_COLUMNS}x${FZF_PREVIEW_LINES}
|
dim=${FZF_PREVIEW_COLUMNS}x${FZF_PREVIEW_LINES}
|
||||||
if [[ $dim == x ]]; then
|
if [[ $dim = x ]]; then
|
||||||
dim=$(stty size < /dev/tty | awk '{print $2 "x" $1}')
|
dim=$(stty size < /dev/tty | awk '{print $2 "x" $1}')
|
||||||
elif ! [[ $KITTY_WINDOW_ID ]] && ((FZF_PREVIEW_TOP + FZF_PREVIEW_LINES == $(stty size < /dev/tty | awk '{print $1}'))); then
|
elif ! [[ $KITTY_WINDOW_ID ]] && (( FZF_PREVIEW_TOP + FZF_PREVIEW_LINES == $(stty size < /dev/tty | awk '{print $1}') )); then
|
||||||
# Avoid scrolling issue when the Sixel image touches the bottom of the screen
|
# Avoid scrolling issue when the Sixel image touches the bottom of the screen
|
||||||
# * https://github.com/junegunn/fzf/issues/2544
|
# * https://github.com/junegunn/fzf/issues/2544
|
||||||
dim=${FZF_PREVIEW_COLUMNS}x$((FZF_PREVIEW_LINES - 1))
|
dim=${FZF_PREVIEW_COLUMNS}x$((FZF_PREVIEW_LINES - 1))
|
||||||
fi
|
fi
|
||||||
|
|
||||||
# 1. Use icat (from Kitty) if kitten is installed
|
# 1. Use kitty icat on kitty terminal
|
||||||
if [[ $KITTY_WINDOW_ID ]] || [[ $GHOSTTY_RESOURCES_DIR ]] && command -v kitten > /dev/null; then
|
if [[ $KITTY_WINDOW_ID ]]; then
|
||||||
# 1. 'memory' is the fastest option but if you want the image to be scrollable,
|
# 1. 'memory' is the fastest option but if you want the image to be scrollable,
|
||||||
# you have to use 'stream'.
|
# you have to use 'stream'.
|
||||||
#
|
#
|
||||||
# 2. The last line of the output is the ANSI reset code without newline.
|
# 2. The last line of the output is the ANSI reset code without newline.
|
||||||
# This confuses fzf and makes it render scroll offset indicator.
|
# This confuses fzf and makes it render scroll offset indicator.
|
||||||
# So we remove the last line and append the reset code to its previous line.
|
# So we remove the last line and append the reset code to its previous line.
|
||||||
kitten icat --clear --transfer-mode=memory --unicode-placeholder --stdin=no --place="$dim@0x0" "$file" | sed '$d' | sed $'$s/$/\e[m/'
|
kitty icat --clear --transfer-mode=memory --unicode-placeholder --stdin=no --place="$dim@0x0" "$file" | sed '$d' | sed $'$s/$/\e[m/'
|
||||||
|
|
||||||
# 2. Use chafa with Sixel output
|
# 2. Use chafa with Sixel output
|
||||||
elif command -v chafa > /dev/null; then
|
elif command -v chafa > /dev/null; then
|
||||||
|
|||||||
+48
-50
@@ -8,7 +8,7 @@ fail() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
fzf="$(command which fzf)" || fzf="$(dirname "$0")/fzf"
|
fzf="$(command which fzf)" || fzf="$(dirname "$0")/fzf"
|
||||||
[[ -x $fzf ]] || fail 'fzf executable not found'
|
[[ -x "$fzf" ]] || fail 'fzf executable not found'
|
||||||
|
|
||||||
args=()
|
args=()
|
||||||
opt=""
|
opt=""
|
||||||
@@ -16,8 +16,8 @@ skip=""
|
|||||||
swap=""
|
swap=""
|
||||||
close=""
|
close=""
|
||||||
term=""
|
term=""
|
||||||
[[ -n $LINES ]] && lines=$LINES || lines=$(tput lines) || lines=$(tmux display-message -p "#{pane_height}")
|
[[ -n "$LINES" ]] && lines=$LINES || lines=$(tput lines) || lines=$(tmux display-message -p "#{pane_height}")
|
||||||
[[ -n $COLUMNS ]] && columns=$COLUMNS || columns=$(tput cols) || columns=$(tmux display-message -p "#{pane_width}")
|
[[ -n "$COLUMNS" ]] && columns=$COLUMNS || columns=$(tput cols) || columns=$(tmux display-message -p "#{pane_width}")
|
||||||
|
|
||||||
tmux_version=$(tmux -V | sed 's/[^0-9.]//g')
|
tmux_version=$(tmux -V | sed 's/[^0-9.]//g')
|
||||||
tmux_32=$(awk '{print ($1 >= 3.2)}' <<< "$tmux_version" 2> /dev/null || bc -l <<< "$tmux_version >= 3.2")
|
tmux_32=$(awk '{print ($1 >= 3.2)}' <<< "$tmux_version" 2> /dev/null || bc -l <<< "$tmux_version >= 3.2")
|
||||||
@@ -47,7 +47,7 @@ help() {
|
|||||||
while [[ $# -gt 0 ]]; do
|
while [[ $# -gt 0 ]]; do
|
||||||
arg="$1"
|
arg="$1"
|
||||||
shift
|
shift
|
||||||
[[ -z $skip ]] && case "$arg" in
|
[[ -z "$skip" ]] && case "$arg" in
|
||||||
-)
|
-)
|
||||||
term=1
|
term=1
|
||||||
;;
|
;;
|
||||||
@@ -58,19 +58,19 @@ while [[ $# -gt 0 ]]; do
|
|||||||
echo "fzf-tmux (with fzf $("$fzf" --version))"
|
echo "fzf-tmux (with fzf $("$fzf" --version))"
|
||||||
exit
|
exit
|
||||||
;;
|
;;
|
||||||
-p* | -w* | -h* | -x* | -y* | -d* | -u* | -r* | -l*)
|
-p*|-w*|-h*|-x*|-y*|-d*|-u*|-r*|-l*)
|
||||||
if [[ $arg =~ ^-[pwhxy] ]]; then
|
if [[ "$arg" =~ ^-[pwhxy] ]]; then
|
||||||
[[ $opt =~ "-E" ]] || opt="-E"
|
[[ "$opt" =~ "-E" ]] || opt="-E"
|
||||||
elif [[ $arg =~ ^.[lr] ]]; then
|
elif [[ "$arg" =~ ^.[lr] ]]; then
|
||||||
opt="-h"
|
opt="-h"
|
||||||
if [[ $arg =~ ^.l ]]; then
|
if [[ "$arg" =~ ^.l ]]; then
|
||||||
opt="$opt -d"
|
opt="$opt -d"
|
||||||
swap="; swap-pane -D ; select-pane -L"
|
swap="; swap-pane -D ; select-pane -L"
|
||||||
close="; tmux swap-pane -D"
|
close="; tmux swap-pane -D"
|
||||||
fi
|
fi
|
||||||
else
|
else
|
||||||
opt=""
|
opt=""
|
||||||
if [[ $arg =~ ^.u ]]; then
|
if [[ "$arg" =~ ^.u ]]; then
|
||||||
opt="$opt -d"
|
opt="$opt -d"
|
||||||
swap="; swap-pane -D ; select-pane -U"
|
swap="; swap-pane -D ; select-pane -U"
|
||||||
close="; tmux swap-pane -D"
|
close="; tmux swap-pane -D"
|
||||||
@@ -79,7 +79,7 @@ while [[ $# -gt 0 ]]; do
|
|||||||
if [[ ${#arg} -gt 2 ]]; then
|
if [[ ${#arg} -gt 2 ]]; then
|
||||||
size="${arg:2}"
|
size="${arg:2}"
|
||||||
else
|
else
|
||||||
if [[ $1 =~ ^[0-9%,]+$ ]] || [[ $1 =~ ^[A-Z]$ ]]; then
|
if [[ "$1" =~ ^[0-9%,]+$ ]] || [[ "$1" =~ ^[A-Z]$ ]]; then
|
||||||
size="$1"
|
size="$1"
|
||||||
shift
|
shift
|
||||||
else
|
else
|
||||||
@@ -87,37 +87,37 @@ while [[ $# -gt 0 ]]; do
|
|||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
|
|
||||||
if [[ $arg =~ ^-p ]]; then
|
if [[ "$arg" =~ ^-p ]]; then
|
||||||
if [[ -n $size ]]; then
|
if [[ -n "$size" ]]; then
|
||||||
w=${size%%,*}
|
w=${size%%,*}
|
||||||
h=${size##*,}
|
h=${size##*,}
|
||||||
opt="$opt -w$w -h$h"
|
opt="$opt -w$w -h$h"
|
||||||
fi
|
fi
|
||||||
elif [[ $arg =~ ^-[whxy] ]]; then
|
elif [[ "$arg" =~ ^-[whxy] ]]; then
|
||||||
opt="$opt ${arg:0:2}$size"
|
opt="$opt ${arg:0:2}$size"
|
||||||
elif [[ $size =~ %$ ]]; then
|
elif [[ "$size" =~ %$ ]]; then
|
||||||
size=${size:0:${#size}-1}
|
size=${size:0:((${#size}-1))}
|
||||||
if [[ $tmux_32 == 1 ]]; then
|
if [[ $tmux_32 = 1 ]]; then
|
||||||
if [[ -n $swap ]]; then
|
if [[ -n "$swap" ]]; then
|
||||||
opt="$opt -l $((100 - size))%"
|
opt="$opt -l $(( 100 - size ))%"
|
||||||
else
|
else
|
||||||
opt="$opt -l $size%"
|
opt="$opt -l $size%"
|
||||||
fi
|
fi
|
||||||
else
|
else
|
||||||
if [[ -n $swap ]]; then
|
if [[ -n "$swap" ]]; then
|
||||||
opt="$opt -p $((100 - size))"
|
opt="$opt -p $(( 100 - size ))"
|
||||||
else
|
else
|
||||||
opt="$opt -p $size"
|
opt="$opt -p $size"
|
||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
else
|
else
|
||||||
if [[ -n $swap ]]; then
|
if [[ -n "$swap" ]]; then
|
||||||
if [[ $arg =~ ^.l ]]; then
|
if [[ "$arg" =~ ^.l ]]; then
|
||||||
max=$columns
|
max=$columns
|
||||||
else
|
else
|
||||||
max=$lines
|
max=$lines
|
||||||
fi
|
fi
|
||||||
size=$((max - size))
|
size=$(( max - size ))
|
||||||
[[ $size -lt 0 ]] && size=0
|
[[ $size -lt 0 ]] && size=0
|
||||||
opt="$opt -l $size"
|
opt="$opt -l $size"
|
||||||
else
|
else
|
||||||
@@ -135,10 +135,10 @@ while [[ $# -gt 0 ]]; do
|
|||||||
args+=("$arg")
|
args+=("$arg")
|
||||||
;;
|
;;
|
||||||
esac
|
esac
|
||||||
[[ -n $skip ]] && args+=("$arg")
|
[[ -n "$skip" ]] && args+=("$arg")
|
||||||
done
|
done
|
||||||
|
|
||||||
if [[ -z $TMUX ]]; then
|
if [[ -z "$TMUX" ]]; then
|
||||||
"$fzf" "${args[@]}"
|
"$fzf" "${args[@]}"
|
||||||
exit $?
|
exit $?
|
||||||
fi
|
fi
|
||||||
@@ -149,7 +149,7 @@ fi
|
|||||||
args=("${args[@]}" "--no-height" "--bind=ctrl-z:ignore" "--no-tmux")
|
args=("${args[@]}" "--no-height" "--bind=ctrl-z:ignore" "--no-tmux")
|
||||||
|
|
||||||
# Handle zoomed tmux pane without popup options by moving it to a temp window
|
# Handle zoomed tmux pane without popup options by moving it to a temp window
|
||||||
if [[ ! $opt =~ "-E" ]] && tmux list-panes -F '#F' | grep -q Z; then
|
if [[ ! "$opt" =~ "-E" ]] && tmux list-panes -F '#F' | grep -q Z; then
|
||||||
zoomed_without_popup=1
|
zoomed_without_popup=1
|
||||||
original_window=$(tmux display-message -p "#{window_id}")
|
original_window=$(tmux display-message -p "#{window_id}")
|
||||||
tmp_window=$(tmux new-window -d -P -F "#{window_id}" "bash -c 'while :; do for c in \\| / - '\\;' do sleep 0.2; printf \"\\r\$c fzf-tmux is running\\r\"; done; done'")
|
tmp_window=$(tmux new-window -d -P -F "#{window_id}" "bash -c 'while :; do for c in \\| / - '\\;' do sleep 0.2; printf \"\\r\$c fzf-tmux is running\\r\"; done; done'")
|
||||||
@@ -159,27 +159,28 @@ fi
|
|||||||
set -e
|
set -e
|
||||||
|
|
||||||
# Clean up named pipes on exit
|
# Clean up named pipes on exit
|
||||||
tmpdir=$(mktemp -d "${TMPDIR:-/tmp}/fzf-tmux-XXXXXX")
|
id=$RANDOM
|
||||||
argsf="$tmpdir/args"
|
argsf="${TMPDIR:-/tmp}/fzf-args-$id"
|
||||||
fifo1="$tmpdir/fifo1"
|
fifo1="${TMPDIR:-/tmp}/fzf-fifo1-$id"
|
||||||
fifo2="$tmpdir/fifo2"
|
fifo2="${TMPDIR:-/tmp}/fzf-fifo2-$id"
|
||||||
fifo3="$tmpdir/fifo3"
|
fifo3="${TMPDIR:-/tmp}/fzf-fifo3-$id"
|
||||||
if tmux_win_opts=$(tmux show-options -p remain-on-exit \; show-options -p synchronize-panes 2> /dev/null); then
|
if tmux_win_opts=$(tmux show-options -p remain-on-exit \; show-options -p synchronize-panes 2> /dev/null); then
|
||||||
tmux_win_opts=($(sed '/ off/d; s/synchronize-panes/set-option -p synchronize-panes/; s/remain-on-exit/set-option -p remain-on-exit/; s/$/ \\;/' <<< "$tmux_win_opts"))
|
tmux_win_opts=( $(sed '/ off/d; s/synchronize-panes/set-option -p synchronize-panes/; s/remain-on-exit/set-option -p remain-on-exit/; s/$/ \\;/' <<< "$tmux_win_opts") )
|
||||||
tmux_off_opts='; set-option -p synchronize-panes off ; set-option -p remain-on-exit off'
|
tmux_off_opts='; set-option -p synchronize-panes off ; set-option -p remain-on-exit off'
|
||||||
else
|
else
|
||||||
tmux_win_opts=($(tmux show-window-options remain-on-exit \; show-window-options synchronize-panes | sed '/ off/d; s/^/set-window-option /; s/$/ \\;/'))
|
tmux_win_opts=( $(tmux show-window-options remain-on-exit \; show-window-options synchronize-panes | sed '/ off/d; s/^/set-window-option /; s/$/ \\;/') )
|
||||||
tmux_off_opts='; set-window-option synchronize-panes off ; set-window-option remain-on-exit off'
|
tmux_off_opts='; set-window-option synchronize-panes off ; set-window-option remain-on-exit off'
|
||||||
fi
|
fi
|
||||||
cleanup() {
|
cleanup() {
|
||||||
\rm -rf "$tmpdir"
|
\rm -f $argsf $fifo1 $fifo2 $fifo3
|
||||||
|
|
||||||
# Restore tmux window options
|
# Restore tmux window options
|
||||||
if [[ ${#tmux_win_opts[@]} -gt 1 ]]; then
|
if [[ "${#tmux_win_opts[@]}" -gt 1 ]]; then
|
||||||
eval "tmux ${tmux_win_opts[*]}"
|
eval "tmux ${tmux_win_opts[*]}"
|
||||||
fi
|
fi
|
||||||
|
|
||||||
# Remove temp window if we were zoomed without popup options
|
# Remove temp window if we were zoomed without popup options
|
||||||
if [[ -n $zoomed_without_popup ]]; then
|
if [[ -n "$zoomed_without_popup" ]]; then
|
||||||
tmux display-message -p "#{window_id}" > /dev/null
|
tmux display-message -p "#{window_id}" > /dev/null
|
||||||
tmux swap-pane -t $original_window \; \
|
tmux swap-pane -t $original_window \; \
|
||||||
select-window -t $original_window \; \
|
select-window -t $original_window \; \
|
||||||
@@ -195,11 +196,11 @@ cleanup() {
|
|||||||
trap 'cleanup 1' SIGUSR1
|
trap 'cleanup 1' SIGUSR1
|
||||||
trap 'cleanup' EXIT
|
trap 'cleanup' EXIT
|
||||||
|
|
||||||
envs="export TERM=$(printf %q "$TERM") "
|
envs="export TERM=$TERM "
|
||||||
if [[ $opt =~ "-E" ]]; then
|
if [[ "$opt" =~ "-E" ]]; then
|
||||||
if [[ $tmux_version == 3.2 ]]; then
|
if [[ $tmux_version = 3.2 ]]; then
|
||||||
FZF_DEFAULT_OPTS="--margin 0,1 $FZF_DEFAULT_OPTS"
|
FZF_DEFAULT_OPTS="--margin 0,1 $FZF_DEFAULT_OPTS"
|
||||||
elif [[ $tmux_32 == 1 ]]; then
|
elif [[ $tmux_32 = 1 ]]; then
|
||||||
FZF_DEFAULT_OPTS="--border $FZF_DEFAULT_OPTS"
|
FZF_DEFAULT_OPTS="--border $FZF_DEFAULT_OPTS"
|
||||||
opt="-B $opt"
|
opt="-B $opt"
|
||||||
else
|
else
|
||||||
@@ -210,8 +211,8 @@ fi
|
|||||||
envs="$envs FZF_DEFAULT_COMMAND=$(printf %q "$FZF_DEFAULT_COMMAND")"
|
envs="$envs FZF_DEFAULT_COMMAND=$(printf %q "$FZF_DEFAULT_COMMAND")"
|
||||||
envs="$envs FZF_DEFAULT_OPTS=$(printf %q "$FZF_DEFAULT_OPTS")"
|
envs="$envs FZF_DEFAULT_OPTS=$(printf %q "$FZF_DEFAULT_OPTS")"
|
||||||
envs="$envs FZF_DEFAULT_OPTS_FILE=$(printf %q "$FZF_DEFAULT_OPTS_FILE")"
|
envs="$envs FZF_DEFAULT_OPTS_FILE=$(printf %q "$FZF_DEFAULT_OPTS_FILE")"
|
||||||
[[ -n $RUNEWIDTH_EASTASIAN ]] && envs="$envs RUNEWIDTH_EASTASIAN=$(printf %q "$RUNEWIDTH_EASTASIAN")"
|
[[ -n "$RUNEWIDTH_EASTASIAN" ]] && envs="$envs RUNEWIDTH_EASTASIAN=$(printf %q "$RUNEWIDTH_EASTASIAN")"
|
||||||
[[ -n $BAT_THEME ]] && envs="$envs BAT_THEME=$(printf %q "$BAT_THEME")"
|
[[ -n "$BAT_THEME" ]] && envs="$envs BAT_THEME=$(printf %q "$BAT_THEME")"
|
||||||
echo "$envs;" > "$argsf"
|
echo "$envs;" > "$argsf"
|
||||||
|
|
||||||
# Build arguments to fzf
|
# Build arguments to fzf
|
||||||
@@ -223,9 +224,9 @@ close="; trap - EXIT SIGINT SIGTERM $close"
|
|||||||
|
|
||||||
export TMUX=$(cut -d , -f 1,2 <<< "$TMUX")
|
export TMUX=$(cut -d , -f 1,2 <<< "$TMUX")
|
||||||
mkfifo -m o+w $fifo2
|
mkfifo -m o+w $fifo2
|
||||||
if [[ $opt =~ "-E" ]]; then
|
if [[ "$opt" =~ "-E" ]]; then
|
||||||
cat $fifo2 &
|
cat $fifo2 &
|
||||||
if [[ -n $term ]] || [[ -t 0 ]]; then
|
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||||
cat <<< "\"$fzf\" $opts > $fifo2; out=\$? $close; exit \$out" >> $argsf
|
cat <<< "\"$fzf\" $opts > $fifo2; out=\$? $close; exit \$out" >> $argsf
|
||||||
else
|
else
|
||||||
mkfifo $fifo1
|
mkfifo $fifo1
|
||||||
@@ -238,7 +239,7 @@ if [[ $opt =~ "-E" ]]; then
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
mkfifo -m o+w $fifo3
|
mkfifo -m o+w $fifo3
|
||||||
if [[ -n $term ]] || [[ -t 0 ]]; then
|
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||||
cat <<< "\"$fzf\" $opts > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
cat <<< "\"$fzf\" $opts > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
||||||
else
|
else
|
||||||
mkfifo $fifo1
|
mkfifo $fifo1
|
||||||
@@ -248,9 +249,6 @@ fi
|
|||||||
tmux \
|
tmux \
|
||||||
split-window -c "$PWD" $opt "bash -c 'exec -a fzf bash $argsf'" $swap \
|
split-window -c "$PWD" $opt "bash -c 'exec -a fzf bash $argsf'" $swap \
|
||||||
$tmux_off_opts \
|
$tmux_off_opts \
|
||||||
> /dev/null 2>&1 || {
|
> /dev/null 2>&1 || { "$fzf" "${args[@]}"; exit $?; }
|
||||||
"$fzf" "${args[@]}"
|
|
||||||
exit $?
|
|
||||||
}
|
|
||||||
cat $fifo2
|
cat $fifo2
|
||||||
exit "$(cat $fifo3)"
|
exit "$(cat $fifo3)"
|
||||||
|
|||||||
+5
-3
@@ -112,7 +112,7 @@ the whole if we start off with `:FZF` command.
|
|||||||
" Bang version starts fzf in fullscreen mode
|
" Bang version starts fzf in fullscreen mode
|
||||||
:FZF!
|
:FZF!
|
||||||
<
|
<
|
||||||
Similarly to {ctrlp.vim}{3}, use Enter key, CTRL-T, CTRL-X or CTRL-V to open
|
Similarly to {ctrlp.vim}{3}, use enter key, CTRL-T, CTRL-X or CTRL-V to open
|
||||||
selected files in the current window, in new tabs, in horizontal splits, or in
|
selected files in the current window, in new tabs, in horizontal splits, or in
|
||||||
vertical splits respectively.
|
vertical splits respectively.
|
||||||
|
|
||||||
@@ -218,6 +218,7 @@ list:
|
|||||||
`fg` / `bg` / `hl` | Item (foreground / background / highlight)
|
`fg` / `bg` / `hl` | Item (foreground / background / highlight)
|
||||||
`fg+` / `bg+` / `hl+` | Current item (foreground / background / highlight)
|
`fg+` / `bg+` / `hl+` | Current item (foreground / background / highlight)
|
||||||
`preview-fg` / `preview-bg` | Preview window text and background
|
`preview-fg` / `preview-bg` | Preview window text and background
|
||||||
|
`hl` / `hl+` | Highlighted substrings (normal / current)
|
||||||
`gutter` | Background of the gutter on the left
|
`gutter` | Background of the gutter on the left
|
||||||
`pointer` | Pointer to the current line ( `>` )
|
`pointer` | Pointer to the current line ( `>` )
|
||||||
`marker` | Multi-select marker ( `>` )
|
`marker` | Multi-select marker ( `>` )
|
||||||
@@ -228,6 +229,7 @@ list:
|
|||||||
`query` | Query string
|
`query` | Query string
|
||||||
`disabled` | Query string when search is disabled
|
`disabled` | Query string when search is disabled
|
||||||
`prompt` | Prompt before query ( `> ` )
|
`prompt` | Prompt before query ( `> ` )
|
||||||
|
`pointer` | Pointer to the current line ( `>` )
|
||||||
----------------------------+------------------------------------------------------
|
----------------------------+------------------------------------------------------
|
||||||
- `component` specifies the component (`fg` / `bg`) from which to extract the
|
- `component` specifies the component (`fg` / `bg`) from which to extract the
|
||||||
color when considering each of the following highlight groups
|
color when considering each of the following highlight groups
|
||||||
@@ -243,7 +245,7 @@ if it exists, - otherwise use the `fg` attribute of the `Comment` highlight
|
|||||||
group if it exists, - otherwise fall back to the default color settings for
|
group if it exists, - otherwise fall back to the default color settings for
|
||||||
the prompt.
|
the prompt.
|
||||||
|
|
||||||
You can examine the color option generated according to the setting by printing
|
You can examine the color option generated according the setting by printing
|
||||||
the result of `fzf#wrap()` function like so:
|
the result of `fzf#wrap()` function like so:
|
||||||
>
|
>
|
||||||
:echo fzf#wrap()
|
:echo fzf#wrap()
|
||||||
@@ -501,7 +503,7 @@ LICENSE *fzf-license*
|
|||||||
|
|
||||||
The MIT License (MIT)
|
The MIT License (MIT)
|
||||||
|
|
||||||
Copyright (c) 2013-2026 Junegunn Choi
|
Copyright (c) 2013-2024 Junegunn Choi
|
||||||
|
|
||||||
==============================================================================
|
==============================================================================
|
||||||
vim:tw=78:sw=2:ts=2:ft=help:norl:nowrap:
|
vim:tw=78:sw=2:ts=2:ft=help:norl:nowrap:
|
||||||
|
|||||||
@@ -1,20 +1,20 @@
|
|||||||
module github.com/junegunn/fzf
|
module github.com/junegunn/fzf
|
||||||
|
|
||||||
require (
|
require (
|
||||||
github.com/charlievieth/fastwalk v1.0.14
|
github.com/charlievieth/fastwalk v1.0.8
|
||||||
github.com/gdamore/tcell/v2 v2.9.0
|
github.com/gdamore/tcell/v2 v2.7.4
|
||||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741
|
github.com/junegunn/go-shellwords v0.0.0-20240813092932-a62c48c52e97
|
||||||
github.com/mattn/go-isatty v0.0.22
|
github.com/mattn/go-isatty v0.0.20
|
||||||
github.com/rivo/uniseg v0.4.7
|
github.com/rivo/uniseg v0.4.7
|
||||||
golang.org/x/sys v0.35.0
|
golang.org/x/sys v0.25.0
|
||||||
golang.org/x/term v0.34.0
|
golang.org/x/term v0.24.0
|
||||||
)
|
)
|
||||||
|
|
||||||
require (
|
require (
|
||||||
github.com/gdamore/encoding v1.0.1 // indirect
|
github.com/gdamore/encoding v1.0.0 // indirect
|
||||||
github.com/lucasb-eyer/go-colorful v1.2.0 // indirect
|
github.com/lucasb-eyer/go-colorful v1.2.0 // indirect
|
||||||
github.com/mattn/go-runewidth v0.0.16 // indirect
|
github.com/mattn/go-runewidth v0.0.15 // indirect
|
||||||
golang.org/x/text v0.28.0 // indirect
|
golang.org/x/text v0.14.0 // indirect
|
||||||
)
|
)
|
||||||
|
|
||||||
go 1.23.0
|
go 1.20
|
||||||
|
|||||||
@@ -1,18 +1,19 @@
|
|||||||
github.com/charlievieth/fastwalk v1.0.14 h1:3Eh5uaFGwHZd8EGwTjJnSpBkfwfsak9h6ICgnWlhAyg=
|
github.com/charlievieth/fastwalk v1.0.8 h1:uaoH6cAKSk73aK7aKXqs0+bL+J3Txzd3NGH8tRXgHko=
|
||||||
github.com/charlievieth/fastwalk v1.0.14/go.mod h1:diVcUreiU1aQ4/Wu3NbxxH4/KYdKpLDojrQ1Bb2KgNY=
|
github.com/charlievieth/fastwalk v1.0.8/go.mod h1:yGy1zbxog41ZVMcKA/i8ojXLFsuayX5VvwhQVoj9PBI=
|
||||||
github.com/gdamore/encoding v1.0.1 h1:YzKZckdBL6jVt2Gc+5p82qhrGiqMdG/eNs6Wy0u3Uhw=
|
github.com/gdamore/encoding v1.0.0 h1:+7OoQ1Bc6eTm5niUzBa0Ctsh6JbMW6Ra+YNuAtDBdko=
|
||||||
github.com/gdamore/encoding v1.0.1/go.mod h1:0Z0cMFinngz9kS1QfMjCP8TY7em3bZYeeklsSDPivEo=
|
github.com/gdamore/encoding v1.0.0/go.mod h1:alR0ol34c49FCSBLjhosxzcPHQbf2trDkoo5dl+VrEg=
|
||||||
github.com/gdamore/tcell/v2 v2.9.0 h1:N6t+eqK7/xwtRPwxzs1PXeRWnm0H9l02CrgJ7DLn1ys=
|
github.com/gdamore/tcell/v2 v2.7.4 h1:sg6/UnTM9jGpZU+oFYAsDahfchWAFW8Xx2yFinNSAYU=
|
||||||
github.com/gdamore/tcell/v2 v2.9.0/go.mod h1:8/ZoqM9rxzYphT9tH/9LnunhV9oPBqwS8WHGYm5nrmo=
|
github.com/gdamore/tcell/v2 v2.7.4/go.mod h1:dSXtXTSK0VsW1biw65DZLZ2NKr7j0qP/0J7ONmsraWg=
|
||||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741 h1:7dYDtfMDfKzjT+DVfIS4iqknSEKtZpEcXtu6vuaasHs=
|
github.com/junegunn/go-shellwords v0.0.0-20240813092932-a62c48c52e97 h1:rqzLixVo1c/GQW6px9j1xQmlvQIn+lf/V6M1UQ7IFzw=
|
||||||
github.com/junegunn/go-shellwords v0.0.0-20250127100254-2aa3b3277741/go.mod h1:6EILKtGpo5t+KLb85LNZLAF6P9LKp78hJI80PXMcn3c=
|
github.com/junegunn/go-shellwords v0.0.0-20240813092932-a62c48c52e97/go.mod h1:6EILKtGpo5t+KLb85LNZLAF6P9LKp78hJI80PXMcn3c=
|
||||||
github.com/lucasb-eyer/go-colorful v1.2.0 h1:1nnpGOrhyZZuNyfu1QjKiUICQ74+3FNCN69Aj6K7nkY=
|
github.com/lucasb-eyer/go-colorful v1.2.0 h1:1nnpGOrhyZZuNyfu1QjKiUICQ74+3FNCN69Aj6K7nkY=
|
||||||
github.com/lucasb-eyer/go-colorful v1.2.0/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
github.com/lucasb-eyer/go-colorful v1.2.0/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
||||||
github.com/mattn/go-isatty v0.0.22 h1:j8l17JJ9i6VGPUFUYoTUKPSgKe/83EYU2zBC7YNKMw4=
|
github.com/mattn/go-isatty v0.0.20 h1:xfD0iDuEKnDkl03q4limB+vH+GxLEtL/jb4xVJSWWEY=
|
||||||
github.com/mattn/go-isatty v0.0.22/go.mod h1:ZXfXG4SQHsB/w3ZeOYbR0PrPwLy+n6xiMrJlRFqopa4=
|
github.com/mattn/go-isatty v0.0.20/go.mod h1:W+V8PltTTMOvKvAeJH7IuucS94S2C6jfK/D7dTCTo3Y=
|
||||||
github.com/mattn/go-runewidth v0.0.16 h1:E5ScNMtiwvlvB5paMFdw9p4kSQzbXFikJ5SQO6TULQc=
|
github.com/mattn/go-runewidth v0.0.15 h1:UNAjwbU9l54TA3KzvqLGxwWjHmMgBUVhBiTjelZgg3U=
|
||||||
github.com/mattn/go-runewidth v0.0.16/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
github.com/mattn/go-runewidth v0.0.15/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
||||||
github.com/rivo/uniseg v0.2.0/go.mod h1:J6wj4VEh+S6ZtnVlnTBMWIodfgj8LQOQFoIToxlJtxc=
|
github.com/rivo/uniseg v0.2.0/go.mod h1:J6wj4VEh+S6ZtnVlnTBMWIodfgj8LQOQFoIToxlJtxc=
|
||||||
|
github.com/rivo/uniseg v0.4.3/go.mod h1:FN3SvrM+Zdj16jyLfmOkMNblXMcoc8DfTHruCPUcx88=
|
||||||
github.com/rivo/uniseg v0.4.7 h1:WUdvkW8uEhrYfLC4ZzdpI2ztxP1I582+49Oc5Mq64VQ=
|
github.com/rivo/uniseg v0.4.7 h1:WUdvkW8uEhrYfLC4ZzdpI2ztxP1I582+49Oc5Mq64VQ=
|
||||||
github.com/rivo/uniseg v0.4.7/go.mod h1:FN3SvrM+Zdj16jyLfmOkMNblXMcoc8DfTHruCPUcx88=
|
github.com/rivo/uniseg v0.4.7/go.mod h1:FN3SvrM+Zdj16jyLfmOkMNblXMcoc8DfTHruCPUcx88=
|
||||||
github.com/yuin/goldmark v1.4.13/go.mod h1:6yULJ656Px+3vBD8DxQVa3kxgyrAnzto9xy5taEt/CY=
|
github.com/yuin/goldmark v1.4.13/go.mod h1:6yULJ656Px+3vBD8DxQVa3kxgyrAnzto9xy5taEt/CY=
|
||||||
@@ -33,20 +34,22 @@ golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBc
|
|||||||
golang.org/x/sys v0.0.0-20220520151302-bc2c85ada10a/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
golang.org/x/sys v0.0.0-20220520151302-bc2c85ada10a/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
golang.org/x/sys v0.35.0 h1:vz1N37gP5bs89s7He8XuIYXpyY0+QlsKmzipCbUtyxI=
|
golang.org/x/sys v0.6.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
golang.org/x/sys v0.35.0/go.mod h1:BJP2sWEmIv4KK5OTEluFJCKSidICx8ciO85XgH3Ak8k=
|
golang.org/x/sys v0.17.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA=
|
||||||
|
golang.org/x/sys v0.25.0 h1:r+8e+loiHxRqhXVl6ML1nO3l1+oFoWbnlu2Ehimmi34=
|
||||||
|
golang.org/x/sys v0.25.0/go.mod h1:/VUhepiaJMQUp4+oa/7Zr1D23ma6VTLIYjOOTFZPUcA=
|
||||||
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||||
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
|
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
|
||||||
golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
|
golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
|
||||||
golang.org/x/term v0.34.0 h1:O/2T7POpk0ZZ7MAzMeWFSg6S5IpWd/RXDlM9hgM3DR4=
|
golang.org/x/term v0.17.0/go.mod h1:lLRBjIVuehSbZlaOtGMbcMncT+aqLLLmKrsjNrUguwk=
|
||||||
golang.org/x/term v0.34.0/go.mod h1:5jC53AEywhIVebHgPVeg0mj8OD3VO9OzclacVrqpaAw=
|
golang.org/x/term v0.24.0 h1:Mh5cbb+Zk2hqqXNO7S1iTjEphVL+jb8ZWaqh/g+JWkM=
|
||||||
|
golang.org/x/term v0.24.0/go.mod h1:lOBK/LVxemqiMij05LGJ0tzNr8xlmwBRJ81PX6wVLH8=
|
||||||
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||||
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||||
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
||||||
golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
||||||
|
golang.org/x/text v0.14.0 h1:ScX5w1eTa3QqT8oi6+ziP7dTV1S2+ALU0bI+0zXKWiQ=
|
||||||
golang.org/x/text v0.14.0/go.mod h1:18ZOQIKpY8NJVqYksKHtTdi31H5itFRjB5/qKTNYzSU=
|
golang.org/x/text v0.14.0/go.mod h1:18ZOQIKpY8NJVqYksKHtTdi31H5itFRjB5/qKTNYzSU=
|
||||||
golang.org/x/text v0.28.0 h1:rhazDwis8INMIwQ4tpjLDzUhx6RlXqZNPEM0huQojng=
|
|
||||||
golang.org/x/text v0.28.0/go.mod h1:U8nCwOR8jO/marOQ0QbDiOngZVEBB7MAiitBuMjXiNU=
|
|
||||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||||
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
|
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
|
||||||
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
||||||
|
|||||||
@@ -2,11 +2,11 @@
|
|||||||
|
|
||||||
set -u
|
set -u
|
||||||
|
|
||||||
version=0.73.1
|
version=0.55.0
|
||||||
auto_completion=
|
auto_completion=
|
||||||
key_bindings=
|
key_bindings=
|
||||||
update_config=2
|
update_config=2
|
||||||
shells="bash zsh fish nushell"
|
shells="bash zsh fish"
|
||||||
prefix='~/.fzf'
|
prefix='~/.fzf'
|
||||||
prefix_expand=~/.fzf
|
prefix_expand=~/.fzf
|
||||||
fish_dir=${XDG_CONFIG_HOME:-$HOME/.config}/fish
|
fish_dir=${XDG_CONFIG_HOME:-$HOME/.config}/fish
|
||||||
@@ -27,7 +27,6 @@ usage: $0 [OPTIONS]
|
|||||||
--no-bash Do not set up bash configuration
|
--no-bash Do not set up bash configuration
|
||||||
--no-zsh Do not set up zsh configuration
|
--no-zsh Do not set up zsh configuration
|
||||||
--no-fish Do not set up fish configuration
|
--no-fish Do not set up fish configuration
|
||||||
--no-nushell Do not set up nushell configuration
|
|
||||||
EOF
|
EOF
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -47,17 +46,16 @@ for opt in "$@"; do
|
|||||||
prefix_expand=${XDG_CONFIG_HOME:-$HOME/.config}/fzf/fzf
|
prefix_expand=${XDG_CONFIG_HOME:-$HOME/.config}/fzf/fzf
|
||||||
mkdir -p "${XDG_CONFIG_HOME:-$HOME/.config}/fzf"
|
mkdir -p "${XDG_CONFIG_HOME:-$HOME/.config}/fzf"
|
||||||
;;
|
;;
|
||||||
--key-bindings) key_bindings=1 ;;
|
--key-bindings) key_bindings=1 ;;
|
||||||
--no-key-bindings) key_bindings=0 ;;
|
--no-key-bindings) key_bindings=0 ;;
|
||||||
--completion) auto_completion=1 ;;
|
--completion) auto_completion=1 ;;
|
||||||
--no-completion) auto_completion=0 ;;
|
--no-completion) auto_completion=0 ;;
|
||||||
--update-rc) update_config=1 ;;
|
--update-rc) update_config=1 ;;
|
||||||
--no-update-rc) update_config=0 ;;
|
--no-update-rc) update_config=0 ;;
|
||||||
--bin) ;;
|
--bin) ;;
|
||||||
--no-bash) shells=${shells/bash/} ;;
|
--no-bash) shells=${shells/bash/} ;;
|
||||||
--no-zsh) shells=${shells/zsh/} ;;
|
--no-zsh) shells=${shells/zsh/} ;;
|
||||||
--no-fish) shells=${shells/fish/} ;;
|
--no-fish) shells=${shells/fish/} ;;
|
||||||
--no-nushell) shells=${shells/nushell/} ;;
|
|
||||||
*)
|
*)
|
||||||
echo "unknown option: $opt"
|
echo "unknown option: $opt"
|
||||||
help
|
help
|
||||||
@@ -85,7 +83,7 @@ ask() {
|
|||||||
check_binary() {
|
check_binary() {
|
||||||
echo -n " - Checking fzf executable ... "
|
echo -n " - Checking fzf executable ... "
|
||||||
local output
|
local output
|
||||||
output=$(FZF_DEFAULT_OPTS= "$fzf_base"/bin/fzf --version 2>&1)
|
output=$("$fzf_base"/bin/fzf --version 2>&1)
|
||||||
if [ $? -ne 0 ]; then
|
if [ $? -ne 0 ]; then
|
||||||
echo "Error: $output"
|
echo "Error: $output"
|
||||||
binary_error="Invalid binary"
|
binary_error="Invalid binary"
|
||||||
@@ -106,7 +104,7 @@ check_binary() {
|
|||||||
|
|
||||||
link_fzf_in_path() {
|
link_fzf_in_path() {
|
||||||
if which_fzf="$(command -v fzf)"; then
|
if which_fzf="$(command -v fzf)"; then
|
||||||
echo ' - Found in $PATH'
|
echo " - Found in \$PATH"
|
||||||
echo " - Creating symlink: bin/fzf -> $which_fzf"
|
echo " - Creating symlink: bin/fzf -> $which_fzf"
|
||||||
(cd "$fzf_base"/bin && rm -f fzf && ln -sf "$which_fzf" fzf)
|
(cd "$fzf_base"/bin && rm -f fzf && ln -sf "$which_fzf" fzf)
|
||||||
check_binary && return
|
check_binary && return
|
||||||
@@ -114,29 +112,24 @@ link_fzf_in_path() {
|
|||||||
return 1
|
return 1
|
||||||
}
|
}
|
||||||
|
|
||||||
tar_opts="-xzf -"
|
|
||||||
if tar --no-same-owner -tf /dev/null 2> /dev/null; then
|
|
||||||
tar_opts="--no-same-owner $tar_opts"
|
|
||||||
fi
|
|
||||||
|
|
||||||
try_curl() {
|
try_curl() {
|
||||||
command -v curl > /dev/null &&
|
command -v curl > /dev/null &&
|
||||||
if [[ $1 =~ tar.gz$ ]]; then
|
if [[ $1 =~ tar.gz$ ]]; then
|
||||||
curl -fL $1 | tar $tar_opts
|
curl -fL $1 | tar --no-same-owner -xzf -
|
||||||
else
|
else
|
||||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||||
curl -fLo "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
curl -fLo "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||||
fi
|
fi
|
||||||
}
|
}
|
||||||
|
|
||||||
try_wget() {
|
try_wget() {
|
||||||
command -v wget > /dev/null &&
|
command -v wget > /dev/null &&
|
||||||
if [[ $1 =~ tar.gz$ ]]; then
|
if [[ $1 =~ tar.gz$ ]]; then
|
||||||
wget -O - $1 | tar $tar_opts
|
wget -O - $1 | tar --no-same-owner -xzf -
|
||||||
else
|
else
|
||||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||||
wget -O "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
wget -O "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||||
fi
|
fi
|
||||||
}
|
}
|
||||||
|
|
||||||
download() {
|
download() {
|
||||||
@@ -171,30 +164,28 @@ download() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
# Try to download binary executable
|
# Try to download binary executable
|
||||||
archi=$(uname -smo 2> /dev/null || uname -sm)
|
archi=$(uname -sm)
|
||||||
binary_available=1
|
binary_available=1
|
||||||
binary_error=""
|
binary_error=""
|
||||||
case "$archi" in
|
case "$archi" in
|
||||||
Darwin\ arm64*) download fzf-$version-darwin_arm64.tar.gz ;;
|
Darwin\ arm64) download fzf-$version-darwin_arm64.tar.gz ;;
|
||||||
Darwin\ x86_64*) download fzf-$version-darwin_amd64.tar.gz ;;
|
Darwin\ x86_64) download fzf-$version-darwin_amd64.tar.gz ;;
|
||||||
Linux\ armv5*) download fzf-$version-linux_armv5.tar.gz ;;
|
Linux\ armv5*) download fzf-$version-linux_armv5.tar.gz ;;
|
||||||
Linux\ armv6*) download fzf-$version-linux_armv6.tar.gz ;;
|
Linux\ armv6*) download fzf-$version-linux_armv6.tar.gz ;;
|
||||||
Linux\ armv7*) download fzf-$version-linux_armv7.tar.gz ;;
|
Linux\ armv7*) download fzf-$version-linux_armv7.tar.gz ;;
|
||||||
Linux\ armv8*) download fzf-$version-linux_arm64.tar.gz ;;
|
Linux\ armv8*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||||
Linux\ aarch64\ Android) download fzf-$version-android_arm64.tar.gz ;;
|
Linux\ aarch64*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||||
Linux\ aarch64*) download fzf-$version-linux_arm64.tar.gz ;;
|
Linux\ loongarch64) download fzf-$version-linux_loong64.tar.gz ;;
|
||||||
Linux\ loongarch64*) download fzf-$version-linux_loong64.tar.gz ;;
|
Linux\ ppc64le) download fzf-$version-linux_ppc64le.tar.gz ;;
|
||||||
Linux\ riscv64*) download fzf-$version-linux_riscv64.tar.gz ;;
|
Linux\ *64) download fzf-$version-linux_amd64.tar.gz ;;
|
||||||
Linux\ ppc64le*) download fzf-$version-linux_ppc64le.tar.gz ;;
|
Linux\ s390x) download fzf-$version-linux_s390x.tar.gz ;;
|
||||||
Linux\ *64*) download fzf-$version-linux_amd64.tar.gz ;;
|
FreeBSD\ *64) download fzf-$version-freebsd_amd64.tar.gz ;;
|
||||||
Linux\ s390x*) download fzf-$version-linux_s390x.tar.gz ;;
|
OpenBSD\ *64) download fzf-$version-openbsd_amd64.tar.gz ;;
|
||||||
FreeBSD\ *64*) download fzf-$version-freebsd_amd64.tar.gz ;;
|
CYGWIN*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||||
OpenBSD\ *64*) download fzf-$version-openbsd_amd64.tar.gz ;;
|
MINGW*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||||
CYGWIN*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
MSYS*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||||
MINGW*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
Windows*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||||
MSYS*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
*) binary_available=0 binary_error=1 ;;
|
||||||
Windows*\ *64*) download fzf-$version-windows_amd64.zip ;;
|
|
||||||
*) binary_available=0 binary_error=1 ;;
|
|
||||||
esac
|
esac
|
||||||
|
|
||||||
cd "$fzf_base"
|
cd "$fzf_base"
|
||||||
@@ -223,17 +214,15 @@ if [ -n "$binary_error" ]; then
|
|||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
|
|
||||||
[[ $* =~ "--bin" ]] && exit 0
|
[[ "$*" =~ "--bin" ]] && exit 0
|
||||||
|
|
||||||
for s in $shells; do
|
for s in $shells; do
|
||||||
bin=$s
|
if ! command -v "$s" > /dev/null; then
|
||||||
[[ $s == nushell ]] && bin=nu
|
|
||||||
if ! command -v "$bin" > /dev/null; then
|
|
||||||
shells=${shells/$s/}
|
shells=${shells/$s/}
|
||||||
fi
|
fi
|
||||||
done
|
done
|
||||||
|
|
||||||
if [[ -z ${shells// /} ]]; then
|
if [[ ${#shells} -lt 3 ]]; then
|
||||||
echo "No shell configuration to be updated."
|
echo "No shell configuration to be updated."
|
||||||
exit 0
|
exit 0
|
||||||
fi
|
fi
|
||||||
@@ -252,17 +241,16 @@ fi
|
|||||||
|
|
||||||
echo
|
echo
|
||||||
for shell in $shells; do
|
for shell in $shells; do
|
||||||
[[ $shell == nushell ]] && continue
|
[[ "$shell" = fish ]] && continue
|
||||||
fzf_completion="source \"$fzf_base/shell/completion.${shell}\""
|
|
||||||
fzf_key_bindings="source \"$fzf_base/shell/key-bindings.${shell}\""
|
|
||||||
[[ $shell == fish ]] && continue
|
|
||||||
src=${prefix_expand}.${shell}
|
src=${prefix_expand}.${shell}
|
||||||
echo -n "Generate $src ... "
|
echo -n "Generate $src ... "
|
||||||
|
|
||||||
|
fzf_completion="source \"$fzf_base/shell/completion.${shell}\""
|
||||||
if [ $auto_completion -eq 0 ]; then
|
if [ $auto_completion -eq 0 ]; then
|
||||||
fzf_completion="# $fzf_completion"
|
fzf_completion="# $fzf_completion"
|
||||||
fi
|
fi
|
||||||
|
|
||||||
|
fzf_key_bindings="source \"$fzf_base/shell/key-bindings.${shell}\""
|
||||||
if [ $key_bindings -eq 0 ]; then
|
if [ $key_bindings -eq 0 ]; then
|
||||||
fzf_key_bindings="# $fzf_key_bindings"
|
fzf_key_bindings="# $fzf_key_bindings"
|
||||||
fi
|
fi
|
||||||
@@ -277,7 +265,7 @@ fi
|
|||||||
EOF
|
EOF
|
||||||
|
|
||||||
if [[ $auto_completion -eq 1 ]] && [[ $key_bindings -eq 1 ]]; then
|
if [[ $auto_completion -eq 1 ]] && [[ $key_bindings -eq 1 ]]; then
|
||||||
if [[ $shell == zsh ]]; then
|
if [[ "$shell" = zsh ]]; then
|
||||||
echo "source <(fzf --$shell)" >> "$src"
|
echo "source <(fzf --$shell)" >> "$src"
|
||||||
else
|
else
|
||||||
echo "eval \"\$(fzf --$shell)\"" >> "$src"
|
echo "eval \"\$(fzf --$shell)\"" >> "$src"
|
||||||
@@ -297,7 +285,7 @@ EOF
|
|||||||
done
|
done
|
||||||
|
|
||||||
# fish
|
# fish
|
||||||
if [[ $shells =~ fish ]]; then
|
if [[ "$shells" =~ fish ]]; then
|
||||||
echo -n "Update fish_user_paths ... "
|
echo -n "Update fish_user_paths ... "
|
||||||
fish << EOF
|
fish << EOF
|
||||||
echo \$fish_user_paths | \grep "$fzf_base"/bin > /dev/null
|
echo \$fish_user_paths | \grep "$fzf_base"/bin > /dev/null
|
||||||
@@ -307,49 +295,35 @@ EOF
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
append_line() {
|
append_line() {
|
||||||
local update line file pat lines
|
set -e
|
||||||
|
|
||||||
|
local update line file pat lno
|
||||||
update="$1"
|
update="$1"
|
||||||
line="$2"
|
line="$2"
|
||||||
file="$3"
|
file="$3"
|
||||||
pat="${4:-}"
|
pat="${4:-}"
|
||||||
at_lno="${5:-}"
|
lno=""
|
||||||
lines=""
|
|
||||||
|
|
||||||
echo "Update $file:"
|
echo "Update $file:"
|
||||||
echo " - $line"
|
echo " - $line"
|
||||||
if [ -f "$file" ]; then
|
if [ -f "$file" ]; then
|
||||||
if [[ -n $pat ]]; then
|
if [ $# -lt 4 ]; then
|
||||||
lines=$(\grep -nF "$pat" "$file")
|
lno=$(\grep -nF "$line" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||||
else
|
else
|
||||||
lines=$(\grep -nF "${line#"${line%%[![:space:]]*}"}" "$file")
|
lno=$(\grep -nF "$pat" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
|
if [ -n "$lno" ]; then
|
||||||
if [ -n "$lines" ]; then
|
echo " - Already exists: line #$lno"
|
||||||
echo " - Already exists:"
|
else
|
||||||
sed 's/^/ Line /' <<< "$lines"
|
if [ $update -eq 1 ]; then
|
||||||
|
|
||||||
update=0
|
|
||||||
if ! \grep -qv "^[0-9]*:[[:space:]]*#" <<< "$lines"; then
|
|
||||||
echo " - But they all seem to be commented"
|
|
||||||
ask " - Continue modifying $file?"
|
|
||||||
update=$?
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
set -e
|
|
||||||
if [ "$update" -eq 1 ]; then
|
|
||||||
if [[ -z $at_lno ]]; then
|
|
||||||
[ -f "$file" ] && echo >> "$file"
|
[ -f "$file" ] && echo >> "$file"
|
||||||
echo "$line" >> "$file"
|
echo "$line" >> "$file"
|
||||||
|
echo " + Added"
|
||||||
else
|
else
|
||||||
sed -i.~fzf_bak "${at_lno}a\\"$'\n'"$line" "$file" && rm "$file.~fzf_bak"
|
echo " ~ Skipped"
|
||||||
fi
|
fi
|
||||||
echo " + Added"
|
|
||||||
else
|
|
||||||
echo " ~ Skipped"
|
|
||||||
fi
|
fi
|
||||||
|
|
||||||
echo
|
echo
|
||||||
set +e
|
set +e
|
||||||
}
|
}
|
||||||
@@ -372,105 +346,43 @@ if [ $update_config -eq 2 ]; then
|
|||||||
fi
|
fi
|
||||||
echo
|
echo
|
||||||
for shell in $shells; do
|
for shell in $shells; do
|
||||||
[[ $shell == fish ]] && continue
|
[[ "$shell" = fish ]] && continue
|
||||||
[[ $shell == nushell ]] && continue
|
|
||||||
[ $shell = zsh ] && dest=${ZDOTDIR:-~}/.zshrc || dest=~/.bashrc
|
[ $shell = zsh ] && dest=${ZDOTDIR:-~}/.zshrc || dest=~/.bashrc
|
||||||
append_line $update_config "[ -f ${prefix}.${shell} ] && source ${prefix}.${shell}" "$dest" "${prefix}.${shell}"
|
append_line $update_config "[ -f ${prefix}.${shell} ] && source ${prefix}.${shell}" "$dest" "${prefix}.${shell}"
|
||||||
done
|
done
|
||||||
|
|
||||||
if [[ $shells =~ fish ]]; then
|
if [ $key_bindings -eq 1 ] && [[ "$shells" =~ fish ]]; then
|
||||||
bind_file="${fish_dir}/functions/fish_user_key_bindings.fish"
|
bind_file="${fish_dir}/functions/fish_user_key_bindings.fish"
|
||||||
if [ ! -e "$bind_file" ]; then
|
if [ ! -e "$bind_file" ]; then
|
||||||
if [[ $key_bindings -eq 1 || $auto_completion -eq 1 ]]; then
|
mkdir -p "${fish_dir}/functions"
|
||||||
mkdir -p "${fish_dir}/functions"
|
create_file "$bind_file" \
|
||||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
'function fish_user_key_bindings' \
|
||||||
create_file "$bind_file" \
|
' fzf --fish | source' \
|
||||||
'function fish_user_key_bindings' \
|
'end'
|
||||||
' fzf --fish | source' \
|
|
||||||
'end'
|
|
||||||
elif [[ $key_bindings -eq 1 ]]; then
|
|
||||||
create_file "$bind_file" \
|
|
||||||
'function fish_user_key_bindings' \
|
|
||||||
" $fzf_key_bindings" \
|
|
||||||
'end'
|
|
||||||
elif [[ $auto_completion -eq 1 ]]; then
|
|
||||||
create_file "$bind_file" \
|
|
||||||
'function fish_user_key_bindings' \
|
|
||||||
" $fzf_completion" \
|
|
||||||
'end'
|
|
||||||
fi
|
|
||||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
|
||||||
else
|
|
||||||
lno_func=0
|
|
||||||
fi
|
|
||||||
else
|
else
|
||||||
echo "Check $bind_file:"
|
echo "Check $bind_file:"
|
||||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
lno=$(\grep -nF "fzf_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
||||||
if [[ -z $lno_func ]]; then
|
if [[ -n $lno ]]; then
|
||||||
echo -e "function fish_user_key_bindings\nend" >> "$bind_file"
|
echo " ** Found 'fzf_key_bindings' in line #$lno"
|
||||||
lno_func=$(\grep -nF "function fish_user_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
echo " ** You have to replace the line to 'fzf --fish | source'"
|
||||||
fi
|
|
||||||
lno_keys=$(\grep -nF "fzf_key_bindings" "$bind_file" | sed 's/:.*//' | tr '\n' ' ')
|
|
||||||
if [[ -n $lno_keys ]]; then
|
|
||||||
echo " ** Found 'fzf_key_bindings' in line #$lno_keys"
|
|
||||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
|
||||||
echo " ** You have to replace the line to 'fzf --fish | source'"
|
|
||||||
elif [[ $key_bindings -eq 1 ]]; then
|
|
||||||
echo " ** You have to replace the line to '$fzf_key_bindings'"
|
|
||||||
else
|
|
||||||
echo " ** You have to remove the line"
|
|
||||||
fi
|
|
||||||
echo
|
echo
|
||||||
else
|
else
|
||||||
echo " - Clear"
|
echo " - Clear"
|
||||||
echo
|
echo
|
||||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
append_line $update_config "fzf --fish | source" "$bind_file"
|
||||||
sed -i.~fzf_bak "\#$fzf_completion#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
|
||||||
sed -i.~fzf_bak "\#$fzf_key_bindings#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
|
||||||
append_line $update_config " fzf --fish | source" "$bind_file" "" "$lno_func"
|
|
||||||
else
|
|
||||||
sed -i.~fzf_bak '/fzf --fish \| source/d' "$bind_file" && rm "$bind_file.~fzf_bak"
|
|
||||||
if [[ $key_bindings -eq 1 ]]; then
|
|
||||||
sed -i.~fzf_bak "\#$fzf_completion#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
|
||||||
append_line $update_config " $fzf_key_bindings" "$bind_file" "" "$lno_func"
|
|
||||||
elif [[ $auto_completion -eq 1 ]]; then
|
|
||||||
sed -i.~fzf_bak "\#$fzf_key_bindings#d" "$bind_file" && rm "$bind_file.~fzf_bak"
|
|
||||||
append_line $update_config " $fzf_completion" "$bind_file" "" "$lno_func"
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
|
|
||||||
if [[ $shells =~ nushell ]]; then
|
|
||||||
if [[ $key_bindings -eq 1 || $auto_completion -eq 1 ]]; then
|
|
||||||
echo "Setting up Nushell integration ..."
|
|
||||||
nushell_autoload_dir=$(nu -c '$nu.user-autoload-dirs | first')
|
|
||||||
mkdir -p "$nushell_autoload_dir"
|
|
||||||
dest="$nushell_autoload_dir/_fzf_integration.nu"
|
|
||||||
echo -n " Generate $dest ... "
|
|
||||||
if [[ $key_bindings -eq 1 && $auto_completion -eq 1 ]]; then
|
|
||||||
"$fzf_base"/bin/fzf --nushell > "$dest"
|
|
||||||
elif [[ $key_bindings -eq 1 ]]; then
|
|
||||||
cp "$fzf_base/shell/key-bindings.nu" "$dest"
|
|
||||||
else
|
|
||||||
cp "$fzf_base/shell/completion.nu" "$dest"
|
|
||||||
fi
|
|
||||||
echo "OK"
|
|
||||||
echo
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ $update_config -eq 1 ]; then
|
if [ $update_config -eq 1 ]; then
|
||||||
echo 'Finished. Restart your shell or reload config file.'
|
echo 'Finished. Restart your shell or reload config file.'
|
||||||
if [[ $shells =~ bash ]]; then
|
if [[ "$shells" =~ bash ]]; then
|
||||||
echo -n ' source ~/.bashrc # bash'
|
echo -n ' source ~/.bashrc # bash'
|
||||||
[[ $archi =~ Darwin ]] && echo -n ' (.bashrc should be loaded from .bash_profile)'
|
[[ "$archi" =~ Darwin ]] && echo -n ' (.bashrc should be loaded from .bash_profile)'
|
||||||
echo
|
echo
|
||||||
fi
|
fi
|
||||||
[[ $shells =~ zsh ]] && echo " source ${ZDOTDIR:-~}/.zshrc # zsh"
|
[[ "$shells" =~ zsh ]] && echo " source ${ZDOTDIR:-~}/.zshrc # zsh"
|
||||||
[[ $shells =~ fish && $lno_func -ne 0 ]] && echo ' fish_user_key_bindings # fish'
|
[[ "$shells" =~ fish ]] && [ $key_bindings -eq 1 ] && echo ' fzf_key_bindings # fish'
|
||||||
[[ $shells =~ nushell ]] && echo ' # nushell: files are loaded automatically from autoload directory'
|
|
||||||
echo
|
echo
|
||||||
echo 'Use uninstall script to remove fzf.'
|
echo 'Use uninstall script to remove fzf.'
|
||||||
echo
|
echo
|
||||||
|
|||||||
+1
-1
@@ -1,4 +1,4 @@
|
|||||||
$version="0.73.1"
|
$version="0.55.0"
|
||||||
|
|
||||||
$fzf_base=Split-Path -Parent $MyInvocation.MyCommand.Definition
|
$fzf_base=Split-Path -Parent $MyInvocation.MyCommand.Definition
|
||||||
|
|
||||||
|
|||||||
@@ -11,7 +11,7 @@ import (
|
|||||||
"github.com/junegunn/fzf/src/protector"
|
"github.com/junegunn/fzf/src/protector"
|
||||||
)
|
)
|
||||||
|
|
||||||
var version = "0.73"
|
var version = "0.55"
|
||||||
var revision = "devel"
|
var revision = "devel"
|
||||||
|
|
||||||
//go:embed shell/key-bindings.bash
|
//go:embed shell/key-bindings.bash
|
||||||
@@ -29,15 +29,6 @@ var zshCompletion []byte
|
|||||||
//go:embed shell/key-bindings.fish
|
//go:embed shell/key-bindings.fish
|
||||||
var fishKeyBindings []byte
|
var fishKeyBindings []byte
|
||||||
|
|
||||||
//go:embed shell/key-bindings.nu
|
|
||||||
var nushellKeyBindings []byte
|
|
||||||
|
|
||||||
//go:embed shell/completion.nu
|
|
||||||
var nushellCompletion []byte
|
|
||||||
|
|
||||||
//go:embed shell/completion.fish
|
|
||||||
var fishCompletion []byte
|
|
||||||
|
|
||||||
//go:embed man/man1/fzf.1
|
//go:embed man/man1/fzf.1
|
||||||
var manPage []byte
|
var manPage []byte
|
||||||
|
|
||||||
@@ -74,12 +65,7 @@ func main() {
|
|||||||
}
|
}
|
||||||
if options.Fish {
|
if options.Fish {
|
||||||
printScript("key-bindings.fish", fishKeyBindings)
|
printScript("key-bindings.fish", fishKeyBindings)
|
||||||
printScript("completion.fish", fishCompletion)
|
fmt.Println("fzf_key_bindings")
|
||||||
return
|
|
||||||
}
|
|
||||||
if options.Nushell {
|
|
||||||
printScript("key-bindings.nu", nushellKeyBindings)
|
|
||||||
printScript("completion.nu", nushellCompletion)
|
|
||||||
return
|
return
|
||||||
}
|
}
|
||||||
if options.Help {
|
if options.Help {
|
||||||
|
|||||||
+2
-2
@@ -1,7 +1,7 @@
|
|||||||
.ig
|
.ig
|
||||||
The MIT License (MIT)
|
The MIT License (MIT)
|
||||||
|
|
||||||
Copyright (c) 2013-2026 Junegunn Choi
|
Copyright (c) 2013-2024 Junegunn Choi
|
||||||
|
|
||||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
of this software and associated documentation files (the "Software"), to deal
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
@@ -21,7 +21,7 @@ LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|||||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||||
THE SOFTWARE.
|
THE SOFTWARE.
|
||||||
..
|
..
|
||||||
.TH fzf\-tmux 1 "May 2026" "fzf 0.73.1" "fzf\-tmux - open fzf in tmux split pane"
|
.TH fzf\-tmux 1 "Aug 2024" "fzf 0.55.0" "fzf\-tmux - open fzf in tmux split pane"
|
||||||
|
|
||||||
.SH NAME
|
.SH NAME
|
||||||
fzf\-tmux - open fzf in tmux split pane
|
fzf\-tmux - open fzf in tmux split pane
|
||||||
|
|||||||
+432
-1077
File diff suppressed because it is too large
Load Diff
+29
-83
@@ -1,4 +1,4 @@
|
|||||||
" Copyright (c) 2013-2026 Junegunn Choi
|
" Copyright (c) 2013-2024 Junegunn Choi
|
||||||
"
|
"
|
||||||
" MIT License
|
" MIT License
|
||||||
"
|
"
|
||||||
@@ -358,7 +358,7 @@ endfunction
|
|||||||
|
|
||||||
function! s:get_color(attr, ...)
|
function! s:get_color(attr, ...)
|
||||||
" Force 24 bit colors: g:fzf_force_termguicolors (temporary workaround for https://github.com/junegunn/fzf.vim/issues/1152)
|
" Force 24 bit colors: g:fzf_force_termguicolors (temporary workaround for https://github.com/junegunn/fzf.vim/issues/1152)
|
||||||
let gui = get(g:, 'fzf_force_termguicolors', 0) || (!s:is_win && !has('win32unix') && (has('gui_running') || has('termguicolors') && &termguicolors))
|
let gui = get(g:, 'fzf_force_termguicolors', 0) || (!s:is_win && !has('win32unix') && has('termguicolors') && &termguicolors)
|
||||||
let fam = gui ? 'gui' : 'cterm'
|
let fam = gui ? 'gui' : 'cterm'
|
||||||
let pat = gui ? '^#[a-f0-9]\+' : '^[0-9]\+$'
|
let pat = gui ? '^#[a-f0-9]\+' : '^[0-9]\+$'
|
||||||
for group in a:000
|
for group in a:000
|
||||||
@@ -553,15 +553,8 @@ try
|
|||||||
let height = s:calc_size(&lines, dict.down, dict)
|
let height = s:calc_size(&lines, dict.down, dict)
|
||||||
let optstr .= ' --no-tmux --height='.height
|
let optstr .= ' --no-tmux --height='.height
|
||||||
endif
|
endif
|
||||||
|
" Respect --border option given in $FZF_DEFAULT_OPTS and 'options'
|
||||||
if exists('&winborder') && &winborder !=# '' && &winborder !=# 'none'
|
let optstr = join([s:border_opt(get(dict, 'window', 0)), s:extract_option($FZF_DEFAULT_OPTS, 'border'), optstr])
|
||||||
" Add 1-column horizontal margin
|
|
||||||
let optstr = join(['--margin 0,1', optstr])
|
|
||||||
else
|
|
||||||
" Respect --border option given in $FZF_DEFAULT_OPTS and 'options'
|
|
||||||
let optstr = join([s:border_opt(get(dict, 'window', 0)), s:extract_option($FZF_DEFAULT_OPTS, 'border'), optstr])
|
|
||||||
endif
|
|
||||||
|
|
||||||
let command = prefix.(use_tmux ? s:fzf_tmux(dict) : fzf_exec).' '.optstr.' > '.temps.result
|
let command = prefix.(use_tmux ? s:fzf_tmux(dict) : fzf_exec).' '.optstr.' > '.temps.result
|
||||||
|
|
||||||
if use_term
|
if use_term
|
||||||
@@ -896,7 +889,6 @@ function! s:execute_term(dict, command, temps) abort
|
|||||||
endif
|
endif
|
||||||
endfunction
|
endfunction
|
||||||
function! fzf.on_exit(id, code, ...)
|
function! fzf.on_exit(id, code, ...)
|
||||||
silent! autocmd! fzf_popup_resize
|
|
||||||
if s:getpos() == self.ppos " {'window': 'enew'}
|
if s:getpos() == self.ppos " {'window': 'enew'}
|
||||||
for [opt, val] in items(self.winopts)
|
for [opt, val] in items(self.winopts)
|
||||||
execute 'let' opt '=' val
|
execute 'let' opt '=' val
|
||||||
@@ -1024,79 +1016,41 @@ function! s:callback(dict, lines) abort
|
|||||||
endfunction
|
endfunction
|
||||||
|
|
||||||
if has('nvim')
|
if has('nvim')
|
||||||
function! s:create_popup() abort
|
function s:create_popup(opts) abort
|
||||||
let opts = s:popup_bounds()
|
|
||||||
let opts = extend({'relative': 'editor', 'style': 'minimal'}, opts)
|
|
||||||
|
|
||||||
let buf = nvim_create_buf(v:false, v:true)
|
let buf = nvim_create_buf(v:false, v:true)
|
||||||
let s:popup_id = nvim_open_win(buf, v:true, opts)
|
let opts = extend({'relative': 'editor', 'style': 'minimal'}, a:opts)
|
||||||
call setwinvar(s:popup_id, '&colorcolumn', '')
|
let win = nvim_open_win(buf, v:true, opts)
|
||||||
|
silent! call setwinvar(win, '&winhighlight', 'Pmenu:,Normal:Normal')
|
||||||
" Colors
|
call setwinvar(win, '&colorcolumn', '')
|
||||||
try
|
|
||||||
call setwinvar(s:popup_id, '&winhighlight', 'Pmenu:,Normal:Normal')
|
|
||||||
let rules = get(g:, 'fzf_colors', {})
|
|
||||||
if has_key(rules, 'bg')
|
|
||||||
let color = call('s:get_color', rules.bg)
|
|
||||||
if len(color)
|
|
||||||
let ns = nvim_create_namespace('fzf_popup')
|
|
||||||
let hl = nvim_set_hl(ns, 'Normal',
|
|
||||||
\ &termguicolors ? { 'bg': color } : { 'ctermbg': str2nr(color) })
|
|
||||||
call nvim_win_set_hl_ns(s:popup_id, ns)
|
|
||||||
endif
|
|
||||||
endif
|
|
||||||
catch
|
|
||||||
endtry
|
|
||||||
return buf
|
return buf
|
||||||
endfunction
|
endfunction
|
||||||
|
|
||||||
function! s:resize_popup() abort
|
|
||||||
if !exists('s:popup_id') || !nvim_win_is_valid(s:popup_id)
|
|
||||||
return
|
|
||||||
endif
|
|
||||||
let opts = s:popup_bounds()
|
|
||||||
let opts = extend({'relative': 'editor'}, opts)
|
|
||||||
call nvim_win_set_config(s:popup_id, opts)
|
|
||||||
endfunction
|
|
||||||
else
|
else
|
||||||
function! s:create_popup() abort
|
function! s:create_popup(opts) abort
|
||||||
function! s:popup_create(buf)
|
let s:popup_create = {buf -> popup_create(buf, #{
|
||||||
let s:popup_id = popup_create(a:buf, #{zindex: 1000})
|
\ line: a:opts.row,
|
||||||
call s:resize_popup()
|
\ col: a:opts.col,
|
||||||
endfunction
|
\ minwidth: a:opts.width,
|
||||||
|
\ maxwidth: a:opts.width,
|
||||||
|
\ minheight: a:opts.height,
|
||||||
|
\ maxheight: a:opts.height,
|
||||||
|
\ zindex: 1000,
|
||||||
|
\ })}
|
||||||
autocmd TerminalOpen * ++once call s:popup_create(str2nr(expand('<abuf>')))
|
autocmd TerminalOpen * ++once call s:popup_create(str2nr(expand('<abuf>')))
|
||||||
endfunction
|
endfunction
|
||||||
|
|
||||||
function! s:resize_popup() abort
|
|
||||||
if !exists('s:popup_id') || empty(popup_getpos(s:popup_id))
|
|
||||||
return
|
|
||||||
endif
|
|
||||||
let opts = s:popup_bounds()
|
|
||||||
call popup_move(s:popup_id, {
|
|
||||||
\ 'line': opts.row,
|
|
||||||
\ 'col': opts.col,
|
|
||||||
\ 'minwidth': opts.width,
|
|
||||||
\ 'maxwidth': opts.width,
|
|
||||||
\ 'minheight': opts.height,
|
|
||||||
\ 'maxheight': opts.height,
|
|
||||||
\ })
|
|
||||||
endfunction
|
|
||||||
endif
|
endif
|
||||||
|
|
||||||
function! s:popup_bounds() abort
|
function! s:popup(opts) abort
|
||||||
let opts = s:popup_opts
|
let xoffset = get(a:opts, 'xoffset', 0.5)
|
||||||
|
let yoffset = get(a:opts, 'yoffset', 0.5)
|
||||||
let xoffset = get(opts, 'xoffset', 0.5)
|
let relative = get(a:opts, 'relative', 0)
|
||||||
let yoffset = get(opts, 'yoffset', 0.5)
|
|
||||||
let relative = get(opts, 'relative', 0)
|
|
||||||
|
|
||||||
" Use current window size for positioning relatively positioned popups
|
" Use current window size for positioning relatively positioned popups
|
||||||
let columns = relative ? winwidth(0) : &columns
|
let columns = relative ? winwidth(0) : &columns
|
||||||
let lines = relative ? winheight(0) : (&lines - has('nvim'))
|
let lines = relative ? winheight(0) : (&lines - has('nvim'))
|
||||||
|
|
||||||
" Size and position
|
" Size and position
|
||||||
let width = min([max([8, opts.width > 1 ? opts.width : float2nr(columns * opts.width)]), columns])
|
let width = min([max([8, a:opts.width > 1 ? a:opts.width : float2nr(columns * a:opts.width)]), columns])
|
||||||
let height = min([max([4, opts.height > 1 ? opts.height : float2nr(lines * opts.height)]), lines])
|
let height = min([max([4, a:opts.height > 1 ? a:opts.height : float2nr(lines * a:opts.height)]), lines])
|
||||||
let row = float2nr(yoffset * (lines - height)) + (relative ? win_screenpos(0)[0] - 1 : 0)
|
let row = float2nr(yoffset * (lines - height)) + (relative ? win_screenpos(0)[0] - 1 : 0)
|
||||||
let col = float2nr(xoffset * (columns - width)) + (relative ? win_screenpos(0)[1] - 1 : 0)
|
let col = float2nr(xoffset * (columns - width)) + (relative ? win_screenpos(0)[1] - 1 : 0)
|
||||||
|
|
||||||
@@ -1106,17 +1060,9 @@ function! s:popup_bounds() abort
|
|||||||
let row += !has('nvim')
|
let row += !has('nvim')
|
||||||
let col += !has('nvim')
|
let col += !has('nvim')
|
||||||
|
|
||||||
return { 'row': row, 'col': col, 'width': width, 'height': height }
|
call s:create_popup({
|
||||||
endfunction
|
\ 'row': row, 'col': col, 'width': width, 'height': height
|
||||||
|
\ })
|
||||||
function! s:popup(opts) abort
|
|
||||||
let s:popup_opts = a:opts
|
|
||||||
call s:create_popup()
|
|
||||||
|
|
||||||
augroup fzf_popup_resize
|
|
||||||
autocmd!
|
|
||||||
autocmd VimResized * call s:resize_popup()
|
|
||||||
augroup END
|
|
||||||
endfunction
|
endfunction
|
||||||
|
|
||||||
let s:default_action = {
|
let s:default_action = {
|
||||||
@@ -1135,7 +1081,7 @@ endfunction
|
|||||||
|
|
||||||
function! s:cmd(bang, ...) abort
|
function! s:cmd(bang, ...) abort
|
||||||
let args = copy(a:000)
|
let args = copy(a:000)
|
||||||
let opts = { 'options': ['--multi', '--scheme', 'path'] }
|
let opts = { 'options': ['--multi'] }
|
||||||
if len(args) && isdirectory(expand(args[-1]))
|
if len(args) && isdirectory(expand(args[-1]))
|
||||||
let opts.dir = substitute(substitute(remove(args, -1), '\\\(["'']\)', '\1', 'g'), '[/\\]*$', '/', '')
|
let opts.dir = substitute(substitute(remove(args, -1), '\\\(["'']\)', '\1', 'g'), '[/\\]*$', '/', '')
|
||||||
if s:is_win && !&shellslash
|
if s:is_win && !&shellslash
|
||||||
|
|||||||
@@ -1,40 +0,0 @@
|
|||||||
__fzf_defaults() {
|
|
||||||
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
|
||||||
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
|
||||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
|
||||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
|
||||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
|
||||||
}
|
|
||||||
|
|
||||||
__fzf_exec_awk() {
|
|
||||||
# This function performs `exec awk "$@"` safely by working around awk
|
|
||||||
# compatibility issues.
|
|
||||||
#
|
|
||||||
# To reduce an extra fork, this function performs "exec" so is expected to be
|
|
||||||
# run as the last command in a subshell.
|
|
||||||
if [[ -z ${__fzf_awk-} ]]; then
|
|
||||||
__fzf_awk=awk
|
|
||||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
|
||||||
# Note: Solaris awk at /usr/bin/awk is meant for backward compatibility
|
|
||||||
# with an ancient implementation of 1977 awk in the original UNIX. It
|
|
||||||
# lacks many features of POSIX awk, so it is essentially useless in the
|
|
||||||
# modern point of view. To use a standard-conforming version in Solaris,
|
|
||||||
# one needs to explicitly use /usr/xpg4/bin/awk.
|
|
||||||
__fzf_awk=/usr/xpg4/bin/awk
|
|
||||||
elif command -v mawk > /dev/null 2>&1; then
|
|
||||||
# choose the faster mawk if: it's installed && build date >= 20230322 &&
|
|
||||||
# version >= 1.3.4
|
|
||||||
local n x y z d
|
|
||||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
|
||||||
[[ $n == mawk ]] &&
|
|
||||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
|
||||||
((d >= 20230302)) 2> /dev/null &&
|
|
||||||
__fzf_awk=mawk
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
# Note: macOS awk has a quirk that it stops processing at all when it sees
|
|
||||||
# any data not following UTF-8 in the input stream when the current LC_CTYPE
|
|
||||||
# specifies the UTF-8 encoding. To work around this quirk, one needs to
|
|
||||||
# specify LC_ALL=C to change the current encoding to the plain one.
|
|
||||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
|
||||||
}
|
|
||||||
@@ -1,91 +0,0 @@
|
|||||||
# ____ ____
|
|
||||||
# / __/___ / __/
|
|
||||||
# / /_/_ / / /_
|
|
||||||
# / __/ / /_/ __/
|
|
||||||
# /_/ /___/_/ completion-examples.nu
|
|
||||||
#
|
|
||||||
# Example custom completers for fzf's Nushell integration.
|
|
||||||
#
|
|
||||||
# To use these, add the desired entries to $env.FZF_COMPLETERS in your
|
|
||||||
# config.nu. Each closure receives two arguments:
|
|
||||||
# - prefix: the text before the trigger (e.g. "vim" in "vim **<TAB>")
|
|
||||||
# - spans: the full command as a list of words (e.g. ["pacman", "-S", "vim**"])
|
|
||||||
#
|
|
||||||
# A closure can return either:
|
|
||||||
# - a list of candidate strings (fzf will use default options), or
|
|
||||||
# - a record with the following optional fields:
|
|
||||||
# candidates: list<string> # candidates to feed to fzf
|
|
||||||
# opts: list<string> # custom fzf options (default: ["-m"])
|
|
||||||
# post: closure (|sel| ...) # post-processing of the selected item
|
|
||||||
#
|
|
||||||
# Simple example:
|
|
||||||
# $env.FZF_COMPLETERS = {
|
|
||||||
# git: {|prefix, spans| ["branch-main", "branch-dev", "branch-feature"]}
|
|
||||||
# }
|
|
||||||
|
|
||||||
# --- pacman / paru ---
|
|
||||||
# Completes package names for pacman and paru.
|
|
||||||
# Uses the spans to distinguish between subcommands:
|
|
||||||
# -S (sync), -F (files): list available packages from repos
|
|
||||||
# -Q (query), -R (remove): list installed packages
|
|
||||||
# Returns a record with custom fzf options for package preview.
|
|
||||||
|
|
||||||
$env.FZF_COMPLETERS = {}
|
|
||||||
|
|
||||||
$env.FZF_COMPLETERS.pacman = {|prefix, spans|
|
|
||||||
let sub = $spans | skip 1 | first
|
|
||||||
let candidates = (if ($sub =~ "-[SF]") {
|
|
||||||
^pacman -Slq | lines
|
|
||||||
} else if ($sub =~ "-[QR]") {
|
|
||||||
^pacman -Qq | lines
|
|
||||||
} else {
|
|
||||||
[]
|
|
||||||
})
|
|
||||||
{
|
|
||||||
candidates: $candidates
|
|
||||||
opts: ["-m", "--preview", "pacman -Si {}", "--prompt", "Package > "]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
$env.FZF_COMPLETERS.paru = {|prefix, spans|
|
|
||||||
let sub = $spans | skip 1 | first
|
|
||||||
let candidates = (if ($sub =~ "-[SF]") {
|
|
||||||
^pacman -Slq | lines
|
|
||||||
} else if ($sub =~ "-[QR]") {
|
|
||||||
^pacman -Qq | lines
|
|
||||||
} else {
|
|
||||||
[]
|
|
||||||
})
|
|
||||||
{
|
|
||||||
candidates: $candidates
|
|
||||||
opts: ["-m", "--preview", "pacman -Si {}", "--prompt", "Package > "]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# --- pass (password-store) ---
|
|
||||||
# Completes entry names from ~/.password-store.
|
|
||||||
# Returns a simple list (no custom fzf options needed).
|
|
||||||
|
|
||||||
$env.FZF_COMPLETERS.pass = {|prefix, spans|
|
|
||||||
try {
|
|
||||||
ls ~/.password-store/**/*.gpg
|
|
||||||
| get name
|
|
||||||
| each {$in | str replace -r '^.*?\.password-store/(.*).gpg' '${1}'}
|
|
||||||
} catch {
|
|
||||||
[]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# --- Example with post-processing hook ---
|
|
||||||
# The "post" closure transforms the selected line after fzf returns.
|
|
||||||
# This is useful when the displayed line contains more information than
|
|
||||||
# what you want inserted on the command line (e.g. extracting a PID from
|
|
||||||
# a full "ps" output line).
|
|
||||||
#
|
|
||||||
# $env.FZF_COMPLETERS.mycommand = {|prefix, spans|
|
|
||||||
# {
|
|
||||||
# candidates: (^some-command | lines)
|
|
||||||
# opts: ["+m", "--header-lines=1"]
|
|
||||||
# post: {|selection| $selection | split row ' ' | get 0}
|
|
||||||
# }
|
|
||||||
# }
|
|
||||||
+130
-244
@@ -4,6 +4,8 @@
|
|||||||
# / __/ / /_/ __/
|
# / __/ / /_/ __/
|
||||||
# /_/ /___/_/ completion.bash
|
# /_/ /___/_/ completion.bash
|
||||||
#
|
#
|
||||||
|
# - $FZF_TMUX (default: 0)
|
||||||
|
# - $FZF_TMUX_OPTS (default: empty)
|
||||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||||
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
||||||
@@ -29,40 +31,21 @@ if [[ $- =~ i ]]; then
|
|||||||
|
|
||||||
###########################################################
|
###########################################################
|
||||||
|
|
||||||
#----BEGIN shfmt
|
# To redraw line after fzf closes (printf '\e[5n')
|
||||||
#----BEGIN INCLUDE common.sh
|
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
||||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
|
||||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
|
||||||
# the changes. See code comments in "common.sh" for the implementation details.
|
|
||||||
|
|
||||||
__fzf_defaults() {
|
__fzf_defaults() {
|
||||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
echo "--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore $1"
|
||||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
echo "${FZF_DEFAULT_OPTS-} $2"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_exec_awk() {
|
|
||||||
if [[ -z ${__fzf_awk-} ]]; then
|
|
||||||
__fzf_awk=awk
|
|
||||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
|
||||||
__fzf_awk=/usr/xpg4/bin/awk
|
|
||||||
elif command -v mawk > /dev/null 2>&1; then
|
|
||||||
local n x y z d
|
|
||||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
|
||||||
[[ $n == mawk ]] &&
|
|
||||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
|
||||||
((d >= 20230302)) 2> /dev/null &&
|
|
||||||
__fzf_awk=mawk
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
|
||||||
}
|
|
||||||
#----END INCLUDE
|
|
||||||
|
|
||||||
__fzf_comprun() {
|
__fzf_comprun() {
|
||||||
if [[ "$(type -t _fzf_comprun 2>&1)" == function ]]; then
|
if [[ "$(type -t _fzf_comprun 2>&1)" = function ]]; then
|
||||||
_fzf_comprun "$@"
|
_fzf_comprun "$@"
|
||||||
elif [[ -n ${TMUX_PANE-} ]] && { [[ ${FZF_TMUX:-0} != 0 ]] || [[ -n ${FZF_TMUX_OPTS-} ]]; }; then
|
elif [[ -n "${TMUX_PANE-}" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "${FZF_TMUX_OPTS-}" ]]; }; then
|
||||||
shift
|
shift
|
||||||
fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- "$@"
|
fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- "$@"
|
||||||
else
|
else
|
||||||
@@ -74,13 +57,13 @@ __fzf_comprun() {
|
|||||||
__fzf_orig_completion() {
|
__fzf_orig_completion() {
|
||||||
local l comp f cmd
|
local l comp f cmd
|
||||||
while read -r l; do
|
while read -r l; do
|
||||||
if [[ $l =~ ^(.*\ -F)\ *([^ ]*).*\ ([^ ]*)$ ]]; then
|
if [[ "$l" =~ ^(.*\ -F)\ *([^ ]*).*\ ([^ ]*)$ ]]; then
|
||||||
comp="${BASH_REMATCH[1]}"
|
comp="${BASH_REMATCH[1]}"
|
||||||
f="${BASH_REMATCH[2]}"
|
f="${BASH_REMATCH[2]}"
|
||||||
cmd="${BASH_REMATCH[3]}"
|
cmd="${BASH_REMATCH[3]}"
|
||||||
[[ $f == _fzf_* ]] && continue
|
[[ "$f" = _fzf_* ]] && continue
|
||||||
builtin printf -v "_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}" "%s" "${comp} %s ${cmd} #${f}"
|
printf -v "_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}" "%s" "${comp} %s ${cmd} #${f}"
|
||||||
if [[ $l == *" -o nospace "* ]] && [[ ${__fzf_nospace_commands-} != *" $cmd "* ]]; then
|
if [[ "$l" = *" -o nospace "* ]] && [[ ! "${__fzf_nospace_commands-}" = *" $cmd "* ]]; then
|
||||||
__fzf_nospace_commands="${__fzf_nospace_commands-} $cmd "
|
__fzf_nospace_commands="${__fzf_nospace_commands-} $cmd "
|
||||||
fi
|
fi
|
||||||
fi
|
fi
|
||||||
@@ -109,20 +92,19 @@ __fzf_orig_completion_instantiate() {
|
|||||||
orig="${!orig_var-}"
|
orig="${!orig_var-}"
|
||||||
orig="${orig%#*}"
|
orig="${orig%#*}"
|
||||||
[[ $orig == *' %s '* ]] || return 1
|
[[ $orig == *' %s '* ]] || return 1
|
||||||
builtin printf -v REPLY "$orig" "$func"
|
printf -v REPLY "$orig" "$func"
|
||||||
}
|
}
|
||||||
|
|
||||||
_fzf_opts_completion() {
|
_fzf_opts_completion() {
|
||||||
local cur prev opts
|
local cur prev opts
|
||||||
COMPREPLY=()
|
COMPREPLY=()
|
||||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||||
prev="${COMP_WORDS[COMP_CWORD - 1]}"
|
prev="${COMP_WORDS[COMP_CWORD-1]}"
|
||||||
opts="
|
opts="
|
||||||
+c --no-color
|
+c --no-color
|
||||||
+i --no-ignore-case
|
+i --no-ignore-case
|
||||||
+s --no-sort
|
+s --no-sort
|
||||||
+x --no-extended
|
+x --no-extended
|
||||||
--accept-nth
|
|
||||||
--ansi
|
--ansi
|
||||||
--bash
|
--bash
|
||||||
--bind
|
--bind
|
||||||
@@ -136,89 +118,56 @@ _fzf_opts_completion() {
|
|||||||
--expect
|
--expect
|
||||||
--filepath-word
|
--filepath-word
|
||||||
--fish
|
--fish
|
||||||
--footer
|
|
||||||
--footer-border
|
|
||||||
--footer-label
|
|
||||||
--footer-label-pos
|
|
||||||
--freeze-left
|
|
||||||
--freeze-right
|
|
||||||
--gap
|
|
||||||
--gap-line
|
|
||||||
--ghost
|
|
||||||
--gutter
|
|
||||||
--gutter-raw
|
|
||||||
--header
|
--header
|
||||||
--header-border
|
|
||||||
--header-first
|
--header-first
|
||||||
--header-label
|
|
||||||
--header-label-pos
|
|
||||||
--header-lines
|
--header-lines
|
||||||
--header-lines-border
|
|
||||||
--height
|
--height
|
||||||
--highlight-line
|
--highlight-line
|
||||||
--history
|
--history
|
||||||
--history-size
|
--history-size
|
||||||
--hscroll-off
|
--hscroll-off
|
||||||
--id-nth
|
|
||||||
--info
|
--info
|
||||||
--info-command
|
|
||||||
--input-border
|
|
||||||
--input-label
|
|
||||||
--input-label-pos
|
|
||||||
--jump-labels
|
--jump-labels
|
||||||
--keep-right
|
--keep-right
|
||||||
--layout
|
--layout
|
||||||
--listen
|
--listen
|
||||||
--listen-unsafe
|
--listen-unsafe
|
||||||
--list-border
|
|
||||||
--list-label
|
|
||||||
--list-label-pos
|
|
||||||
--literal
|
--literal
|
||||||
--man
|
--man
|
||||||
--margin
|
--margin
|
||||||
--marker
|
--marker
|
||||||
--marker-multi-line
|
|
||||||
--min-height
|
--min-height
|
||||||
--no-bold
|
--no-bold
|
||||||
|
--no-clear
|
||||||
--no-hscroll
|
--no-hscroll
|
||||||
--no-input
|
--no-mouse
|
||||||
--no-multi-line
|
|
||||||
--no-scrollbar
|
--no-scrollbar
|
||||||
--no-separator
|
--no-separator
|
||||||
|
--no-unicode
|
||||||
--padding
|
--padding
|
||||||
--pointer
|
--pointer
|
||||||
--preview
|
--preview
|
||||||
--preview-border
|
|
||||||
--preview-label
|
--preview-label
|
||||||
--preview-label-pos
|
--preview-label-pos
|
||||||
--preview-window
|
--preview-window
|
||||||
--print-query
|
--print-query
|
||||||
--print0
|
--print0
|
||||||
--prompt
|
--prompt
|
||||||
--raw
|
|
||||||
--read0
|
--read0
|
||||||
|
--reverse
|
||||||
--scheme
|
--scheme
|
||||||
--scroll-off
|
--scroll-off
|
||||||
--scrollbar
|
|
||||||
--separator
|
--separator
|
||||||
--smart-case
|
|
||||||
--style
|
|
||||||
--sync
|
--sync
|
||||||
--tabstop
|
--tabstop
|
||||||
--tac
|
--tac
|
||||||
--tail
|
|
||||||
--tiebreak
|
--tiebreak
|
||||||
--tmux
|
--tmux
|
||||||
--track
|
--track
|
||||||
--version
|
--version
|
||||||
--walker
|
|
||||||
--walker-root
|
|
||||||
--walker-skip
|
|
||||||
--with-nth
|
--with-nth
|
||||||
--with-shell
|
--with-shell
|
||||||
--wrap
|
--wrap
|
||||||
--wrap-sign
|
|
||||||
--preview-wrap-sign
|
|
||||||
--zsh
|
--zsh
|
||||||
-0 --exit-0
|
-0 --exit-0
|
||||||
-1 --select-1
|
-1 --select-1
|
||||||
@@ -233,41 +182,32 @@ _fzf_opts_completion() {
|
|||||||
--"
|
--"
|
||||||
|
|
||||||
case "${prev}" in
|
case "${prev}" in
|
||||||
--scheme)
|
--scheme)
|
||||||
COMPREPLY=($(compgen -W "default path history" -- "$cur"))
|
COMPREPLY=( $(compgen -W "default path history" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
;;
|
;;
|
||||||
--tiebreak)
|
--tiebreak)
|
||||||
COMPREPLY=($(compgen -W "length chunk pathname begin end index" -- "$cur"))
|
COMPREPLY=( $(compgen -W "length chunk begin end index" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
;;
|
;;
|
||||||
--color)
|
--color)
|
||||||
COMPREPLY=($(compgen -W "dark light base16 16 bw no" -- "$cur"))
|
COMPREPLY=( $(compgen -W "dark light 16 bw no" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
;;
|
;;
|
||||||
--layout)
|
--layout)
|
||||||
COMPREPLY=($(compgen -W "default reverse reverse-list" -- "$cur"))
|
COMPREPLY=( $(compgen -W "default reverse reverse-list" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
;;
|
;;
|
||||||
--info)
|
--info)
|
||||||
COMPREPLY=($(compgen -W "default right hidden inline inline-right" -- "$cur"))
|
COMPREPLY=( $(compgen -W "default right hidden inline inline-right" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
;;
|
;;
|
||||||
--wrap)
|
--preview-window)
|
||||||
COMPREPLY=($(compgen -W "char word" -- "$cur"))
|
COMPREPLY=( $(compgen -W "
|
||||||
return 0
|
|
||||||
;;
|
|
||||||
--style)
|
|
||||||
COMPREPLY=($(compgen -W "default minimal full" -- "$cur"))
|
|
||||||
return 0
|
|
||||||
;;
|
|
||||||
--preview-window)
|
|
||||||
COMPREPLY=($(compgen -W "
|
|
||||||
default
|
default
|
||||||
hidden
|
hidden
|
||||||
nohidden
|
nohidden
|
||||||
wrap
|
wrap
|
||||||
wrap-word
|
|
||||||
nowrap
|
nowrap
|
||||||
cycle
|
cycle
|
||||||
nocycle
|
nocycle
|
||||||
@@ -276,7 +216,6 @@ _fzf_opts_completion() {
|
|||||||
left
|
left
|
||||||
right
|
right
|
||||||
rounded border border-rounded
|
rounded border border-rounded
|
||||||
border-line
|
|
||||||
sharp border-sharp
|
sharp border-sharp
|
||||||
border-bold
|
border-bold
|
||||||
border-block
|
border-block
|
||||||
@@ -290,23 +229,21 @@ _fzf_opts_completion() {
|
|||||||
border-left
|
border-left
|
||||||
border-right
|
border-right
|
||||||
follow
|
follow
|
||||||
nofollow
|
nofollow" -- "$cur") )
|
||||||
info
|
return 0
|
||||||
noinfo" -- "$cur"))
|
;;
|
||||||
return 0
|
--border)
|
||||||
;;
|
COMPREPLY=( $(compgen -W "rounded sharp bold block thinblock double horizontal vertical top bottom left right none" -- "$cur") )
|
||||||
--border | --list-border | --header-border | --header-lines-border | --footer-border | --input-border | --preview-border)
|
return 0
|
||||||
COMPREPLY=($(compgen -W "line rounded sharp bold block thinblock double horizontal vertical top bottom left right none" -- "$cur"))
|
;;
|
||||||
return 0
|
--border-label-pos|--preview-label-pos)
|
||||||
;;
|
COMPREPLY=( $(compgen -W "center bottom top" -- "$cur") )
|
||||||
--border-label-pos | --preview-label-pos | --list-label-pos | --header-label-pos | --footer-label-pos | --input-label-pos)
|
return 0
|
||||||
COMPREPLY=($(compgen -W "center bottom top" -- "$cur"))
|
;;
|
||||||
return 0
|
|
||||||
;;
|
|
||||||
esac
|
esac
|
||||||
|
|
||||||
if [[ $cur =~ ^-|\+ ]]; then
|
if [[ "$cur" =~ ^-|\+ ]]; then
|
||||||
COMPREPLY=($(compgen -W "${opts}" -- "$cur"))
|
COMPREPLY=( $(compgen -W "${opts}" -- "$cur") )
|
||||||
return 0
|
return 0
|
||||||
fi
|
fi
|
||||||
|
|
||||||
@@ -320,7 +257,7 @@ _fzf_handle_dynamic_completion() {
|
|||||||
orig_cmd="$1"
|
orig_cmd="$1"
|
||||||
if __fzf_orig_completion_get_orig_func "$cmd"; then
|
if __fzf_orig_completion_get_orig_func "$cmd"; then
|
||||||
"$REPLY" "$@"
|
"$REPLY" "$@"
|
||||||
elif [[ -n ${_fzf_completion_loader-} ]]; then
|
elif [[ -n "${_fzf_completion_loader-}" ]]; then
|
||||||
orig_complete=$(complete -p "$orig_cmd" 2> /dev/null)
|
orig_complete=$(complete -p "$orig_cmd" 2> /dev/null)
|
||||||
$_fzf_completion_loader "$@"
|
$_fzf_completion_loader "$@"
|
||||||
ret=$?
|
ret=$?
|
||||||
@@ -334,7 +271,7 @@ _fzf_handle_dynamic_completion() {
|
|||||||
__fzf_orig_completion_instantiate "$cmd" "${BASH_REMATCH[1]}" &&
|
__fzf_orig_completion_instantiate "$cmd" "${BASH_REMATCH[1]}" &&
|
||||||
orig_complete=$REPLY
|
orig_complete=$REPLY
|
||||||
|
|
||||||
if [[ ${__fzf_nospace_commands-} == *" $orig_cmd "* ]]; then
|
if [[ "${__fzf_nospace_commands-}" = *" $orig_cmd "* ]]; then
|
||||||
eval "${orig_complete/ -F / -o nospace -F }"
|
eval "${orig_complete/ -F / -o nospace -F }"
|
||||||
else
|
else
|
||||||
eval "$orig_complete"
|
eval "$orig_complete"
|
||||||
@@ -346,7 +283,7 @@ _fzf_handle_dynamic_completion() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
__fzf_generic_path_completion() {
|
__fzf_generic_path_completion() {
|
||||||
local cur base dir leftover matches trigger cmd
|
local cur base dir leftover matches trigger cmd rest
|
||||||
cmd="${COMP_WORDS[0]}"
|
cmd="${COMP_WORDS[0]}"
|
||||||
if [[ $cmd == \\* ]]; then
|
if [[ $cmd == \\* ]]; then
|
||||||
cmd="${cmd:1}"
|
cmd="${cmd:1}"
|
||||||
@@ -354,53 +291,62 @@ __fzf_generic_path_completion() {
|
|||||||
COMPREPLY=()
|
COMPREPLY=()
|
||||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||||
[[ $COMP_CWORD -ge 0 ]] && cur="${COMP_WORDS[COMP_CWORD]}"
|
[[ $COMP_CWORD -ge 0 ]] && cur="${COMP_WORDS[COMP_CWORD]}"
|
||||||
if [[ $cur == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
if [[ "$cur" == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
||||||
base=${cur:0:${#cur}-${#trigger}}
|
base=${cur:0:${#cur}-${#trigger}}
|
||||||
eval "base=$base" 2> /dev/null || return
|
eval "base=$base" 2> /dev/null || return
|
||||||
|
|
||||||
|
# Try to leverage existing completion
|
||||||
|
rest=("${@:4}")
|
||||||
|
unset 'rest[${#rest[@]}-2]'
|
||||||
|
COMP_LINE=${COMP_LINE:0:${#COMP_LINE}-${#trigger}}
|
||||||
|
COMP_POINT=$((COMP_POINT-${#trigger}))
|
||||||
|
COMP_WORDS[$COMP_CWORD]=$base
|
||||||
|
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||||
|
[[ $? -ne 0 ]] &&
|
||||||
|
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||||
|
|
||||||
dir=
|
dir=
|
||||||
[[ $base == *"/"* ]] && dir="$base"
|
[[ $base = *"/"* ]] && dir="$base"
|
||||||
while true; do
|
while true; do
|
||||||
if [[ -z $dir ]] || [[ -d $dir ]]; then
|
if [[ -z "$dir" ]] || [[ -d "$dir" ]]; then
|
||||||
leftover=${base/#"$dir"/}
|
leftover=${base/#"$dir"}
|
||||||
leftover=${leftover/#\//}
|
leftover=${leftover/#\/}
|
||||||
[[ -z $dir ]] && dir='.'
|
[[ -z "$dir" ]] && dir='.'
|
||||||
[[ $dir != "/" ]] && dir="${dir/%\//}"
|
[[ "$dir" != "/" ]] && dir="${dir/%\//}"
|
||||||
matches=$(
|
matches=$(
|
||||||
export FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-} $2")
|
export FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-} $2")
|
||||||
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
||||||
if [[ $1 =~ dir ]]; then
|
if [[ ${#COMPREPLY[@]} -gt 0 ]]; then
|
||||||
eval "rest=(${FZF_COMPLETION_DIR_OPTS-})"
|
for h in "${COMPREPLY[@]}"; do
|
||||||
else
|
echo "$h"
|
||||||
eval "rest=(${FZF_COMPLETION_PATH_OPTS-})"
|
done | command sort -u | __fzf_comprun "$4" -q "$leftover"
|
||||||
fi
|
elif declare -F "$1" > /dev/null; then
|
||||||
if declare -F "$1" > /dev/null; then
|
eval "$1 $(printf %q "$dir")" | __fzf_comprun "$4" -q "$leftover"
|
||||||
eval "$1 $(builtin printf %q "$dir")" | __fzf_comprun "$4" -q "$leftover" "${rest[@]}"
|
|
||||||
else
|
else
|
||||||
if [[ $1 =~ dir ]]; then
|
if [[ $1 =~ dir ]]; then
|
||||||
walker=dir,follow
|
walker=dir,follow
|
||||||
|
rest=${FZF_COMPLETION_DIR_OPTS-}
|
||||||
else
|
else
|
||||||
walker=file,dir,follow,hidden
|
walker=file,dir,follow,hidden
|
||||||
|
rest=${FZF_COMPLETION_PATH_OPTS-}
|
||||||
fi
|
fi
|
||||||
__fzf_comprun "$4" -q "$leftover" --walker "$walker" --walker-root="$dir" "${rest[@]}"
|
__fzf_comprun "$4" -q "$leftover" --walker "$walker" --walker-root="$dir" $rest
|
||||||
fi | while read -r item; do
|
fi | while read -r item; do
|
||||||
builtin printf "%q " "${item%$3}$3"
|
printf "%q " "${item%$3}$3"
|
||||||
done
|
done
|
||||||
)
|
)
|
||||||
matches=${matches% }
|
matches=${matches% }
|
||||||
[[ -z $3 ]] && [[ ${__fzf_nospace_commands-} == *" ${COMP_WORDS[0]} "* ]] && matches="$matches "
|
[[ -z "$3" ]] && [[ "${__fzf_nospace_commands-}" = *" ${COMP_WORDS[0]} "* ]] && matches="$matches "
|
||||||
if [[ -n $matches ]]; then
|
if [[ -n "$matches" ]]; then
|
||||||
COMPREPLY=("$matches")
|
COMPREPLY=( "$matches" )
|
||||||
else
|
else
|
||||||
COMPREPLY=("$cur")
|
COMPREPLY=( "$cur" )
|
||||||
fi
|
fi
|
||||||
# To redraw line after fzf closes (builtin printf '\e[5n')
|
printf '\e[5n'
|
||||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
|
||||||
builtin printf '\e[5n'
|
|
||||||
return 0
|
return 0
|
||||||
fi
|
fi
|
||||||
dir=$(command dirname "$dir")
|
dir=$(command dirname "$dir")
|
||||||
[[ $dir =~ /$ ]] || dir="$dir"/
|
[[ "$dir" =~ /$ ]] || dir="$dir"/
|
||||||
done
|
done
|
||||||
else
|
else
|
||||||
shift
|
shift
|
||||||
@@ -416,15 +362,15 @@ _fzf_complete() {
|
|||||||
args=("$@")
|
args=("$@")
|
||||||
sep=
|
sep=
|
||||||
for i in "${!args[@]}"; do
|
for i in "${!args[@]}"; do
|
||||||
if [[ ${args[$i]} == -- ]]; then
|
if [[ "${args[$i]}" = -- ]]; then
|
||||||
sep=$i
|
sep=$i
|
||||||
break
|
break
|
||||||
fi
|
fi
|
||||||
done
|
done
|
||||||
if [[ -n $sep ]]; then
|
if [[ -n "$sep" ]]; then
|
||||||
str_arg=
|
str_arg=
|
||||||
rest=("${args[@]:$((sep + 1)):${#args[@]}}")
|
rest=("${args[@]:$((sep + 1)):${#args[@]}}")
|
||||||
args=("${args[@]:0:sep}")
|
args=("${args[@]:0:$sep}")
|
||||||
else
|
else
|
||||||
str_arg=$1
|
str_arg=$1
|
||||||
args=()
|
args=()
|
||||||
@@ -433,28 +379,39 @@ _fzf_complete() {
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
local cur selected trigger cmd post
|
local cur selected trigger cmd post
|
||||||
post="$(caller 0 | __fzf_exec_awk '{print $2}')_post"
|
post="$(caller 0 | command awk '{print $2}')_post"
|
||||||
type -t "$post" > /dev/null 2>&1 || post='command cat'
|
type -t "$post" > /dev/null 2>&1 || post='command cat'
|
||||||
|
|
||||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||||
cmd="${COMP_WORDS[0]}"
|
cmd="${COMP_WORDS[0]}"
|
||||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||||
if [[ $cur == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
if [[ "$cur" == *"$trigger" ]] && [[ $cur != *'$('* ]] && [[ $cur != *':='* ]] && [[ $cur != *'`'* ]]; then
|
||||||
cur=${cur:0:${#cur}-${#trigger}}
|
cur=${cur:0:${#cur}-${#trigger}}
|
||||||
|
|
||||||
|
# Try to leverage existing completion
|
||||||
|
COMP_LINE=${COMP_LINE:0:${#COMP_LINE}-${#trigger}}
|
||||||
|
COMP_POINT=$((COMP_POINT-${#trigger}))
|
||||||
|
unset 'rest[${#rest[@]}-2]'
|
||||||
|
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||||
|
[[ $? -ne 0 ]] &&
|
||||||
|
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||||
|
|
||||||
selected=$(
|
selected=$(
|
||||||
|
(if [[ ${#COMPREPLY[@]} -gt 0 ]]; then
|
||||||
|
for h in "${COMPREPLY[@]}"; do
|
||||||
|
echo "$h"
|
||||||
|
done
|
||||||
|
fi; cat) | command sort -u |
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' \
|
FZF_DEFAULT_OPTS_FILE='' \
|
||||||
__fzf_comprun "${rest[0]}" "${args[@]}" -q "$cur" | eval "$post" | command tr '\n' ' '
|
__fzf_comprun "${rest[0]}" "${args[@]}" -q "$cur" | $post | command tr '\n' ' ')
|
||||||
)
|
|
||||||
selected=${selected% } # Strip trailing space not to repeat "-o nospace"
|
selected=${selected% } # Strip trailing space not to repeat "-o nospace"
|
||||||
if [[ -n $selected ]]; then
|
if [[ -n "$selected" ]]; then
|
||||||
COMPREPLY=("$selected")
|
COMPREPLY=("$selected")
|
||||||
else
|
else
|
||||||
COMPREPLY=("$cur")
|
COMPREPLY=("$cur")
|
||||||
fi
|
fi
|
||||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
printf '\e[5n'
|
||||||
builtin printf '\e[5n'
|
|
||||||
return 0
|
return 0
|
||||||
else
|
else
|
||||||
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||||
@@ -479,41 +436,15 @@ _fzf_complete_kill() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
_fzf_proc_completion() {
|
_fzf_proc_completion() {
|
||||||
local transformer
|
_fzf_complete -m --header-lines=1 --no-preview --wrap -- "$@" < <(
|
||||||
transformer='
|
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
||||||
if [[ $FZF_KEY =~ ctrl|alt|shift ]] && [[ -n $FZF_NTH ]]; then
|
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
||||||
nths=( ${FZF_NTH//,/ } )
|
command ps --everyone --full --windows # For cygwin
|
||||||
new_nths=()
|
)
|
||||||
found=0
|
|
||||||
for nth in ${nths[@]}; do
|
|
||||||
if [[ $nth = $FZF_CLICK_HEADER_NTH ]]; then
|
|
||||||
found=1
|
|
||||||
else
|
|
||||||
new_nths+=($nth)
|
|
||||||
fi
|
|
||||||
done
|
|
||||||
[[ $found = 0 ]] && new_nths+=($FZF_CLICK_HEADER_NTH)
|
|
||||||
new_nths=${new_nths[*]}
|
|
||||||
new_nths=${new_nths// /,}
|
|
||||||
echo "change-nth($new_nths)+change-prompt($new_nths> )"
|
|
||||||
else
|
|
||||||
if [[ $FZF_NTH = $FZF_CLICK_HEADER_NTH ]]; then
|
|
||||||
echo "change-nth()+change-prompt(> )"
|
|
||||||
else
|
|
||||||
echo "change-nth($FZF_CLICK_HEADER_NTH)+change-prompt($FZF_CLICK_HEADER_WORD> )"
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
'
|
|
||||||
_fzf_complete -m --header-lines=1 --no-preview --wrap --color fg:dim,nth:regular \
|
|
||||||
--bind "click-header:transform:$transformer" -- "$@" < <(
|
|
||||||
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
|
||||||
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
|
||||||
command ps --everyone --full --windows # For cygwin
|
|
||||||
)
|
|
||||||
}
|
}
|
||||||
|
|
||||||
_fzf_proc_completion_post() {
|
_fzf_proc_completion_post() {
|
||||||
__fzf_exec_awk '{print $2}'
|
command awk '{print $2}'
|
||||||
}
|
}
|
||||||
|
|
||||||
# To use custom hostname lists, override __fzf_list_hosts.
|
# To use custom hostname lists, override __fzf_list_hosts.
|
||||||
@@ -526,58 +457,14 @@ _fzf_proc_completion_post() {
|
|||||||
# # Set the local attribute for any non-local variable that is set by _known_hosts_real()
|
# # Set the local attribute for any non-local variable that is set by _known_hosts_real()
|
||||||
# local COMPREPLY=()
|
# local COMPREPLY=()
|
||||||
# _known_hosts_real ''
|
# _known_hosts_real ''
|
||||||
# builtin printf '%s\n' "${COMPREPLY[@]}" | command sort -u --version-sort
|
# printf '%s\n' "${COMPREPLY[@]}" | command sort -u --version-sort
|
||||||
# }
|
# }
|
||||||
if ! declare -F __fzf_list_hosts > /dev/null; then
|
if ! declare -F __fzf_list_hosts > /dev/null; then
|
||||||
__fzf_list_hosts() {
|
__fzf_list_hosts() {
|
||||||
command sort -u \
|
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | command awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?%]') \
|
||||||
<(
|
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts 2> /dev/null | command tr ',' '\n' | command tr -d '[' | command awk '{ print $1 " " $1 }') \
|
||||||
# Note: To make the pathname expansion of "~/.ssh/config.d/*" work
|
<(command grep -v '^\s*\(#\|$\)' /etc/hosts 2> /dev/null | command grep -Fv '0.0.0.0' | command sed 's/#.*//') |
|
||||||
# properly, we need to adjust the related shell options. We need to
|
command awk '{for (i = 2; i <= NF; i++) print $i}' | command sort -u
|
||||||
# unset "set -f" and "GLOBIGNORE", which disable the pathname expansion
|
|
||||||
# totally or partially. We need to unset "dotglob" and "nocaseglob" to
|
|
||||||
# avoid matching unwanted files. We need to unset "failglob" to avoid
|
|
||||||
# outputting the error messages to the terminal when no matching is
|
|
||||||
# found. We need to set "nullglob" to avoid attempting to read the
|
|
||||||
# literal filename '~/.ssh/config.d/*' when no matching is found.
|
|
||||||
set +f
|
|
||||||
GLOBIGNORE=
|
|
||||||
shopt -u dotglob nocaseglob failglob
|
|
||||||
shopt -s nullglob
|
|
||||||
|
|
||||||
__fzf_exec_awk '
|
|
||||||
# Note: mawk <= 1.3.3-20090705 does not support the POSIX brackets of
|
|
||||||
# the form [[:blank:]], and Ubuntu 18.04 LTS still uses this
|
|
||||||
# 16-year-old mawk unfortunately. We need to use [ \t] instead.
|
|
||||||
match(tolower($0), /^[ \t]*host(name)?[ \t]*[ \t=]/) {
|
|
||||||
$0 = substr($0, RLENGTH + 1) # Remove "Host(name)?=?"
|
|
||||||
sub(/#.*/, "")
|
|
||||||
for (i = 1; i <= NF; i++)
|
|
||||||
if ($i !~ /[*?%]/)
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null
|
|
||||||
) \
|
|
||||||
<(
|
|
||||||
__fzf_exec_awk -F ',' '
|
|
||||||
match($0, /^[][a-zA-Z0-9.,:-]+/) {
|
|
||||||
$0 = substr($0, 1, RLENGTH)
|
|
||||||
gsub(/[][]|:[^,]*/, "")
|
|
||||||
for (i = 1; i <= NF; i++)
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' ~/.ssh/known_hosts 2> /dev/null
|
|
||||||
) \
|
|
||||||
<(
|
|
||||||
__fzf_exec_awk '
|
|
||||||
{
|
|
||||||
sub(/#.*/, "")
|
|
||||||
for (i = 2; i <= NF; i++)
|
|
||||||
if ($i != "0.0.0.0")
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' /etc/hosts 2> /dev/null
|
|
||||||
)
|
|
||||||
}
|
}
|
||||||
fi
|
fi
|
||||||
|
|
||||||
@@ -592,13 +479,13 @@ _fzf_host_completion() {
|
|||||||
# > and the third argument ($3) is the word preceding the word being completed on the current command line.
|
# > and the third argument ($3) is the word preceding the word being completed on the current command line.
|
||||||
_fzf_complete_ssh() {
|
_fzf_complete_ssh() {
|
||||||
case $3 in
|
case $3 in
|
||||||
-i | -F | -E)
|
-i|-F|-E)
|
||||||
_fzf_path_completion "$@"
|
_fzf_path_completion "$@"
|
||||||
;;
|
;;
|
||||||
*)
|
*)
|
||||||
local user=
|
local user=
|
||||||
[[ $2 =~ '@' ]] && user="${2%%@*}@"
|
[[ "$2" =~ '@' ]] && user="${2%%@*}@"
|
||||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | __fzf_exec_awk -v user="$user" '{print user $0}')
|
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | command awk -v user="$user" '{print user $0}')
|
||||||
;;
|
;;
|
||||||
esac
|
esac
|
||||||
}
|
}
|
||||||
@@ -686,7 +573,7 @@ __fzf_defc() {
|
|||||||
if __fzf_orig_completion_instantiate "$cmd" "$func"; then
|
if __fzf_orig_completion_instantiate "$cmd" "$func"; then
|
||||||
eval "$REPLY"
|
eval "$REPLY"
|
||||||
else
|
else
|
||||||
eval "complete -F \"$func\" $opts \"$cmd\""
|
complete -F "$func" $opts "$cmd"
|
||||||
fi
|
fi
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -728,13 +615,12 @@ _fzf_setup_completion() {
|
|||||||
__fzf_orig_completion < <(complete -p "$@" 2> /dev/null)
|
__fzf_orig_completion < <(complete -p "$@" 2> /dev/null)
|
||||||
for cmd in "$@"; do
|
for cmd in "$@"; do
|
||||||
case "$kind" in
|
case "$kind" in
|
||||||
dir) __fzf_defc "$cmd" "$fn" "-o nospace -o dirnames" ;;
|
dir) __fzf_defc "$cmd" "$fn" "-o nospace -o dirnames" ;;
|
||||||
var) __fzf_defc "$cmd" "$fn" "-o default -o nospace -v" ;;
|
var) __fzf_defc "$cmd" "$fn" "-o default -o nospace -v" ;;
|
||||||
alias) __fzf_defc "$cmd" "$fn" "-a" ;;
|
alias) __fzf_defc "$cmd" "$fn" "-a" ;;
|
||||||
*) __fzf_defc "$cmd" "$fn" "-o default -o bashdefault" ;;
|
*) __fzf_defc "$cmd" "$fn" "-o default -o bashdefault" ;;
|
||||||
esac
|
esac
|
||||||
done
|
done
|
||||||
}
|
}
|
||||||
#----END shfmt
|
|
||||||
|
|
||||||
fi
|
fi
|
||||||
|
|||||||
@@ -1,169 +0,0 @@
|
|||||||
# ____ ____
|
|
||||||
# / __/___ / __/
|
|
||||||
# / /_/_ / / /_
|
|
||||||
# / __/ / /_/ __/
|
|
||||||
# /_/ /___/_/ completion.fish
|
|
||||||
#
|
|
||||||
# - $FZF_COMPLETION_OPTS
|
|
||||||
# - $FZF_EXPANSION_OPTS
|
|
||||||
|
|
||||||
# The oldest supported fish version is 3.4.0. For this message being able to be
|
|
||||||
# displayed on older versions, the command substitution syntax $() should not
|
|
||||||
# be used anywhere in the script, otherwise the source command will fail.
|
|
||||||
if string match -qr -- '^[12]\\.|^3\\.[0-3]' $version
|
|
||||||
echo "fzf completion script requires fish version 3.4.0 or newer." >&2
|
|
||||||
return 1
|
|
||||||
else if not command -q fzf
|
|
||||||
echo "fzf was not found in path." >&2
|
|
||||||
return 1
|
|
||||||
end
|
|
||||||
|
|
||||||
function fzf_complete -w fzf -d 'fzf command completion and wildcard expansion search'
|
|
||||||
# Restore the default shift-tab behavior on tab completions
|
|
||||||
if commandline --paging-mode
|
|
||||||
commandline -f complete-and-search
|
|
||||||
return
|
|
||||||
end
|
|
||||||
|
|
||||||
# Remove any trailing unescaped backslash from token and update command line
|
|
||||||
set -l -- token (string replace -r -- '(?<!\\\\)(?:\\\\\\\\)*\\K\\\\$' '' (commandline -t | string collect) | string collect)
|
|
||||||
commandline -rt -- $token
|
|
||||||
|
|
||||||
# Remove any line breaks from token
|
|
||||||
set -- token (string replace -ra -- '\\\\\\n' '' $token | string collect)
|
|
||||||
|
|
||||||
# regex: Match token with unescaped/unquoted glob character
|
|
||||||
set -l -- r_glob '^(?:[^\'"\\\\*]|\\\\[\\S\\s]|\'(?:\\\\[\\S\\s]|[^\'\\\\])*\'|"(?:\\\\[\\S\\s]|[^"\\\\])*")*\\*[\\S\\s]*$'
|
|
||||||
|
|
||||||
# regex: Match any unbalanced quote character
|
|
||||||
set -l -- r_quote '^(?>(?:\\\\[\\s\\S]|"(?:[^"\\\\]|\\\\[\\s\\S])*"|\'(?:[^\'\\\\]|\\\\[\\s\\S])*\'|[^\'"\\\\]+)*)\\K[\'"]'
|
|
||||||
|
|
||||||
# The expansion pattern is the token with any open quote closed, or is empty.
|
|
||||||
set -l -- glob_pattern (string match -r -- $r_glob $token | string collect)(string match -r -- $r_quote $token | string collect -a)
|
|
||||||
|
|
||||||
set -l -- cl_tokenize_opt '--tokens-expanded'
|
|
||||||
string match -q -- '3.*' $version
|
|
||||||
and set -- cl_tokenize_opt '--tokenize'
|
|
||||||
|
|
||||||
# Set command line tokens without any leading variable definitions or launcher
|
|
||||||
# commands (including their options, but not any option arguments).
|
|
||||||
set -l -- r_cmd '^(?:(?:builtin|command|doas|env|sudo|\\w+=\\S*|-\\S+)\\s+)*\\K[\\s\\S]+'
|
|
||||||
set -l -- cmd (commandline $cl_tokenize_opt --input=(commandline -pc | string match -r $r_cmd))
|
|
||||||
test -z "$token"
|
|
||||||
and set -a -- cmd ''
|
|
||||||
|
|
||||||
# Set fzf options
|
|
||||||
test -z "$FZF_TMUX_HEIGHT"
|
|
||||||
and set -l -- FZF_TMUX_HEIGHT 40%
|
|
||||||
|
|
||||||
set -lax -- FZF_DEFAULT_OPTS \
|
|
||||||
"--height=$FZF_TMUX_HEIGHT --min-height=20+ --bind=ctrl-z:ignore" \
|
|
||||||
(test -r "$FZF_DEFAULT_OPTS_FILE"; and string join -- ' ' <$FZF_DEFAULT_OPTS_FILE) \
|
|
||||||
$FZF_DEFAULT_OPTS '--bind=alt-r:toggle-raw --multi --wrap=word --reverse' \
|
|
||||||
(if test -n "$glob_pattern"; string collect -- $FZF_EXPANSION_OPTS; else;
|
|
||||||
string collect -- $FZF_COMPLETION_OPTS; end; string escape -n -- $argv) \
|
|
||||||
--with-shell=(status fish-path)\\ -c
|
|
||||||
|
|
||||||
set -lx FZF_DEFAULT_OPTS_FILE
|
|
||||||
|
|
||||||
set -l -- fzf_cmd fzf
|
|
||||||
test "$FZF_TMUX" = 1
|
|
||||||
and set -- fzf_cmd fzf-tmux $FZF_TMUX_OPTS -d$FZF_TMUX_HEIGHT --
|
|
||||||
|
|
||||||
set -l result
|
|
||||||
|
|
||||||
# Get the completion list from stdin when it's not a tty
|
|
||||||
if not isatty stdin
|
|
||||||
set -l -- custom_post_func _fzf_post_complete_$cmd[1]
|
|
||||||
functions -q $custom_post_func
|
|
||||||
or set -- custom_post_func _fzf_complete_$cmd[1]_post
|
|
||||||
|
|
||||||
if functions -q $custom_post_func
|
|
||||||
$fzf_cmd | $custom_post_func $cmd | while read -l r; set -a -- result $r; end
|
|
||||||
else if string match -q -- '*--print0*' "$FZF_DEFAULT_OPTS"
|
|
||||||
$fzf_cmd | while read -lz r; set -a -- result $r; end
|
|
||||||
else
|
|
||||||
$fzf_cmd | while read -l r; set -a -- result $r; end
|
|
||||||
end
|
|
||||||
|
|
||||||
# Wildcard expansion
|
|
||||||
else if test -n "$glob_pattern"
|
|
||||||
# Set the command to be run by fzf, so there is a visual indicator and an
|
|
||||||
# easy way to abort on long recursive searches.
|
|
||||||
set -lx -- FZF_DEFAULT_COMMAND "for i in $glob_pattern;" \
|
|
||||||
'test -d "$i"; and string match -qv -- "*/" $i; and set -- i $i/;' \
|
|
||||||
'string join0 -- $i; end'
|
|
||||||
|
|
||||||
set -- result (string escape -n -- ($fzf_cmd --read0 --print0 --scheme=path --no-multi-line | string split0))
|
|
||||||
|
|
||||||
# Command completion
|
|
||||||
else
|
|
||||||
# Call custom function if defined
|
|
||||||
set -l -- custom_func _fzf_complete_$cmd[1]
|
|
||||||
if functions -q $custom_func; and not set -q __fzf_no_custom_complete
|
|
||||||
set -lx __fzf_no_custom_complete
|
|
||||||
$custom_func $cmd
|
|
||||||
return
|
|
||||||
end
|
|
||||||
|
|
||||||
# Workaround for complete not having newlines in results
|
|
||||||
if string match -qr -- '\\n' $token
|
|
||||||
set -- token (string replace -ra -- '(?<!\\\\)(?:\\\\\\\\)*\\K\\\\\$' '\\\\\\\\\$' $token | string collect)
|
|
||||||
set -- token (string unescape -- $token | string collect)
|
|
||||||
set -- token (string replace -ra -- '\\n' '\\\\n' $token | string collect)
|
|
||||||
end
|
|
||||||
|
|
||||||
set -- list (complete -C --escape -- (string join -- ' ' (commandline -pc $cl_tokenize_opt) $token | string collect))
|
|
||||||
if test -n "$list"
|
|
||||||
# Get the initial tabstop value
|
|
||||||
if set -l -- tabstop (string match -rga -- '--tabstop[= ](?:0*)([1-9]\\d+|[4-9])' "$FZF_DEFAULT_OPTS")[-1]
|
|
||||||
set -- tabstop (math $tabstop - 4)
|
|
||||||
else
|
|
||||||
set -- tabstop 4
|
|
||||||
end
|
|
||||||
|
|
||||||
# Determine the tabstop length for description alignment
|
|
||||||
set -l -- max_columns (math $COLUMNS - 40)
|
|
||||||
for i in $list[1..500]
|
|
||||||
set -l -- item (string split -f 1 -- \t $i)
|
|
||||||
and set -l -- len (string length -V -- $item)
|
|
||||||
and test "$len" -gt "$tabstop" -a "$len" -lt "$max_columns"
|
|
||||||
and set -- tabstop $len
|
|
||||||
end
|
|
||||||
set -- tabstop (math $tabstop + 4)
|
|
||||||
|
|
||||||
set -- result (string collect -- $list | $fzf_cmd --delimiter="\t" --tabstop=$tabstop --wrap-sign=\t"↳ " --accept-nth=1)
|
|
||||||
end
|
|
||||||
end
|
|
||||||
|
|
||||||
# Update command line
|
|
||||||
if test -n "$result"
|
|
||||||
# No extra space after single selection that ends with path separator
|
|
||||||
set -l -- tail ' '
|
|
||||||
test (count $result) -eq 1
|
|
||||||
and string match -q -- '*/' "$result"
|
|
||||||
and set -- tail ''
|
|
||||||
|
|
||||||
commandline -rt -- (string join -- ' ' $result)$tail
|
|
||||||
end
|
|
||||||
|
|
||||||
commandline -f repaint
|
|
||||||
end
|
|
||||||
|
|
||||||
function _fzf_complete
|
|
||||||
set -l fzf_args
|
|
||||||
for i in $argv
|
|
||||||
string match -q -- '--' $i; and break
|
|
||||||
set -a -- fzf_args $i
|
|
||||||
end
|
|
||||||
fzf_complete $fzf_args
|
|
||||||
end
|
|
||||||
|
|
||||||
# Bind to shift-tab
|
|
||||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
|
||||||
bind shift-tab fzf_complete
|
|
||||||
bind -M insert shift-tab fzf_complete
|
|
||||||
else
|
|
||||||
bind -k btab fzf_complete
|
|
||||||
bind -M insert -k btab fzf_complete
|
|
||||||
end
|
|
||||||
@@ -1,489 +0,0 @@
|
|||||||
# ____ ____
|
|
||||||
# / __/___ / __/
|
|
||||||
# / /_/_ / / /_
|
|
||||||
# / __/ / /_/ __/
|
|
||||||
# /_/ /___/_/ completion.nu
|
|
||||||
|
|
||||||
|
|
||||||
# An implementation of completion.nu
|
|
||||||
# This loads FZF as a Nushell External Completer
|
|
||||||
# https://www.nushell.sh/cookbook/external_completers.html
|
|
||||||
|
|
||||||
|
|
||||||
# --- Default Environment Variables ---
|
|
||||||
# These can be overridden in your config.nu or environment.
|
|
||||||
# Example: $env.FZF_COMPLETION_TRIGGER = "!<TAB>"
|
|
||||||
|
|
||||||
# - $env.FZF_TMUX (default: 0)
|
|
||||||
# - $env.FZF_TMUX_OPTS (default: empty)
|
|
||||||
# - $env.FZF_TMUX_HEIGHT (default: 40%)
|
|
||||||
# - $env.FZF_COMPLETION_TRIGGER (default: '**')
|
|
||||||
# - $env.FZF_COMPLETION_OPTS (default: empty)
|
|
||||||
# - $env.FZF_COMPLETION_PATH_OPTS (default: empty)
|
|
||||||
# - $env.FZF_COMPLETION_DIR_OPTS (default: empty)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
$env.FZF_COMPLETION_TRIGGER = $env.FZF_COMPLETION_TRIGGER? | default '**'
|
|
||||||
|
|
||||||
# Options for fzf completion in general. e.g. '--border'
|
|
||||||
$env.FZF_COMPLETION_OPTS = $env.FZF_COMPLETION_OPTS? | default ''
|
|
||||||
|
|
||||||
# Options specific to path completion. e.g. '--extended'
|
|
||||||
$env.FZF_COMPLETION_PATH_OPTS = $env.FZF_COMPLETION_PATH_OPTS? | default ''
|
|
||||||
# Options specific to directory completion. e.g. '--extended'
|
|
||||||
$env.FZF_COMPLETION_DIR_OPTS = $env.FZF_COMPLETION_DIR_OPTS? | default ''
|
|
||||||
|
|
||||||
$env.FZF_COMPLETION_DIR_COMMANDS = $env.FZF_COMPLETION_DIR_COMMANDS? | default ['cd', 'pushd', 'rmdir']
|
|
||||||
|
|
||||||
# --- Helper Functions ---
|
|
||||||
|
|
||||||
# Helper to build default fzf options list
|
|
||||||
def __fzf_defaults_completion [prepend: string, append: string]: nothing -> string {
|
|
||||||
let base = $"--height ($env.FZF_TMUX_HEIGHT? | default '40%') --min-height 20+ --bind=ctrl-z:ignore ($prepend)"
|
|
||||||
let opts_file = if ($env.FZF_DEFAULT_OPTS_FILE? | default '' | is-not-empty) {
|
|
||||||
try { open --raw ($env.FZF_DEFAULT_OPTS_FILE) | str trim } catch { '' }
|
|
||||||
} else {
|
|
||||||
''
|
|
||||||
}
|
|
||||||
let default_opts = $env.FZF_DEFAULT_OPTS? | default ''
|
|
||||||
$"($base) ($opts_file) ($default_opts) ($append)" | str trim
|
|
||||||
}
|
|
||||||
|
|
||||||
# Wrapper for running fzf or fzf-tmux
|
|
||||||
def __fzf_comprun [ context_name: string # e.g., "fzf-completion" , "fzf-helper" - mainly for potential debugging
|
|
||||||
, query: string # The initial query string for fzf
|
|
||||||
, fzf_opts_arg: list<string> # Remaining options for fzf/fzf-tmux
|
|
||||||
] {
|
|
||||||
let stdin_content = try {
|
|
||||||
# Collect stdin into a single string. Adjust if structured data is expected.
|
|
||||||
$in | into string
|
|
||||||
} catch {
|
|
||||||
null # Set to null if there's no stdin or an error occurs reading it
|
|
||||||
}
|
|
||||||
|
|
||||||
let fzf_default_opts = (__fzf_defaults_completion "" ($env.FZF_COMPLETION_OPTS | default ''))
|
|
||||||
let fzf_prefinal_opt = ['--query', $query, '--reverse'] | append $fzf_opts_arg
|
|
||||||
|
|
||||||
# Get the configured height, defaulting to '40%'
|
|
||||||
let height_opt = $env.FZF_TMUX_HEIGHT? | default '40%'
|
|
||||||
|
|
||||||
# Determine if fzf should generate its own candidates via walker
|
|
||||||
let has_walker = ($fzf_prefinal_opt | find '--walker' | is-not-empty)
|
|
||||||
|
|
||||||
# Check for custom comprun function (Nu equivalent)
|
|
||||||
if (which _fzf_comprun | is-not-empty) {
|
|
||||||
# Note: Nushell doesn't have a direct equivalent to Zsh/Bash `type -t _fzf_comprun`.
|
|
||||||
# This check assumes a user might define a custom command named `_fzf_comprun`.
|
|
||||||
_fzf_comprun $context_name $query ...$fzf_prefinal_opt # Pass args correctly to custom function
|
|
||||||
} else if ($env.TMUX_PANE? | default '' | into string | is-not-empty) and (($env.FZF_TMUX? | default 0) != 0 or ($env.FZF_TMUX_OPTS? | is-not-empty)) {
|
|
||||||
# Running inside tmux, use fzf-tmux
|
|
||||||
let final_fzf_opts = if ($env.FZF_TMUX_OPTS? | is-not-empty) {
|
|
||||||
$env.FZF_TMUX_OPTS | split row ' ' | append ['--'] | append $fzf_prefinal_opt
|
|
||||||
} else {
|
|
||||||
# Use the default -d option with the configured height for fzf-tmux
|
|
||||||
['-d', $height_opt, '--'] | append $fzf_prefinal_opt
|
|
||||||
}
|
|
||||||
|
|
||||||
if $has_walker or ($stdin_content == null) {
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf-tmux ...$final_fzf_opts }
|
|
||||||
} else {
|
|
||||||
$stdin_content | with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf-tmux ...$final_fzf_opts }
|
|
||||||
}
|
|
||||||
|
|
||||||
} else {
|
|
||||||
# Not in tmux or not configured for fzf-tmux, use fzf directly
|
|
||||||
let final_fzf_opts = $fzf_prefinal_opt
|
|
||||||
|
|
||||||
if $has_walker or ($stdin_content == null) {
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf ...$final_fzf_opts }
|
|
||||||
} else {
|
|
||||||
$stdin_content | with-env { FZF_DEFAULT_OPTS: $fzf_default_opts, FZF_DEFAULT_OPTS_FILE: '' } { fzf ...$final_fzf_opts }
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# Generate host list for ssh/telnet
|
|
||||||
def __fzf_list_hosts [] {
|
|
||||||
# Translate the Zsh pipeline using Nu commands and external tools
|
|
||||||
let ssh_configs = try { open ~/.ssh/config | lines } catch { [] }
|
|
||||||
let ssh_configs_d = try { open ~/.ssh/config.d/* | lines } catch { [] }
|
|
||||||
let ssh_config_global = try { open /etc/ssh/ssh_config | lines } catch { [] }
|
|
||||||
let known_hosts = try { open ~/.ssh/known_hosts | lines } catch { [] }
|
|
||||||
let hosts_file = try { open /etc/hosts | lines } catch { [] }
|
|
||||||
|
|
||||||
[
|
|
||||||
(
|
|
||||||
# Process ssh config files
|
|
||||||
$ssh_configs | append $ssh_configs_d | append $ssh_config_global
|
|
||||||
| where {|it| ($it | str downcase | str starts-with 'host') or ($it | str downcase | str starts-with 'hostname') }
|
|
||||||
| parse --regex '^\s*host(?:name)?\s+(?<hosts>.+)' # Extract hosts after keyword
|
|
||||||
| default { hosts: null } # Handle lines that don't match regex
|
|
||||||
| get hosts
|
|
||||||
| where {|it| $it != null }
|
|
||||||
| split row ' '
|
|
||||||
| where {|it| not ($it =~ '[*?%]') } # Exclude patterns containing *, ?, or %
|
|
||||||
)
|
|
||||||
(
|
|
||||||
# Process known_hosts file
|
|
||||||
$known_hosts | parse --regex '^(?:\[)?(?<hosts>[a-z0-9.,:_-]+)' # Extract hostnames (possibly in [], possibly comma-separated) - added underscore
|
|
||||||
| default { hosts: null }
|
|
||||||
| get hosts
|
|
||||||
| where {|it| $it != null }
|
|
||||||
| each { |it| $it | split row ',' } # Split comma-separated hosts if any
|
|
||||||
| flatten
|
|
||||||
)
|
|
||||||
(
|
|
||||||
# Process /etc/hosts file
|
|
||||||
$hosts_file | where { |it| not ($it | str starts-with '#') } # Ignore comments
|
|
||||||
| where { |it| not ($it | str trim | is-empty) } # Ignore empty lines
|
|
||||||
| where { |it| not ($it | str contains '0.0.0.0') } # Ignore 0.0.0.0
|
|
||||||
| str replace --regex '#.*$' '' # Remove trailing comments
|
|
||||||
| parse --regex '^\s*\S+\s+(?<hosts>.+)' # Extract hosts part (after IP)
|
|
||||||
| default { hosts: null }
|
|
||||||
| get hosts
|
|
||||||
| where {|it| $it != null }
|
|
||||||
| split row ' ' # Split multiple hosts on the same line
|
|
||||||
)
|
|
||||||
]
|
|
||||||
| flatten # Combine all lists into a single stream
|
|
||||||
| where {|it| not ($it | is-empty) } # Remove empty entries
|
|
||||||
| sort | uniq # Sort and remove duplicates
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
# Base function for path/directory completion
|
|
||||||
def __fzf_generic_path_completion [ prefix: string # The text before the trigger
|
|
||||||
, fzf_opts_arg: list<string> # Extra options for fzf
|
|
||||||
, suffix: string # Suffix to add to selection (e.g. , "/")
|
|
||||||
] {
|
|
||||||
# --- Determine walker root and initial query from the prefix ---
|
|
||||||
|
|
||||||
mut walker_root = "."
|
|
||||||
mut initial_query = ""
|
|
||||||
|
|
||||||
if ($prefix | is-empty) {
|
|
||||||
# Case: "**"
|
|
||||||
$walker_root = "."
|
|
||||||
$initial_query = ""
|
|
||||||
} else if ($prefix | str contains (char separator)) {
|
|
||||||
# Case: "dir/subdir/partial**" or "dir/**"
|
|
||||||
$walker_root = $prefix | path dirname
|
|
||||||
$initial_query = $prefix | path basename
|
|
||||||
# Handle edge case where prefix ends with separator, e.g., "dir/"
|
|
||||||
if ($prefix | str ends-with (char separator)) {
|
|
||||||
# Remove trailing separator to get the intended directory
|
|
||||||
$walker_root = $prefix | str substring 0..-2
|
|
||||||
$initial_query = ""
|
|
||||||
}
|
|
||||||
# Ensure walker_root isn't empty if prefix was like "/file**"
|
|
||||||
# or if path dirname returned empty string for some reason (e.g. prefix="file/")
|
|
||||||
if ($walker_root | is-empty) {
|
|
||||||
if ($prefix | str starts-with (char separator)) {
|
|
||||||
$walker_root = (char separator)
|
|
||||||
} else if ($prefix | str ends-with (char separator)) {
|
|
||||||
$walker_root = $prefix | str substring 0..-2
|
|
||||||
} else { $walker_root = "." } # Fallback if dirname weirdly fails
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
# Case: "partial**" (no slashes)
|
|
||||||
$walker_root = "."
|
|
||||||
$initial_query = $prefix
|
|
||||||
}
|
|
||||||
|
|
||||||
# --- Prepare FZF options ---
|
|
||||||
let completion_type_opts = if $suffix == '/' {
|
|
||||||
$env.FZF_COMPLETION_DIR_OPTS? | default '' | split row ' ' | where {not ($in | is-empty)}
|
|
||||||
} else {
|
|
||||||
$env.FZF_COMPLETION_PATH_OPTS? | default '' | split row ' ' | where {not ($in | is-empty)}
|
|
||||||
}
|
|
||||||
|
|
||||||
let walker_type = if ($suffix == '/') {
|
|
||||||
"dir,follow"
|
|
||||||
} else {
|
|
||||||
"file,dir,follow,hidden"
|
|
||||||
}
|
|
||||||
# Expand tilde so fzf receives a valid absolute path as walker-root
|
|
||||||
let needs_tilde_rewrite = ($walker_root | str starts-with '~')
|
|
||||||
let walker_root_expanded = ($walker_root | path expand)
|
|
||||||
|
|
||||||
# Use the 'walker_root' calculated at the beginning
|
|
||||||
let fzf_all_opts = ["--scheme=path", "--walker", $walker_type, "--walker-root", $walker_root_expanded] | append $fzf_opts_arg
|
|
||||||
| append $completion_type_opts
|
|
||||||
|
|
||||||
# Call FZF run
|
|
||||||
let fzf_selection = ( __fzf_comprun "fzf-path-completion-walker" $initial_query $fzf_all_opts ) | str trim
|
|
||||||
|
|
||||||
|
|
||||||
# --- Return Result ---
|
|
||||||
if ($fzf_selection | is-not-empty) {
|
|
||||||
# Restore tilde prefix if the user originally typed ~/
|
|
||||||
let home = $nu.home-dir | path expand
|
|
||||||
let result = if $needs_tilde_rewrite {
|
|
||||||
$fzf_selection | lines | each {|line| $line | str replace $home '~' } | str join ' '
|
|
||||||
} else {
|
|
||||||
$fzf_selection | lines | str join ' '
|
|
||||||
}
|
|
||||||
[$result]
|
|
||||||
} else {
|
|
||||||
[]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# Specific path completion wrapper
|
|
||||||
def _fzf_path_completion [prefix: string] {
|
|
||||||
# Zsh args: base, lbuf, _fzf_compgen_path, "-m", "", " "
|
|
||||||
# Nu: prefix, empty command name (use find), ["-m"], "", " "
|
|
||||||
__fzf_generic_path_completion $prefix ["-m"] ""
|
|
||||||
}
|
|
||||||
|
|
||||||
# General completion helper for commands that feed a list to fzf
|
|
||||||
# This is called by ssh, kill, and user-defined completers.
|
|
||||||
def _fzf_complete [ query: string # The initial query string for fzf
|
|
||||||
, data_gen_closure: closure # Closure that generates candidates
|
|
||||||
, fzf_opts_arg: list<string> # Extra options for fzf (like -m, +m)
|
|
||||||
, --post_process_closure: closure # Closure to process the selected item (optional)
|
|
||||||
] {
|
|
||||||
# Generate candidates using the provided command
|
|
||||||
let candidates = try {
|
|
||||||
do $data_gen_closure
|
|
||||||
} catch {
|
|
||||||
# Capture the actual error object provided by the catch block
|
|
||||||
let actual_error = $in
|
|
||||||
# Print a more informative error message including the actual error details
|
|
||||||
print -e $"Error executing data_gen closure. Closure code: ($data_gen_closure). Actual error: ($actual_error)"
|
|
||||||
[]
|
|
||||||
}
|
|
||||||
|
|
||||||
# Run fzf and get selection
|
|
||||||
let fzf_selection = $candidates | to text
|
|
||||||
| __fzf_comprun "fzf-helper" $query $fzf_opts_arg
|
|
||||||
| str trim # Trim potential trailing newline from fzf
|
|
||||||
|
|
||||||
# Apply post-processing if closure provided and selection is not empty
|
|
||||||
let processed_selection = if ($fzf_selection | is-not-empty) and ($post_process_closure | is-not-empty) {
|
|
||||||
# Call the post-processing closure with the selection
|
|
||||||
try {
|
|
||||||
do $post_process_closure $fzf_selection
|
|
||||||
} catch {
|
|
||||||
print -e $"Error executing post_process closure: ($post_process_closure)"
|
|
||||||
$fzf_selection # Return original selection on error
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
$fzf_selection
|
|
||||||
}
|
|
||||||
|
|
||||||
if not ($processed_selection | is-empty) {
|
|
||||||
[($processed_selection | lines | str join ' ')]
|
|
||||||
} else {
|
|
||||||
[]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# SSH/Telnet completion
|
|
||||||
def _fzf_complete_ssh [ prefix: string
|
|
||||||
, input_line_before_trigger: string
|
|
||||||
] {
|
|
||||||
let words = ($input_line_before_trigger | split row ' ')
|
|
||||||
let word_count = $words | length
|
|
||||||
|
|
||||||
# Find the index of the word being completed (which is the prefix)
|
|
||||||
# If prefix is empty, completion happens after a space, index is word_count
|
|
||||||
# If prefix is not empty, it's the last word, index is word_count - 1
|
|
||||||
let completion_index = if ($prefix | is-empty) { $word_count } else { $word_count - 1 }
|
|
||||||
|
|
||||||
mut handled = false
|
|
||||||
mut completion_result = [] # List of completion strings to return
|
|
||||||
|
|
||||||
# Check for -i, -F, -E flags immediately preceding the cursor position
|
|
||||||
if $completion_index > 0 {
|
|
||||||
let prev_arg = ($words | get ($completion_index - 1))
|
|
||||||
if ($prev_arg in ['-i', '-F', '-E']) {
|
|
||||||
$handled = true
|
|
||||||
# Call path completion with the current prefix
|
|
||||||
$completion_result = (_fzf_path_completion $prefix)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# If not handled by path completion, do host completion
|
|
||||||
if not $handled {
|
|
||||||
let user_part = if ($prefix | str contains "@") { ($prefix | split row "@" | first) + "@" } else { "" }
|
|
||||||
# The part after '@' (or the whole prefix if no '@') is the initial query for fzf
|
|
||||||
let query = if ($prefix | str contains "@") { $prefix | split row "@" | last } else { $prefix }
|
|
||||||
|
|
||||||
let host_candidates_gen = {||
|
|
||||||
__fzf_list_hosts
|
|
||||||
| each {|host_item| $user_part + $host_item } # Prepend user@ if present in prefix
|
|
||||||
}
|
|
||||||
|
|
||||||
# Zsh options: +m -- ; Nu: pass ["+m"]
|
|
||||||
# Pass the host part of the prefix to _fzf_complete for the initial query
|
|
||||||
let selected_host = (_fzf_complete $query $host_candidates_gen ["+m"]) # Pass host_prefix here
|
|
||||||
if not ($selected_host | is-empty) {
|
|
||||||
$completion_result = $selected_host # _fzf_complete returns a list
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
$completion_result
|
|
||||||
}
|
|
||||||
|
|
||||||
# Kill completion post-processor (extracts PID)
|
|
||||||
def _fzf_complete_kill_post_get_pid [selected_line: string] {
|
|
||||||
# Assuming standard ps output where PID is the second column
|
|
||||||
$selected_line | lines | each { $in | from ssv --noheaders | get 0.column1 } | to text
|
|
||||||
}
|
|
||||||
|
|
||||||
# Kill completion to get process PID
|
|
||||||
def _fzf_complete_kill [query: string] {
|
|
||||||
let ps_gen_closure = {|| # Define ps generator as a closure
|
|
||||||
# Try standard ps, then busybox, then cygwin format approximation
|
|
||||||
# Use `^ps` to ensure external command execution
|
|
||||||
try {
|
|
||||||
^ps -eo user,pid,ppid,start,time,command | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
|
||||||
} catch {
|
|
||||||
try {
|
|
||||||
^ps -eo user,pid,ppid,time,args | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
|
||||||
} catch {
|
|
||||||
try {
|
|
||||||
^ps --everyone --full --windows | complete | if $in.exit_code == 0 { $in.stdout | lines } else { error make {msg: "ps failed"} }
|
|
||||||
} catch {
|
|
||||||
print -e "Error: ps command failed."
|
|
||||||
[] # Return empty list on failure
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# Note: Complex Zsh FZF bindings for kill (click-header transformer) are omitted for simplicity.
|
|
||||||
# Users can set custom bindings via FZF_DEFAULT_OPTS if needed.
|
|
||||||
let kill_post_closure = {|selected_line| _fzf_complete_kill_post_get_pid $selected_line }
|
|
||||||
|
|
||||||
let fzf_opts = ["-m", "--header-lines=1", "--no-preview", "--wrap", "--color", "fg:dim,nth:regular"]
|
|
||||||
|
|
||||||
_fzf_complete $query $ps_gen_closure $fzf_opts --post_process_closure $kill_post_closure
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
# --- Main FZF External Completer ---
|
|
||||||
|
|
||||||
# This function is registered with Nushell's external completion system.
|
|
||||||
# It gets called when Tab is pressed.
|
|
||||||
let fzf_external_completer = {|spans|
|
|
||||||
let trigger: string = $env.FZF_COMPLETION_TRIGGER? | default '**'
|
|
||||||
|
|
||||||
if ($trigger | is-empty) { return null } # Cannot work with empty trigger
|
|
||||||
if (($spans | length ) == 0) { return null } # Nothing to complete
|
|
||||||
|
|
||||||
let last_span = $spans | last
|
|
||||||
|
|
||||||
if ($last_span | str ends-with $trigger) {
|
|
||||||
# --- Trigger Found ---
|
|
||||||
|
|
||||||
# Skip sudo to determine the actual command
|
|
||||||
let cmd_spans = if ($spans | first) == "sudo" { $spans | skip 1 } else { $spans }
|
|
||||||
let cmd_word = ($cmd_spans | first | default "")
|
|
||||||
|
|
||||||
# Calculate the prefix (part before the trigger in the last span)
|
|
||||||
let prefix = $last_span | str substring 0..(-1 * ($trigger | str length) - 1)
|
|
||||||
|
|
||||||
# Reconstruct the line content *before* the trigger for context
|
|
||||||
# This is an approximation based on spans
|
|
||||||
let line_without_trigger = $cmd_spans | take (($cmd_spans | length) - 1) | append $prefix | str join ' '
|
|
||||||
|
|
||||||
# --- Dispatch to Completer ---
|
|
||||||
mut completion_results = [] # Will hold the list of strings from the completer
|
|
||||||
|
|
||||||
# Check for user-defined completer in $env.FZF_COMPLETERS first.
|
|
||||||
# Users can define custom completers in their config.nu as a record of closures:
|
|
||||||
# $env.FZF_COMPLETERS = { git: {|prefix, spans| ... }, docker: {|prefix, spans| ... } }
|
|
||||||
# Each closure receives the prefix (text before the trigger) and the full
|
|
||||||
# command spans (e.g. ["pacman", "-S", "vim**"]), and should return either:
|
|
||||||
# - a list of candidate strings, or
|
|
||||||
# - a record { candidates: [...], opts: [...], post: {|sel| ...} } to pass
|
|
||||||
# custom fzf options and/or a post-processing closure.
|
|
||||||
# See shell/completion-examples.nu for examples.
|
|
||||||
let user_completers = ($env.FZF_COMPLETERS? | default {})
|
|
||||||
if ($cmd_word in $user_completers) {
|
|
||||||
let user_gen = ($user_completers | get $cmd_word)
|
|
||||||
let user_result = (do $user_gen $prefix $cmd_spans)
|
|
||||||
if ($user_result | describe | str starts-with 'record') {
|
|
||||||
let candidates = ($user_result | get candidates)
|
|
||||||
let fzf_opts = ($user_result | get opts? | default ["-m"])
|
|
||||||
let post = ($user_result | get post? | default null)
|
|
||||||
if ($post != null) {
|
|
||||||
$completion_results = (_fzf_complete $prefix {|| $candidates} $fzf_opts --post_process_closure $post)
|
|
||||||
} else {
|
|
||||||
$completion_results = (_fzf_complete $prefix {|| $candidates} $fzf_opts)
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
$completion_results = (_fzf_complete $prefix {|| $user_result} ["-m"])
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
match $cmd_word {
|
|
||||||
"ssh" | "scp" | "sftp" | "telnet" => { $completion_results = (_fzf_complete_ssh $prefix $line_without_trigger) }
|
|
||||||
"kill" => { $completion_results = (_fzf_complete_kill $prefix) }
|
|
||||||
_ if ($cmd_word in $env.FZF_COMPLETION_DIR_COMMANDS) => {
|
|
||||||
$completion_results = (__fzf_generic_path_completion $prefix [] "/")
|
|
||||||
}
|
|
||||||
_ => {
|
|
||||||
# Default to path completion if no specific command matches
|
|
||||||
$completion_results = (_fzf_path_completion $prefix)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# --- Return Results ---
|
|
||||||
# The _fzf_... functions return a list of completion strings.
|
|
||||||
# Nushell's completer expects the suggestions for the token being completed (prefix + trigger).
|
|
||||||
# The results from the helper functions should be the final desired strings.
|
|
||||||
# We don't need to manually add spaces; Nushell handles that.
|
|
||||||
$completion_results # Return the list directly
|
|
||||||
} else {
|
|
||||||
# --- Trigger Not Found ---
|
|
||||||
# Return null to let Nushell fall back to other completers (e.g., default file completion).
|
|
||||||
null
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# --- WRAPPER AND REGISTRATION ---
|
|
||||||
|
|
||||||
# Guard against re-sourcing: wrapping the completer multiple times would
|
|
||||||
# nest wrappers and grow the call chain on every reload.
|
|
||||||
if ($env.__fzf_completer_registered? | default false) != true {
|
|
||||||
|
|
||||||
# Get the currently configured external completer, if any exists
|
|
||||||
let previous_external_completer = $env.config? | get completions? | get external? | get completer?
|
|
||||||
|
|
||||||
# Define the new wrapper completer
|
|
||||||
let fzf_wrapper_completer = {|spans|
|
|
||||||
# 1. Try the FZF completer logic first
|
|
||||||
let fzf_result = do $fzf_external_completer $spans
|
|
||||||
|
|
||||||
# 2. If FZF returned a result (a list, even an empty one), return it.
|
|
||||||
# `null` means FZF didn't handle it because the trigger wasn't present.
|
|
||||||
if $fzf_result != null {
|
|
||||||
$fzf_result
|
|
||||||
} else {
|
|
||||||
# 3. FZF didn't handle it, so call the previous completer (if it exists).
|
|
||||||
if $previous_external_completer != null {
|
|
||||||
do $previous_external_completer $spans
|
|
||||||
} else {
|
|
||||||
# 4. No previous completer, and FZF didn't handle it. Return null.
|
|
||||||
null
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
# Register the new wrapper completer
|
|
||||||
# This ensures external completions are enabled and sets our wrapper.
|
|
||||||
$env.config = $env.config | upsert completions {
|
|
||||||
external: {
|
|
||||||
enable: true
|
|
||||||
completer: $fzf_wrapper_completer
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
$env.__fzf_completer_registered = true
|
|
||||||
}
|
|
||||||
|
|
||||||
# vim: set sts=2 ts=2 sw=2 tw=120 et :
|
|
||||||
+41
-140
@@ -4,6 +4,8 @@
|
|||||||
# / __/ / /_/ __/
|
# / __/ / /_/ __/
|
||||||
# /_/ /___/_/ completion.zsh
|
# /_/ /___/_/ completion.zsh
|
||||||
#
|
#
|
||||||
|
# - $FZF_TMUX (default: 0)
|
||||||
|
# - $FZF_TMUX_OPTS (default: empty)
|
||||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||||
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
# - $FZF_COMPLETION_PATH_OPTS (default: empty)
|
||||||
@@ -94,35 +96,14 @@ if [[ -o interactive ]]; then
|
|||||||
|
|
||||||
###########################################################
|
###########################################################
|
||||||
|
|
||||||
#----BEGIN INCLUDE common.sh
|
|
||||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
|
||||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
|
||||||
# the changes. See code comments in "common.sh" for the implementation details.
|
|
||||||
|
|
||||||
__fzf_defaults() {
|
__fzf_defaults() {
|
||||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
echo "--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore $1"
|
||||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
echo "${FZF_DEFAULT_OPTS-} $2"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_exec_awk() {
|
|
||||||
if [[ -z ${__fzf_awk-} ]]; then
|
|
||||||
__fzf_awk=awk
|
|
||||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
|
||||||
__fzf_awk=/usr/xpg4/bin/awk
|
|
||||||
elif command -v mawk > /dev/null 2>&1; then
|
|
||||||
local n x y z d
|
|
||||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
|
||||||
[[ $n == mawk ]] &&
|
|
||||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
|
||||||
((d >= 20230302)) 2> /dev/null &&
|
|
||||||
__fzf_awk=mawk
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
|
||||||
}
|
|
||||||
#----END INCLUDE
|
|
||||||
|
|
||||||
__fzf_comprun() {
|
__fzf_comprun() {
|
||||||
if [[ "$(type _fzf_comprun 2>&1)" =~ function ]]; then
|
if [[ "$(type _fzf_comprun 2>&1)" =~ function ]]; then
|
||||||
_fzf_comprun "$@"
|
_fzf_comprun "$@"
|
||||||
@@ -139,18 +120,25 @@ __fzf_comprun() {
|
|||||||
fi
|
fi
|
||||||
}
|
}
|
||||||
|
|
||||||
# Extract the name of the command. e.g. ls; foo=1 ssh **<tab>
|
# Extract the name of the command. e.g. foo=1 bar baz**<tab>
|
||||||
__fzf_extract_command() {
|
__fzf_extract_command() {
|
||||||
# Control completion with the "compstate" parameter, insert and list nothing
|
local token tokens
|
||||||
compstate[insert]=
|
tokens=(${(z)1})
|
||||||
compstate[list]=
|
for token in $tokens; do
|
||||||
cmd_word="${(Q)words[1]}"
|
token=${(Q)token}
|
||||||
|
if [[ "$token" =~ [[:alnum:]] && ! "$token" =~ "=" ]]; then
|
||||||
|
echo "$token"
|
||||||
|
return
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
echo "${tokens[1]}"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_generic_path_completion() {
|
__fzf_generic_path_completion() {
|
||||||
local base lbuf compgen fzf_opts suffix tail dir leftover matches
|
local base lbuf cmd compgen fzf_opts suffix tail dir leftover matches
|
||||||
base=$1
|
base=$1
|
||||||
lbuf=$2
|
lbuf=$2
|
||||||
|
cmd=$(__fzf_extract_command "$lbuf")
|
||||||
compgen=$3
|
compgen=$3
|
||||||
fzf_opts=$4
|
fzf_opts=$4
|
||||||
suffix=$5
|
suffix=$5
|
||||||
@@ -172,20 +160,17 @@ __fzf_generic_path_completion() {
|
|||||||
export FZF_DEFAULT_OPTS
|
export FZF_DEFAULT_OPTS
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-}")
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --scheme=path" "${FZF_COMPLETION_OPTS-}")
|
||||||
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
unset FZF_DEFAULT_COMMAND FZF_DEFAULT_OPTS_FILE
|
||||||
if [[ $compgen =~ dir ]]; then
|
|
||||||
rest=${FZF_COMPLETION_DIR_OPTS-}
|
|
||||||
else
|
|
||||||
rest=${FZF_COMPLETION_PATH_OPTS-}
|
|
||||||
fi
|
|
||||||
if declare -f "$compgen" > /dev/null; then
|
if declare -f "$compgen" > /dev/null; then
|
||||||
eval "$compgen $(printf %q "$dir")" | __fzf_comprun "$cmd_word" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" ${(Q)${(Z+n+)rest}}
|
eval "$compgen $(printf %q "$dir")" | __fzf_comprun "$cmd" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover"
|
||||||
else
|
else
|
||||||
if [[ $compgen =~ dir ]]; then
|
if [[ $compgen =~ dir ]]; then
|
||||||
walker=dir,follow
|
walker=dir,follow
|
||||||
|
rest=${FZF_COMPLETION_DIR_OPTS-}
|
||||||
else
|
else
|
||||||
walker=file,dir,follow,hidden
|
walker=file,dir,follow,hidden
|
||||||
|
rest=${FZF_COMPLETION_PATH_OPTS-}
|
||||||
fi
|
fi
|
||||||
__fzf_comprun "$cmd_word" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" --walker "$walker" --walker-root="$dir" ${(Q)${(Z+n+)rest}} < /dev/tty
|
__fzf_comprun "$cmd" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" --walker "$walker" --walker-root="$dir" ${(Q)${(Z+n+)rest}} < /dev/tty
|
||||||
fi | while read -r item; do
|
fi | while read -r item; do
|
||||||
item="${item%$suffix}$suffix"
|
item="${item%$suffix}$suffix"
|
||||||
echo -n -E "${(q)item} "
|
echo -n -E "${(q)item} "
|
||||||
@@ -242,9 +227,10 @@ _fzf_complete() {
|
|||||||
rest=("$@")
|
rest=("$@")
|
||||||
fi
|
fi
|
||||||
|
|
||||||
local fifo lbuf matches post
|
local fifo lbuf cmd matches post
|
||||||
fifo="${TMPDIR:-/tmp}/fzf-complete-fifo-$$"
|
fifo="${TMPDIR:-/tmp}/fzf-complete-fifo-$$"
|
||||||
lbuf=${rest[0]}
|
lbuf=${rest[0]}
|
||||||
|
cmd=$(__fzf_extract_command "$lbuf")
|
||||||
post="${funcstack[1]}_post"
|
post="${funcstack[1]}_post"
|
||||||
type $post > /dev/null 2>&1 || post=cat
|
type $post > /dev/null 2>&1 || post=cat
|
||||||
|
|
||||||
@@ -252,7 +238,7 @@ _fzf_complete() {
|
|||||||
matches=$(
|
matches=$(
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse" "${FZF_COMPLETION_OPTS-} $str_arg") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' \
|
FZF_DEFAULT_OPTS_FILE='' \
|
||||||
__fzf_comprun "$cmd_word" "${args[@]}" -q "${(Q)prefix}" < "$fifo" | $post | tr '\n' ' ')
|
__fzf_comprun "$cmd" "${args[@]}" -q "${(Q)prefix}" < "$fifo" | $post | tr '\n' ' ')
|
||||||
if [ -n "$matches" ]; then
|
if [ -n "$matches" ]; then
|
||||||
LBUFFER="$lbuf$matches"
|
LBUFFER="$lbuf$matches"
|
||||||
fi
|
fi
|
||||||
@@ -264,50 +250,11 @@ _fzf_complete() {
|
|||||||
# desired sorting and with any duplicates removed, to standard output.
|
# desired sorting and with any duplicates removed, to standard output.
|
||||||
if ! declare -f __fzf_list_hosts > /dev/null; then
|
if ! declare -f __fzf_list_hosts > /dev/null; then
|
||||||
__fzf_list_hosts() {
|
__fzf_list_hosts() {
|
||||||
command sort -u \
|
setopt localoptions nonomatch
|
||||||
<(
|
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?%]') \
|
||||||
# Note: To make the pathname expansion of "~/.ssh/config.d/*" work
|
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts 2> /dev/null | tr ',' '\n' | tr -d '[' | awk '{ print $1 " " $1 }') \
|
||||||
# properly, we need to adjust the related shell options. We need to
|
<(command grep -v '^\s*\(#\|$\)' /etc/hosts 2> /dev/null | command grep -Fv '0.0.0.0' | command sed 's/#.*//') |
|
||||||
# unset "NO_GLOB" (or reset "GLOB"), which disable the pathname
|
awk '{for (i = 2; i <= NF; i++) print $i}' | sort -u
|
||||||
# expansion totally. We need to unset "DOT_GLOB" and set "CASE_GLOB"
|
|
||||||
# to avoid matching unwanted files. We need to set "NULL_GLOB" to
|
|
||||||
# avoid attempting to read the literal filename '~/.ssh/config.d/*'
|
|
||||||
# when no matching is found.
|
|
||||||
setopt GLOB NO_DOT_GLOB CASE_GLOB NO_NOMATCH NULL_GLOB
|
|
||||||
|
|
||||||
__fzf_exec_awk '
|
|
||||||
# Note: mawk <= 1.3.3-20090705 does not support the POSIX brackets of
|
|
||||||
# the form [[:blank:]], and Ubuntu 18.04 LTS still uses this
|
|
||||||
# 16-year-old mawk unfortunately. We need to use [ \t] instead.
|
|
||||||
match(tolower($0), /^[ \t]*host(name)?[ \t]*[ \t=]/) {
|
|
||||||
$0 = substr($0, RLENGTH + 1) # Remove "Host(name)?=?"
|
|
||||||
sub(/#.*/, "")
|
|
||||||
for (i = 1; i <= NF; i++)
|
|
||||||
if ($i !~ /[*?%]/)
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null
|
|
||||||
) \
|
|
||||||
<(
|
|
||||||
__fzf_exec_awk -F ',' '
|
|
||||||
match($0, /^[][a-zA-Z0-9.,:-]+/) {
|
|
||||||
$0 = substr($0, 1, RLENGTH)
|
|
||||||
gsub(/[][]|:[^,]*/, "")
|
|
||||||
for (i = 1; i <= NF; i++)
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' ~/.ssh/known_hosts 2> /dev/null
|
|
||||||
) \
|
|
||||||
<(
|
|
||||||
__fzf_exec_awk '
|
|
||||||
{
|
|
||||||
sub(/#.*/, "")
|
|
||||||
for (i = 2; i <= NF; i++)
|
|
||||||
if ($i != "0.0.0.0")
|
|
||||||
print $i
|
|
||||||
}
|
|
||||||
' /etc/hosts 2> /dev/null
|
|
||||||
)
|
|
||||||
}
|
}
|
||||||
fi
|
fi
|
||||||
|
|
||||||
@@ -327,7 +274,7 @@ _fzf_complete_ssh() {
|
|||||||
*)
|
*)
|
||||||
local user
|
local user
|
||||||
[[ $prefix =~ @ ]] && user="${prefix%%@*}@"
|
[[ $prefix =~ @ ]] && user="${prefix%%@*}@"
|
||||||
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | __fzf_exec_awk -v user="$user" '{print user $0}')
|
_fzf_complete +m -- "$@" < <(__fzf_list_hosts | awk -v user="$user" '{print user $0}')
|
||||||
;;
|
;;
|
||||||
esac
|
esac
|
||||||
}
|
}
|
||||||
@@ -351,33 +298,7 @@ _fzf_complete_unalias() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
_fzf_complete_kill() {
|
_fzf_complete_kill() {
|
||||||
local transformer
|
_fzf_complete -m --header-lines=1 --no-preview --wrap -- "$@" < <(
|
||||||
transformer='
|
|
||||||
if [[ $FZF_KEY =~ ctrl|alt|shift ]] && [[ -n $FZF_NTH ]]; then
|
|
||||||
nths=( ${FZF_NTH//,/ } )
|
|
||||||
new_nths=()
|
|
||||||
found=0
|
|
||||||
for nth in ${nths[@]}; do
|
|
||||||
if [[ $nth = $FZF_CLICK_HEADER_NTH ]]; then
|
|
||||||
found=1
|
|
||||||
else
|
|
||||||
new_nths+=($nth)
|
|
||||||
fi
|
|
||||||
done
|
|
||||||
[[ $found = 0 ]] && new_nths+=($FZF_CLICK_HEADER_NTH)
|
|
||||||
new_nths=${new_nths[*]}
|
|
||||||
new_nths=${new_nths// /,}
|
|
||||||
echo "change-nth($new_nths)+change-prompt($new_nths> )"
|
|
||||||
else
|
|
||||||
if [[ $FZF_NTH = $FZF_CLICK_HEADER_NTH ]]; then
|
|
||||||
echo "change-nth()+change-prompt(> )"
|
|
||||||
else
|
|
||||||
echo "change-nth($FZF_CLICK_HEADER_NTH)+change-prompt($FZF_CLICK_HEADER_WORD> )"
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
'
|
|
||||||
_fzf_complete -m --header-lines=1 --no-preview --wrap --color fg:dim,nth:regular \
|
|
||||||
--bind "click-header:transform:$transformer" -- "$@" < <(
|
|
||||||
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
command ps -eo user,pid,ppid,start,time,command 2> /dev/null ||
|
||||||
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
command ps -eo user,pid,ppid,time,args 2> /dev/null || # For BusyBox
|
||||||
command ps --everyone --full --windows # For cygwin
|
command ps --everyone --full --windows # For cygwin
|
||||||
@@ -385,11 +306,11 @@ _fzf_complete_kill() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
_fzf_complete_kill_post() {
|
_fzf_complete_kill_post() {
|
||||||
__fzf_exec_awk '{print $2}'
|
awk '{print $2}'
|
||||||
}
|
}
|
||||||
|
|
||||||
fzf-completion() {
|
fzf-completion() {
|
||||||
local tokens prefix trigger tail matches lbuf d_cmds cursor_pos cmd_word
|
local tokens cmd prefix trigger tail matches lbuf d_cmds
|
||||||
setopt localoptions noshwordsplit noksh_arrays noposixbuiltins
|
setopt localoptions noshwordsplit noksh_arrays noposixbuiltins
|
||||||
|
|
||||||
# http://zsh.sourceforge.net/FAQ/zshfaq03.html
|
# http://zsh.sourceforge.net/FAQ/zshfaq03.html
|
||||||
@@ -400,9 +321,11 @@ fzf-completion() {
|
|||||||
return
|
return
|
||||||
fi
|
fi
|
||||||
|
|
||||||
|
cmd=$(__fzf_extract_command "$LBUFFER")
|
||||||
|
|
||||||
# Explicitly allow for empty trigger.
|
# Explicitly allow for empty trigger.
|
||||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||||
[[ -z $trigger && ${LBUFFER[-1]} == ' ' ]] && tokens+=("")
|
[ -z "$trigger" -a ${LBUFFER[-1]} = ' ' ] && tokens+=("")
|
||||||
|
|
||||||
# When the trigger starts with ';', it becomes a separate token
|
# When the trigger starts with ';', it becomes a separate token
|
||||||
if [[ ${LBUFFER} = *"${tokens[-2]-}${tokens[-1]}" ]]; then
|
if [[ ${LBUFFER} = *"${tokens[-2]-}${tokens[-1]}" ]]; then
|
||||||
@@ -417,37 +340,16 @@ fzf-completion() {
|
|||||||
if [ ${#tokens} -gt 1 -a "$tail" = "$trigger" ]; then
|
if [ ${#tokens} -gt 1 -a "$tail" = "$trigger" ]; then
|
||||||
d_cmds=(${=FZF_COMPLETION_DIR_COMMANDS-cd pushd rmdir})
|
d_cmds=(${=FZF_COMPLETION_DIR_COMMANDS-cd pushd rmdir})
|
||||||
|
|
||||||
{
|
|
||||||
cursor_pos=$CURSOR
|
|
||||||
# Move the cursor before the trigger to preserve word array elements when
|
|
||||||
# trigger chars like ';' or '`' would otherwise reset the 'words' array.
|
|
||||||
CURSOR=$((cursor_pos - ${#trigger} - 1))
|
|
||||||
# Check if at least one completion system (old or new) is active.
|
|
||||||
# If at least one user-defined completion widget is detected, nothing will
|
|
||||||
# be completed if neither the old nor the new completion system is enabled.
|
|
||||||
# In such cases, the 'zsh/compctl' module is loaded as a fallback.
|
|
||||||
if ! zmodload -F zsh/parameter p:functions 2>/dev/null || ! (( ${+functions[compdef]} )); then
|
|
||||||
zmodload -F zsh/compctl 2>/dev/null
|
|
||||||
fi
|
|
||||||
# Create a completion widget to access the 'words' array (man zshcompwid)
|
|
||||||
zle -C __fzf_extract_command .complete-word __fzf_extract_command
|
|
||||||
zle __fzf_extract_command
|
|
||||||
} always {
|
|
||||||
CURSOR=$cursor_pos
|
|
||||||
# Delete the completion widget
|
|
||||||
zle -D __fzf_extract_command 2>/dev/null
|
|
||||||
}
|
|
||||||
|
|
||||||
[ -z "$trigger" ] && prefix=${tokens[-1]} || prefix=${tokens[-1]:0:-${#trigger}}
|
[ -z "$trigger" ] && prefix=${tokens[-1]} || prefix=${tokens[-1]:0:-${#trigger}}
|
||||||
if [[ $prefix = *'$('* ]] || [[ $prefix = *'<('* ]] || [[ $prefix = *'>('* ]] || [[ $prefix = *':='* ]] || [[ $prefix = *'`'* ]]; then
|
if [[ $prefix = *'$('* ]] || [[ $prefix = *'<('* ]] || [[ $prefix = *'>('* ]] || [[ $prefix = *':='* ]] || [[ $prefix = *'`'* ]]; then
|
||||||
return
|
return
|
||||||
fi
|
fi
|
||||||
[ -n "${tokens[-1]}" ] && lbuf=${lbuf:0:-${#tokens[-1]}}
|
[ -n "${tokens[-1]}" ] && lbuf=${lbuf:0:-${#tokens[-1]}}
|
||||||
|
|
||||||
if eval "noglob type _fzf_complete_${cmd_word} >/dev/null"; then
|
if eval "type _fzf_complete_${cmd} > /dev/null"; then
|
||||||
prefix="$prefix" eval _fzf_complete_${cmd_word} ${(q)lbuf}
|
prefix="$prefix" eval _fzf_complete_${cmd} ${(q)lbuf}
|
||||||
zle reset-prompt
|
zle reset-prompt
|
||||||
elif [ ${d_cmds[(i)$cmd_word]} -le ${#d_cmds} ]; then
|
elif [ ${d_cmds[(i)$cmd]} -le ${#d_cmds} ]; then
|
||||||
_fzf_dir_completion "$prefix" "$lbuf"
|
_fzf_dir_completion "$prefix" "$lbuf"
|
||||||
else
|
else
|
||||||
_fzf_path_completion "$prefix" "$lbuf"
|
_fzf_path_completion "$prefix" "$lbuf"
|
||||||
@@ -464,7 +366,6 @@ fzf-completion() {
|
|||||||
unset binding
|
unset binding
|
||||||
}
|
}
|
||||||
|
|
||||||
# Normal widget
|
|
||||||
zle -N fzf-completion
|
zle -N fzf-completion
|
||||||
bindkey '^I' fzf-completion
|
bindkey '^I' fzf-completion
|
||||||
fi
|
fi
|
||||||
|
|||||||
+43
-92
@@ -4,9 +4,9 @@
|
|||||||
# / __/ / /_/ __/
|
# / __/ / /_/ __/
|
||||||
# /_/ /___/_/ key-bindings.bash
|
# /_/ /___/_/ key-bindings.bash
|
||||||
#
|
#
|
||||||
|
# - $FZF_TMUX_OPTS
|
||||||
# - $FZF_CTRL_T_COMMAND
|
# - $FZF_CTRL_T_COMMAND
|
||||||
# - $FZF_CTRL_T_OPTS
|
# - $FZF_CTRL_T_OPTS
|
||||||
# - $FZF_CTRL_R_COMMAND
|
|
||||||
# - $FZF_CTRL_R_OPTS
|
# - $FZF_CTRL_R_OPTS
|
||||||
# - $FZF_ALT_C_COMMAND
|
# - $FZF_ALT_C_COMMAND
|
||||||
# - $FZF_ALT_C_OPTS
|
# - $FZF_ALT_C_OPTS
|
||||||
@@ -17,96 +17,56 @@ if [[ $- =~ i ]]; then
|
|||||||
# Key bindings
|
# Key bindings
|
||||||
# ------------
|
# ------------
|
||||||
|
|
||||||
#----BEGIN shfmt
|
|
||||||
#----BEGIN INCLUDE common.sh
|
|
||||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
|
||||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
|
||||||
# the changes. See code comments in "common.sh" for the implementation details.
|
|
||||||
|
|
||||||
__fzf_defaults() {
|
__fzf_defaults() {
|
||||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
echo "--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore $1"
|
||||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
echo "${FZF_DEFAULT_OPTS-} $2"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_exec_awk() {
|
|
||||||
if [[ -z ${__fzf_awk-} ]]; then
|
|
||||||
__fzf_awk=awk
|
|
||||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
|
||||||
__fzf_awk=/usr/xpg4/bin/awk
|
|
||||||
elif command -v mawk > /dev/null 2>&1; then
|
|
||||||
local n x y z d
|
|
||||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
|
||||||
[[ $n == mawk ]] &&
|
|
||||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
|
||||||
((d >= 20230302)) 2> /dev/null &&
|
|
||||||
__fzf_awk=mawk
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
|
||||||
}
|
|
||||||
#----END INCLUDE
|
|
||||||
|
|
||||||
__fzf_select__() {
|
__fzf_select__() {
|
||||||
FZF_DEFAULT_COMMAND=${FZF_CTRL_T_COMMAND:-} \
|
FZF_DEFAULT_COMMAND=${FZF_CTRL_T_COMMAND:-} \
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=file,dir,follow,hidden --scheme=path" "${FZF_CTRL_T_OPTS-} -m") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=file,dir,follow,hidden --scheme=path" "${FZF_CTRL_T_OPTS-} -m") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) "$@" |
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) "$@" |
|
||||||
while read -r item; do
|
while read -r item; do
|
||||||
printf '%q ' "$item" # escape special chars
|
printf '%q ' "$item" # escape special chars
|
||||||
done
|
done
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzfcmd() {
|
__fzfcmd() {
|
||||||
[[ -n ${TMUX_PANE-} ]] && { [[ ${FZF_TMUX:-0} != 0 ]] || [[ -n ${FZF_TMUX_OPTS-} ]]; } &&
|
[[ -n "${TMUX_PANE-}" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "${FZF_TMUX_OPTS-}" ]]; } &&
|
||||||
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
||||||
}
|
}
|
||||||
|
|
||||||
fzf-file-widget() {
|
fzf-file-widget() {
|
||||||
local selected="$(__fzf_select__ "$@")"
|
local selected="$(__fzf_select__ "$@")"
|
||||||
READLINE_LINE="${READLINE_LINE:0:READLINE_POINT}$selected${READLINE_LINE:READLINE_POINT}"
|
READLINE_LINE="${READLINE_LINE:0:$READLINE_POINT}$selected${READLINE_LINE:$READLINE_POINT}"
|
||||||
READLINE_POINT=$((READLINE_POINT + ${#selected}))
|
READLINE_POINT=$(( READLINE_POINT + ${#selected} ))
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_cd__() {
|
__fzf_cd__() {
|
||||||
local dir
|
local dir
|
||||||
dir=$(
|
dir=$(
|
||||||
FZF_DEFAULT_COMMAND=${FZF_ALT_C_COMMAND:-} \
|
FZF_DEFAULT_COMMAND=${FZF_ALT_C_COMMAND:-} \
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=dir,follow,hidden --scheme=path" "${FZF_ALT_C_OPTS-} +m") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "--reverse --walker=dir,follow,hidden --scheme=path" "${FZF_ALT_C_OPTS-} +m") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd)
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd)
|
||||||
) && printf 'builtin cd -- %q' "$(builtin unset CDPATH && builtin cd -- "$dir" && builtin pwd)"
|
) && printf 'builtin cd -- %q' "$(builtin unset CDPATH && builtin cd -- "$dir" && builtin pwd)"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_history_delete() {
|
|
||||||
[[ -s $1 ]] || return
|
|
||||||
|
|
||||||
local offsets
|
|
||||||
offsets=($(sort -rnu "$1"))
|
|
||||||
for offset in "${offsets[@]}"; do
|
|
||||||
builtin history -d "$offset"
|
|
||||||
done
|
|
||||||
|
|
||||||
if [[ ${#offsets[@]} -gt 0 ]] && shopt -q histappend; then
|
|
||||||
builtin history -w
|
|
||||||
fi
|
|
||||||
}
|
|
||||||
|
|
||||||
if command -v perl > /dev/null; then
|
if command -v perl > /dev/null; then
|
||||||
__fzf_history__() {
|
__fzf_history__() {
|
||||||
local output script deletefile
|
local output script
|
||||||
deletefile=$(mktemp)
|
|
||||||
script='BEGIN { getc; $/ = "\n\t"; $HISTCOUNT = $ENV{last_hist} + 1 } s/^[ *]//; s/\n/\n\t/gm; print $HISTCOUNT - $. . "\t$_" if !$seen{$_}++'
|
script='BEGIN { getc; $/ = "\n\t"; $HISTCOUNT = $ENV{last_hist} + 1 } s/^[ *]//; s/\n/\n\t/gm; print $HISTCOUNT - $. . "\t$_" if !$seen{$_}++'
|
||||||
output=$(
|
output=$(
|
||||||
set +o pipefail
|
set +o pipefail
|
||||||
builtin fc -lnr -2147483648 |
|
builtin fc -lnr -2147483648 |
|
||||||
last_hist=$(HISTTIMEFORMAT='' builtin history 1) command perl -n -l0 -e "$script" |
|
last_hist=$(HISTTIMEFORMAT='' builtin history 1) command perl -n -l0 -e "$script" |
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '"$'\t'"↳ ' --highlight-line --bind 'shift-delete:execute-silent(cat {+f1} >> \"$deletefile\")+exclude-multi' --multi ${FZF_CTRL_R_OPTS-} --read0") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '"$'\t'"↳ ' --highlight-line ${FZF_CTRL_R_OPTS-} +m --read0") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
||||||
)
|
) || return
|
||||||
__fzf_history_delete "$deletefile"
|
|
||||||
command rm -f "$deletefile"
|
|
||||||
[[ -n $output ]] || return
|
|
||||||
READLINE_LINE=$(command perl -pe 's/^\d*\t//' <<< "$output")
|
READLINE_LINE=$(command perl -pe 's/^\d*\t//' <<< "$output")
|
||||||
if [[ -z $READLINE_POINT ]]; then
|
if [[ -z "$READLINE_POINT" ]]; then
|
||||||
echo "$READLINE_LINE"
|
echo "$READLINE_LINE"
|
||||||
else
|
else
|
||||||
READLINE_POINT=0x7fffffff
|
READLINE_POINT=0x7fffffff
|
||||||
@@ -114,9 +74,14 @@ if command -v perl > /dev/null; then
|
|||||||
}
|
}
|
||||||
else # awk - fallback for POSIX systems
|
else # awk - fallback for POSIX systems
|
||||||
__fzf_history__() {
|
__fzf_history__() {
|
||||||
local output script deletefile
|
local output script n x y z d
|
||||||
deletefile=$(mktemp)
|
if [[ -z $__fzf_awk ]]; then
|
||||||
[[ $(HISTTIMEFORMAT='' builtin history 1) =~ [[:digit:]]+ ]] # how many history entries
|
__fzf_awk=awk
|
||||||
|
# choose the faster mawk if: it's installed && build date >= 20230322 && version >= 1.3.4
|
||||||
|
IFS=' .' read n x y z d <<< $(command mawk -W version 2> /dev/null)
|
||||||
|
[[ $n == mawk ]] && (( d >= 20230302 && (x *1000 +y) *1000 +z >= 1003004 )) && __fzf_awk=mawk
|
||||||
|
fi
|
||||||
|
[[ $(HISTTIMEFORMAT='' builtin history 1) =~ [[:digit:]]+ ]] # how many history entries
|
||||||
script='function P(b) { ++n; sub(/^[ *]/, "", b); if (!seen[b]++) { printf "%d\t%s%c", '$((BASH_REMATCH + 1))' - n, b, 0 } }
|
script='function P(b) { ++n; sub(/^[ *]/, "", b); if (!seen[b]++) { printf "%d\t%s%c", '$((BASH_REMATCH + 1))' - n, b, 0 } }
|
||||||
NR==1 { b = substr($0, 2); next }
|
NR==1 { b = substr($0, 2); next }
|
||||||
/^\t/ { P(b); b = substr($0, 2); next }
|
/^\t/ { P(b); b = substr($0, 2); next }
|
||||||
@@ -124,16 +89,13 @@ else # awk - fallback for POSIX systems
|
|||||||
END { if (NR) P(b) }'
|
END { if (NR) P(b) }'
|
||||||
output=$(
|
output=$(
|
||||||
set +o pipefail
|
set +o pipefail
|
||||||
builtin fc -lnr -2147483648 2> /dev/null | # ( $'\t '<lines>$'\n' )* ; <lines> ::= [^\n]* ( $'\n'<lines> )*
|
builtin fc -lnr -2147483648 2> /dev/null | # ( $'\t '<lines>$'\n' )* ; <lines> ::= [^\n]* ( $'\n'<lines> )*
|
||||||
__fzf_exec_awk "$script" | # ( <counter>$'\t'<lines>$'\000' )*
|
command $__fzf_awk "$script" | # ( <counter>$'\t'<lines>$'\000' )*
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '"$'\t'"↳ ' --highlight-line --bind 'shift-delete:execute-silent(cat {+f1} >> \"$deletefile\")+exclude-multi' --multi ${FZF_CTRL_R_OPTS-} --read0") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '"$'\t'"↳ ' --highlight-line ${FZF_CTRL_R_OPTS-} +m --read0") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd) --query "$READLINE_LINE"
|
||||||
)
|
) || return
|
||||||
__fzf_history_delete "$deletefile"
|
|
||||||
command rm -f "$deletefile"
|
|
||||||
[[ -n $output ]] || return
|
|
||||||
READLINE_LINE=${output#*$'\t'}
|
READLINE_LINE=${output#*$'\t'}
|
||||||
if [[ -z $READLINE_POINT ]]; then
|
if [[ -z "$READLINE_POINT" ]]; then
|
||||||
echo "$READLINE_LINE"
|
echo "$READLINE_LINE"
|
||||||
else
|
else
|
||||||
READLINE_POINT=0x7fffffff
|
READLINE_POINT=0x7fffffff
|
||||||
@@ -142,54 +104,43 @@ else # awk - fallback for POSIX systems
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
# Required to refresh the prompt after fzf
|
# Required to refresh the prompt after fzf
|
||||||
bind -m emacs-standard '"\C-\e(": redraw-current-line'
|
bind -m emacs-standard '"\er": redraw-current-line'
|
||||||
|
|
||||||
bind -m vi-command '"\C-z": emacs-editing-mode'
|
bind -m vi-command '"\C-z": emacs-editing-mode'
|
||||||
bind -m vi-insert '"\C-z": emacs-editing-mode'
|
bind -m vi-insert '"\C-z": emacs-editing-mode'
|
||||||
bind -m emacs-standard '"\C-z": vi-editing-mode'
|
bind -m emacs-standard '"\C-z": vi-editing-mode'
|
||||||
|
|
||||||
if ((BASH_VERSINFO[0] < 4)); then
|
if (( BASH_VERSINFO[0] < 4 )); then
|
||||||
# CTRL-T - Paste the selected file path into the command line
|
# CTRL-T - Paste the selected file path into the command line
|
||||||
if [[ ${FZF_CTRL_T_COMMAND-x} != "" ]]; then
|
if [[ "${FZF_CTRL_T_COMMAND-x}" != "" ]]; then
|
||||||
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`__fzf_select__`\e\C-e\C-\e(\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f\C-y\ey\C-_"'
|
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`__fzf_select__`\e\C-e\er\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f"'
|
||||||
bind -m vi-command '"\C-t": "\C-z\C-t\C-z"'
|
bind -m vi-command '"\C-t": "\C-z\C-t\C-z"'
|
||||||
bind -m vi-insert '"\C-t": "\C-z\C-t\C-z"'
|
bind -m vi-insert '"\C-t": "\C-z\C-t\C-z"'
|
||||||
fi
|
fi
|
||||||
|
|
||||||
# CTRL-R - Paste the selected command from history into the command line
|
# CTRL-R - Paste the selected command from history into the command line
|
||||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
bind -m emacs-standard '"\C-r": "\C-e \C-u\C-y\ey\C-u`__fzf_history__`\e\C-e\er"'
|
||||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
bind -m vi-command '"\C-r": "\C-z\C-r\C-z"'
|
||||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
bind -m vi-insert '"\C-r": "\C-z\C-r\C-z"'
|
||||||
fi
|
|
||||||
bind -m emacs-standard '"\C-r": "\C-e \C-u\C-y\ey\C-u`__fzf_history__`\e\C-e\C-\e("'
|
|
||||||
bind -m vi-command '"\C-r": "\C-z\C-r\C-z"'
|
|
||||||
bind -m vi-insert '"\C-r": "\C-z\C-r\C-z"'
|
|
||||||
fi
|
|
||||||
else
|
else
|
||||||
# CTRL-T - Paste the selected file path into the command line
|
# CTRL-T - Paste the selected file path into the command line
|
||||||
if [[ ${FZF_CTRL_T_COMMAND-x} != "" ]]; then
|
if [[ "${FZF_CTRL_T_COMMAND-x}" != "" ]]; then
|
||||||
bind -m emacs-standard -x '"\C-t": fzf-file-widget'
|
bind -m emacs-standard -x '"\C-t": fzf-file-widget'
|
||||||
bind -m vi-command -x '"\C-t": fzf-file-widget'
|
bind -m vi-command -x '"\C-t": fzf-file-widget'
|
||||||
bind -m vi-insert -x '"\C-t": fzf-file-widget'
|
bind -m vi-insert -x '"\C-t": fzf-file-widget'
|
||||||
fi
|
fi
|
||||||
|
|
||||||
# CTRL-R - Paste the selected command from history into the command line
|
# CTRL-R - Paste the selected command from history into the command line
|
||||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
bind -m emacs-standard -x '"\C-r": __fzf_history__'
|
||||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
bind -m vi-command -x '"\C-r": __fzf_history__'
|
||||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
bind -m vi-insert -x '"\C-r": __fzf_history__'
|
||||||
fi
|
|
||||||
bind -m emacs-standard -x '"\C-r": __fzf_history__'
|
|
||||||
bind -m vi-command -x '"\C-r": __fzf_history__'
|
|
||||||
bind -m vi-insert -x '"\C-r": __fzf_history__'
|
|
||||||
fi
|
|
||||||
fi
|
fi
|
||||||
|
|
||||||
# ALT-C - cd into the selected directory
|
# ALT-C - cd into the selected directory
|
||||||
if [[ ${FZF_ALT_C_COMMAND-x} != "" ]]; then
|
if [[ "${FZF_ALT_C_COMMAND-x}" != "" ]]; then
|
||||||
bind -m emacs-standard '"\ec": " \C-b\C-k \C-u`__fzf_cd__`\e\C-e\C-\e(\C-m\C-y\C-h\e \C-y\ey\C-x\C-x\C-d\C-y\ey\C-_"'
|
bind -m emacs-standard '"\ec": " \C-b\C-k \C-u`__fzf_cd__`\e\C-e\er\C-m\C-y\C-h\e \C-y\ey\C-x\C-x\C-d"'
|
||||||
bind -m vi-command '"\ec": "\C-z\ec\C-z"'
|
bind -m vi-command '"\ec": "\C-z\ec\C-z"'
|
||||||
bind -m vi-insert '"\ec": "\C-z\ec\C-z"'
|
bind -m vi-insert '"\ec": "\C-z\ec\C-z"'
|
||||||
fi
|
fi
|
||||||
#----END shfmt
|
|
||||||
|
|
||||||
fi
|
fi
|
||||||
|
|||||||
+135
-157
@@ -4,101 +4,27 @@
|
|||||||
# / __/ / /_/ __/
|
# / __/ / /_/ __/
|
||||||
# /_/ /___/_/ key-bindings.fish
|
# /_/ /___/_/ key-bindings.fish
|
||||||
#
|
#
|
||||||
|
# - $FZF_TMUX_OPTS
|
||||||
# - $FZF_CTRL_T_COMMAND
|
# - $FZF_CTRL_T_COMMAND
|
||||||
# - $FZF_CTRL_T_OPTS
|
# - $FZF_CTRL_T_OPTS
|
||||||
# - $FZF_CTRL_R_COMMAND
|
|
||||||
# - $FZF_CTRL_R_OPTS
|
# - $FZF_CTRL_R_OPTS
|
||||||
# - $FZF_ALT_C_COMMAND
|
# - $FZF_ALT_C_COMMAND
|
||||||
# - $FZF_ALT_C_OPTS
|
# - $FZF_ALT_C_OPTS
|
||||||
|
|
||||||
|
status is-interactive; or exit 0
|
||||||
|
|
||||||
|
|
||||||
# Key bindings
|
# Key bindings
|
||||||
# ------------
|
# ------------
|
||||||
function fzf_key_bindings
|
function fzf_key_bindings
|
||||||
|
|
||||||
# The oldest supported fish version is 3.4.0. For this message being able to be
|
|
||||||
# displayed on older versions, the command substitution syntax $() should not
|
|
||||||
# be used anywhere in the script, otherwise the source command will fail.
|
|
||||||
if string match -qr -- '^[12]\\.|^3\\.[0-3]' $version
|
|
||||||
echo "fzf key bindings script requires fish version 3.4.0 or newer." >&2
|
|
||||||
return 1
|
|
||||||
else if not command -q fzf
|
|
||||||
echo "fzf was not found in path." >&2
|
|
||||||
return 1
|
|
||||||
end
|
|
||||||
|
|
||||||
function __fzf_defaults
|
function __fzf_defaults
|
||||||
# $argv[1]: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
# $argv[2..]: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
test -n "$FZF_TMUX_HEIGHT"; or set -l FZF_TMUX_HEIGHT 40%
|
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||||
string join ' ' -- \
|
echo "--height $FZF_TMUX_HEIGHT --bind=ctrl-z:ignore" $argv[1]
|
||||||
"--height $FZF_TMUX_HEIGHT --min-height=20+ --bind=ctrl-z:ignore" $argv[1] \
|
command cat "$FZF_DEFAULT_OPTS_FILE" 2> /dev/null
|
||||||
(test -r "$FZF_DEFAULT_OPTS_FILE"; and string join -- ' ' <$FZF_DEFAULT_OPTS_FILE) \
|
echo $FZF_DEFAULT_OPTS $argv[2]
|
||||||
$FZF_DEFAULT_OPTS $argv[2..]
|
|
||||||
end
|
|
||||||
|
|
||||||
function __fzfcmd
|
|
||||||
test -n "$FZF_TMUX_HEIGHT"; or set -l FZF_TMUX_HEIGHT 40%
|
|
||||||
if test -n "$FZF_TMUX_OPTS"
|
|
||||||
echo "fzf-tmux $FZF_TMUX_OPTS -- "
|
|
||||||
else if test "$FZF_TMUX" = "1"
|
|
||||||
echo "fzf-tmux -d$FZF_TMUX_HEIGHT -- "
|
|
||||||
else
|
|
||||||
echo "fzf"
|
|
||||||
end
|
|
||||||
end
|
|
||||||
|
|
||||||
function __fzf_parse_commandline -d 'Parse the current command line token and return split of existing filepath, fzf query, and optional -option= prefix'
|
|
||||||
set -l fzf_query ''
|
|
||||||
set -l prefix ''
|
|
||||||
set -l dir '.'
|
|
||||||
|
|
||||||
set -l -- match_regex '(?<fzf_query>[\\s\\S]*?(?=\\n?$)$)'
|
|
||||||
set -l -- prefix_regex '^-[^\\s=]+=|^-(?!-)\\S'
|
|
||||||
|
|
||||||
# Don't use option prefix if " -- " is preceded.
|
|
||||||
string match -qv -- '* -- *' (string sub -l (commandline -Cp) -- (commandline -p))
|
|
||||||
and set -- match_regex "(?<prefix>$prefix_regex)?$match_regex"
|
|
||||||
|
|
||||||
# Set $prefix and expanded $fzf_query with preserved trailing newlines.
|
|
||||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
|
||||||
# fish v4.0.0 and newer
|
|
||||||
string match -q -r -- $match_regex (commandline --current-token --tokens-expanded | string collect -N)
|
|
||||||
else
|
|
||||||
string match -q -r -- $match_regex (commandline --current-token --tokenize | string collect -N)
|
|
||||||
eval set -- fzf_query (string escape -n -- $fzf_query | string replace -r -a '^\\\\(?=~)|\\\\(?=\\$\\w)' '')
|
|
||||||
end
|
|
||||||
|
|
||||||
if test -n "$fzf_query"
|
|
||||||
# Normalize path in $fzf_query, set $dir to the longest existing directory.
|
|
||||||
if string match -qr -- '^\\d\\d+|^4|^3\\.[5-9]' $version
|
|
||||||
# fish v3.5.0 and newer
|
|
||||||
set -- fzf_query (path normalize -- $fzf_query)
|
|
||||||
set -- dir $fzf_query
|
|
||||||
while not path is -d $dir
|
|
||||||
set -- dir (path dirname $dir)
|
|
||||||
end
|
|
||||||
else
|
|
||||||
string match -q -r -- '(?<fzf_query>^[\\s\\S]*?(?=\\n?$)$)' \
|
|
||||||
(string replace -r -a -- '(?<=/)/|(?<!^)/+(?!\\n)$' '' $fzf_query | string collect -N)
|
|
||||||
set -- dir $fzf_query
|
|
||||||
while not test -d "$dir"
|
|
||||||
set -- dir (dirname -z -- "$dir" | string split0)
|
|
||||||
end
|
|
||||||
end
|
|
||||||
|
|
||||||
if not string match -q -- '.' $dir; or string match -qr -- '^\\.(/|$)' $fzf_query
|
|
||||||
# Strip $dir from $fzf_query - preserve trailing newlines.
|
|
||||||
if string match -qr -- '^\\d\\d+|^[4-9]' $version
|
|
||||||
# fish v4.0.0 and newer
|
|
||||||
string match -q -r -- '^'(string escape --style=regex -- $dir)'/?(?<fzf_query>[\\s\\S]*)' $fzf_query
|
|
||||||
else
|
|
||||||
string match -q -r -- '^/?(?<fzf_query>[\\s\\S]*?(?=\\n?$)$)' \
|
|
||||||
(string replace -- "$dir" '' $fzf_query | string collect -N)
|
|
||||||
end
|
|
||||||
end
|
|
||||||
end
|
|
||||||
|
|
||||||
string escape -n -- "$dir" "$fzf_query" "$prefix"
|
|
||||||
end
|
end
|
||||||
|
|
||||||
# Store current token in $dir as root for the 'find' command
|
# Store current token in $dir as root for the 'find' command
|
||||||
@@ -108,69 +34,59 @@ function fzf_key_bindings
|
|||||||
set -l fzf_query $commandline[2]
|
set -l fzf_query $commandline[2]
|
||||||
set -l prefix $commandline[3]
|
set -l prefix $commandline[3]
|
||||||
|
|
||||||
set -lx FZF_DEFAULT_OPTS (__fzf_defaults \
|
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||||
"--reverse --walker=file,dir,follow,hidden --scheme=path" \
|
begin
|
||||||
"--multi $FZF_CTRL_T_OPTS --print0")
|
set -lx FZF_DEFAULT_OPTS (__fzf_defaults "--reverse --walker=file,dir,follow,hidden --scheme=path --walker-root='$dir'" "$FZF_CTRL_T_OPTS")
|
||||||
|
set -lx FZF_DEFAULT_COMMAND "$FZF_CTRL_T_COMMAND"
|
||||||
set -lx FZF_DEFAULT_COMMAND "$FZF_CTRL_T_COMMAND"
|
set -lx FZF_DEFAULT_OPTS_FILE ''
|
||||||
set -lx FZF_DEFAULT_OPTS_FILE
|
eval (__fzfcmd)' -m --query "'$fzf_query'"' | while read -l r; set result $result $r; end
|
||||||
|
end
|
||||||
set -l result (eval (__fzfcmd) --walker-root=$dir --query=$fzf_query | string split0)
|
if [ -z "$result" ]
|
||||||
and commandline -rt -- (string join -- ' ' $prefix(string escape -n -- $result))' '
|
commandline -f repaint
|
||||||
|
return
|
||||||
|
else
|
||||||
|
# Remove last token from commandline.
|
||||||
|
commandline -t ""
|
||||||
|
end
|
||||||
|
for i in $result
|
||||||
|
commandline -it -- $prefix
|
||||||
|
commandline -it -- (string escape $i)
|
||||||
|
commandline -it -- ' '
|
||||||
|
end
|
||||||
commandline -f repaint
|
commandline -f repaint
|
||||||
end
|
end
|
||||||
|
|
||||||
function fzf-history-widget -d "Show command history"
|
function fzf-history-widget -d "Show command history"
|
||||||
set -l -- command_line (commandline)
|
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||||
set -l -- current_line (commandline -L)
|
begin
|
||||||
set -l -- total_lines (count $command_line)
|
set -l FISH_MAJOR (echo $version | cut -f1 -d.)
|
||||||
set -l -- fzf_query (string escape -- $command_line[$current_line])
|
set -l FISH_MINOR (echo $version | cut -f2 -d.)
|
||||||
|
|
||||||
set -lx -- FZF_DEFAULT_OPTS (__fzf_defaults '' \
|
# merge history from other sessions before searching
|
||||||
'--with-nth=2.. --nth=2..,.. --scheme=history --multi --no-multi-line' \
|
if test -z "$fish_private_mode"
|
||||||
'--no-wrap --wrap-sign="\t\t\t↳ " --preview-wrap-sign="↳ " --freeze-left=1' \
|
builtin history merge
|
||||||
'--bind="alt-enter:become(set -g fzf_temp {+sf3..}; string join0 -- (string split0 -- <$fzf_temp | fish_indent -i); unlink $fzf_temp &>/dev/null)"' \
|
end
|
||||||
'--bind="alt-t:change-with-nth(1,3..|3..|2..)"' \
|
|
||||||
'--bind="shift-delete:execute-silent(eval builtin history delete -Ce -- (string escape -n -- (string split0 -- <{+sf3..})))+reload(eval $FZF_DEFAULT_COMMAND)"' \
|
|
||||||
"--bind=ctrl-r:toggle-sort,alt-r:toggle-raw --highlight-line $FZF_CTRL_R_OPTS" \
|
|
||||||
'--accept-nth=3.. --delimiter="\t" --tabstop=4 --read0 --print0 --with-shell='(status fish-path)\\ -c)
|
|
||||||
|
|
||||||
# Add dynamic preview options if preview command isn't already set by user
|
# history's -z flag is needed for multi-line support.
|
||||||
if string match -qvr -- '--preview[= ]' "$FZF_DEFAULT_OPTS"
|
# history's -z flag was added in fish 2.4.0, so don't use it for versions
|
||||||
# Prepend the options to allow user overrides
|
# before 2.4.0.
|
||||||
set -p -- FZF_DEFAULT_OPTS \
|
if [ "$FISH_MAJOR" -gt 2 -o \( "$FISH_MAJOR" -eq 2 -a "$FISH_MINOR" -ge 4 \) ];
|
||||||
'--bind="focus,multi,resize:bg-transform:if test \\"$FZF_COLUMNS\\" -gt 100 -a \\\\( \\"$FZF_SELECT_COUNT\\" -gt 0 -o \\\\( -z \\"$FZF_WRAP\\" -a (string join0 -- <{f3..} | string length) -gt (math $FZF_COLUMNS - (switch $FZF_WITH_NTH; case 2..; echo 13; case 1,3..; echo 25; case 3..; echo 1; end)) \\\\) -o (string split0 -- <{sf3..} | fish_indent | count) -gt 1 \\\\); echo show-preview; else; echo hide-preview; end"' \
|
if type -P perl > /dev/null 2>&1
|
||||||
'--preview="test \\"$FZF_SELECT_COUNT\\" -gt 0; and string split0 -- <{+sf3..} | fish_indent (string match -q -- 3.\\\\* $version; or echo -- --only-indent) --ansi; and echo -n \\\\n; string collect -- \\\\#\\\\ {1} (string split0 -- <{sf3..}) | fish_indent --ansi"' \
|
set -lx FZF_DEFAULT_OPTS (__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '"\t"↳ ' --highlight-line $FZF_CTRL_R_OPTS +m")
|
||||||
'--preview-window="right,50%,wrap-word,follow,info,hidden"'
|
set -lx FZF_DEFAULT_OPTS_FILE ''
|
||||||
end
|
builtin history -z --reverse | command perl -0 -pe 's/^/$.\t/g; s/\n/\n\t/gm' | eval (__fzfcmd) --tac --read0 --print0 -q '(commandline)' | command perl -pe 's/^\d*\t//' | read -lz result
|
||||||
|
and commandline -- $result
|
||||||
set -lx FZF_DEFAULT_OPTS_FILE
|
else
|
||||||
|
set -lx FZF_DEFAULT_OPTS (__fzf_defaults "" "--scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '"\t"↳ ' --highlight-line $FZF_CTRL_R_OPTS +m")
|
||||||
set -lx -- FZF_DEFAULT_COMMAND 'builtin history -z'
|
set -lx FZF_DEFAULT_OPTS_FILE ''
|
||||||
|
builtin history -z | eval (__fzfcmd) --read0 --print0 -q '(commandline)' | read -lz result
|
||||||
# Enable syntax highlighting colors on fish v4.3.3 and newer
|
and commandline -- $result
|
||||||
if string match -qr -- '^\\d\\d+|^4\\.[4-9]|^4\\.3\\.[3-9]' $version
|
end
|
||||||
set -a -- FZF_DEFAULT_OPTS '--ansi'
|
|
||||||
set -a -- FZF_DEFAULT_COMMAND '--color=always --show-time=(set_color $fish_color_comment 2>/dev/null; or set_color normal)"%F %a %T%t%s%t"(set_color normal)'
|
|
||||||
else
|
|
||||||
set -a -- FZF_DEFAULT_COMMAND '--show-time="%F %a %T%t%s%t"'
|
|
||||||
end
|
|
||||||
|
|
||||||
# Merge history from other sessions before searching
|
|
||||||
test -z "$fish_private_mode"; and builtin history merge
|
|
||||||
|
|
||||||
if set -l result (eval $FZF_DEFAULT_COMMAND \| (__fzfcmd) --query=$fzf_query | string split0)
|
|
||||||
if test "$total_lines" -eq 1
|
|
||||||
commandline -- $result
|
|
||||||
else
|
else
|
||||||
set -l a (math $current_line - 1)
|
builtin history | eval (__fzfcmd) -q '(commandline)' | read -l result
|
||||||
set -l b (math $current_line + 1)
|
and commandline -- $result
|
||||||
commandline -- $command_line[1..$a] $result
|
|
||||||
commandline -a -- '' $command_line[$b..-1]
|
|
||||||
end
|
end
|
||||||
end
|
end
|
||||||
|
|
||||||
commandline -f repaint
|
commandline -f repaint
|
||||||
end
|
end
|
||||||
|
|
||||||
@@ -180,40 +96,102 @@ function fzf_key_bindings
|
|||||||
set -l fzf_query $commandline[2]
|
set -l fzf_query $commandline[2]
|
||||||
set -l prefix $commandline[3]
|
set -l prefix $commandline[3]
|
||||||
|
|
||||||
set -lx FZF_DEFAULT_OPTS (__fzf_defaults \
|
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||||
"--reverse --walker=dir,follow,hidden --scheme=path" \
|
begin
|
||||||
"$FZF_ALT_C_OPTS --no-multi --print0")
|
set -lx FZF_DEFAULT_OPTS (__fzf_defaults "--reverse --walker=dir,follow,hidden --scheme=path --walker-root='$dir'" "$FZF_ALT_C_OPTS")
|
||||||
|
set -lx FZF_DEFAULT_OPTS_FILE ''
|
||||||
|
set -lx FZF_DEFAULT_COMMAND "$FZF_ALT_C_COMMAND"
|
||||||
|
eval (__fzfcmd)' +m --query "'$fzf_query'"' | read -l result
|
||||||
|
|
||||||
set -lx FZF_DEFAULT_OPTS_FILE
|
if [ -n "$result" ]
|
||||||
set -lx FZF_DEFAULT_COMMAND "$FZF_ALT_C_COMMAND"
|
cd -- $result
|
||||||
|
|
||||||
if set -l result (eval (__fzfcmd) --query=$fzf_query --walker-root=$dir | string split0)
|
# Remove last token from commandline.
|
||||||
cd -- $result
|
commandline -t ""
|
||||||
commandline -rt -- $prefix
|
commandline -it -- $prefix
|
||||||
|
end
|
||||||
end
|
end
|
||||||
|
|
||||||
commandline -f repaint
|
commandline -f repaint
|
||||||
end
|
end
|
||||||
|
|
||||||
if not set -q FZF_CTRL_R_COMMAND; or test -n "$FZF_CTRL_R_COMMAND"
|
function __fzfcmd
|
||||||
if test -n "$FZF_CTRL_R_COMMAND"
|
test -n "$FZF_TMUX"; or set FZF_TMUX 0
|
||||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||||
|
if [ -n "$FZF_TMUX_OPTS" ]
|
||||||
|
echo "fzf-tmux $FZF_TMUX_OPTS -- "
|
||||||
|
else if [ $FZF_TMUX -eq 1 ]
|
||||||
|
echo "fzf-tmux -d$FZF_TMUX_HEIGHT -- "
|
||||||
|
else
|
||||||
|
echo "fzf"
|
||||||
end
|
end
|
||||||
bind \cr fzf-history-widget
|
|
||||||
bind -M insert \cr fzf-history-widget
|
|
||||||
end
|
end
|
||||||
|
|
||||||
|
bind \cr fzf-history-widget
|
||||||
if not set -q FZF_CTRL_T_COMMAND; or test -n "$FZF_CTRL_T_COMMAND"
|
if not set -q FZF_CTRL_T_COMMAND; or test -n "$FZF_CTRL_T_COMMAND"
|
||||||
bind \ct fzf-file-widget
|
bind \ct fzf-file-widget
|
||||||
bind -M insert \ct fzf-file-widget
|
|
||||||
end
|
end
|
||||||
|
|
||||||
if not set -q FZF_ALT_C_COMMAND; or test -n "$FZF_ALT_C_COMMAND"
|
if not set -q FZF_ALT_C_COMMAND; or test -n "$FZF_ALT_C_COMMAND"
|
||||||
bind \ec fzf-cd-widget
|
bind \ec fzf-cd-widget
|
||||||
bind -M insert \ec fzf-cd-widget
|
end
|
||||||
|
|
||||||
|
if bind -M insert > /dev/null 2>&1
|
||||||
|
bind -M insert \cr fzf-history-widget
|
||||||
|
if not set -q FZF_CTRL_T_COMMAND; or test -n "$FZF_CTRL_T_COMMAND"
|
||||||
|
bind -M insert \ct fzf-file-widget
|
||||||
|
end
|
||||||
|
if not set -q FZF_ALT_C_COMMAND; or test -n "$FZF_ALT_C_COMMAND"
|
||||||
|
bind -M insert \ec fzf-cd-widget
|
||||||
|
end
|
||||||
|
end
|
||||||
|
|
||||||
|
function __fzf_parse_commandline -d 'Parse the current command line token and return split of existing filepath, fzf query, and optional -option= prefix'
|
||||||
|
set -l commandline (commandline -t)
|
||||||
|
|
||||||
|
# strip -option= from token if present
|
||||||
|
set -l prefix (string match -r -- '^-[^\s=]+=' $commandline)
|
||||||
|
set commandline (string replace -- "$prefix" '' $commandline)
|
||||||
|
|
||||||
|
# eval is used to do shell expansion on paths
|
||||||
|
eval set commandline $commandline
|
||||||
|
|
||||||
|
if [ -z $commandline ]
|
||||||
|
# Default to current directory with no --query
|
||||||
|
set dir '.'
|
||||||
|
set fzf_query ''
|
||||||
|
else
|
||||||
|
set dir (__fzf_get_dir $commandline)
|
||||||
|
|
||||||
|
if [ "$dir" = "." -a (string sub -l 1 -- $commandline) != '.' ]
|
||||||
|
# if $dir is "." but commandline is not a relative path, this means no file path found
|
||||||
|
set fzf_query $commandline
|
||||||
|
else
|
||||||
|
# Also remove trailing slash after dir, to "split" input properly
|
||||||
|
set fzf_query (string replace -r "^$dir/?" -- '' "$commandline")
|
||||||
|
end
|
||||||
|
end
|
||||||
|
|
||||||
|
echo $dir
|
||||||
|
echo $fzf_query
|
||||||
|
echo $prefix
|
||||||
|
end
|
||||||
|
|
||||||
|
function __fzf_get_dir -d 'Find the longest existing filepath from input string'
|
||||||
|
set dir $argv
|
||||||
|
|
||||||
|
# Strip all trailing slashes. Ignore if $dir is root dir (/)
|
||||||
|
if [ (string length -- $dir) -gt 1 ]
|
||||||
|
set dir (string replace -r '/*$' -- '' $dir)
|
||||||
|
end
|
||||||
|
|
||||||
|
# Iteratively check if dir exists and strip tail end of path
|
||||||
|
while [ ! -d "$dir" ]
|
||||||
|
# If path is absolute, this can keep going until ends up at /
|
||||||
|
# If path is relative, this can keep going until entire input is consumed, dirname returns "."
|
||||||
|
set dir (dirname -- "$dir")
|
||||||
|
end
|
||||||
|
|
||||||
|
echo $dir
|
||||||
end
|
end
|
||||||
|
|
||||||
end
|
end
|
||||||
|
|
||||||
# Run setup
|
|
||||||
fzf_key_bindings
|
|
||||||
|
|||||||
@@ -1,166 +0,0 @@
|
|||||||
# ____ ____
|
|
||||||
# / __/___ / __/
|
|
||||||
# / /_/_ / / /_
|
|
||||||
# / __/ / /_/ __/
|
|
||||||
# /_/ /___/_/ key-bindings.nu
|
|
||||||
#
|
|
||||||
# - $FZF_TMUX (default: 0)
|
|
||||||
# - $FZF_TMUX_OPTS
|
|
||||||
# - $FZF_TMUX_HEIGHT (default: 40%)
|
|
||||||
# - $FZF_CTRL_T_COMMAND (set to "" to disable)
|
|
||||||
# - $FZF_CTRL_T_OPTS
|
|
||||||
# - $FZF_CTRL_R_COMMAND (set to "" to disable)
|
|
||||||
# - $FZF_CTRL_R_OPTS
|
|
||||||
# - $FZF_ALT_C_COMMAND (set to "" to disable)
|
|
||||||
# - $FZF_ALT_C_OPTS
|
|
||||||
|
|
||||||
# Code provided by @igor-ramazanov
|
|
||||||
# Source: https://github.com/junegunn/fzf/issues/4122#issuecomment-2607368316
|
|
||||||
|
|
||||||
# Merge default options in the same order as bash/zsh:
|
|
||||||
# 1. --height, --min-height, --bind=ctrl-z:ignore, $prepend
|
|
||||||
# 2. $FZF_DEFAULT_OPTS_FILE contents
|
|
||||||
# 3. $FZF_DEFAULT_OPTS, $append
|
|
||||||
def __fzf_defaults [prepend: string, append: string]: nothing -> string {
|
|
||||||
let base = $"--height ($env.FZF_TMUX_HEIGHT? | default '40%') --min-height 20+ --bind=ctrl-z:ignore ($prepend)"
|
|
||||||
let opts_file = if ($env.FZF_DEFAULT_OPTS_FILE? | default '' | is-not-empty) {
|
|
||||||
try { open --raw ($env.FZF_DEFAULT_OPTS_FILE) | str trim } catch { '' }
|
|
||||||
} else {
|
|
||||||
''
|
|
||||||
}
|
|
||||||
let default_opts = $env.FZF_DEFAULT_OPTS? | default ''
|
|
||||||
$"($base) ($opts_file) ($default_opts) ($append)" | str trim
|
|
||||||
}
|
|
||||||
|
|
||||||
# Return the fzf command to use: fzf-tmux when inside tmux and
|
|
||||||
# FZF_TMUX is enabled or FZF_TMUX_OPTS is set, plain fzf otherwise.
|
|
||||||
def __fzfcmd []: nothing -> list<string> {
|
|
||||||
let in_tmux = ($env.TMUX_PANE? | default '' | into string | is-not-empty)
|
|
||||||
if $in_tmux {
|
|
||||||
let fzf_tmux = ($env.FZF_TMUX? | default 0 | into string)
|
|
||||||
let fzf_tmux_opts = ($env.FZF_TMUX_OPTS? | default '' | into string)
|
|
||||||
if ($fzf_tmux != '0') or ($fzf_tmux_opts | is-not-empty) {
|
|
||||||
let opts = if ($fzf_tmux_opts | is-not-empty) { $fzf_tmux_opts } else { $"-d($env.FZF_TMUX_HEIGHT? | default '40%')" }
|
|
||||||
return ['fzf-tmux' ...(($opts | split row ' ' | where { $in != '' })) '--']
|
|
||||||
}
|
|
||||||
}
|
|
||||||
['fzf']
|
|
||||||
}
|
|
||||||
|
|
||||||
|
|
||||||
export-env {
|
|
||||||
$env.FZF_CTRL_T_OPTS = $env.FZF_CTRL_T_OPTS? | default ""
|
|
||||||
$env.FZF_CTRL_R_OPTS = $env.FZF_CTRL_R_OPTS? | default ""
|
|
||||||
$env.FZF_ALT_C_OPTS = $env.FZF_ALT_C_OPTS? | default ""
|
|
||||||
}
|
|
||||||
|
|
||||||
# Directories
|
|
||||||
const alt_c = {
|
|
||||||
name: fzf_dirs
|
|
||||||
modifier: alt
|
|
||||||
keycode: char_c
|
|
||||||
mode: [emacs, vi_normal, vi_insert]
|
|
||||||
event: [
|
|
||||||
{
|
|
||||||
send: executehostcommand
|
|
||||||
cmd: "
|
|
||||||
let fzf_opts = (__fzf_defaults '--reverse --walker=dir,follow,hidden --scheme=path' $'($env.FZF_ALT_C_OPTS) +m');
|
|
||||||
let fzfcmd = (__fzfcmd);
|
|
||||||
let fzf_args = ($fzfcmd | skip 1);
|
|
||||||
let alt_c_cmd = ($env.FZF_ALT_C_COMMAND? | default null);
|
|
||||||
let result = if ($alt_c_cmd == null) or ($alt_c_cmd | is-empty) {
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args }
|
|
||||||
} else {
|
|
||||||
let fzf_cmd_str = ($fzfcmd | str join ' ');
|
|
||||||
let sh_cmd = [$alt_c_cmd '|' $fzf_cmd_str] | str join ' ';
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^sh -c $sh_cmd }
|
|
||||||
};
|
|
||||||
if ($result | is-not-empty) { cd $result };
|
|
||||||
"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
# History
|
|
||||||
const ctrl_r = {
|
|
||||||
name: fzf_history
|
|
||||||
modifier: control
|
|
||||||
keycode: char_r
|
|
||||||
mode: [emacs, vi_insert, vi_normal]
|
|
||||||
event: [
|
|
||||||
{
|
|
||||||
send: executehostcommand
|
|
||||||
cmd: "commandline edit --replace (
|
|
||||||
let fzf_opts = (__fzf_defaults '' $'--scheme=history --bind=ctrl-r:toggle-sort --wrap-sign \"\t↳ \" --highlight-line ($env.FZF_CTRL_R_OPTS) +m --read0');
|
|
||||||
let fzfcmd = (__fzfcmd);
|
|
||||||
let fzf_args = ($fzfcmd | skip 1);
|
|
||||||
# reverse | uniq: show most recent first, deduplicate keeping the latest.
|
|
||||||
# Nushell's `history` loads the full history as an in-memory table
|
|
||||||
# (bounded by $env.config.history.max_size, default 100,000), so
|
|
||||||
# reverse and uniq run on an already-materialized list. This is O(n)
|
|
||||||
# but acceptable for typical history sizes; unlike bash/zsh `fc -r`,
|
|
||||||
# there is no streaming primitive that would let fzf show the latest
|
|
||||||
# entries before the full list is consumed.
|
|
||||||
history
|
|
||||||
| get command
|
|
||||||
| reverse
|
|
||||||
| uniq
|
|
||||||
| str join (char -i 0)
|
|
||||||
| with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args --query (commandline) }
|
|
||||||
| decode utf-8
|
|
||||||
| str trim
|
|
||||||
)"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
# Files
|
|
||||||
const ctrl_t = {
|
|
||||||
name: fzf_files
|
|
||||||
modifier: control
|
|
||||||
keycode: char_t
|
|
||||||
mode: [emacs, vi_normal, vi_insert]
|
|
||||||
event: [
|
|
||||||
{
|
|
||||||
send: executehostcommand
|
|
||||||
cmd: "
|
|
||||||
let fzf_opts = (__fzf_defaults '--reverse --walker=file,dir,follow,hidden --scheme=path' $'($env.FZF_CTRL_T_OPTS) -m');
|
|
||||||
let fzfcmd = (__fzfcmd);
|
|
||||||
let fzf_args = ($fzfcmd | skip 1);
|
|
||||||
let ctrl_t_cmd = ($env.FZF_CTRL_T_COMMAND? | default null);
|
|
||||||
let result = if ($ctrl_t_cmd == null) or ($ctrl_t_cmd | is-empty) {
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^($fzfcmd | first) ...$fzf_args }
|
|
||||||
} else {
|
|
||||||
let fzf_cmd_str = ($fzfcmd | str join ' ');
|
|
||||||
let sh_cmd = [$ctrl_t_cmd '|' $fzf_cmd_str] | str join ' ';
|
|
||||||
with-env { FZF_DEFAULT_OPTS: $fzf_opts, FZF_DEFAULT_OPTS_FILE: '' } { ^sh -c $sh_cmd }
|
|
||||||
};
|
|
||||||
let result = ($result | str replace --all (char newline) ' ' | str trim);
|
|
||||||
commandline edit --append $result;
|
|
||||||
commandline set-cursor --end
|
|
||||||
"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
# Helper to check if a binding is enabled. A binding is disabled when
|
|
||||||
# the corresponding *_COMMAND variable is explicitly set to "".
|
|
||||||
# When not defined (null), the binding is enabled (using fzf's built-in walker).
|
|
||||||
def __fzf_binding_enabled [var_name: string]: nothing -> bool {
|
|
||||||
let val = ($env | get -o $var_name)
|
|
||||||
# null = not defined = enabled; "" = explicitly disabled
|
|
||||||
$val == null or ($val | into string | is-not-empty)
|
|
||||||
}
|
|
||||||
|
|
||||||
# Update the $env.config
|
|
||||||
export-env {
|
|
||||||
let fzf_names = ['fzf_files', 'fzf_dirs', 'fzf_history']
|
|
||||||
# Filter out any existing fzf bindings, then re-add the enabled ones.
|
|
||||||
# This allows re-sourcing to update bindings (e.g. after changing
|
|
||||||
# FZF_CTRL_T_COMMAND) without creating duplicates.
|
|
||||||
mut bindings = ($env.config.keybindings | where { |kb| $kb.name not-in $fzf_names })
|
|
||||||
if (__fzf_binding_enabled 'FZF_ALT_C_COMMAND') { $bindings = ($bindings | append $alt_c) }
|
|
||||||
if (__fzf_binding_enabled 'FZF_CTRL_R_COMMAND') { $bindings = ($bindings | append $ctrl_r) }
|
|
||||||
if (__fzf_binding_enabled 'FZF_CTRL_T_COMMAND') { $bindings = ($bindings | append $ctrl_t) }
|
|
||||||
$env.config.keybindings = $bindings
|
|
||||||
}
|
|
||||||
+20
-80
@@ -4,9 +4,9 @@
|
|||||||
# / __/ / /_/ __/
|
# / __/ / /_/ __/
|
||||||
# /_/ /___/_/ key-bindings.zsh
|
# /_/ /___/_/ key-bindings.zsh
|
||||||
#
|
#
|
||||||
|
# - $FZF_TMUX_OPTS
|
||||||
# - $FZF_CTRL_T_COMMAND
|
# - $FZF_CTRL_T_COMMAND
|
||||||
# - $FZF_CTRL_T_OPTS
|
# - $FZF_CTRL_T_OPTS
|
||||||
# - $FZF_CTRL_R_COMMAND
|
|
||||||
# - $FZF_CTRL_R_OPTS
|
# - $FZF_CTRL_R_OPTS
|
||||||
# - $FZF_ALT_C_COMMAND
|
# - $FZF_ALT_C_COMMAND
|
||||||
# - $FZF_ALT_C_OPTS
|
# - $FZF_ALT_C_OPTS
|
||||||
@@ -38,35 +38,14 @@ fi
|
|||||||
{
|
{
|
||||||
if [[ -o interactive ]]; then
|
if [[ -o interactive ]]; then
|
||||||
|
|
||||||
#----BEGIN INCLUDE common.sh
|
|
||||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
|
||||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
|
||||||
# the changes. See code comments in "common.sh" for the implementation details.
|
|
||||||
|
|
||||||
__fzf_defaults() {
|
__fzf_defaults() {
|
||||||
builtin printf '%s\n' "--height ${FZF_TMUX_HEIGHT:-40%} --min-height 20+ --bind=ctrl-z:ignore $1"
|
# $1: Prepend to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
# $2: Append to FZF_DEFAULT_OPTS_FILE and FZF_DEFAULT_OPTS
|
||||||
|
echo "--height ${FZF_TMUX_HEIGHT:-40%} --bind=ctrl-z:ignore $1"
|
||||||
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
command cat "${FZF_DEFAULT_OPTS_FILE-}" 2> /dev/null
|
||||||
builtin printf '%s\n' "${FZF_DEFAULT_OPTS-} $2"
|
echo "${FZF_DEFAULT_OPTS-} $2"
|
||||||
}
|
}
|
||||||
|
|
||||||
__fzf_exec_awk() {
|
|
||||||
if [[ -z ${__fzf_awk-} ]]; then
|
|
||||||
__fzf_awk=awk
|
|
||||||
if [[ $OSTYPE == solaris* && -x /usr/xpg4/bin/awk ]]; then
|
|
||||||
__fzf_awk=/usr/xpg4/bin/awk
|
|
||||||
elif command -v mawk > /dev/null 2>&1; then
|
|
||||||
local n x y z d
|
|
||||||
IFS=' .' read -r n x y z d <<< $(command mawk -W version 2> /dev/null)
|
|
||||||
[[ $n == mawk ]] &&
|
|
||||||
(((x * 1000 + y) * 1000 + z >= 1003004)) 2> /dev/null &&
|
|
||||||
((d >= 20230302)) 2> /dev/null &&
|
|
||||||
__fzf_awk=mawk
|
|
||||||
fi
|
|
||||||
fi
|
|
||||||
LC_ALL=C exec "$__fzf_awk" "$@"
|
|
||||||
}
|
|
||||||
#----END INCLUDE
|
|
||||||
|
|
||||||
# CTRL-T - Paste the selected file path(s) into the command line
|
# CTRL-T - Paste the selected file path(s) into the command line
|
||||||
__fzf_select() {
|
__fzf_select() {
|
||||||
setopt localoptions pipefail no_aliases 2> /dev/null
|
setopt localoptions pipefail no_aliases 2> /dev/null
|
||||||
@@ -110,14 +89,8 @@ fzf-cd-widget() {
|
|||||||
zle redisplay
|
zle redisplay
|
||||||
return 0
|
return 0
|
||||||
fi
|
fi
|
||||||
# Use subshell expansion to get the absolute PWD of the target dir.
|
|
||||||
# This allows the recorded shell history to be reused even from a different
|
|
||||||
# working directory.
|
|
||||||
# If failed, fallback to the unexpanded path to surface the error to the user.
|
|
||||||
# NOTE: Don't use the `:a` modifier as it resolves symlinks like `pwd -P`.
|
|
||||||
dir=$(builtin cd >/dev/null -- "${dir}" && echo "${PWD}" || echo "${dir}")
|
|
||||||
zle push-line # Clear buffer. Auto-restored on next prompt.
|
zle push-line # Clear buffer. Auto-restored on next prompt.
|
||||||
BUFFER="builtin cd -- ${(q)dir}"
|
BUFFER="builtin cd -- ${(q)dir:a}"
|
||||||
zle accept-line
|
zle accept-line
|
||||||
local ret=$?
|
local ret=$?
|
||||||
unset dir # ensure this doesn't end up appearing in prompt expansion
|
unset dir # ensure this doesn't end up appearing in prompt expansion
|
||||||
@@ -133,52 +106,24 @@ fi
|
|||||||
|
|
||||||
# CTRL-R - Paste the selected command from history into the command line
|
# CTRL-R - Paste the selected command from history into the command line
|
||||||
fzf-history-widget() {
|
fzf-history-widget() {
|
||||||
local selected extracted_with_perl=0
|
local selected
|
||||||
setopt localoptions noglobsubst noposixbuiltins pipefail no_aliases no_glob no_sh_glob no_ksharrays extendedglob 2> /dev/null
|
setopt localoptions noglobsubst noposixbuiltins pipefail no_aliases noglob nobash_rematch 2> /dev/null
|
||||||
# Ensure the module is loaded if not already, and the required features, such
|
# Ensure the associative history array, which maps event numbers to the full
|
||||||
# as the associative 'history' array, which maps event numbers to full history
|
# history lines, is loaded, and that Perl is installed for multi-line output.
|
||||||
# lines, are set. Also, make sure Perl is installed for multi-line output.
|
if zmodload -F zsh/parameter p:history 2>/dev/null && (( ${#commands[perl]} )); then
|
||||||
if zmodload -F zsh/parameter p:{commands,history} 2>/dev/null && (( ${+commands[perl]} )); then
|
|
||||||
selected="$(printf '%s\t%s\000' "${(kv)history[@]}" |
|
selected="$(printf '%s\t%s\000' "${(kv)history[@]}" |
|
||||||
perl -0 -ne 'if (!$seen{(/^\s*[0-9]+\**\t(.*)/s, $1)}++) { s/\n/\n\t/g; print; }' |
|
perl -0 -ne 'if (!$seen{(/^\s*[0-9]+\**\t(.*)/s, $1)}++) { s/\n/\n\t/g; print; }' |
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '\t↳ ' --highlight-line --multi ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER} --read0") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '\t↳ ' --highlight-line ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER} +m --read0") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
||||||
extracted_with_perl=1
|
|
||||||
else
|
else
|
||||||
selected="$(fc -rl 1 | __fzf_exec_awk '{ cmd=$0; sub(/^[ \t]*[0-9]+\**[ \t]+/, "", cmd); if (!seen[cmd]++) print $0 }' |
|
selected="$(fc -rl 1 | awk '{ cmd=$0; sub(/^[ \t]*[0-9]+\**[ \t]+/, "", cmd); if (!seen[cmd]++) print $0 }' |
|
||||||
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort,alt-r:toggle-raw --wrap-sign '\t↳ ' --highlight-line --multi ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER}") \
|
FZF_DEFAULT_OPTS=$(__fzf_defaults "" "-n2..,.. --scheme=history --bind=ctrl-r:toggle-sort --wrap-sign '\t↳ ' --highlight-line ${FZF_CTRL_R_OPTS-} --query=${(qqq)LBUFFER} +m") \
|
||||||
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
FZF_DEFAULT_OPTS_FILE='' $(__fzfcmd))"
|
||||||
fi
|
fi
|
||||||
local ret=$?
|
local ret=$?
|
||||||
local -a cmds
|
|
||||||
# Avoid leaking auto assigned values when using backreferences '(#b)'
|
|
||||||
local -a mbegin mend match
|
|
||||||
if [ -n "$selected" ]; then
|
if [ -n "$selected" ]; then
|
||||||
# Heuristic to check if the selected value is from history or a custom query
|
if [[ $(awk '{print $1; exit}' <<< "$selected") =~ ^[1-9][0-9]* ]]; then
|
||||||
if ((( extracted_with_perl )) && [[ $selected == <->$'\t'* ]]) ||
|
zle vi-fetch-history -n $MATCH
|
||||||
((( ! extracted_with_perl )) && [[ $selected == [[:blank:]]#<->( |\* )* ]]); then
|
|
||||||
# Split at newlines
|
|
||||||
for line in ${(ps:\n:)selected}; do
|
|
||||||
if (( extracted_with_perl )); then
|
|
||||||
if [[ $line == (#b)(<->)(#B)$'\t'* ]]; then
|
|
||||||
(( ${+history[${match[1]}]} )) && cmds+=("${history[${match[1]}]}")
|
|
||||||
fi
|
|
||||||
elif [[ $line == [[:blank:]]#(#b)(<->)(#B)( |\* )* ]]; then
|
|
||||||
# Avoid $history array: lags behind 'fc' on foreign commands (*)
|
|
||||||
# https://zsh.org/mla/users/2024/msg00692.html
|
|
||||||
# Push BUFFER onto stack; fetch and save history entry from BUFFER; restore
|
|
||||||
zle .push-line
|
|
||||||
zle vi-fetch-history -n ${match[1]}
|
|
||||||
(( ${#BUFFER} )) && cmds+=("${BUFFER}")
|
|
||||||
BUFFER=""
|
|
||||||
zle .get-line
|
|
||||||
fi
|
|
||||||
done
|
|
||||||
if (( ${#cmds[@]} )); then
|
|
||||||
# Join by newline after stripping trailing newlines from each command
|
|
||||||
BUFFER="${(pj:\n:)${(@)cmds%%$'\n'#}}"
|
|
||||||
CURSOR=${#BUFFER}
|
|
||||||
fi
|
|
||||||
else # selected is a custom query, not from history
|
else # selected is a custom query, not from history
|
||||||
LBUFFER="$selected"
|
LBUFFER="$selected"
|
||||||
fi
|
fi
|
||||||
@@ -186,15 +131,10 @@ fzf-history-widget() {
|
|||||||
zle reset-prompt
|
zle reset-prompt
|
||||||
return $ret
|
return $ret
|
||||||
}
|
}
|
||||||
if [[ ${FZF_CTRL_R_COMMAND-x} != "" ]]; then
|
zle -N fzf-history-widget
|
||||||
if [[ -n ${FZF_CTRL_R_COMMAND-} ]]; then
|
bindkey -M emacs '^R' fzf-history-widget
|
||||||
echo "warning: FZF_CTRL_R_COMMAND is set to a custom command, but custom commands are not yet supported for CTRL-R" >&2
|
bindkey -M vicmd '^R' fzf-history-widget
|
||||||
fi
|
bindkey -M viins '^R' fzf-history-widget
|
||||||
zle -N fzf-history-widget
|
|
||||||
bindkey -M emacs '^R' fzf-history-widget
|
|
||||||
bindkey -M vicmd '^R' fzf-history-widget
|
|
||||||
bindkey -M viins '^R' fzf-history-widget
|
|
||||||
fi
|
|
||||||
fi
|
fi
|
||||||
|
|
||||||
} always {
|
} always {
|
||||||
|
|||||||
@@ -1,68 +0,0 @@
|
|||||||
#!/usr/bin/env bash
|
|
||||||
|
|
||||||
# This script applies the contents of "common.sh" to the other files.
|
|
||||||
|
|
||||||
set -e
|
|
||||||
|
|
||||||
dir=${0%"${0##*/}"}
|
|
||||||
|
|
||||||
update() {
|
|
||||||
{
|
|
||||||
sed -n '1,/^#----BEGIN INCLUDE common\.sh/p' "$1"
|
|
||||||
cat << EOF
|
|
||||||
# NOTE: Do not directly edit this section, which is copied from "common.sh".
|
|
||||||
# To modify it, one can edit "common.sh" and run "./update.sh" to apply
|
|
||||||
# the changes. See code comments in "common.sh" for the implementation details.
|
|
||||||
EOF
|
|
||||||
echo
|
|
||||||
grep -v '^[[:blank:]]*#' "$dir/common.sh" # remove code comments in common.sh
|
|
||||||
sed -n '/^#----END INCLUDE/,$p' "$1"
|
|
||||||
} > "$1.part"
|
|
||||||
|
|
||||||
mv -f "$1.part" "$1"
|
|
||||||
}
|
|
||||||
|
|
||||||
update "$dir/completion.bash"
|
|
||||||
update "$dir/completion.zsh"
|
|
||||||
update "$dir/key-bindings.bash"
|
|
||||||
update "$dir/key-bindings.zsh"
|
|
||||||
|
|
||||||
# Check if --check is in ARGV
|
|
||||||
check=0
|
|
||||||
rest=()
|
|
||||||
for arg in "$@"; do
|
|
||||||
case $arg in
|
|
||||||
--check) check=1 ;;
|
|
||||||
*) rest+=("$arg") ;;
|
|
||||||
esac
|
|
||||||
done
|
|
||||||
|
|
||||||
fmt() {
|
|
||||||
if ! grep -q "^#----BEGIN shfmt" "$1"; then
|
|
||||||
if [[ $check == 1 ]]; then
|
|
||||||
shfmt -d "$1"
|
|
||||||
return $?
|
|
||||||
else
|
|
||||||
shfmt -w "$1"
|
|
||||||
fi
|
|
||||||
else
|
|
||||||
{
|
|
||||||
sed -n '1,/^#----BEGIN shfmt/p' "$1" | sed '$d'
|
|
||||||
sed -n '/^#----BEGIN shfmt/,/^#----END shfmt/p' "$1" | shfmt --filename "$1"
|
|
||||||
sed -n '/^#----END shfmt/,$p' "$1" | sed '1d'
|
|
||||||
} > "$1.part"
|
|
||||||
|
|
||||||
if [[ $check == 1 ]]; then
|
|
||||||
diff -q "$1" "$1.part"
|
|
||||||
ret=$?
|
|
||||||
rm -f "$1.part"
|
|
||||||
return $ret
|
|
||||||
fi
|
|
||||||
|
|
||||||
mv -f "$1.part" "$1"
|
|
||||||
fi
|
|
||||||
}
|
|
||||||
|
|
||||||
for file in "${rest[@]}"; do
|
|
||||||
fmt "$file" || exit $?
|
|
||||||
done
|
|
||||||
+1
-1
@@ -1,6 +1,6 @@
|
|||||||
The MIT License (MIT)
|
The MIT License (MIT)
|
||||||
|
|
||||||
Copyright (c) 2013-2026 Junegunn Choi
|
Copyright (c) 2013-2024 Junegunn Choi
|
||||||
|
|
||||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
of this software and associated documentation files (the "Software"), to deal
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
|||||||
+111
-176
@@ -12,185 +12,120 @@ func _() {
|
|||||||
_ = x[actStart-1]
|
_ = x[actStart-1]
|
||||||
_ = x[actClick-2]
|
_ = x[actClick-2]
|
||||||
_ = x[actInvalid-3]
|
_ = x[actInvalid-3]
|
||||||
_ = x[actBracketedPasteBegin-4]
|
_ = x[actChar-4]
|
||||||
_ = x[actBracketedPasteEnd-5]
|
_ = x[actMouse-5]
|
||||||
_ = x[actChar-6]
|
_ = x[actBeginningOfLine-6]
|
||||||
_ = x[actMouse-7]
|
_ = x[actAbort-7]
|
||||||
_ = x[actBeginningOfLine-8]
|
_ = x[actAccept-8]
|
||||||
_ = x[actAbort-9]
|
_ = x[actAcceptNonEmpty-9]
|
||||||
_ = x[actAccept-10]
|
_ = x[actAcceptOrPrintQuery-10]
|
||||||
_ = x[actAcceptNonEmpty-11]
|
_ = x[actBackwardChar-11]
|
||||||
_ = x[actAcceptOrPrintQuery-12]
|
_ = x[actBackwardDeleteChar-12]
|
||||||
_ = x[actBackwardChar-13]
|
_ = x[actBackwardDeleteCharEof-13]
|
||||||
_ = x[actBackwardDeleteChar-14]
|
_ = x[actBackwardWord-14]
|
||||||
_ = x[actBackwardDeleteCharEof-15]
|
_ = x[actCancel-15]
|
||||||
_ = x[actBackwardWord-16]
|
_ = x[actChangeBorderLabel-16]
|
||||||
_ = x[actBackwardSubWord-17]
|
_ = x[actChangeHeader-17]
|
||||||
_ = x[actCancel-18]
|
_ = x[actChangeMulti-18]
|
||||||
_ = x[actChangeBorderLabel-19]
|
_ = x[actChangePreviewLabel-19]
|
||||||
_ = x[actChangeGhost-20]
|
_ = x[actChangePrompt-20]
|
||||||
_ = x[actChangeHeader-21]
|
_ = x[actChangeQuery-21]
|
||||||
_ = x[actChangeHeaderLines-22]
|
_ = x[actClearScreen-22]
|
||||||
_ = x[actChangeFooter-23]
|
_ = x[actClearQuery-23]
|
||||||
_ = x[actChangeHeaderLabel-24]
|
_ = x[actClearSelection-24]
|
||||||
_ = x[actChangeFooterLabel-25]
|
_ = x[actClose-25]
|
||||||
_ = x[actChangeInputLabel-26]
|
_ = x[actDeleteChar-26]
|
||||||
_ = x[actChangeListLabel-27]
|
_ = x[actDeleteCharEof-27]
|
||||||
_ = x[actChangeMulti-28]
|
_ = x[actEndOfLine-28]
|
||||||
_ = x[actChangeNth-29]
|
_ = x[actFatal-29]
|
||||||
_ = x[actChangeWithNth-30]
|
_ = x[actForwardChar-30]
|
||||||
_ = x[actChangePointer-31]
|
_ = x[actForwardWord-31]
|
||||||
_ = x[actChangePreview-32]
|
_ = x[actKillLine-32]
|
||||||
_ = x[actChangePreviewLabel-33]
|
_ = x[actKillWord-33]
|
||||||
_ = x[actChangePreviewWindow-34]
|
_ = x[actUnixLineDiscard-34]
|
||||||
_ = x[actChangePrompt-35]
|
_ = x[actUnixWordRubout-35]
|
||||||
_ = x[actChangeQuery-36]
|
_ = x[actYank-36]
|
||||||
_ = x[actClearScreen-37]
|
_ = x[actBackwardKillWord-37]
|
||||||
_ = x[actClearQuery-38]
|
_ = x[actSelectAll-38]
|
||||||
_ = x[actClearSelection-39]
|
_ = x[actDeselectAll-39]
|
||||||
_ = x[actClose-40]
|
_ = x[actToggle-40]
|
||||||
_ = x[actDeleteChar-41]
|
_ = x[actToggleSearch-41]
|
||||||
_ = x[actDeleteCharEof-42]
|
_ = x[actToggleAll-42]
|
||||||
_ = x[actEndOfLine-43]
|
_ = x[actToggleDown-43]
|
||||||
_ = x[actFatal-44]
|
_ = x[actToggleUp-44]
|
||||||
_ = x[actForwardChar-45]
|
_ = x[actToggleIn-45]
|
||||||
_ = x[actForwardWord-46]
|
_ = x[actToggleOut-46]
|
||||||
_ = x[actForwardSubWord-47]
|
_ = x[actToggleTrack-47]
|
||||||
_ = x[actKillLine-48]
|
_ = x[actToggleTrackCurrent-48]
|
||||||
_ = x[actKillWord-49]
|
_ = x[actToggleHeader-49]
|
||||||
_ = x[actKillSubWord-50]
|
_ = x[actToggleWrap-50]
|
||||||
_ = x[actUnixLineDiscard-51]
|
_ = x[actTrackCurrent-51]
|
||||||
_ = x[actUnixWordRubout-52]
|
_ = x[actUntrackCurrent-52]
|
||||||
_ = x[actYank-53]
|
_ = x[actDown-53]
|
||||||
_ = x[actBackwardKillWord-54]
|
_ = x[actUp-54]
|
||||||
_ = x[actBackwardKillSubWord-55]
|
_ = x[actPageUp-55]
|
||||||
_ = x[actSelectAll-56]
|
_ = x[actPageDown-56]
|
||||||
_ = x[actDeselectAll-57]
|
_ = x[actPosition-57]
|
||||||
_ = x[actToggle-58]
|
_ = x[actHalfPageUp-58]
|
||||||
_ = x[actToggleSearch-59]
|
_ = x[actHalfPageDown-59]
|
||||||
_ = x[actToggleAll-60]
|
_ = x[actOffsetUp-60]
|
||||||
_ = x[actToggleDown-61]
|
_ = x[actOffsetDown-61]
|
||||||
_ = x[actToggleUp-62]
|
_ = x[actOffsetMiddle-62]
|
||||||
_ = x[actToggleIn-63]
|
_ = x[actJump-63]
|
||||||
_ = x[actToggleOut-64]
|
_ = x[actJumpAccept-64]
|
||||||
_ = x[actToggleTrack-65]
|
_ = x[actPrintQuery-65]
|
||||||
_ = x[actToggleTrackCurrent-66]
|
_ = x[actRefreshPreview-66]
|
||||||
_ = x[actToggleHeader-67]
|
_ = x[actReplaceQuery-67]
|
||||||
_ = x[actToggleWrap-68]
|
_ = x[actToggleSort-68]
|
||||||
_ = x[actToggleWrapWord-69]
|
_ = x[actShowPreview-69]
|
||||||
_ = x[actToggleMultiLine-70]
|
_ = x[actHidePreview-70]
|
||||||
_ = x[actToggleHscroll-71]
|
_ = x[actTogglePreview-71]
|
||||||
_ = x[actToggleRaw-72]
|
_ = x[actTogglePreviewWrap-72]
|
||||||
_ = x[actEnableRaw-73]
|
_ = x[actTransform-73]
|
||||||
_ = x[actDisableRaw-74]
|
_ = x[actTransformBorderLabel-74]
|
||||||
_ = x[actTrackCurrent-75]
|
_ = x[actTransformHeader-75]
|
||||||
_ = x[actToggleInput-76]
|
_ = x[actTransformPreviewLabel-76]
|
||||||
_ = x[actHideInput-77]
|
_ = x[actTransformPrompt-77]
|
||||||
_ = x[actShowInput-78]
|
_ = x[actTransformQuery-78]
|
||||||
_ = x[actUntrackCurrent-79]
|
_ = x[actPreview-79]
|
||||||
_ = x[actDown-80]
|
_ = x[actChangePreview-80]
|
||||||
_ = x[actDownMatch-81]
|
_ = x[actChangePreviewWindow-81]
|
||||||
_ = x[actUp-82]
|
_ = x[actPreviewTop-82]
|
||||||
_ = x[actUpMatch-83]
|
_ = x[actPreviewBottom-83]
|
||||||
_ = x[actPageUp-84]
|
_ = x[actPreviewUp-84]
|
||||||
_ = x[actPageDown-85]
|
_ = x[actPreviewDown-85]
|
||||||
_ = x[actPosition-86]
|
_ = x[actPreviewPageUp-86]
|
||||||
_ = x[actHalfPageUp-87]
|
_ = x[actPreviewPageDown-87]
|
||||||
_ = x[actHalfPageDown-88]
|
_ = x[actPreviewHalfPageUp-88]
|
||||||
_ = x[actOffsetUp-89]
|
_ = x[actPreviewHalfPageDown-89]
|
||||||
_ = x[actOffsetDown-90]
|
_ = x[actPrevHistory-90]
|
||||||
_ = x[actOffsetMiddle-91]
|
_ = x[actPrevSelected-91]
|
||||||
_ = x[actJump-92]
|
_ = x[actPrint-92]
|
||||||
_ = x[actJumpAccept-93]
|
_ = x[actPut-93]
|
||||||
_ = x[actPrintQuery-94]
|
_ = x[actNextHistory-94]
|
||||||
_ = x[actRefreshPreview-95]
|
_ = x[actNextSelected-95]
|
||||||
_ = x[actReplaceQuery-96]
|
_ = x[actExecute-96]
|
||||||
_ = x[actToggleSort-97]
|
_ = x[actExecuteSilent-97]
|
||||||
_ = x[actShowPreview-98]
|
_ = x[actExecuteMulti-98]
|
||||||
_ = x[actHidePreview-99]
|
_ = x[actSigStop-99]
|
||||||
_ = x[actTogglePreview-100]
|
_ = x[actFirst-100]
|
||||||
_ = x[actTogglePreviewWrap-101]
|
_ = x[actLast-101]
|
||||||
_ = x[actTogglePreviewWrapWord-102]
|
_ = x[actReload-102]
|
||||||
_ = x[actTransform-103]
|
_ = x[actReloadSync-103]
|
||||||
_ = x[actTransformBorderLabel-104]
|
_ = x[actDisableSearch-104]
|
||||||
_ = x[actTransformGhost-105]
|
_ = x[actEnableSearch-105]
|
||||||
_ = x[actTransformHeader-106]
|
_ = x[actSelect-106]
|
||||||
_ = x[actTransformHeaderLines-107]
|
_ = x[actDeselect-107]
|
||||||
_ = x[actTransformFooter-108]
|
_ = x[actUnbind-108]
|
||||||
_ = x[actTransformHeaderLabel-109]
|
_ = x[actRebind-109]
|
||||||
_ = x[actTransformFooterLabel-110]
|
_ = x[actBecome-110]
|
||||||
_ = x[actTransformInputLabel-111]
|
_ = x[actShowHeader-111]
|
||||||
_ = x[actTransformListLabel-112]
|
_ = x[actHideHeader-112]
|
||||||
_ = x[actTransformNth-113]
|
|
||||||
_ = x[actTransformWithNth-114]
|
|
||||||
_ = x[actTransformPointer-115]
|
|
||||||
_ = x[actTransformPreviewLabel-116]
|
|
||||||
_ = x[actTransformPrompt-117]
|
|
||||||
_ = x[actTransformQuery-118]
|
|
||||||
_ = x[actTransformSearch-119]
|
|
||||||
_ = x[actTrigger-120]
|
|
||||||
_ = x[actBgTransform-121]
|
|
||||||
_ = x[actBgTransformBorderLabel-122]
|
|
||||||
_ = x[actBgTransformGhost-123]
|
|
||||||
_ = x[actBgTransformHeader-124]
|
|
||||||
_ = x[actBgTransformHeaderLines-125]
|
|
||||||
_ = x[actBgTransformFooter-126]
|
|
||||||
_ = x[actBgTransformHeaderLabel-127]
|
|
||||||
_ = x[actBgTransformFooterLabel-128]
|
|
||||||
_ = x[actBgTransformInputLabel-129]
|
|
||||||
_ = x[actBgTransformListLabel-130]
|
|
||||||
_ = x[actBgTransformNth-131]
|
|
||||||
_ = x[actBgTransformWithNth-132]
|
|
||||||
_ = x[actBgTransformPointer-133]
|
|
||||||
_ = x[actBgTransformPreviewLabel-134]
|
|
||||||
_ = x[actBgTransformPrompt-135]
|
|
||||||
_ = x[actBgTransformQuery-136]
|
|
||||||
_ = x[actBgTransformSearch-137]
|
|
||||||
_ = x[actBgCancel-138]
|
|
||||||
_ = x[actSearch-139]
|
|
||||||
_ = x[actPreview-140]
|
|
||||||
_ = x[actPreviewTop-141]
|
|
||||||
_ = x[actPreviewBottom-142]
|
|
||||||
_ = x[actPreviewUp-143]
|
|
||||||
_ = x[actPreviewDown-144]
|
|
||||||
_ = x[actPreviewPageUp-145]
|
|
||||||
_ = x[actPreviewPageDown-146]
|
|
||||||
_ = x[actPreviewHalfPageUp-147]
|
|
||||||
_ = x[actPreviewHalfPageDown-148]
|
|
||||||
_ = x[actPrevHistory-149]
|
|
||||||
_ = x[actPrevSelected-150]
|
|
||||||
_ = x[actPrint-151]
|
|
||||||
_ = x[actPut-152]
|
|
||||||
_ = x[actNextHistory-153]
|
|
||||||
_ = x[actNextSelected-154]
|
|
||||||
_ = x[actExecute-155]
|
|
||||||
_ = x[actExecuteSilent-156]
|
|
||||||
_ = x[actExecuteMulti-157]
|
|
||||||
_ = x[actSigStop-158]
|
|
||||||
_ = x[actBest-159]
|
|
||||||
_ = x[actFirst-160]
|
|
||||||
_ = x[actLast-161]
|
|
||||||
_ = x[actReload-162]
|
|
||||||
_ = x[actReloadSync-163]
|
|
||||||
_ = x[actDisableSearch-164]
|
|
||||||
_ = x[actEnableSearch-165]
|
|
||||||
_ = x[actSelect-166]
|
|
||||||
_ = x[actDeselect-167]
|
|
||||||
_ = x[actUnbind-168]
|
|
||||||
_ = x[actRebind-169]
|
|
||||||
_ = x[actToggleBind-170]
|
|
||||||
_ = x[actBecome-171]
|
|
||||||
_ = x[actShowHeader-172]
|
|
||||||
_ = x[actHideHeader-173]
|
|
||||||
_ = x[actBell-174]
|
|
||||||
_ = x[actExclude-175]
|
|
||||||
_ = x[actExcludeMulti-176]
|
|
||||||
_ = x[actAsync-177]
|
|
||||||
}
|
}
|
||||||
|
|
||||||
const _actionType_name = "actIgnoreactStartactClickactInvalidactBracketedPasteBeginactBracketedPasteEndactCharactMouseactBeginningOfLineactAbortactAcceptactAcceptNonEmptyactAcceptOrPrintQueryactBackwardCharactBackwardDeleteCharactBackwardDeleteCharEofactBackwardWordactBackwardSubWordactCancelactChangeBorderLabelactChangeGhostactChangeHeaderactChangeHeaderLinesactChangeFooteractChangeHeaderLabelactChangeFooterLabelactChangeInputLabelactChangeListLabelactChangeMultiactChangeNthactChangeWithNthactChangePointeractChangePreviewactChangePreviewLabelactChangePreviewWindowactChangePromptactChangeQueryactClearScreenactClearQueryactClearSelectionactCloseactDeleteCharactDeleteCharEofactEndOfLineactFatalactForwardCharactForwardWordactForwardSubWordactKillLineactKillWordactKillSubWordactUnixLineDiscardactUnixWordRuboutactYankactBackwardKillWordactBackwardKillSubWordactSelectAllactDeselectAllactToggleactToggleSearchactToggleAllactToggleDownactToggleUpactToggleInactToggleOutactToggleTrackactToggleTrackCurrentactToggleHeaderactToggleWrapactToggleWrapWordactToggleMultiLineactToggleHscrollactToggleRawactEnableRawactDisableRawactTrackCurrentactToggleInputactHideInputactShowInputactUntrackCurrentactDownactDownMatchactUpactUpMatchactPageUpactPageDownactPositionactHalfPageUpactHalfPageDownactOffsetUpactOffsetDownactOffsetMiddleactJumpactJumpAcceptactPrintQueryactRefreshPreviewactReplaceQueryactToggleSortactShowPreviewactHidePreviewactTogglePreviewactTogglePreviewWrapactTogglePreviewWrapWordactTransformactTransformBorderLabelactTransformGhostactTransformHeaderactTransformHeaderLinesactTransformFooteractTransformHeaderLabelactTransformFooterLabelactTransformInputLabelactTransformListLabelactTransformNthactTransformWithNthactTransformPointeractTransformPreviewLabelactTransformPromptactTransformQueryactTransformSearchactTriggeractBgTransformactBgTransformBorderLabelactBgTransformGhostactBgTransformHeaderactBgTransformHeaderLinesactBgTransformFooteractBgTransformHeaderLabelactBgTransformFooterLabelactBgTransformInputLabelactBgTransformListLabelactBgTransformNthactBgTransformWithNthactBgTransformPointeractBgTransformPreviewLabelactBgTransformPromptactBgTransformQueryactBgTransformSearchactBgCancelactSearchactPreviewactPreviewTopactPreviewBottomactPreviewUpactPreviewDownactPreviewPageUpactPreviewPageDownactPreviewHalfPageUpactPreviewHalfPageDownactPrevHistoryactPrevSelectedactPrintactPutactNextHistoryactNextSelectedactExecuteactExecuteSilentactExecuteMultiactSigStopactBestactFirstactLastactReloadactReloadSyncactDisableSearchactEnableSearchactSelectactDeselectactUnbindactRebindactToggleBindactBecomeactShowHeaderactHideHeaderactBellactExcludeactExcludeMultiactAsync"
|
const _actionType_name = "actIgnoreactStartactClickactInvalidactCharactMouseactBeginningOfLineactAbortactAcceptactAcceptNonEmptyactAcceptOrPrintQueryactBackwardCharactBackwardDeleteCharactBackwardDeleteCharEofactBackwardWordactCancelactChangeBorderLabelactChangeHeaderactChangeMultiactChangePreviewLabelactChangePromptactChangeQueryactClearScreenactClearQueryactClearSelectionactCloseactDeleteCharactDeleteCharEofactEndOfLineactFatalactForwardCharactForwardWordactKillLineactKillWordactUnixLineDiscardactUnixWordRuboutactYankactBackwardKillWordactSelectAllactDeselectAllactToggleactToggleSearchactToggleAllactToggleDownactToggleUpactToggleInactToggleOutactToggleTrackactToggleTrackCurrentactToggleHeaderactToggleWrapactTrackCurrentactUntrackCurrentactDownactUpactPageUpactPageDownactPositionactHalfPageUpactHalfPageDownactOffsetUpactOffsetDownactOffsetMiddleactJumpactJumpAcceptactPrintQueryactRefreshPreviewactReplaceQueryactToggleSortactShowPreviewactHidePreviewactTogglePreviewactTogglePreviewWrapactTransformactTransformBorderLabelactTransformHeaderactTransformPreviewLabelactTransformPromptactTransformQueryactPreviewactChangePreviewactChangePreviewWindowactPreviewTopactPreviewBottomactPreviewUpactPreviewDownactPreviewPageUpactPreviewPageDownactPreviewHalfPageUpactPreviewHalfPageDownactPrevHistoryactPrevSelectedactPrintactPutactNextHistoryactNextSelectedactExecuteactExecuteSilentactExecuteMultiactSigStopactFirstactLastactReloadactReloadSyncactDisableSearchactEnableSearchactSelectactDeselectactUnbindactRebindactBecomeactShowHeaderactHideHeader"
|
||||||
|
|
||||||
var _actionType_index = [...]uint16{0, 9, 17, 25, 35, 57, 77, 84, 92, 110, 118, 127, 144, 165, 180, 201, 225, 240, 258, 267, 287, 301, 316, 336, 351, 371, 391, 410, 428, 442, 454, 470, 486, 502, 523, 545, 560, 574, 588, 601, 618, 626, 639, 655, 667, 675, 689, 703, 720, 731, 742, 756, 774, 791, 798, 817, 839, 851, 865, 874, 889, 901, 914, 925, 936, 948, 962, 983, 998, 1011, 1028, 1046, 1062, 1074, 1086, 1099, 1114, 1128, 1140, 1152, 1169, 1176, 1188, 1193, 1203, 1212, 1223, 1234, 1247, 1262, 1273, 1286, 1301, 1308, 1321, 1334, 1351, 1366, 1379, 1393, 1407, 1423, 1443, 1467, 1479, 1502, 1519, 1537, 1560, 1578, 1601, 1624, 1646, 1667, 1682, 1701, 1720, 1744, 1762, 1779, 1797, 1807, 1821, 1846, 1865, 1885, 1910, 1930, 1955, 1980, 2004, 2027, 2044, 2065, 2086, 2112, 2132, 2151, 2171, 2182, 2191, 2201, 2214, 2230, 2242, 2256, 2272, 2290, 2310, 2332, 2346, 2361, 2369, 2375, 2389, 2404, 2414, 2430, 2445, 2455, 2462, 2470, 2477, 2486, 2499, 2515, 2530, 2539, 2550, 2559, 2568, 2581, 2590, 2603, 2616, 2623, 2633, 2648, 2656}
|
var _actionType_index = [...]uint16{0, 9, 17, 25, 35, 42, 50, 68, 76, 85, 102, 123, 138, 159, 183, 198, 207, 227, 242, 256, 277, 292, 306, 320, 333, 350, 358, 371, 387, 399, 407, 421, 435, 446, 457, 475, 492, 499, 518, 530, 544, 553, 568, 580, 593, 604, 615, 627, 641, 662, 677, 690, 705, 722, 729, 734, 743, 754, 765, 778, 793, 804, 817, 832, 839, 852, 865, 882, 897, 910, 924, 938, 954, 974, 986, 1009, 1027, 1051, 1069, 1086, 1096, 1112, 1134, 1147, 1163, 1175, 1189, 1205, 1223, 1243, 1265, 1279, 1294, 1302, 1308, 1322, 1337, 1347, 1363, 1378, 1388, 1396, 1403, 1412, 1425, 1441, 1456, 1465, 1476, 1485, 1494, 1503, 1516, 1529}
|
||||||
|
|
||||||
func (i actionType) String() string {
|
func (i actionType) String() string {
|
||||||
if i < 0 || i >= actionType(len(_actionType_index)-1) {
|
if i < 0 || i >= actionType(len(_actionType_index)-1) {
|
||||||
|
|||||||
@@ -1,99 +0,0 @@
|
|||||||
# SIMD byte search: `indexByteTwo` / `lastIndexByteTwo`
|
|
||||||
|
|
||||||
## What these functions do
|
|
||||||
|
|
||||||
`indexByteTwo(s []byte, b1, b2 byte) int` -- returns the index of the
|
|
||||||
**first** occurrence of `b1` or `b2` in `s`, or `-1`.
|
|
||||||
|
|
||||||
`lastIndexByteTwo(s []byte, b1, b2 byte) int` -- returns the index of the
|
|
||||||
**last** occurrence of `b1` or `b2` in `s`, or `-1`.
|
|
||||||
|
|
||||||
They are used by the fuzzy matching algorithm (`algo.go`) to skip ahead
|
|
||||||
during case-insensitive search. Instead of calling `bytes.IndexByte` twice
|
|
||||||
(once for lowercase, once for uppercase), a single SIMD pass finds both at
|
|
||||||
once.
|
|
||||||
|
|
||||||
## File layout
|
|
||||||
|
|
||||||
| File | Purpose |
|
|
||||||
| ------ | --------- |
|
|
||||||
| `indexbyte2_arm64.go` | Go declarations (`//go:noescape`) for ARM64 |
|
|
||||||
| `indexbyte2_arm64.s` | ARM64 NEON assembly (32-byte aligned blocks, syndrome extraction) |
|
|
||||||
| `indexbyte2_amd64.go` | Go declarations + AVX2 runtime detection for AMD64 |
|
|
||||||
| `indexbyte2_amd64.s` | AMD64 AVX2/SSE2 assembly with CPUID dispatch |
|
|
||||||
| `indexbyte2_other.go` | Pure Go fallback for all other architectures |
|
|
||||||
| `indexbyte2_test.go` | Unit tests, exhaustive tests, fuzz tests, and benchmarks |
|
|
||||||
|
|
||||||
## How the SIMD implementations work
|
|
||||||
|
|
||||||
**ARM64 (NEON):**
|
|
||||||
- Broadcasts both needle bytes into NEON registers (`VMOV`).
|
|
||||||
- Processes 32-byte aligned chunks. For each chunk, compares all bytes
|
|
||||||
against both needles (`VCMEQ`), ORs the results (`VORR`), and builds a
|
|
||||||
64-bit syndrome with 2 bits per byte.
|
|
||||||
- `indexByteTwo` uses `RBIT` + `CLZ` to find the lowest set bit (first match).
|
|
||||||
- `lastIndexByteTwo` scans backward and uses `CLZ` on the raw syndrome to
|
|
||||||
find the highest set bit (last match).
|
|
||||||
- Handles alignment and partial first/last blocks with bit masking.
|
|
||||||
- Adapted from Go's `internal/bytealg/indexbyte_arm64.s`.
|
|
||||||
|
|
||||||
**AMD64 (AVX2 with SSE2 fallback):**
|
|
||||||
- At init time, `cpuHasAVX2()` checks CPUID + XGETBV for AVX2 and OS YMM
|
|
||||||
support. The result is cached in `_useAVX2`.
|
|
||||||
- **AVX2 path** (inputs >= 32 bytes, when available):
|
|
||||||
- Broadcasts both needles via `VPBROADCASTB`.
|
|
||||||
- Processes 32-byte blocks: `VPCMPEQB` against both needles, `VPOR`, then
|
|
||||||
`VPMOVMSKB` to get a 32-bit mask.
|
|
||||||
- 5 instructions per loop iteration (vs 7 for SSE2) at 2x the throughput.
|
|
||||||
- `VZEROUPPER` before every return to avoid SSE/AVX transition penalties.
|
|
||||||
- **SSE2 fallback** (inputs < 32 bytes, or CPUs without AVX2):
|
|
||||||
- Broadcasts via `PUNPCKLBW` + `PSHUFL`.
|
|
||||||
- Processes 16-byte blocks: `PCMPEQB`, `POR`, `PMOVMSKB`.
|
|
||||||
- Small inputs (<16 bytes) are handled with page-boundary-safe loads.
|
|
||||||
- Both paths use `BSFL` (forward) / `BSRL` (reverse) for bit scanning.
|
|
||||||
- Adapted from Go's `internal/bytealg/indexbyte_amd64.s`.
|
|
||||||
|
|
||||||
**Fallback (other platforms):**
|
|
||||||
- `indexByteTwo` uses two `bytes.IndexByte` calls with scope-limiting
|
|
||||||
(search `b1` first, then limit the `b2` search to `s[:i1]`).
|
|
||||||
- `lastIndexByteTwo` uses a simple backward for loop.
|
|
||||||
|
|
||||||
## Running tests
|
|
||||||
|
|
||||||
```bash
|
|
||||||
# Unit + exhaustive tests
|
|
||||||
go test ./src/algo/ -run 'TestIndexByteTwo|TestLastIndexByteTwo' -v
|
|
||||||
|
|
||||||
# Fuzz tests (run for 10 seconds each)
|
|
||||||
go test ./src/algo/ -run '^$' -fuzz FuzzIndexByteTwo -fuzztime 10s
|
|
||||||
go test ./src/algo/ -run '^$' -fuzz FuzzLastIndexByteTwo -fuzztime 10s
|
|
||||||
|
|
||||||
# Cross-architecture: test amd64 on an arm64 Mac (via Rosetta)
|
|
||||||
GOARCH=amd64 go test ./src/algo/ -run 'TestIndexByteTwo|TestLastIndexByteTwo' -v
|
|
||||||
GOARCH=amd64 go test ./src/algo/ -run '^$' -fuzz FuzzIndexByteTwo -fuzztime 10s
|
|
||||||
GOARCH=amd64 go test ./src/algo/ -run '^$' -fuzz FuzzLastIndexByteTwo -fuzztime 10s
|
|
||||||
```
|
|
||||||
|
|
||||||
## Running micro-benchmarks
|
|
||||||
|
|
||||||
```bash
|
|
||||||
# All indexByteTwo / lastIndexByteTwo benchmarks
|
|
||||||
go test ./src/algo/ -bench 'IndexByteTwo' -benchmem
|
|
||||||
|
|
||||||
# Specific size
|
|
||||||
go test ./src/algo/ -bench 'IndexByteTwo_1000'
|
|
||||||
```
|
|
||||||
|
|
||||||
Each benchmark compares the SIMD `asm` implementation against reference
|
|
||||||
implementations (`2xIndexByte` using `bytes.IndexByte`, and a simple `loop`).
|
|
||||||
|
|
||||||
## Correctness verification
|
|
||||||
|
|
||||||
The assembly is verified by three layers of testing:
|
|
||||||
|
|
||||||
1. **Table-driven tests** -- known inputs with expected outputs.
|
|
||||||
2. **Exhaustive tests** -- all lengths 0–256, every match position, no-match
|
|
||||||
cases, and both-bytes-present cases, compared against a simple loop
|
|
||||||
reference.
|
|
||||||
3. **Fuzz tests** -- randomized inputs via `testing.F`, compared against the
|
|
||||||
same loop reference.
|
|
||||||
+36
-46
@@ -266,7 +266,7 @@ func charClassOf(char rune) charClass {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func bonusFor(prevClass charClass, class charClass) int16 {
|
func bonusFor(prevClass charClass, class charClass) int16 {
|
||||||
if class >= charNonWord {
|
if class > charNonWord {
|
||||||
switch prevClass {
|
switch prevClass {
|
||||||
case charWhite:
|
case charWhite:
|
||||||
// Word boundary after whitespace
|
// Word boundary after whitespace
|
||||||
@@ -303,7 +303,7 @@ func bonusAt(input *util.Chars, idx int) int16 {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func normalizeRune(r rune) rune {
|
func normalizeRune(r rune) rune {
|
||||||
if r < 0x00C0 || r > 0xFF61 {
|
if r < 0x00C0 || r > 0x2184 {
|
||||||
return r
|
return r
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -321,15 +321,22 @@ type Algo func(caseSensitive bool, normalize bool, forward bool, input *util.Cha
|
|||||||
|
|
||||||
func trySkip(input *util.Chars, caseSensitive bool, b byte, from int) int {
|
func trySkip(input *util.Chars, caseSensitive bool, b byte, from int) int {
|
||||||
byteArray := input.Bytes()[from:]
|
byteArray := input.Bytes()[from:]
|
||||||
// For case-insensitive search of a letter, search for both cases in one pass
|
|
||||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
|
||||||
idx := IndexByteTwo(byteArray, b, b-32)
|
|
||||||
if idx < 0 {
|
|
||||||
return -1
|
|
||||||
}
|
|
||||||
return from + idx
|
|
||||||
}
|
|
||||||
idx := bytes.IndexByte(byteArray, b)
|
idx := bytes.IndexByte(byteArray, b)
|
||||||
|
if idx == 0 {
|
||||||
|
// Can't skip any further
|
||||||
|
return from
|
||||||
|
}
|
||||||
|
// We may need to search for the uppercase letter again. We don't have to
|
||||||
|
// consider normalization as we can be sure that this is an ASCII string.
|
||||||
|
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||||
|
if idx > 0 {
|
||||||
|
byteArray = byteArray[:idx]
|
||||||
|
}
|
||||||
|
uidx := bytes.IndexByte(byteArray, b-32)
|
||||||
|
if uidx >= 0 {
|
||||||
|
idx = uidx
|
||||||
|
}
|
||||||
|
}
|
||||||
if idx < 0 {
|
if idx < 0 {
|
||||||
return -1
|
return -1
|
||||||
}
|
}
|
||||||
@@ -358,7 +365,7 @@ func asciiFuzzyIndex(input *util.Chars, pattern []rune, caseSensitive bool) (int
|
|||||||
|
|
||||||
firstIdx, idx, lastIdx := 0, 0, 0
|
firstIdx, idx, lastIdx := 0, 0, 0
|
||||||
var b byte
|
var b byte
|
||||||
for pidx := range pattern {
|
for pidx := 0; pidx < len(pattern); pidx++ {
|
||||||
b = byte(pattern[pidx])
|
b = byte(pattern[pidx])
|
||||||
idx = trySkip(input, caseSensitive, b, idx)
|
idx = trySkip(input, caseSensitive, b, idx)
|
||||||
if idx < 0 {
|
if idx < 0 {
|
||||||
@@ -373,17 +380,14 @@ func asciiFuzzyIndex(input *util.Chars, pattern []rune, caseSensitive bool) (int
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Find the last appearance of the last character of the pattern to limit the search scope
|
// Find the last appearance of the last character of the pattern to limit the search scope
|
||||||
|
bu := b
|
||||||
|
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||||
|
bu = b - 32
|
||||||
|
}
|
||||||
scope := input.Bytes()[lastIdx:]
|
scope := input.Bytes()[lastIdx:]
|
||||||
if len(scope) > 1 {
|
for offset := len(scope) - 1; offset > 0; offset-- {
|
||||||
tail := scope[1:]
|
if scope[offset] == b || scope[offset] == bu {
|
||||||
var end int
|
return firstIdx, lastIdx + offset + 1
|
||||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
|
||||||
end = lastIndexByteTwo(tail, b, b-32)
|
|
||||||
} else {
|
|
||||||
end = bytes.LastIndexByte(tail, b)
|
|
||||||
}
|
|
||||||
if end >= 0 {
|
|
||||||
return firstIdx, lastIdx + 1 + end + 1
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
return firstIdx, lastIdx + 1
|
return firstIdx, lastIdx + 1
|
||||||
@@ -397,7 +401,7 @@ func debugV2(T []rune, pattern []rune, F []int32, lastIdx int, H []int16, C []in
|
|||||||
if i == 0 {
|
if i == 0 {
|
||||||
fmt.Print(" ")
|
fmt.Print(" ")
|
||||||
for j := int(f); j <= lastIdx; j++ {
|
for j := int(f); j <= lastIdx; j++ {
|
||||||
fmt.Print(" " + string(T[j]) + " ")
|
fmt.Printf(" " + string(T[j]) + " ")
|
||||||
}
|
}
|
||||||
fmt.Println()
|
fmt.Println()
|
||||||
}
|
}
|
||||||
@@ -441,9 +445,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
|||||||
|
|
||||||
// Since O(nm) algorithm can be prohibitively expensive for large input,
|
// Since O(nm) algorithm can be prohibitively expensive for large input,
|
||||||
// we fall back to the greedy algorithm.
|
// we fall back to the greedy algorithm.
|
||||||
// Also, we should not allow a very long pattern to avoid 16-bit integer
|
if slab != nil && N*M > cap(slab.I16) {
|
||||||
// overflow in the score matrix. 1000 is a safe limit.
|
|
||||||
if slab != nil && int64(N)*int64(M) > int64(cap(slab.I16)) || M > 1000 {
|
|
||||||
return FuzzyMatchV1(caseSensitive, normalize, forward, input, pattern, withPos, slab)
|
return FuzzyMatchV1(caseSensitive, normalize, forward, input, pattern, withPos, slab)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -499,7 +501,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
|||||||
if pidx < M {
|
if pidx < M {
|
||||||
F[pidx] = int32(off)
|
F[pidx] = int32(off)
|
||||||
pidx++
|
pidx++
|
||||||
pchar = pattern[min(pidx, M-1)]
|
pchar = pattern[util.Min(pidx, M-1)]
|
||||||
}
|
}
|
||||||
lastIdx = off
|
lastIdx = off
|
||||||
}
|
}
|
||||||
@@ -517,9 +519,9 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
|||||||
inGap = false
|
inGap = false
|
||||||
} else {
|
} else {
|
||||||
if inGap {
|
if inGap {
|
||||||
H0[off] = max(prevH0+scoreGapExtension, 0)
|
H0[off] = util.Max16(prevH0+scoreGapExtension, 0)
|
||||||
} else {
|
} else {
|
||||||
H0[off] = max(prevH0+scoreGapStart, 0)
|
H0[off] = util.Max16(prevH0+scoreGapStart, 0)
|
||||||
}
|
}
|
||||||
C0[off] = 0
|
C0[off] = 0
|
||||||
inGap = true
|
inGap = true
|
||||||
@@ -585,7 +587,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
|||||||
if b >= bonusBoundary && b > fb {
|
if b >= bonusBoundary && b > fb {
|
||||||
consecutive = 1
|
consecutive = 1
|
||||||
} else {
|
} else {
|
||||||
b = max(b, bonusConsecutive, fb)
|
b = util.Max16(b, util.Max16(bonusConsecutive, fb))
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
if s1+b < s2 {
|
if s1+b < s2 {
|
||||||
@@ -598,7 +600,7 @@ func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.
|
|||||||
Csub[off] = consecutive
|
Csub[off] = consecutive
|
||||||
|
|
||||||
inGap = s1 < s2
|
inGap = s1 < s2
|
||||||
score := max(s1, s2, 0)
|
score := util.Max16(util.Max16(s1, s2), 0)
|
||||||
if pidx == M-1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
if pidx == M-1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
||||||
maxScore, maxScorePos = score, col
|
maxScore, maxScorePos = score, col
|
||||||
}
|
}
|
||||||
@@ -682,7 +684,7 @@ func calculateScore(caseSensitive bool, normalize bool, text *util.Chars, patter
|
|||||||
if bonus >= bonusBoundary && bonus > firstBonus {
|
if bonus >= bonusBoundary && bonus > firstBonus {
|
||||||
firstBonus = bonus
|
firstBonus = bonus
|
||||||
}
|
}
|
||||||
bonus = max(bonus, firstBonus, bonusConsecutive)
|
bonus = util.Max16(util.Max16(bonus, firstBonus), bonusConsecutive)
|
||||||
}
|
}
|
||||||
if pidx == 0 {
|
if pidx == 0 {
|
||||||
score += int(bonus * bonusFirstCharMultiplier)
|
score += int(bonus * bonusFirstCharMultiplier)
|
||||||
@@ -724,7 +726,7 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
|||||||
lenRunes := text.Length()
|
lenRunes := text.Length()
|
||||||
lenPattern := len(pattern)
|
lenPattern := len(pattern)
|
||||||
|
|
||||||
for index := range lenRunes {
|
for index := 0; index < lenRunes; index++ {
|
||||||
char := text.Get(indexAt(index, lenRunes, forward))
|
char := text.Get(indexAt(index, lenRunes, forward))
|
||||||
// This is considerably faster than blindly applying strings.ToLower to the
|
// This is considerably faster than blindly applying strings.ToLower to the
|
||||||
// whole string
|
// whole string
|
||||||
@@ -765,9 +767,6 @@ func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.C
|
|||||||
char = unicode.To(unicode.LowerCase, char)
|
char = unicode.To(unicode.LowerCase, char)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
if normalize {
|
|
||||||
char = normalizeRune(char)
|
|
||||||
}
|
|
||||||
|
|
||||||
pidx_ := indexAt(pidx, lenPattern, forward)
|
pidx_ := indexAt(pidx, lenPattern, forward)
|
||||||
pchar := pattern[pidx_]
|
pchar := pattern[pidx_]
|
||||||
@@ -825,7 +824,7 @@ func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryC
|
|||||||
|
|
||||||
// For simplicity, only look at the bonus at the first character position
|
// For simplicity, only look at the bonus at the first character position
|
||||||
pidx := 0
|
pidx := 0
|
||||||
bestPos, bonus, bbonus, bestBonus := -1, int16(0), int16(0), int16(-1)
|
bestPos, bonus, bestBonus := -1, int16(0), int16(-1)
|
||||||
for index := 0; index < lenRunes; index++ {
|
for index := 0; index < lenRunes; index++ {
|
||||||
index_ := indexAt(index, lenRunes, forward)
|
index_ := indexAt(index, lenRunes, forward)
|
||||||
char := text.Get(index_)
|
char := text.Get(index_)
|
||||||
@@ -847,16 +846,7 @@ func exactMatchNaive(caseSensitive bool, normalize bool, forward bool, boundaryC
|
|||||||
bonus = bonusAt(text, index_)
|
bonus = bonusAt(text, index_)
|
||||||
}
|
}
|
||||||
if boundaryCheck {
|
if boundaryCheck {
|
||||||
if forward && pidx_ == 0 {
|
ok = bonus >= bonusBoundary
|
||||||
bbonus = bonus
|
|
||||||
} else if !forward && pidx_ == lenPattern-1 {
|
|
||||||
if index_ < lenRunes-1 {
|
|
||||||
bbonus = bonusAt(text, index_+1)
|
|
||||||
} else {
|
|
||||||
bbonus = bonusBoundaryWhite
|
|
||||||
}
|
|
||||||
}
|
|
||||||
ok = bbonus >= bonusBoundary
|
|
||||||
if ok && pidx_ == 0 {
|
if ok && pidx_ == 0 {
|
||||||
ok = index_ == 0 || charClassOf(text.Get(index_-1)) <= charDelimiter
|
ok = index_ == 0 || charClassOf(text.Get(index_-1)) <= charDelimiter
|
||||||
}
|
}
|
||||||
|
|||||||
+1
-19
@@ -57,15 +57,6 @@ func TestFuzzyMatch(t *testing.T) {
|
|||||||
scoreMatch*4+int(bonusBoundaryDelimiter)*bonusFirstCharMultiplier+int(bonusBoundaryDelimiter)*3)
|
scoreMatch*4+int(bonusBoundaryDelimiter)*bonusFirstCharMultiplier+int(bonusBoundaryDelimiter)*3)
|
||||||
assertMatch(t, fn, false, forward, "/.oh-my-zsh/cache", "zshc", 8, 13,
|
assertMatch(t, fn, false, forward, "/.oh-my-zsh/cache", "zshc", 8, 13,
|
||||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*2+scoreGapStart+int(bonusBoundaryDelimiter))
|
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*2+scoreGapStart+int(bonusBoundaryDelimiter))
|
||||||
// Non-word character at start of input is treated as a strong boundary
|
|
||||||
assertMatch(t, fn, false, forward, ".vimrc", ".vimrc", 0, 6,
|
|
||||||
scoreMatch*6+int(bonusBoundaryWhite)*(bonusFirstCharMultiplier+5))
|
|
||||||
// Non-word character right after a delimiter inherits the delimiter boundary
|
|
||||||
assertMatch(t, fn, false, forward, "/.vimrc", ".vimrc", 1, 7,
|
|
||||||
scoreMatch*6+int(bonusBoundaryDelimiter)*(bonusFirstCharMultiplier+5))
|
|
||||||
// Non-word character in the middle of a word stays at bonusNonWord
|
|
||||||
assertMatch(t, fn, false, forward, "a.vimrc", ".vimrc", 1, 7,
|
|
||||||
scoreMatch*6+bonusBoundary*(bonusFirstCharMultiplier+5))
|
|
||||||
assertMatch(t, fn, false, forward, "ab0123 456", "12356", 3, 10,
|
assertMatch(t, fn, false, forward, "ab0123 456", "12356", 3, 10,
|
||||||
scoreMatch*5+bonusConsecutive*3+scoreGapStart+scoreGapExtension)
|
scoreMatch*5+bonusConsecutive*3+scoreGapStart+scoreGapExtension)
|
||||||
assertMatch(t, fn, false, forward, "abc123 456", "12356", 3, 10,
|
assertMatch(t, fn, false, forward, "abc123 456", "12356", 3, 10,
|
||||||
@@ -95,7 +86,7 @@ func TestFuzzyMatch(t *testing.T) {
|
|||||||
scoreGapStart*2+scoreGapExtension*2)
|
scoreGapStart*2+scoreGapExtension*2)
|
||||||
assertMatch(t, fn, true, forward, "FooBar Baz", "FooB", 0, 4,
|
assertMatch(t, fn, true, forward, "FooBar Baz", "FooB", 0, 4,
|
||||||
scoreMatch*4+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite)*2+
|
scoreMatch*4+int(bonusBoundaryWhite)*bonusFirstCharMultiplier+int(bonusBoundaryWhite)*2+
|
||||||
max(bonusCamel123, int(bonusBoundaryWhite)))
|
util.Max(bonusCamel123, int(bonusBoundaryWhite)))
|
||||||
|
|
||||||
// Consecutive bonus updated
|
// Consecutive bonus updated
|
||||||
assertMatch(t, fn, true, forward, "foo-bar", "o-ba", 2, 6,
|
assertMatch(t, fn, true, forward, "foo-bar", "o-ba", 2, 6,
|
||||||
@@ -209,12 +200,3 @@ func TestLongString(t *testing.T) {
|
|||||||
bytes[math.MaxUint16] = 'z'
|
bytes[math.MaxUint16] = 'z'
|
||||||
assertMatch(t, FuzzyMatchV2, true, true, string(bytes), "zx", math.MaxUint16, math.MaxUint16+2, scoreMatch*2+bonusConsecutive)
|
assertMatch(t, FuzzyMatchV2, true, true, string(bytes), "zx", math.MaxUint16, math.MaxUint16+2, scoreMatch*2+bonusConsecutive)
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestLongStringWithNormalize(t *testing.T) {
|
|
||||||
bytes := make([]byte, 30000)
|
|
||||||
for i := range bytes {
|
|
||||||
bytes[i] = 'x'
|
|
||||||
}
|
|
||||||
unicodeString := string(bytes) + " Minímal example"
|
|
||||||
assertMatch2(t, FuzzyMatchV1, false, true, false, unicodeString, "minim", 30001, 30006, 140)
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -1,24 +0,0 @@
|
|||||||
//go:build amd64
|
|
||||||
|
|
||||||
package algo
|
|
||||||
|
|
||||||
var _useAVX2 bool
|
|
||||||
|
|
||||||
func init() {
|
|
||||||
_useAVX2 = cpuHasAVX2()
|
|
||||||
}
|
|
||||||
|
|
||||||
//go:noescape
|
|
||||||
func cpuHasAVX2() bool
|
|
||||||
|
|
||||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present. Uses AVX2 when available, SSE2 otherwise.
|
|
||||||
//
|
|
||||||
//go:noescape
|
|
||||||
func IndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
|
|
||||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present. Uses AVX2 when available, SSE2 otherwise.
|
|
||||||
//
|
|
||||||
//go:noescape
|
|
||||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
@@ -1,377 +0,0 @@
|
|||||||
#include "textflag.h"
|
|
||||||
|
|
||||||
// func cpuHasAVX2() bool
|
|
||||||
//
|
|
||||||
// Checks CPUID and XGETBV for AVX2 + OS YMM support.
|
|
||||||
TEXT ·cpuHasAVX2(SB),NOSPLIT,$0-1
|
|
||||||
MOVQ BX, R8 // save BX (callee-saved, clobbered by CPUID)
|
|
||||||
|
|
||||||
// Check max CPUID leaf >= 7
|
|
||||||
MOVL $0, AX
|
|
||||||
CPUID
|
|
||||||
CMPL AX, $7
|
|
||||||
JL cpuid_no
|
|
||||||
|
|
||||||
// Check OSXSAVE (CPUID.1:ECX bit 27)
|
|
||||||
MOVL $1, AX
|
|
||||||
CPUID
|
|
||||||
TESTL $(1<<27), CX
|
|
||||||
JZ cpuid_no
|
|
||||||
|
|
||||||
// Check AVX2 (CPUID.7.0:EBX bit 5)
|
|
||||||
MOVL $7, AX
|
|
||||||
MOVL $0, CX
|
|
||||||
CPUID
|
|
||||||
TESTL $(1<<5), BX
|
|
||||||
JZ cpuid_no
|
|
||||||
|
|
||||||
// Check OS YMM state support via XGETBV
|
|
||||||
MOVL $0, CX
|
|
||||||
BYTE $0x0F; BYTE $0x01; BYTE $0xD0 // XGETBV → EDX:EAX
|
|
||||||
ANDL $6, AX // bits 1 (XMM) and 2 (YMM)
|
|
||||||
CMPL AX, $6
|
|
||||||
JNE cpuid_no
|
|
||||||
|
|
||||||
MOVQ R8, BX // restore BX
|
|
||||||
MOVB $1, ret+0(FP)
|
|
||||||
RET
|
|
||||||
|
|
||||||
cpuid_no:
|
|
||||||
MOVQ R8, BX
|
|
||||||
MOVB $0, ret+0(FP)
|
|
||||||
RET
|
|
||||||
|
|
||||||
// func IndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
//
|
|
||||||
// Returns the index of the first occurrence of b1 or b2 in s, or -1.
|
|
||||||
// Uses AVX2 (32 bytes/iter) when available, SSE2 (16 bytes/iter) otherwise.
|
|
||||||
TEXT ·IndexByteTwo(SB),NOSPLIT,$0-40
|
|
||||||
MOVQ s_base+0(FP), SI
|
|
||||||
MOVQ s_len+8(FP), BX
|
|
||||||
MOVBLZX b1+24(FP), AX
|
|
||||||
MOVBLZX b2+25(FP), CX
|
|
||||||
LEAQ ret+32(FP), R8
|
|
||||||
|
|
||||||
TESTQ BX, BX
|
|
||||||
JEQ fwd_failure
|
|
||||||
|
|
||||||
// Try AVX2 for inputs >= 32 bytes
|
|
||||||
CMPQ BX, $32
|
|
||||||
JLT fwd_sse2
|
|
||||||
CMPB ·_useAVX2(SB), $1
|
|
||||||
JNE fwd_sse2
|
|
||||||
|
|
||||||
// ====== AVX2 forward search ======
|
|
||||||
MOVD AX, X0
|
|
||||||
VPBROADCASTB X0, Y0 // Y0 = splat(b1)
|
|
||||||
MOVD CX, X1
|
|
||||||
VPBROADCASTB X1, Y1 // Y1 = splat(b2)
|
|
||||||
|
|
||||||
MOVQ SI, DI
|
|
||||||
LEAQ -32(SI)(BX*1), AX // AX = last valid 32-byte chunk
|
|
||||||
JMP fwd_avx2_entry
|
|
||||||
|
|
||||||
fwd_avx2_loop:
|
|
||||||
VMOVDQU (DI), Y2
|
|
||||||
VPCMPEQB Y0, Y2, Y3
|
|
||||||
VPCMPEQB Y1, Y2, Y4
|
|
||||||
VPOR Y3, Y4, Y3
|
|
||||||
VPMOVMSKB Y3, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JNZ fwd_avx2_success
|
|
||||||
ADDQ $32, DI
|
|
||||||
|
|
||||||
fwd_avx2_entry:
|
|
||||||
CMPQ DI, AX
|
|
||||||
JB fwd_avx2_loop
|
|
||||||
|
|
||||||
// Last 32-byte chunk (may overlap with previous)
|
|
||||||
MOVQ AX, DI
|
|
||||||
VMOVDQU (AX), Y2
|
|
||||||
VPCMPEQB Y0, Y2, Y3
|
|
||||||
VPCMPEQB Y1, Y2, Y4
|
|
||||||
VPOR Y3, Y4, Y3
|
|
||||||
VPMOVMSKB Y3, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JNZ fwd_avx2_success
|
|
||||||
|
|
||||||
MOVQ $-1, (R8)
|
|
||||||
VZEROUPPER
|
|
||||||
RET
|
|
||||||
|
|
||||||
fwd_avx2_success:
|
|
||||||
SUBQ SI, DI
|
|
||||||
ADDQ DX, DI
|
|
||||||
MOVQ DI, (R8)
|
|
||||||
VZEROUPPER
|
|
||||||
RET
|
|
||||||
|
|
||||||
// ====== SSE2 forward search (< 32 bytes or no AVX2) ======
|
|
||||||
|
|
||||||
fwd_sse2:
|
|
||||||
// Broadcast b1 into X0
|
|
||||||
MOVD AX, X0
|
|
||||||
PUNPCKLBW X0, X0
|
|
||||||
PUNPCKLBW X0, X0
|
|
||||||
PSHUFL $0, X0, X0
|
|
||||||
|
|
||||||
// Broadcast b2 into X4
|
|
||||||
MOVD CX, X4
|
|
||||||
PUNPCKLBW X4, X4
|
|
||||||
PUNPCKLBW X4, X4
|
|
||||||
PSHUFL $0, X4, X4
|
|
||||||
|
|
||||||
CMPQ BX, $16
|
|
||||||
JLT fwd_small
|
|
||||||
|
|
||||||
MOVQ SI, DI
|
|
||||||
LEAQ -16(SI)(BX*1), AX
|
|
||||||
JMP fwd_sseloopentry
|
|
||||||
|
|
||||||
fwd_sseloop:
|
|
||||||
MOVOU (DI), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JNZ fwd_ssesuccess
|
|
||||||
ADDQ $16, DI
|
|
||||||
|
|
||||||
fwd_sseloopentry:
|
|
||||||
CMPQ DI, AX
|
|
||||||
JB fwd_sseloop
|
|
||||||
|
|
||||||
// Search the last 16-byte chunk (may overlap)
|
|
||||||
MOVQ AX, DI
|
|
||||||
MOVOU (AX), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JNZ fwd_ssesuccess
|
|
||||||
|
|
||||||
fwd_failure:
|
|
||||||
MOVQ $-1, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
fwd_ssesuccess:
|
|
||||||
SUBQ SI, DI
|
|
||||||
ADDQ DX, DI
|
|
||||||
MOVQ DI, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
fwd_small:
|
|
||||||
// Check if loading 16 bytes from SI would cross a page boundary
|
|
||||||
LEAQ 16(SI), AX
|
|
||||||
TESTW $0xff0, AX
|
|
||||||
JEQ fwd_endofpage
|
|
||||||
|
|
||||||
MOVOU (SI), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JZ fwd_failure
|
|
||||||
CMPL DX, BX
|
|
||||||
JAE fwd_failure
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
fwd_endofpage:
|
|
||||||
MOVOU -16(SI)(BX*1), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
MOVL BX, CX
|
|
||||||
SHLL CX, DX
|
|
||||||
SHRL $16, DX
|
|
||||||
BSFL DX, DX
|
|
||||||
JZ fwd_failure
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
// func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
//
|
|
||||||
// Returns the index of the last occurrence of b1 or b2 in s, or -1.
|
|
||||||
// Uses AVX2 (32 bytes/iter) when available, SSE2 (16 bytes/iter) otherwise.
|
|
||||||
TEXT ·lastIndexByteTwo(SB),NOSPLIT,$0-40
|
|
||||||
MOVQ s_base+0(FP), SI
|
|
||||||
MOVQ s_len+8(FP), BX
|
|
||||||
MOVBLZX b1+24(FP), AX
|
|
||||||
MOVBLZX b2+25(FP), CX
|
|
||||||
LEAQ ret+32(FP), R8
|
|
||||||
|
|
||||||
TESTQ BX, BX
|
|
||||||
JEQ back_failure
|
|
||||||
|
|
||||||
// Try AVX2 for inputs >= 32 bytes
|
|
||||||
CMPQ BX, $32
|
|
||||||
JLT back_sse2
|
|
||||||
CMPB ·_useAVX2(SB), $1
|
|
||||||
JNE back_sse2
|
|
||||||
|
|
||||||
// ====== AVX2 backward search ======
|
|
||||||
MOVD AX, X0
|
|
||||||
VPBROADCASTB X0, Y0
|
|
||||||
MOVD CX, X1
|
|
||||||
VPBROADCASTB X1, Y1
|
|
||||||
|
|
||||||
// DI = start of last 32-byte chunk
|
|
||||||
LEAQ -32(SI)(BX*1), DI
|
|
||||||
|
|
||||||
back_avx2_loop:
|
|
||||||
CMPQ DI, SI
|
|
||||||
JBE back_avx2_first
|
|
||||||
|
|
||||||
VMOVDQU (DI), Y2
|
|
||||||
VPCMPEQB Y0, Y2, Y3
|
|
||||||
VPCMPEQB Y1, Y2, Y4
|
|
||||||
VPOR Y3, Y4, Y3
|
|
||||||
VPMOVMSKB Y3, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JNZ back_avx2_success
|
|
||||||
SUBQ $32, DI
|
|
||||||
JMP back_avx2_loop
|
|
||||||
|
|
||||||
back_avx2_first:
|
|
||||||
// First 32 bytes (DI <= SI, load from SI)
|
|
||||||
VMOVDQU (SI), Y2
|
|
||||||
VPCMPEQB Y0, Y2, Y3
|
|
||||||
VPCMPEQB Y1, Y2, Y4
|
|
||||||
VPOR Y3, Y4, Y3
|
|
||||||
VPMOVMSKB Y3, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JNZ back_avx2_firstsuccess
|
|
||||||
|
|
||||||
MOVQ $-1, (R8)
|
|
||||||
VZEROUPPER
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_avx2_success:
|
|
||||||
SUBQ SI, DI
|
|
||||||
ADDQ DX, DI
|
|
||||||
MOVQ DI, (R8)
|
|
||||||
VZEROUPPER
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_avx2_firstsuccess:
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
VZEROUPPER
|
|
||||||
RET
|
|
||||||
|
|
||||||
// ====== SSE2 backward search (< 32 bytes or no AVX2) ======
|
|
||||||
|
|
||||||
back_sse2:
|
|
||||||
// Broadcast b1 into X0
|
|
||||||
MOVD AX, X0
|
|
||||||
PUNPCKLBW X0, X0
|
|
||||||
PUNPCKLBW X0, X0
|
|
||||||
PSHUFL $0, X0, X0
|
|
||||||
|
|
||||||
// Broadcast b2 into X4
|
|
||||||
MOVD CX, X4
|
|
||||||
PUNPCKLBW X4, X4
|
|
||||||
PUNPCKLBW X4, X4
|
|
||||||
PSHUFL $0, X4, X4
|
|
||||||
|
|
||||||
CMPQ BX, $16
|
|
||||||
JLT back_small
|
|
||||||
|
|
||||||
// DI = start of last 16-byte chunk
|
|
||||||
LEAQ -16(SI)(BX*1), DI
|
|
||||||
|
|
||||||
back_sseloop:
|
|
||||||
CMPQ DI, SI
|
|
||||||
JBE back_ssefirst
|
|
||||||
|
|
||||||
MOVOU (DI), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JNZ back_ssesuccess
|
|
||||||
SUBQ $16, DI
|
|
||||||
JMP back_sseloop
|
|
||||||
|
|
||||||
back_ssefirst:
|
|
||||||
// First 16 bytes (DI <= SI, load from SI)
|
|
||||||
MOVOU (SI), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JNZ back_ssefirstsuccess
|
|
||||||
|
|
||||||
back_failure:
|
|
||||||
MOVQ $-1, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_ssesuccess:
|
|
||||||
SUBQ SI, DI
|
|
||||||
ADDQ DX, DI
|
|
||||||
MOVQ DI, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_ssefirstsuccess:
|
|
||||||
// DX = byte offset from base
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_small:
|
|
||||||
// Check page boundary
|
|
||||||
LEAQ 16(SI), AX
|
|
||||||
TESTW $0xff0, AX
|
|
||||||
JEQ back_endofpage
|
|
||||||
|
|
||||||
MOVOU (SI), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
// Mask to first BX bytes: keep bits 0..BX-1
|
|
||||||
MOVL $1, AX
|
|
||||||
MOVL BX, CX
|
|
||||||
SHLL CX, AX
|
|
||||||
DECL AX
|
|
||||||
ANDL AX, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JZ back_failure
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
back_endofpage:
|
|
||||||
// Load 16 bytes ending at base+n
|
|
||||||
MOVOU -16(SI)(BX*1), X1
|
|
||||||
MOVOU X1, X2
|
|
||||||
PCMPEQB X0, X1
|
|
||||||
PCMPEQB X4, X2
|
|
||||||
POR X2, X1
|
|
||||||
PMOVMSKB X1, DX
|
|
||||||
// Bits correspond to bytes [base+n-16, base+n).
|
|
||||||
// We want original bytes [0, n), which are bits [16-n, 16).
|
|
||||||
// Mask: keep bits (16-n) through 15.
|
|
||||||
MOVL $16, CX
|
|
||||||
SUBL BX, CX
|
|
||||||
SHRL CX, DX
|
|
||||||
SHLL CX, DX
|
|
||||||
BSRL DX, DX
|
|
||||||
JZ back_failure
|
|
||||||
// DX is the bit position in the loaded chunk.
|
|
||||||
// Original byte index = DX - (16 - n) = DX + n - 16
|
|
||||||
ADDL BX, DX
|
|
||||||
SUBL $16, DX
|
|
||||||
MOVQ DX, (R8)
|
|
||||||
RET
|
|
||||||
@@ -1,17 +0,0 @@
|
|||||||
//go:build arm64
|
|
||||||
|
|
||||||
package algo
|
|
||||||
|
|
||||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present. Implemented in assembly using ARM64 NEON
|
|
||||||
// to search for both bytes in a single pass.
|
|
||||||
//
|
|
||||||
//go:noescape
|
|
||||||
func IndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
|
|
||||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present. Implemented in assembly using ARM64 NEON,
|
|
||||||
// scanning backward.
|
|
||||||
//
|
|
||||||
//go:noescape
|
|
||||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
@@ -1,249 +0,0 @@
|
|||||||
#include "textflag.h"
|
|
||||||
|
|
||||||
// func IndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
//
|
|
||||||
// Returns the index of the first occurrence of b1 or b2 in s, or -1.
|
|
||||||
// Uses ARM64 NEON to search for both bytes in a single pass over the data.
|
|
||||||
// Adapted from Go's internal/bytealg/indexbyte_arm64.s (single-byte version).
|
|
||||||
TEXT ·IndexByteTwo(SB),NOSPLIT,$0-40
|
|
||||||
MOVD s_base+0(FP), R0
|
|
||||||
MOVD s_len+8(FP), R2
|
|
||||||
MOVBU b1+24(FP), R1
|
|
||||||
MOVBU b2+25(FP), R7
|
|
||||||
MOVD $ret+32(FP), R8
|
|
||||||
|
|
||||||
// Core algorithm:
|
|
||||||
// For each 32-byte chunk we calculate a 64-bit syndrome value,
|
|
||||||
// with two bits per byte. We compare against both b1 and b2,
|
|
||||||
// OR the results, then use the same syndrome extraction as
|
|
||||||
// Go's IndexByte.
|
|
||||||
|
|
||||||
CBZ R2, fail
|
|
||||||
MOVD R0, R11
|
|
||||||
// Magic constant 0x40100401 allows us to identify which lane matches.
|
|
||||||
// Each byte in the group of 4 gets a distinct bit: 1, 4, 16, 64.
|
|
||||||
MOVD $0x40100401, R5
|
|
||||||
VMOV R1, V0.B16 // V0 = splat(b1)
|
|
||||||
VMOV R7, V7.B16 // V7 = splat(b2)
|
|
||||||
// Work with aligned 32-byte chunks
|
|
||||||
BIC $0x1f, R0, R3
|
|
||||||
VMOV R5, V5.S4
|
|
||||||
ANDS $0x1f, R0, R9
|
|
||||||
AND $0x1f, R2, R10
|
|
||||||
BEQ loop
|
|
||||||
|
|
||||||
// Input string is not 32-byte aligned. Process the first
|
|
||||||
// aligned 32-byte block and mask off bytes before our start.
|
|
||||||
VLD1.P (R3), [V1.B16, V2.B16]
|
|
||||||
SUB $0x20, R9, R4
|
|
||||||
ADDS R4, R2, R2
|
|
||||||
// Compare against both needles
|
|
||||||
VCMEQ V0.B16, V1.B16, V3.B16 // b1 vs first 16 bytes
|
|
||||||
VCMEQ V7.B16, V1.B16, V8.B16 // b2 vs first 16 bytes
|
|
||||||
VORR V8.B16, V3.B16, V3.B16 // combine
|
|
||||||
VCMEQ V0.B16, V2.B16, V4.B16 // b1 vs second 16 bytes
|
|
||||||
VCMEQ V7.B16, V2.B16, V9.B16 // b2 vs second 16 bytes
|
|
||||||
VORR V9.B16, V4.B16, V4.B16 // combine
|
|
||||||
// Build syndrome
|
|
||||||
VAND V5.B16, V3.B16, V3.B16
|
|
||||||
VAND V5.B16, V4.B16, V4.B16
|
|
||||||
VADDP V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.B16, V6.B16, V6.B16
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
// Clear the irrelevant lower bits
|
|
||||||
LSL $1, R9, R4
|
|
||||||
LSR R4, R6, R6
|
|
||||||
LSL R4, R6, R6
|
|
||||||
// The first block can also be the last
|
|
||||||
BLS masklast
|
|
||||||
// Have we found something already?
|
|
||||||
CBNZ R6, tail
|
|
||||||
|
|
||||||
loop:
|
|
||||||
VLD1.P (R3), [V1.B16, V2.B16]
|
|
||||||
SUBS $0x20, R2, R2
|
|
||||||
// Compare against both needles, OR results
|
|
||||||
VCMEQ V0.B16, V1.B16, V3.B16
|
|
||||||
VCMEQ V7.B16, V1.B16, V8.B16
|
|
||||||
VORR V8.B16, V3.B16, V3.B16
|
|
||||||
VCMEQ V0.B16, V2.B16, V4.B16
|
|
||||||
VCMEQ V7.B16, V2.B16, V9.B16
|
|
||||||
VORR V9.B16, V4.B16, V4.B16
|
|
||||||
// If we're out of data we finish regardless of the result
|
|
||||||
BLS end
|
|
||||||
// Fast check: OR both halves and check for any match
|
|
||||||
VORR V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.D2, V6.D2, V6.D2
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
CBZ R6, loop
|
|
||||||
|
|
||||||
end:
|
|
||||||
// Found something or out of data, build full syndrome
|
|
||||||
VAND V5.B16, V3.B16, V3.B16
|
|
||||||
VAND V5.B16, V4.B16, V4.B16
|
|
||||||
VADDP V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.B16, V6.B16, V6.B16
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
// Only mask for the last block
|
|
||||||
BHS tail
|
|
||||||
|
|
||||||
masklast:
|
|
||||||
// Clear irrelevant upper bits
|
|
||||||
ADD R9, R10, R4
|
|
||||||
AND $0x1f, R4, R4
|
|
||||||
SUB $0x20, R4, R4
|
|
||||||
NEG R4<<1, R4
|
|
||||||
LSL R4, R6, R6
|
|
||||||
LSR R4, R6, R6
|
|
||||||
|
|
||||||
tail:
|
|
||||||
CBZ R6, fail
|
|
||||||
RBIT R6, R6
|
|
||||||
SUB $0x20, R3, R3
|
|
||||||
CLZ R6, R6
|
|
||||||
ADD R6>>1, R3, R0
|
|
||||||
SUB R11, R0, R0
|
|
||||||
MOVD R0, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
fail:
|
|
||||||
MOVD $-1, R0
|
|
||||||
MOVD R0, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
// func lastIndexByteTwo(s []byte, b1, b2 byte) int
|
|
||||||
//
|
|
||||||
// Returns the index of the last occurrence of b1 or b2 in s, or -1.
|
|
||||||
// Scans backward using ARM64 NEON.
|
|
||||||
TEXT ·lastIndexByteTwo(SB),NOSPLIT,$0-40
|
|
||||||
MOVD s_base+0(FP), R0
|
|
||||||
MOVD s_len+8(FP), R2
|
|
||||||
MOVBU b1+24(FP), R1
|
|
||||||
MOVBU b2+25(FP), R7
|
|
||||||
MOVD $ret+32(FP), R8
|
|
||||||
|
|
||||||
CBZ R2, lfail
|
|
||||||
MOVD R0, R11 // save base
|
|
||||||
ADD R0, R2, R12 // R12 = end = base + len
|
|
||||||
MOVD $0x40100401, R5
|
|
||||||
VMOV R1, V0.B16 // V0 = splat(b1)
|
|
||||||
VMOV R7, V7.B16 // V7 = splat(b2)
|
|
||||||
VMOV R5, V5.S4
|
|
||||||
|
|
||||||
// Align: find the aligned block containing the last byte
|
|
||||||
SUB $1, R12, R3
|
|
||||||
BIC $0x1f, R3, R3 // R3 = start of aligned block containing last byte
|
|
||||||
|
|
||||||
// --- Process tail block ---
|
|
||||||
VLD1 (R3), [V1.B16, V2.B16]
|
|
||||||
VCMEQ V0.B16, V1.B16, V3.B16
|
|
||||||
VCMEQ V7.B16, V1.B16, V8.B16
|
|
||||||
VORR V8.B16, V3.B16, V3.B16
|
|
||||||
VCMEQ V0.B16, V2.B16, V4.B16
|
|
||||||
VCMEQ V7.B16, V2.B16, V9.B16
|
|
||||||
VORR V9.B16, V4.B16, V4.B16
|
|
||||||
VAND V5.B16, V3.B16, V3.B16
|
|
||||||
VAND V5.B16, V4.B16, V4.B16
|
|
||||||
VADDP V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.B16, V6.B16, V6.B16
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
|
|
||||||
// Mask upper bits (bytes past end of slice)
|
|
||||||
// tail_bytes = end - R3 (1..32)
|
|
||||||
SUB R3, R12, R10 // R10 = tail_bytes
|
|
||||||
MOVD $64, R4
|
|
||||||
SUB R10<<1, R4, R4 // R4 = 64 - 2*tail_bytes
|
|
||||||
LSL R4, R6, R6
|
|
||||||
LSR R4, R6, R6
|
|
||||||
|
|
||||||
// Is this also the head block?
|
|
||||||
CMP R11, R3 // R3 - R11
|
|
||||||
BLO lmaskfirst // R3 < base: head+tail in same block
|
|
||||||
BEQ ltailonly // R3 == base: single aligned block
|
|
||||||
|
|
||||||
// R3 > base: more blocks before this one
|
|
||||||
CBNZ R6, llast
|
|
||||||
B lbacksetup
|
|
||||||
|
|
||||||
ltailonly:
|
|
||||||
// Single block, already masked upper bits
|
|
||||||
CBNZ R6, llast
|
|
||||||
B lfail
|
|
||||||
|
|
||||||
lmaskfirst:
|
|
||||||
// Mask lower bits (bytes before start of slice)
|
|
||||||
SUB R3, R11, R4 // R4 = base - R3
|
|
||||||
LSL $1, R4, R4
|
|
||||||
LSR R4, R6, R6
|
|
||||||
LSL R4, R6, R6
|
|
||||||
CBNZ R6, llast
|
|
||||||
B lfail
|
|
||||||
|
|
||||||
lbacksetup:
|
|
||||||
SUB $0x20, R3
|
|
||||||
|
|
||||||
lbackloop:
|
|
||||||
VLD1 (R3), [V1.B16, V2.B16]
|
|
||||||
VCMEQ V0.B16, V1.B16, V3.B16
|
|
||||||
VCMEQ V7.B16, V1.B16, V8.B16
|
|
||||||
VORR V8.B16, V3.B16, V3.B16
|
|
||||||
VCMEQ V0.B16, V2.B16, V4.B16
|
|
||||||
VCMEQ V7.B16, V2.B16, V9.B16
|
|
||||||
VORR V9.B16, V4.B16, V4.B16
|
|
||||||
// Quick check: any match in this block?
|
|
||||||
VORR V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.D2, V6.D2, V6.D2
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
|
|
||||||
// Is this a head block? (R3 < base)
|
|
||||||
CMP R11, R3
|
|
||||||
BLO lheadblock
|
|
||||||
|
|
||||||
// Full block (R3 >= base)
|
|
||||||
CBNZ R6, lbackfound
|
|
||||||
// More blocks?
|
|
||||||
BEQ lfail // R3 == base, no more
|
|
||||||
SUB $0x20, R3
|
|
||||||
B lbackloop
|
|
||||||
|
|
||||||
lbackfound:
|
|
||||||
// Build full syndrome
|
|
||||||
VAND V5.B16, V3.B16, V3.B16
|
|
||||||
VAND V5.B16, V4.B16, V4.B16
|
|
||||||
VADDP V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.B16, V6.B16, V6.B16
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
B llast
|
|
||||||
|
|
||||||
lheadblock:
|
|
||||||
// R3 < base. Build full syndrome if quick check had a match.
|
|
||||||
CBZ R6, lfail
|
|
||||||
VAND V5.B16, V3.B16, V3.B16
|
|
||||||
VAND V5.B16, V4.B16, V4.B16
|
|
||||||
VADDP V4.B16, V3.B16, V6.B16
|
|
||||||
VADDP V6.B16, V6.B16, V6.B16
|
|
||||||
VMOV V6.D[0], R6
|
|
||||||
// Mask lower bits
|
|
||||||
SUB R3, R11, R4 // R4 = base - R3
|
|
||||||
LSL $1, R4, R4
|
|
||||||
LSR R4, R6, R6
|
|
||||||
LSL R4, R6, R6
|
|
||||||
CBZ R6, lfail
|
|
||||||
|
|
||||||
llast:
|
|
||||||
// Find last match: highest set bit in syndrome
|
|
||||||
// Syndrome has bit 2i set for matching byte i.
|
|
||||||
// CLZ gives leading zeros; byte_offset = (63 - CLZ) / 2.
|
|
||||||
CLZ R6, R6
|
|
||||||
MOVD $63, R4
|
|
||||||
SUB R6, R4, R6 // R6 = 63 - CLZ = bit position
|
|
||||||
LSR $1, R6 // R6 = byte offset within block
|
|
||||||
ADD R3, R6, R0 // R0 = absolute address
|
|
||||||
SUB R11, R0, R0 // R0 = slice index
|
|
||||||
MOVD R0, (R8)
|
|
||||||
RET
|
|
||||||
|
|
||||||
lfail:
|
|
||||||
MOVD $-1, R0
|
|
||||||
MOVD R0, (R8)
|
|
||||||
RET
|
|
||||||
@@ -1,33 +0,0 @@
|
|||||||
//go:build !arm64 && !amd64
|
|
||||||
|
|
||||||
package algo
|
|
||||||
|
|
||||||
import "bytes"
|
|
||||||
|
|
||||||
// indexByteTwo returns the index of the first occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present.
|
|
||||||
func IndexByteTwo(s []byte, b1, b2 byte) int {
|
|
||||||
i1 := bytes.IndexByte(s, b1)
|
|
||||||
if i1 == 0 {
|
|
||||||
return 0
|
|
||||||
}
|
|
||||||
scope := s
|
|
||||||
if i1 > 0 {
|
|
||||||
scope = s[:i1]
|
|
||||||
}
|
|
||||||
if i2 := bytes.IndexByte(scope, b2); i2 >= 0 {
|
|
||||||
return i2
|
|
||||||
}
|
|
||||||
return i1
|
|
||||||
}
|
|
||||||
|
|
||||||
// lastIndexByteTwo returns the index of the last occurrence of b1 or b2 in s,
|
|
||||||
// or -1 if neither is present.
|
|
||||||
func lastIndexByteTwo(s []byte, b1, b2 byte) int {
|
|
||||||
for i := len(s) - 1; i >= 0; i-- {
|
|
||||||
if s[i] == b1 || s[i] == b2 {
|
|
||||||
return i
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return -1
|
|
||||||
}
|
|
||||||
@@ -1,259 +0,0 @@
|
|||||||
package algo
|
|
||||||
|
|
||||||
import (
|
|
||||||
"bytes"
|
|
||||||
"testing"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestIndexByteTwo(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
s string
|
|
||||||
b1 byte
|
|
||||||
b2 byte
|
|
||||||
want int
|
|
||||||
}{
|
|
||||||
{"empty", "", 'a', 'b', -1},
|
|
||||||
{"single_b1", "a", 'a', 'b', 0},
|
|
||||||
{"single_b2", "b", 'a', 'b', 0},
|
|
||||||
{"single_none", "c", 'a', 'b', -1},
|
|
||||||
{"b1_first", "xaxb", 'a', 'b', 1},
|
|
||||||
{"b2_first", "xbxa", 'a', 'b', 1},
|
|
||||||
{"same_byte", "xxa", 'a', 'a', 2},
|
|
||||||
{"at_end", "xxxxa", 'a', 'b', 4},
|
|
||||||
{"not_found", "xxxxxxxx", 'a', 'b', -1},
|
|
||||||
{"long_b1_at_3000", string(make([]byte, 3000)) + "a" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
|
||||||
{"long_b2_at_3000", string(make([]byte, 3000)) + "b" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
got := IndexByteTwo([]byte(tt.s), tt.b1, tt.b2)
|
|
||||||
if got != tt.want {
|
|
||||||
t.Errorf("IndexByteTwo(%q, %c, %c) = %d, want %d", tt.s[:min(len(tt.s), 40)], tt.b1, tt.b2, got, tt.want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
// Exhaustive test: compare against loop reference for various lengths,
|
|
||||||
// including sizes around SIMD block boundaries (16, 32, 64).
|
|
||||||
for n := 0; n <= 256; n++ {
|
|
||||||
data := make([]byte, n)
|
|
||||||
for i := range data {
|
|
||||||
data[i] = byte('c' + (i % 20))
|
|
||||||
}
|
|
||||||
// Test with match at every position
|
|
||||||
for pos := 0; pos < n; pos++ {
|
|
||||||
for _, b := range []byte{'A', 'B'} {
|
|
||||||
data[pos] = b
|
|
||||||
got := IndexByteTwo(data, 'A', 'B')
|
|
||||||
want := loopIndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != want {
|
|
||||||
t.Fatalf("IndexByteTwo(len=%d, match=%c@%d) = %d, want %d", n, b, pos, got, want)
|
|
||||||
}
|
|
||||||
data[pos] = byte('c' + (pos % 20))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// Test with no match
|
|
||||||
got := IndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != -1 {
|
|
||||||
t.Fatalf("IndexByteTwo(len=%d, no match) = %d, want -1", n, got)
|
|
||||||
}
|
|
||||||
// Test with both bytes present
|
|
||||||
if n >= 2 {
|
|
||||||
data[n/3] = 'A'
|
|
||||||
data[n*2/3] = 'B'
|
|
||||||
got := IndexByteTwo(data, 'A', 'B')
|
|
||||||
want := loopIndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != want {
|
|
||||||
t.Fatalf("IndexByteTwo(len=%d, both@%d,%d) = %d, want %d", n, n/3, n*2/3, got, want)
|
|
||||||
}
|
|
||||||
data[n/3] = byte('c' + ((n / 3) % 20))
|
|
||||||
data[n*2/3] = byte('c' + ((n * 2 / 3) % 20))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestLastIndexByteTwo(t *testing.T) {
|
|
||||||
tests := []struct {
|
|
||||||
name string
|
|
||||||
s string
|
|
||||||
b1 byte
|
|
||||||
b2 byte
|
|
||||||
want int
|
|
||||||
}{
|
|
||||||
{"empty", "", 'a', 'b', -1},
|
|
||||||
{"single_b1", "a", 'a', 'b', 0},
|
|
||||||
{"single_b2", "b", 'a', 'b', 0},
|
|
||||||
{"single_none", "c", 'a', 'b', -1},
|
|
||||||
{"b1_last", "xbxa", 'a', 'b', 3},
|
|
||||||
{"b2_last", "xaxb", 'a', 'b', 3},
|
|
||||||
{"same_byte", "axx", 'a', 'a', 0},
|
|
||||||
{"at_start", "axxxx", 'a', 'b', 0},
|
|
||||||
{"both_present", "axbx", 'a', 'b', 2},
|
|
||||||
{"not_found", "xxxxxxxx", 'a', 'b', -1},
|
|
||||||
{"long_b1_at_3000", string(make([]byte, 3000)) + "a" + string(make([]byte, 1000)), 'a', 'b', 3000},
|
|
||||||
{"long_b2_at_end", string(make([]byte, 4000)) + "b", 'a', 'b', 4000},
|
|
||||||
}
|
|
||||||
|
|
||||||
for _, tt := range tests {
|
|
||||||
t.Run(tt.name, func(t *testing.T) {
|
|
||||||
got := lastIndexByteTwo([]byte(tt.s), tt.b1, tt.b2)
|
|
||||||
if got != tt.want {
|
|
||||||
t.Errorf("lastIndexByteTwo(%q, %c, %c) = %d, want %d", tt.s[:min(len(tt.s), 40)], tt.b1, tt.b2, got, tt.want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
// Exhaustive test against loop reference
|
|
||||||
for n := 0; n <= 256; n++ {
|
|
||||||
data := make([]byte, n)
|
|
||||||
for i := range data {
|
|
||||||
data[i] = byte('c' + (i % 20))
|
|
||||||
}
|
|
||||||
for pos := 0; pos < n; pos++ {
|
|
||||||
for _, b := range []byte{'A', 'B'} {
|
|
||||||
data[pos] = b
|
|
||||||
got := lastIndexByteTwo(data, 'A', 'B')
|
|
||||||
want := refLastIndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != want {
|
|
||||||
t.Fatalf("lastIndexByteTwo(len=%d, match=%c@%d) = %d, want %d", n, b, pos, got, want)
|
|
||||||
}
|
|
||||||
data[pos] = byte('c' + (pos % 20))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// No match
|
|
||||||
got := lastIndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != -1 {
|
|
||||||
t.Fatalf("lastIndexByteTwo(len=%d, no match) = %d, want -1", n, got)
|
|
||||||
}
|
|
||||||
// Both bytes present
|
|
||||||
if n >= 2 {
|
|
||||||
data[n/3] = 'A'
|
|
||||||
data[n*2/3] = 'B'
|
|
||||||
got := lastIndexByteTwo(data, 'A', 'B')
|
|
||||||
want := refLastIndexByteTwo(data, 'A', 'B')
|
|
||||||
if got != want {
|
|
||||||
t.Fatalf("lastIndexByteTwo(len=%d, both@%d,%d) = %d, want %d", n, n/3, n*2/3, got, want)
|
|
||||||
}
|
|
||||||
data[n/3] = byte('c' + ((n / 3) % 20))
|
|
||||||
data[n*2/3] = byte('c' + ((n * 2 / 3) % 20))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func FuzzIndexByteTwo(f *testing.F) {
|
|
||||||
f.Add([]byte("hello world"), byte('o'), byte('l'))
|
|
||||||
f.Add([]byte(""), byte('a'), byte('b'))
|
|
||||||
f.Add([]byte("aaa"), byte('a'), byte('a'))
|
|
||||||
f.Fuzz(func(t *testing.T, data []byte, b1, b2 byte) {
|
|
||||||
got := IndexByteTwo(data, b1, b2)
|
|
||||||
want := loopIndexByteTwo(data, b1, b2)
|
|
||||||
if got != want {
|
|
||||||
t.Errorf("IndexByteTwo(len=%d, b1=%d, b2=%d) = %d, want %d", len(data), b1, b2, got, want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
func FuzzLastIndexByteTwo(f *testing.F) {
|
|
||||||
f.Add([]byte("hello world"), byte('o'), byte('l'))
|
|
||||||
f.Add([]byte(""), byte('a'), byte('b'))
|
|
||||||
f.Add([]byte("aaa"), byte('a'), byte('a'))
|
|
||||||
f.Fuzz(func(t *testing.T, data []byte, b1, b2 byte) {
|
|
||||||
got := lastIndexByteTwo(data, b1, b2)
|
|
||||||
want := refLastIndexByteTwo(data, b1, b2)
|
|
||||||
if got != want {
|
|
||||||
t.Errorf("lastIndexByteTwo(len=%d, b1=%d, b2=%d) = %d, want %d", len(data), b1, b2, got, want)
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
// Reference implementations for correctness checking
|
|
||||||
func refIndexByteTwo(s []byte, b1, b2 byte) int {
|
|
||||||
i1 := bytes.IndexByte(s, b1)
|
|
||||||
if i1 == 0 {
|
|
||||||
return 0
|
|
||||||
}
|
|
||||||
scope := s
|
|
||||||
if i1 > 0 {
|
|
||||||
scope = s[:i1]
|
|
||||||
}
|
|
||||||
if i2 := bytes.IndexByte(scope, b2); i2 >= 0 {
|
|
||||||
return i2
|
|
||||||
}
|
|
||||||
return i1
|
|
||||||
}
|
|
||||||
|
|
||||||
func loopIndexByteTwo(s []byte, b1, b2 byte) int {
|
|
||||||
for i, b := range s {
|
|
||||||
if b == b1 || b == b2 {
|
|
||||||
return i
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return -1
|
|
||||||
}
|
|
||||||
|
|
||||||
func refLastIndexByteTwo(s []byte, b1, b2 byte) int {
|
|
||||||
for i := len(s) - 1; i >= 0; i-- {
|
|
||||||
if s[i] == b1 || s[i] == b2 {
|
|
||||||
return i
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return -1
|
|
||||||
}
|
|
||||||
|
|
||||||
func benchIndexByteTwo(b *testing.B, size int, pos int) {
|
|
||||||
data := make([]byte, size)
|
|
||||||
for i := range data {
|
|
||||||
data[i] = byte('a' + (i % 20))
|
|
||||||
}
|
|
||||||
data[pos] = 'Z'
|
|
||||||
|
|
||||||
type impl struct {
|
|
||||||
name string
|
|
||||||
fn func([]byte, byte, byte) int
|
|
||||||
}
|
|
||||||
impls := []impl{
|
|
||||||
{"asm", IndexByteTwo},
|
|
||||||
{"2xIndexByte", refIndexByteTwo},
|
|
||||||
{"loop", loopIndexByteTwo},
|
|
||||||
}
|
|
||||||
for _, im := range impls {
|
|
||||||
b.Run(im.name, func(b *testing.B) {
|
|
||||||
for i := 0; i < b.N; i++ {
|
|
||||||
im.fn(data, 'Z', 'z')
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func benchLastIndexByteTwo(b *testing.B, size int, pos int) {
|
|
||||||
data := make([]byte, size)
|
|
||||||
for i := range data {
|
|
||||||
data[i] = byte('a' + (i % 20))
|
|
||||||
}
|
|
||||||
data[pos] = 'Z'
|
|
||||||
|
|
||||||
type impl struct {
|
|
||||||
name string
|
|
||||||
fn func([]byte, byte, byte) int
|
|
||||||
}
|
|
||||||
impls := []impl{
|
|
||||||
{"asm", lastIndexByteTwo},
|
|
||||||
{"loop", refLastIndexByteTwo},
|
|
||||||
}
|
|
||||||
for _, im := range impls {
|
|
||||||
b.Run(im.name, func(b *testing.B) {
|
|
||||||
for i := 0; i < b.N; i++ {
|
|
||||||
im.fn(data, 'Z', 'z')
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func BenchmarkIndexByteTwo_10(b *testing.B) { benchIndexByteTwo(b, 10, 8) }
|
|
||||||
func BenchmarkIndexByteTwo_100(b *testing.B) { benchIndexByteTwo(b, 100, 80) }
|
|
||||||
func BenchmarkIndexByteTwo_1000(b *testing.B) { benchIndexByteTwo(b, 1000, 800) }
|
|
||||||
func BenchmarkLastIndexByteTwo_10(b *testing.B) { benchLastIndexByteTwo(b, 10, 2) }
|
|
||||||
func BenchmarkLastIndexByteTwo_100(b *testing.B) { benchLastIndexByteTwo(b, 100, 20) }
|
|
||||||
func BenchmarkLastIndexByteTwo_1000(b *testing.B) { benchLastIndexByteTwo(b, 1000, 200) }
|
|
||||||
+1
-98
@@ -473,103 +473,6 @@ var normalized = map[rune]rune{
|
|||||||
'ử': 'u',
|
'ử': 'u',
|
||||||
'ữ': 'u',
|
'ữ': 'u',
|
||||||
'ự': 'u',
|
'ự': 'u',
|
||||||
|
|
||||||
// https://en.wikipedia.org/wiki/Halfwidth_and_Fullwidth_Forms_(Unicode_block)
|
|
||||||
0xFF01: '!', // Fullwidth exclamation
|
|
||||||
0xFF02: '"', // Fullwidth quotation mark
|
|
||||||
0xFF03: '#', // Fullwidth number sign
|
|
||||||
0xFF04: '$', // Fullwidth dollar sign
|
|
||||||
0xFF05: '%', // Fullwidth percent
|
|
||||||
0xFF06: '&', // Fullwidth ampersand
|
|
||||||
0xFF07: '\'', // Fullwidth apostrophe
|
|
||||||
0xFF08: '(', // Fullwidth left parenthesis
|
|
||||||
0xFF09: ')', // Fullwidth right parenthesis
|
|
||||||
0xFF0A: '*', // Fullwidth asterisk
|
|
||||||
0xFF0B: '+', // Fullwidth plus
|
|
||||||
0xFF0C: ',', // Fullwidth comma
|
|
||||||
0xFF0D: '-', // Fullwidth hyphen-minus
|
|
||||||
0xFF0E: '.', // Fullwidth period
|
|
||||||
0xFF0F: '/', // Fullwidth slash
|
|
||||||
0xFF10: '0',
|
|
||||||
0xFF11: '1',
|
|
||||||
0xFF12: '2',
|
|
||||||
0xFF13: '3',
|
|
||||||
0xFF14: '4',
|
|
||||||
0xFF15: '5',
|
|
||||||
0xFF16: '6',
|
|
||||||
0xFF17: '7',
|
|
||||||
0xFF18: '8',
|
|
||||||
0xFF19: '9',
|
|
||||||
0xFF1A: ':', // Fullwidth colon
|
|
||||||
0xFF1B: ';', // Fullwidth semicolon
|
|
||||||
0xFF1C: '<', // Fullwidth less-than
|
|
||||||
0xFF1D: '=', // Fullwidth equal
|
|
||||||
0xFF1E: '>', // Fullwidth greater-than
|
|
||||||
0xFF1F: '?', // Fullwidth question mark
|
|
||||||
0xFF20: '@', // Fullwidth at sign
|
|
||||||
0xFF21: 'A',
|
|
||||||
0xFF22: 'B',
|
|
||||||
0xFF23: 'C',
|
|
||||||
0xFF24: 'D',
|
|
||||||
0xFF25: 'E',
|
|
||||||
0xFF26: 'F',
|
|
||||||
0xFF27: 'G',
|
|
||||||
0xFF28: 'H',
|
|
||||||
0xFF29: 'I',
|
|
||||||
0xFF2A: 'J',
|
|
||||||
0xFF2B: 'K',
|
|
||||||
0xFF2C: 'L',
|
|
||||||
0xFF2D: 'M',
|
|
||||||
0xFF2E: 'N',
|
|
||||||
0xFF2F: 'O',
|
|
||||||
0xFF30: 'P',
|
|
||||||
0xFF31: 'Q',
|
|
||||||
0xFF32: 'R',
|
|
||||||
0xFF33: 'S',
|
|
||||||
0xFF34: 'T',
|
|
||||||
0xFF35: 'U',
|
|
||||||
0xFF36: 'V',
|
|
||||||
0xFF37: 'W',
|
|
||||||
0xFF38: 'X',
|
|
||||||
0xFF39: 'Y',
|
|
||||||
0xFF3A: 'Z',
|
|
||||||
0xFF3B: '[', // Fullwidth left bracket
|
|
||||||
0xFF3C: '\\', // Fullwidth backslash
|
|
||||||
0xFF3D: ']', // Fullwidth right bracket
|
|
||||||
0xFF3E: '^', // Fullwidth circumflex
|
|
||||||
0xFF3F: '_', // Fullwidth underscore
|
|
||||||
0xFF40: '`', // Fullwidth grave accent
|
|
||||||
0xFF41: 'a',
|
|
||||||
0xFF42: 'b',
|
|
||||||
0xFF43: 'c',
|
|
||||||
0xFF44: 'd',
|
|
||||||
0xFF45: 'e',
|
|
||||||
0xFF46: 'f',
|
|
||||||
0xFF47: 'g',
|
|
||||||
0xFF48: 'h',
|
|
||||||
0xFF49: 'i',
|
|
||||||
0xFF4A: 'j',
|
|
||||||
0xFF4B: 'k',
|
|
||||||
0xFF4C: 'l',
|
|
||||||
0xFF4D: 'm',
|
|
||||||
0xFF4E: 'n',
|
|
||||||
0xFF4F: 'o',
|
|
||||||
0xFF50: 'p',
|
|
||||||
0xFF51: 'q',
|
|
||||||
0xFF52: 'r',
|
|
||||||
0xFF53: 's',
|
|
||||||
0xFF54: 't',
|
|
||||||
0xFF55: 'u',
|
|
||||||
0xFF56: 'v',
|
|
||||||
0xFF57: 'w',
|
|
||||||
0xFF58: 'x',
|
|
||||||
0xFF59: 'y',
|
|
||||||
0xFF5A: 'z',
|
|
||||||
0xFF5B: '{', // Fullwidth left brace
|
|
||||||
0xFF5C: '|', // Fullwidth vertical bar
|
|
||||||
0xFF5D: '}', // Fullwidth right brace
|
|
||||||
0xFF5E: '~', // Fullwidth tilde
|
|
||||||
0xFF61: '.', // Halfwidth ideographic full stop
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// NormalizeRunes normalizes latin script letters
|
// NormalizeRunes normalizes latin script letters
|
||||||
@@ -577,7 +480,7 @@ func NormalizeRunes(runes []rune) []rune {
|
|||||||
ret := make([]rune, len(runes))
|
ret := make([]rune, len(runes))
|
||||||
copy(ret, runes)
|
copy(ret, runes)
|
||||||
for idx, r := range runes {
|
for idx, r := range runes {
|
||||||
if r < 0x00C0 || r > 0xFF61 {
|
if r < 0x00C0 || r > 0x2184 {
|
||||||
continue
|
continue
|
||||||
}
|
}
|
||||||
n := normalized[r]
|
n := normalized[r]
|
||||||
|
|||||||
+62
-161
@@ -6,7 +6,6 @@ import (
|
|||||||
"strings"
|
"strings"
|
||||||
"unicode/utf8"
|
"unicode/utf8"
|
||||||
|
|
||||||
"github.com/junegunn/fzf/src/algo"
|
|
||||||
"github.com/junegunn/fzf/src/tui"
|
"github.com/junegunn/fzf/src/tui"
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -23,21 +22,20 @@ type url struct {
|
|||||||
type ansiState struct {
|
type ansiState struct {
|
||||||
fg tui.Color
|
fg tui.Color
|
||||||
bg tui.Color
|
bg tui.Color
|
||||||
ul tui.Color
|
|
||||||
attr tui.Attr
|
attr tui.Attr
|
||||||
lbg tui.Color
|
lbg tui.Color
|
||||||
url *url
|
url *url
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *ansiState) colored() bool {
|
func (s *ansiState) colored() bool {
|
||||||
return s.fg != -1 || s.bg != -1 || s.ul != -1 || s.attr > 0 || s.lbg >= 0 || s.url != nil
|
return s.fg != -1 || s.bg != -1 || s.attr > 0 || s.lbg >= 0 || s.url != nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *ansiState) equals(t *ansiState) bool {
|
func (s *ansiState) equals(t *ansiState) bool {
|
||||||
if t == nil {
|
if t == nil {
|
||||||
return !s.colored()
|
return !s.colored()
|
||||||
}
|
}
|
||||||
return s.fg == t.fg && s.bg == t.bg && s.ul == t.ul && s.attr == t.attr && s.lbg == t.lbg && s.url == t.url
|
return s.fg == t.fg && s.bg == t.bg && s.attr == t.attr && s.lbg == t.lbg && s.url == t.url
|
||||||
}
|
}
|
||||||
|
|
||||||
func (s *ansiState) ToString() string {
|
func (s *ansiState) ToString() string {
|
||||||
@@ -46,7 +44,7 @@ func (s *ansiState) ToString() string {
|
|||||||
}
|
}
|
||||||
|
|
||||||
ret := ""
|
ret := ""
|
||||||
if s.attr&tui.Bold > 0 || s.attr&tui.BoldForce > 0 {
|
if s.attr&tui.Bold > 0 {
|
||||||
ret += "1;"
|
ret += "1;"
|
||||||
}
|
}
|
||||||
if s.attr&tui.Dim > 0 {
|
if s.attr&tui.Dim > 0 {
|
||||||
@@ -56,18 +54,7 @@ func (s *ansiState) ToString() string {
|
|||||||
ret += "3;"
|
ret += "3;"
|
||||||
}
|
}
|
||||||
if s.attr&tui.Underline > 0 {
|
if s.attr&tui.Underline > 0 {
|
||||||
switch s.attr.UnderlineStyle() {
|
ret += "4;"
|
||||||
case tui.UlStyleDouble:
|
|
||||||
ret += "4:2;"
|
|
||||||
case tui.UlStyleCurly:
|
|
||||||
ret += "4:3;"
|
|
||||||
case tui.UlStyleDotted:
|
|
||||||
ret += "4:4;"
|
|
||||||
case tui.UlStyleDashed:
|
|
||||||
ret += "4:5;"
|
|
||||||
default:
|
|
||||||
ret += "4;"
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
if s.attr&tui.Blink > 0 {
|
if s.attr&tui.Blink > 0 {
|
||||||
ret += "5;"
|
ret += "5;"
|
||||||
@@ -79,9 +66,6 @@ func (s *ansiState) ToString() string {
|
|||||||
ret += "9;"
|
ret += "9;"
|
||||||
}
|
}
|
||||||
ret += toAnsiString(s.fg, 30) + toAnsiString(s.bg, 40)
|
ret += toAnsiString(s.fg, 30) + toAnsiString(s.bg, 40)
|
||||||
if s.ul != -1 {
|
|
||||||
ret += toAnsiStringUl(s.ul)
|
|
||||||
}
|
|
||||||
|
|
||||||
ret = "\x1b[" + strings.TrimSuffix(ret, ";") + "m"
|
ret = "\x1b[" + strings.TrimSuffix(ret, ";") + "m"
|
||||||
if s.url != nil {
|
if s.url != nil {
|
||||||
@@ -90,20 +74,6 @@ func (s *ansiState) ToString() string {
|
|||||||
return ret
|
return ret
|
||||||
}
|
}
|
||||||
|
|
||||||
func toAnsiStringUl(color tui.Color) string {
|
|
||||||
col := int(color)
|
|
||||||
if col < 0 {
|
|
||||||
return ""
|
|
||||||
}
|
|
||||||
if col >= (1 << 24) {
|
|
||||||
r := strconv.Itoa((col >> 16) & 0xff)
|
|
||||||
g := strconv.Itoa((col >> 8) & 0xff)
|
|
||||||
b := strconv.Itoa(col & 0xff)
|
|
||||||
return "58;2;" + r + ";" + g + ";" + b + ";"
|
|
||||||
}
|
|
||||||
return "58;5;" + strconv.Itoa(col) + ";"
|
|
||||||
}
|
|
||||||
|
|
||||||
func toAnsiString(color tui.Color, offset int) string {
|
func toAnsiString(color tui.Color, offset int) string {
|
||||||
col := int(color)
|
col := int(color)
|
||||||
ret := ""
|
ret := ""
|
||||||
@@ -124,31 +94,31 @@ func toAnsiString(color tui.Color, offset int) string {
|
|||||||
return ret + ";"
|
return ret + ";"
|
||||||
}
|
}
|
||||||
|
|
||||||
func matchOperatingSystemCommand(s string, start int) int {
|
func isPrint(c uint8) bool {
|
||||||
|
return '\x20' <= c && c <= '\x7e'
|
||||||
|
}
|
||||||
|
|
||||||
|
func matchOperatingSystemCommand(s string) int {
|
||||||
// `\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
// `\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
||||||
// ^ match starting here after the first printable character
|
// ^ match starting here
|
||||||
//
|
//
|
||||||
i := start // prefix matched in nextAnsiEscapeSequence()
|
i := 5 // prefix matched in nextAnsiEscapeSequence()
|
||||||
|
for ; i < len(s) && isPrint(s[i]); i++ {
|
||||||
// Find the terminator: BEL (\x07) or ESC (\x1b) for ST (\x1b\\)
|
|
||||||
idx := algo.IndexByteTwo(stringBytes(s[i:]), '\x07', '\x1b')
|
|
||||||
if idx < 0 {
|
|
||||||
return -1
|
|
||||||
}
|
}
|
||||||
i += idx
|
if i < len(s) {
|
||||||
|
if s[i] == '\x07' {
|
||||||
if s[i] == '\x07' {
|
return i + 1
|
||||||
return i + 1
|
}
|
||||||
}
|
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
||||||
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
// ------
|
||||||
// ------
|
if s[i] == '\x1b' && i < len(s)-1 && s[i+1] == '\\' {
|
||||||
if i < len(s)-1 && s[i+1] == '\\' {
|
return i + 2
|
||||||
return i + 2
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
// `\x1b]8;PARAMS;URI\x1b\\TITLE\x1b]8;;\x1b`
|
||||||
// ------------
|
// ------------
|
||||||
if s[:i+1] == "\x1b]8;;\x1b" {
|
if i < len(s) && s[:i+1] == "\x1b]8;;\x1b" {
|
||||||
return i + 1
|
return i + 1
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -186,13 +156,13 @@ func isCtrlSeqStart(c uint8) bool {
|
|||||||
// nextAnsiEscapeSequence returns the ANSI escape sequence and is equivalent to
|
// nextAnsiEscapeSequence returns the ANSI escape sequence and is equivalent to
|
||||||
// calling FindStringIndex() on the below regex (which was originally used):
|
// calling FindStringIndex() on the below regex (which was originally used):
|
||||||
//
|
//
|
||||||
// "(?:\x1b[\\[()][0-9;:?]*[a-zA-Z@]|\x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08|\n)"
|
// "(?:\x1b[\\[()][0-9;:?]*[a-zA-Z@]|\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)"
|
||||||
func nextAnsiEscapeSequence(s string) (int, int) {
|
func nextAnsiEscapeSequence(s string) (int, int) {
|
||||||
// fast check for ANSI escape sequences
|
// fast check for ANSI escape sequences
|
||||||
i := 0
|
i := 0
|
||||||
for ; i < len(s); i++ {
|
for ; i < len(s); i++ {
|
||||||
switch s[i] {
|
switch s[i] {
|
||||||
case '\x0e', '\x0f', '\x1b', '\x08', '\n':
|
case '\x0e', '\x0f', '\x1b', '\x08':
|
||||||
// We ignore the fact that '\x08' cannot be the first char
|
// We ignore the fact that '\x08' cannot be the first char
|
||||||
// in the string and be an escape sequence for the sake of
|
// in the string and be an escape sequence for the sake of
|
||||||
// speed and simplicity.
|
// speed and simplicity.
|
||||||
@@ -204,9 +174,6 @@ func nextAnsiEscapeSequence(s string) (int, int) {
|
|||||||
Loop:
|
Loop:
|
||||||
for ; i < len(s); i++ {
|
for ; i < len(s); i++ {
|
||||||
switch s[i] {
|
switch s[i] {
|
||||||
case '\n':
|
|
||||||
// match: `\n`
|
|
||||||
return i, i + 1
|
|
||||||
case '\x08':
|
case '\x08':
|
||||||
// backtrack to match: `.\x08`
|
// backtrack to match: `.\x08`
|
||||||
if i > 0 && s[i-1] != '\n' {
|
if i > 0 && s[i-1] != '\n' {
|
||||||
@@ -224,20 +191,12 @@ Loop:
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// match: `\x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
// match: `\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)`
|
||||||
if i+5 < len(s) && s[i+1] == ']' {
|
if i+5 < len(s) && s[i+1] == ']' && isNumeric(s[i+2]) &&
|
||||||
j := 2
|
(s[i+3] == ';' || s[i+3] == ':') && isPrint(s[i+4]) {
|
||||||
// \x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)
|
|
||||||
// ------
|
|
||||||
for ; i+j < len(s) && isNumeric(s[i+j]); j++ {
|
|
||||||
}
|
|
||||||
|
|
||||||
// \x1b][0-9]+[;:][[:print:]]+(?:\x1b\\\\|\x07)
|
if j := matchOperatingSystemCommand(s[i:]); j != -1 {
|
||||||
// ---------------
|
return i, i + j
|
||||||
if j > 2 && i+j+1 < len(s) && (s[i+j] == ';' || s[i+j] == ':') && s[i+j+1] >= '\x20' {
|
|
||||||
if k := matchOperatingSystemCommand(s[i:], j+2); k != -1 {
|
|
||||||
return i, i + k
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -298,30 +257,13 @@ func extractColor(str string, state *ansiState, proc func(string, *ansiState) bo
|
|||||||
output.WriteString(prev)
|
output.WriteString(prev)
|
||||||
}
|
}
|
||||||
|
|
||||||
code := str[start:idx]
|
newState := interpretCode(str[start:idx], state)
|
||||||
newState := interpretCode(code, state)
|
if !newState.equals(state) {
|
||||||
if code == "\n" || !newState.equals(state) {
|
|
||||||
if state != nil {
|
if state != nil {
|
||||||
// Update last offset
|
// Update last offset
|
||||||
(&offsets[len(offsets)-1]).offset[1] = int32(runeCount)
|
(&offsets[len(offsets)-1]).offset[1] = int32(runeCount)
|
||||||
}
|
}
|
||||||
|
|
||||||
if code == "\n" {
|
|
||||||
output.WriteRune('\n')
|
|
||||||
runeCount++
|
|
||||||
// Full-background marker
|
|
||||||
if newState.lbg >= 0 {
|
|
||||||
marker := newState
|
|
||||||
marker.attr |= tui.FullBg
|
|
||||||
offsets = append(offsets, ansiOffset{
|
|
||||||
[2]int32{int32(runeCount), int32(runeCount)},
|
|
||||||
marker,
|
|
||||||
})
|
|
||||||
// Reset the full-line background color
|
|
||||||
newState.lbg = -1
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
if newState.colored() {
|
if newState.colored() {
|
||||||
// Append new offset
|
// Append new offset
|
||||||
if pstate == nil {
|
if pstate == nil {
|
||||||
@@ -368,19 +310,20 @@ func extractColor(str string, state *ansiState, proc func(string, *ansiState) bo
|
|||||||
return trimmed, nil, state
|
return trimmed, nil, state
|
||||||
}
|
}
|
||||||
|
|
||||||
func parseAnsiCode(s string) (int, byte, string) {
|
func parseAnsiCode(s string, delimiter byte) (int, byte, string) {
|
||||||
var remaining string
|
var remaining string
|
||||||
var sep byte
|
var i int
|
||||||
// Find the first separator (either ; or :)
|
if delimiter == 0 {
|
||||||
i := -1
|
// Faster than strings.IndexAny(";:")
|
||||||
for j := 0; j < len(s); j++ {
|
i = strings.IndexByte(s, ';')
|
||||||
if s[j] == ';' || s[j] == ':' {
|
if i < 0 {
|
||||||
i = j
|
i = strings.IndexByte(s, ':')
|
||||||
break
|
|
||||||
}
|
}
|
||||||
|
} else {
|
||||||
|
i = strings.IndexByte(s, delimiter)
|
||||||
}
|
}
|
||||||
if i >= 0 {
|
if i >= 0 {
|
||||||
sep = s[i]
|
delimiter = s[i]
|
||||||
remaining = s[i+1:]
|
remaining = s[i+1:]
|
||||||
s = s[:i]
|
s = s[:i]
|
||||||
}
|
}
|
||||||
@@ -392,59 +335,42 @@ func parseAnsiCode(s string) (int, byte, string) {
|
|||||||
for _, ch := range stringBytes(s) {
|
for _, ch := range stringBytes(s) {
|
||||||
ch -= '0'
|
ch -= '0'
|
||||||
if ch > 9 {
|
if ch > 9 {
|
||||||
return -1, sep, remaining
|
return -1, delimiter, remaining
|
||||||
}
|
}
|
||||||
code = code*10 + int(ch)
|
code = code*10 + int(ch)
|
||||||
}
|
}
|
||||||
return code, sep, remaining
|
return code, delimiter, remaining
|
||||||
}
|
}
|
||||||
|
|
||||||
return -1, sep, remaining
|
return -1, delimiter, remaining
|
||||||
}
|
}
|
||||||
|
|
||||||
func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||||
if ansiCode == "\n" {
|
|
||||||
if prevState != nil {
|
|
||||||
return *prevState
|
|
||||||
}
|
|
||||||
return ansiState{-1, -1, -1, 0, -1, nil}
|
|
||||||
}
|
|
||||||
|
|
||||||
var state ansiState
|
var state ansiState
|
||||||
if prevState == nil {
|
if prevState == nil {
|
||||||
state = ansiState{-1, -1, -1, 0, -1, nil}
|
state = ansiState{-1, -1, 0, -1, nil}
|
||||||
} else {
|
} else {
|
||||||
state = ansiState{prevState.fg, prevState.bg, prevState.ul, prevState.attr, prevState.lbg, prevState.url}
|
state = ansiState{prevState.fg, prevState.bg, prevState.attr, prevState.lbg, prevState.url}
|
||||||
}
|
}
|
||||||
if ansiCode[0] != '\x1b' || ansiCode[1] != '[' || ansiCode[len(ansiCode)-1] != 'm' {
|
if ansiCode[0] != '\x1b' || ansiCode[1] != '[' || ansiCode[len(ansiCode)-1] != 'm' {
|
||||||
if prevState != nil && (strings.HasSuffix(ansiCode, "0K") || strings.HasSuffix(ansiCode, "[K")) {
|
if prevState != nil && strings.HasSuffix(ansiCode, "0K") {
|
||||||
state.lbg = prevState.bg
|
state.lbg = prevState.bg
|
||||||
} else if strings.HasPrefix(ansiCode, "\x1b]8;") && (strings.HasSuffix(ansiCode, "\x1b\\") || strings.HasSuffix(ansiCode, "\a")) {
|
} else if ansiCode == "\x1b]8;;\x1b\\" { // End of a hyperlink
|
||||||
stLen := 2
|
state.url = nil
|
||||||
if strings.HasSuffix(ansiCode, "\a") {
|
} else if strings.HasPrefix(ansiCode, "\x1b]8;") && strings.HasSuffix(ansiCode, "\x1b\\") {
|
||||||
stLen = 1
|
if paramsEnd := strings.IndexRune(ansiCode[4:], ';'); paramsEnd >= 0 {
|
||||||
}
|
|
||||||
// "\x1b]8;;\x1b\\" or "\x1b]8;;\a"
|
|
||||||
if len(ansiCode) == 5+stLen && ansiCode[4] == ';' {
|
|
||||||
state.url = nil
|
|
||||||
} else if paramsEnd := strings.IndexRune(ansiCode[4:], ';'); paramsEnd >= 0 {
|
|
||||||
params := ansiCode[4 : 4+paramsEnd]
|
params := ansiCode[4 : 4+paramsEnd]
|
||||||
uri := ansiCode[5+paramsEnd : len(ansiCode)-stLen]
|
uri := ansiCode[5+paramsEnd : len(ansiCode)-2]
|
||||||
state.url = &url{uri: uri, params: params}
|
state.url = &url{uri: uri, params: params}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
return state
|
return state
|
||||||
}
|
}
|
||||||
|
|
||||||
reset := func() {
|
if len(ansiCode) <= 3 {
|
||||||
state.fg = -1
|
state.fg = -1
|
||||||
state.bg = -1
|
state.bg = -1
|
||||||
state.ul = -1
|
|
||||||
state.attr = 0
|
state.attr = 0
|
||||||
}
|
|
||||||
|
|
||||||
if len(ansiCode) <= 3 {
|
|
||||||
reset()
|
|
||||||
return state
|
return state
|
||||||
}
|
}
|
||||||
ansiCode = ansiCode[2 : len(ansiCode)-1]
|
ansiCode = ansiCode[2 : len(ansiCode)-1]
|
||||||
@@ -452,11 +378,11 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
state256 := 0
|
state256 := 0
|
||||||
ptr := &state.fg
|
ptr := &state.fg
|
||||||
|
|
||||||
|
var delimiter byte
|
||||||
count := 0
|
count := 0
|
||||||
for len(ansiCode) != 0 {
|
for len(ansiCode) != 0 {
|
||||||
var num int
|
var num int
|
||||||
var sep byte
|
if num, delimiter, ansiCode = parseAnsiCode(ansiCode, delimiter); num != -1 {
|
||||||
if num, sep, ansiCode = parseAnsiCode(ansiCode); num != -1 {
|
|
||||||
count++
|
count++
|
||||||
switch state256 {
|
switch state256 {
|
||||||
case 0:
|
case 0:
|
||||||
@@ -467,15 +393,10 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
case 48:
|
case 48:
|
||||||
ptr = &state.bg
|
ptr = &state.bg
|
||||||
state256++
|
state256++
|
||||||
case 58:
|
|
||||||
ptr = &state.ul
|
|
||||||
state256++
|
|
||||||
case 39:
|
case 39:
|
||||||
state.fg = -1
|
state.fg = -1
|
||||||
case 49:
|
case 49:
|
||||||
state.bg = -1
|
state.bg = -1
|
||||||
case 59:
|
|
||||||
state.ul = -1
|
|
||||||
case 1:
|
case 1:
|
||||||
state.attr = state.attr | tui.Bold
|
state.attr = state.attr | tui.Bold
|
||||||
case 2:
|
case 2:
|
||||||
@@ -483,30 +404,7 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
case 3:
|
case 3:
|
||||||
state.attr = state.attr | tui.Italic
|
state.attr = state.attr | tui.Italic
|
||||||
case 4:
|
case 4:
|
||||||
if sep == ':' {
|
state.attr = state.attr | tui.Underline
|
||||||
// SGR 4:N - underline style sub-parameter
|
|
||||||
var subNum int
|
|
||||||
subNum, _, ansiCode = parseAnsiCode(ansiCode)
|
|
||||||
state.attr = state.attr &^ tui.UnderlineStyleMask
|
|
||||||
switch subNum {
|
|
||||||
case 0:
|
|
||||||
state.attr = state.attr &^ tui.Underline
|
|
||||||
case 1:
|
|
||||||
state.attr = state.attr | tui.Underline
|
|
||||||
case 2:
|
|
||||||
state.attr = state.attr | tui.Underline | tui.UlStyleDouble
|
|
||||||
case 3:
|
|
||||||
state.attr = state.attr | tui.Underline | tui.UlStyleCurly
|
|
||||||
case 4:
|
|
||||||
state.attr = state.attr | tui.Underline | tui.UlStyleDotted
|
|
||||||
case 5:
|
|
||||||
state.attr = state.attr | tui.Underline | tui.UlStyleDashed
|
|
||||||
default:
|
|
||||||
state.attr = state.attr | tui.Underline
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
state.attr = state.attr | tui.Underline
|
|
||||||
}
|
|
||||||
case 5:
|
case 5:
|
||||||
state.attr = state.attr | tui.Blink
|
state.attr = state.attr | tui.Blink
|
||||||
case 7:
|
case 7:
|
||||||
@@ -520,7 +418,6 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
state.attr = state.attr &^ tui.Italic
|
state.attr = state.attr &^ tui.Italic
|
||||||
case 24: // tput rmul
|
case 24: // tput rmul
|
||||||
state.attr = state.attr &^ tui.Underline
|
state.attr = state.attr &^ tui.Underline
|
||||||
state.attr = state.attr &^ tui.UnderlineStyleMask
|
|
||||||
case 25:
|
case 25:
|
||||||
state.attr = state.attr &^ tui.Blink
|
state.attr = state.attr &^ tui.Blink
|
||||||
case 27:
|
case 27:
|
||||||
@@ -528,7 +425,9 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
case 29:
|
case 29:
|
||||||
state.attr = state.attr &^ tui.StrikeThrough
|
state.attr = state.attr &^ tui.StrikeThrough
|
||||||
case 0:
|
case 0:
|
||||||
reset()
|
state.fg = -1
|
||||||
|
state.bg = -1
|
||||||
|
state.attr = 0
|
||||||
state256 = 0
|
state256 = 0
|
||||||
default:
|
default:
|
||||||
if num >= 30 && num <= 37 {
|
if num >= 30 && num <= 37 {
|
||||||
@@ -568,7 +467,9 @@ func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
|||||||
|
|
||||||
// Empty sequence: reset
|
// Empty sequence: reset
|
||||||
if count == 0 {
|
if count == 0 {
|
||||||
reset()
|
state.fg = -1
|
||||||
|
state.bg = -1
|
||||||
|
state.attr = 0
|
||||||
}
|
}
|
||||||
|
|
||||||
if state256 > 0 {
|
if state256 > 0 {
|
||||||
|
|||||||
+22
-150
@@ -22,7 +22,7 @@ import (
|
|||||||
// (archived from http://ascii-table.com/ansi-escape-sequences-vt-100.php)
|
// (archived from http://ascii-table.com/ansi-escape-sequences-vt-100.php)
|
||||||
// - http://tldp.org/HOWTO/Bash-Prompt-HOWTO/x405.html
|
// - http://tldp.org/HOWTO/Bash-Prompt-HOWTO/x405.html
|
||||||
// - https://invisible-island.net/xterm/ctlseqs/ctlseqs.html
|
// - https://invisible-island.net/xterm/ctlseqs/ctlseqs.html
|
||||||
var ansiRegexReference = regexp.MustCompile("(?:\x1b[\\[()][0-9;:]*[a-zA-Z@]|\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08|\n)")
|
var ansiRegexReference = regexp.MustCompile("(?:\x1b[\\[()][0-9;:]*[a-zA-Z@]|\x1b][0-9][;:][[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)")
|
||||||
|
|
||||||
func testParserReference(t testing.TB, str string) {
|
func testParserReference(t testing.TB, str string) {
|
||||||
t.Helper()
|
t.Helper()
|
||||||
@@ -41,7 +41,7 @@ func testParserReference(t testing.TB, str string) {
|
|||||||
|
|
||||||
equal := len(got) == len(exp)
|
equal := len(got) == len(exp)
|
||||||
if equal {
|
if equal {
|
||||||
for i := range got {
|
for i := 0; i < len(got); i++ {
|
||||||
if got[i] != exp[i] {
|
if got[i] != exp[i] {
|
||||||
equal = false
|
equal = false
|
||||||
break
|
break
|
||||||
@@ -167,9 +167,9 @@ func TestNextAnsiEscapeSequence_Fuzz_Random(t *testing.T) {
|
|||||||
randomString := func(rr *rand.Rand) string {
|
randomString := func(rr *rand.Rand) string {
|
||||||
numChars := rand.Intn(50)
|
numChars := rand.Intn(50)
|
||||||
codePoints := make([]rune, numChars)
|
codePoints := make([]rune, numChars)
|
||||||
for i := range codePoints {
|
for i := 0; i < len(codePoints); i++ {
|
||||||
var r rune
|
var r rune
|
||||||
for range 1000 {
|
for n := 0; n < 1000; n++ {
|
||||||
r = rune(rr.Intn(utf8.MaxRune))
|
r = rune(rr.Intn(utf8.MaxRune))
|
||||||
// Allow 10% of runes to be invalid
|
// Allow 10% of runes to be invalid
|
||||||
if utf8.ValidRune(r) || rr.Float64() < 0.10 {
|
if utf8.ValidRune(r) || rr.Float64() < 0.10 {
|
||||||
@@ -182,7 +182,7 @@ func TestNextAnsiEscapeSequence_Fuzz_Random(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
rr := rand.New(rand.NewSource(1))
|
rr := rand.New(rand.NewSource(1))
|
||||||
for range 100_000 {
|
for i := 0; i < 100_000; i++ {
|
||||||
testParserReference(t, randomString(rr))
|
testParserReference(t, randomString(rr))
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -335,28 +335,6 @@ func TestExtractColor(t *testing.T) {
|
|||||||
assert((*offsets)[0], 0, 6, 2, -1, true)
|
assert((*offsets)[0], 0, 6, 2, -1, true)
|
||||||
assert((*offsets)[1], 6, 11, 200, 100, false)
|
assert((*offsets)[1], 6, 11, 200, 100, false)
|
||||||
})
|
})
|
||||||
|
|
||||||
state = nil
|
|
||||||
var color24 tui.Color = (1 << 24) + (180 << 16) + (190 << 8) + 254
|
|
||||||
src = "\x1b[1mhello \x1b[22;1;38:2:180:190:254mworld"
|
|
||||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
|
||||||
if len(*offsets) != 2 {
|
|
||||||
t.Fail()
|
|
||||||
}
|
|
||||||
if state.fg != color24 || state.attr != 1 {
|
|
||||||
t.Fail()
|
|
||||||
}
|
|
||||||
assert((*offsets)[0], 0, 6, -1, -1, true)
|
|
||||||
assert((*offsets)[1], 6, 11, color24, -1, true)
|
|
||||||
})
|
|
||||||
|
|
||||||
src = "\x1b]133;A\x1b\\hello \x1b]133;C\x1b\\world"
|
|
||||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
|
||||||
if len(*offsets) != 1 {
|
|
||||||
t.Fail()
|
|
||||||
}
|
|
||||||
assert((*offsets)[0], 0, 11, color24, -1, true)
|
|
||||||
})
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestAnsiCodeStringConversion(t *testing.T) {
|
func TestAnsiCodeStringConversion(t *testing.T) {
|
||||||
@@ -369,10 +347,10 @@ func TestAnsiCodeStringConversion(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
assert("\x1b[m", nil, "")
|
assert("\x1b[m", nil, "")
|
||||||
assert("\x1b[m", &ansiState{attr: tui.Blink, ul: -1, lbg: -1}, "")
|
assert("\x1b[m", &ansiState{attr: tui.Blink, lbg: -1}, "")
|
||||||
assert("\x1b[0m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
assert("\x1b[0m", &ansiState{fg: 4, bg: 4, lbg: -1}, "")
|
||||||
assert("\x1b[;m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
assert("\x1b[;m", &ansiState{fg: 4, bg: 4, lbg: -1}, "")
|
||||||
assert("\x1b[;;m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "")
|
assert("\x1b[;;m", &ansiState{fg: 4, bg: 4, lbg: -1}, "")
|
||||||
|
|
||||||
assert("\x1b[31m", nil, "\x1b[31;49m")
|
assert("\x1b[31m", nil, "\x1b[31;49m")
|
||||||
assert("\x1b[41m", nil, "\x1b[39;41m")
|
assert("\x1b[41m", nil, "\x1b[39;41m")
|
||||||
@@ -380,142 +358,36 @@ func TestAnsiCodeStringConversion(t *testing.T) {
|
|||||||
assert("\x1b[92m", nil, "\x1b[92;49m")
|
assert("\x1b[92m", nil, "\x1b[92;49m")
|
||||||
assert("\x1b[102m", nil, "\x1b[39;102m")
|
assert("\x1b[102m", nil, "\x1b[39;102m")
|
||||||
|
|
||||||
assert("\x1b[31m", &ansiState{fg: 4, bg: 4, ul: -1, lbg: -1}, "\x1b[31;44m")
|
assert("\x1b[31m", &ansiState{fg: 4, bg: 4, lbg: -1}, "\x1b[31;44m")
|
||||||
assert("\x1b[1;2;31m", &ansiState{fg: 2, bg: -1, ul: -1, attr: tui.Reverse, lbg: -1}, "\x1b[1;2;7;31;49m")
|
assert("\x1b[1;2;31m", &ansiState{fg: 2, bg: -1, attr: tui.Reverse, lbg: -1}, "\x1b[1;2;7;31;49m")
|
||||||
assert("\x1b[38;5;100;48;5;200m", nil, "\x1b[38;5;100;48;5;200m")
|
assert("\x1b[38;5;100;48;5;200m", nil, "\x1b[38;5;100;48;5;200m")
|
||||||
assert("\x1b[38:5:100:48:5:200m", nil, "\x1b[38;5;100;48;5;200m")
|
assert("\x1b[38:5:100:48:5:200m", nil, "\x1b[38;5;100;48;5;200m")
|
||||||
assert("\x1b[48;5;100;38;5;200m", nil, "\x1b[38;5;200;48;5;100m")
|
assert("\x1b[48;5;100;38;5;200m", nil, "\x1b[38;5;200;48;5;100m")
|
||||||
assert("\x1b[48;5;100;38;2;10;20;30;1m", nil, "\x1b[1;38;2;10;20;30;48;5;100m")
|
assert("\x1b[48;5;100;38;2;10;20;30;1m", nil, "\x1b[1;38;2;10;20;30;48;5;100m")
|
||||||
assert("\x1b[48;5;100;38;2;10;20;30;7m",
|
assert("\x1b[48;5;100;38;2;10;20;30;7m",
|
||||||
&ansiState{attr: tui.Dim | tui.Italic, fg: 1, bg: 1, ul: -1},
|
&ansiState{attr: tui.Dim | tui.Italic, fg: 1, bg: 1},
|
||||||
"\x1b[2;3;7;38;2;10;20;30;48;5;100m")
|
"\x1b[2;3;7;38;2;10;20;30;48;5;100m")
|
||||||
|
|
||||||
// Underline styles
|
|
||||||
assert("\x1b[4:3m", nil, "\x1b[4:3;39;49m")
|
|
||||||
assert("\x1b[4:2m", nil, "\x1b[4:2;39;49m")
|
|
||||||
assert("\x1b[4:4m", nil, "\x1b[4:4;39;49m")
|
|
||||||
assert("\x1b[4:5m", nil, "\x1b[4:5;39;49m")
|
|
||||||
assert("\x1b[4:1m", nil, "\x1b[4;39;49m")
|
|
||||||
|
|
||||||
// Underline color (256-color)
|
|
||||||
assert("\x1b[4;58;5;100m", nil, "\x1b[4;39;49;58;5;100m")
|
|
||||||
// Underline color (24-bit)
|
|
||||||
assert("\x1b[4;58;2;255;0;128m", nil, "\x1b[4;39;49;58;2;255;0;128m")
|
|
||||||
// Curly underline + underline color
|
|
||||||
assert("\x1b[4:3;58;2;255;0;0m", nil, "\x1b[4:3;39;49;58;2;255;0;0m")
|
|
||||||
// SGR 59 resets underline color
|
|
||||||
assert("\x1b[59m", &ansiState{fg: 1, bg: -1, ul: 100, lbg: -1}, "\x1b[31;49m")
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestParseAnsiCode(t *testing.T) {
|
func TestParseAnsiCode(t *testing.T) {
|
||||||
tests := []struct {
|
tests := []struct {
|
||||||
In string
|
In, Exp string
|
||||||
Exp string
|
N int
|
||||||
N int
|
|
||||||
Sep byte
|
|
||||||
}{
|
}{
|
||||||
{"123", "", 123, 0},
|
{"123", "", 123},
|
||||||
{"1a", "", -1, 0},
|
{"1a", "", -1},
|
||||||
{"1a;12", "12", -1, ';'},
|
{"1a;12", "12", -1},
|
||||||
{"12;a", "a", 12, ';'},
|
{"12;a", "a", 12},
|
||||||
{"-2", "", -1, 0},
|
{"-2", "", -1},
|
||||||
// Colon sub-parameters: earliest separator wins (@shtse8)
|
|
||||||
{"4:3", "3", 4, ':'},
|
|
||||||
{"4:3;31", "3;31", 4, ':'},
|
|
||||||
{"38:2:255:0:0", "2:255:0:0", 38, ':'},
|
|
||||||
{"58:5:200", "5:200", 58, ':'},
|
|
||||||
// Semicolon before colon
|
|
||||||
{"4;38:2:0:0:0", "38:2:0:0:0", 4, ';'},
|
|
||||||
}
|
}
|
||||||
for _, x := range tests {
|
for _, x := range tests {
|
||||||
n, sep, s := parseAnsiCode(x.In)
|
n, _, s := parseAnsiCode(x.In, 0)
|
||||||
if n != x.N || s != x.Exp || sep != x.Sep {
|
if n != x.N || s != x.Exp {
|
||||||
t.Fatalf("%q: got: (%d %q %q) want: (%d %q %q)", x.In, n, s, string(sep), x.N, x.Exp, string(x.Sep))
|
t.Fatalf("%q: got: (%d %q) want: (%d %q)", x.In, n, s, x.N, x.Exp)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Test cases adapted from @shtse8 (PR #4678)
|
|
||||||
func TestInterpretCodeUnderlineStyles(t *testing.T) {
|
|
||||||
// 4:0 = no underline
|
|
||||||
state := interpretCode("\x1b[4:0m", nil)
|
|
||||||
if state.attr&tui.Underline != 0 {
|
|
||||||
t.Error("4:0 should not set underline")
|
|
||||||
}
|
|
||||||
|
|
||||||
// 4:1 = single underline
|
|
||||||
state = interpretCode("\x1b[4:1m", nil)
|
|
||||||
if state.attr&tui.Underline == 0 {
|
|
||||||
t.Error("4:1 should set underline")
|
|
||||||
}
|
|
||||||
|
|
||||||
// 4:3 = curly underline
|
|
||||||
state = interpretCode("\x1b[4:3m", nil)
|
|
||||||
if state.attr&tui.Underline == 0 {
|
|
||||||
t.Error("4:3 should set underline")
|
|
||||||
}
|
|
||||||
if state.attr.UnderlineStyle() != tui.UlStyleCurly {
|
|
||||||
t.Error("4:3 should set curly underline style")
|
|
||||||
}
|
|
||||||
|
|
||||||
// 4:3 should NOT set italic (3 is a sub-param, not SGR 3)
|
|
||||||
if state.attr&tui.Italic != 0 {
|
|
||||||
t.Error("4:3 should not set italic")
|
|
||||||
}
|
|
||||||
|
|
||||||
// 4:2;31 = double underline + red fg
|
|
||||||
state = interpretCode("\x1b[4:2;31m", nil)
|
|
||||||
if state.attr&tui.Underline == 0 {
|
|
||||||
t.Error("4:2;31 should set underline")
|
|
||||||
}
|
|
||||||
if state.fg != 1 {
|
|
||||||
t.Errorf("4:2;31 should set fg to red (1), got %d", state.fg)
|
|
||||||
}
|
|
||||||
if state.attr&tui.Dim != 0 {
|
|
||||||
t.Error("4:2;31 should not set dim")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Plain 4 still works
|
|
||||||
state = interpretCode("\x1b[4m", nil)
|
|
||||||
if state.attr&tui.Underline == 0 {
|
|
||||||
t.Error("4 should set underline")
|
|
||||||
}
|
|
||||||
|
|
||||||
// 4;2 (semicolon) = underline + dim
|
|
||||||
state = interpretCode("\x1b[4;2m", nil)
|
|
||||||
if state.attr&tui.Underline == 0 {
|
|
||||||
t.Error("4;2 should set underline")
|
|
||||||
}
|
|
||||||
if state.attr&tui.Dim == 0 {
|
|
||||||
t.Error("4;2 should set dim")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Test cases adapted from @shtse8 (PR #4678)
|
|
||||||
func TestInterpretCodeUnderlineColor(t *testing.T) {
|
|
||||||
// 58:2:R:G:B should not affect fg or bg
|
|
||||||
state := interpretCode("\x1b[58:2:255:0:0m", nil)
|
|
||||||
if state.fg != -1 || state.bg != -1 {
|
|
||||||
t.Errorf("58:2:R:G:B should not affect fg/bg, got fg=%d bg=%d", state.fg, state.bg)
|
|
||||||
}
|
|
||||||
|
|
||||||
// 58:5:200 should not affect fg or bg
|
|
||||||
state = interpretCode("\x1b[58:5:200m", nil)
|
|
||||||
if state.fg != -1 || state.bg != -1 {
|
|
||||||
t.Errorf("58:5:N should not affect fg/bg, got fg=%d bg=%d", state.fg, state.bg)
|
|
||||||
}
|
|
||||||
|
|
||||||
// 58:2:R:G:B combined with 38:2:R:G:B should only set fg
|
|
||||||
state = interpretCode("\x1b[58:2:255:0:0;38:2:0:255:0m", nil)
|
|
||||||
expectedFg := tui.Color(1<<24 | 0<<16 | 255<<8 | 0)
|
|
||||||
if state.fg != expectedFg {
|
|
||||||
t.Errorf("expected fg=%d, got %d", expectedFg, state.fg)
|
|
||||||
}
|
|
||||||
if state.bg != -1 {
|
|
||||||
t.Errorf("bg should be -1, got %d", state.bg)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// kernel/bpf/preload/iterators/README
|
// kernel/bpf/preload/iterators/README
|
||||||
const ansiBenchmarkString = "\x1b[38;5;81m\x1b[01;31m\x1b[Kkernel/\x1b[0m\x1b[38:5:81mbpf/" +
|
const ansiBenchmarkString = "\x1b[38;5;81m\x1b[01;31m\x1b[Kkernel/\x1b[0m\x1b[38:5:81mbpf/" +
|
||||||
"\x1b[0m\x1b[38:5:81mpreload/\x1b[0m\x1b[38;5;81miterators/" +
|
"\x1b[0m\x1b[38:5:81mpreload/\x1b[0m\x1b[38;5;81miterators/" +
|
||||||
|
|||||||
+15
-18
@@ -2,13 +2,10 @@ package fzf
|
|||||||
|
|
||||||
import "sync"
|
import "sync"
|
||||||
|
|
||||||
// ChunkBitmap is a bitmap with one bit per item in a chunk.
|
// queryCache associates strings to lists of items
|
||||||
type ChunkBitmap [chunkBitWords]uint64
|
type queryCache map[string][]Result
|
||||||
|
|
||||||
// queryCache associates query strings to bitmaps of matching items
|
// ChunkCache associates Chunk and query string to lists of items
|
||||||
type queryCache map[string]ChunkBitmap
|
|
||||||
|
|
||||||
// ChunkCache associates Chunk and query string to bitmaps
|
|
||||||
type ChunkCache struct {
|
type ChunkCache struct {
|
||||||
mutex sync.Mutex
|
mutex sync.Mutex
|
||||||
cache map[*Chunk]*queryCache
|
cache map[*Chunk]*queryCache
|
||||||
@@ -33,9 +30,9 @@ func (cc *ChunkCache) retire(chunk ...*Chunk) {
|
|||||||
cc.mutex.Unlock()
|
cc.mutex.Unlock()
|
||||||
}
|
}
|
||||||
|
|
||||||
// Add stores the bitmap for the given chunk and key
|
// Add adds the list to the cache
|
||||||
func (cc *ChunkCache) Add(chunk *Chunk, key string, bitmap ChunkBitmap, matchCount int) {
|
func (cc *ChunkCache) Add(chunk *Chunk, key string, list []Result) {
|
||||||
if len(key) == 0 || !chunk.IsFull() || matchCount > queryCacheMax {
|
if len(key) == 0 || !chunk.IsFull() || len(list) > queryCacheMax {
|
||||||
return
|
return
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -47,11 +44,11 @@ func (cc *ChunkCache) Add(chunk *Chunk, key string, bitmap ChunkBitmap, matchCou
|
|||||||
cc.cache[chunk] = &queryCache{}
|
cc.cache[chunk] = &queryCache{}
|
||||||
qc = cc.cache[chunk]
|
qc = cc.cache[chunk]
|
||||||
}
|
}
|
||||||
(*qc)[key] = bitmap
|
(*qc)[key] = list
|
||||||
}
|
}
|
||||||
|
|
||||||
// Lookup returns the bitmap for the exact key
|
// Lookup is called to lookup ChunkCache
|
||||||
func (cc *ChunkCache) Lookup(chunk *Chunk, key string) *ChunkBitmap {
|
func (cc *ChunkCache) Lookup(chunk *Chunk, key string) []Result {
|
||||||
if len(key) == 0 || !chunk.IsFull() {
|
if len(key) == 0 || !chunk.IsFull() {
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
@@ -61,15 +58,15 @@ func (cc *ChunkCache) Lookup(chunk *Chunk, key string) *ChunkBitmap {
|
|||||||
|
|
||||||
qc, ok := cc.cache[chunk]
|
qc, ok := cc.cache[chunk]
|
||||||
if ok {
|
if ok {
|
||||||
if bm, ok := (*qc)[key]; ok {
|
list, ok := (*qc)[key]
|
||||||
return &bm
|
if ok {
|
||||||
|
return list
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
|
|
||||||
// Search finds the bitmap for the longest prefix or suffix of the key
|
func (cc *ChunkCache) Search(chunk *Chunk, key string) []Result {
|
||||||
func (cc *ChunkCache) Search(chunk *Chunk, key string) *ChunkBitmap {
|
|
||||||
if len(key) == 0 || !chunk.IsFull() {
|
if len(key) == 0 || !chunk.IsFull() {
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
@@ -89,8 +86,8 @@ func (cc *ChunkCache) Search(chunk *Chunk, key string) *ChunkBitmap {
|
|||||||
prefix := key[:len(key)-idx]
|
prefix := key[:len(key)-idx]
|
||||||
suffix := key[idx:]
|
suffix := key[idx:]
|
||||||
for _, substr := range [2]string{prefix, suffix} {
|
for _, substr := range [2]string{prefix, suffix} {
|
||||||
if bm, found := (*qc)[substr]; found {
|
if cached, found := (*qc)[substr]; found {
|
||||||
return &bm
|
return cached
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
+11
-11
@@ -6,34 +6,34 @@ func TestChunkCache(t *testing.T) {
|
|||||||
cache := NewChunkCache()
|
cache := NewChunkCache()
|
||||||
chunk1p := &Chunk{}
|
chunk1p := &Chunk{}
|
||||||
chunk2p := &Chunk{count: chunkSize}
|
chunk2p := &Chunk{count: chunkSize}
|
||||||
bm1 := ChunkBitmap{1}
|
items1 := []Result{{}}
|
||||||
bm2 := ChunkBitmap{1, 2}
|
items2 := []Result{{}, {}}
|
||||||
cache.Add(chunk1p, "foo", bm1, 1)
|
cache.Add(chunk1p, "foo", items1)
|
||||||
cache.Add(chunk2p, "foo", bm1, 1)
|
cache.Add(chunk2p, "foo", items1)
|
||||||
cache.Add(chunk2p, "bar", bm2, 2)
|
cache.Add(chunk2p, "bar", items2)
|
||||||
|
|
||||||
{ // chunk1 is not full
|
{ // chunk1 is not full
|
||||||
cached := cache.Lookup(chunk1p, "foo")
|
cached := cache.Lookup(chunk1p, "foo")
|
||||||
if cached != nil {
|
if cached != nil {
|
||||||
t.Error("Cached disabled for non-full chunks", cached)
|
t.Error("Cached disabled for non-empty chunks", cached)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
{
|
{
|
||||||
cached := cache.Lookup(chunk2p, "foo")
|
cached := cache.Lookup(chunk2p, "foo")
|
||||||
if cached == nil || cached[0] != 1 {
|
if cached == nil || len(cached) != 1 {
|
||||||
t.Error("Expected bitmap cached", cached)
|
t.Error("Expected 1 item cached", cached)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
{
|
{
|
||||||
cached := cache.Lookup(chunk2p, "bar")
|
cached := cache.Lookup(chunk2p, "bar")
|
||||||
if cached == nil || cached[1] != 2 {
|
if cached == nil || len(cached) != 2 {
|
||||||
t.Error("Expected bitmap cached", cached)
|
t.Error("Expected 2 items cached", cached)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
{
|
{
|
||||||
cached := cache.Lookup(chunk1p, "foobar")
|
cached := cache.Lookup(chunk1p, "foobar")
|
||||||
if cached != nil {
|
if cached != nil {
|
||||||
t.Error("Expected nil cached", cached)
|
t.Error("Expected 0 item cached", cached)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -41,31 +41,10 @@ func (c *Chunk) IsFull() bool {
|
|||||||
return c.count == chunkSize
|
return c.count == chunkSize
|
||||||
}
|
}
|
||||||
|
|
||||||
func (c *Chunk) lastIndex(minValue int32) int32 {
|
|
||||||
if c.count == 0 {
|
|
||||||
return minValue
|
|
||||||
}
|
|
||||||
return c.items[c.count-1].Index() + 1 // Exclusive
|
|
||||||
}
|
|
||||||
|
|
||||||
func (cl *ChunkList) lastChunk() *Chunk {
|
func (cl *ChunkList) lastChunk() *Chunk {
|
||||||
return cl.chunks[len(cl.chunks)-1]
|
return cl.chunks[len(cl.chunks)-1]
|
||||||
}
|
}
|
||||||
|
|
||||||
// GetItems returns the first n items from the given chunks
|
|
||||||
func GetItems(chunks []*Chunk, n int) []Item {
|
|
||||||
items := make([]Item, 0, n)
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
for i := 0; i < chunk.count && len(items) < n; i++ {
|
|
||||||
items = append(items, chunk.items[i])
|
|
||||||
}
|
|
||||||
if len(items) >= n {
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return items
|
|
||||||
}
|
|
||||||
|
|
||||||
// CountItems returns the total number of Items
|
// CountItems returns the total number of Items
|
||||||
func CountItems(cs []*Chunk) int {
|
func CountItems(cs []*Chunk) int {
|
||||||
if len(cs) == 0 {
|
if len(cs) == 0 {
|
||||||
@@ -99,21 +78,6 @@ func (cl *ChunkList) Clear() {
|
|||||||
cl.mutex.Unlock()
|
cl.mutex.Unlock()
|
||||||
}
|
}
|
||||||
|
|
||||||
// ForEachItem iterates all items and applies fn to each one.
|
|
||||||
// The done callback runs under the lock to safely update shared state.
|
|
||||||
func (cl *ChunkList) ForEachItem(fn func(*Item), done func()) {
|
|
||||||
cl.mutex.Lock()
|
|
||||||
for _, chunk := range cl.chunks {
|
|
||||||
for i := 0; i < chunk.count; i++ {
|
|
||||||
fn(&chunk.items[i])
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if done != nil {
|
|
||||||
done()
|
|
||||||
}
|
|
||||||
cl.mutex.Unlock()
|
|
||||||
}
|
|
||||||
|
|
||||||
// Snapshot returns immutable snapshot of the ChunkList
|
// Snapshot returns immutable snapshot of the ChunkList
|
||||||
func (cl *ChunkList) Snapshot(tail int) ([]*Chunk, int, bool) {
|
func (cl *ChunkList) Snapshot(tail int) ([]*Chunk, int, bool) {
|
||||||
cl.mutex.Lock()
|
cl.mutex.Lock()
|
||||||
|
|||||||
@@ -51,8 +51,8 @@ func TestChunkList(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Add more data
|
// Add more data
|
||||||
for i := range chunkSize * 2 {
|
for i := 0; i < chunkSize*2; i++ {
|
||||||
cl.Push(fmt.Appendf(nil, "item %d", i))
|
cl.Push([]byte(fmt.Sprintf("item %d", i)))
|
||||||
}
|
}
|
||||||
|
|
||||||
// Previous snapshot should remain the same
|
// Previous snapshot should remain the same
|
||||||
@@ -85,8 +85,8 @@ func TestChunkListTail(t *testing.T) {
|
|||||||
return true
|
return true
|
||||||
})
|
})
|
||||||
total := chunkSize*2 + chunkSize/2
|
total := chunkSize*2 + chunkSize/2
|
||||||
for i := range total {
|
for i := 0; i < total; i++ {
|
||||||
cl.Push(fmt.Appendf(nil, "item %d", i))
|
cl.Push([]byte(fmt.Sprintf("item %d", i)))
|
||||||
}
|
}
|
||||||
|
|
||||||
snapshot, count, changed := cl.Snapshot(0)
|
snapshot, count, changed := cl.Snapshot(0)
|
||||||
|
|||||||
+7
-9
@@ -26,26 +26,23 @@ const (
|
|||||||
previewCancelWait = 500 * time.Millisecond
|
previewCancelWait = 500 * time.Millisecond
|
||||||
previewChunkDelay = 100 * time.Millisecond
|
previewChunkDelay = 100 * time.Millisecond
|
||||||
previewDelayed = 500 * time.Millisecond
|
previewDelayed = 500 * time.Millisecond
|
||||||
maxPatternLength = 1000
|
maxPatternLength = 300
|
||||||
maxMulti = math.MaxInt32
|
maxMulti = math.MaxInt32
|
||||||
|
|
||||||
// Background processes
|
|
||||||
maxBgProcesses = 30
|
|
||||||
maxBgProcessesPerAction = 3
|
|
||||||
|
|
||||||
// Matcher
|
// Matcher
|
||||||
progressMinDuration = 200 * time.Millisecond
|
numPartitionsMultiplier = 8
|
||||||
|
maxPartitions = 32
|
||||||
|
progressMinDuration = 200 * time.Millisecond
|
||||||
|
|
||||||
// Capacity of each chunk
|
// Capacity of each chunk
|
||||||
chunkSize int = 1024
|
chunkSize int = 100
|
||||||
chunkBitWords = (chunkSize + 63) / 64
|
|
||||||
|
|
||||||
// Pre-allocated memory slices to minimize GC
|
// Pre-allocated memory slices to minimize GC
|
||||||
slab16Size int = 100 * 1024 // 200KB * 32 = 12.8MB
|
slab16Size int = 100 * 1024 // 200KB * 32 = 12.8MB
|
||||||
slab32Size int = 2048 // 8KB * 32 = 256KB
|
slab32Size int = 2048 // 8KB * 32 = 256KB
|
||||||
|
|
||||||
// Do not cache results of low selectivity queries
|
// Do not cache results of low selectivity queries
|
||||||
queryCacheMax int = chunkSize / 2
|
queryCacheMax int = chunkSize / 5
|
||||||
|
|
||||||
// Not to cache mergers with large lists
|
// Not to cache mergers with large lists
|
||||||
mergerCacheMax int = 100000
|
mergerCacheMax int = 100000
|
||||||
@@ -64,6 +61,7 @@ const (
|
|||||||
EvtSearchNew
|
EvtSearchNew
|
||||||
EvtSearchProgress
|
EvtSearchProgress
|
||||||
EvtSearchFin
|
EvtSearchFin
|
||||||
|
EvtHeader
|
||||||
EvtReady
|
EvtReady
|
||||||
EvtQuit
|
EvtQuit
|
||||||
)
|
)
|
||||||
|
|||||||
+80
-263
@@ -2,14 +2,10 @@
|
|||||||
package fzf
|
package fzf
|
||||||
|
|
||||||
import (
|
import (
|
||||||
"fmt"
|
|
||||||
"maps"
|
|
||||||
"math"
|
|
||||||
"os"
|
"os"
|
||||||
"sync"
|
"sync"
|
||||||
"time"
|
"time"
|
||||||
|
|
||||||
"github.com/junegunn/fzf/src/tui"
|
|
||||||
"github.com/junegunn/fzf/src/util"
|
"github.com/junegunn/fzf/src/util"
|
||||||
)
|
)
|
||||||
|
|
||||||
@@ -19,6 +15,7 @@ Reader -> EvtReadNew -> Matcher (restart)
|
|||||||
Terminal -> EvtSearchNew:bool -> Matcher (restart)
|
Terminal -> EvtSearchNew:bool -> Matcher (restart)
|
||||||
Matcher -> EvtSearchProgress -> Terminal (update info)
|
Matcher -> EvtSearchProgress -> Terminal (update info)
|
||||||
Matcher -> EvtSearchFin -> Terminal (update list)
|
Matcher -> EvtSearchFin -> Terminal (update list)
|
||||||
|
Matcher -> EvtHeader -> Terminal (update header)
|
||||||
*/
|
*/
|
||||||
|
|
||||||
type revision struct {
|
type revision struct {
|
||||||
@@ -39,27 +36,12 @@ func (r revision) compatible(other revision) bool {
|
|||||||
return r.major == other.major
|
return r.major == other.major
|
||||||
}
|
}
|
||||||
|
|
||||||
func buildItemTransformer(opts *Options) func(*Item) string {
|
|
||||||
if opts.AcceptNth != nil {
|
|
||||||
fn := opts.AcceptNth(opts.Delimiter)
|
|
||||||
return func(item *Item) string {
|
|
||||||
return item.acceptNth(opts.Ansi, opts.Delimiter, fn)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return func(item *Item) string {
|
|
||||||
return item.AsString(opts.Ansi)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Run starts fzf
|
// Run starts fzf
|
||||||
func Run(opts *Options) (int, error) {
|
func Run(opts *Options) (int, error) {
|
||||||
if opts.Filter == nil {
|
if opts.Filter == nil {
|
||||||
if opts.useTmux() {
|
if opts.Tmux != nil && len(os.Getenv("TMUX")) > 0 && opts.Tmux.index >= opts.Height.index {
|
||||||
return runTmux(os.Args, opts)
|
return runTmux(os.Args, opts)
|
||||||
}
|
}
|
||||||
if opts.useZellij() {
|
|
||||||
return runZellij(os.Args, opts)
|
|
||||||
}
|
|
||||||
|
|
||||||
if needWinpty(opts) {
|
if needWinpty(opts) {
|
||||||
return runWinpty(os.Args, opts)
|
return runWinpty(os.Args, opts)
|
||||||
@@ -92,24 +74,20 @@ func Run(opts *Options) (int, error) {
|
|||||||
|
|
||||||
var lineAnsiState, prevLineAnsiState *ansiState
|
var lineAnsiState, prevLineAnsiState *ansiState
|
||||||
if opts.Ansi {
|
if opts.Ansi {
|
||||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
if opts.Theme.Colored {
|
||||||
prevLineAnsiState = lineAnsiState
|
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||||
trimmed, offsets, newState := extractColor(byteString(data), lineAnsiState, nil)
|
prevLineAnsiState = lineAnsiState
|
||||||
lineAnsiState = newState
|
trimmed, offsets, newState := extractColor(byteString(data), lineAnsiState, nil)
|
||||||
|
lineAnsiState = newState
|
||||||
// Full line background is found. Add a special marker.
|
return util.ToChars(stringBytes(trimmed)), offsets
|
||||||
if offsets != nil && newState != nil && len(*offsets) > 0 && newState.lbg >= 0 {
|
}
|
||||||
marker := (*offsets)[len(*offsets)-1]
|
} else {
|
||||||
marker.offset[0] = marker.offset[1]
|
// When color is disabled but ansi option is given,
|
||||||
marker.color.bg = newState.lbg
|
// we simply strip out ANSI codes from the input
|
||||||
marker.color.attr = marker.color.attr | tui.FullBg
|
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||||
newOffsets := append(*offsets, marker)
|
trimmed, _, _ := extractColor(byteString(data), nil, nil)
|
||||||
offsets = &newOffsets
|
return util.ToChars(stringBytes(trimmed)), nil
|
||||||
|
|
||||||
// Reset the full-line background color
|
|
||||||
lineAnsiState.lbg = -1
|
|
||||||
}
|
}
|
||||||
return util.ToChars(stringBytes(trimmed)), offsets
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -117,57 +95,47 @@ func Run(opts *Options) (int, error) {
|
|||||||
cache := NewChunkCache()
|
cache := NewChunkCache()
|
||||||
var chunkList *ChunkList
|
var chunkList *ChunkList
|
||||||
var itemIndex int32
|
var itemIndex int32
|
||||||
// transformItem applies with-nth transformation to an item's raw data.
|
header := make([]string, 0, opts.HeaderLines)
|
||||||
// It handles ANSI token propagation using prevLineAnsiState for cross-line continuity.
|
if len(opts.WithNth) == 0 {
|
||||||
transformItem := func(item *Item, data []byte, transformer func([]Token, int32) string, index int32) {
|
|
||||||
tokens := Tokenize(byteString(data), opts.Delimiter)
|
|
||||||
if opts.Ansi && len(tokens) > 1 {
|
|
||||||
var ansiState *ansiState
|
|
||||||
if prevLineAnsiState != nil {
|
|
||||||
ansiStateDup := *prevLineAnsiState
|
|
||||||
ansiState = &ansiStateDup
|
|
||||||
}
|
|
||||||
for _, token := range tokens {
|
|
||||||
prevAnsiState := ansiState
|
|
||||||
_, _, ansiState = extractColor(token.text.ToString(), ansiState, nil)
|
|
||||||
if prevAnsiState != nil {
|
|
||||||
token.text.Prepend("\x1b[m" + prevAnsiState.ToString())
|
|
||||||
} else {
|
|
||||||
token.text.Prepend("\x1b[m")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
transformed := transformer(tokens, index)
|
|
||||||
item.text, item.colors = ansiProcessor(stringBytes(transformed))
|
|
||||||
|
|
||||||
// We should not trim trailing whitespaces with background colors
|
|
||||||
var maxColorOffset int32
|
|
||||||
if item.colors != nil {
|
|
||||||
for _, ansi := range *item.colors {
|
|
||||||
if ansi.color.bg >= 0 {
|
|
||||||
maxColorOffset = max(maxColorOffset, ansi.offset[1])
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
item.text.TrimTrailingWhitespaces(int(maxColorOffset))
|
|
||||||
}
|
|
||||||
|
|
||||||
var nthTransformer func([]Token, int32) string
|
|
||||||
if opts.WithNth == nil {
|
|
||||||
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
||||||
|
if len(header) < opts.HeaderLines {
|
||||||
|
header = append(header, byteString(data))
|
||||||
|
eventBox.Set(EvtHeader, header)
|
||||||
|
return false
|
||||||
|
}
|
||||||
item.text, item.colors = ansiProcessor(data)
|
item.text, item.colors = ansiProcessor(data)
|
||||||
item.text.Index = itemIndex
|
item.text.Index = itemIndex
|
||||||
itemIndex++
|
itemIndex++
|
||||||
return true
|
return true
|
||||||
})
|
})
|
||||||
} else {
|
} else {
|
||||||
nthTransformer = opts.WithNth(opts.Delimiter)
|
|
||||||
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
chunkList = NewChunkList(cache, func(item *Item, data []byte) bool {
|
||||||
if nthTransformer == nil {
|
tokens := Tokenize(byteString(data), opts.Delimiter)
|
||||||
item.text, item.colors = ansiProcessor(data)
|
if opts.Ansi && opts.Theme.Colored && len(tokens) > 1 {
|
||||||
} else {
|
var ansiState *ansiState
|
||||||
transformItem(item, data, nthTransformer, itemIndex)
|
if prevLineAnsiState != nil {
|
||||||
|
ansiStateDup := *prevLineAnsiState
|
||||||
|
ansiState = &ansiStateDup
|
||||||
|
}
|
||||||
|
for _, token := range tokens {
|
||||||
|
prevAnsiState := ansiState
|
||||||
|
_, _, ansiState = extractColor(token.text.ToString(), ansiState, nil)
|
||||||
|
if prevAnsiState != nil {
|
||||||
|
token.text.Prepend("\x1b[m" + prevAnsiState.ToString())
|
||||||
|
} else {
|
||||||
|
token.text.Prepend("\x1b[m")
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
trans := Transform(tokens, opts.WithNth)
|
||||||
|
transformed := joinTokens(trans)
|
||||||
|
if len(header) < opts.HeaderLines {
|
||||||
|
header = append(header, transformed)
|
||||||
|
eventBox.Set(EvtHeader, header)
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
item.text, item.colors = ansiProcessor(stringBytes(transformed))
|
||||||
|
item.text.TrimTrailingWhitespaces()
|
||||||
item.text.Index = itemIndex
|
item.text.Index = itemIndex
|
||||||
item.origText = &data
|
item.origText = &data
|
||||||
itemIndex++
|
itemIndex++
|
||||||
@@ -197,18 +165,14 @@ func Run(opts *Options) (int, error) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Reader
|
// Reader
|
||||||
streamingFilter := opts.Filter != nil && !sort && !opts.Tac && !opts.Sync && opts.Bench == 0
|
streamingFilter := opts.Filter != nil && !sort && !opts.Tac && !opts.Sync
|
||||||
var reader *Reader
|
var reader *Reader
|
||||||
var ingestionStart time.Time
|
|
||||||
if !streamingFilter {
|
if !streamingFilter {
|
||||||
reader = NewReader(func(data []byte) bool {
|
reader = NewReader(func(data []byte) bool {
|
||||||
return chunkList.Push(data)
|
return chunkList.Push(data)
|
||||||
}, eventBox, executor, opts.ReadZero, opts.Filter == nil)
|
}, eventBox, executor, opts.ReadZero, opts.Filter == nil)
|
||||||
|
|
||||||
ingestionStart = time.Now()
|
go reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv)
|
||||||
readyChan := make(chan bool)
|
|
||||||
go reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv, readyChan)
|
|
||||||
<-readyChan
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// Matcher
|
// Matcher
|
||||||
@@ -222,40 +186,17 @@ func Run(opts *Options) (int, error) {
|
|||||||
forward = false
|
forward = false
|
||||||
case byBegin:
|
case byBegin:
|
||||||
forward = true
|
forward = true
|
||||||
case byPathname:
|
|
||||||
withPos = true
|
|
||||||
forward = false
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
nth := opts.Nth
|
|
||||||
inputRevision := revision{}
|
|
||||||
snapshotRevision := revision{}
|
|
||||||
patternCache := make(map[string]*Pattern)
|
patternCache := make(map[string]*Pattern)
|
||||||
denyMutex := sync.Mutex{}
|
|
||||||
denylist := make(map[int32]struct{})
|
|
||||||
clearDenylist := func() {
|
|
||||||
denyMutex.Lock()
|
|
||||||
if len(denylist) > 0 {
|
|
||||||
patternCache = make(map[string]*Pattern)
|
|
||||||
}
|
|
||||||
denylist = make(map[int32]struct{})
|
|
||||||
denyMutex.Unlock()
|
|
||||||
}
|
|
||||||
if opts.HeaderLines > math.MaxInt32 {
|
|
||||||
opts.HeaderLines = math.MaxInt32
|
|
||||||
}
|
|
||||||
headerLines := int32(opts.HeaderLines)
|
|
||||||
headerUpdated := false
|
|
||||||
patternBuilder := func(runes []rune) *Pattern {
|
patternBuilder := func(runes []rune) *Pattern {
|
||||||
denyMutex.Lock()
|
|
||||||
denylistCopy := maps.Clone(denylist)
|
|
||||||
denyMutex.Unlock()
|
|
||||||
return BuildPattern(cache, patternCache,
|
return BuildPattern(cache, patternCache,
|
||||||
opts.Fuzzy, opts.FuzzyAlgo, opts.Extended, opts.Case, opts.Normalize, forward, withPos,
|
opts.Fuzzy, opts.FuzzyAlgo, opts.Extended, opts.Case, opts.Normalize, forward, withPos,
|
||||||
opts.Filter == nil, nth, opts.Delimiter, inputRevision, runes, denylistCopy, headerLines)
|
opts.Filter == nil, opts.Nth, opts.Delimiter, runes)
|
||||||
}
|
}
|
||||||
matcher := NewMatcher(cache, patternBuilder, sort, opts.Tac, eventBox, inputRevision, opts.Threads)
|
inputRevision := revision{}
|
||||||
|
snapshotRevision := revision{}
|
||||||
|
matcher := NewMatcher(cache, patternBuilder, sort, opts.Tac, eventBox, inputRevision)
|
||||||
|
|
||||||
// Filtering mode
|
// Filtering mode
|
||||||
if opts.Filter != nil {
|
if opts.Filter != nil {
|
||||||
@@ -266,8 +207,6 @@ func Run(opts *Options) (int, error) {
|
|||||||
pattern := patternBuilder([]rune(*opts.Filter))
|
pattern := patternBuilder([]rune(*opts.Filter))
|
||||||
matcher.sort = pattern.sortable
|
matcher.sort = pattern.sortable
|
||||||
|
|
||||||
transformer := buildItemTransformer(opts)
|
|
||||||
|
|
||||||
found := false
|
found := false
|
||||||
if streamingFilter {
|
if streamingFilter {
|
||||||
slab := util.MakeSlab(slab16Size, slab32Size)
|
slab := util.MakeSlab(slab16Size, slab32Size)
|
||||||
@@ -276,72 +215,27 @@ func Run(opts *Options) (int, error) {
|
|||||||
func(runes []byte) bool {
|
func(runes []byte) bool {
|
||||||
item := Item{}
|
item := Item{}
|
||||||
if chunkList.trans(&item, runes) {
|
if chunkList.trans(&item, runes) {
|
||||||
if item.Index() < headerLines {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
mutex.Lock()
|
mutex.Lock()
|
||||||
if result, _, _ := pattern.MatchItem(&item, false, slab); result.item != nil {
|
if result, _, _ := pattern.MatchItem(&item, false, slab); result != nil {
|
||||||
opts.Printer(transformer(&item))
|
opts.Printer(item.text.ToString())
|
||||||
found = true
|
found = true
|
||||||
}
|
}
|
||||||
mutex.Unlock()
|
mutex.Unlock()
|
||||||
}
|
}
|
||||||
return false
|
return false
|
||||||
}, eventBox, executor, opts.ReadZero, false)
|
}, eventBox, executor, opts.ReadZero, false)
|
||||||
reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv, nil)
|
reader.ReadSource(opts.Input, opts.WalkerRoot, opts.WalkerOpts, opts.WalkerSkip, initialReload, initialEnv)
|
||||||
} else {
|
} else {
|
||||||
eventBox.Unwatch(EvtReadNew)
|
eventBox.Unwatch(EvtReadNew)
|
||||||
eventBox.WaitFor(EvtReadFin)
|
eventBox.WaitFor(EvtReadFin)
|
||||||
ingestionTime := time.Since(ingestionStart)
|
|
||||||
|
|
||||||
// NOTE: Streaming filter is inherently not compatible with --tail
|
// NOTE: Streaming filter is inherently not compatible with --tail
|
||||||
snapshot, _, _ := chunkList.Snapshot(opts.Tail)
|
snapshot, _, _ := chunkList.Snapshot(opts.Tail)
|
||||||
|
merger, _ := matcher.scan(MatchRequest{
|
||||||
if opts.Bench > 0 {
|
|
||||||
// Benchmark mode: repeat scan for the given duration
|
|
||||||
totalItems := CountItems(snapshot)
|
|
||||||
var matchCount int
|
|
||||||
var times []time.Duration
|
|
||||||
deadline := time.Now().Add(opts.Bench)
|
|
||||||
for time.Now().Before(deadline) {
|
|
||||||
cache.Clear()
|
|
||||||
start := time.Now()
|
|
||||||
result := matcher.scan(MatchRequest{
|
|
||||||
chunks: snapshot,
|
|
||||||
pattern: pattern})
|
|
||||||
times = append(times, time.Since(start))
|
|
||||||
matchCount = result.merger.Length()
|
|
||||||
}
|
|
||||||
// Print stats
|
|
||||||
var total time.Duration
|
|
||||||
minD, maxD := times[0], times[0]
|
|
||||||
for _, d := range times {
|
|
||||||
total += d
|
|
||||||
if d < minD {
|
|
||||||
minD = d
|
|
||||||
}
|
|
||||||
if d > maxD {
|
|
||||||
maxD = d
|
|
||||||
}
|
|
||||||
}
|
|
||||||
avg := total / time.Duration(len(times))
|
|
||||||
selectivity := float64(matchCount) / float64(totalItems) * 100
|
|
||||||
fmt.Printf(" %d iterations avg: %.2fms min: %.2fms max: %.2fms total: %.2fs items: %d matches: %d (%.2f%%) ingestion: %.2fms\n",
|
|
||||||
len(times),
|
|
||||||
float64(avg.Microseconds())/1000,
|
|
||||||
float64(minD.Microseconds())/1000,
|
|
||||||
float64(maxD.Microseconds())/1000,
|
|
||||||
total.Seconds(),
|
|
||||||
totalItems, matchCount, selectivity,
|
|
||||||
float64(ingestionTime.Microseconds())/1000)
|
|
||||||
return ExitOk, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
result := matcher.scan(MatchRequest{
|
|
||||||
chunks: snapshot,
|
chunks: snapshot,
|
||||||
pattern: pattern})
|
pattern: pattern})
|
||||||
for i := 0; i < result.merger.Length(); i++ {
|
for i := 0; i < merger.Length(); i++ {
|
||||||
opts.Printer(transformer(result.merger.Get(i).item))
|
opts.Printer(merger.Get(i).item.AsString(opts.Ansi))
|
||||||
found = true
|
found = true
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -378,7 +272,6 @@ func Run(opts *Options) (int, error) {
|
|||||||
// Event coordination
|
// Event coordination
|
||||||
reading := true
|
reading := true
|
||||||
ticks := 0
|
ticks := 0
|
||||||
startTick := 0
|
|
||||||
var nextCommand *commandSpec
|
var nextCommand *commandSpec
|
||||||
var nextEnviron []string
|
var nextEnviron []string
|
||||||
eventBox.Watch(EvtReadNew)
|
eventBox.Watch(EvtReadNew)
|
||||||
@@ -386,11 +279,10 @@ func Run(opts *Options) (int, error) {
|
|||||||
query := []rune{}
|
query := []rune{}
|
||||||
determine := func(final bool) {
|
determine := func(final bool) {
|
||||||
if heightUnknown {
|
if heightUnknown {
|
||||||
items := max(0, total-int(headerLines))
|
if total >= maxFit || final {
|
||||||
if items >= maxFit || final {
|
|
||||||
deferred = false
|
deferred = false
|
||||||
heightUnknown = false
|
heightUnknown = false
|
||||||
terminal.startChan <- fitpad{min(items, maxFit), padHeight}
|
terminal.startChan <- fitpad{util.Min(total, maxFit), padHeight}
|
||||||
}
|
}
|
||||||
} else if deferred {
|
} else if deferred {
|
||||||
deferred = false
|
deferred = false
|
||||||
@@ -402,18 +294,12 @@ func Run(opts *Options) (int, error) {
|
|||||||
var snapshot []*Chunk
|
var snapshot []*Chunk
|
||||||
var count int
|
var count int
|
||||||
restart := func(command commandSpec, environ []string) {
|
restart := func(command commandSpec, environ []string) {
|
||||||
if !useSnapshot {
|
|
||||||
clearDenylist()
|
|
||||||
}
|
|
||||||
reading = true
|
reading = true
|
||||||
headerUpdated = false
|
|
||||||
startTick = ticks
|
|
||||||
chunkList.Clear()
|
chunkList.Clear()
|
||||||
itemIndex = 0
|
itemIndex = 0
|
||||||
inputRevision.bumpMajor()
|
inputRevision.bumpMajor()
|
||||||
readyChan := make(chan bool)
|
header = make([]string, 0, opts.HeaderLines)
|
||||||
go reader.restart(command, environ, readyChan)
|
go reader.restart(command, environ)
|
||||||
<-readyChan
|
|
||||||
}
|
}
|
||||||
|
|
||||||
exitCode := ExitOk
|
exitCode := ExitOk
|
||||||
@@ -452,8 +338,7 @@ func Run(opts *Options) (int, error) {
|
|||||||
} else {
|
} else {
|
||||||
reading = reading && evt == EvtReadNew
|
reading = reading && evt == EvtReadNew
|
||||||
}
|
}
|
||||||
if useSnapshot && evt == EvtReadFin { // reload-sync
|
if useSnapshot && evt == EvtReadFin {
|
||||||
clearDenylist()
|
|
||||||
useSnapshot = false
|
useSnapshot = false
|
||||||
}
|
}
|
||||||
if !useSnapshot {
|
if !useSnapshot {
|
||||||
@@ -468,83 +353,22 @@ func Run(opts *Options) (int, error) {
|
|||||||
snapshotRevision = inputRevision
|
snapshotRevision = inputRevision
|
||||||
}
|
}
|
||||||
total = count
|
total = count
|
||||||
terminal.UpdateCount(max(0, total-int(headerLines)), !reading, value.(*string))
|
terminal.UpdateCount(total, !reading, value.(*string))
|
||||||
if headerLines > 0 && !headerUpdated {
|
|
||||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
|
||||||
headerUpdated = total >= int(headerLines)
|
|
||||||
}
|
|
||||||
if heightUnknown && !deferred {
|
if heightUnknown && !deferred {
|
||||||
determine(!reading)
|
determine(!reading)
|
||||||
}
|
}
|
||||||
if !useSnapshot || evt == EvtReadFin {
|
matcher.Reset(snapshot, input(), false, !reading, sort, snapshotRevision)
|
||||||
matcher.Reset(snapshot, input(), false, !reading, sort, snapshotRevision)
|
|
||||||
}
|
|
||||||
|
|
||||||
case EvtSearchNew:
|
case EvtSearchNew:
|
||||||
var command *commandSpec
|
var command *commandSpec
|
||||||
var environ []string
|
var environ []string
|
||||||
var changed bool
|
var changed bool
|
||||||
headerLinesChanged := false
|
|
||||||
withNthChanged := false
|
|
||||||
switch val := value.(type) {
|
switch val := value.(type) {
|
||||||
case searchRequest:
|
case searchRequest:
|
||||||
sort = val.sort
|
sort = val.sort
|
||||||
command = val.command
|
command = val.command
|
||||||
environ = val.environ
|
environ = val.environ
|
||||||
changed = val.changed
|
changed = val.changed
|
||||||
bump := false
|
|
||||||
if len(val.denylist) > 0 && val.revision.compatible(inputRevision) {
|
|
||||||
denyMutex.Lock()
|
|
||||||
for _, itemIndex := range val.denylist {
|
|
||||||
denylist[itemIndex] = struct{}{}
|
|
||||||
}
|
|
||||||
denyMutex.Unlock()
|
|
||||||
bump = true
|
|
||||||
}
|
|
||||||
if val.nth != nil {
|
|
||||||
// Change nth and clear caches
|
|
||||||
nth = *val.nth
|
|
||||||
bump = true
|
|
||||||
}
|
|
||||||
if val.headerLines != nil {
|
|
||||||
headerLines = int32(*val.headerLines)
|
|
||||||
headerUpdated = false
|
|
||||||
headerLinesChanged = true
|
|
||||||
bump = true
|
|
||||||
}
|
|
||||||
if val.withNth != nil {
|
|
||||||
newTransformer := val.withNth.fn
|
|
||||||
// Cancel any in-flight scan and block the terminal from reading
|
|
||||||
// items before mutating them in-place. Snapshot shares middle
|
|
||||||
// chunk pointers, so the matcher and terminal can race with us.
|
|
||||||
matcher.CancelScan()
|
|
||||||
terminal.PauseRendering()
|
|
||||||
// Reset cross-line ANSI state before re-processing all items
|
|
||||||
lineAnsiState = nil
|
|
||||||
prevLineAnsiState = nil
|
|
||||||
chunkList.ForEachItem(func(item *Item) {
|
|
||||||
origBytes := *item.origText
|
|
||||||
savedIndex := item.Index()
|
|
||||||
if newTransformer != nil {
|
|
||||||
transformItem(item, origBytes, newTransformer, savedIndex)
|
|
||||||
} else {
|
|
||||||
item.text, item.colors = ansiProcessor(origBytes)
|
|
||||||
}
|
|
||||||
item.text.Index = savedIndex
|
|
||||||
item.transformed = nil
|
|
||||||
}, func() {
|
|
||||||
nthTransformer = newTransformer
|
|
||||||
})
|
|
||||||
terminal.ResumeRendering()
|
|
||||||
matcher.ResumeScan()
|
|
||||||
withNthChanged = true
|
|
||||||
bump = true
|
|
||||||
}
|
|
||||||
if bump {
|
|
||||||
patternCache = make(map[string]*Pattern)
|
|
||||||
cache.Clear()
|
|
||||||
inputRevision.bumpMinor()
|
|
||||||
}
|
|
||||||
if command != nil {
|
if command != nil {
|
||||||
useSnapshot = val.sync
|
useSnapshot = val.sync
|
||||||
}
|
}
|
||||||
@@ -576,16 +400,6 @@ func Run(opts *Options) (int, error) {
|
|||||||
snapshotRevision = inputRevision
|
snapshotRevision = inputRevision
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
if headerLinesChanged {
|
|
||||||
terminal.UpdateCount(max(0, total-int(headerLines)), !reading, nil)
|
|
||||||
if headerLines > 0 {
|
|
||||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
|
||||||
} else {
|
|
||||||
terminal.UpdateHeader(nil)
|
|
||||||
}
|
|
||||||
} else if withNthChanged && headerLines > 0 {
|
|
||||||
terminal.UpdateHeader(GetItems(snapshot, int(headerLines)))
|
|
||||||
}
|
|
||||||
matcher.Reset(snapshot, input(), true, !reading, sort, snapshotRevision)
|
matcher.Reset(snapshot, input(), true, !reading, sort, snapshotRevision)
|
||||||
delay = false
|
delay = false
|
||||||
|
|
||||||
@@ -595,15 +409,19 @@ func Run(opts *Options) (int, error) {
|
|||||||
terminal.UpdateProgress(val)
|
terminal.UpdateProgress(val)
|
||||||
}
|
}
|
||||||
|
|
||||||
|
case EvtHeader:
|
||||||
|
headerPadded := make([]string, opts.HeaderLines)
|
||||||
|
copy(headerPadded, value.([]string))
|
||||||
|
terminal.UpdateHeader(headerPadded)
|
||||||
|
|
||||||
case EvtSearchFin:
|
case EvtSearchFin:
|
||||||
switch val := value.(type) {
|
switch val := value.(type) {
|
||||||
case MatchResult:
|
case *Merger:
|
||||||
merger := val.merger
|
|
||||||
if deferred {
|
if deferred {
|
||||||
count := merger.Length()
|
count := val.Length()
|
||||||
if opts.Select1 && count > 1 || opts.Exit0 && !opts.Select1 && count > 0 {
|
if opts.Select1 && count > 1 || opts.Exit0 && !opts.Select1 && count > 0 {
|
||||||
determine(merger.final)
|
determine(val.final)
|
||||||
} else if merger.final {
|
} else if val.final {
|
||||||
if opts.Exit0 && count == 0 || opts.Select1 && count == 1 {
|
if opts.Exit0 && count == 0 || opts.Select1 && count == 1 {
|
||||||
if opts.PrintQuery {
|
if opts.PrintQuery {
|
||||||
opts.Printer(opts.Query)
|
opts.Printer(opts.Query)
|
||||||
@@ -611,9 +429,8 @@ func Run(opts *Options) (int, error) {
|
|||||||
if len(opts.Expect) > 0 {
|
if len(opts.Expect) > 0 {
|
||||||
opts.Printer("")
|
opts.Printer("")
|
||||||
}
|
}
|
||||||
transformer := buildItemTransformer(opts)
|
for i := 0; i < count; i++ {
|
||||||
for i := range count {
|
opts.Printer(val.Get(i).item.AsString(opts.Ansi))
|
||||||
opts.Printer(transformer(merger.Get(i).item))
|
|
||||||
}
|
}
|
||||||
if count == 0 {
|
if count == 0 {
|
||||||
exitCode = ExitNoMatch
|
exitCode = ExitNoMatch
|
||||||
@@ -621,7 +438,7 @@ func Run(opts *Options) (int, error) {
|
|||||||
stop = true
|
stop = true
|
||||||
return
|
return
|
||||||
}
|
}
|
||||||
determine(merger.final)
|
determine(val.final)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
terminal.UpdateList(val)
|
terminal.UpdateList(val)
|
||||||
@@ -634,8 +451,8 @@ func Run(opts *Options) (int, error) {
|
|||||||
break
|
break
|
||||||
}
|
}
|
||||||
if delay && reading {
|
if delay && reading {
|
||||||
dur := util.Constrain(
|
dur := util.DurWithin(
|
||||||
time.Duration(ticks-startTick)*coordinatorDelayStep,
|
time.Duration(ticks)*coordinatorDelayStep,
|
||||||
0, coordinatorDelayMax)
|
0, coordinatorDelayMax)
|
||||||
time.Sleep(dur)
|
time.Sleep(dur)
|
||||||
}
|
}
|
||||||
|
|||||||
+1
-1
@@ -38,7 +38,7 @@ func TestHistory(t *testing.T) {
|
|||||||
if len(h.lines) != maxHistory+1 {
|
if len(h.lines) != maxHistory+1 {
|
||||||
t.Errorf("Expected: %d, actual: %d\n", maxHistory+1, len(h.lines))
|
t.Errorf("Expected: %d, actual: %d\n", maxHistory+1, len(h.lines))
|
||||||
}
|
}
|
||||||
for i := range maxHistory {
|
for i := 0; i < maxHistory; i++ {
|
||||||
if h.lines[i] != "foobar" {
|
if h.lines[i] != "foobar" {
|
||||||
t.Error("Expected: foobar, actual: " + h.lines[i])
|
t.Error("Expected: foobar, actual: " + h.lines[i])
|
||||||
}
|
}
|
||||||
|
|||||||
+1
-14
@@ -6,17 +6,10 @@ import (
|
|||||||
"github.com/junegunn/fzf/src/util"
|
"github.com/junegunn/fzf/src/util"
|
||||||
)
|
)
|
||||||
|
|
||||||
type transformed struct {
|
|
||||||
// Because nth can be changed dynamically by change-nth action, we need to
|
|
||||||
// keep the revision number at the time of transformation.
|
|
||||||
revision revision
|
|
||||||
tokens []Token
|
|
||||||
}
|
|
||||||
|
|
||||||
// Item represents each input line. 56 bytes.
|
// Item represents each input line. 56 bytes.
|
||||||
type Item struct {
|
type Item struct {
|
||||||
text util.Chars // 32 = 24 + 1 + 1 + 2 + 4
|
text util.Chars // 32 = 24 + 1 + 1 + 2 + 4
|
||||||
transformed *transformed // 8
|
transformed *[]Token // 8
|
||||||
origText *[]byte // 8
|
origText *[]byte // 8
|
||||||
colors *[]ansiOffset // 8
|
colors *[]ansiOffset // 8
|
||||||
}
|
}
|
||||||
@@ -51,9 +44,3 @@ func (item *Item) AsString(stripAnsi bool) string {
|
|||||||
}
|
}
|
||||||
return item.text.ToString()
|
return item.text.ToString()
|
||||||
}
|
}
|
||||||
|
|
||||||
func (item *Item) acceptNth(stripAnsi bool, delimiter Delimiter, transformer func([]Token, int32) string) string {
|
|
||||||
tokens := Tokenize(item.AsString(stripAnsi), delimiter)
|
|
||||||
transformed := transformer(tokens, item.Index())
|
|
||||||
return StripLastDelimiter(transformed, delimiter)
|
|
||||||
}
|
|
||||||
|
|||||||
+73
-87
@@ -3,8 +3,8 @@ package fzf
|
|||||||
import (
|
import (
|
||||||
"fmt"
|
"fmt"
|
||||||
"runtime"
|
"runtime"
|
||||||
|
"sort"
|
||||||
"sync"
|
"sync"
|
||||||
"sync/atomic"
|
|
||||||
"time"
|
"time"
|
||||||
|
|
||||||
"github.com/junegunn/fzf/src/util"
|
"github.com/junegunn/fzf/src/util"
|
||||||
@@ -19,20 +19,6 @@ type MatchRequest struct {
|
|||||||
revision revision
|
revision revision
|
||||||
}
|
}
|
||||||
|
|
||||||
type MatchResult struct {
|
|
||||||
merger *Merger
|
|
||||||
passMerger *Merger
|
|
||||||
cancelled bool
|
|
||||||
}
|
|
||||||
|
|
||||||
func (mr MatchResult) cacheable() bool {
|
|
||||||
return mr.merger != nil && mr.merger.cacheable()
|
|
||||||
}
|
|
||||||
|
|
||||||
func (mr MatchResult) final() bool {
|
|
||||||
return mr.merger != nil && mr.merger.final
|
|
||||||
}
|
|
||||||
|
|
||||||
// Matcher is responsible for performing search
|
// Matcher is responsible for performing search
|
||||||
type Matcher struct {
|
type Matcher struct {
|
||||||
cache *ChunkCache
|
cache *ChunkCache
|
||||||
@@ -43,11 +29,8 @@ type Matcher struct {
|
|||||||
reqBox *util.EventBox
|
reqBox *util.EventBox
|
||||||
partitions int
|
partitions int
|
||||||
slab []*util.Slab
|
slab []*util.Slab
|
||||||
sortBuf [][]Result
|
mergerCache map[string]*Merger
|
||||||
mergerCache map[string]MatchResult
|
|
||||||
revision revision
|
revision revision
|
||||||
scanMutex sync.Mutex
|
|
||||||
cancelScan *util.AtomicBool
|
|
||||||
}
|
}
|
||||||
|
|
||||||
const (
|
const (
|
||||||
@@ -57,11 +40,8 @@ const (
|
|||||||
|
|
||||||
// NewMatcher returns a new Matcher
|
// NewMatcher returns a new Matcher
|
||||||
func NewMatcher(cache *ChunkCache, patternBuilder func([]rune) *Pattern,
|
func NewMatcher(cache *ChunkCache, patternBuilder func([]rune) *Pattern,
|
||||||
sort bool, tac bool, eventBox *util.EventBox, revision revision, threads int) *Matcher {
|
sort bool, tac bool, eventBox *util.EventBox, revision revision) *Matcher {
|
||||||
partitions := runtime.NumCPU()
|
partitions := util.Min(numPartitionsMultiplier*runtime.NumCPU(), maxPartitions)
|
||||||
if threads > 0 {
|
|
||||||
partitions = threads
|
|
||||||
}
|
|
||||||
return &Matcher{
|
return &Matcher{
|
||||||
cache: cache,
|
cache: cache,
|
||||||
patternBuilder: patternBuilder,
|
patternBuilder: patternBuilder,
|
||||||
@@ -71,10 +51,8 @@ func NewMatcher(cache *ChunkCache, patternBuilder func([]rune) *Pattern,
|
|||||||
reqBox: util.NewEventBox(),
|
reqBox: util.NewEventBox(),
|
||||||
partitions: partitions,
|
partitions: partitions,
|
||||||
slab: make([]*util.Slab, partitions),
|
slab: make([]*util.Slab, partitions),
|
||||||
sortBuf: make([][]Result, partitions),
|
mergerCache: make(map[string]*Merger),
|
||||||
mergerCache: make(map[string]MatchResult),
|
revision: revision}
|
||||||
revision: revision,
|
|
||||||
cancelScan: util.NewAtomicBool(false)}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// Loop puts Matcher in action
|
// Loop puts Matcher in action
|
||||||
@@ -107,102 +85,125 @@ func (m *Matcher) Loop() {
|
|||||||
cacheCleared := false
|
cacheCleared := false
|
||||||
if request.sort != m.sort || request.revision != m.revision {
|
if request.sort != m.sort || request.revision != m.revision {
|
||||||
m.sort = request.sort
|
m.sort = request.sort
|
||||||
m.mergerCache = make(map[string]MatchResult)
|
m.revision = request.revision
|
||||||
|
m.mergerCache = make(map[string]*Merger)
|
||||||
if !request.revision.compatible(m.revision) {
|
if !request.revision.compatible(m.revision) {
|
||||||
m.cache.Clear()
|
m.cache.Clear()
|
||||||
}
|
}
|
||||||
m.revision = request.revision
|
|
||||||
cacheCleared = true
|
cacheCleared = true
|
||||||
}
|
}
|
||||||
|
|
||||||
// Restart search
|
// Restart search
|
||||||
patternString := request.pattern.AsString()
|
patternString := request.pattern.AsString()
|
||||||
var result MatchResult
|
var merger *Merger
|
||||||
|
cancelled := false
|
||||||
count := CountItems(request.chunks)
|
count := CountItems(request.chunks)
|
||||||
|
|
||||||
if !cacheCleared {
|
if !cacheCleared {
|
||||||
if count == prevCount {
|
if count == prevCount {
|
||||||
// Look up mergerCache
|
// Look up mergerCache
|
||||||
if cached, found := m.mergerCache[patternString]; found && cached.final() == request.final {
|
if cached, found := m.mergerCache[patternString]; found {
|
||||||
result = cached
|
merger = cached
|
||||||
}
|
}
|
||||||
} else {
|
} else {
|
||||||
// Invalidate mergerCache
|
// Invalidate mergerCache
|
||||||
prevCount = count
|
prevCount = count
|
||||||
m.mergerCache = make(map[string]MatchResult)
|
m.mergerCache = make(map[string]*Merger)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
if result.merger == nil {
|
if merger == nil {
|
||||||
m.scanMutex.Lock()
|
merger, cancelled = m.scan(request)
|
||||||
result = m.scan(request)
|
|
||||||
m.scanMutex.Unlock()
|
|
||||||
}
|
}
|
||||||
|
|
||||||
if !result.cancelled {
|
if !cancelled {
|
||||||
if result.cacheable() {
|
if merger.cacheable() {
|
||||||
m.mergerCache[patternString] = result
|
m.mergerCache[patternString] = merger
|
||||||
}
|
}
|
||||||
result.merger.final = request.final
|
merger.final = request.final
|
||||||
m.eventBox.Set(EvtSearchFin, result)
|
m.eventBox.Set(EvtSearchFin, merger)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
func (m *Matcher) sliceChunks(chunks []*Chunk) [][]*Chunk {
|
||||||
|
partitions := m.partitions
|
||||||
|
perSlice := len(chunks) / partitions
|
||||||
|
|
||||||
|
if perSlice == 0 {
|
||||||
|
partitions = len(chunks)
|
||||||
|
perSlice = 1
|
||||||
|
}
|
||||||
|
|
||||||
|
slices := make([][]*Chunk, partitions)
|
||||||
|
for i := 0; i < partitions; i++ {
|
||||||
|
start := i * perSlice
|
||||||
|
end := start + perSlice
|
||||||
|
if i == partitions-1 {
|
||||||
|
end = len(chunks)
|
||||||
|
}
|
||||||
|
slices[i] = chunks[start:end]
|
||||||
|
}
|
||||||
|
return slices
|
||||||
|
}
|
||||||
|
|
||||||
type partialResult struct {
|
type partialResult struct {
|
||||||
index int
|
index int
|
||||||
matches []Result
|
matches []Result
|
||||||
}
|
}
|
||||||
|
|
||||||
func (m *Matcher) scan(request MatchRequest) MatchResult {
|
func (m *Matcher) scan(request MatchRequest) (*Merger, bool) {
|
||||||
startedAt := time.Now()
|
startedAt := time.Now()
|
||||||
|
|
||||||
numChunks := len(request.chunks)
|
numChunks := len(request.chunks)
|
||||||
if numChunks == 0 {
|
if numChunks == 0 {
|
||||||
m := EmptyMerger(request.revision)
|
return EmptyMerger(request.revision), false
|
||||||
return MatchResult{m, m, false}
|
|
||||||
}
|
}
|
||||||
pattern := request.pattern
|
pattern := request.pattern
|
||||||
passMerger := PassMerger(&request.chunks, m.tac, request.revision, pattern.startIndex)
|
|
||||||
if pattern.IsEmpty() {
|
if pattern.IsEmpty() {
|
||||||
return MatchResult{passMerger, passMerger, false}
|
return PassMerger(&request.chunks, m.tac, request.revision), false
|
||||||
}
|
}
|
||||||
|
|
||||||
minIndex := request.chunks[0].items[0].Index()
|
minIndex := request.chunks[0].items[0].Index()
|
||||||
maxIndex := request.chunks[numChunks-1].lastIndex(minIndex)
|
|
||||||
cancelled := util.NewAtomicBool(false)
|
cancelled := util.NewAtomicBool(false)
|
||||||
|
|
||||||
numWorkers := min(m.partitions, numChunks)
|
slices := m.sliceChunks(request.chunks)
|
||||||
var nextChunk atomic.Int32
|
numSlices := len(slices)
|
||||||
resultChan := make(chan partialResult, numWorkers)
|
resultChan := make(chan partialResult, numSlices)
|
||||||
countChan := make(chan int, numChunks)
|
countChan := make(chan int, numChunks)
|
||||||
waitGroup := sync.WaitGroup{}
|
waitGroup := sync.WaitGroup{}
|
||||||
|
|
||||||
for idx := range numWorkers {
|
for idx, chunks := range slices {
|
||||||
waitGroup.Add(1)
|
waitGroup.Add(1)
|
||||||
if m.slab[idx] == nil {
|
if m.slab[idx] == nil {
|
||||||
m.slab[idx] = util.MakeSlab(slab16Size, slab32Size)
|
m.slab[idx] = util.MakeSlab(slab16Size, slab32Size)
|
||||||
}
|
}
|
||||||
go func(idx int, slab *util.Slab) {
|
go func(idx int, slab *util.Slab, chunks []*Chunk) {
|
||||||
defer waitGroup.Done()
|
defer func() { waitGroup.Done() }()
|
||||||
var matches []Result
|
count := 0
|
||||||
for {
|
allMatches := make([][]Result, len(chunks))
|
||||||
ci := int(nextChunk.Add(1)) - 1
|
for idx, chunk := range chunks {
|
||||||
if ci >= numChunks {
|
matches := request.pattern.Match(chunk, slab)
|
||||||
break
|
allMatches[idx] = matches
|
||||||
}
|
count += len(matches)
|
||||||
chunkMatches := request.pattern.Match(request.chunks[ci], slab)
|
|
||||||
matches = append(matches, chunkMatches...)
|
|
||||||
if cancelled.Get() {
|
if cancelled.Get() {
|
||||||
return
|
return
|
||||||
}
|
}
|
||||||
countChan <- len(chunkMatches)
|
countChan <- len(matches)
|
||||||
|
}
|
||||||
|
sliceMatches := make([]Result, 0, count)
|
||||||
|
for _, matches := range allMatches {
|
||||||
|
sliceMatches = append(sliceMatches, matches...)
|
||||||
}
|
}
|
||||||
if m.sort && request.pattern.sortable {
|
if m.sort && request.pattern.sortable {
|
||||||
m.sortBuf[idx] = radixSortResults(matches, m.tac, m.sortBuf[idx])
|
if m.tac {
|
||||||
|
sort.Sort(ByRelevanceTac(sliceMatches))
|
||||||
|
} else {
|
||||||
|
sort.Sort(ByRelevance(sliceMatches))
|
||||||
|
}
|
||||||
}
|
}
|
||||||
resultChan <- partialResult{idx, matches}
|
resultChan <- partialResult{idx, sliceMatches}
|
||||||
}(idx, m.slab[idx])
|
}(idx, m.slab[idx], chunks)
|
||||||
}
|
}
|
||||||
|
|
||||||
wait := func() bool {
|
wait := func() bool {
|
||||||
@@ -221,8 +222,8 @@ func (m *Matcher) scan(request MatchRequest) MatchResult {
|
|||||||
break
|
break
|
||||||
}
|
}
|
||||||
|
|
||||||
if m.cancelScan.Get() || m.reqBox.Peek(reqReset) {
|
if m.reqBox.Peek(reqReset) {
|
||||||
return MatchResult{nil, nil, wait()}
|
return nil, wait()
|
||||||
}
|
}
|
||||||
|
|
||||||
if time.Since(startedAt) > progressMinDuration {
|
if time.Since(startedAt) > progressMinDuration {
|
||||||
@@ -230,13 +231,12 @@ func (m *Matcher) scan(request MatchRequest) MatchResult {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
partialResults := make([][]Result, numWorkers)
|
partialResults := make([][]Result, numSlices)
|
||||||
for range numWorkers {
|
for range slices {
|
||||||
partialResult := <-resultChan
|
partialResult := <-resultChan
|
||||||
partialResults[partialResult.index] = partialResult.matches
|
partialResults[partialResult.index] = partialResult.matches
|
||||||
}
|
}
|
||||||
merger := NewMerger(pattern, partialResults, m.sort && request.pattern.sortable, m.tac, request.revision, minIndex, maxIndex)
|
return NewMerger(pattern, partialResults, m.sort && request.pattern.sortable, m.tac, request.revision, minIndex), false
|
||||||
return MatchResult{merger, passMerger, false}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// Reset is called to interrupt/signal the ongoing search
|
// Reset is called to interrupt/signal the ongoing search
|
||||||
@@ -252,20 +252,6 @@ func (m *Matcher) Reset(chunks []*Chunk, patternRunes []rune, cancel bool, final
|
|||||||
m.reqBox.Set(event, MatchRequest{chunks, pattern, final, sort, revision})
|
m.reqBox.Set(event, MatchRequest{chunks, pattern, final, sort, revision})
|
||||||
}
|
}
|
||||||
|
|
||||||
// CancelScan cancels any in-flight scan, waits for it to finish,
|
|
||||||
// and prevents new scans from starting until ResumeScan is called.
|
|
||||||
// This is used to safely mutate shared items (e.g., during with-nth changes).
|
|
||||||
func (m *Matcher) CancelScan() {
|
|
||||||
m.cancelScan.Set(true)
|
|
||||||
m.scanMutex.Lock()
|
|
||||||
m.cancelScan.Set(false)
|
|
||||||
}
|
|
||||||
|
|
||||||
// ResumeScan allows scans to proceed again after CancelScan.
|
|
||||||
func (m *Matcher) ResumeScan() {
|
|
||||||
m.scanMutex.Unlock()
|
|
||||||
}
|
|
||||||
|
|
||||||
func (m *Matcher) Stop() {
|
func (m *Matcher) Stop() {
|
||||||
m.reqBox.Set(reqQuit, nil)
|
m.reqBox.Set(reqQuit, nil)
|
||||||
}
|
}
|
||||||
|
|||||||
+33
-44
@@ -4,57 +4,50 @@ import "fmt"
|
|||||||
|
|
||||||
// EmptyMerger is a Merger with no data
|
// EmptyMerger is a Merger with no data
|
||||||
func EmptyMerger(revision revision) *Merger {
|
func EmptyMerger(revision revision) *Merger {
|
||||||
return NewMerger(nil, [][]Result{}, false, false, revision, 0, 0)
|
return NewMerger(nil, [][]Result{}, false, false, revision, 0)
|
||||||
}
|
}
|
||||||
|
|
||||||
// Merger holds a set of locally sorted lists of items and provides the view of
|
// Merger holds a set of locally sorted lists of items and provides the view of
|
||||||
// a single, globally-sorted list
|
// a single, globally-sorted list
|
||||||
type Merger struct {
|
type Merger struct {
|
||||||
pattern *Pattern
|
pattern *Pattern
|
||||||
lists [][]Result
|
lists [][]Result
|
||||||
merged []Result
|
merged []Result
|
||||||
chunks *[]*Chunk
|
chunks *[]*Chunk
|
||||||
cursors []int
|
cursors []int
|
||||||
sorted bool
|
sorted bool
|
||||||
tac bool
|
tac bool
|
||||||
final bool
|
final bool
|
||||||
count int
|
count int
|
||||||
pass bool
|
pass bool
|
||||||
startIndex int
|
revision revision
|
||||||
revision revision
|
minIndex int32
|
||||||
minIndex int32
|
|
||||||
maxIndex int32
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// PassMerger returns a new Merger that simply returns the items in the
|
// PassMerger returns a new Merger that simply returns the items in the
|
||||||
// original order. startIndex items are skipped from the beginning.
|
// original order
|
||||||
func PassMerger(chunks *[]*Chunk, tac bool, revision revision, startIndex int32) *Merger {
|
func PassMerger(chunks *[]*Chunk, tac bool, revision revision) *Merger {
|
||||||
var minIndex, maxIndex int32
|
var minIndex int32
|
||||||
if len(*chunks) > 0 {
|
if len(*chunks) > 0 {
|
||||||
minIndex = (*chunks)[0].items[0].Index()
|
minIndex = (*chunks)[0].items[0].Index()
|
||||||
maxIndex = (*chunks)[len(*chunks)-1].lastIndex(minIndex)
|
|
||||||
}
|
}
|
||||||
si := int(startIndex)
|
|
||||||
mg := Merger{
|
mg := Merger{
|
||||||
pattern: nil,
|
pattern: nil,
|
||||||
chunks: chunks,
|
chunks: chunks,
|
||||||
tac: tac,
|
tac: tac,
|
||||||
count: 0,
|
count: 0,
|
||||||
pass: true,
|
pass: true,
|
||||||
startIndex: si,
|
revision: revision,
|
||||||
revision: revision,
|
minIndex: minIndex}
|
||||||
minIndex: minIndex + startIndex,
|
|
||||||
maxIndex: maxIndex}
|
|
||||||
|
|
||||||
for _, chunk := range *mg.chunks {
|
for _, chunk := range *mg.chunks {
|
||||||
mg.count += chunk.count
|
mg.count += chunk.count
|
||||||
}
|
}
|
||||||
mg.count = max(0, mg.count-si)
|
|
||||||
return &mg
|
return &mg
|
||||||
}
|
}
|
||||||
|
|
||||||
// NewMerger returns a new Merger
|
// NewMerger returns a new Merger
|
||||||
func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool, revision revision, minIndex int32, maxIndex int32) *Merger {
|
func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool, revision revision, minIndex int32) *Merger {
|
||||||
mg := Merger{
|
mg := Merger{
|
||||||
pattern: pattern,
|
pattern: pattern,
|
||||||
lists: lists,
|
lists: lists,
|
||||||
@@ -66,8 +59,7 @@ func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool, revisi
|
|||||||
final: false,
|
final: false,
|
||||||
count: 0,
|
count: 0,
|
||||||
revision: revision,
|
revision: revision,
|
||||||
minIndex: minIndex,
|
minIndex: minIndex}
|
||||||
maxIndex: maxIndex}
|
|
||||||
|
|
||||||
for _, list := range mg.lists {
|
for _, list := range mg.lists {
|
||||||
mg.count += len(list)
|
mg.count += len(list)
|
||||||
@@ -117,7 +109,6 @@ func (mg *Merger) Get(idx int) Result {
|
|||||||
if mg.tac {
|
if mg.tac {
|
||||||
idx = mg.count - idx - 1
|
idx = mg.count - idx - 1
|
||||||
}
|
}
|
||||||
idx += mg.startIndex
|
|
||||||
firstChunk := (*mg.chunks)[0]
|
firstChunk := (*mg.chunks)[0]
|
||||||
if firstChunk.count < chunkSize && idx >= firstChunk.count {
|
if firstChunk.count < chunkSize && idx >= firstChunk.count {
|
||||||
idx -= firstChunk.count
|
idx -= firstChunk.count
|
||||||
@@ -136,16 +127,14 @@ func (mg *Merger) Get(idx int) Result {
|
|||||||
if mg.tac {
|
if mg.tac {
|
||||||
idx = mg.count - idx - 1
|
idx = mg.count - idx - 1
|
||||||
}
|
}
|
||||||
return mg.mergedGet(idx)
|
for _, list := range mg.lists {
|
||||||
}
|
numItems := len(list)
|
||||||
|
if idx < numItems {
|
||||||
func (mg *Merger) ToMap() map[int32]Result {
|
return list[idx]
|
||||||
ret := make(map[int32]Result, mg.count)
|
}
|
||||||
for i := 0; i < mg.count; i++ {
|
idx -= numItems
|
||||||
result := mg.Get(i)
|
|
||||||
ret[result.Index()] = result
|
|
||||||
}
|
}
|
||||||
return ret
|
panic(fmt.Sprintf("Index out of bounds (unsorted, %d/%d)", idx, mg.count))
|
||||||
}
|
}
|
||||||
|
|
||||||
func (mg *Merger) cacheable() bool {
|
func (mg *Merger) cacheable() bool {
|
||||||
@@ -164,7 +153,7 @@ func (mg *Merger) mergedGet(idx int) Result {
|
|||||||
}
|
}
|
||||||
if cursor >= 0 {
|
if cursor >= 0 {
|
||||||
rank := list[cursor]
|
rank := list[cursor]
|
||||||
if minIdx < 0 || mg.sorted && compareRanks(rank, minRank, mg.tac) || !mg.sorted && rank.item.Index() < minRank.item.Index() {
|
if minIdx < 0 || compareRanks(rank, minRank, mg.tac) {
|
||||||
minRank = rank
|
minRank = rank
|
||||||
minIdx = listIdx
|
minIdx = listIdx
|
||||||
}
|
}
|
||||||
|
|||||||
+9
-24
@@ -34,11 +34,11 @@ func buildLists(partiallySorted bool) ([][]Result, []Result) {
|
|||||||
numLists := 4
|
numLists := 4
|
||||||
lists := make([][]Result, numLists)
|
lists := make([][]Result, numLists)
|
||||||
cnt := 0
|
cnt := 0
|
||||||
for i := range numLists {
|
for i := 0; i < numLists; i++ {
|
||||||
numResults := rand.Int() % 20
|
numResults := rand.Int() % 20
|
||||||
cnt += numResults
|
cnt += numResults
|
||||||
lists[i] = make([]Result, numResults)
|
lists[i] = make([]Result, numResults)
|
||||||
for j := range numResults {
|
for j := 0; j < numResults; j++ {
|
||||||
item := randResult()
|
item := randResult()
|
||||||
lists[i][j] = item
|
lists[i][j] = item
|
||||||
}
|
}
|
||||||
@@ -54,28 +54,13 @@ func buildLists(partiallySorted bool) ([][]Result, []Result) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestMergerUnsorted(t *testing.T) {
|
func TestMergerUnsorted(t *testing.T) {
|
||||||
lists, _ := buildLists(false)
|
lists, items := buildLists(false)
|
||||||
|
|
||||||
// Sort each list by index to simulate real worker behavior
|
|
||||||
// (workers process chunks in ascending order via nextChunk.Add(1))
|
|
||||||
for _, list := range lists {
|
|
||||||
sort.Slice(list, func(i, j int) bool {
|
|
||||||
return list[i].item.Index() < list[j].item.Index()
|
|
||||||
})
|
|
||||||
}
|
|
||||||
items := []Result{}
|
|
||||||
for _, list := range lists {
|
|
||||||
items = append(items, list...)
|
|
||||||
}
|
|
||||||
sort.Slice(items, func(i, j int) bool {
|
|
||||||
return items[i].item.Index() < items[j].item.Index()
|
|
||||||
})
|
|
||||||
cnt := len(items)
|
cnt := len(items)
|
||||||
|
|
||||||
// Not sorted: items in ascending index order
|
// Not sorted: same order
|
||||||
mg := NewMerger(nil, lists, false, false, revision{}, 0, 0)
|
mg := NewMerger(nil, lists, false, false, revision{}, 0)
|
||||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||||
for i := range cnt {
|
for i := 0; i < cnt; i++ {
|
||||||
assert(t, items[i] == mg.Get(i), "Invalid Get")
|
assert(t, items[i] == mg.Get(i), "Invalid Get")
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -85,17 +70,17 @@ func TestMergerSorted(t *testing.T) {
|
|||||||
cnt := len(items)
|
cnt := len(items)
|
||||||
|
|
||||||
// Sorted sorted order
|
// Sorted sorted order
|
||||||
mg := NewMerger(nil, lists, true, false, revision{}, 0, 0)
|
mg := NewMerger(nil, lists, true, false, revision{}, 0)
|
||||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||||
sort.Sort(ByRelevance(items))
|
sort.Sort(ByRelevance(items))
|
||||||
for i := range cnt {
|
for i := 0; i < cnt; i++ {
|
||||||
if items[i] != mg.Get(i) {
|
if items[i] != mg.Get(i) {
|
||||||
t.Error("Not sorted", items[i], mg.Get(i))
|
t.Error("Not sorted", items[i], mg.Get(i))
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Inverse order
|
// Inverse order
|
||||||
mg2 := NewMerger(nil, lists, true, false, revision{}, 0, 0)
|
mg2 := NewMerger(nil, lists, true, false, revision{}, 0)
|
||||||
for i := cnt - 1; i >= 0; i-- {
|
for i := cnt - 1; i >= 0; i-- {
|
||||||
if items[i] != mg2.Get(i) {
|
if items[i] != mg2.Get(i) {
|
||||||
t.Error("Not sorted", items[i], mg2.Get(i))
|
t.Error("Not sorted", items[i], mg2.Get(i))
|
||||||
|
|||||||
+646
-1642
File diff suppressed because it is too large
Load Diff
+23
-125
@@ -9,13 +9,9 @@ import (
|
|||||||
)
|
)
|
||||||
|
|
||||||
func TestDelimiterRegex(t *testing.T) {
|
func TestDelimiterRegex(t *testing.T) {
|
||||||
// Valid regex, but a single character -> string
|
// Valid regex
|
||||||
delim := delimiterRegexp(".")
|
delim := delimiterRegexp(".")
|
||||||
if delim.regex != nil || *delim.str != "." {
|
if delim.regex == nil || delim.str != nil {
|
||||||
t.Error(delim)
|
|
||||||
}
|
|
||||||
delim = delimiterRegexp("|")
|
|
||||||
if delim.regex != nil || *delim.str != "|" {
|
|
||||||
t.Error(delim)
|
t.Error(delim)
|
||||||
}
|
}
|
||||||
// Broken regex -> string
|
// Broken regex -> string
|
||||||
@@ -142,7 +138,7 @@ func TestIrrelevantNth(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestParseKeys(t *testing.T) {
|
func TestParseKeys(t *testing.T) {
|
||||||
pairs, _, _ := parseKeyChords("ctrl-z,alt-z,f2,@,Alt-a,!,ctrl-G,J,g,ctrl-alt-a,ALT-enter,alt-SPACE", "")
|
pairs, _ := parseKeyChords("ctrl-z,alt-z,f2,@,Alt-a,!,ctrl-G,J,g,ctrl-alt-a,ALT-enter,alt-SPACE", "")
|
||||||
checkEvent := func(e tui.Event, s string) {
|
checkEvent := func(e tui.Event, s string) {
|
||||||
if pairs[e] != s {
|
if pairs[e] != s {
|
||||||
t.Errorf("%s != %s", pairs[e], s)
|
t.Errorf("%s != %s", pairs[e], s)
|
||||||
@@ -168,11 +164,11 @@ func TestParseKeys(t *testing.T) {
|
|||||||
checkEvent(tui.AltKey(' '), "alt-SPACE")
|
checkEvent(tui.AltKey(' '), "alt-SPACE")
|
||||||
|
|
||||||
// Synonyms
|
// Synonyms
|
||||||
pairs, _, _ = parseKeyChords("enter,Return,space,tab,btab,esc,up,down,left,right", "")
|
pairs, _ = parseKeyChords("enter,Return,space,tab,btab,esc,up,down,left,right", "")
|
||||||
if len(pairs) != 9 {
|
if len(pairs) != 9 {
|
||||||
t.Error(9)
|
t.Error(9)
|
||||||
}
|
}
|
||||||
check(tui.Enter, "Return")
|
check(tui.CtrlM, "Return")
|
||||||
checkEvent(tui.Key(' '), "space")
|
checkEvent(tui.Key(' '), "space")
|
||||||
check(tui.Tab, "tab")
|
check(tui.Tab, "tab")
|
||||||
check(tui.ShiftTab, "btab")
|
check(tui.ShiftTab, "btab")
|
||||||
@@ -182,7 +178,7 @@ func TestParseKeys(t *testing.T) {
|
|||||||
check(tui.Left, "left")
|
check(tui.Left, "left")
|
||||||
check(tui.Right, "right")
|
check(tui.Right, "right")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords("Tab,Ctrl-I,PgUp,page-up,pgdn,Page-Down,Home,End,Alt-BS,Alt-BSpace,shift-left,shift-right,btab,shift-tab,return,Enter,bspace", "")
|
pairs, _ = parseKeyChords("Tab,Ctrl-I,PgUp,page-up,pgdn,Page-Down,Home,End,Alt-BS,Alt-BSpace,shift-left,shift-right,btab,shift-tab,return,Enter,bspace", "")
|
||||||
if len(pairs) != 11 {
|
if len(pairs) != 11 {
|
||||||
t.Error(11)
|
t.Error(11)
|
||||||
}
|
}
|
||||||
@@ -195,7 +191,7 @@ func TestParseKeys(t *testing.T) {
|
|||||||
check(tui.ShiftLeft, "shift-left")
|
check(tui.ShiftLeft, "shift-left")
|
||||||
check(tui.ShiftRight, "shift-right")
|
check(tui.ShiftRight, "shift-right")
|
||||||
check(tui.ShiftTab, "shift-tab")
|
check(tui.ShiftTab, "shift-tab")
|
||||||
check(tui.Enter, "Enter")
|
check(tui.CtrlM, "Enter")
|
||||||
check(tui.Backspace, "bspace")
|
check(tui.Backspace, "bspace")
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -211,40 +207,40 @@ func TestParseKeysWithComma(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
pairs, _, _ := parseKeyChords(",", "")
|
pairs, _ := parseKeyChords(",", "")
|
||||||
checkN(len(pairs), 1)
|
checkN(len(pairs), 1)
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords(",,a,b", "")
|
pairs, _ = parseKeyChords(",,a,b", "")
|
||||||
checkN(len(pairs), 3)
|
checkN(len(pairs), 3)
|
||||||
check(pairs, tui.Key('a'), "a")
|
check(pairs, tui.Key('a'), "a")
|
||||||
check(pairs, tui.Key('b'), "b")
|
check(pairs, tui.Key('b'), "b")
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords("a,b,,", "")
|
pairs, _ = parseKeyChords("a,b,,", "")
|
||||||
checkN(len(pairs), 3)
|
checkN(len(pairs), 3)
|
||||||
check(pairs, tui.Key('a'), "a")
|
check(pairs, tui.Key('a'), "a")
|
||||||
check(pairs, tui.Key('b'), "b")
|
check(pairs, tui.Key('b'), "b")
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords("a,,,b", "")
|
pairs, _ = parseKeyChords("a,,,b", "")
|
||||||
checkN(len(pairs), 3)
|
checkN(len(pairs), 3)
|
||||||
check(pairs, tui.Key('a'), "a")
|
check(pairs, tui.Key('a'), "a")
|
||||||
check(pairs, tui.Key('b'), "b")
|
check(pairs, tui.Key('b'), "b")
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords("a,,,b,c", "")
|
pairs, _ = parseKeyChords("a,,,b,c", "")
|
||||||
checkN(len(pairs), 4)
|
checkN(len(pairs), 4)
|
||||||
check(pairs, tui.Key('a'), "a")
|
check(pairs, tui.Key('a'), "a")
|
||||||
check(pairs, tui.Key('b'), "b")
|
check(pairs, tui.Key('b'), "b")
|
||||||
check(pairs, tui.Key('c'), "c")
|
check(pairs, tui.Key('c'), "c")
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords(",,,", "")
|
pairs, _ = parseKeyChords(",,,", "")
|
||||||
checkN(len(pairs), 1)
|
checkN(len(pairs), 1)
|
||||||
check(pairs, tui.Key(','), ",")
|
check(pairs, tui.Key(','), ",")
|
||||||
|
|
||||||
pairs, _, _ = parseKeyChords(",ALT-,,", "")
|
pairs, _ = parseKeyChords(",ALT-,,", "")
|
||||||
checkN(len(pairs), 1)
|
checkN(len(pairs), 1)
|
||||||
check(pairs, tui.AltKey(','), "ALT-,")
|
check(pairs, tui.AltKey(','), "ALT-,")
|
||||||
}
|
}
|
||||||
@@ -299,46 +295,9 @@ func TestBind(t *testing.T) {
|
|||||||
check(tui.F1.AsEvent(), "", actAbort)
|
check(tui.F1.AsEvent(), "", actAbort)
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestParseEveryEvent(t *testing.T) {
|
|
||||||
pairs, _, err := parseKeyChords("every(2),every(0.5)", "")
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("unexpected error: %v", err)
|
|
||||||
}
|
|
||||||
if len(pairs) != 2 {
|
|
||||||
t.Errorf("expected 2 distinct every events, got %d", len(pairs))
|
|
||||||
}
|
|
||||||
if pairs[(tui.Event{Type: tui.Every, Char: 2000})] != "every(2)" {
|
|
||||||
t.Errorf("every(2) not registered")
|
|
||||||
}
|
|
||||||
if pairs[(tui.Event{Type: tui.Every, Char: 500})] != "every(0.5)" {
|
|
||||||
t.Errorf("every(0.5) not registered")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Floor at 0.01s -> 10ms
|
|
||||||
pairs, _, err = parseKeyChords("every(0.001)", "")
|
|
||||||
if err != nil {
|
|
||||||
t.Fatalf("unexpected error: %v", err)
|
|
||||||
}
|
|
||||||
if pairs[(tui.Event{Type: tui.Every, Char: 10})] != "every(0.001)" {
|
|
||||||
t.Errorf("every(0.001) should floor to 10ms")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Reject zero, negatives, and overflow (>= 2^31 ms = ~24.85 days)
|
|
||||||
for _, bad := range []string{"every(0)", "every(-1)", "every(abc)", "every()", "every(2147484)"} {
|
|
||||||
if _, _, err := parseKeyChords(bad, ""); err == nil {
|
|
||||||
t.Errorf("%s should be rejected", bad)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestColorSpec(t *testing.T) {
|
func TestColorSpec(t *testing.T) {
|
||||||
var base *tui.ColorTheme
|
|
||||||
theme := tui.Dark256
|
theme := tui.Dark256
|
||||||
base, dark, _ := parseTheme(theme, "dark")
|
dark, _ := parseTheme(theme, "dark")
|
||||||
if *dark != *base {
|
|
||||||
t.Errorf("incorrect base theme returned")
|
|
||||||
}
|
|
||||||
if *dark != *theme {
|
if *dark != *theme {
|
||||||
t.Errorf("colors should be equivalent")
|
t.Errorf("colors should be equivalent")
|
||||||
}
|
}
|
||||||
@@ -346,10 +305,7 @@ func TestColorSpec(t *testing.T) {
|
|||||||
t.Errorf("point should not be equivalent")
|
t.Errorf("point should not be equivalent")
|
||||||
}
|
}
|
||||||
|
|
||||||
base, light, _ := parseTheme(theme, "dark,light")
|
light, _ := parseTheme(theme, "dark,light")
|
||||||
if *light != *base {
|
|
||||||
t.Errorf("incorrect base theme returned")
|
|
||||||
}
|
|
||||||
if *light == *theme {
|
if *light == *theme {
|
||||||
t.Errorf("should not be equivalent")
|
t.Errorf("should not be equivalent")
|
||||||
}
|
}
|
||||||
@@ -360,7 +316,7 @@ func TestColorSpec(t *testing.T) {
|
|||||||
t.Errorf("point should not be equivalent")
|
t.Errorf("point should not be equivalent")
|
||||||
}
|
}
|
||||||
|
|
||||||
_, customized, _ := parseTheme(theme, "fg:231,bg:232")
|
customized, _ := parseTheme(theme, "fg:231,bg:232")
|
||||||
if customized.Fg.Color != 231 || customized.Bg.Color != 232 {
|
if customized.Fg.Color != 231 || customized.Bg.Color != 232 {
|
||||||
t.Errorf("color not customized")
|
t.Errorf("color not customized")
|
||||||
}
|
}
|
||||||
@@ -373,7 +329,7 @@ func TestColorSpec(t *testing.T) {
|
|||||||
t.Errorf("colors should now be equivalent: %v, %v", tui.Dark256, customized)
|
t.Errorf("colors should now be equivalent: %v, %v", tui.Dark256, customized)
|
||||||
}
|
}
|
||||||
|
|
||||||
_, customized, _ = parseTheme(theme, "fg:231,dark bg:232")
|
customized, _ = parseTheme(theme, "fg:231,dark,bg:232")
|
||||||
if customized.Fg != tui.Dark256.Fg || customized.Bg == tui.Dark256.Bg {
|
if customized.Fg != tui.Dark256.Fg || customized.Bg == tui.Dark256.Bg {
|
||||||
t.Errorf("color not customized")
|
t.Errorf("color not customized")
|
||||||
}
|
}
|
||||||
@@ -390,8 +346,8 @@ func TestDefaultCtrlNP(t *testing.T) {
|
|||||||
t.Error()
|
t.Error()
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
check([]string{}, tui.CtrlN, actDownMatch)
|
check([]string{}, tui.CtrlN, actDown)
|
||||||
check([]string{}, tui.CtrlP, actUpMatch)
|
check([]string{}, tui.CtrlP, actUp)
|
||||||
|
|
||||||
check([]string{"--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
check([]string{"--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
||||||
check([]string{"--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
check([]string{"--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
||||||
@@ -481,64 +437,6 @@ func TestPreviewOpts(t *testing.T) {
|
|||||||
opts.Preview.size.size == 70) {
|
opts.Preview.size.size == 70) {
|
||||||
t.Error(opts.Preview)
|
t.Error(opts.Preview)
|
||||||
}
|
}
|
||||||
|
|
||||||
// wrap-word tests
|
|
||||||
opts = optsFor("--preview-window=wrap-word")
|
|
||||||
if !(opts.Preview.wrap == true && opts.Preview.wrapWord == true) {
|
|
||||||
t.Errorf("wrap-word: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
|
||||||
}
|
|
||||||
opts = optsFor("--preview-window=wrap-word,nowrap")
|
|
||||||
if !(opts.Preview.wrap == false && opts.Preview.wrapWord == false) {
|
|
||||||
t.Errorf("wrap-word,nowrap: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
|
||||||
}
|
|
||||||
opts = optsFor("--preview-window=wrap-word,wrap")
|
|
||||||
if !(opts.Preview.wrap == true && opts.Preview.wrapWord == false) {
|
|
||||||
t.Errorf("wrap-word,wrap: wrap=%v, wrapWord=%v", opts.Preview.wrap, opts.Preview.wrapWord)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestPreviewWrapSign(t *testing.T) {
|
|
||||||
// Default: no preview wrap sign override
|
|
||||||
opts := optsFor()
|
|
||||||
if opts.PreviewWrapSign != nil {
|
|
||||||
t.Errorf("expected nil PreviewWrapSign, got %v", *opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
|
|
||||||
// --preview-wrap-sign sets PreviewWrapSign
|
|
||||||
opts = optsFor("--preview-wrap-sign", ">> ")
|
|
||||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != ">> " {
|
|
||||||
t.Errorf("expected '>> ', got %v", opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
|
|
||||||
// --preview-wrap-sign is independent of --wrap-sign
|
|
||||||
opts = optsFor("--wrap-sign", "| ", "--preview-wrap-sign", ">> ")
|
|
||||||
if opts.WrapSign == nil || *opts.WrapSign != "| " {
|
|
||||||
t.Errorf("expected WrapSign '| ', got %v", opts.WrapSign)
|
|
||||||
}
|
|
||||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != ">> " {
|
|
||||||
t.Errorf("expected PreviewWrapSign '>> ', got %v", opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
|
|
||||||
// --preview-wrap-sign without --wrap-sign
|
|
||||||
opts = optsFor("--preview-wrap-sign", "→ ")
|
|
||||||
if opts.WrapSign != nil {
|
|
||||||
t.Errorf("expected nil WrapSign, got %v", *opts.WrapSign)
|
|
||||||
}
|
|
||||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "→ " {
|
|
||||||
t.Errorf("expected PreviewWrapSign '→ ', got %v", opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Last --preview-wrap-sign wins
|
|
||||||
opts = optsFor("--preview-wrap-sign", "A ", "--preview-wrap-sign", "B ")
|
|
||||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "B " {
|
|
||||||
t.Errorf("expected PreviewWrapSign 'B ', got %v", opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Empty string is allowed
|
|
||||||
opts = optsFor("--preview-wrap-sign", "")
|
|
||||||
if opts.PreviewWrapSign == nil || *opts.PreviewWrapSign != "" {
|
|
||||||
t.Errorf("expected empty PreviewWrapSign, got %v", opts.PreviewWrapSign)
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestAdditiveExpect(t *testing.T) {
|
func TestAdditiveExpect(t *testing.T) {
|
||||||
@@ -560,7 +458,7 @@ func TestValidateSign(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
for _, testCase := range testCases {
|
for _, testCase := range testCases {
|
||||||
err := validateSign(testCase.inputSign, "", 2)
|
err := validateSign(testCase.inputSign, "")
|
||||||
if testCase.isValid && err != nil {
|
if testCase.isValid && err != nil {
|
||||||
t.Errorf("Input sign `%s` caused error", testCase.inputSign)
|
t.Errorf("Input sign `%s` caused error", testCase.inputSign)
|
||||||
}
|
}
|
||||||
@@ -572,7 +470,7 @@ func TestValidateSign(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestParseSingleActionList(t *testing.T) {
|
func TestParseSingleActionList(t *testing.T) {
|
||||||
actions, _ := parseSingleActionList("Execute@foo+bar,baz@+up+up+reload:down+down", false)
|
actions, _ := parseSingleActionList("Execute@foo+bar,baz@+up+up+reload:down+down")
|
||||||
if len(actions) != 4 {
|
if len(actions) != 4 {
|
||||||
t.Errorf("Invalid number of actions parsed:%d", len(actions))
|
t.Errorf("Invalid number of actions parsed:%d", len(actions))
|
||||||
}
|
}
|
||||||
@@ -588,7 +486,7 @@ func TestParseSingleActionList(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
func TestParseSingleActionListError(t *testing.T) {
|
func TestParseSingleActionListError(t *testing.T) {
|
||||||
_, err := parseSingleActionList("change-query(foobar)baz", false)
|
_, err := parseSingleActionList("change-query(foobar)baz")
|
||||||
if err == nil {
|
if err == nil {
|
||||||
t.Errorf("Failed to detect error")
|
t.Errorf("Failed to detect error")
|
||||||
}
|
}
|
||||||
|
|||||||
+32
-114
@@ -60,13 +60,8 @@ type Pattern struct {
|
|||||||
cacheKey string
|
cacheKey string
|
||||||
delimiter Delimiter
|
delimiter Delimiter
|
||||||
nth []Range
|
nth []Range
|
||||||
revision revision
|
procFun map[termType]algo.Algo
|
||||||
procFun [6]algo.Algo
|
|
||||||
cache *ChunkCache
|
cache *ChunkCache
|
||||||
denylist map[int32]struct{}
|
|
||||||
startIndex int32
|
|
||||||
directAlgo algo.Algo
|
|
||||||
directTerm *term
|
|
||||||
}
|
}
|
||||||
|
|
||||||
var _splitRegex *regexp.Regexp
|
var _splitRegex *regexp.Regexp
|
||||||
@@ -77,7 +72,7 @@ func init() {
|
|||||||
|
|
||||||
// BuildPattern builds Pattern object from the given arguments
|
// BuildPattern builds Pattern object from the given arguments
|
||||||
func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
||||||
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, revision revision, runes []rune, denylist map[int32]struct{}, startIndex int32) *Pattern {
|
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
||||||
|
|
||||||
var asString string
|
var asString string
|
||||||
if extended {
|
if extended {
|
||||||
@@ -145,15 +140,11 @@ func BuildPattern(cache *ChunkCache, patternCache map[string]*Pattern, fuzzy boo
|
|||||||
sortable: sortable,
|
sortable: sortable,
|
||||||
cacheable: cacheable,
|
cacheable: cacheable,
|
||||||
nth: nth,
|
nth: nth,
|
||||||
revision: revision,
|
|
||||||
delimiter: delimiter,
|
delimiter: delimiter,
|
||||||
cache: cache,
|
cache: cache,
|
||||||
denylist: denylist,
|
procFun: make(map[termType]algo.Algo)}
|
||||||
startIndex: startIndex,
|
|
||||||
}
|
|
||||||
|
|
||||||
ptr.cacheKey = ptr.buildCacheKey()
|
ptr.cacheKey = ptr.buildCacheKey()
|
||||||
ptr.directAlgo, ptr.directTerm = ptr.buildDirectAlgo(fuzzyAlgo)
|
|
||||||
ptr.procFun[termFuzzy] = fuzzyAlgo
|
ptr.procFun[termFuzzy] = fuzzyAlgo
|
||||||
ptr.procFun[termEqual] = algo.EqualMatch
|
ptr.procFun[termEqual] = algo.EqualMatch
|
||||||
ptr.procFun[termExact] = algo.ExactMatchNaive
|
ptr.procFun[termExact] = algo.ExactMatchNaive
|
||||||
@@ -250,9 +241,6 @@ func parseTerms(fuzzy bool, caseMode Case, normalize bool, str string) []termSet
|
|||||||
|
|
||||||
// IsEmpty returns true if the pattern is effectively empty
|
// IsEmpty returns true if the pattern is effectively empty
|
||||||
func (p *Pattern) IsEmpty() bool {
|
func (p *Pattern) IsEmpty() bool {
|
||||||
if len(p.denylist) > 0 {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
if !p.extended {
|
if !p.extended {
|
||||||
return len(p.text) == 0
|
return len(p.text) == 0
|
||||||
}
|
}
|
||||||
@@ -277,22 +265,6 @@ func (p *Pattern) buildCacheKey() string {
|
|||||||
return strings.Join(cacheableTerms, "\t")
|
return strings.Join(cacheableTerms, "\t")
|
||||||
}
|
}
|
||||||
|
|
||||||
// buildDirectAlgo returns the algo function and term for the direct fast path
|
|
||||||
// in matchChunk. Returns (nil, nil) if the pattern is not suitable.
|
|
||||||
// Requirements: extended mode, single term set with single non-inverse fuzzy term, no nth.
|
|
||||||
func (p *Pattern) buildDirectAlgo(fuzzyAlgo algo.Algo) (algo.Algo, *term) {
|
|
||||||
if !p.extended || len(p.nth) > 0 {
|
|
||||||
return nil, nil
|
|
||||||
}
|
|
||||||
if len(p.termSets) == 1 && len(p.termSets[0]) == 1 {
|
|
||||||
t := &p.termSets[0][0]
|
|
||||||
if !t.inv && t.typ == termFuzzy {
|
|
||||||
return fuzzyAlgo, t
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return nil, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// CacheKey is used to build string to be used as the key of result cache
|
// CacheKey is used to build string to be used as the key of result cache
|
||||||
func (p *Pattern) CacheKey() string {
|
func (p *Pattern) CacheKey() string {
|
||||||
return p.cacheKey
|
return p.cacheKey
|
||||||
@@ -300,104 +272,60 @@ func (p *Pattern) CacheKey() string {
|
|||||||
|
|
||||||
// Match returns the list of matches Items in the given Chunk
|
// Match returns the list of matches Items in the given Chunk
|
||||||
func (p *Pattern) Match(chunk *Chunk, slab *util.Slab) []Result {
|
func (p *Pattern) Match(chunk *Chunk, slab *util.Slab) []Result {
|
||||||
|
// ChunkCache: Exact match
|
||||||
cacheKey := p.CacheKey()
|
cacheKey := p.CacheKey()
|
||||||
|
|
||||||
// Bitmap cache: exact match or prefix/suffix
|
|
||||||
var cachedBitmap *ChunkBitmap
|
|
||||||
if p.cacheable {
|
if p.cacheable {
|
||||||
cachedBitmap = p.cache.Lookup(chunk, cacheKey)
|
if cached := p.cache.Lookup(chunk, cacheKey); cached != nil {
|
||||||
}
|
return cached
|
||||||
if cachedBitmap == nil {
|
}
|
||||||
cachedBitmap = p.cache.Search(chunk, cacheKey)
|
|
||||||
}
|
}
|
||||||
|
|
||||||
matches, bitmap := p.matchChunk(chunk, cachedBitmap, slab)
|
// Prefix/suffix cache
|
||||||
|
space := p.cache.Search(chunk, cacheKey)
|
||||||
|
|
||||||
|
matches := p.matchChunk(chunk, space, slab)
|
||||||
|
|
||||||
if p.cacheable {
|
if p.cacheable {
|
||||||
p.cache.Add(chunk, cacheKey, bitmap, len(matches))
|
p.cache.Add(chunk, cacheKey, matches)
|
||||||
}
|
}
|
||||||
return matches
|
return matches
|
||||||
}
|
}
|
||||||
|
|
||||||
func (p *Pattern) matchChunk(chunk *Chunk, cachedBitmap *ChunkBitmap, slab *util.Slab) ([]Result, ChunkBitmap) {
|
func (p *Pattern) matchChunk(chunk *Chunk, space []Result, slab *util.Slab) []Result {
|
||||||
matches := []Result{}
|
matches := []Result{}
|
||||||
var bitmap ChunkBitmap
|
|
||||||
|
|
||||||
// Skip header items in chunks that contain them
|
if space == nil {
|
||||||
startIdx := 0
|
for idx := 0; idx < chunk.count; idx++ {
|
||||||
if p.startIndex > 0 && chunk.count > 0 && chunk.items[0].Index() < p.startIndex {
|
if match, _, _ := p.MatchItem(&chunk.items[idx], p.withPos, slab); match != nil {
|
||||||
startIdx = int(p.startIndex - chunk.items[0].Index())
|
matches = append(matches, *match)
|
||||||
if startIdx >= chunk.count {
|
|
||||||
return matches, bitmap
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
hasCachedBitmap := cachedBitmap != nil
|
|
||||||
|
|
||||||
// Fast path: single fuzzy term, no nth, no denylist.
|
|
||||||
// Calls the algo function directly, bypassing MatchItem/extendedMatch/iter
|
|
||||||
// and avoiding per-match []Offset heap allocation.
|
|
||||||
if p.directAlgo != nil && len(p.denylist) == 0 {
|
|
||||||
t := p.directTerm
|
|
||||||
for idx := startIdx; idx < chunk.count; idx++ {
|
|
||||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
res, _ := p.directAlgo(t.caseSensitive, t.normalize, p.forward,
|
|
||||||
&chunk.items[idx].text, t.text, p.withPos, slab)
|
|
||||||
if res.Start >= 0 {
|
|
||||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
|
||||||
matches = append(matches, buildResultFromBounds(
|
|
||||||
&chunk.items[idx], res.Score,
|
|
||||||
int(res.Start), int(res.End), int(res.End), true))
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
return matches, bitmap
|
} else {
|
||||||
}
|
for _, result := range space {
|
||||||
|
if match, _, _ := p.MatchItem(result.item, p.withPos, slab); match != nil {
|
||||||
if len(p.denylist) == 0 {
|
matches = append(matches, *match)
|
||||||
for idx := startIdx; idx < chunk.count; idx++ {
|
|
||||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
if match, _, _ := p.MatchItem(&chunk.items[idx], p.withPos, slab); match.item != nil {
|
|
||||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
|
||||||
matches = append(matches, match)
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
return matches, bitmap
|
|
||||||
}
|
}
|
||||||
|
return matches
|
||||||
for idx := startIdx; idx < chunk.count; idx++ {
|
|
||||||
if hasCachedBitmap && cachedBitmap[idx/64]&(uint64(1)<<(idx%64)) == 0 {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
if _, prs := p.denylist[chunk.items[idx].Index()]; prs {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
if match, _, _ := p.MatchItem(&chunk.items[idx], p.withPos, slab); match.item != nil {
|
|
||||||
bitmap[idx/64] |= uint64(1) << (idx % 64)
|
|
||||||
matches = append(matches, match)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return matches, bitmap
|
|
||||||
}
|
}
|
||||||
|
|
||||||
// MatchItem returns the match result if the Item is a match.
|
// MatchItem returns true if the Item is a match
|
||||||
// A zero-value Result (with item == nil) indicates no match.
|
func (p *Pattern) MatchItem(item *Item, withPos bool, slab *util.Slab) (*Result, []Offset, *[]int) {
|
||||||
func (p *Pattern) MatchItem(item *Item, withPos bool, slab *util.Slab) (Result, []Offset, *[]int) {
|
|
||||||
if p.extended {
|
if p.extended {
|
||||||
if offsets, bonus, pos := p.extendedMatch(item, withPos, slab); len(offsets) == len(p.termSets) {
|
if offsets, bonus, pos := p.extendedMatch(item, withPos, slab); len(offsets) == len(p.termSets) {
|
||||||
return buildResult(item, offsets, bonus), offsets, pos
|
result := buildResult(item, offsets, bonus)
|
||||||
|
return &result, offsets, pos
|
||||||
}
|
}
|
||||||
return Result{}, nil, nil
|
return nil, nil, nil
|
||||||
}
|
}
|
||||||
offset, bonus, pos := p.basicMatch(item, withPos, slab)
|
offset, bonus, pos := p.basicMatch(item, withPos, slab)
|
||||||
if sidx := offset[0]; sidx >= 0 {
|
if sidx := offset[0]; sidx >= 0 {
|
||||||
offsets := []Offset{offset}
|
offsets := []Offset{offset}
|
||||||
return buildResult(item, offsets, bonus), offsets, pos
|
result := buildResult(item, offsets, bonus)
|
||||||
|
return &result, offsets, pos
|
||||||
}
|
}
|
||||||
return Result{}, nil, nil
|
return nil, nil, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func (p *Pattern) basicMatch(item *Item, withPos bool, slab *util.Slab) (Offset, int, *[]int) {
|
func (p *Pattern) basicMatch(item *Item, withPos bool, slab *util.Slab) (Offset, int, *[]int) {
|
||||||
@@ -465,22 +393,12 @@ func (p *Pattern) extendedMatch(item *Item, withPos bool, slab *util.Slab) ([]Of
|
|||||||
|
|
||||||
func (p *Pattern) transformInput(item *Item) []Token {
|
func (p *Pattern) transformInput(item *Item) []Token {
|
||||||
if item.transformed != nil {
|
if item.transformed != nil {
|
||||||
transformed := *item.transformed
|
return *item.transformed
|
||||||
if transformed.revision == p.revision {
|
|
||||||
return transformed.tokens
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
tokens := Tokenize(item.text.ToString(), p.delimiter)
|
tokens := Tokenize(item.text.ToString(), p.delimiter)
|
||||||
ret := Transform(tokens, p.nth)
|
ret := Transform(tokens, p.nth)
|
||||||
// Strip the last delimiter to allow suffix match
|
item.transformed = &ret
|
||||||
if len(ret) > 0 && !p.delimiter.IsAwk() {
|
|
||||||
chars := ret[len(ret)-1].text
|
|
||||||
stripped := StripLastDelimiter(chars.ToString(), p.delimiter)
|
|
||||||
newChars := util.ToChars(stringBytes(stripped))
|
|
||||||
ret[len(ret)-1].text = &newChars
|
|
||||||
}
|
|
||||||
item.transformed = &transformed{p.revision, ret}
|
|
||||||
return ret
|
return ret
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
+5
-122
@@ -2,7 +2,6 @@ package fzf
|
|||||||
|
|
||||||
import (
|
import (
|
||||||
"reflect"
|
"reflect"
|
||||||
"runtime"
|
|
||||||
"testing"
|
"testing"
|
||||||
|
|
||||||
"github.com/junegunn/fzf/src/algo"
|
"github.com/junegunn/fzf/src/algo"
|
||||||
@@ -69,7 +68,7 @@ func buildPattern(fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case,
|
|||||||
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
withPos bool, cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
||||||
return BuildPattern(NewChunkCache(), make(map[string]*Pattern),
|
return BuildPattern(NewChunkCache(), make(map[string]*Pattern),
|
||||||
fuzzy, fuzzyAlgo, extended, caseMode, normalize, forward,
|
fuzzy, fuzzyAlgo, extended, caseMode, normalize, forward,
|
||||||
withPos, cacheable, nth, delimiter, revision{}, runes, nil, 0)
|
withPos, cacheable, nth, delimiter, runes)
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestExact(t *testing.T) {
|
func TestExact(t *testing.T) {
|
||||||
@@ -136,12 +135,12 @@ func TestOrigTextAndTransformed(t *testing.T) {
|
|||||||
chunk.items[0] = Item{
|
chunk.items[0] = Item{
|
||||||
text: util.ToChars([]byte("junegunn")),
|
text: util.ToChars([]byte("junegunn")),
|
||||||
origText: &origBytes,
|
origText: &origBytes,
|
||||||
transformed: &transformed{pattern.revision, trans}}
|
transformed: &trans}
|
||||||
pattern.extended = extended
|
pattern.extended = extended
|
||||||
matches, _ := pattern.matchChunk(&chunk, nil, slab) // No cache
|
matches := pattern.matchChunk(&chunk, nil, slab) // No cache
|
||||||
if !(matches[0].item.text.ToString() == "junegunn" &&
|
if !(matches[0].item.text.ToString() == "junegunn" &&
|
||||||
string(*matches[0].item.origText) == "junegunn.choi" &&
|
string(*matches[0].item.origText) == "junegunn.choi" &&
|
||||||
reflect.DeepEqual((*matches[0].item.transformed).tokens, trans)) {
|
reflect.DeepEqual(*matches[0].item.transformed, trans)) {
|
||||||
t.Error("Invalid match result", matches)
|
t.Error("Invalid match result", matches)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -149,7 +148,7 @@ func TestOrigTextAndTransformed(t *testing.T) {
|
|||||||
if !(match.item.text.ToString() == "junegunn" &&
|
if !(match.item.text.ToString() == "junegunn" &&
|
||||||
string(*match.item.origText) == "junegunn.choi" &&
|
string(*match.item.origText) == "junegunn.choi" &&
|
||||||
offsets[0][0] == 0 && offsets[0][1] == 5 &&
|
offsets[0][0] == 0 && offsets[0][1] == 5 &&
|
||||||
reflect.DeepEqual((*match.item.transformed).tokens, trans)) {
|
reflect.DeepEqual(*match.item.transformed, trans)) {
|
||||||
t.Error("Invalid match result", match, offsets, extended)
|
t.Error("Invalid match result", match, offsets, extended)
|
||||||
}
|
}
|
||||||
if !((*pos)[0] == 4 && (*pos)[1] == 0) {
|
if !((*pos)[0] == 4 && (*pos)[1] == 0) {
|
||||||
@@ -200,119 +199,3 @@ func TestCacheable(t *testing.T) {
|
|||||||
test(false, "foo 'bar", "foo", false)
|
test(false, "foo 'bar", "foo", false)
|
||||||
test(false, "foo !bar", "foo", false)
|
test(false, "foo !bar", "foo", false)
|
||||||
}
|
}
|
||||||
|
|
||||||
func buildChunks(numChunks int) []*Chunk {
|
|
||||||
chunks := make([]*Chunk, numChunks)
|
|
||||||
words := []string{
|
|
||||||
"src/main/java/com/example/service/UserService.java",
|
|
||||||
"src/test/java/com/example/service/UserServiceTest.java",
|
|
||||||
"docs/api/reference/endpoints.md",
|
|
||||||
"lib/internal/utils/string_helper.go",
|
|
||||||
"pkg/server/http/handler/auth.go",
|
|
||||||
"build/output/release/app.exe",
|
|
||||||
"config/production/database.yml",
|
|
||||||
"scripts/deploy/kubernetes/setup.sh",
|
|
||||||
"vendor/github.com/junegunn/fzf/src/core.go",
|
|
||||||
"node_modules/.cache/babel/transform.js",
|
|
||||||
}
|
|
||||||
for ci := range numChunks {
|
|
||||||
chunks[ci] = &Chunk{count: chunkSize}
|
|
||||||
for i := range chunkSize {
|
|
||||||
text := words[(ci*chunkSize+i)%len(words)]
|
|
||||||
chunks[ci].items[i] = Item{text: util.ToChars([]byte(text))}
|
|
||||||
chunks[ci].items[i].text.Index = int32(ci*chunkSize + i)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return chunks
|
|
||||||
}
|
|
||||||
|
|
||||||
func buildPatternWith(cache *ChunkCache, runes []rune) *Pattern {
|
|
||||||
return BuildPattern(cache, make(map[string]*Pattern),
|
|
||||||
true, algo.FuzzyMatchV2, true, CaseSmart, false, true,
|
|
||||||
false, true, []Range{}, Delimiter{}, revision{}, runes, nil, 0)
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestBitmapCacheBenefit(t *testing.T) {
|
|
||||||
numChunks := 100
|
|
||||||
chunks := buildChunks(numChunks)
|
|
||||||
queries := []string{"s", "se", "ser", "serv", "servi"}
|
|
||||||
|
|
||||||
// 1. Run all queries with shared cache (simulates incremental typing)
|
|
||||||
cache := NewChunkCache()
|
|
||||||
for _, q := range queries {
|
|
||||||
pat := buildPatternWith(cache, []rune(q))
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
pat.Match(chunk, slab)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// 2. GC and measure memory with cache populated
|
|
||||||
runtime.GC()
|
|
||||||
runtime.GC()
|
|
||||||
var memWith runtime.MemStats
|
|
||||||
runtime.ReadMemStats(&memWith)
|
|
||||||
|
|
||||||
// 3. Clear cache, GC, measure again
|
|
||||||
cache.Clear()
|
|
||||||
runtime.GC()
|
|
||||||
runtime.GC()
|
|
||||||
var memWithout runtime.MemStats
|
|
||||||
runtime.ReadMemStats(&memWithout)
|
|
||||||
|
|
||||||
cacheMem := int64(memWith.Alloc) - int64(memWithout.Alloc)
|
|
||||||
t.Logf("Chunks: %d, Queries: %d", numChunks, len(queries))
|
|
||||||
t.Logf("Cache memory: %d bytes (%.1f KB)", cacheMem, float64(cacheMem)/1024)
|
|
||||||
t.Logf("Per-chunk-per-query: %.0f bytes", float64(cacheMem)/float64(numChunks*len(queries)))
|
|
||||||
|
|
||||||
// 4. Verify correctness: cached vs uncached produce same results
|
|
||||||
cache2 := NewChunkCache()
|
|
||||||
for _, q := range queries {
|
|
||||||
pat := buildPatternWith(cache2, []rune(q))
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
pat.Match(chunk, slab)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
for _, q := range queries {
|
|
||||||
patCached := buildPatternWith(cache2, []rune(q))
|
|
||||||
patFresh := buildPatternWith(NewChunkCache(), []rune(q))
|
|
||||||
var countCached, countFresh int
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
countCached += len(patCached.Match(chunk, slab))
|
|
||||||
countFresh += len(patFresh.Match(chunk, slab))
|
|
||||||
}
|
|
||||||
if countCached != countFresh {
|
|
||||||
t.Errorf("query=%q: cached=%d, fresh=%d", q, countCached, countFresh)
|
|
||||||
}
|
|
||||||
t.Logf("query=%q: matches=%d", q, countCached)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func BenchmarkWithCache(b *testing.B) {
|
|
||||||
numChunks := 100
|
|
||||||
chunks := buildChunks(numChunks)
|
|
||||||
queries := []string{"s", "se", "ser", "serv", "servi"}
|
|
||||||
|
|
||||||
b.Run("cached", func(b *testing.B) {
|
|
||||||
for range b.N {
|
|
||||||
cache := NewChunkCache()
|
|
||||||
for _, q := range queries {
|
|
||||||
pat := buildPatternWith(cache, []rune(q))
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
pat.Match(chunk, slab)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
})
|
|
||||||
|
|
||||||
b.Run("uncached", func(b *testing.B) {
|
|
||||||
for range b.N {
|
|
||||||
for _, q := range queries {
|
|
||||||
cache := NewChunkCache()
|
|
||||||
pat := buildPatternWith(cache, []rune(q))
|
|
||||||
for _, chunk := range chunks {
|
|
||||||
pat.Match(chunk, slab)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -6,5 +6,5 @@ import "golang.org/x/sys/unix"
|
|||||||
|
|
||||||
// Protect calls OS specific protections like pledge on OpenBSD
|
// Protect calls OS specific protections like pledge on OpenBSD
|
||||||
func Protect() {
|
func Protect() {
|
||||||
unix.PledgePromises("stdio cpath dpath wpath rpath inet fattr unix tty proc exec")
|
unix.PledgePromises("stdio dpath wpath rpath tty proc exec inet tmppath")
|
||||||
}
|
}
|
||||||
|
|||||||
+5
-35
@@ -23,32 +23,6 @@ func escapeSingleQuote(str string) string {
|
|||||||
return "'" + strings.ReplaceAll(str, "'", "'\\''") + "'"
|
return "'" + strings.ReplaceAll(str, "'", "'\\''") + "'"
|
||||||
}
|
}
|
||||||
|
|
||||||
func popupArgStr(args []string, opts *Options) (string, string) {
|
|
||||||
fzf, rest := args[0], args[1:]
|
|
||||||
args = []string{"--bind=ctrl-z:ignore"}
|
|
||||||
if !opts.Tmux.border && (opts.BorderShape == tui.BorderUndefined || opts.BorderShape == tui.BorderLine) {
|
|
||||||
if tui.DefaultBorderShape == tui.BorderRounded {
|
|
||||||
rest = append(rest, "--border=rounded")
|
|
||||||
} else {
|
|
||||||
rest = append(rest, "--border=sharp")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if opts.Tmux.border && opts.Margin == defaultMargin() {
|
|
||||||
args = append(args, "--margin=0,1")
|
|
||||||
}
|
|
||||||
argStr := escapeSingleQuote(fzf)
|
|
||||||
for _, arg := range append(args, rest...) {
|
|
||||||
argStr += " " + escapeSingleQuote(arg)
|
|
||||||
}
|
|
||||||
argStr += ` --no-popup --no-height`
|
|
||||||
|
|
||||||
dir, err := os.Getwd()
|
|
||||||
if err != nil {
|
|
||||||
dir = "."
|
|
||||||
}
|
|
||||||
return argStr, dir
|
|
||||||
}
|
|
||||||
|
|
||||||
func fifo(name string) (string, error) {
|
func fifo(name string) (string, error) {
|
||||||
ns := time.Now().UnixNano()
|
ns := time.Now().UnixNano()
|
||||||
output := filepath.Join(os.TempDir(), fmt.Sprintf("fzf-%s-%d", name, ns))
|
output := filepath.Join(os.TempDir(), fmt.Sprintf("fzf-%s-%d", name, ns))
|
||||||
@@ -85,12 +59,12 @@ func runProxy(commandPrefix string, cmdBuilder func(temp string, needBash bool)
|
|||||||
})
|
})
|
||||||
}()
|
}()
|
||||||
|
|
||||||
var command, input string
|
var command string
|
||||||
commandPrefix += ` --no-force-tty-in --proxy-script "$0"`
|
commandPrefix += ` --no-force-tty-in --proxy-script "$0"`
|
||||||
if opts.Input == nil && (opts.ForceTtyIn || util.IsTty(os.Stdin)) {
|
if opts.Input == nil && (opts.ForceTtyIn || util.IsTty(os.Stdin)) {
|
||||||
command = fmt.Sprintf(`%s > %q`, commandPrefix, output)
|
command = fmt.Sprintf(`%s > %q`, commandPrefix, output)
|
||||||
} else {
|
} else {
|
||||||
input, err = fifo("proxy-input")
|
input, err := fifo("proxy-input")
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return ExitError, err
|
return ExitError, err
|
||||||
}
|
}
|
||||||
@@ -116,12 +90,11 @@ func runProxy(commandPrefix string, cmdBuilder func(temp string, needBash bool)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Write the command to a temporary file and run it with sh to ensure POSIX compliance.
|
// To ensure that the options are processed by a POSIX-compliant shell,
|
||||||
|
// we need to write the command to a temporary file and execute it with sh.
|
||||||
var exports []string
|
var exports []string
|
||||||
needBash := false
|
needBash := false
|
||||||
if withExports {
|
if withExports {
|
||||||
// Nullify FZF_DEFAULT_* variables as tmux popup may inject them even when undefined.
|
|
||||||
exports = []string{"FZF_DEFAULT_COMMAND=", "FZF_DEFAULT_OPTS=", "FZF_DEFAULT_OPTS_FILE="}
|
|
||||||
validIdentifier := regexp.MustCompile(`^[a-zA-Z_][a-zA-Z0-9_]*$`)
|
validIdentifier := regexp.MustCompile(`^[a-zA-Z_][a-zA-Z0-9_]*$`)
|
||||||
for _, pairStr := range os.Environ() {
|
for _, pairStr := range os.Environ() {
|
||||||
pair := strings.SplitN(pairStr, "=", 2)
|
pair := strings.SplitN(pairStr, "=", 2)
|
||||||
@@ -171,13 +144,10 @@ func runProxy(commandPrefix string, cmdBuilder func(temp string, needBash bool)
|
|||||||
env = elems[1:]
|
env = elems[1:]
|
||||||
}
|
}
|
||||||
executor := util.NewExecutor(opts.WithShell)
|
executor := util.NewExecutor(opts.WithShell)
|
||||||
ttyin, err := tui.TtyIn(opts.TtyDefault)
|
ttyin, err := tui.TtyIn()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return ExitError, err
|
return ExitError, err
|
||||||
}
|
}
|
||||||
os.Remove(temp)
|
|
||||||
os.Remove(input)
|
|
||||||
os.Remove(output)
|
|
||||||
executor.Become(ttyin, env, command)
|
executor.Become(ttyin, env, command)
|
||||||
}
|
}
|
||||||
return code, err
|
return code, err
|
||||||
|
|||||||
+41
-136
@@ -6,9 +6,8 @@ import (
|
|||||||
"io"
|
"io"
|
||||||
"io/fs"
|
"io/fs"
|
||||||
"os"
|
"os"
|
||||||
|
"os/exec"
|
||||||
"path/filepath"
|
"path/filepath"
|
||||||
"slices"
|
|
||||||
"strings"
|
|
||||||
"sync"
|
"sync"
|
||||||
"sync/atomic"
|
"sync/atomic"
|
||||||
"time"
|
"time"
|
||||||
@@ -26,26 +25,16 @@ type Reader struct {
|
|||||||
event int32
|
event int32
|
||||||
finChan chan bool
|
finChan chan bool
|
||||||
mutex sync.Mutex
|
mutex sync.Mutex
|
||||||
killed bool
|
exec *exec.Cmd
|
||||||
termFunc func()
|
execOut io.ReadCloser
|
||||||
command *string
|
command *string
|
||||||
|
killed bool
|
||||||
wait bool
|
wait bool
|
||||||
}
|
}
|
||||||
|
|
||||||
// NewReader returns new Reader object
|
// NewReader returns new Reader object
|
||||||
func NewReader(pusher func([]byte) bool, eventBox *util.EventBox, executor *util.Executor, delimNil bool, wait bool) *Reader {
|
func NewReader(pusher func([]byte) bool, eventBox *util.EventBox, executor *util.Executor, delimNil bool, wait bool) *Reader {
|
||||||
return &Reader{
|
return &Reader{pusher, executor, eventBox, delimNil, int32(EvtReady), make(chan bool, 1), sync.Mutex{}, nil, nil, nil, false, wait}
|
||||||
pusher,
|
|
||||||
executor,
|
|
||||||
eventBox,
|
|
||||||
delimNil,
|
|
||||||
int32(EvtReady),
|
|
||||||
make(chan bool, 1),
|
|
||||||
sync.Mutex{},
|
|
||||||
false,
|
|
||||||
func() { os.Stdin.Close() },
|
|
||||||
nil,
|
|
||||||
wait}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *Reader) startEventPoller() {
|
func (r *Reader) startEventPoller() {
|
||||||
@@ -91,19 +80,19 @@ func (r *Reader) fin(success bool) {
|
|||||||
func (r *Reader) terminate() {
|
func (r *Reader) terminate() {
|
||||||
r.mutex.Lock()
|
r.mutex.Lock()
|
||||||
r.killed = true
|
r.killed = true
|
||||||
if r.termFunc != nil {
|
if r.exec != nil && r.exec.Process != nil {
|
||||||
r.termFunc()
|
r.execOut.Close()
|
||||||
r.termFunc = nil
|
util.KillCommand(r.exec)
|
||||||
|
} else {
|
||||||
|
os.Stdin.Close()
|
||||||
}
|
}
|
||||||
r.mutex.Unlock()
|
r.mutex.Unlock()
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *Reader) restart(command commandSpec, environ []string, readyChan chan bool) {
|
func (r *Reader) restart(command commandSpec, environ []string) {
|
||||||
r.event = int32(EvtReady)
|
r.event = int32(EvtReady)
|
||||||
r.startEventPoller()
|
r.startEventPoller()
|
||||||
success := r.readFromCommand(command.command, environ, func() {
|
success := r.readFromCommand(command.command, environ)
|
||||||
readyChan <- true
|
|
||||||
})
|
|
||||||
r.fin(success)
|
r.fin(success)
|
||||||
removeFiles(command.tempFiles)
|
removeFiles(command.tempFiles)
|
||||||
}
|
}
|
||||||
@@ -122,29 +111,21 @@ func (r *Reader) readChannel(inputChan chan string) bool {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// ReadSource reads data from the default command or from standard input
|
// ReadSource reads data from the default command or from standard input
|
||||||
func (r *Reader) ReadSource(inputChan chan string, roots []string, opts walkerOpts, ignores []string, initCmd string, initEnv []string, readyChan chan bool) {
|
func (r *Reader) ReadSource(inputChan chan string, root string, opts walkerOpts, ignores []string, initCmd string, initEnv []string) {
|
||||||
r.startEventPoller()
|
r.startEventPoller()
|
||||||
var success bool
|
var success bool
|
||||||
signalReady := func() {
|
|
||||||
if readyChan != nil {
|
|
||||||
readyChan <- true
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if inputChan != nil {
|
if inputChan != nil {
|
||||||
signalReady()
|
|
||||||
success = r.readChannel(inputChan)
|
success = r.readChannel(inputChan)
|
||||||
} else if len(initCmd) > 0 {
|
} else if len(initCmd) > 0 {
|
||||||
success = r.readFromCommand(initCmd, initEnv, signalReady)
|
success = r.readFromCommand(initCmd, initEnv)
|
||||||
} else if util.IsTty(os.Stdin) {
|
} else if util.IsTty(os.Stdin) {
|
||||||
cmd := os.Getenv("FZF_DEFAULT_COMMAND")
|
cmd := os.Getenv("FZF_DEFAULT_COMMAND")
|
||||||
if len(cmd) == 0 {
|
if len(cmd) == 0 {
|
||||||
signalReady()
|
success = r.readFiles(root, opts, ignores)
|
||||||
success = r.readFiles(roots, opts, ignores)
|
|
||||||
} else {
|
} else {
|
||||||
success = r.readFromCommand(cmd, initEnv, signalReady)
|
success = r.readFromCommand(cmd, initEnv)
|
||||||
}
|
}
|
||||||
} else {
|
} else {
|
||||||
signalReady()
|
|
||||||
success = r.readFromStdin()
|
success = r.readFromStdin()
|
||||||
}
|
}
|
||||||
r.fin(success)
|
r.fin(success)
|
||||||
@@ -178,8 +159,8 @@ func (r *Reader) feed(src io.Reader) {
|
|||||||
var err error
|
var err error
|
||||||
for {
|
for {
|
||||||
n := 0
|
n := 0
|
||||||
scope := slab[:min(len(slab), readerBufferSize)]
|
scope := slab[:util.Min(len(slab), readerBufferSize)]
|
||||||
for range 100 {
|
for i := 0; i < 100; i++ {
|
||||||
n, err = src.Read(scope)
|
n, err = src.Read(scope)
|
||||||
if n > 0 || err != nil {
|
if n > 0 || err != nil {
|
||||||
break
|
break
|
||||||
@@ -267,102 +248,31 @@ func trimPath(path string) string {
|
|||||||
return byteString(bytes)
|
return byteString(bytes)
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *Reader) readFiles(roots []string, opts walkerOpts, ignores []string) bool {
|
func (r *Reader) readFiles(root string, opts walkerOpts, ignores []string) bool {
|
||||||
|
r.killed = false
|
||||||
conf := fastwalk.Config{
|
conf := fastwalk.Config{
|
||||||
Follow: opts.follow,
|
Follow: opts.follow,
|
||||||
// Use forward slashes when running a Windows binary under WSL or MSYS
|
// Use forward slashes when running a Windows binary under WSL or MSYS
|
||||||
ToSlash: fastwalk.DefaultToSlash(),
|
ToSlash: fastwalk.DefaultToSlash(),
|
||||||
Sort: fastwalk.SortFilesFirst,
|
Sort: fastwalk.SortFilesFirst,
|
||||||
}
|
}
|
||||||
|
|
||||||
// When following symlinks, precompute the absolute real paths of walker
|
|
||||||
// roots so we can skip symlinks that point to an ancestor. fastwalk's
|
|
||||||
// built-in loop detection (shouldTraverse) catches loops on the second
|
|
||||||
// pass, but a single pass through a symlink like z: -> / already
|
|
||||||
// traverses the entire root filesystem, causing severe resource
|
|
||||||
// exhaustion. Skipping ancestor symlinks prevents this entirely.
|
|
||||||
var absRoots []string
|
|
||||||
if opts.follow {
|
|
||||||
for _, root := range roots {
|
|
||||||
if real, err := filepath.EvalSymlinks(root); err == nil {
|
|
||||||
if abs, err := filepath.Abs(real); err == nil {
|
|
||||||
absRoots = append(absRoots, filepath.Clean(abs))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
ignoresBase := []string{}
|
|
||||||
ignoresFull := []string{}
|
|
||||||
ignoresSuffix := []string{}
|
|
||||||
sep := string(os.PathSeparator)
|
|
||||||
if _, ok := os.LookupEnv("MSYSTEM"); ok {
|
|
||||||
sep = "/"
|
|
||||||
}
|
|
||||||
for _, ignore := range ignores {
|
|
||||||
if strings.ContainsRune(ignore, os.PathSeparator) {
|
|
||||||
if strings.HasPrefix(ignore, sep) {
|
|
||||||
ignoresSuffix = append(ignoresSuffix, ignore)
|
|
||||||
} else {
|
|
||||||
// 'foo/bar' should match
|
|
||||||
// * 'foo/bar'
|
|
||||||
// * 'baz/foo/bar'
|
|
||||||
// * but NOT 'bazfoo/bar'
|
|
||||||
ignoresFull = append(ignoresFull, ignore)
|
|
||||||
ignoresSuffix = append(ignoresSuffix, sep+ignore)
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
ignoresBase = append(ignoresBase, ignore)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
fn := func(path string, de os.DirEntry, err error) error {
|
fn := func(path string, de os.DirEntry, err error) error {
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
path = trimPath(path)
|
path = trimPath(path)
|
||||||
if path != "." {
|
if path != "." {
|
||||||
isDirSymlink := isSymlinkToDir(path, de)
|
isDir := de.IsDir()
|
||||||
if isDirSymlink && !opts.follow {
|
if isDir || opts.follow && isSymlinkToDir(path, de) {
|
||||||
return filepath.SkipDir
|
|
||||||
}
|
|
||||||
// Skip symlinks whose target is an ancestor of (or equal to)
|
|
||||||
// any walker root. Following such symlinks would traverse a
|
|
||||||
// superset of the tree we're already walking.
|
|
||||||
if isDirSymlink && len(absRoots) > 0 {
|
|
||||||
if target, err := filepath.EvalSymlinks(path); err == nil {
|
|
||||||
if abs, err := filepath.Abs(target); err == nil {
|
|
||||||
abs = filepath.Clean(abs)
|
|
||||||
if abs == string(os.PathSeparator) {
|
|
||||||
return filepath.SkipDir
|
|
||||||
}
|
|
||||||
for _, absRoot := range absRoots {
|
|
||||||
if absRoot == abs || strings.HasPrefix(absRoot, abs+string(os.PathSeparator)) {
|
|
||||||
return filepath.SkipDir
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
isDir := de.IsDir() || isDirSymlink
|
|
||||||
if isDir {
|
|
||||||
base := filepath.Base(path)
|
base := filepath.Base(path)
|
||||||
if !opts.hidden && base[0] == '.' && base != ".." {
|
if !opts.hidden && base[0] == '.' {
|
||||||
return filepath.SkipDir
|
return filepath.SkipDir
|
||||||
}
|
}
|
||||||
if slices.Contains(ignoresBase, base) {
|
for _, ignore := range ignores {
|
||||||
return filepath.SkipDir
|
if ignore == base {
|
||||||
}
|
|
||||||
if slices.Contains(ignoresFull, path) {
|
|
||||||
return filepath.SkipDir
|
|
||||||
}
|
|
||||||
for _, ignore := range ignoresSuffix {
|
|
||||||
if strings.HasSuffix(path, ignore) {
|
|
||||||
return filepath.SkipDir
|
return filepath.SkipDir
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
if path != sep {
|
|
||||||
path += sep
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
if ((opts.file && !isDir) || (opts.dir && isDir)) && r.pusher(stringBytes(path)) {
|
if ((opts.file && !isDir) || (opts.dir && isDir)) && r.pusher(stringBytes(path)) {
|
||||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||||
@@ -375,39 +285,34 @@ func (r *Reader) readFiles(roots []string, opts walkerOpts, ignores []string) bo
|
|||||||
}
|
}
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
noerr := true
|
return fastwalk.Walk(&conf, root, fn) == nil
|
||||||
for _, root := range roots {
|
|
||||||
noerr = noerr && (fastwalk.Walk(&conf, root, fn) == nil)
|
|
||||||
}
|
|
||||||
return noerr
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *Reader) readFromCommand(command string, environ []string, signalReady func()) bool {
|
func (r *Reader) readFromCommand(command string, environ []string) bool {
|
||||||
r.mutex.Lock()
|
r.mutex.Lock()
|
||||||
|
|
||||||
r.killed = false
|
r.killed = false
|
||||||
r.termFunc = nil
|
|
||||||
r.command = &command
|
r.command = &command
|
||||||
exec := r.executor.ExecCommand(command, true)
|
r.exec = r.executor.ExecCommand(command, true)
|
||||||
if environ != nil {
|
if environ != nil {
|
||||||
exec.Env = environ
|
r.exec.Env = environ
|
||||||
}
|
}
|
||||||
execOut, err := exec.StdoutPipe()
|
|
||||||
if err != nil || exec.Start() != nil {
|
var err error
|
||||||
signalReady()
|
r.execOut, err = r.exec.StdoutPipe()
|
||||||
|
if err != nil {
|
||||||
|
r.exec = nil
|
||||||
r.mutex.Unlock()
|
r.mutex.Unlock()
|
||||||
return false
|
return false
|
||||||
}
|
}
|
||||||
|
|
||||||
// Function to call to terminate the running command
|
err = r.exec.Start()
|
||||||
r.termFunc = func() {
|
if err != nil {
|
||||||
execOut.Close()
|
r.exec = nil
|
||||||
util.KillCommand(exec)
|
r.mutex.Unlock()
|
||||||
|
return false
|
||||||
}
|
}
|
||||||
|
|
||||||
signalReady()
|
|
||||||
r.mutex.Unlock()
|
r.mutex.Unlock()
|
||||||
|
r.feed(r.execOut)
|
||||||
r.feed(execOut)
|
return r.exec.Wait() == nil
|
||||||
return exec.Wait() == nil
|
|
||||||
}
|
}
|
||||||
|
|||||||
+4
-8
@@ -23,12 +23,8 @@ func TestReadFromCommand(t *testing.T) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Normal command
|
// Normal command
|
||||||
counter := 0
|
reader.fin(reader.readFromCommand(`echo abc&&echo def`, nil))
|
||||||
ready := func() {
|
if len(strs) != 2 || strs[0] != "abc" || strs[1] != "def" {
|
||||||
counter++
|
|
||||||
}
|
|
||||||
reader.fin(reader.readFromCommand(`echo abc&&echo def`, nil, ready))
|
|
||||||
if len(strs) != 2 || strs[0] != "abc" || strs[1] != "def" || counter != 1 {
|
|
||||||
t.Errorf("%s", strs)
|
t.Errorf("%s", strs)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -52,9 +48,9 @@ func TestReadFromCommand(t *testing.T) {
|
|||||||
reader.startEventPoller()
|
reader.startEventPoller()
|
||||||
|
|
||||||
// Failing command
|
// Failing command
|
||||||
reader.fin(reader.readFromCommand(`no-such-command`, nil, ready))
|
reader.fin(reader.readFromCommand(`no-such-command`, nil))
|
||||||
strs = []string{}
|
strs = []string{}
|
||||||
if len(strs) > 0 || counter != 2 {
|
if len(strs) > 0 {
|
||||||
t.Errorf("%s", strs)
|
t.Errorf("%s", strs)
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
+57
-213
@@ -2,7 +2,6 @@ package fzf
|
|||||||
|
|
||||||
import (
|
import (
|
||||||
"math"
|
"math"
|
||||||
"slices"
|
|
||||||
"sort"
|
"sort"
|
||||||
"unicode"
|
"unicode"
|
||||||
|
|
||||||
@@ -20,10 +19,6 @@ type colorOffset struct {
|
|||||||
url *url
|
url *url
|
||||||
}
|
}
|
||||||
|
|
||||||
func (co colorOffset) IsFullBgMarker(at int32) bool {
|
|
||||||
return at == co.offset[0] && at == co.offset[1] && co.color.Attr()&tui.FullBg > 0
|
|
||||||
}
|
|
||||||
|
|
||||||
type Result struct {
|
type Result struct {
|
||||||
item *Item
|
item *Item
|
||||||
points [4]uint16
|
points [4]uint16
|
||||||
@@ -31,9 +26,11 @@ type Result struct {
|
|||||||
|
|
||||||
func buildResult(item *Item, offsets []Offset, score int) Result {
|
func buildResult(item *Item, offsets []Offset, score int) Result {
|
||||||
if len(offsets) > 1 {
|
if len(offsets) > 1 {
|
||||||
slices.SortFunc(offsets, compareOffsets)
|
sort.Sort(ByOrder(offsets))
|
||||||
}
|
}
|
||||||
|
|
||||||
|
result := Result{item: item}
|
||||||
|
numChars := item.text.Length()
|
||||||
minBegin := math.MaxUint16
|
minBegin := math.MaxUint16
|
||||||
minEnd := math.MaxUint16
|
minEnd := math.MaxUint16
|
||||||
maxEnd := 0
|
maxEnd := 0
|
||||||
@@ -41,21 +38,13 @@ func buildResult(item *Item, offsets []Offset, score int) Result {
|
|||||||
for _, offset := range offsets {
|
for _, offset := range offsets {
|
||||||
b, e := int(offset[0]), int(offset[1])
|
b, e := int(offset[0]), int(offset[1])
|
||||||
if b < e {
|
if b < e {
|
||||||
minBegin = min(b, minBegin)
|
minBegin = util.Min(b, minBegin)
|
||||||
minEnd = min(e, minEnd)
|
minEnd = util.Min(e, minEnd)
|
||||||
maxEnd = max(e, maxEnd)
|
maxEnd = util.Max(e, maxEnd)
|
||||||
validOffsetFound = true
|
validOffsetFound = true
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
return buildResultFromBounds(item, score, minBegin, minEnd, maxEnd, validOffsetFound)
|
|
||||||
}
|
|
||||||
|
|
||||||
// buildResultFromBounds builds a Result from pre-computed offset bounds.
|
|
||||||
func buildResultFromBounds(item *Item, score int, minBegin, minEnd, maxEnd int, validOffsetFound bool) Result {
|
|
||||||
result := Result{item: item}
|
|
||||||
numChars := item.text.Length()
|
|
||||||
|
|
||||||
for idx, criterion := range sortCriteria {
|
for idx, criterion := range sortCriteria {
|
||||||
val := uint16(math.MaxUint16)
|
val := uint16(math.MaxUint16)
|
||||||
switch criterion {
|
switch criterion {
|
||||||
@@ -80,24 +69,10 @@ func buildResultFromBounds(item *Item, score int, minBegin, minEnd, maxEnd int,
|
|||||||
}
|
}
|
||||||
case byLength:
|
case byLength:
|
||||||
val = item.TrimLength()
|
val = item.TrimLength()
|
||||||
case byPathname:
|
|
||||||
if validOffsetFound {
|
|
||||||
lastDelim := -1
|
|
||||||
s := item.text.ToString()
|
|
||||||
for i := len(s) - 1; i >= 0; i-- {
|
|
||||||
if s[i] == '/' || s[i] == '\\' {
|
|
||||||
lastDelim = i
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
if lastDelim <= minBegin {
|
|
||||||
val = util.AsUint16(minBegin - lastDelim)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
case byBegin, byEnd:
|
case byBegin, byEnd:
|
||||||
if validOffsetFound {
|
if validOffsetFound {
|
||||||
whitePrefixLen := 0
|
whitePrefixLen := 0
|
||||||
for idx := range numChars {
|
for idx := 0; idx < numChars; idx++ {
|
||||||
r := item.text.Get(idx)
|
r := item.text.Get(idx)
|
||||||
whitePrefixLen = idx
|
whitePrefixLen = idx
|
||||||
if idx == minBegin || !unicode.IsSpace(r) {
|
if idx == minBegin || !unicode.IsSpace(r) {
|
||||||
@@ -129,21 +104,21 @@ func minRank() Result {
|
|||||||
return Result{item: &minItem, points: [4]uint16{math.MaxUint16, 0, 0, 0}}
|
return Result{item: &minItem, points: [4]uint16{math.MaxUint16, 0, 0, 0}}
|
||||||
}
|
}
|
||||||
|
|
||||||
func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, theme *tui.ColorTheme, colBase tui.ColorPair, colMatch tui.ColorPair, attrNth tui.Attr, nthOverlay tui.Attr, hidden bool) []colorOffset {
|
func (result *Result) colorOffsets(matchOffsets []Offset, theme *tui.ColorTheme, colBase tui.ColorPair, colMatch tui.ColorPair, current bool) []colorOffset {
|
||||||
itemColors := result.item.Colors()
|
itemColors := result.item.Colors()
|
||||||
|
|
||||||
// No ANSI codes
|
// No ANSI codes
|
||||||
if len(itemColors) == 0 && len(nthOffsets) == 0 {
|
if len(itemColors) == 0 {
|
||||||
offsets := make([]colorOffset, len(matchOffsets))
|
var offsets []colorOffset
|
||||||
for i, off := range matchOffsets {
|
for _, off := range matchOffsets {
|
||||||
offsets[i] = colorOffset{offset: [2]int32{off[0], off[1]}, color: colMatch, match: true}
|
offsets = append(offsets, colorOffset{offset: [2]int32{off[0], off[1]}, color: colMatch, match: true})
|
||||||
}
|
}
|
||||||
return offsets
|
return offsets
|
||||||
}
|
}
|
||||||
|
|
||||||
// Find max column
|
// Find max column
|
||||||
var maxCol int32
|
var maxCol int32
|
||||||
for _, off := range append(matchOffsets, nthOffsets...) {
|
for _, off := range matchOffsets {
|
||||||
if off[1] > maxCol {
|
if off[1] > maxCol {
|
||||||
maxCol = off[1]
|
maxCol = off[1]
|
||||||
}
|
}
|
||||||
@@ -154,93 +129,58 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
type cellInfo struct {
|
cols := make([]int, maxCol)
|
||||||
index int
|
|
||||||
color bool
|
|
||||||
match bool
|
|
||||||
nth bool
|
|
||||||
fbg tui.Color
|
|
||||||
}
|
|
||||||
|
|
||||||
cols := make([]cellInfo, maxCol+1)
|
|
||||||
for idx := range cols {
|
|
||||||
cols[idx].fbg = -1
|
|
||||||
}
|
|
||||||
for colorIndex, ansi := range itemColors {
|
for colorIndex, ansi := range itemColors {
|
||||||
if ansi.offset[0] == ansi.offset[1] && ansi.color.attr&tui.FullBg > 0 {
|
for i := ansi.offset[0]; i < ansi.offset[1]; i++ {
|
||||||
cols[ansi.offset[0]].fbg = ansi.color.lbg
|
cols[i] = colorIndex + 1 // 1-based index of itemColors
|
||||||
} else {
|
|
||||||
for i := ansi.offset[0]; i < ansi.offset[1]; i++ {
|
|
||||||
cols[i] = cellInfo{colorIndex, true, false, false, cols[i].fbg}
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, off := range matchOffsets {
|
for _, off := range matchOffsets {
|
||||||
for i := off[0]; i < off[1]; i++ {
|
for i := off[0]; i < off[1]; i++ {
|
||||||
cols[i].match = true
|
// Negative of 1-based index of itemColors
|
||||||
|
// - The extra -1 means highlighted
|
||||||
|
if cols[i] >= 0 {
|
||||||
|
cols[i] = cols[i]*-1 - 1
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
for _, off := range nthOffsets {
|
// sort.Sort(ByOrder(offsets))
|
||||||
for i := off[0]; i < off[1]; i++ {
|
|
||||||
cols[i].nth = true
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// slices.SortFunc(offsets, compareOffsets)
|
|
||||||
|
|
||||||
// Merge offsets
|
// Merge offsets
|
||||||
// ------------ ---- -- ----
|
// ------------ ---- -- ----
|
||||||
// ++++++++ ++++++++++
|
// ++++++++ ++++++++++
|
||||||
// --++++++++-- --++++++++++---
|
// --++++++++-- --++++++++++---
|
||||||
curr := cellInfo{0, false, false, false, -1}
|
curr := 0
|
||||||
start := 0
|
start := 0
|
||||||
ansiToColorPair := func(ansi ansiOffset, base tui.ColorPair) tui.ColorPair {
|
ansiToColorPair := func(ansi ansiOffset, base tui.ColorPair) tui.ColorPair {
|
||||||
if !theme.Colored {
|
|
||||||
// Ignore ANSI colors but keep the attributes. Retain the base
|
|
||||||
// colors (e.g. an overridden input-bg or list-bg) instead of
|
|
||||||
// resetting to the terminal default.
|
|
||||||
return tui.NewColorPair(base.Fg(), base.Bg(), ansi.color.attr).MergeAttr(base)
|
|
||||||
}
|
|
||||||
// fd --color always | fzf --ansi --delimiter / --nth -1 --color fg:dim:strip,nth:regular
|
|
||||||
if base.ShouldStripColors() {
|
|
||||||
return base
|
|
||||||
}
|
|
||||||
fg := ansi.color.fg
|
fg := ansi.color.fg
|
||||||
bg := ansi.color.bg
|
bg := ansi.color.bg
|
||||||
if fg == -1 {
|
if fg == -1 {
|
||||||
fg = colBase.Fg()
|
if current {
|
||||||
|
fg = theme.Current.Color
|
||||||
|
} else {
|
||||||
|
fg = theme.Fg.Color
|
||||||
|
}
|
||||||
}
|
}
|
||||||
if bg == -1 {
|
if bg == -1 {
|
||||||
bg = colBase.Bg()
|
if current {
|
||||||
|
bg = theme.DarkBg.Color
|
||||||
|
} else {
|
||||||
|
bg = theme.Bg.Color
|
||||||
|
}
|
||||||
}
|
}
|
||||||
return tui.NewColorPair(fg, bg, ansi.color.attr).WithUl(ansi.color.ul).MergeAttr(base)
|
return tui.NewColorPair(fg, bg, ansi.color.attr).MergeAttr(base)
|
||||||
}
|
}
|
||||||
fgAttr := tui.ColNormal.Attr()
|
|
||||||
nthAttrFinal := fgAttr.Merge(attrNth).Merge(nthOverlay)
|
|
||||||
nthBase := colBase.WithNewAttr(nthAttrFinal)
|
|
||||||
|
|
||||||
var colors []colorOffset
|
var colors []colorOffset
|
||||||
add := func(idx int) {
|
add := func(idx int) {
|
||||||
if curr.fbg >= 0 {
|
if curr != 0 && idx > start {
|
||||||
colors = append(colors, colorOffset{
|
if curr < 0 {
|
||||||
offset: [2]int32{int32(start), int32(start)},
|
color := colMatch
|
||||||
color: tui.NewColorPair(-1, curr.fbg, tui.FullBg),
|
|
||||||
match: false,
|
|
||||||
url: nil})
|
|
||||||
}
|
|
||||||
if (curr.color || curr.nth || curr.match) && idx > start {
|
|
||||||
if curr.match {
|
|
||||||
var color tui.ColorPair
|
|
||||||
if curr.nth {
|
|
||||||
color = nthBase.Merge(colMatch)
|
|
||||||
} else {
|
|
||||||
color = colBase.Merge(colMatch)
|
|
||||||
}
|
|
||||||
var url *url
|
var url *url
|
||||||
if curr.color {
|
if curr < -1 && theme.Colored {
|
||||||
ansi := itemColors[curr.index]
|
ansi := itemColors[-curr-2]
|
||||||
url = ansi.color.url
|
url = ansi.color.url
|
||||||
origColor := ansiToColorPair(ansi, colMatch)
|
origColor := ansiToColorPair(ansi, colMatch)
|
||||||
// hl or hl+ only sets the foreground color, so colMatch is the
|
// hl or hl+ only sets the foreground color, so colMatch is the
|
||||||
@@ -253,40 +193,19 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
|||||||
// echo -e "\x1b[42mfoo\x1b[mbar" | fzf --ansi --color bg+:1,hl+:-1:underline
|
// echo -e "\x1b[42mfoo\x1b[mbar" | fzf --ansi --color bg+:1,hl+:-1:underline
|
||||||
if color.Fg().IsDefault() && origColor.HasBg() {
|
if color.Fg().IsDefault() && origColor.HasBg() {
|
||||||
color = origColor
|
color = origColor
|
||||||
if curr.nth {
|
|
||||||
color = color.WithAttr((attrNth &^ tui.AttrRegular).Merge(nthOverlay))
|
|
||||||
}
|
|
||||||
} else {
|
} else {
|
||||||
color = origColor.MergeNonDefault(color)
|
color = origColor.MergeNonDefault(color)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
colors = append(colors, colorOffset{
|
colors = append(colors, colorOffset{
|
||||||
offset: [2]int32{int32(start), int32(idx)}, color: color, match: true, url: url})
|
offset: [2]int32{int32(start), int32(idx)}, color: color, match: true, url: url})
|
||||||
} else if curr.color {
|
} else {
|
||||||
ansi := itemColors[curr.index]
|
ansi := itemColors[curr-1]
|
||||||
base := colBase
|
|
||||||
if curr.nth {
|
|
||||||
base = nthBase
|
|
||||||
}
|
|
||||||
if hidden {
|
|
||||||
base = base.WithFg(theme.Nomatch)
|
|
||||||
}
|
|
||||||
color := ansiToColorPair(ansi, base)
|
|
||||||
colors = append(colors, colorOffset{
|
colors = append(colors, colorOffset{
|
||||||
offset: [2]int32{int32(start), int32(idx)},
|
offset: [2]int32{int32(start), int32(idx)},
|
||||||
color: color,
|
color: ansiToColorPair(ansi, colBase),
|
||||||
match: false,
|
match: false,
|
||||||
url: ansi.color.url})
|
url: ansi.color.url})
|
||||||
} else {
|
|
||||||
color := nthBase
|
|
||||||
if hidden {
|
|
||||||
color = color.WithFg(theme.Nomatch)
|
|
||||||
}
|
|
||||||
colors = append(colors, colorOffset{
|
|
||||||
offset: [2]int32{int32(start), int32(idx)},
|
|
||||||
color: color,
|
|
||||||
match: false,
|
|
||||||
url: nil})
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -301,20 +220,21 @@ func (result *Result) colorOffsets(matchOffsets []Offset, nthOffsets []Offset, t
|
|||||||
return colors
|
return colors
|
||||||
}
|
}
|
||||||
|
|
||||||
func compareOffsets(a, b Offset) int {
|
// ByOrder is for sorting substring offsets
|
||||||
if a[0] < b[0] {
|
type ByOrder []Offset
|
||||||
return -1
|
|
||||||
}
|
func (a ByOrder) Len() int {
|
||||||
if a[0] > b[0] {
|
return len(a)
|
||||||
return 1
|
}
|
||||||
}
|
|
||||||
if a[1] < b[1] {
|
func (a ByOrder) Swap(i, j int) {
|
||||||
return -1
|
a[i], a[j] = a[j], a[i]
|
||||||
}
|
}
|
||||||
if a[1] > b[1] {
|
|
||||||
return 1
|
func (a ByOrder) Less(i, j int) bool {
|
||||||
}
|
ioff := a[i]
|
||||||
return 0
|
joff := a[j]
|
||||||
|
return (ioff[0] < joff[0]) || (ioff[0] == joff[0]) && (ioff[1] <= joff[1])
|
||||||
}
|
}
|
||||||
|
|
||||||
// ByRelevance is for sorting Items
|
// ByRelevance is for sorting Items
|
||||||
@@ -346,79 +266,3 @@ func (a ByRelevanceTac) Swap(i, j int) {
|
|||||||
func (a ByRelevanceTac) Less(i, j int) bool {
|
func (a ByRelevanceTac) Less(i, j int) bool {
|
||||||
return compareRanks(a[i], a[j], true)
|
return compareRanks(a[i], a[j], true)
|
||||||
}
|
}
|
||||||
|
|
||||||
// radixSortResults sorts Results by their points key using LSD radix sort.
|
|
||||||
// O(n) time complexity vs O(n log n) for comparison sort.
|
|
||||||
// The sort is stable, so equal-key items maintain original (item-index) order.
|
|
||||||
// For tac mode, runs of equal keys are reversed after sorting.
|
|
||||||
func radixSortResults(a []Result, tac bool, scratch []Result) []Result {
|
|
||||||
n := len(a)
|
|
||||||
if n < 128 {
|
|
||||||
if tac {
|
|
||||||
sort.Sort(ByRelevanceTac(a))
|
|
||||||
} else {
|
|
||||||
sort.Sort(ByRelevance(a))
|
|
||||||
}
|
|
||||||
return scratch[:0]
|
|
||||||
}
|
|
||||||
|
|
||||||
if cap(scratch) < n {
|
|
||||||
scratch = make([]Result, n)
|
|
||||||
}
|
|
||||||
buf := scratch[:n]
|
|
||||||
src, dst := a, buf
|
|
||||||
scattered := 0
|
|
||||||
|
|
||||||
for pass := range 8 {
|
|
||||||
shift := uint(pass) * 8
|
|
||||||
|
|
||||||
var count [256]int
|
|
||||||
for i := range src {
|
|
||||||
count[byte(sortKey(&src[i])>>shift)]++
|
|
||||||
}
|
|
||||||
|
|
||||||
// Skip if all items have the same byte value at this position
|
|
||||||
if count[byte(sortKey(&src[0])>>shift)] == n {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
|
|
||||||
var offset [256]int
|
|
||||||
for i := 1; i < 256; i++ {
|
|
||||||
offset[i] = offset[i-1] + count[i-1]
|
|
||||||
}
|
|
||||||
|
|
||||||
for i := range src {
|
|
||||||
b := byte(sortKey(&src[i]) >> shift)
|
|
||||||
dst[offset[b]] = src[i]
|
|
||||||
offset[b]++
|
|
||||||
}
|
|
||||||
|
|
||||||
src, dst = dst, src
|
|
||||||
scattered++
|
|
||||||
}
|
|
||||||
|
|
||||||
// If odd number of scatters, data is in buf, copy back to a
|
|
||||||
if scattered%2 == 1 {
|
|
||||||
copy(a, src)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Handle tac: reverse runs of equal keys so equal-key items
|
|
||||||
// are in reverse item-index order
|
|
||||||
if tac {
|
|
||||||
i := 0
|
|
||||||
for i < n {
|
|
||||||
ki := sortKey(&a[i])
|
|
||||||
j := i + 1
|
|
||||||
for j < n && sortKey(&a[j]) == ki {
|
|
||||||
j++
|
|
||||||
}
|
|
||||||
if j-i > 1 {
|
|
||||||
for l, r := i, j-1; l < r; l, r = l+1, r-1 {
|
|
||||||
a[l], a[r] = a[r], a[l]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
i = j
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return scratch
|
|
||||||
}
|
|
||||||
|
|||||||
@@ -1,4 +1,4 @@
|
|||||||
//go:build !386 && !amd64 && !arm64
|
//go:build !386 && !amd64
|
||||||
|
|
||||||
package fzf
|
package fzf
|
||||||
|
|
||||||
@@ -14,7 +14,3 @@ func compareRanks(irank Result, jrank Result, tac bool) bool {
|
|||||||
}
|
}
|
||||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||||
}
|
}
|
||||||
|
|
||||||
func sortKey(r *Result) uint64 {
|
|
||||||
return uint64(r.points[0]) | uint64(r.points[1])<<16 | uint64(r.points[2])<<32 | uint64(r.points[3])<<48
|
|
||||||
}
|
|
||||||
|
|||||||
+12
-112
@@ -2,8 +2,6 @@ package fzf
|
|||||||
|
|
||||||
import (
|
import (
|
||||||
"math"
|
"math"
|
||||||
"math/rand"
|
|
||||||
"slices"
|
|
||||||
"sort"
|
"sort"
|
||||||
"testing"
|
"testing"
|
||||||
|
|
||||||
@@ -20,7 +18,7 @@ func TestOffsetSort(t *testing.T) {
|
|||||||
offsets := []Offset{
|
offsets := []Offset{
|
||||||
{3, 5}, {2, 7},
|
{3, 5}, {2, 7},
|
||||||
{1, 3}, {2, 9}}
|
{1, 3}, {2, 9}}
|
||||||
slices.SortFunc(offsets, compareOffsets)
|
sort.Sort(ByOrder(offsets))
|
||||||
|
|
||||||
if offsets[0][0] != 1 || offsets[0][1] != 3 ||
|
if offsets[0][0] != 1 || offsets[0][1] != 3 ||
|
||||||
offsets[1][0] != 2 || offsets[1][1] != 7 ||
|
offsets[1][0] != 2 || offsets[1][1] != 7 ||
|
||||||
@@ -126,14 +124,14 @@ func TestColorOffset(t *testing.T) {
|
|||||||
item := Result{
|
item := Result{
|
||||||
item: &Item{
|
item: &Item{
|
||||||
colors: &[]ansiOffset{
|
colors: &[]ansiOffset{
|
||||||
{[2]int32{0, 20}, ansiState{1, 5, -1, 0, -1, nil}},
|
{[2]int32{0, 20}, ansiState{1, 5, 0, -1, nil}},
|
||||||
{[2]int32{22, 27}, ansiState{2, 6, -1, tui.Bold, -1, nil}},
|
{[2]int32{22, 27}, ansiState{2, 6, tui.Bold, -1, nil}},
|
||||||
{[2]int32{30, 32}, ansiState{3, 7, -1, 0, -1, nil}},
|
{[2]int32{30, 32}, ansiState{3, 7, 0, -1, nil}},
|
||||||
{[2]int32{33, 40}, ansiState{4, 8, -1, tui.Bold, -1, nil}}}}}
|
{[2]int32{33, 40}, ansiState{4, 8, tui.Bold, -1, nil}}}}}
|
||||||
|
|
||||||
colBase := tui.NewColorPair(89, 189, tui.AttrUndefined)
|
colBase := tui.NewColorPair(89, 189, tui.AttrUndefined)
|
||||||
colMatch := tui.NewColorPair(99, 199, tui.AttrUndefined)
|
colMatch := tui.NewColorPair(99, 199, tui.AttrUndefined)
|
||||||
colors := item.colorOffsets(offsets, nil, tui.Dark256, colBase, colMatch, tui.AttrUndefined, 0, false)
|
colors := item.colorOffsets(offsets, tui.Dark256, colBase, colMatch, true)
|
||||||
assert := func(idx int, b int32, e int32, c tui.ColorPair) {
|
assert := func(idx int, b int32, e int32, c tui.ColorPair) {
|
||||||
o := colors[idx]
|
o := colors[idx]
|
||||||
if o.offset[0] != b || o.offset[1] != e || o.color != c {
|
if o.offset[0] != b || o.offset[1] != e || o.color != c {
|
||||||
@@ -157,40 +155,12 @@ func TestColorOffset(t *testing.T) {
|
|||||||
|
|
||||||
colRegular := tui.NewColorPair(-1, -1, tui.AttrUndefined)
|
colRegular := tui.NewColorPair(-1, -1, tui.AttrUndefined)
|
||||||
colUnderline := tui.NewColorPair(-1, -1, tui.Underline)
|
colUnderline := tui.NewColorPair(-1, -1, tui.Underline)
|
||||||
|
colors = item.colorOffsets(offsets, tui.Dark256, colRegular, colUnderline, true)
|
||||||
|
|
||||||
nthOffsets := []Offset{{37, 39}, {42, 45}}
|
// [{[0 5] {1 5 0}} {[5 15] {1 5 8}} {[15 20] {1 5 0}}
|
||||||
for _, attr := range []tui.Attr{tui.AttrRegular, tui.StrikeThrough} {
|
// {[22 25] {2 6 1}} {[25 27] {2 6 9}} {[27 30] {-1 -1 8}}
|
||||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, attr, 0, false)
|
// {[30 32] {3 7 8}} {[32 33] {-1 -1 8}} {[33 35] {4 8 9}}
|
||||||
|
// {[35 40] {4 8 1}}]
|
||||||
// [{[0 5] {1 5 0}} {[5 15] {1 5 8}} {[15 20] {1 5 0}}
|
|
||||||
// {[22 25] {2 6 1}} {[25 27] {2 6 9}} {[27 30] {-1 -1 8}}
|
|
||||||
// {[30 32] {3 7 8}} {[32 33] {-1 -1 8}} {[33 35] {4 8 9}}
|
|
||||||
// {[35 37] {4 8 1}} {[37 39] {4 8 x|1}} {[39 40] {4 8 x|1}}]
|
|
||||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
|
||||||
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
|
||||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
|
||||||
assert(3, 22, 25, tui.NewColorPair(2, 6, tui.Bold))
|
|
||||||
assert(4, 25, 27, tui.NewColorPair(2, 6, tui.Bold|tui.Underline))
|
|
||||||
assert(5, 27, 30, colUnderline)
|
|
||||||
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
|
||||||
assert(7, 32, 33, colUnderline)
|
|
||||||
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
|
||||||
assert(9, 35, 37, tui.NewColorPair(4, 8, tui.Bold))
|
|
||||||
expected := tui.Bold | attr
|
|
||||||
if attr == tui.AttrRegular {
|
|
||||||
expected = tui.Bold
|
|
||||||
}
|
|
||||||
assert(10, 37, 39, tui.NewColorPair(4, 8, expected))
|
|
||||||
assert(11, 39, 40, tui.NewColorPair(4, 8, tui.Bold))
|
|
||||||
}
|
|
||||||
|
|
||||||
// Test nthOverlay: simulates nth:regular with current-fg:underline
|
|
||||||
// The overlay (underline) should survive even though nth:regular clears attrs.
|
|
||||||
// Precedence: fg < nth < current-fg
|
|
||||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, tui.AttrRegular, tui.Underline, false)
|
|
||||||
|
|
||||||
// nth regions should have Underline (from overlay), not cleared by AttrRegular
|
|
||||||
// Non-nth regions keep colBase attrs (AttrUndefined)
|
|
||||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||||
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
||||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||||
@@ -200,75 +170,5 @@ func TestColorOffset(t *testing.T) {
|
|||||||
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
||||||
assert(7, 32, 33, colUnderline)
|
assert(7, 32, 33, colUnderline)
|
||||||
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
||||||
assert(9, 35, 37, tui.NewColorPair(4, 8, tui.Bold))
|
assert(9, 35, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||||
// nth region within ANSI bold: AttrRegular clears, overlay adds Underline back
|
|
||||||
assert(10, 37, 39, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
|
||||||
assert(11, 39, 40, tui.NewColorPair(4, 8, tui.Bold))
|
|
||||||
|
|
||||||
// Test nthOverlay with additive attrs: nth:strikethrough with selected-fg:bold
|
|
||||||
colors = item.colorOffsets(offsets, nthOffsets, tui.Dark256, colRegular, colUnderline, tui.StrikeThrough, tui.Bold, false)
|
|
||||||
|
|
||||||
// Non-nth entries unchanged from overlay=0 case
|
|
||||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
|
||||||
assert(5, 27, 30, colUnderline) // match only, no nth
|
|
||||||
assert(7, 32, 33, colUnderline) // match only, no nth
|
|
||||||
// nth region within ANSI bold: StrikeThrough|Bold merged with ANSI Bold
|
|
||||||
assert(10, 37, 39, tui.NewColorPair(4, 8, tui.Bold|tui.StrikeThrough))
|
|
||||||
}
|
|
||||||
|
|
||||||
func TestRadixSortResults(t *testing.T) {
|
|
||||||
sortCriteria = []criterion{byScore, byLength}
|
|
||||||
|
|
||||||
rng := rand.New(rand.NewSource(42))
|
|
||||||
|
|
||||||
for _, n := range []int{128, 256, 500, 1000} {
|
|
||||||
for _, tac := range []bool{false, true} {
|
|
||||||
// Build items with random points and indices
|
|
||||||
items := make([]*Item, n)
|
|
||||||
for i := range items {
|
|
||||||
items[i] = &Item{text: util.Chars{Index: int32(i)}}
|
|
||||||
}
|
|
||||||
|
|
||||||
results := make([]Result, n)
|
|
||||||
for i := range results {
|
|
||||||
results[i] = Result{
|
|
||||||
item: items[i],
|
|
||||||
points: [4]uint16{
|
|
||||||
uint16(rng.Intn(256)),
|
|
||||||
uint16(rng.Intn(256)),
|
|
||||||
uint16(rng.Intn(256)),
|
|
||||||
uint16(rng.Intn(256)),
|
|
||||||
},
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Make some duplicates to test stability
|
|
||||||
for i := 0; i < n/4; i++ {
|
|
||||||
j := rng.Intn(n)
|
|
||||||
k := rng.Intn(n)
|
|
||||||
results[j].points = results[k].points
|
|
||||||
}
|
|
||||||
|
|
||||||
// Copy for reference sort
|
|
||||||
expected := make([]Result, n)
|
|
||||||
copy(expected, results)
|
|
||||||
if tac {
|
|
||||||
sort.Sort(ByRelevanceTac(expected))
|
|
||||||
} else {
|
|
||||||
sort.Sort(ByRelevance(expected))
|
|
||||||
}
|
|
||||||
|
|
||||||
// Radix sort
|
|
||||||
var scratch []Result
|
|
||||||
scratch = radixSortResults(results, tac, scratch)
|
|
||||||
|
|
||||||
for i := range results {
|
|
||||||
if results[i] != expected[i] {
|
|
||||||
t.Errorf("n=%d tac=%v: mismatch at index %d: got item %d, want item %d",
|
|
||||||
n, tac, i, results[i].item.Index(), expected[i].item.Index())
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|||||||
+1
-5
@@ -1,4 +1,4 @@
|
|||||||
//go:build 386 || amd64 || arm64
|
//go:build 386 || amd64
|
||||||
|
|
||||||
package fzf
|
package fzf
|
||||||
|
|
||||||
@@ -14,7 +14,3 @@ func compareRanks(irank Result, jrank Result, tac bool) bool {
|
|||||||
}
|
}
|
||||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||||
}
|
}
|
||||||
|
|
||||||
func sortKey(r *Result) uint64 {
|
|
||||||
return *(*uint64)(unsafe.Pointer(&r.points[0]))
|
|
||||||
}
|
|
||||||
|
|||||||
+38
-69
@@ -46,20 +46,15 @@ type httpServer struct {
|
|||||||
type listenAddress struct {
|
type listenAddress struct {
|
||||||
host string
|
host string
|
||||||
port int
|
port int
|
||||||
sock string
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (addr listenAddress) IsLocal() bool {
|
func (addr listenAddress) IsLocal() bool {
|
||||||
return addr.host == "localhost" || addr.host == "127.0.0.1" || len(addr.sock) > 0
|
return addr.host == "localhost" || addr.host == "127.0.0.1"
|
||||||
}
|
}
|
||||||
|
|
||||||
var defaultListenAddr = listenAddress{"localhost", 0, ""}
|
var defaultListenAddr = listenAddress{"localhost", 0}
|
||||||
|
|
||||||
func parseListenAddress(address string) (listenAddress, error) {
|
func parseListenAddress(address string) (listenAddress, error) {
|
||||||
if strings.HasSuffix(address, ".sock") {
|
|
||||||
return listenAddress{"", 0, address}, nil
|
|
||||||
}
|
|
||||||
|
|
||||||
parts := strings.SplitN(address, ":", 3)
|
parts := strings.SplitN(address, ":", 3)
|
||||||
if len(parts) == 1 {
|
if len(parts) == 1 {
|
||||||
parts = []string{"localhost", parts[0]}
|
parts = []string{"localhost", parts[0]}
|
||||||
@@ -75,7 +70,7 @@ func parseListenAddress(address string) (listenAddress, error) {
|
|||||||
if len(parts[0]) == 0 {
|
if len(parts[0]) == 0 {
|
||||||
parts[0] = "localhost"
|
parts[0] = "localhost"
|
||||||
}
|
}
|
||||||
return listenAddress{parts[0], port, ""}, nil
|
return listenAddress{parts[0], port}, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func startHttpServer(address listenAddress, actionChannel chan []*action, getHandler func(getParams) string) (net.Listener, int, error) {
|
func startHttpServer(address listenAddress, actionChannel chan []*action, getHandler func(getParams) string) (net.Listener, int, error) {
|
||||||
@@ -85,49 +80,31 @@ func startHttpServer(address listenAddress, actionChannel chan []*action, getHan
|
|||||||
if !address.IsLocal() && len(apiKey) == 0 {
|
if !address.IsLocal() && len(apiKey) == 0 {
|
||||||
return nil, port, errors.New("FZF_API_KEY is required to allow remote access")
|
return nil, port, errors.New("FZF_API_KEY is required to allow remote access")
|
||||||
}
|
}
|
||||||
|
addrStr := fmt.Sprintf("%s:%d", host, port)
|
||||||
var listener net.Listener
|
listener, err := net.Listen("tcp", addrStr)
|
||||||
var err error
|
if err != nil {
|
||||||
if len(address.sock) > 0 {
|
return nil, port, fmt.Errorf("failed to listen on %s", addrStr)
|
||||||
if _, err := os.Stat(address.sock); err == nil {
|
}
|
||||||
// Check if the socket is already in use
|
if port == 0 {
|
||||||
if conn, err := net.Dial("unix", address.sock); err == nil {
|
addr := listener.Addr().String()
|
||||||
conn.Close()
|
parts := strings.Split(addr, ":")
|
||||||
return nil, 0, fmt.Errorf("socket already in use: %s", address.sock)
|
if len(parts) < 2 {
|
||||||
}
|
return nil, port, fmt.Errorf("cannot extract port: %s", addr)
|
||||||
os.Remove(address.sock)
|
|
||||||
}
|
}
|
||||||
listener, err = net.Listen("unix", address.sock)
|
var err error
|
||||||
|
port, err = strconv.Atoi(parts[len(parts)-1])
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return nil, 0, fmt.Errorf("failed to listen on %s", address.sock)
|
return nil, port, err
|
||||||
}
|
|
||||||
os.Chmod(address.sock, 0600)
|
|
||||||
} else {
|
|
||||||
addrStr := fmt.Sprintf("%s:%d", host, port)
|
|
||||||
listener, err = net.Listen("tcp", addrStr)
|
|
||||||
if err != nil {
|
|
||||||
return nil, port, fmt.Errorf("failed to listen on %s", addrStr)
|
|
||||||
}
|
|
||||||
if port == 0 {
|
|
||||||
addr := listener.Addr().String()
|
|
||||||
parts := strings.Split(addr, ":")
|
|
||||||
if len(parts) < 2 {
|
|
||||||
return nil, port, fmt.Errorf("cannot extract port: %s", addr)
|
|
||||||
}
|
|
||||||
var err error
|
|
||||||
port, err = strconv.Atoi(parts[len(parts)-1])
|
|
||||||
if err != nil {
|
|
||||||
return nil, port, err
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
server := httpServer{
|
||||||
|
apiKey: []byte(apiKey),
|
||||||
|
actionChannel: actionChannel,
|
||||||
|
getHandler: getHandler,
|
||||||
|
}
|
||||||
|
|
||||||
go func() {
|
go func() {
|
||||||
server := httpServer{
|
|
||||||
apiKey: []byte(apiKey),
|
|
||||||
actionChannel: actionChannel,
|
|
||||||
getHandler: getHandler,
|
|
||||||
}
|
|
||||||
for {
|
for {
|
||||||
conn, err := listener.Accept()
|
conn, err := listener.Accept()
|
||||||
if err != nil {
|
if err != nil {
|
||||||
@@ -153,7 +130,7 @@ func startHttpServer(address listenAddress, actionChannel chan []*action, getHan
|
|||||||
func (server *httpServer) handleHttpRequest(conn net.Conn) string {
|
func (server *httpServer) handleHttpRequest(conn net.Conn) string {
|
||||||
contentLength := 0
|
contentLength := 0
|
||||||
apiKey := ""
|
apiKey := ""
|
||||||
var bodyBuilder strings.Builder
|
body := ""
|
||||||
answer := func(code string, message string) string {
|
answer := func(code string, message string) string {
|
||||||
message += "\n"
|
message += "\n"
|
||||||
return code + fmt.Sprintf("Content-Length: %d%s", len(message), crlf+crlf+message)
|
return code + fmt.Sprintf("Content-Length: %d%s", len(message), crlf+crlf+message)
|
||||||
@@ -175,29 +152,30 @@ func (server *httpServer) handleHttpRequest(conn net.Conn) string {
|
|||||||
token := data[:found+len(crlf)]
|
token := data[:found+len(crlf)]
|
||||||
return len(token), token, nil
|
return len(token), token, nil
|
||||||
}
|
}
|
||||||
if atEOF || bodyBuilder.Len()+len(data) >= contentLength {
|
if atEOF || len(body)+len(data) >= contentLength {
|
||||||
return 0, data, bufio.ErrFinalToken
|
return 0, data, bufio.ErrFinalToken
|
||||||
}
|
}
|
||||||
return 0, nil, nil
|
return 0, nil, nil
|
||||||
})
|
})
|
||||||
|
|
||||||
section := 0
|
section := 0
|
||||||
var getMatch []string
|
|
||||||
Loop:
|
|
||||||
for scanner.Scan() {
|
for scanner.Scan() {
|
||||||
text := scanner.Text()
|
text := scanner.Text()
|
||||||
switch section {
|
switch section {
|
||||||
case 0: // Request line
|
case 0:
|
||||||
getMatch = getRegex.FindStringSubmatch(text)
|
getMatch := getRegex.FindStringSubmatch(text)
|
||||||
if len(getMatch) == 0 && !strings.HasPrefix(text, "POST / HTTP") {
|
if len(getMatch) > 0 {
|
||||||
|
response := server.getHandler(parseGetParams(getMatch[1]))
|
||||||
|
if len(response) > 0 {
|
||||||
|
return good(response)
|
||||||
|
}
|
||||||
|
return answer(httpUnavailable+jsonContentType, `{"error":"timeout"}`)
|
||||||
|
} else if !strings.HasPrefix(text, "POST / HTTP") {
|
||||||
return bad("invalid request method")
|
return bad("invalid request method")
|
||||||
}
|
}
|
||||||
section++
|
section++
|
||||||
case 1: // Request headers
|
case 1:
|
||||||
if text == crlf { // End of headers
|
if text == crlf {
|
||||||
if len(getMatch) > 0 {
|
|
||||||
break Loop
|
|
||||||
}
|
|
||||||
if contentLength == 0 {
|
if contentLength == 0 {
|
||||||
return bad("content-length header missing")
|
return bad("content-length header missing")
|
||||||
}
|
}
|
||||||
@@ -217,8 +195,8 @@ Loop:
|
|||||||
apiKey = strings.TrimSpace(pair[1])
|
apiKey = strings.TrimSpace(pair[1])
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
case 2: // Request body
|
case 2:
|
||||||
bodyBuilder.WriteString(text)
|
body += text
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -226,21 +204,12 @@ Loop:
|
|||||||
return unauthorized("invalid api key")
|
return unauthorized("invalid api key")
|
||||||
}
|
}
|
||||||
|
|
||||||
if len(getMatch) > 0 {
|
|
||||||
response := server.getHandler(parseGetParams(getMatch[1]))
|
|
||||||
if len(response) > 0 {
|
|
||||||
return good(response)
|
|
||||||
}
|
|
||||||
return answer(httpUnavailable+jsonContentType, `{"error":"timeout"}`)
|
|
||||||
}
|
|
||||||
|
|
||||||
body := bodyBuilder.String()
|
|
||||||
if len(body) < contentLength {
|
if len(body) < contentLength {
|
||||||
return bad("incomplete request")
|
return bad("incomplete request")
|
||||||
}
|
}
|
||||||
body = body[:contentLength]
|
body = body[:contentLength]
|
||||||
|
|
||||||
actions, err := parseSingleActionList(strings.Trim(string(body), "\r\n"), false)
|
actions, err := parseSingleActionList(strings.Trim(string(body), "\r\n"))
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return bad(err.Error())
|
return bad(err.Error())
|
||||||
}
|
}
|
||||||
|
|||||||
+911
-4224
File diff suppressed because it is too large
Load Diff
+36
-147
@@ -12,7 +12,7 @@ import (
|
|||||||
"github.com/junegunn/fzf/src/util"
|
"github.com/junegunn/fzf/src/util"
|
||||||
)
|
)
|
||||||
|
|
||||||
func replacePlaceholderTest(template string, stripAnsi bool, delimiter Delimiter, printsep string, forcePlus bool, query string, allItems [3][]*Item) string {
|
func replacePlaceholderTest(template string, stripAnsi bool, delimiter Delimiter, printsep string, forcePlus bool, query string, allItems []*Item) string {
|
||||||
replaced, _ := replacePlaceholder(replacePlaceholderParams{
|
replaced, _ := replacePlaceholder(replacePlaceholderParams{
|
||||||
template: template,
|
template: template,
|
||||||
stripAnsi: stripAnsi,
|
stripAnsi: stripAnsi,
|
||||||
@@ -30,11 +30,11 @@ func replacePlaceholderTest(template string, stripAnsi bool, delimiter Delimiter
|
|||||||
|
|
||||||
func TestReplacePlaceholder(t *testing.T) {
|
func TestReplacePlaceholder(t *testing.T) {
|
||||||
item1 := newItem(" foo'bar \x1b[31mbaz\x1b[m")
|
item1 := newItem(" foo'bar \x1b[31mbaz\x1b[m")
|
||||||
items1 := [3][]*Item{{item1}, {item1}, nil}
|
items1 := []*Item{item1, item1}
|
||||||
items2 := [3][]*Item{
|
items2 := []*Item{
|
||||||
{newItem("foo'bar \x1b[31mbaz\x1b[m")},
|
newItem("foo'bar \x1b[31mbaz\x1b[m"),
|
||||||
{newItem("foo'bar \x1b[31mbaz\x1b[m"),
|
newItem("foo'bar \x1b[31mbaz\x1b[m"),
|
||||||
newItem("FOO'BAR \x1b[31mBAZ\x1b[m")}, nil}
|
newItem("FOO'BAR \x1b[31mBAZ\x1b[m")}
|
||||||
|
|
||||||
delim := "'"
|
delim := "'"
|
||||||
var regex *regexp.Regexp
|
var regex *regexp.Regexp
|
||||||
@@ -75,14 +75,6 @@ func TestReplacePlaceholder(t *testing.T) {
|
|||||||
result = replacePlaceholderTest("echo {}", true, Delimiter{}, printsep, false, "query", items1)
|
result = replacePlaceholderTest("echo {}", true, Delimiter{}, printsep, false, "query", items1)
|
||||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}")
|
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}")
|
||||||
|
|
||||||
// {r}, strip ansi
|
|
||||||
result = replacePlaceholderTest("echo {r}", true, Delimiter{}, printsep, false, "query", items1)
|
|
||||||
checkFormat("echo foo'bar baz")
|
|
||||||
|
|
||||||
// {r..}, strip ansi
|
|
||||||
result = replacePlaceholderTest("echo {r..}", true, Delimiter{}, printsep, false, "query", items1)
|
|
||||||
checkFormat("echo foo'bar baz")
|
|
||||||
|
|
||||||
// {}, with multiple items
|
// {}, with multiple items
|
||||||
result = replacePlaceholderTest("echo {}", true, Delimiter{}, printsep, false, "query", items2)
|
result = replacePlaceholderTest("echo {}", true, Delimiter{}, printsep, false, "query", items2)
|
||||||
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}}")
|
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}}")
|
||||||
@@ -145,11 +137,11 @@ func TestReplacePlaceholder(t *testing.T) {
|
|||||||
checkFormat("echo {{.O}} {{.O}}")
|
checkFormat("echo {{.O}} {{.O}}")
|
||||||
|
|
||||||
// No match
|
// No match
|
||||||
result = replacePlaceholderTest("echo {}/{+}", true, Delimiter{}, printsep, false, "query", [3][]*Item{nil, nil, nil})
|
result = replacePlaceholderTest("echo {}/{+}", true, Delimiter{}, printsep, false, "query", []*Item{nil, nil})
|
||||||
check("echo /")
|
check("echo /")
|
||||||
|
|
||||||
// No match, but with selections
|
// No match, but with selections
|
||||||
result = replacePlaceholderTest("echo {}/{+}", true, Delimiter{}, printsep, false, "query", [3][]*Item{nil, {item1}, nil})
|
result = replacePlaceholderTest("echo {}/{+}", true, Delimiter{}, printsep, false, "query", []*Item{nil, item1})
|
||||||
checkFormat("echo /{{.O}} foo{{.I}}bar baz{{.O}}")
|
checkFormat("echo /{{.O}} foo{{.I}}bar baz{{.O}}")
|
||||||
|
|
||||||
// String delimiter
|
// String delimiter
|
||||||
@@ -166,18 +158,17 @@ func TestReplacePlaceholder(t *testing.T) {
|
|||||||
Test single placeholders, but focus on the placeholders' parameters (e.g. flags).
|
Test single placeholders, but focus on the placeholders' parameters (e.g. flags).
|
||||||
see: TestParsePlaceholder
|
see: TestParsePlaceholder
|
||||||
*/
|
*/
|
||||||
items3 := [3][]*Item{
|
items3 := []*Item{
|
||||||
// single line
|
// single line
|
||||||
{newItem("1a 1b 1c 1d 1e 1f")},
|
newItem("1a 1b 1c 1d 1e 1f"),
|
||||||
// multi line
|
// multi line
|
||||||
{newItem("1a 1b 1c 1d 1e 1f"),
|
newItem("1a 1b 1c 1d 1e 1f"),
|
||||||
newItem("2a 2b 2c 2d 2e 2f"),
|
newItem("2a 2b 2c 2d 2e 2f"),
|
||||||
newItem("3a 3b 3c 3d 3e 3f"),
|
newItem("3a 3b 3c 3d 3e 3f"),
|
||||||
newItem("4a 4b 4c 4d 4e 4f"),
|
newItem("4a 4b 4c 4d 4e 4f"),
|
||||||
newItem("5a 5b 5c 5d 5e 5f"),
|
newItem("5a 5b 5c 5d 5e 5f"),
|
||||||
newItem("6a 6b 6c 6d 6e 6f"),
|
newItem("6a 6b 6c 6d 6e 6f"),
|
||||||
newItem("7a 7b 7c 7d 7e 7f")},
|
newItem("7a 7b 7c 7d 7e 7f"),
|
||||||
nil,
|
|
||||||
}
|
}
|
||||||
stripAnsi := false
|
stripAnsi := false
|
||||||
forcePlus := false
|
forcePlus := false
|
||||||
@@ -493,12 +484,7 @@ func TestParsePlaceholder(t *testing.T) {
|
|||||||
// III. query type placeholder
|
// III. query type placeholder
|
||||||
// query flag is not removed after parsing, so it gets doubled
|
// query flag is not removed after parsing, so it gets doubled
|
||||||
// while the double q is invalid, it is useful here for testing purposes
|
// while the double q is invalid, it is useful here for testing purposes
|
||||||
`{q}`: `{qq}`,
|
`{q}`: `{qq}`,
|
||||||
`{q:1}`: `{qq:1}`,
|
|
||||||
`{q:2..}`: `{qq:2..}`,
|
|
||||||
`{q:..}`: `{qq:..}`,
|
|
||||||
`{q:2..-1}`: `{qq:2..-1}`,
|
|
||||||
`{q:s2..-1}`: `{sqq:2..-1}`, // FIXME
|
|
||||||
|
|
||||||
// IV. escaping placeholder
|
// IV. escaping placeholder
|
||||||
`\{}`: `{}`,
|
`\{}`: `{}`,
|
||||||
@@ -521,34 +507,6 @@ func TestParsePlaceholder(t *testing.T) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestExtractPassthroughs(t *testing.T) {
|
|
||||||
for _, middle := range []string{
|
|
||||||
"\x1bPtmux;\x1b\x1bbar\x1b\\",
|
|
||||||
"\x1bPtmux;\x1b\x1bbar\x1bbar\x1b\\",
|
|
||||||
"\x1b]1337;bar\x1b\\",
|
|
||||||
"\x1b]1337;bar\x1bbar\x1b\\",
|
|
||||||
"\x1b]1337;bar\a",
|
|
||||||
"\x1b_Ga=T,f=32,s=1258,v=1295,c=74,r=35,m=1\x1b\\",
|
|
||||||
"\x1b_Ga=T,f=32,s=1258,v=1295,c=74,r=35,m=1\x1b\\\r",
|
|
||||||
"\x1b_Ga=T,f=32,s=1258,v=1295,c=74,r=35,m=1\x1bbar\x1b\\\r",
|
|
||||||
"\x1b_Gm=1;AAAAAAAAA=\x1b\\",
|
|
||||||
"\x1b_Gm=1;AAAAAAAAA=\x1b\\\r",
|
|
||||||
"\x1b_Gm=1;\x1bAAAAAAAAA=\x1b\\\r",
|
|
||||||
} {
|
|
||||||
line := "foo" + middle + "baz"
|
|
||||||
loc := findPassThrough(line)
|
|
||||||
if loc == nil || line[0:loc[0]] != "foo" || line[loc[1]:] != "baz" {
|
|
||||||
t.Error("failed to find passthrough")
|
|
||||||
}
|
|
||||||
garbage := "\x1bPtmux;\x1b]1337;\x1b_Ga=\x1b]1337;bar\x1b."
|
|
||||||
line = strings.Repeat("foo"+middle+middle+"baz", 3) + garbage
|
|
||||||
passthroughs, result := extractPassThroughs(line)
|
|
||||||
if result != "foobazfoobazfoobaz"+garbage || len(passthroughs) != 6 {
|
|
||||||
t.Error("failed to extract passthroughs")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
/* utilities section */
|
/* utilities section */
|
||||||
|
|
||||||
// Item represents one line in fzf UI. Usually it is relative path to files and folders.
|
// Item represents one line in fzf UI. Usually it is relative path to files and folders.
|
||||||
@@ -558,14 +516,14 @@ func newItem(str string) *Item {
|
|||||||
return &Item{origText: &bytes, text: util.ToChars([]byte(trimmed))}
|
return &Item{origText: &bytes, text: util.ToChars([]byte(trimmed))}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Functions tested in this file require array of items (allItems).
|
// Functions tested in this file require array of items (allItems). The array needs
|
||||||
// This is helper function.
|
// to consist of at least two nils. This is helper function.
|
||||||
func newItems(str ...string) [3][]*Item {
|
func newItems(str ...string) []*Item {
|
||||||
result := make([]*Item, len(str))
|
result := make([]*Item, util.Max(len(str), 2))
|
||||||
for i, s := range str {
|
for i, s := range str {
|
||||||
result[i] = newItem(s)
|
result[i] = newItem(s)
|
||||||
}
|
}
|
||||||
return [3][]*Item{result, nil, nil}
|
return result
|
||||||
}
|
}
|
||||||
|
|
||||||
// (for logging purposes)
|
// (for logging purposes)
|
||||||
@@ -574,7 +532,7 @@ func (item *Item) String() string {
|
|||||||
}
|
}
|
||||||
|
|
||||||
// Helper function to parse, execute and convert "text/template" to string. Panics on error.
|
// Helper function to parse, execute and convert "text/template" to string. Panics on error.
|
||||||
func templateToString(format string, data any) string {
|
func templateToString(format string, data interface{}) string {
|
||||||
bb := &bytes.Buffer{}
|
bb := &bytes.Buffer{}
|
||||||
|
|
||||||
err := template.Must(template.New("").Parse(format)).Execute(bb, data)
|
err := template.Must(template.New("").Parse(format)).Execute(bb, data)
|
||||||
@@ -589,7 +547,7 @@ func templateToString(format string, data any) string {
|
|||||||
type give struct {
|
type give struct {
|
||||||
template string
|
template string
|
||||||
query string
|
query string
|
||||||
allItems [3][]*Item
|
allItems []*Item
|
||||||
}
|
}
|
||||||
type want struct {
|
type want struct {
|
||||||
/*
|
/*
|
||||||
@@ -627,25 +585,25 @@ func testCommands(t *testing.T, tests []testCase) {
|
|||||||
// evaluate the test cases
|
// evaluate the test cases
|
||||||
for idx, test := range tests {
|
for idx, test := range tests {
|
||||||
gotOutput := replacePlaceholderTest(
|
gotOutput := replacePlaceholderTest(
|
||||||
test.template, stripAnsi, delimiter, printsep, forcePlus,
|
test.give.template, stripAnsi, delimiter, printsep, forcePlus,
|
||||||
test.query,
|
test.give.query,
|
||||||
test.allItems)
|
test.give.allItems)
|
||||||
switch {
|
switch {
|
||||||
case test.output != "":
|
case test.want.output != "":
|
||||||
if gotOutput != test.output {
|
if gotOutput != test.want.output {
|
||||||
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
||||||
idx,
|
idx,
|
||||||
test.template, test.query, test.allItems,
|
test.give.template, test.give.query, test.give.allItems,
|
||||||
gotOutput, test.output)
|
gotOutput, test.want.output)
|
||||||
}
|
}
|
||||||
case test.match != "":
|
case test.want.match != "":
|
||||||
wantMatch := strings.ReplaceAll(test.match, `\`, `\\`)
|
wantMatch := strings.ReplaceAll(test.want.match, `\`, `\\`)
|
||||||
wantRegex := regexp.MustCompile(wantMatch)
|
wantRegex := regexp.MustCompile(wantMatch)
|
||||||
if !wantRegex.MatchString(gotOutput) {
|
if !wantRegex.MatchString(gotOutput) {
|
||||||
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
||||||
idx,
|
idx,
|
||||||
test.template, test.query, test.allItems,
|
test.give.template, test.give.query, test.give.allItems,
|
||||||
gotOutput, test.match)
|
gotOutput, test.want.match)
|
||||||
}
|
}
|
||||||
default:
|
default:
|
||||||
t.Errorf("tests[%v]: test case does not describe 'want' property", idx)
|
t.Errorf("tests[%v]: test case does not describe 'want' property", idx)
|
||||||
@@ -699,72 +657,3 @@ func readFile(path string) ([]byte, error) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestWordWrapAnsiLine(t *testing.T) {
|
|
||||||
term := &Terminal{}
|
|
||||||
|
|
||||||
// Simple wrapping
|
|
||||||
result := term.wordWrapAnsiLine("hello world", 7, 2)
|
|
||||||
if len(result) != 2 || result[0] != "hello" || result[1] != "world" {
|
|
||||||
t.Errorf("Simple: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// No wrapping needed
|
|
||||||
result = term.wordWrapAnsiLine("hello", 10, 2)
|
|
||||||
if len(result) != 1 || result[0] != "hello" {
|
|
||||||
t.Errorf("No wrap: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// ANSI codes preserved across split
|
|
||||||
result = term.wordWrapAnsiLine("\x1b[31mhello \x1b[32mworld", 8, 2)
|
|
||||||
if len(result) != 2 || result[0] != "\x1b[31mhello" || result[1] != "\x1b[32mworld" {
|
|
||||||
t.Errorf("ANSI: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Long word (no space) - no break, let character wrapping handle it
|
|
||||||
result = term.wordWrapAnsiLine("abcdefghij", 5, 2)
|
|
||||||
if len(result) != 1 || result[0] != "abcdefghij" {
|
|
||||||
t.Errorf("Long word: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Multiple words with continuation wrapSignWidth
|
|
||||||
result = term.wordWrapAnsiLine("aa bb cc dd", 5, 2)
|
|
||||||
// max=5 for first line, max=3 for continuations (5-2)
|
|
||||||
// "aa bb" (5 wide), split at second space -> "aa bb" | "cc" | "dd"
|
|
||||||
if len(result) != 3 || result[0] != "aa bb" || result[1] != "cc" || result[2] != "dd" {
|
|
||||||
t.Errorf("Multiple words: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Empty string
|
|
||||||
result = term.wordWrapAnsiLine("", 10, 2)
|
|
||||||
if len(result) != 1 || result[0] != "" {
|
|
||||||
t.Errorf("Empty: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// OSC 8 hyperlink preserved
|
|
||||||
result = term.wordWrapAnsiLine("\x1b]8;;http://example.com\x1b\\click here\x1b]8;;\x1b\\", 8, 2)
|
|
||||||
if len(result) != 2 {
|
|
||||||
t.Errorf("Hyperlink split count: %d, %q", len(result), result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Tab handling: tab expands to tabstop-aligned width
|
|
||||||
term.tabstop = 8
|
|
||||||
// "\thi there" - tab at column 0 expands to 8, total "hi" starts at 8
|
|
||||||
// maxWidth=15: "\thi" = 10 wide, "there" = 5 wide, total 16 > 15, wrap at space
|
|
||||||
result = term.wordWrapAnsiLine("\thi there", 15, 2)
|
|
||||||
if len(result) != 2 || result[0] != "\thi" || result[1] != "there" {
|
|
||||||
t.Errorf("Tab: %q", result)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Tab as word boundary: "hello"(5) + tab(3→col8) + "world"(5) = 13 total
|
|
||||||
// maxWidth=13: fits without wrapping
|
|
||||||
result = term.wordWrapAnsiLine("hello\tworld", 13, 2)
|
|
||||||
if len(result) != 1 || result[0] != "hello\tworld" {
|
|
||||||
t.Errorf("Tab no wrap: %q", result)
|
|
||||||
}
|
|
||||||
// maxWidth=12: 13 > 12, wraps at tab
|
|
||||||
result = term.wordWrapAnsiLine("hello\tworld", 12, 2)
|
|
||||||
if len(result) != 2 || result[0] != "hello" || result[1] != "world" {
|
|
||||||
t.Errorf("Tab wrap: %q", result)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|||||||
+21
-5
@@ -1,11 +1,30 @@
|
|||||||
package fzf
|
package fzf
|
||||||
|
|
||||||
import (
|
import (
|
||||||
|
"os"
|
||||||
"os/exec"
|
"os/exec"
|
||||||
|
|
||||||
|
"github.com/junegunn/fzf/src/tui"
|
||||||
)
|
)
|
||||||
|
|
||||||
func runTmux(args []string, opts *Options) (int, error) {
|
func runTmux(args []string, opts *Options) (int, error) {
|
||||||
argStr, dir := popupArgStr(args, opts)
|
// Prepare arguments
|
||||||
|
fzf := args[0]
|
||||||
|
args = append([]string{"--bind=ctrl-z:ignore"}, args[1:]...)
|
||||||
|
if opts.BorderShape == tui.BorderUndefined {
|
||||||
|
args = append(args, "--border")
|
||||||
|
}
|
||||||
|
argStr := escapeSingleQuote(fzf)
|
||||||
|
for _, arg := range args {
|
||||||
|
argStr += " " + escapeSingleQuote(arg)
|
||||||
|
}
|
||||||
|
argStr += ` --no-tmux --no-height`
|
||||||
|
|
||||||
|
// Get current directory
|
||||||
|
dir, err := os.Getwd()
|
||||||
|
if err != nil {
|
||||||
|
dir = "."
|
||||||
|
}
|
||||||
|
|
||||||
// Set tmux options for popup placement
|
// Set tmux options for popup placement
|
||||||
// C Both The centre of the terminal
|
// C Both The centre of the terminal
|
||||||
@@ -14,10 +33,7 @@ func runTmux(args []string, opts *Options) (int, error) {
|
|||||||
// M Both The mouse position
|
// M Both The mouse position
|
||||||
// W Both The window position on the status line
|
// W Both The window position on the status line
|
||||||
// S -y The line above or below the status line
|
// S -y The line above or below the status line
|
||||||
tmuxArgs := []string{"display-popup", "-E", "-d", dir}
|
tmuxArgs := []string{"display-popup", "-E", "-B", "-d", dir}
|
||||||
if !opts.Tmux.border {
|
|
||||||
tmuxArgs = append(tmuxArgs, "-B")
|
|
||||||
}
|
|
||||||
switch opts.Tmux.position {
|
switch opts.Tmux.position {
|
||||||
case posUp:
|
case posUp:
|
||||||
tmuxArgs = append(tmuxArgs, "-xC", "-y0")
|
tmuxArgs = append(tmuxArgs, "-xC", "-y0")
|
||||||
|
|||||||
+8
-93
@@ -6,7 +6,6 @@ import (
|
|||||||
"regexp"
|
"regexp"
|
||||||
"strconv"
|
"strconv"
|
||||||
"strings"
|
"strings"
|
||||||
"unicode"
|
|
||||||
|
|
||||||
"github.com/junegunn/fzf/src/util"
|
"github.com/junegunn/fzf/src/util"
|
||||||
)
|
)
|
||||||
@@ -19,48 +18,6 @@ type Range struct {
|
|||||||
end int
|
end int
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r Range) IsFull() bool {
|
|
||||||
return r.begin == rangeEllipsis && r.end == rangeEllipsis
|
|
||||||
}
|
|
||||||
|
|
||||||
func compareRanges(r1 []Range, r2 []Range) bool {
|
|
||||||
if len(r1) != len(r2) {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
for idx := range r1 {
|
|
||||||
if r1[idx] != r2[idx] {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return true
|
|
||||||
}
|
|
||||||
|
|
||||||
func RangesToString(ranges []Range) string {
|
|
||||||
strs := []string{}
|
|
||||||
for _, r := range ranges {
|
|
||||||
s := ""
|
|
||||||
if r.begin == rangeEllipsis && r.end == rangeEllipsis {
|
|
||||||
s = ".."
|
|
||||||
} else if r.begin == r.end {
|
|
||||||
s = strconv.Itoa(r.begin)
|
|
||||||
} else {
|
|
||||||
if r.begin != rangeEllipsis {
|
|
||||||
s += strconv.Itoa(r.begin)
|
|
||||||
}
|
|
||||||
|
|
||||||
if r.begin != -1 {
|
|
||||||
s += ".."
|
|
||||||
if r.end != rangeEllipsis {
|
|
||||||
s += strconv.Itoa(r.end)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
strs = append(strs, s)
|
|
||||||
}
|
|
||||||
|
|
||||||
return strings.Join(strs, ",")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Token contains the tokenized part of the strings and its prefix length
|
// Token contains the tokenized part of the strings and its prefix length
|
||||||
type Token struct {
|
type Token struct {
|
||||||
text *util.Chars
|
text *util.Chars
|
||||||
@@ -78,18 +35,13 @@ type Delimiter struct {
|
|||||||
str *string
|
str *string
|
||||||
}
|
}
|
||||||
|
|
||||||
// IsAwk returns true if the delimiter is an AWK-style delimiter
|
|
||||||
func (d Delimiter) IsAwk() bool {
|
|
||||||
return d.regex == nil && d.str == nil
|
|
||||||
}
|
|
||||||
|
|
||||||
// String returns the string representation of a Delimiter.
|
// String returns the string representation of a Delimiter.
|
||||||
func (d Delimiter) String() string {
|
func (d Delimiter) String() string {
|
||||||
return fmt.Sprintf("Delimiter{regex: %v, str: &%q}", d.regex, *d.str)
|
return fmt.Sprintf("Delimiter{regex: %v, str: &%q}", d.regex, *d.str)
|
||||||
}
|
}
|
||||||
|
|
||||||
func newRange(begin int, end int) Range {
|
func newRange(begin int, end int) Range {
|
||||||
if begin == 1 && end != 1 {
|
if begin == 1 {
|
||||||
begin = rangeEllipsis
|
begin = rangeEllipsis
|
||||||
}
|
}
|
||||||
if end == -1 {
|
if end == -1 {
|
||||||
@@ -121,7 +73,7 @@ func ParseRange(str *string) (Range, bool) {
|
|||||||
}
|
}
|
||||||
begin, err1 := strconv.Atoi(ns[0])
|
begin, err1 := strconv.Atoi(ns[0])
|
||||||
end, err2 := strconv.Atoi(ns[1])
|
end, err2 := strconv.Atoi(ns[1])
|
||||||
if err1 != nil || err2 != nil || begin == 0 || end == 0 || begin < 0 && end > 0 {
|
if err1 != nil || err2 != nil || begin == 0 || end == 0 {
|
||||||
return Range{}, false
|
return Range{}, false
|
||||||
}
|
}
|
||||||
return newRange(begin, end), true
|
return newRange(begin, end), true
|
||||||
@@ -161,7 +113,7 @@ func awkTokenizer(input string) ([]string, int) {
|
|||||||
end := 0
|
end := 0
|
||||||
for idx := 0; idx < len(input); idx++ {
|
for idx := 0; idx < len(input); idx++ {
|
||||||
r := input[idx]
|
r := input[idx]
|
||||||
white := r == 9 || r == 32 || r == 10
|
white := r == 9 || r == 32
|
||||||
switch state {
|
switch state {
|
||||||
case awkNil:
|
case awkNil:
|
||||||
if white {
|
if white {
|
||||||
@@ -206,9 +158,8 @@ func Tokenize(text string, delimiter Delimiter) []Token {
|
|||||||
if delimiter.regex != nil {
|
if delimiter.regex != nil {
|
||||||
locs := delimiter.regex.FindAllStringIndex(text, -1)
|
locs := delimiter.regex.FindAllStringIndex(text, -1)
|
||||||
begin := 0
|
begin := 0
|
||||||
tokens = make([]string, len(locs))
|
for _, loc := range locs {
|
||||||
for i, loc := range locs {
|
tokens = append(tokens, text[begin:loc[1]])
|
||||||
tokens[i] = text[begin:loc[1]]
|
|
||||||
begin = loc[1]
|
begin = loc[1]
|
||||||
}
|
}
|
||||||
if begin < len(text) {
|
if begin < len(text) {
|
||||||
@@ -218,43 +169,7 @@ func Tokenize(text string, delimiter Delimiter) []Token {
|
|||||||
return withPrefixLengths(tokens, 0)
|
return withPrefixLengths(tokens, 0)
|
||||||
}
|
}
|
||||||
|
|
||||||
// StripLastDelimiter removes the trailing delimiter
|
func joinTokens(tokens []Token) string {
|
||||||
func StripLastDelimiter(str string, delimiter Delimiter) string {
|
|
||||||
if delimiter.str != nil {
|
|
||||||
return strings.TrimSuffix(str, *delimiter.str)
|
|
||||||
}
|
|
||||||
if delimiter.regex != nil {
|
|
||||||
locs := delimiter.regex.FindAllStringIndex(str, -1)
|
|
||||||
if len(locs) > 0 {
|
|
||||||
lastLoc := locs[len(locs)-1]
|
|
||||||
if lastLoc[1] == len(str) {
|
|
||||||
str = str[:lastLoc[0]]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return str
|
|
||||||
}
|
|
||||||
return strings.TrimRightFunc(str, unicode.IsSpace)
|
|
||||||
}
|
|
||||||
|
|
||||||
func GetLastDelimiter(str string, delimiter Delimiter) string {
|
|
||||||
if delimiter.str != nil {
|
|
||||||
if strings.HasSuffix(str, *delimiter.str) {
|
|
||||||
return *delimiter.str
|
|
||||||
}
|
|
||||||
} else if delimiter.regex != nil {
|
|
||||||
locs := delimiter.regex.FindAllStringIndex(str, -1)
|
|
||||||
if len(locs) > 0 {
|
|
||||||
lastLoc := locs[len(locs)-1]
|
|
||||||
if lastLoc[1] == len(str) {
|
|
||||||
return str[lastLoc[0]:]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return ""
|
|
||||||
}
|
|
||||||
|
|
||||||
// JoinTokens concatenates the tokens into a single string
|
|
||||||
func JoinTokens(tokens []Token) string {
|
|
||||||
var output bytes.Buffer
|
var output bytes.Buffer
|
||||||
for _, token := range tokens {
|
for _, token := range tokens {
|
||||||
output.WriteString(token.text.ToString())
|
output.WriteString(token.text.ToString())
|
||||||
@@ -272,7 +187,7 @@ func Transform(tokens []Token, withNth []Range) []Token {
|
|||||||
if r.begin == r.end {
|
if r.begin == r.end {
|
||||||
idx := r.begin
|
idx := r.begin
|
||||||
if idx == rangeEllipsis {
|
if idx == rangeEllipsis {
|
||||||
chars := util.ToChars(stringBytes(JoinTokens(tokens)))
|
chars := util.ToChars(stringBytes(joinTokens(tokens)))
|
||||||
parts = append(parts, &chars)
|
parts = append(parts, &chars)
|
||||||
} else {
|
} else {
|
||||||
if idx < 0 {
|
if idx < 0 {
|
||||||
@@ -304,7 +219,7 @@ func Transform(tokens []Token, withNth []Range) []Token {
|
|||||||
end += numTokens + 1
|
end += numTokens + 1
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
minIdx = max(0, begin-1)
|
minIdx = util.Max(0, begin-1)
|
||||||
for idx := begin; idx <= end; idx++ {
|
for idx := begin; idx <= end; idx++ {
|
||||||
if idx >= 1 && idx <= numTokens {
|
if idx >= 1 && idx <= numTokens {
|
||||||
parts = append(parts, tokens[idx-1].text)
|
parts = append(parts, tokens[idx-1].text)
|
||||||
|
|||||||
+8
-20
@@ -40,25 +40,13 @@ func TestParseRange(t *testing.T) {
|
|||||||
t.Errorf("%v", r)
|
t.Errorf("%v", r)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
{
|
|
||||||
i := "1..3..5"
|
|
||||||
if r, ok := ParseRange(&i); ok {
|
|
||||||
t.Errorf("%v", r)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
{
|
|
||||||
i := "-3..3"
|
|
||||||
if r, ok := ParseRange(&i); ok {
|
|
||||||
t.Errorf("%v", r)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func TestTokenize(t *testing.T) {
|
func TestTokenize(t *testing.T) {
|
||||||
// AWK-style
|
// AWK-style
|
||||||
input := " abc: \n\t def: ghi "
|
input := " abc: def: ghi "
|
||||||
tokens := Tokenize(input, Delimiter{})
|
tokens := Tokenize(input, Delimiter{})
|
||||||
if tokens[0].text.ToString() != "abc: \n\t " || tokens[0].prefixLength != 2 {
|
if tokens[0].text.ToString() != "abc: " || tokens[0].prefixLength != 2 {
|
||||||
t.Errorf("%s", tokens)
|
t.Errorf("%s", tokens)
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -71,9 +59,9 @@ func TestTokenize(t *testing.T) {
|
|||||||
// With delimiter regex
|
// With delimiter regex
|
||||||
tokens = Tokenize(input, delimiterRegexp("\\s+"))
|
tokens = Tokenize(input, delimiterRegexp("\\s+"))
|
||||||
if tokens[0].text.ToString() != " " || tokens[0].prefixLength != 0 ||
|
if tokens[0].text.ToString() != " " || tokens[0].prefixLength != 0 ||
|
||||||
tokens[1].text.ToString() != "abc: \n\t " || tokens[1].prefixLength != 2 ||
|
tokens[1].text.ToString() != "abc: " || tokens[1].prefixLength != 2 ||
|
||||||
tokens[2].text.ToString() != "def: " || tokens[2].prefixLength != 10 ||
|
tokens[2].text.ToString() != "def: " || tokens[2].prefixLength != 8 ||
|
||||||
tokens[3].text.ToString() != "ghi " || tokens[3].prefixLength != 16 {
|
tokens[3].text.ToString() != "ghi " || tokens[3].prefixLength != 14 {
|
||||||
t.Errorf("%s", tokens)
|
t.Errorf("%s", tokens)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -85,14 +73,14 @@ func TestTransform(t *testing.T) {
|
|||||||
{
|
{
|
||||||
ranges, _ := splitNth("1,2,3")
|
ranges, _ := splitNth("1,2,3")
|
||||||
tx := Transform(tokens, ranges)
|
tx := Transform(tokens, ranges)
|
||||||
if JoinTokens(tx) != "abc: def: ghi: " {
|
if joinTokens(tx) != "abc: def: ghi: " {
|
||||||
t.Errorf("%s", tx)
|
t.Errorf("%s", tx)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
{
|
{
|
||||||
ranges, _ := splitNth("1..2,3,2..,1")
|
ranges, _ := splitNth("1..2,3,2..,1")
|
||||||
tx := Transform(tokens, ranges)
|
tx := Transform(tokens, ranges)
|
||||||
if string(JoinTokens(tx)) != "abc: def: ghi: def: ghi: jklabc: " ||
|
if string(joinTokens(tx)) != "abc: def: ghi: def: ghi: jklabc: " ||
|
||||||
len(tx) != 4 ||
|
len(tx) != 4 ||
|
||||||
tx[0].text.ToString() != "abc: def: " || tx[0].prefixLength != 2 ||
|
tx[0].text.ToString() != "abc: def: " || tx[0].prefixLength != 2 ||
|
||||||
tx[1].text.ToString() != "ghi: " || tx[1].prefixLength != 14 ||
|
tx[1].text.ToString() != "ghi: " || tx[1].prefixLength != 14 ||
|
||||||
@@ -107,7 +95,7 @@ func TestTransform(t *testing.T) {
|
|||||||
{
|
{
|
||||||
ranges, _ := splitNth("1..2,3,2..,1")
|
ranges, _ := splitNth("1..2,3,2..,1")
|
||||||
tx := Transform(tokens, ranges)
|
tx := Transform(tokens, ranges)
|
||||||
if JoinTokens(tx) != " abc: def: ghi: def: ghi: jkl abc:" ||
|
if joinTokens(tx) != " abc: def: ghi: def: ghi: jkl abc:" ||
|
||||||
len(tx) != 4 ||
|
len(tx) != 4 ||
|
||||||
tx[0].text.ToString() != " abc: def:" || tx[0].prefixLength != 0 ||
|
tx[0].text.ToString() != " abc: def:" || tx[0].prefixLength != 0 ||
|
||||||
tx[1].text.ToString() != " ghi:" || tx[1].prefixLength != 12 ||
|
tx[1].text.ToString() != " ghi:" || tx[1].prefixLength != 12 ||
|
||||||
|
|||||||
+22
-16
@@ -2,7 +2,23 @@
|
|||||||
|
|
||||||
package tui
|
package tui
|
||||||
|
|
||||||
|
type Attr int32
|
||||||
|
|
||||||
|
func HasFullscreenRenderer() bool {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
|
||||||
|
var DefaultBorderShape = BorderRounded
|
||||||
|
|
||||||
|
func (a Attr) Merge(b Attr) Attr {
|
||||||
|
return a | b
|
||||||
|
}
|
||||||
|
|
||||||
const (
|
const (
|
||||||
|
AttrUndefined = Attr(0)
|
||||||
|
AttrRegular = Attr(1 << 8)
|
||||||
|
AttrClear = Attr(1 << 9)
|
||||||
|
|
||||||
Bold = Attr(1)
|
Bold = Attr(1)
|
||||||
Dim = Attr(1 << 1)
|
Dim = Attr(1 << 1)
|
||||||
Italic = Attr(1 << 2)
|
Italic = Attr(1 << 2)
|
||||||
@@ -13,14 +29,7 @@ const (
|
|||||||
StrikeThrough = Attr(1 << 7)
|
StrikeThrough = Attr(1 << 7)
|
||||||
)
|
)
|
||||||
|
|
||||||
func HasFullscreenRenderer() bool {
|
|
||||||
return false
|
|
||||||
}
|
|
||||||
|
|
||||||
var DefaultBorderShape = BorderRounded
|
|
||||||
|
|
||||||
func (r *FullscreenRenderer) Init() error { return nil }
|
func (r *FullscreenRenderer) Init() error { return nil }
|
||||||
func (r *FullscreenRenderer) DefaultTheme() *ColorTheme { return nil }
|
|
||||||
func (r *FullscreenRenderer) Resize(maxHeightFunc func(int) int) {}
|
func (r *FullscreenRenderer) Resize(maxHeightFunc func(int) int) {}
|
||||||
func (r *FullscreenRenderer) Pause(bool) {}
|
func (r *FullscreenRenderer) Pause(bool) {}
|
||||||
func (r *FullscreenRenderer) Resume(bool, bool) {}
|
func (r *FullscreenRenderer) Resume(bool, bool) {}
|
||||||
@@ -28,20 +37,17 @@ func (r *FullscreenRenderer) PassThrough(string) {}
|
|||||||
func (r *FullscreenRenderer) Clear() {}
|
func (r *FullscreenRenderer) Clear() {}
|
||||||
func (r *FullscreenRenderer) NeedScrollbarRedraw() bool { return false }
|
func (r *FullscreenRenderer) NeedScrollbarRedraw() bool { return false }
|
||||||
func (r *FullscreenRenderer) ShouldEmitResizeEvent() bool { return false }
|
func (r *FullscreenRenderer) ShouldEmitResizeEvent() bool { return false }
|
||||||
func (r *FullscreenRenderer) Bell() {}
|
|
||||||
func (r *FullscreenRenderer) HideCursor() {}
|
|
||||||
func (r *FullscreenRenderer) ShowCursor() {}
|
|
||||||
func (r *FullscreenRenderer) Refresh() {}
|
func (r *FullscreenRenderer) Refresh() {}
|
||||||
func (r *FullscreenRenderer) Close() {}
|
func (r *FullscreenRenderer) Close() {}
|
||||||
func (r *FullscreenRenderer) Size() TermSize { return TermSize{} }
|
func (r *FullscreenRenderer) Size() TermSize { return TermSize{} }
|
||||||
func (r *FullscreenRenderer) Top() int { return 0 }
|
|
||||||
func (r *FullscreenRenderer) MaxX() int { return 0 }
|
func (r *FullscreenRenderer) GetChar() Event { return Event{} }
|
||||||
func (r *FullscreenRenderer) MaxY() int { return 0 }
|
func (r *FullscreenRenderer) Top() int { return 0 }
|
||||||
func (r *FullscreenRenderer) GetChar(bool) Event { return Event{} }
|
func (r *FullscreenRenderer) MaxX() int { return 0 }
|
||||||
func (r *FullscreenRenderer) CancelGetChar() {}
|
func (r *FullscreenRenderer) MaxY() int { return 0 }
|
||||||
|
|
||||||
func (r *FullscreenRenderer) RefreshWindows(windows []Window) {}
|
func (r *FullscreenRenderer) RefreshWindows(windows []Window) {}
|
||||||
|
|
||||||
func (r *FullscreenRenderer) NewWindow(top int, left int, width int, height int, windowType WindowType, borderStyle BorderStyle, erase bool) Window {
|
func (r *FullscreenRenderer) NewWindow(top int, left int, width int, height int, preview bool, borderStyle BorderStyle) Window {
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
|
|||||||
+74
-131
@@ -21,7 +21,7 @@ func _() {
|
|||||||
_ = x[CtrlJ-10]
|
_ = x[CtrlJ-10]
|
||||||
_ = x[CtrlK-11]
|
_ = x[CtrlK-11]
|
||||||
_ = x[CtrlL-12]
|
_ = x[CtrlL-12]
|
||||||
_ = x[Enter-13]
|
_ = x[CtrlM-13]
|
||||||
_ = x[CtrlN-14]
|
_ = x[CtrlN-14]
|
||||||
_ = x[CtrlO-15]
|
_ = x[CtrlO-15]
|
||||||
_ = x[CtrlP-16]
|
_ = x[CtrlP-16]
|
||||||
@@ -37,139 +37,82 @@ func _() {
|
|||||||
_ = x[CtrlZ-26]
|
_ = x[CtrlZ-26]
|
||||||
_ = x[Esc-27]
|
_ = x[Esc-27]
|
||||||
_ = x[CtrlSpace-28]
|
_ = x[CtrlSpace-28]
|
||||||
_ = x[CtrlBackSlash-29]
|
_ = x[CtrlDelete-29]
|
||||||
_ = x[CtrlRightBracket-30]
|
_ = x[CtrlBackSlash-30]
|
||||||
_ = x[CtrlCaret-31]
|
_ = x[CtrlRightBracket-31]
|
||||||
_ = x[CtrlSlash-32]
|
_ = x[CtrlCaret-32]
|
||||||
_ = x[ShiftTab-33]
|
_ = x[CtrlSlash-33]
|
||||||
_ = x[Backspace-34]
|
_ = x[ShiftTab-34]
|
||||||
_ = x[Delete-35]
|
_ = x[Backspace-35]
|
||||||
_ = x[PageUp-36]
|
_ = x[Delete-36]
|
||||||
_ = x[PageDown-37]
|
_ = x[PageUp-37]
|
||||||
_ = x[Up-38]
|
_ = x[PageDown-38]
|
||||||
_ = x[Down-39]
|
_ = x[Up-39]
|
||||||
_ = x[Left-40]
|
_ = x[Down-40]
|
||||||
_ = x[Right-41]
|
_ = x[Left-41]
|
||||||
_ = x[Home-42]
|
_ = x[Right-42]
|
||||||
_ = x[End-43]
|
_ = x[Home-43]
|
||||||
_ = x[Insert-44]
|
_ = x[End-44]
|
||||||
_ = x[ShiftUp-45]
|
_ = x[Insert-45]
|
||||||
_ = x[ShiftDown-46]
|
_ = x[ShiftUp-46]
|
||||||
_ = x[ShiftLeft-47]
|
_ = x[ShiftDown-47]
|
||||||
_ = x[ShiftRight-48]
|
_ = x[ShiftLeft-48]
|
||||||
_ = x[ShiftDelete-49]
|
_ = x[ShiftRight-49]
|
||||||
_ = x[ShiftHome-50]
|
_ = x[ShiftDelete-50]
|
||||||
_ = x[ShiftEnd-51]
|
_ = x[F1-51]
|
||||||
_ = x[ShiftPageUp-52]
|
_ = x[F2-52]
|
||||||
_ = x[ShiftPageDown-53]
|
_ = x[F3-53]
|
||||||
_ = x[F1-54]
|
_ = x[F4-54]
|
||||||
_ = x[F2-55]
|
_ = x[F5-55]
|
||||||
_ = x[F3-56]
|
_ = x[F6-56]
|
||||||
_ = x[F4-57]
|
_ = x[F7-57]
|
||||||
_ = x[F5-58]
|
_ = x[F8-58]
|
||||||
_ = x[F6-59]
|
_ = x[F9-59]
|
||||||
_ = x[F7-60]
|
_ = x[F10-60]
|
||||||
_ = x[F8-61]
|
_ = x[F11-61]
|
||||||
_ = x[F9-62]
|
_ = x[F12-62]
|
||||||
_ = x[F10-63]
|
_ = x[AltBackspace-63]
|
||||||
_ = x[F11-64]
|
_ = x[AltUp-64]
|
||||||
_ = x[F12-65]
|
_ = x[AltDown-65]
|
||||||
_ = x[AltBackspace-66]
|
_ = x[AltLeft-66]
|
||||||
_ = x[AltUp-67]
|
_ = x[AltRight-67]
|
||||||
_ = x[AltDown-68]
|
_ = x[AltShiftUp-68]
|
||||||
_ = x[AltLeft-69]
|
_ = x[AltShiftDown-69]
|
||||||
_ = x[AltRight-70]
|
_ = x[AltShiftLeft-70]
|
||||||
_ = x[AltDelete-71]
|
_ = x[AltShiftRight-71]
|
||||||
_ = x[AltHome-72]
|
_ = x[Alt-72]
|
||||||
_ = x[AltEnd-73]
|
_ = x[CtrlAlt-73]
|
||||||
_ = x[AltPageUp-74]
|
_ = x[Invalid-74]
|
||||||
_ = x[AltPageDown-75]
|
_ = x[Fatal-75]
|
||||||
_ = x[AltShiftUp-76]
|
_ = x[Mouse-76]
|
||||||
_ = x[AltShiftDown-77]
|
_ = x[DoubleClick-77]
|
||||||
_ = x[AltShiftLeft-78]
|
_ = x[LeftClick-78]
|
||||||
_ = x[AltShiftRight-79]
|
_ = x[RightClick-79]
|
||||||
_ = x[AltShiftDelete-80]
|
_ = x[SLeftClick-80]
|
||||||
_ = x[AltShiftHome-81]
|
_ = x[SRightClick-81]
|
||||||
_ = x[AltShiftEnd-82]
|
_ = x[ScrollUp-82]
|
||||||
_ = x[AltShiftPageUp-83]
|
_ = x[ScrollDown-83]
|
||||||
_ = x[AltShiftPageDown-84]
|
_ = x[SScrollUp-84]
|
||||||
_ = x[CtrlUp-85]
|
_ = x[SScrollDown-85]
|
||||||
_ = x[CtrlDown-86]
|
_ = x[PreviewScrollUp-86]
|
||||||
_ = x[CtrlLeft-87]
|
_ = x[PreviewScrollDown-87]
|
||||||
_ = x[CtrlRight-88]
|
_ = x[Resize-88]
|
||||||
_ = x[CtrlHome-89]
|
_ = x[Change-89]
|
||||||
_ = x[CtrlEnd-90]
|
_ = x[BackwardEOF-90]
|
||||||
_ = x[CtrlBackspace-91]
|
_ = x[Start-91]
|
||||||
_ = x[CtrlDelete-92]
|
_ = x[Load-92]
|
||||||
_ = x[CtrlPageUp-93]
|
_ = x[Focus-93]
|
||||||
_ = x[CtrlPageDown-94]
|
_ = x[One-94]
|
||||||
_ = x[Alt-95]
|
_ = x[Zero-95]
|
||||||
_ = x[CtrlAlt-96]
|
_ = x[Result-96]
|
||||||
_ = x[CtrlAltUp-97]
|
_ = x[Jump-97]
|
||||||
_ = x[CtrlAltDown-98]
|
_ = x[JumpCancel-98]
|
||||||
_ = x[CtrlAltLeft-99]
|
_ = x[ClickHeader-99]
|
||||||
_ = x[CtrlAltRight-100]
|
|
||||||
_ = x[CtrlAltHome-101]
|
|
||||||
_ = x[CtrlAltEnd-102]
|
|
||||||
_ = x[CtrlAltBackspace-103]
|
|
||||||
_ = x[CtrlAltDelete-104]
|
|
||||||
_ = x[CtrlAltPageUp-105]
|
|
||||||
_ = x[CtrlAltPageDown-106]
|
|
||||||
_ = x[CtrlShiftUp-107]
|
|
||||||
_ = x[CtrlShiftDown-108]
|
|
||||||
_ = x[CtrlShiftLeft-109]
|
|
||||||
_ = x[CtrlShiftRight-110]
|
|
||||||
_ = x[CtrlShiftHome-111]
|
|
||||||
_ = x[CtrlShiftEnd-112]
|
|
||||||
_ = x[CtrlShiftDelete-113]
|
|
||||||
_ = x[CtrlShiftPageUp-114]
|
|
||||||
_ = x[CtrlShiftPageDown-115]
|
|
||||||
_ = x[CtrlAltShiftUp-116]
|
|
||||||
_ = x[CtrlAltShiftDown-117]
|
|
||||||
_ = x[CtrlAltShiftLeft-118]
|
|
||||||
_ = x[CtrlAltShiftRight-119]
|
|
||||||
_ = x[CtrlAltShiftHome-120]
|
|
||||||
_ = x[CtrlAltShiftEnd-121]
|
|
||||||
_ = x[CtrlAltShiftDelete-122]
|
|
||||||
_ = x[CtrlAltShiftPageUp-123]
|
|
||||||
_ = x[CtrlAltShiftPageDown-124]
|
|
||||||
_ = x[Mouse-125]
|
|
||||||
_ = x[DoubleClick-126]
|
|
||||||
_ = x[LeftClick-127]
|
|
||||||
_ = x[RightClick-128]
|
|
||||||
_ = x[SLeftClick-129]
|
|
||||||
_ = x[SRightClick-130]
|
|
||||||
_ = x[ScrollUp-131]
|
|
||||||
_ = x[ScrollDown-132]
|
|
||||||
_ = x[SScrollUp-133]
|
|
||||||
_ = x[SScrollDown-134]
|
|
||||||
_ = x[PreviewScrollUp-135]
|
|
||||||
_ = x[PreviewScrollDown-136]
|
|
||||||
_ = x[Invalid-137]
|
|
||||||
_ = x[Fatal-138]
|
|
||||||
_ = x[BracketedPasteBegin-139]
|
|
||||||
_ = x[BracketedPasteEnd-140]
|
|
||||||
_ = x[Resize-141]
|
|
||||||
_ = x[Change-142]
|
|
||||||
_ = x[BackwardEOF-143]
|
|
||||||
_ = x[Start-144]
|
|
||||||
_ = x[Load-145]
|
|
||||||
_ = x[Focus-146]
|
|
||||||
_ = x[One-147]
|
|
||||||
_ = x[Zero-148]
|
|
||||||
_ = x[Result-149]
|
|
||||||
_ = x[Jump-150]
|
|
||||||
_ = x[JumpCancel-151]
|
|
||||||
_ = x[ClickHeader-152]
|
|
||||||
_ = x[ClickFooter-153]
|
|
||||||
_ = x[Multi-154]
|
|
||||||
_ = x[Every-155]
|
|
||||||
_ = x[ResultFinal-156]
|
|
||||||
}
|
}
|
||||||
|
|
||||||
const _EventType_name = "RuneCtrlACtrlBCtrlCCtrlDCtrlECtrlFCtrlGCtrlHTabCtrlJCtrlKCtrlLEnterCtrlNCtrlOCtrlPCtrlQCtrlRCtrlSCtrlTCtrlUCtrlVCtrlWCtrlXCtrlYCtrlZEscCtrlSpaceCtrlBackSlashCtrlRightBracketCtrlCaretCtrlSlashShiftTabBackspaceDeletePageUpPageDownUpDownLeftRightHomeEndInsertShiftUpShiftDownShiftLeftShiftRightShiftDeleteShiftHomeShiftEndShiftPageUpShiftPageDownF1F2F3F4F5F6F7F8F9F10F11F12AltBackspaceAltUpAltDownAltLeftAltRightAltDeleteAltHomeAltEndAltPageUpAltPageDownAltShiftUpAltShiftDownAltShiftLeftAltShiftRightAltShiftDeleteAltShiftHomeAltShiftEndAltShiftPageUpAltShiftPageDownCtrlUpCtrlDownCtrlLeftCtrlRightCtrlHomeCtrlEndCtrlBackspaceCtrlDeleteCtrlPageUpCtrlPageDownAltCtrlAltCtrlAltUpCtrlAltDownCtrlAltLeftCtrlAltRightCtrlAltHomeCtrlAltEndCtrlAltBackspaceCtrlAltDeleteCtrlAltPageUpCtrlAltPageDownCtrlShiftUpCtrlShiftDownCtrlShiftLeftCtrlShiftRightCtrlShiftHomeCtrlShiftEndCtrlShiftDeleteCtrlShiftPageUpCtrlShiftPageDownCtrlAltShiftUpCtrlAltShiftDownCtrlAltShiftLeftCtrlAltShiftRightCtrlAltShiftHomeCtrlAltShiftEndCtrlAltShiftDeleteCtrlAltShiftPageUpCtrlAltShiftPageDownMouseDoubleClickLeftClickRightClickSLeftClickSRightClickScrollUpScrollDownSScrollUpSScrollDownPreviewScrollUpPreviewScrollDownInvalidFatalBracketedPasteBeginBracketedPasteEndResizeChangeBackwardEOFStartLoadFocusOneZeroResultJumpJumpCancelClickHeaderClickFooterMultiEveryResultFinal"
|
const _EventType_name = "RuneCtrlACtrlBCtrlCCtrlDCtrlECtrlFCtrlGCtrlHTabCtrlJCtrlKCtrlLCtrlMCtrlNCtrlOCtrlPCtrlQCtrlRCtrlSCtrlTCtrlUCtrlVCtrlWCtrlXCtrlYCtrlZEscCtrlSpaceCtrlDeleteCtrlBackSlashCtrlRightBracketCtrlCaretCtrlSlashShiftTabBackspaceDeletePageUpPageDownUpDownLeftRightHomeEndInsertShiftUpShiftDownShiftLeftShiftRightShiftDeleteF1F2F3F4F5F6F7F8F9F10F11F12AltBackspaceAltUpAltDownAltLeftAltRightAltShiftUpAltShiftDownAltShiftLeftAltShiftRightAltCtrlAltInvalidFatalMouseDoubleClickLeftClickRightClickSLeftClickSRightClickScrollUpScrollDownSScrollUpSScrollDownPreviewScrollUpPreviewScrollDownResizeChangeBackwardEOFStartLoadFocusOneZeroResultJumpJumpCancelClickHeader"
|
||||||
|
|
||||||
var _EventType_index = [...]uint16{0, 4, 9, 14, 19, 24, 29, 34, 39, 44, 47, 52, 57, 62, 67, 72, 77, 82, 87, 92, 97, 102, 107, 112, 117, 122, 127, 132, 135, 144, 157, 173, 182, 191, 199, 208, 214, 220, 228, 230, 234, 238, 243, 247, 250, 256, 263, 272, 281, 291, 302, 311, 319, 330, 343, 345, 347, 349, 351, 353, 355, 357, 359, 361, 364, 367, 370, 382, 387, 394, 401, 409, 418, 425, 431, 440, 451, 461, 473, 485, 498, 512, 524, 535, 549, 565, 571, 579, 587, 596, 604, 611, 624, 634, 644, 656, 659, 666, 675, 686, 697, 709, 720, 730, 746, 759, 772, 787, 798, 811, 824, 838, 851, 863, 878, 893, 910, 924, 940, 956, 973, 989, 1004, 1022, 1040, 1060, 1065, 1076, 1085, 1095, 1105, 1116, 1124, 1134, 1143, 1154, 1169, 1186, 1193, 1198, 1217, 1234, 1240, 1246, 1257, 1262, 1266, 1271, 1274, 1278, 1284, 1288, 1298, 1309, 1320, 1325, 1330, 1341}
|
var _EventType_index = [...]uint16{0, 4, 9, 14, 19, 24, 29, 34, 39, 44, 47, 52, 57, 62, 67, 72, 77, 82, 87, 92, 97, 102, 107, 112, 117, 122, 127, 132, 135, 144, 154, 167, 183, 192, 201, 209, 218, 224, 230, 238, 240, 244, 248, 253, 257, 260, 266, 273, 282, 291, 301, 312, 314, 316, 318, 320, 322, 324, 326, 328, 330, 333, 336, 339, 351, 356, 363, 370, 378, 388, 400, 412, 425, 428, 435, 442, 447, 452, 463, 472, 482, 492, 503, 511, 521, 530, 541, 556, 573, 579, 585, 596, 601, 605, 610, 613, 617, 623, 627, 637, 648}
|
||||||
|
|
||||||
func (i EventType) String() string {
|
func (i EventType) String() string {
|
||||||
if i < 0 || i >= EventType(len(_EventType_index)-1) {
|
if i < 0 || i >= EventType(len(_EventType_index)-1) {
|
||||||
|
|||||||
+249
-643
File diff suppressed because it is too large
Load Diff
@@ -1,352 +0,0 @@
|
|||||||
package tui
|
|
||||||
|
|
||||||
import (
|
|
||||||
"fmt"
|
|
||||||
"os"
|
|
||||||
"testing"
|
|
||||||
"unicode"
|
|
||||||
)
|
|
||||||
|
|
||||||
func TestLightRenderer(t *testing.T) {
|
|
||||||
tty_file, _ := os.Open("")
|
|
||||||
renderer, _ := NewLightRenderer(
|
|
||||||
"", tty_file, &ColorTheme{}, true, false, 0, false, true,
|
|
||||||
func(h int) int { return h })
|
|
||||||
|
|
||||||
light_renderer := renderer.(*LightRenderer)
|
|
||||||
|
|
||||||
go func() {
|
|
||||||
for {
|
|
||||||
light_renderer.mutex.Lock()
|
|
||||||
ready := light_renderer.cancel != nil
|
|
||||||
light_renderer.mutex.Unlock()
|
|
||||||
|
|
||||||
if ready {
|
|
||||||
light_renderer.CancelGetChar()
|
|
||||||
break
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}()
|
|
||||||
event := light_renderer.GetChar(true)
|
|
||||||
if event.Type != Invalid {
|
|
||||||
t.Error("Not cancelled")
|
|
||||||
}
|
|
||||||
|
|
||||||
assertCharSequence := func(sequence string, name string) {
|
|
||||||
bytes := []byte(sequence)
|
|
||||||
light_renderer.buffer = bytes
|
|
||||||
event := light_renderer.GetChar(true)
|
|
||||||
if event.KeyName() != name {
|
|
||||||
t.Errorf(
|
|
||||||
"sequence: %q | %v | '%s' (%s) != %s",
|
|
||||||
string(bytes), bytes,
|
|
||||||
event.KeyName(), event.Type.String(), name)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
assertEscSequence := func(sequence string, name string) {
|
|
||||||
bytes := []byte(sequence)
|
|
||||||
light_renderer.buffer = bytes
|
|
||||||
|
|
||||||
sz := 1
|
|
||||||
event := light_renderer.escSequence(&sz)
|
|
||||||
if fmt.Sprintf("!%s", event.Type.String()) == name {
|
|
||||||
// this is fine
|
|
||||||
} else if event.KeyName() != name {
|
|
||||||
t.Errorf(
|
|
||||||
"sequence: %q | %v | '%s' (%s) != %s",
|
|
||||||
string(bytes), bytes,
|
|
||||||
event.KeyName(), event.Type.String(), name)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// invalid
|
|
||||||
assertEscSequence("\x1b[<", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[1;1R", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[1", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[3;3~1", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[13", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[1;3", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[1;10", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[220~", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[5;30~", "!Invalid")
|
|
||||||
assertEscSequence("\x1b[6;30~", "!Invalid")
|
|
||||||
|
|
||||||
// general
|
|
||||||
for r := 'a'; r < 'z'; r++ {
|
|
||||||
lower_r := fmt.Sprintf("%c", r)
|
|
||||||
upper_r := fmt.Sprintf("%c", unicode.ToUpper(r))
|
|
||||||
assertCharSequence(lower_r, lower_r)
|
|
||||||
assertCharSequence(upper_r, upper_r)
|
|
||||||
}
|
|
||||||
|
|
||||||
assertCharSequence("\x01", "ctrl-a")
|
|
||||||
assertCharSequence("\x02", "ctrl-b")
|
|
||||||
assertCharSequence("\x03", "ctrl-c")
|
|
||||||
assertCharSequence("\x04", "ctrl-d")
|
|
||||||
assertCharSequence("\x05", "ctrl-e")
|
|
||||||
assertCharSequence("\x06", "ctrl-f")
|
|
||||||
assertCharSequence("\x07", "ctrl-g")
|
|
||||||
// ctrl-h is the same as ctrl-backspace
|
|
||||||
// ctrl-i is the same as tab
|
|
||||||
assertCharSequence("\n", "ctrl-j")
|
|
||||||
assertCharSequence("\x0b", "ctrl-k")
|
|
||||||
assertCharSequence("\x0c", "ctrl-l")
|
|
||||||
assertCharSequence("\r", "enter") // enter
|
|
||||||
assertCharSequence("\x0e", "ctrl-n")
|
|
||||||
assertCharSequence("\x0f", "ctrl-o")
|
|
||||||
assertCharSequence("\x10", "ctrl-p")
|
|
||||||
assertCharSequence("\x11", "ctrl-q")
|
|
||||||
assertCharSequence("\x12", "ctrl-r")
|
|
||||||
assertCharSequence("\x13", "ctrl-s")
|
|
||||||
assertCharSequence("\x14", "ctrl-t")
|
|
||||||
assertCharSequence("\x15", "ctrl-u")
|
|
||||||
assertCharSequence("\x16", "ctrl-v")
|
|
||||||
assertCharSequence("\x17", "ctrl-w")
|
|
||||||
assertCharSequence("\x18", "ctrl-x")
|
|
||||||
assertCharSequence("\x19", "ctrl-y")
|
|
||||||
assertCharSequence("\x1a", "ctrl-z")
|
|
||||||
|
|
||||||
assertCharSequence("\x00", "ctrl-space")
|
|
||||||
assertCharSequence("\x1c", "ctrl-\\")
|
|
||||||
assertCharSequence("\x1d", "ctrl-]")
|
|
||||||
assertCharSequence("\x1e", "ctrl-^")
|
|
||||||
assertCharSequence("\x1f", "ctrl-/")
|
|
||||||
|
|
||||||
assertEscSequence("\x1ba", "alt-a")
|
|
||||||
assertEscSequence("\x1bb", "alt-b")
|
|
||||||
assertEscSequence("\x1bc", "alt-c")
|
|
||||||
assertEscSequence("\x1bd", "alt-d")
|
|
||||||
assertEscSequence("\x1be", "alt-e")
|
|
||||||
assertEscSequence("\x1bf", "alt-f")
|
|
||||||
assertEscSequence("\x1bg", "alt-g")
|
|
||||||
assertEscSequence("\x1bh", "alt-h")
|
|
||||||
assertEscSequence("\x1bi", "alt-i")
|
|
||||||
assertEscSequence("\x1bj", "alt-j")
|
|
||||||
assertEscSequence("\x1bk", "alt-k")
|
|
||||||
assertEscSequence("\x1bl", "alt-l")
|
|
||||||
assertEscSequence("\x1bm", "alt-m")
|
|
||||||
assertEscSequence("\x1bn", "alt-n")
|
|
||||||
assertEscSequence("\x1bo", "alt-o")
|
|
||||||
assertEscSequence("\x1bp", "alt-p")
|
|
||||||
assertEscSequence("\x1bq", "alt-q")
|
|
||||||
assertEscSequence("\x1br", "alt-r")
|
|
||||||
assertEscSequence("\x1bs", "alt-s")
|
|
||||||
assertEscSequence("\x1bt", "alt-t")
|
|
||||||
assertEscSequence("\x1bu", "alt-u")
|
|
||||||
assertEscSequence("\x1bv", "alt-v")
|
|
||||||
assertEscSequence("\x1bw", "alt-w")
|
|
||||||
assertEscSequence("\x1bx", "alt-x")
|
|
||||||
assertEscSequence("\x1by", "alt-y")
|
|
||||||
assertEscSequence("\x1bz", "alt-z")
|
|
||||||
|
|
||||||
assertEscSequence("\x1bOP", "f1")
|
|
||||||
assertEscSequence("\x1bOQ", "f2")
|
|
||||||
assertEscSequence("\x1bOR", "f3")
|
|
||||||
assertEscSequence("\x1bOS", "f4")
|
|
||||||
assertEscSequence("\x1b[15~", "f5")
|
|
||||||
assertEscSequence("\x1b[17~", "f6")
|
|
||||||
assertEscSequence("\x1b[18~", "f7")
|
|
||||||
assertEscSequence("\x1b[19~", "f8")
|
|
||||||
assertEscSequence("\x1b[20~", "f9")
|
|
||||||
assertEscSequence("\x1b[21~", "f10")
|
|
||||||
assertEscSequence("\x1b[23~", "f11")
|
|
||||||
assertEscSequence("\x1b[24~", "f12")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b", "esc")
|
|
||||||
assertCharSequence("\t", "tab")
|
|
||||||
assertEscSequence("\x1b[Z", "shift-tab")
|
|
||||||
|
|
||||||
assertCharSequence("\x7f", "backspace")
|
|
||||||
assertEscSequence("\x1b\x7f", "alt-backspace")
|
|
||||||
assertCharSequence("\b", "ctrl-backspace")
|
|
||||||
assertEscSequence("\x1b\b", "ctrl-alt-backspace")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[A", "up")
|
|
||||||
assertEscSequence("\x1b[B", "down")
|
|
||||||
assertEscSequence("\x1b[C", "right")
|
|
||||||
assertEscSequence("\x1b[D", "left")
|
|
||||||
assertEscSequence("\x1b[H", "home")
|
|
||||||
assertEscSequence("\x1b[F", "end")
|
|
||||||
assertEscSequence("\x1b[2~", "insert")
|
|
||||||
assertEscSequence("\x1b[3~", "delete")
|
|
||||||
assertEscSequence("\x1b[5~", "page-up")
|
|
||||||
assertEscSequence("\x1b[6~", "page-down")
|
|
||||||
assertEscSequence("\x1b[7~", "home")
|
|
||||||
assertEscSequence("\x1b[8~", "end")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;2A", "shift-up")
|
|
||||||
assertEscSequence("\x1b[1;2B", "shift-down")
|
|
||||||
assertEscSequence("\x1b[1;2C", "shift-right")
|
|
||||||
assertEscSequence("\x1b[1;2D", "shift-left")
|
|
||||||
assertEscSequence("\x1b[1;2H", "shift-home")
|
|
||||||
assertEscSequence("\x1b[1;2F", "shift-end")
|
|
||||||
assertEscSequence("\x1b[3;2~", "shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;2~", "shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;2~", "shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b\x1b", "esc")
|
|
||||||
assertEscSequence("\x1b\x1b[A", "alt-up")
|
|
||||||
assertEscSequence("\x1b\x1b[B", "alt-down")
|
|
||||||
assertEscSequence("\x1b\x1b[C", "alt-right")
|
|
||||||
assertEscSequence("\x1b\x1b[D", "alt-left")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;3A", "alt-up")
|
|
||||||
assertEscSequence("\x1b[1;3B", "alt-down")
|
|
||||||
assertEscSequence("\x1b[1;3C", "alt-right")
|
|
||||||
assertEscSequence("\x1b[1;3D", "alt-left")
|
|
||||||
assertEscSequence("\x1b[1;3H", "alt-home")
|
|
||||||
assertEscSequence("\x1b[1;3F", "alt-end")
|
|
||||||
assertEscSequence("\x1b[3;3~", "alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;3~", "alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;3~", "alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;4A", "alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;4B", "alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;4C", "alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;4D", "alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;4H", "alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;4F", "alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;4~", "alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;4~", "alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;4~", "alt-shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;5A", "ctrl-up")
|
|
||||||
assertEscSequence("\x1b[1;5B", "ctrl-down")
|
|
||||||
assertEscSequence("\x1b[1;5C", "ctrl-right")
|
|
||||||
assertEscSequence("\x1b[1;5D", "ctrl-left")
|
|
||||||
assertEscSequence("\x1b[1;5H", "ctrl-home")
|
|
||||||
assertEscSequence("\x1b[1;5F", "ctrl-end")
|
|
||||||
assertEscSequence("\x1b[3;5~", "ctrl-delete")
|
|
||||||
assertEscSequence("\x1b[5;5~", "ctrl-page-up")
|
|
||||||
assertEscSequence("\x1b[6;5~", "ctrl-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;7A", "ctrl-alt-up")
|
|
||||||
assertEscSequence("\x1b[1;7B", "ctrl-alt-down")
|
|
||||||
assertEscSequence("\x1b[1;7C", "ctrl-alt-right")
|
|
||||||
assertEscSequence("\x1b[1;7D", "ctrl-alt-left")
|
|
||||||
assertEscSequence("\x1b[1;7H", "ctrl-alt-home")
|
|
||||||
assertEscSequence("\x1b[1;7F", "ctrl-alt-end")
|
|
||||||
assertEscSequence("\x1b[3;7~", "ctrl-alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;7~", "ctrl-alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;7~", "ctrl-alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;6A", "ctrl-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;6B", "ctrl-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;6C", "ctrl-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;6D", "ctrl-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;6H", "ctrl-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;6F", "ctrl-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;6~", "ctrl-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;6~", "ctrl-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;6~", "ctrl-shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;8A", "ctrl-alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;8B", "ctrl-alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;8C", "ctrl-alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;8D", "ctrl-alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;8H", "ctrl-alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;8F", "ctrl-alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;8~", "ctrl-alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;8~", "ctrl-alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;8~", "ctrl-alt-shift-page-down")
|
|
||||||
|
|
||||||
// xterm meta & mac
|
|
||||||
assertEscSequence("\x1b[1;9A", "alt-up")
|
|
||||||
assertEscSequence("\x1b[1;9B", "alt-down")
|
|
||||||
assertEscSequence("\x1b[1;9C", "alt-right")
|
|
||||||
assertEscSequence("\x1b[1;9D", "alt-left")
|
|
||||||
assertEscSequence("\x1b[1;9H", "alt-home")
|
|
||||||
assertEscSequence("\x1b[1;9F", "alt-end")
|
|
||||||
assertEscSequence("\x1b[3;9~", "alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;9~", "alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;9~", "alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;10A", "alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;10B", "alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;10C", "alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;10D", "alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;10H", "alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;10F", "alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;10~", "alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;10~", "alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;10~", "alt-shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;11A", "alt-up")
|
|
||||||
assertEscSequence("\x1b[1;11B", "alt-down")
|
|
||||||
assertEscSequence("\x1b[1;11C", "alt-right")
|
|
||||||
assertEscSequence("\x1b[1;11D", "alt-left")
|
|
||||||
assertEscSequence("\x1b[1;11H", "alt-home")
|
|
||||||
assertEscSequence("\x1b[1;11F", "alt-end")
|
|
||||||
assertEscSequence("\x1b[3;11~", "alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;11~", "alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;11~", "alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;12A", "alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;12B", "alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;12C", "alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;12D", "alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;12H", "alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;12F", "alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;12~", "alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;12~", "alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;12~", "alt-shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;13A", "ctrl-alt-up")
|
|
||||||
assertEscSequence("\x1b[1;13B", "ctrl-alt-down")
|
|
||||||
assertEscSequence("\x1b[1;13C", "ctrl-alt-right")
|
|
||||||
assertEscSequence("\x1b[1;13D", "ctrl-alt-left")
|
|
||||||
assertEscSequence("\x1b[1;13H", "ctrl-alt-home")
|
|
||||||
assertEscSequence("\x1b[1;13F", "ctrl-alt-end")
|
|
||||||
assertEscSequence("\x1b[3;13~", "ctrl-alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;13~", "ctrl-alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;13~", "ctrl-alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;14A", "ctrl-alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;14B", "ctrl-alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;14C", "ctrl-alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;14D", "ctrl-alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;14H", "ctrl-alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;14F", "ctrl-alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;14~", "ctrl-alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;14~", "ctrl-alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;14~", "ctrl-alt-shift-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;15A", "ctrl-alt-up")
|
|
||||||
assertEscSequence("\x1b[1;15B", "ctrl-alt-down")
|
|
||||||
assertEscSequence("\x1b[1;15C", "ctrl-alt-right")
|
|
||||||
assertEscSequence("\x1b[1;15D", "ctrl-alt-left")
|
|
||||||
assertEscSequence("\x1b[1;15H", "ctrl-alt-home")
|
|
||||||
assertEscSequence("\x1b[1;15F", "ctrl-alt-end")
|
|
||||||
assertEscSequence("\x1b[3;15~", "ctrl-alt-delete")
|
|
||||||
assertEscSequence("\x1b[5;15~", "ctrl-alt-page-up")
|
|
||||||
assertEscSequence("\x1b[6;15~", "ctrl-alt-page-down")
|
|
||||||
|
|
||||||
assertEscSequence("\x1b[1;16A", "ctrl-alt-shift-up")
|
|
||||||
assertEscSequence("\x1b[1;16B", "ctrl-alt-shift-down")
|
|
||||||
assertEscSequence("\x1b[1;16C", "ctrl-alt-shift-right")
|
|
||||||
assertEscSequence("\x1b[1;16D", "ctrl-alt-shift-left")
|
|
||||||
assertEscSequence("\x1b[1;16H", "ctrl-alt-shift-home")
|
|
||||||
assertEscSequence("\x1b[1;16F", "ctrl-alt-shift-end")
|
|
||||||
assertEscSequence("\x1b[3;16~", "ctrl-alt-shift-delete")
|
|
||||||
assertEscSequence("\x1b[5;16~", "ctrl-alt-shift-page-up")
|
|
||||||
assertEscSequence("\x1b[6;16~", "ctrl-alt-shift-page-down")
|
|
||||||
|
|
||||||
// tmux & emacs
|
|
||||||
assertEscSequence("\x1bOA", "up")
|
|
||||||
assertEscSequence("\x1bOB", "down")
|
|
||||||
assertEscSequence("\x1bOC", "right")
|
|
||||||
assertEscSequence("\x1bOD", "left")
|
|
||||||
assertEscSequence("\x1bOH", "home")
|
|
||||||
assertEscSequence("\x1bOF", "end")
|
|
||||||
|
|
||||||
// rrvt
|
|
||||||
assertEscSequence("\x1b[1~", "home")
|
|
||||||
assertEscSequence("\x1b[4~", "end")
|
|
||||||
assertEscSequence("\x1b[11~", "f1")
|
|
||||||
assertEscSequence("\x1b[12~", "f2")
|
|
||||||
assertEscSequence("\x1b[13~", "f3")
|
|
||||||
assertEscSequence("\x1b[14~", "f4")
|
|
||||||
|
|
||||||
}
|
|
||||||
+17
-73
@@ -18,7 +18,7 @@ func IsLightRendererSupported() bool {
|
|||||||
return true
|
return true
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) DefaultTheme() *ColorTheme {
|
func (r *LightRenderer) defaultTheme() *ColorTheme {
|
||||||
if strings.Contains(os.Getenv("TERM"), "256") {
|
if strings.Contains(os.Getenv("TERM"), "256") {
|
||||||
return Dark256
|
return Dark256
|
||||||
}
|
}
|
||||||
@@ -42,35 +42,26 @@ func (r *LightRenderer) closePlatform() {
|
|||||||
r.ttyout.Close()
|
r.ttyout.Close()
|
||||||
}
|
}
|
||||||
|
|
||||||
func openTty(ttyDefault string, mode int) (*os.File, error) {
|
func openTty(mode int) (*os.File, error) {
|
||||||
var in *os.File
|
in, err := os.OpenFile(consoleDevice, mode, 0)
|
||||||
var err error
|
if err != nil {
|
||||||
if len(ttyDefault) > 0 {
|
|
||||||
in, err = os.OpenFile(ttyDefault, mode, 0)
|
|
||||||
}
|
|
||||||
if in == nil || err != nil || ttyDefault != DefaultTtyDevice && !util.IsTty(in) {
|
|
||||||
tty := ttyname()
|
tty := ttyname()
|
||||||
if len(tty) > 0 {
|
if len(tty) > 0 {
|
||||||
if in, err := os.OpenFile(tty, mode, 0); err == nil {
|
if in, err := os.OpenFile(tty, mode, 0); err == nil {
|
||||||
return in, nil
|
return in, nil
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
if ttyDefault != DefaultTtyDevice {
|
return nil, errors.New("failed to open " + consoleDevice)
|
||||||
if in, err = os.OpenFile(DefaultTtyDevice, mode, 0); err == nil {
|
|
||||||
return in, nil
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return nil, errors.New("failed to open " + DefaultTtyDevice)
|
|
||||||
}
|
}
|
||||||
return in, nil
|
return in, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func openTtyIn(ttyDefault string) (*os.File, error) {
|
func openTtyIn() (*os.File, error) {
|
||||||
return openTty(ttyDefault, syscall.O_RDONLY)
|
return openTty(syscall.O_RDONLY)
|
||||||
}
|
}
|
||||||
|
|
||||||
func openTtyOut(ttyDefault string) (*os.File, error) {
|
func openTtyOut() (*os.File, error) {
|
||||||
return openTty(ttyDefault, syscall.O_WRONLY)
|
return openTty(syscall.O_WRONLY)
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) setupTerminal() {
|
func (r *LightRenderer) setupTerminal() {
|
||||||
@@ -98,8 +89,8 @@ func (r *LightRenderer) findOffset() (row int, col int) {
|
|||||||
r.flush()
|
r.flush()
|
||||||
var err error
|
var err error
|
||||||
bytes := []byte{}
|
bytes := []byte{}
|
||||||
for tries := range offsetPollTries {
|
for tries := 0; tries < offsetPollTries; tries++ {
|
||||||
bytes, _, err = r.getBytesInternal(false, bytes, tries > 0)
|
bytes, err = r.getBytesInternal(bytes, tries > 0)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
return -1, -1
|
return -1, -1
|
||||||
}
|
}
|
||||||
@@ -114,62 +105,15 @@ func (r *LightRenderer) findOffset() (row int, col int) {
|
|||||||
return -1, -1
|
return -1, -1
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) getch(cancellable bool, nonblock bool) (int, getCharResult) {
|
func (r *LightRenderer) getch(nonblock bool) (int, bool) {
|
||||||
|
b := make([]byte, 1)
|
||||||
fd := r.fd()
|
fd := r.fd()
|
||||||
getter := func() (int, getCharResult) {
|
util.SetNonblock(r.ttyin, nonblock)
|
||||||
b := make([]byte, 1)
|
_, err := util.Read(fd, b)
|
||||||
util.SetNonblock(r.ttyin, nonblock)
|
|
||||||
_, err := util.Read(fd, b)
|
|
||||||
if err != nil {
|
|
||||||
return 0, getCharError
|
|
||||||
}
|
|
||||||
return int(b[0]), getCharSuccess
|
|
||||||
}
|
|
||||||
if nonblock || !cancellable {
|
|
||||||
return getter()
|
|
||||||
}
|
|
||||||
|
|
||||||
rpipe, wpipe, err := os.Pipe()
|
|
||||||
if err != nil {
|
if err != nil {
|
||||||
// Fallback to blocking read without cancellation
|
return 0, false
|
||||||
return getter()
|
|
||||||
}
|
}
|
||||||
r.setCancel(func() {
|
return int(b[0]), true
|
||||||
wpipe.Write([]byte{0})
|
|
||||||
})
|
|
||||||
defer func() {
|
|
||||||
r.setCancel(nil)
|
|
||||||
rpipe.Close()
|
|
||||||
wpipe.Close()
|
|
||||||
}()
|
|
||||||
|
|
||||||
cancelFd := int(rpipe.Fd())
|
|
||||||
for range maxSelectTries {
|
|
||||||
var rfds unix.FdSet
|
|
||||||
limit := len(rfds.Bits) * unix.NFDBITS
|
|
||||||
if fd >= limit || cancelFd >= limit {
|
|
||||||
return getter()
|
|
||||||
}
|
|
||||||
|
|
||||||
rfds.Set(fd)
|
|
||||||
rfds.Set(cancelFd)
|
|
||||||
_, err := unix.Select(max(fd, cancelFd)+1, &rfds, nil, nil, nil)
|
|
||||||
if err != nil {
|
|
||||||
if err == syscall.EINTR {
|
|
||||||
continue
|
|
||||||
}
|
|
||||||
return 0, getCharError
|
|
||||||
}
|
|
||||||
|
|
||||||
if rfds.IsSet(cancelFd) {
|
|
||||||
return 0, getCharCancelled
|
|
||||||
}
|
|
||||||
|
|
||||||
if rfds.IsSet(fd) {
|
|
||||||
return getter()
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return 0, getCharError
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) Size() TermSize {
|
func (r *LightRenderer) Size() TermSize {
|
||||||
|
|||||||
+40
-66
@@ -18,7 +18,6 @@ const (
|
|||||||
var (
|
var (
|
||||||
consoleFlagsInput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_INPUT | windows.ENABLE_PROCESSED_INPUT | windows.ENABLE_EXTENDED_FLAGS)
|
consoleFlagsInput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_INPUT | windows.ENABLE_PROCESSED_INPUT | windows.ENABLE_EXTENDED_FLAGS)
|
||||||
consoleFlagsOutput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING | windows.ENABLE_PROCESSED_OUTPUT | windows.DISABLE_NEWLINE_AUTO_RETURN)
|
consoleFlagsOutput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING | windows.ENABLE_PROCESSED_OUTPUT | windows.DISABLE_NEWLINE_AUTO_RETURN)
|
||||||
counter = uint64(0)
|
|
||||||
)
|
)
|
||||||
|
|
||||||
// IsLightRendererSupported checks to see if the Light renderer is supported
|
// IsLightRendererSupported checks to see if the Light renderer is supported
|
||||||
@@ -40,7 +39,7 @@ func IsLightRendererSupported() bool {
|
|||||||
return canSetVt100
|
return canSetVt100
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) DefaultTheme() *ColorTheme {
|
func (r *LightRenderer) defaultTheme() *ColorTheme {
|
||||||
// the getenv check is borrowed from here: https://github.com/gdamore/tcell/commit/0c473b86d82f68226a142e96cc5a34c5a29b3690#diff-b008fcd5e6934bf31bc3d33bf49f47d8R178:
|
// the getenv check is borrowed from here: https://github.com/gdamore/tcell/commit/0c473b86d82f68226a142e96cc5a34c5a29b3690#diff-b008fcd5e6934bf31bc3d33bf49f47d8R178:
|
||||||
if !IsLightRendererSupported() || os.Getenv("ConEmuPID") != "" || os.Getenv("TCELL_TRUECOLOR") == "disable" {
|
if !IsLightRendererSupported() || os.Getenv("ConEmuPID") != "" || os.Getenv("TCELL_TRUECOLOR") == "disable" {
|
||||||
return Default16
|
return Default16
|
||||||
@@ -62,11 +61,27 @@ func (r *LightRenderer) initPlatform() error {
|
|||||||
}
|
}
|
||||||
r.inHandle = uintptr(inHandle)
|
r.inHandle = uintptr(inHandle)
|
||||||
|
|
||||||
|
r.setupTerminal()
|
||||||
|
|
||||||
// channel for non-blocking reads. Buffer to make sure
|
// channel for non-blocking reads. Buffer to make sure
|
||||||
// we get the ESC sets:
|
// we get the ESC sets:
|
||||||
r.ttyinChannel = make(chan byte, 1024)
|
r.ttyinChannel = make(chan byte, 1024)
|
||||||
|
|
||||||
r.setupTerminal()
|
// the following allows for non-blocking IO.
|
||||||
|
// syscall.SetNonblock() is a NOOP under Windows.
|
||||||
|
go func() {
|
||||||
|
fd := int(r.inHandle)
|
||||||
|
b := make([]byte, 1)
|
||||||
|
for !r.closed.Get() {
|
||||||
|
// HACK: if run from PSReadline, something resets ConsoleMode to remove ENABLE_VIRTUAL_TERMINAL_INPUT.
|
||||||
|
_ = windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
||||||
|
|
||||||
|
_, err := util.Read(fd, b)
|
||||||
|
if err == nil {
|
||||||
|
r.ttyinChannel <- b[0]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}()
|
||||||
|
|
||||||
return nil
|
return nil
|
||||||
}
|
}
|
||||||
@@ -76,51 +91,27 @@ func (r *LightRenderer) closePlatform() {
|
|||||||
windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput)
|
windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput)
|
||||||
}
|
}
|
||||||
|
|
||||||
func openTtyIn(ttyDefault string) (*os.File, error) {
|
func openTtyIn() (*os.File, error) {
|
||||||
// not used
|
// not used
|
||||||
return nil, nil
|
return nil, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func openTtyOut(ttyDefault string) (*os.File, error) {
|
func openTtyOut() (*os.File, error) {
|
||||||
return os.Stderr, nil
|
return os.Stderr, nil
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) setupTerminal() {
|
func (r *LightRenderer) setupTerminal() error {
|
||||||
windows.SetConsoleMode(windows.Handle(r.outHandle), consoleFlagsOutput)
|
if err := windows.SetConsoleMode(windows.Handle(r.outHandle), consoleFlagsOutput); err != nil {
|
||||||
windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
return err
|
||||||
|
}
|
||||||
// The following allows for non-blocking IO.
|
return windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
||||||
// syscall.SetNonblock() is a NOOP under Windows.
|
|
||||||
current := counter
|
|
||||||
go func() {
|
|
||||||
fd := int(r.inHandle)
|
|
||||||
b := make([]byte, 1)
|
|
||||||
for {
|
|
||||||
if _, err := util.Read(fd, b); err == nil {
|
|
||||||
r.mutex.Lock()
|
|
||||||
// This condition prevents the goroutine from running after the renderer
|
|
||||||
// has been closed or paused.
|
|
||||||
if current != counter {
|
|
||||||
r.mutex.Unlock()
|
|
||||||
break
|
|
||||||
}
|
|
||||||
r.ttyinChannel <- b[0]
|
|
||||||
// HACK: if run from PSReadline, something resets ConsoleMode to remove ENABLE_VIRTUAL_TERMINAL_INPUT.
|
|
||||||
windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
|
||||||
r.mutex.Unlock()
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}()
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) restoreTerminal() {
|
func (r *LightRenderer) restoreTerminal() error {
|
||||||
r.mutex.Lock()
|
if err := windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput); err != nil {
|
||||||
counter++
|
return err
|
||||||
// We're setting ENABLE_VIRTUAL_TERMINAL_INPUT to allow escape sequences to be read during 'execute'.
|
}
|
||||||
// e.g. fzf --bind 'enter:execute:less {}'
|
return windows.SetConsoleMode(windows.Handle(r.outHandle), r.origStateOutput)
|
||||||
windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput|windows.ENABLE_VIRTUAL_TERMINAL_INPUT)
|
|
||||||
windows.SetConsoleMode(windows.Handle(r.outHandle), r.origStateOutput)
|
|
||||||
r.mutex.Unlock()
|
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) Size() TermSize {
|
func (r *LightRenderer) Size() TermSize {
|
||||||
@@ -151,33 +142,16 @@ func (r *LightRenderer) findOffset() (row int, col int) {
|
|||||||
return int(bufferInfo.CursorPosition.Y), int(bufferInfo.CursorPosition.X)
|
return int(bufferInfo.CursorPosition.Y), int(bufferInfo.CursorPosition.X)
|
||||||
}
|
}
|
||||||
|
|
||||||
func (r *LightRenderer) getch(cancellable bool, nonblock bool) (int, getCharResult) {
|
func (r *LightRenderer) getch(nonblock bool) (int, bool) {
|
||||||
if !nonblock && !cancellable {
|
|
||||||
bc := <-r.ttyinChannel
|
|
||||||
return int(bc), getCharSuccess
|
|
||||||
}
|
|
||||||
|
|
||||||
var timeout <-chan time.Time
|
|
||||||
if nonblock {
|
if nonblock {
|
||||||
timeout = time.After(timeoutInterval * time.Millisecond)
|
select {
|
||||||
}
|
case bc := <-r.ttyinChannel:
|
||||||
|
return int(bc), true
|
||||||
var cancel chan struct{}
|
case <-time.After(timeoutInterval * time.Millisecond):
|
||||||
if cancellable {
|
return 0, false
|
||||||
cancel = make(chan struct{})
|
}
|
||||||
r.setCancel(func() {
|
} else {
|
||||||
close(cancel)
|
bc := <-r.ttyinChannel
|
||||||
})
|
return int(bc), true
|
||||||
defer r.setCancel(nil)
|
|
||||||
}
|
|
||||||
|
|
||||||
select {
|
|
||||||
case bc := <-r.ttyinChannel:
|
|
||||||
return int(bc), getCharSuccess
|
|
||||||
case <-cancel:
|
|
||||||
return 0, getCharCancelled
|
|
||||||
case <-timeout:
|
|
||||||
// NOTE: not really an error
|
|
||||||
return 0, getCharError
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user